¿Sabías que la forma en que marcas tu texto puede mejorar o deshacer tu modelo lingüístico? ¿Alguna vez ha querido marcar documentos con un idioma poco común o un dominio especializado? Dividir texto en marcas no es una tarea ardua; es la puerta de entrada para convertir el lenguaje en inteligencia procesable. Esta historia le enseñará todo lo que necesita saber sobre tokenización, no solo para BERT sino para cualquier LL.M.
En mi último artículo, discutimos BERT, exploramos sus fundamentos teóricos y mecanismos de capacitación, y discutimos cómo perfeccionarlo y crear un sistema de respuesta a preguntas. Ahora, a medida que exploramos más a fondo las complejidades de este modelo innovador, es hora de centrarnos en uno de los héroes anónimos: la tokenización.
Lo entiendo; la tokenización parece el último y aburrido obstáculo entre usted y el apasionante proceso de entrenamiento de modelos. Créame, solía pensar que sí. Pero estoy aquí para decirles que la tokenización no es sólo un “mal necesario”: es una forma de arte en sí misma.
En esta historia, examinaremos cada parte del proceso de tokenización. Algunos pasos son triviales (como la normalización y el preprocesamiento), mientras que otros (como la parte de modelado) hacen que cada tokenizador sea único.
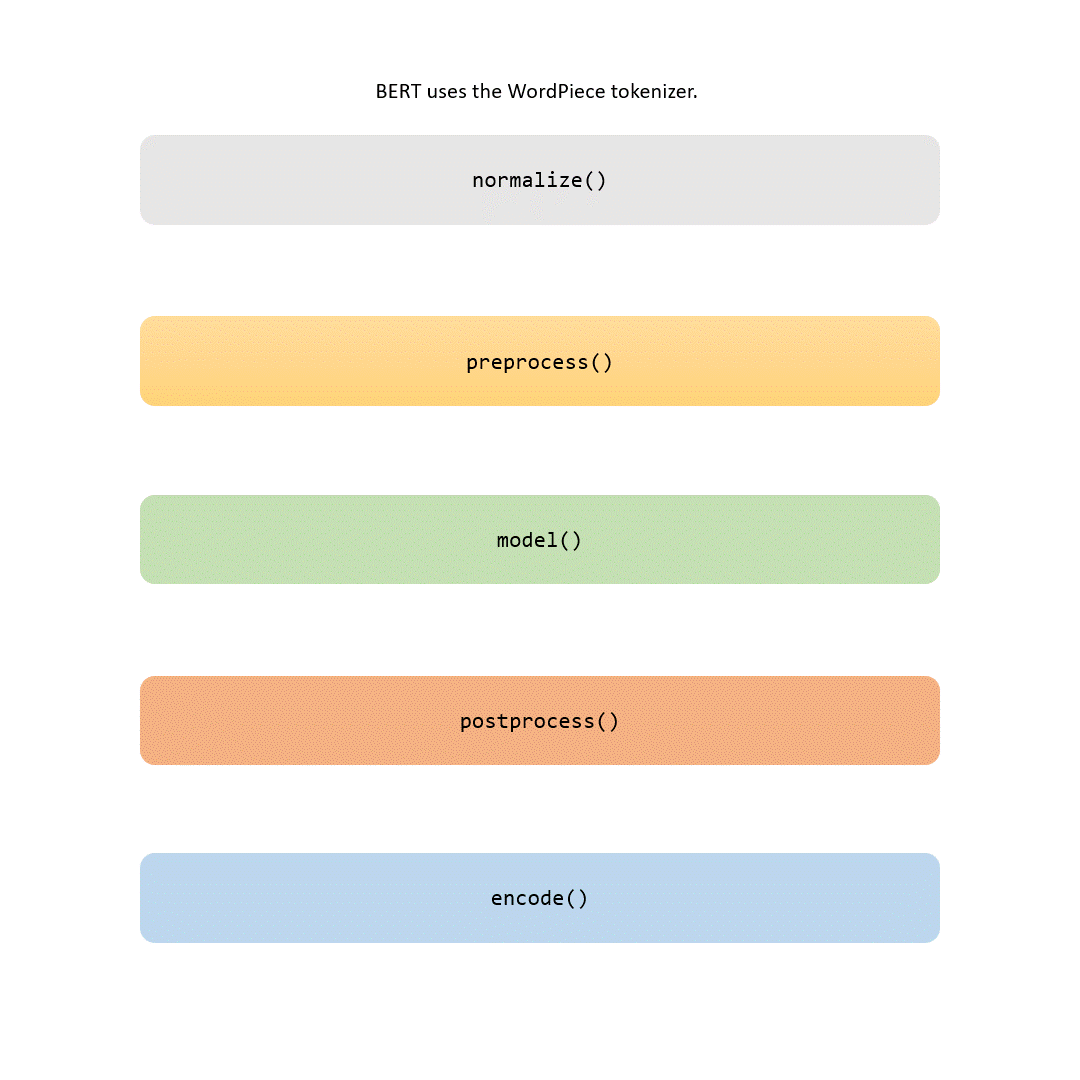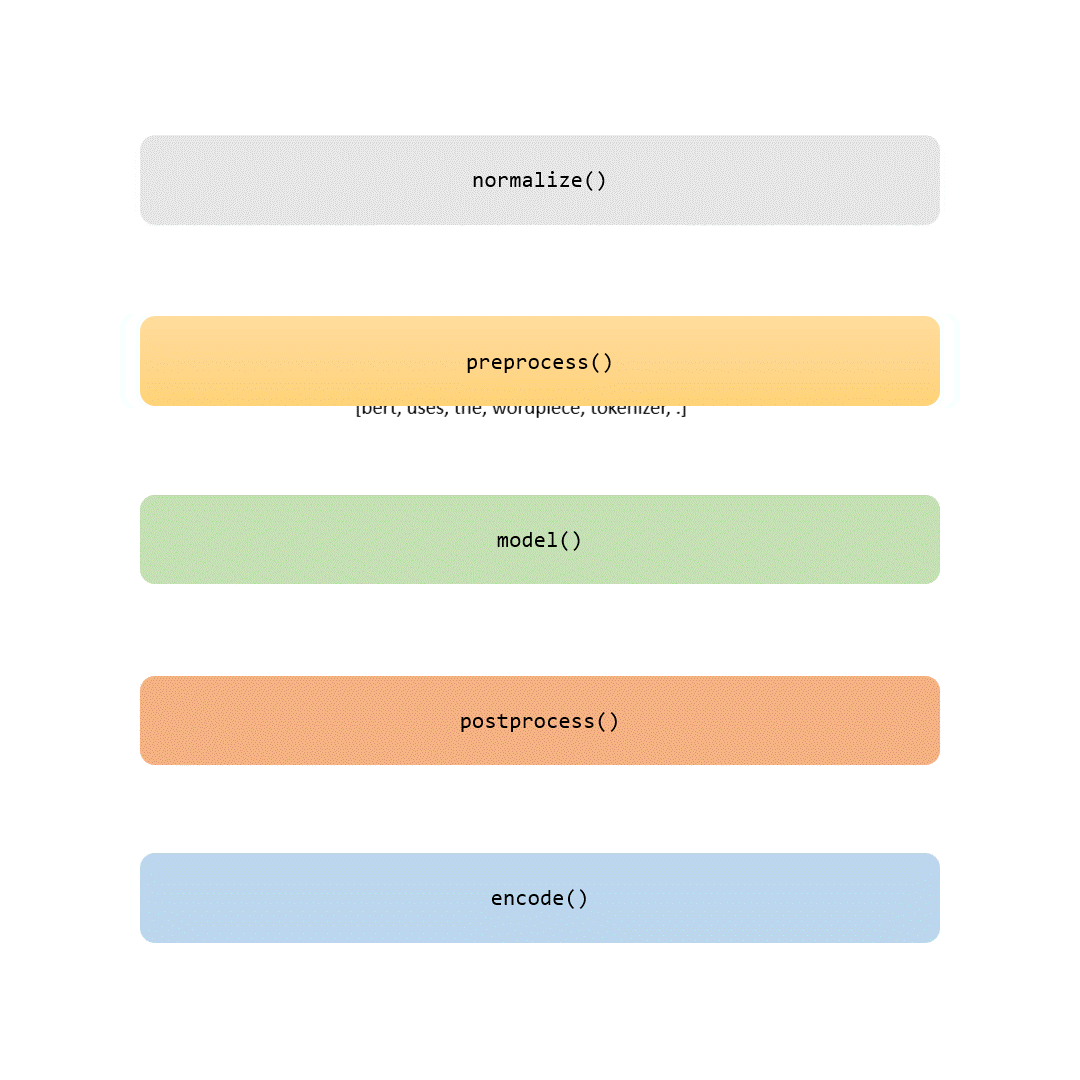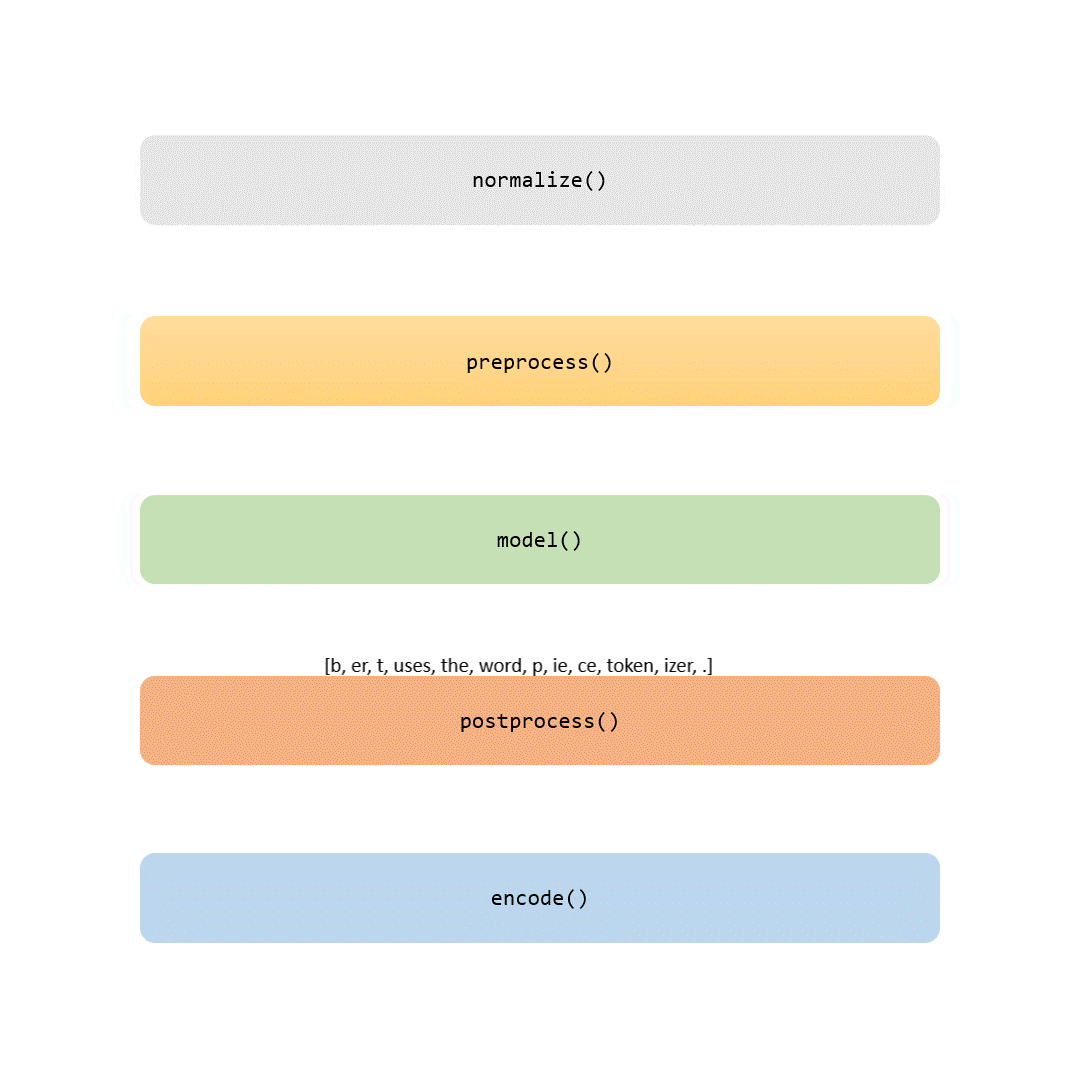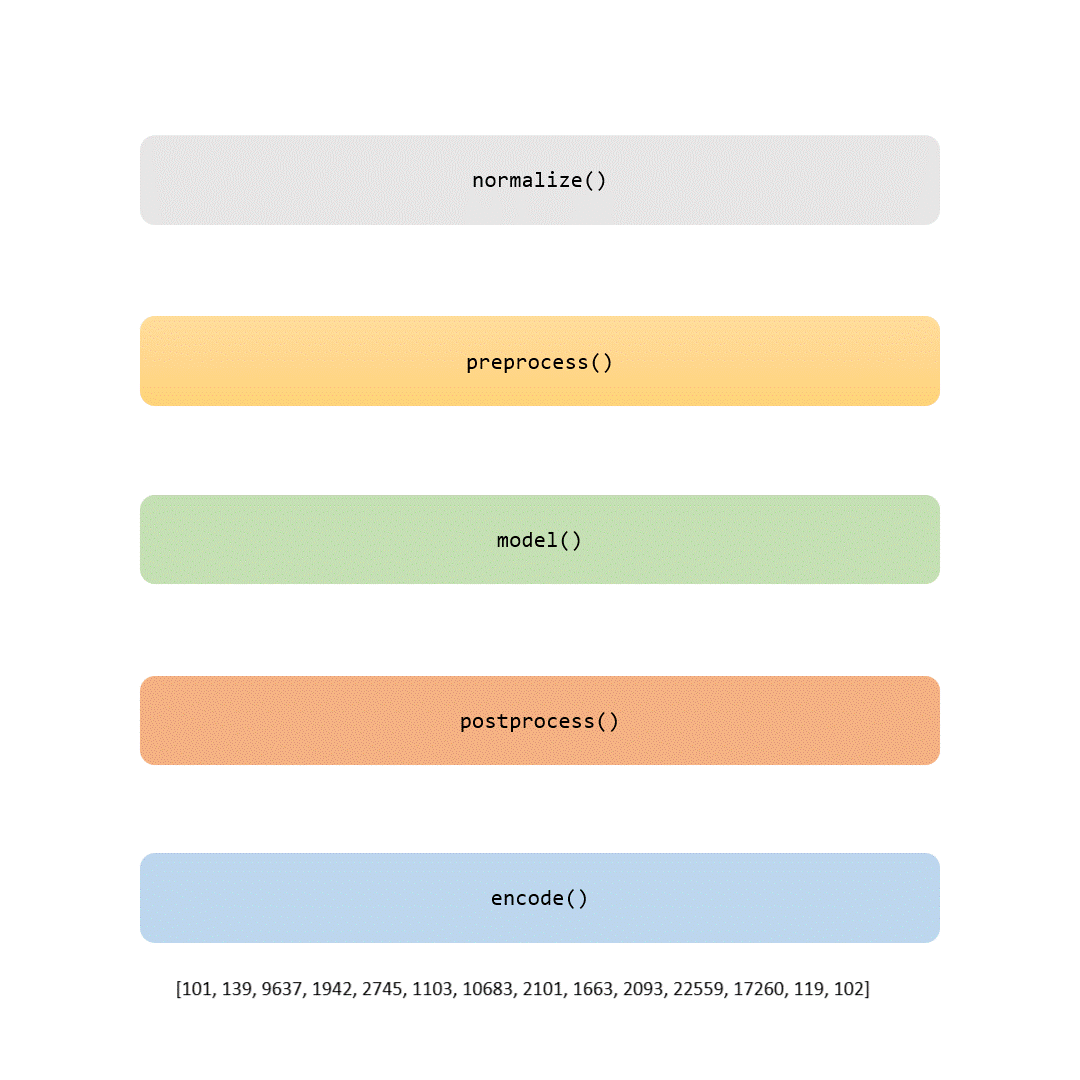
Cuando termine de leer este artículo, no solo conocerá los detalles del tokenizador BERT, sino que también podrá entrenarlo con sus propios datos. Si se siente aventurero, incluso puede utilizar herramientas para personalizar este paso crucial al entrenar su propio modelo BERT desde cero.
Dividir texto en marcas no es una tarea ardua; es la puerta de entrada para convertir el lenguaje en inteligencia procesable.
Entonces, ¿por qué es tan importante la tokenización? Esencialmente, la tokenización es un traductor; toma el lenguaje humano y lo traduce a un lenguaje que las máquinas pueden entender: los números. Pero hay un problema: durante este proceso de traducción, el tokenizador debe mantener el equilibrio crítico entre encontrar significado y calcular.