prefacio
Después de aprender la estructura del registro, debemos aprender la estructura de la página de datos. Anteriormente mencionamos brevemente el concepto de página, que es la unidad básica del espacio de almacenamiento de administración de Innodb. El tamaño de página predeterminado es de 16 KB. InnoDB ha diseñado muchos tipos para Diferentes tipos de páginas, como páginas que almacenan información de encabezado de tablespace, páginas que almacenan información de Insert Buffer, páginas que almacenan información de INODE, páginas que almacenan información de registro de deshacer, etc. Y en lo que nos enfocamos son esas páginas que almacenan los registros en nuestra tabla. Oficialmente, las páginas que almacenan registros se llaman páginas de índice (ÍNDICE). Como aún no hemos entendido qué es el índice, y las páginas en estas tablas Registros son lo que llamamos datos en nuestra boca diaria, por lo que todavía llamamos a esta página para almacenar registros una página de datos.
Tabla de contenido
- 1. La vista previa de la estructura de la página de datos.
- 2. Almacenamiento de registros de usuarios reales en la página de datos (Espacio Libre)
- 3. La estructura de "registro" de la página de datos derivada de la información del encabezado del registro
- Cuatro, directorio de páginas (directorio de páginas)
- Cinco, Encabezado de página (encabezado de página)
- Seis, Encabezado de archivo (encabezado de archivo)
- 7. Tráiler de archivo (al final del archivo)
- Resumir
1. La vista previa de la estructura de la página de datos.
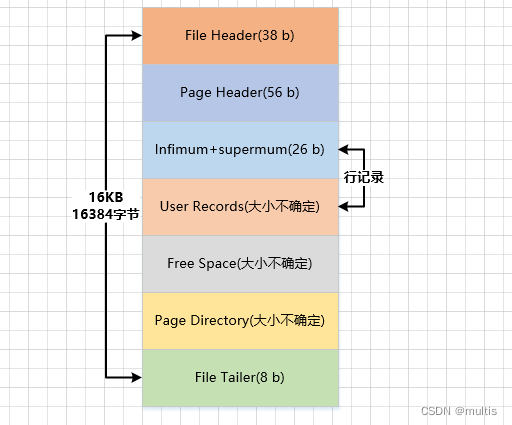
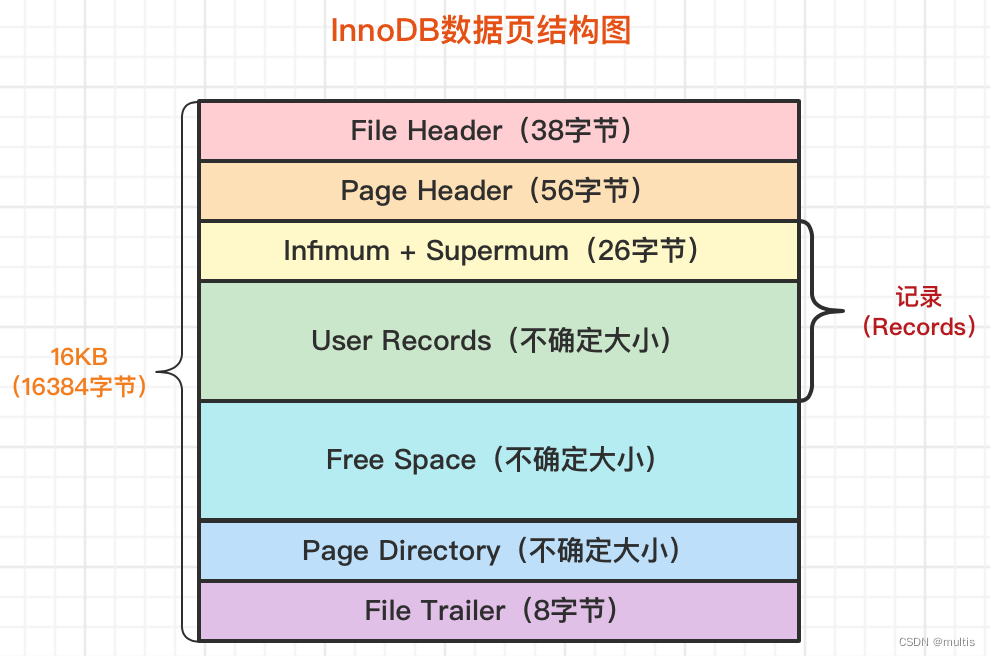
En la figura se puede ver que el espacio de almacenamiento de una página de datos de InnoDB se divide aproximadamente en siete partes, algunas partes ocupan una cierta cantidad de bytes y otras partes ocupan una cantidad incierta de bytes. Echemos un vistazo rápido a lo que almacenan estas 7 secciones:
| nombre | nombre chino | Tamaño (unidad: B) | describir |
|---|---|---|---|
| Encabezado de archivo | encabezado del archivo | 38 | Algunos datos generales de la página |
| Encabezado de página | encabezado de página | 56 | Alguna información específica de la página de datos |
| El más bajo + el más alto | Registro mínimo y registro máximo | 26 | dos registros de línea ficticia |
| Registros de usuario | Registro real del usuario | incierto | El contenido de registro de fila almacenado real |
| Espacio libre | espacio libre | incierto | espacio no utilizado en la página |
| Directorio de páginas | directorio de paginas | incierto | La posición relativa de ciertos registros en la página. |
| Tráiler de archivo | fin del documento | 8 | Si la página de verificación está completa |
2. Almacenamiento de registros de usuarios reales en la página de datos (Espacio Libre)
Entre los siete componentes de la página, los registros que almacenamos nosotros mismos se almacenarán en la sección Registros de usuario de acuerdo con el formato de fila que especificamos. Pero cuando la página se generó por primera vez, no había una sección de Registros de usuario. Cada vez que insertamos un registro, solicitaríamos un espacio del tamaño de un registro de la sección Espacio libre, es decir, el espacio de almacenamiento no utilizado, y lo dividiríamos en el Registro de usuario. Sección Registros. Cuando el espacio en la parte Espacio libre se reemplaza completamente por la parte Registros de usuario, significa que esta página está agotada. Si hay nuevos registros para insertar, debe solicitar una nueva página. Un diagrama de este proceso es el siguiente:
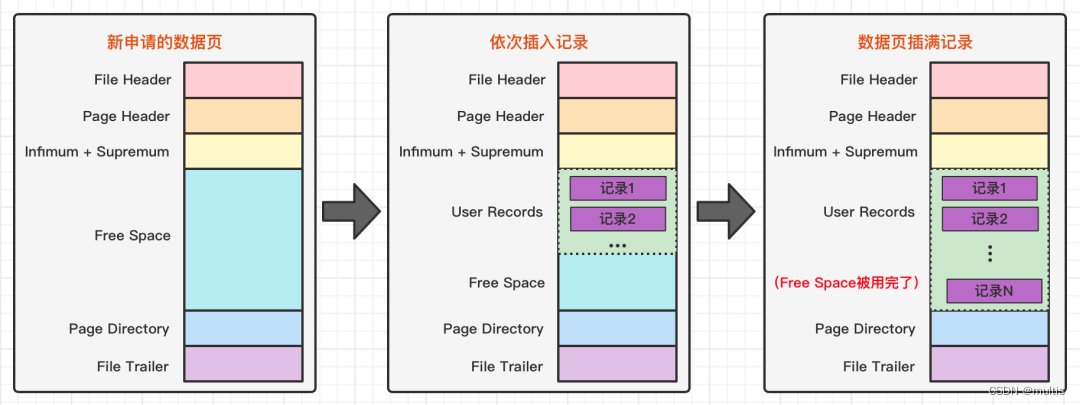
Para administrar mejor estos registros en Registros de usuarios, InnoDB ha realizado un gran esfuerzo, ¿dónde está el esfuerzo? ¿No es solo colocar los registros en la sección Registros de usuario uno por uno de acuerdo con el formato de fila especificado? De hecho, esto tiene que comenzar desde la información del encabezado del registro en el formato de línea de registro.
