prefacio
Uno de los conceptos que no podemos evitar cuando nos involucramos en bases de datos es 连接( join). Creo que muchos amigos están un poco confundidos cuando aprenden a conectarse por primera vez, después de comprender la semántica de la conexión, es posible que no entiendan cómo se conectan los registros en cada tabla, por lo que a menudo caen en los siguientes dos malentendidos al usar el base de datos más tarde:
误区一: El negocio es lo primero, no importa cuán complicada sea la consulta, se puede hacer en una declaración de conexión误区二: Manténgase alejado, la consulta lenta puede deberse al uso de conexiones
Entonces, en este artículo, estudiaremos sistemáticamente el principio de conexión. Teniendo en cuenta que algunos amigos son novatos, primero presentemos algunas sintaxis de conexión admitidas en MySQL.
Los amigos interesados también pueden echar un vistazo a 【数据库原理 • 二】关系数据库理论[ a través del tren ]
Tabla de contenido
1. Conexión Introducción
1.1 La naturaleza de la conexión
Para que podamos estudiar normalmente, aquí se crean dos tablas simples y se insertan algunos datos en ellas:
mysql> create table demo9 (m1 int, n1 char(1));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into demo9 values(1, 'a'), (2, 'b'), (3, 'c');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table demo10 (m2 int, n2 char(1));
Query OK, 0 rows affected (0.03 sec)
mysql> insert into demo10 values(2, 'b'), (3, 'c'), (4, 'd');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
Hemos creado con éxito demo9dos demo10tablas, las cuales tienen 两个列un inttipo y un char(1)tipo.Los datos de estas dos tablas son los siguientes:
mysql> select * from demo9;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.00 sec)
mysql> select * from demo10;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
3 rows in set (0.00 sec)
连接的本质Solo 各个连接表中的记录都取出来依次匹配的组合加⼊结果集并返回给用户pon Entonces, el proceso de conectar las demo9dos demo10tablas se muestra en la siguiente figura:
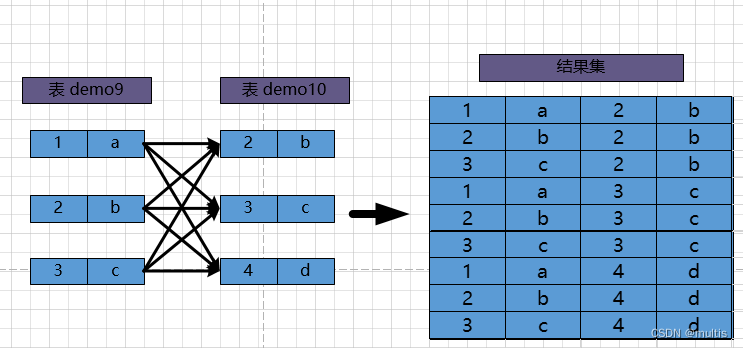
Este proceso consiste en conectar demo9los registros de la tabla y demo10los registros de la tabla para formar un registro nuevo y más grande, por lo que este proceso de consulta se llama 连接查询. El conjunto de resultados de una consulta de combinación contiene una combinación coincidente de todos los registros de una tabla y todos los registros de la otra tabla. Un conjunto de resultados como este se puede llamar 笛卡尔积. Debido a que demo9hay 3registros en la tabla y registros demo10en la tabla, hay registros 3después de conectar las dos tablas . En , la sintaxis de la consulta de conexión también es muy aleatoria, siempre que la declaración esté seguida de varios nombres de tabla, por ejemplo, la declaración de consulta de que conectamos la tabla y la tabla se puede escribir de la siguiente manera:笛卡尔积3×3=9MySQLfromdemo9demo10
mysql> select * from demo9,demo10;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 1 | a | 2 | b |
| 2 | b | 2 | b |
| 3 | c | 2 | b |
| 1 | a | 3 | c |
| 2 | b | 3 | c |
| 3 | c | 3 | c |
| 1 | a | 4 | d |
| 2 | b | 4 | d |
| 3 | c | 4 | d |
+------+------+------+------+
9 rows in set (0.00 sec)
1.2 Introducción al proceso de conexión
Si nos gusta, nosotros 可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接起来产生的笛卡尔积可能是非常巨大. Por ejemplo, el producto cartesiano generado al conectar tres tablas de 100 registros tiene 100 × 100 × 100 = 1,000,000 de datos. 过滤掉特定记录组合Por lo tanto, es necesario cuando se conecta , y la consulta de conexión 过滤条件se puede dividir en dos tipos:
-
Condiciones que involucran una sola tabla
Hemos mencionado la condición de filtro de diseñar solo una sola tabla miles de veces antes, y siempre la hemos llamado antes,搜索条件por ejemplo,demo9.m1 > 1es una condición de filtro solo parademo9tablas, ydemo10.n2 < 'd'es una condición de filtro solo parademo10mesas. -
Condiciones que involucran dos tablas
No hemos mencionado esta condición de filtro antes, comodemo9.m1 = demo10.m2,demo9.n1