3. La estructura de "registro" de la página de datos derivada de la información del encabezado del registro
Primero creemos una tabla
mysql> create table demo5 (c1 int, c2 int, c3 varchar(10000),primary key (c1)) charset=ascii row_format=compact;
Query OK, 0 rows affected (0.04 sec)
Esta tabla recién creada tiene tres columnas, las columnas c1 y c2 se usan para almacenar números enteros, c3 almacena cadenas, pero especificamos c1 como la clave principal, por lo que en el formato de fila específico, Innodb no necesita crear una columna oculta de fila_id para nosotros arriba. Entonces, el diagrama esquemático del formato de fila en la tabla es el siguiente:
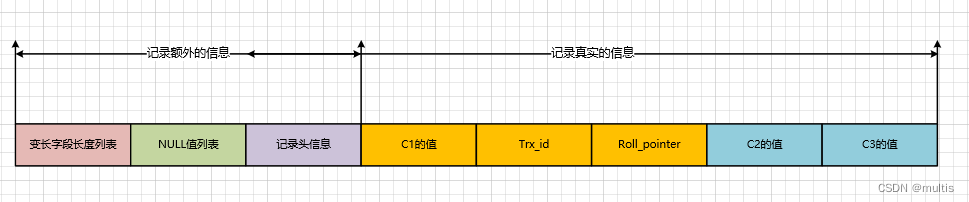
Eliminamos deliberadamente los primeros cinco bytes del registro
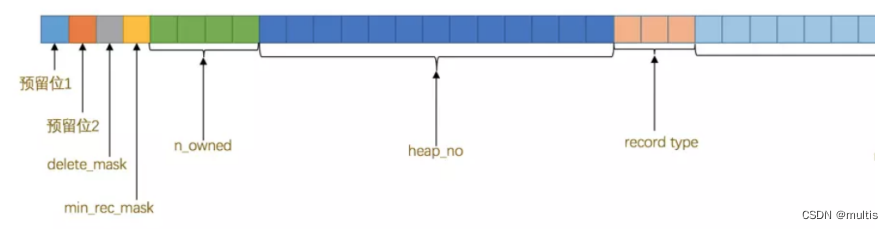
y pegamos el significado de cada atributo en la información del encabezado del registro (actualmente usando el formato de línea compacta):
| nombre | tamaño (unidad: bit) | describir |
|---|---|---|
| bit reservado 1 | 1 | no utilizado |
| reservado 2 | 1 | no utilizado |
| eliminar_mascarilla | 1 | Marcar si se elimina el registro |
| min_rec_mask | 1 | Esta marca se agregará al registro más pequeño en cada nodo que no sea hoja del árbol B+ |
| n_propiedad | 4 | Indica el número de registros que posee el registro actual |
| heap_no | 13 | Indica la información de posición del registro actual en el montón de registros |
| tipo_de_registro | 3 | Indica el tipo de registro actual, 0 indica un registro ordinario, 1 indica un registro de nodo sin hoja de árbol B+, 2 indica el registro más pequeño y 3 indica el registro más grande |
| próximo_registro | dieciséis | Indica la posición relativa del siguiente registro |
A continuación insertamos algunos datos
mysql> insert into demo5 values(1,100,'aaaa'),(2,200,'bbbb'),(3,300,'cccc'),(4,400,'dddd');
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
Nos fijamos en la cabecera de información de estas 4 líneas de registros

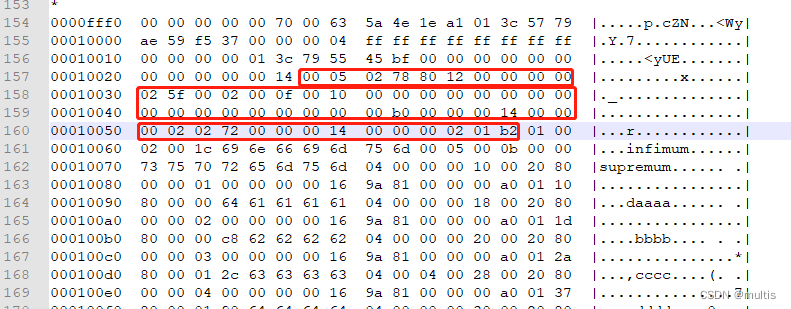
Línea 1: 00 00 10 00 20
Línea 2: 00 00 18 00 20
Línea 3: 00 00 20 00 20
Línea 4:00 00 28 ff 91
Convierta a binario de la siguiente manera:
Línea 1: 00000000 00000000 00010000 00000000 00100000
Línea 2: 00000000 00000000 00011000 00000000 00100000
Línea 3: 00000000 00000000 00100000 00000000 00100000
Línea 4:00000000 00000000 00101000 11111111 10010001
La cuarta línea
11111111 10010001es un número negativo, complemento +1, que es -111
Para facilitar que todos analicen cómo se representan estos registros en la sección Registros de usuario de la página, he expresado la información del encabezado y los datos reales de la columna en los registros en decimal, por lo que el diagrama esquemático de estos registros es
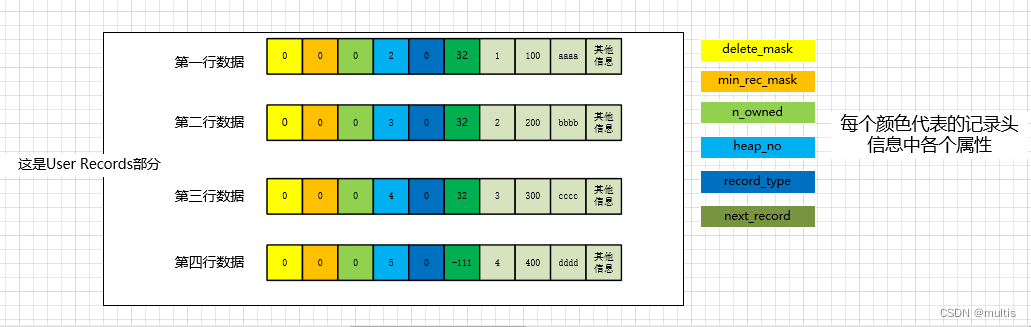
Cabe señalar que no hay lagunas en el almacenamiento de cada registro en Registros de usuario. Esto es para que todos puedan dibujar cada registro por separado. Comparemos esta imagen para ver los atributos en la información del encabezado del registro:
3.1 eliminar_máscara
Este atributo marca si se elimina el registro actual, ocupando un bit binario, 0 significa que no se elimina, 1 se elimina
Los registros eliminados no se eliminan inmediatamente del disco, porque la reorganización de otros registros en el disco después de eliminarlos requiere un consumo de rendimiento, por lo que es solo una marca de eliminación, y todos los registros eliminados formarán una llamada lista enlazada basura, el espacio ocupado por los registros en esta lista enlazada se denomina el llamado espacio reutilizable. Si se insertan nuevos registros en la tabla más tarde, el espacio de almacenamiento ocupado por estos registros eliminados puede sobrescribirse. Establecer el bit delete_mask en 1 y agregar el registro eliminado a la lista de basura son dos etapas
3.2 min_rec_mask
Esta marca se agregará al registro más pequeño en cada nodo que no sea hoja del árbol B+. Un valor de 1 significa que el registro es el registro más pequeño en los nodos que no son hojas del árbol B+; un valor de 0 significa que el registro no es el registro más pequeño en los nodos que no son hojas del árbol B+
3.3 n_propiedad
Indica el número de registros que posee el registro actual, lo presentaremos en detalle más adelante
3.4 montón_no
Esta propiedad indica la posición del registro actual en esta página. MySQL agrega automáticamente dos registros a cada página, ya que estos dos registros no los insertamos nosotros mismos, a veces se les llama pseudo registros o registros virtuales. Uno de estos dos pseudo-registros representa el registro más pequeño y el otro representa el registro más grande.
Los registros también se pueden comparar en tamaño. Para un registro completo, comparar el tamaño del registro es comparar el tamaño de la clave principal. Pero no importa cuántos registros insertemos en la página, InnoDB estipula que los dos pseudo-registros que definen son el registro mínimo y el registro máximo. La estructura de estos dos registros es muy simple, ambos compuestos por información de encabezado de registro de 5 bytes y una parte fija de 8 bytes de tamaño.
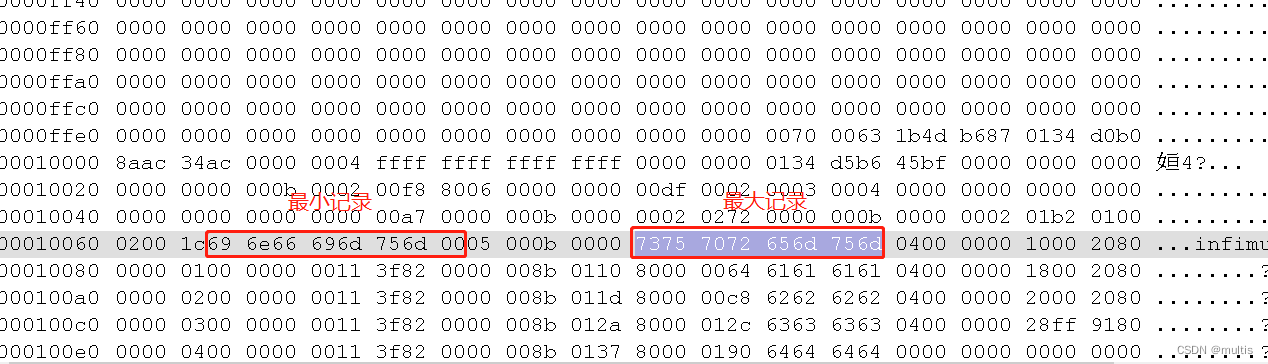
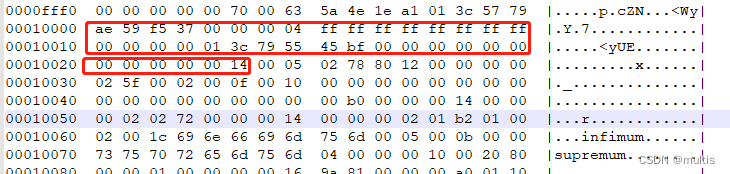
Veamos ahora el encabezado del archivo, que son los siguientes:
Registros máximos: 05 00 0b 00 00
Registros mínimos:01 00 02 00 1c
Convierta a binario de la siguiente manera:
Registros máximos: 00000101 00000000 00011011 00000000 00000000
Registros mínimos:00000001 00000000 00000010 00000000 00011100
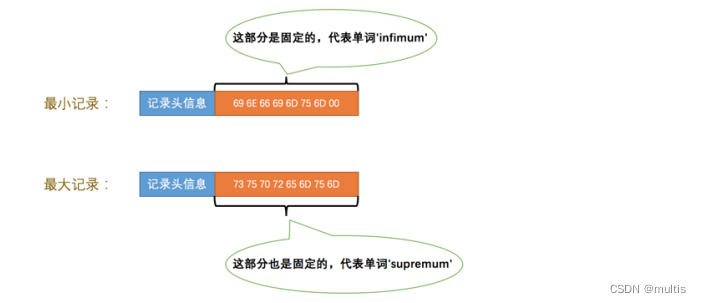
Dado que estos dos registros no están definidos por nosotros, no se almacenan en la sección Registros de usuario de la página. Se colocan por separado en la sección Infimum + Supremum mencionada anteriormente.
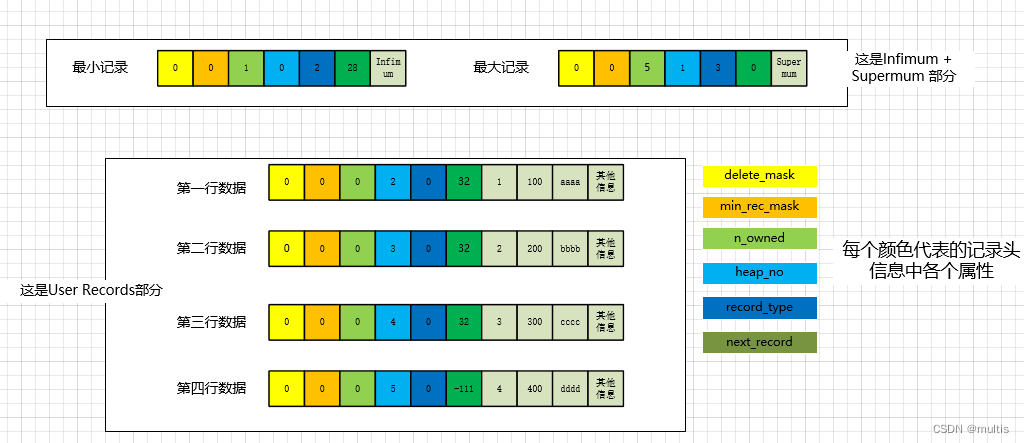
En la figura no se muestran otros datos pero no quiere decir que no existan, sino que se simplifican para comodidad de todos. Los valores heap_no del registro más pequeño y del registro más grande son 0 y 1 respectivamente, es decir, sus posiciones están al frente
3.5 tipo_registro
Este atributo indica el tipo de registro actual. Hay 4 tipos de registros en total. 0 indica registros ordinarios, 1 indica registros de nodo de árbol B+ que no son hojas, 2 indica el registro más pequeño y 3 indica el registro más grande. También podemos ver en la figura que los registros que insertamos nosotros mismos son registros ordinarios, y sus valores record_type son todos 0, mientras que los valores record_type del registro mínimo y el registro máximo son 2 y 3 respectivamente. caso de que record_type sea 1, se enfatizará cuando se hable de indexación.
3.7 siguiente_registro
Esta información es muy importante y representa el desplazamiento de la dirección de los datos reales del registro actual a los datos reales del siguiente registro. Por ejemplo, el valor next_record del primer registro es 32, lo que significa que 32 bytes hacia atrás desde la dirección de los datos reales del primer registro son los datos reales del siguiente registro. Si está familiarizado con las estructuras de datos, comprenderá de inmediato que en realidad se trata de una lista enlazada y puede encontrar su siguiente registro a través de un registro. Pero una cosa a la que debe prestar atención es que el siguiente registro no se refiere al siguiente registro en el orden de nuestra inserción, sino al siguiente registro en el orden del valor de la clave principal de pequeño a grande. Y se estipula que el siguiente registro del registro Infimum (es decir, el registro más pequeño) es el registro de usuario con el valor de clave principal más pequeño en esta página, y el siguiente registro del registro de usuario con el valor de clave principal más grande en este página es el registro supremo (es decir, el registro más grande), para expresar más vívidamente el papel que desempeña este next_record, usamos flechas para reemplazar el desplazamiento de dirección en next_record:
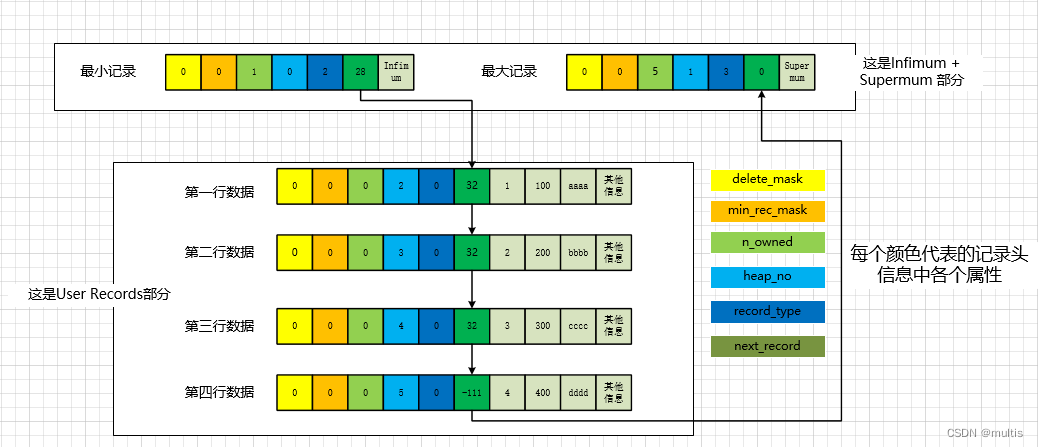
Como se puede ver en la figura, nuestros registros forman una lista enlazada individualmente en orden ascendente de la clave principal. El valor next_record del registro más grande es 0, lo que significa que no hay ningún registro siguiente para el registro más grande y es el último nodo en la lista enlazada individualmente. Si se elimina un registro de él, la lista enlazada también cambiará en consecuencia. Por ejemplo, eliminamos el segundo registro:
mysql> delete from demo5 where c1 =2;
Query OK, 1 row affected (0.02 sec)
Después de eliminar el segundo registro, echemos un vistazo al registro de cuatro líneas del archivo demo5.ibd y la información de encabezado de registro máximo y mínimo
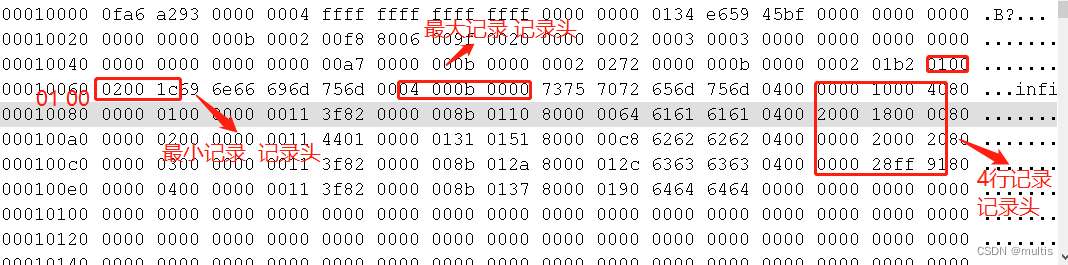
Línea 1 : 00 00 10 00 40
Línea 2 : 20 00 18 00 00
Línea 3: 00 00 20 00 20
Línea 4:00 00 28 ff 91
Registros máximos : 04 00 0b 00 00
Registros mínimos:01 00 02 00 1c
En comparación con los anteriores, encontramos que la primera línea, la segunda línea y el registro máximo han cambiado, y la conversión del sistema base no se demostrará aquí.
0x40=64
0x20=0010 0000
0x04=0000 0100
El esquema es:
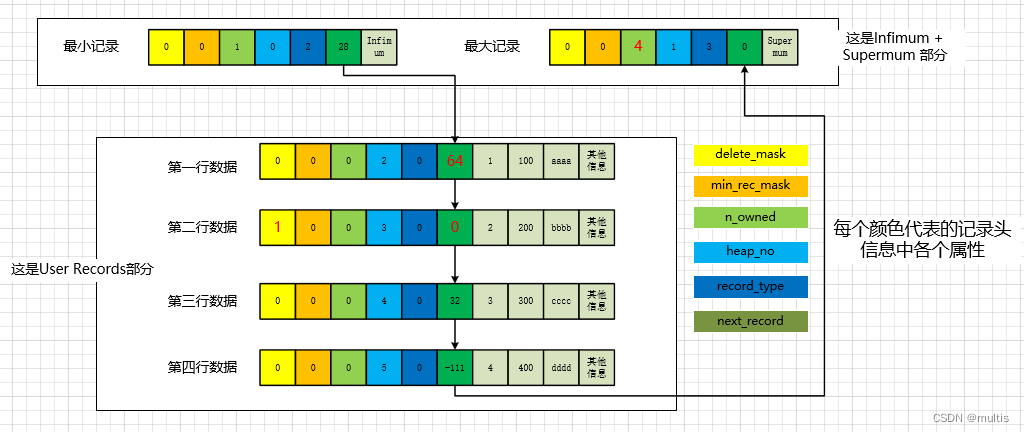
Como puede verse en la figura, estos cambios ocurrieron principalmente antes y después de eliminar el segundo registro:
- El segundo registro no se elimina del espacio de almacenamiento, pero el valor delete_mask de este registro se establece en 1.
- El valor next_record del segundo registro se convierte en 0, lo que significa que no hay ningún registro siguiente para este registro.
- El valor next_record del primer registro se convierte en 64, apuntando al tercer registro.
- El valor n_owned del registro más grande ha cambiado de 5 a 4. Explicaremos este cambio en detalle más adelante.
Por lo tanto, no importa cómo agreguemos, eliminemos o modifiquemos registros en la página, InnoDB siempre mantendrá una lista de registros con un solo enlace, y cada nodo en la lista enlazada está conectado en orden de valor de clave principal de menor a mayor.
¿Crees que el puntero next_record es un poco extraño? ¿Por qué debería apuntar a la posición entre la información del encabezado del registro y los datos reales? ¿Por qué no simplemente señalar el comienzo de todo el registro, es decir, el comienzo de la información adicional registrada?
Debido a que esta posición es la correcta, la lectura a la izquierda es la información del encabezado del registro y la lectura a la derecha son los datos reales. Estructura de registro InnoDB de MySQL También dijimos que la información en la lista de longitud de campo de longitud variable y la lista de valores NULL se almacena en orden inverso, de modo que la distancia entre los campos posicionados al frente en el registro y su información de longitud de campo correspondiente en el la memoria está más cerca, lo que puede mejorar la proporción de aciertos de caché.
Veamos otra cosa interesante, porque eliminamos el registro con el valor de clave principal de 2, pero el espacio de almacenamiento no se recuperó. Si volvemos a insertar este registro en la tabla, ¿qué sucederá?
mysql> insert into demo5 VALUES(2, 200, 'bbbb');
Query OK, 1 row affected (0.01 sec)
Veamos directamente el archivo de datos.

¿Es exactamente igual que el principio, como se muestra en la imagen?
InnoDB no solicita nuevo espacio de almacenamiento para la inserción de nuevos registros, sino que reutiliza directamente el espacio de almacenamiento de los registros borrados originales.
Sugerencias
1. Cuando hay varios registros eliminados en la página de datos, el atributo next_record de estos registros formará una lista de basura con estos registros eliminados, de modo que esta parte del espacio de almacenamiento se pueda reutilizar más adelante. Si se elimina una línea del registro anterior y luego se vuelve a insertar intacta, se reutilizará el espacio de almacenamiento original.
2. Hay otra situación que no se reutilizará: después de eliminar el registro original, cuando el espacio de almacenamiento ocupado por los datos reales del registro recién insertado sea mayor que el espacio de almacenamiento del registro original, el espacio original no se reutilizará y se agregarán a la lista de basura. Los registros recién insertados solicitarán un nuevo espacio de Free Space y se combinarán con los registros existentes para formar una nueva lista vinculada.
Cuatro, directorio de páginas (directorio de páginas)
Ahora que entendemos que los registros en la página están concatenados en una lista enlazada de acuerdo con el valor de la clave principal de menor a mayor, ¿qué debemos hacer si queremos encontrar un registro determinado en la página de acuerdo con el valor de la clave principal? Por ejemplo, una consulta como esta:
select * from where c1=3;
La forma más estúpida: comience desde el registro Infimum (el registro más pequeño), y mire hacia atrás a lo largo de la lista vinculada, y siempre lo encontrará. También puede ser oportunista a la hora de buscarlo, porque los valores de cada registro de la lista enlazada se ordenan de forma ascendente, por lo que cuando el valor de la clave principal del registro representado por un nodo de la lista enlazada es mayor que el valor de la clave principal que desea encontrar, la búsqueda se puede detener, porque los valores de la clave principal de los nodos detrás del nodo se incrementan secuencialmente.
¿Pero puede InnoDB usar un método tan estúpido? Por supuesto, es necesario diseñar un método de búsqueda más rápido, así que casi encontré inspiración en el catálogo del libro.
Cuando normalmente queremos encontrar cierto contenido de un libro, generalmente miramos primero la tabla de contenido, buscamos el número de página del libro correspondiente al contenido que necesitamos encontrar y luego vamos al número de página correspondiente para ver el contenido. InnoDB también creó un directorio similar para nuestros registros, y su proceso de producción es el siguiente:
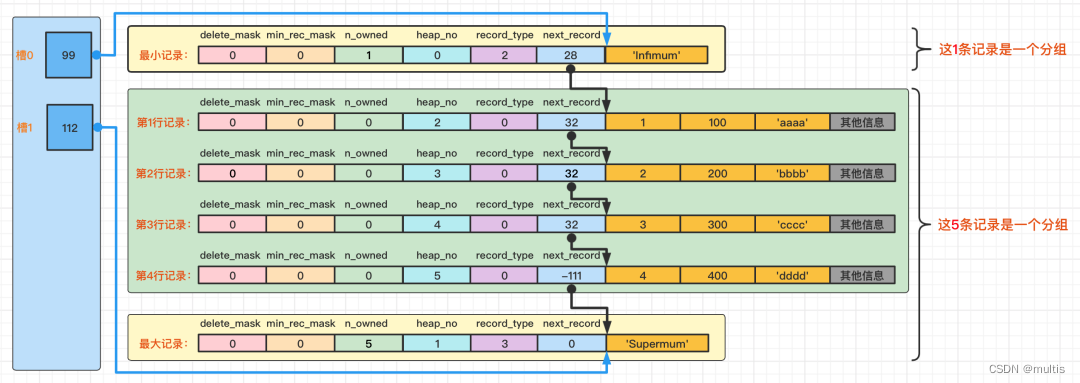
- Divida todos los registros normales (incluidos los registros más grandes y más pequeños, sin incluir los registros marcados como eliminados) en varios grupos.
- El atributo n_propiedad en la información de encabezado del último registro de cada grupo (es decir, el registro más grande del grupo) indica cuántos registros posee el registro, es decir, cuántos registros hay en el grupo.
- El desplazamiento de dirección del último registro de cada grupo se extrae por separado y se almacena en secuencia.Este
靠近页的尾部的地方lugar es el llamado Directorio de páginas, es decir, el directorio de páginas. Estos desplazamientos de direcciones en el directorio de páginas se denominan ranuras (nombre en inglés: Slot), por lo que este directorio de páginas se compone de ranuras.
Cabe señalar que el directorio de páginas se almacena en orden inverso y cada ranura ocupa 2 bytes
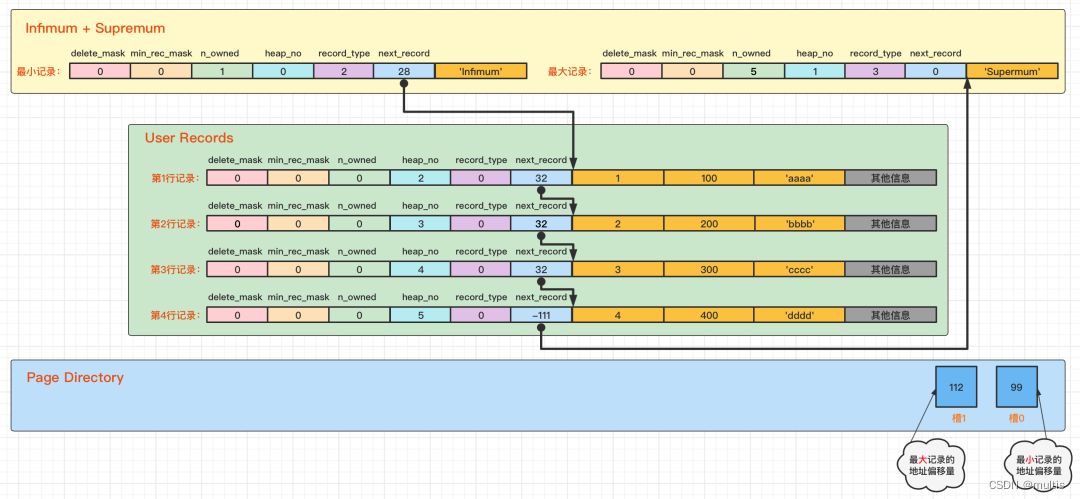
A partir de esta figura, debemos prestar atención a los siguientes puntos:
-
Ahora hay dos ranuras en la sección del directorio de páginas, lo que significa que nuestros registros están divididos en dos grupos. El valor en la ranura 1 es 112, que representa el desplazamiento de dirección del registro más grande (es decir, contando desde el byte 0 de la página , contando 112 bytes); el valor en la ranura 0 es 99, que representa el desplazamiento de dirección del registro mínimo.
-
Tenga en cuenta el atributo n_owned en los encabezados de registro mínimo y máximo
-
El valor de n_propiedad del registro más pequeño es 1, lo que significa que solo hay un registro en el grupo que termina con el registro más pequeño, que es el registro más pequeño en sí.
-
El valor n_owned del registro más grande es 5, lo que significa que solo hay 5 registros en el grupo que termina con el registro más grande, incluido el registro más grande y los 4 registros que insertamos nosotros mismos.
-
Las compensaciones de dirección como 99 y 112 no son intuitivas. Reemplazamos los números con flechas, lo que nos resulta más fácil de entender, por lo que el diagrama esquemático modificado es así:

Independientemente de la disposición de los registros en el dispositivo de almacenamiento por el momento, simplemente mire la relación entre estos registros y el directorio de páginas de forma lógica:
InnoDB tiene regulaciones sobre el número de registros en cada grupo: el grupo con el registro más pequeño solo puede tener 1 registro, el grupo con el registro más grande solo puede tener entre los registros, y el grupo restante El rango del número de registros solo puede 1~8tener estar 4~8entre. Por lo que la agrupación se realiza de acuerdo a los siguientes pasos:
-
Inicialmente, solo hay dos registros en una página de datos, el registro mínimo y el registro máximo, y pertenecen a dos grupos.
-
Después de insertar un registro, encontrará la ranura cuyo valor de clave principal es mayor que el valor de clave principal de este registro y la diferencia es la más pequeña del directorio de la página, y luego agregará 1 al valor n_propiedad del registro correspondiente a la ranura , lo que indica que este grupo ha agregado otro registro One hasta que el número de registros en el grupo sea igual a 8.
-
Cuando el número de registros en un grupo es igual a 8 y luego se inserta un registro, los registros del grupo se dividirán en dos grupos, con 4 registros en un grupo y 5 registros en el otro. Este proceso agregará una nueva ranura en el directorio de la página para registrar el desplazamiento del registro más grande en el grupo recién agregado.
Dado que ahora hay muy pocos registros en la tabla demo5, es imposible demostrar el proceso de acelerar la búsqueda después de agregar el directorio de la página, así que demo5agregue algunos registros más a la tabla.
insert into demo5 values(5, 500, 'eeee');
insert into demo5 values(6, 600, 'ffff');
insert into demo5 values(7, 700, 'gggg');
insert into demo5 values(8, 800, 'hhhh');
insert into demo5 values(9, 900, 'iiii');
insert into demo5 values(10, 1000, 'jjjj');
insert into demo5 values(11, 1100, 'kkkk');
insert into demo5 values(12, 1200, 'llll');
insert into demo5 values(13, 1300, 'mmmm');
insert into demo5 values(14, 1400, 'nnnn');
insert into demo5 values(15, 1500, 'oooo');
insert into demo5 values(16, 1600, 'pppp');
Ahora hay un total de 18 registros en la página (incluidos los registros mínimo y máximo), y estos registros se dividen en 5 grupos, como se muestra en la figura:

Debido a que se necesita demasiado espacio para dibujar toda la información de 16 registros en una sola imagen, es deslumbrante, por lo que solo se conservan los atributos n_owned y next_record en la información del encabezado del registro de usuario, y se omiten las flechas entre cada registro. no significa que no! Ahora vea cómo encontrar registros de este directorio de páginas. Debido a que los valores de clave principal de los registros representados por cada ranura se ordenan de menor a mayor, podemos usar la llamada dicotomía para la búsqueda rápida. Los números de las 5 ranuras son: 0, 1, 2, 3, 4, por lo que la ranura más baja en el caso inicial es baja = 0, y la ranura más alta es alta = 4. Por ejemplo, si queremos encontrar registros con un valor de clave principal de 6, el proceso es el siguiente:
- Calcule la posición de la ranura del medio: (0+4)/2=2, así que mire la ranura 2, el valor de la clave principal del registro correspondiente es 8, y debido a que 8 > 6, configure high=2, y low permanece sin cambios .
- Vuelva a calcular la posición de la ranura del medio: (0+2)/2=1, así que verifique que el valor de la clave principal correspondiente a la ranura 1 sea 4, y debido a que 4 < 6, configure low=1, y high permanece sin cambios.
- Debido a que el valor de alto - bajo es 1, se determina que el registro con un valor de clave principal de 6 está en el grupo correspondiente al espacio 2. En este momento, necesitamos encontrar el registro con el valor de clave principal más pequeño en el espacio 2 y, a continuación, recorra las ranuras a lo largo de los registros de la lista vinculada unidireccional 2. Pero como dijimos antes, el registro correspondiente a cada ranura es el registro con el valor de clave principal más grande del grupo, aquí, el registro correspondiente a la ranura 2 es el registro con el valor de clave principal de 8. Cómo localizar el registro más pequeño ¿en un grupo? No olvide que los espacios están uno al lado del otro. Podemos obtener fácilmente el registro correspondiente al espacio 1 (el valor de la clave principal es 4), y el siguiente registro de este registro es el registro con el valor de clave principal más pequeño en el espacio. 2. El registro tiene un valor de clave principal de 5. Entonces, podemos comenzar desde este registro con un valor de clave principal de 5 y recorrer los registros en la ranura 2 hasta que encontremos el registro con un valor de clave principal de 6. Dado que la cantidad de registros contenidos en un grupo solo puede ser de 1 a 8, el costo de recorrer los registros en un grupo es muy pequeño.
Entonces, el proceso de encontrar el registro del valor de clave principal especificado en una página de datos se divide en dos pasos:
-
Determine el espacio donde se encuentra el registro por dicotomía y busque el registro con el valor de clave principal más pequeño en el grupo donde se encuentra el espacio.
-
Recorra cada registro en el grupo donde se encuentra la ranura a través del atributo next_record del registro
Usamos el comando hexdump para analizar el archivo de datos:
root@mysql2 testdb]# hexdump -C demo5.ibd > demo5.txt

Cinco, Encabezado de página (encabezado de página)
Para obtener la información de estado de los registros almacenados en una página de datos, InnoDB, como cuántos registros se han almacenado en esta página, cuál es la dirección del primer registro, cuántos espacios se almacenan en el directorio de la página, etc. ., se almacenan especialmente en la página Se define una parte llamada Encabezado de página, que es la segunda parte de la estructura de la página.Esta parte ocupa 56 bytes fijos y se dedica a almacenar información de estado diversa.
Consulte la siguiente tabla para conocer el significado de cada byte:
| nombre | Tamaño (unidad: B) | describir |
|---|---|---|
| ranuras_page_n_dir_ | 2 | Número de ranuras para el directorio de páginas |
| página_heap_top | 2 | La dirección mínima del espacio no utilizado, es decir, espacio libre después de esta dirección |
| página_n_montón | 2 | Número de registros en esta página (incluidos los registros mínimo y máximo y los registros marcados para su eliminación) |
| pagina_gratis | 2 | La dirección del primer registro que se marcó como eliminado (cada registro eliminado también formará una lista enlazada individualmente a través de next_record, y los registros en esta lista enlazada individualmente se pueden reutilizar) |
| pagina_basura | 2 | El número de bytes ocupados por registros eliminados |
| página_última_inserción | 2 | La posición del último registro insertado |
| dirección_página | 2 | dirección de inserción del registro |
| página_n_dirección | 2 | El número de registros insertados consecutivamente en una dirección |
| página_n_recs | 2 | Número de registros en la página (excluyendo registros mínimos y máximos y registros marcados para eliminación) |
| página_max_trx_id | 8 | Modifique el id de transacción máximo de la página actual, que solo se define en el índice secundario |
| nivel_de_página | 2 | El nivel de la página actual en el árbol b+ |
| page_index_id | 8 | ID de índice, que indica a qué índice pertenece la página actual |
| page_btr_seg_leaf | 10 | La información del encabezado del segmento de hoja del árbol b+ solo se define en la página raíz del árbol b+ |
| page_btr_seg_top | 10 | La información de encabezado del segmento que no es hoja del árbol b+ solo se define en la página raíz del árbol b+ |
A través de la introducción del artículo anterior, todos deben tener claro el significado de page_n_dir_slots, page_last_insert y page_n_recs.
Si no está seguro, le sugiero que regrese y eche un buen vistazo. No se preocupe por el resto de la información de estado.
Primero veamos el significado de page_direction y page_n_direction:
5.1 página_dirección
Si el valor de la clave principal de un registro recién insertado es mayor que el valor de la clave principal del registro anterior, decimos que la dirección de inserción de este registro es hacia la derecha y viceversa. El estado utilizado para indicar la dirección de inserción del último registro es page_direction
0x02 Derecha
0x01 Izquierda
0x05 Sin ordenar
5.2 página_n_dirección
Suponiendo que la dirección de inserción de nuevos registros varias veces seguidas es la misma, InnoDB registrará la cantidad de registros insertados en la misma dirección, y este número está representado por el estado de page_n_direction. Por supuesto, si se cambia la dirección de inserción del último registro, el valor de este estado se borrará y volverá a contarse.
Miremos el archivo de datos de arriba y corresponde a 0x000f, que es 15.
En cuanto a los atributos que no mencionamos, no los mencioné porque no necesitamos saberlos ahora. No te preocupes, cuando hayamos terminado de aprender el contenido detrás, puedes mirar hacia atrás y todo es tan claro.
Consejo:
cuando se trata de algunas cosas que son claras cuando miramos hacia atrás después de haberlas aprendido, no puedo evitar pensar en el discurso de Jobs en la Universidad de Stanford: "No puedes conectar los puntos mirando hacia adelante; solo puedes conectar ellos mirando hacia atrás. Así que tienes que confiar en que los puntos se conectarán de alguna manera en tu futuro. Tienes que confiar en algo: tu instinto, destino, vida, karma, lo que sea. Este enfoque nunca me ha defraudado, y ha hecho que todo la diferencia en mi vida ". El párrafo anterior fue escrito por capricho, en el sentido de que insistes en hacer las cosas que te gustan. Cuando lo haces, es posible que no puedas descifrar qué impacto tendrán estas cosas en tu vida futura, pero cuando caminé de un lado a otro y miré hacia atrás, todo estaba tan claro, como si estuviera destinado a ser.
Seis, Encabezado de archivo (encabezado de archivo)
El encabezado de página es una variedad de información de estado registrada especialmente para las páginas de datos, como cuántos registros y cuántos espacios hay en la página. El Encabezado del archivo que describimos ahora es común a todos los tipos de páginas, es decir, diferentes tipos de páginas utilizarán el Encabezado del archivo como primer componente, que describe alguna información que es común a varias páginas, como este ¿Qué es el número de página, quién es su página anterior y quién es la página siguiente... Esta parte ocupa unos 38 bytes fijos y está compuesta por los siguientes contenidos:
Consulte la siguiente tabla para conocer el significado de cada byte:
| nombre | Tamaño (unidad: B) | describir |
|---|---|---|
| fil_page_space_or_chksum | 4 | Suma de verificación de página (valor de suma de verificación) |
| fil_page_offset | 4 | número de página |
| página_archivo_prev | 4 | número de página de la página anterior |
| fil_pagina_siguiente | 4 | Número de página de la página siguiente |
| fil_page_lsn | 8 | 页面被最后修改时对应的日志序列位置(英文名是:log sequence number) |
| fil_page_type | 2 | 该页的类型 |
| fil_page_file_flush_lsn | 8 | 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的lsn值 |
| fil_page_arch_log_no_or_space_id | 4 | 页属于哪个表空间 |
对照着这个表格,我们看几个目前比较重要的部分:
6.1 fil_page_space_or_chksum
这个代表当前页面的校验和(checksum)。啥是个校验和?就是对于一个很长很长的字节串来说,我们会通过某种算法来计算一个比较短的值来代表这个很长的字节串,这个比较短的值就称为校验和。这样在比较两个很长的字节串之前先比较这两个长字节串的校验和,如果校验和都不一样两个长字节串肯定是不同的,所以省去了直接比较两个比较长的字节串的时间损耗。
6.2 fil_page_offset
每一个页都有一个单独的页号,就跟你的身份证号码一样,InnoDB通过页号来可以唯一定位一个页。
6.3 fil_page_type
这个代表当前页的类型,我们前边说过,InnoDB为了不同的目的而把页分为不同的类型,我们上边介绍的其实都是存储记录的数据页,其实还有很多别的类型的页,具体如下表:
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
| fil_page_type_allocated | 0x0000 | 最新分配,还没使用 |
| fil_page_undo_log | 0x0002 | undo日志页 |
| fil_page_inode | 0x0003 | 段信息节点 |
| fil_page_ibuf_free_list | 0x0004 | insert buffer空闲列表 |
| fil_page_ibuf_bitmap | 0x0005 | insert buffer位图 |
| fil_page_type_sys | 0x0006 | 系统页 |
| fil_page_type_trx_sys | 0x0007 | 事务系统数据 |
| fil_page_type_fsp_hdr | 0x0008 | 表空间头部信息 |
| fil_page_type_xdes | 0x0009 | 扩展描述页 |
| fil_page_type_blob | 0x000a | 溢出页 |
| fil_page_index | 0x45bf | 索引页,也就是我们所说的数据页 |
6.4 fil_page_prev和fil_page_next
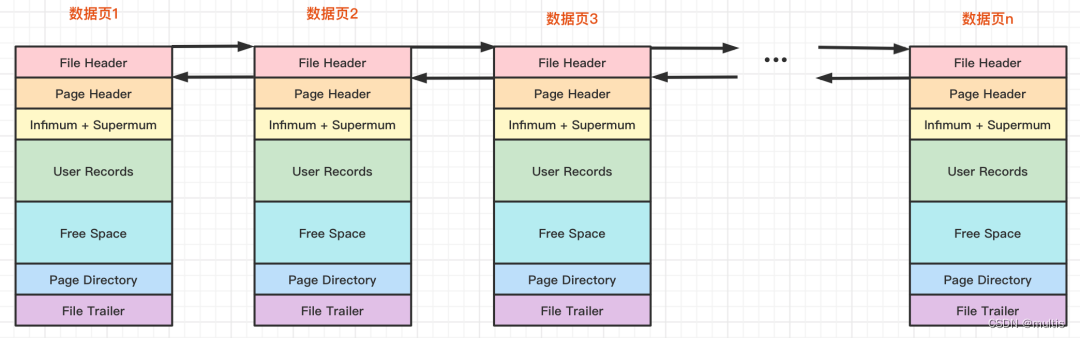
我们前边强调过,InnoDB都是以页为单位存放数据的,有时候我们存放某种类型的数据占用的空间非常大(比方说一张表中可以有成千上万条记录),InnoDB可能不可以一次性为这么多数据分配一个非常大的存储空间,如果分散到多个不连续的页中存储的话需要把这些页关联系起来来,fil_page_prev和fil_page_next就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了,而无需这些页在物理上真正连着。需要注意的是,并不是所有类型的页都有上一个和下一个页的属性,不过我们本集中唠叨的数据页(也就是类型为fil_page_index 的页)是有这两个属性的,所以所有的数据页其实是一个双链表,就像这样:
七、File Trailer(文件尾部)
InnoDB存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办,这不是莫名尴尬么?为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),InnoDB在每个页的尾部都加了一个File Trailer部分,这个部分由8个字节组成,可以分成2个小部分:
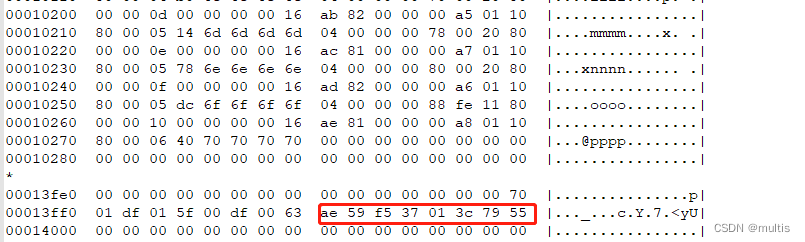
-
前4个字节代表页的校验和
这个部分是和File Header中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为File Header在页面的前边,所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在File Header中的校验和就代表着已经修改过的页,而在File Trailer中的校验和代表着原先的页,二者不同则意味着同步中间出了错。 -
后4个字节代表页面被最后修改时对应的日志序列位置(LSN)
这个部分也是为了校验页的完整性的,只不过我们目前还没说LSN
是个什么意思,所以大家可以先不用管这个属性。这个File Trailer与File Header类似,都是所有类型的页通用的。
总结
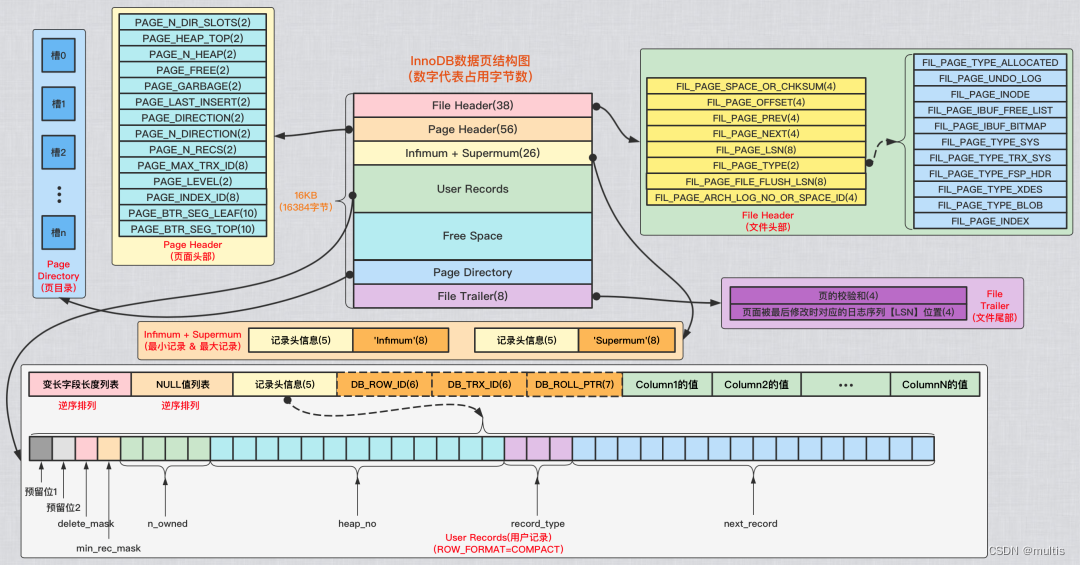
今天的数据页结构理论知识也很多,下面我们来做个总结:
-
InnoDB为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做数据页
-
一个数据页可以被大致划分为7个部分,分别是:
-
-
File Header,表示页的一些通用信息,占固定的38字节。
-
Page Header,表示数据页专有的一些信息,占固定的56个字节。
-
Infimum + Supremum,两个虚拟的伪记录,分别表示页中的最小和最大记录,占固定的26个字节。
-
User Records:真实存储我们插入的记录的部分,大小不固定。
-
Free Space:页中尚未使用的部分,大小不确定。
-
Page Directory:页中的某些记录相对位置,也就是各个槽在页面中的地址偏移量,大小不固定,插入的记录越多,这个部分占用的空间越多。
File Trailer:用于检验页是否完整的部分,占用固定的8个字节
-
-
每个记录的头信息中都有一个next_record属性,从而使页中的所有记录串联成一个单链表
-
InnoDB会把页中的记录划分为若干个组,每个组的最后一个记录的地址偏移量作为一个槽,存放在Page Directory中,所以在一个页中根据主键查找记录是非常快的,分为两步:
- 通过二分法确定该记录所在的槽。
- 通过记录的next_record属性遍历该槽所在的组中的各个记录。
-
每个数据页的File Header部分都有上一个和下一个页的编号,所以所有的数据页会组成一个双链表。
-
为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的LSN值,如果首部和尾部的校验和和LSN值校验不成功的话,就说明同步过程出现了问题。
便于大家理解,我整理了一张数据页结构图:
本章较上一章记录结构知识点更多,原书作者画了很多图,看完后,我是一脸懵,虽然这两章内容理论知识偏多,但是为我们后面理解索引原理打下坚实基础,所以大家一定要理解文中重要的知识点。
至此今天的学习就到此结束了,愿您成为坚不可摧的自己~~~
You can’t connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your future.You have to trust in something - your gut, destiny, life, karma, whatever. This approach has never let me down, and it has made all the difference in my life
Si mi contenido te es útil, por favor 点赞, 评论,, 收藏la creación no es fácil, el apoyo de todos es la motivación para que yo persevere
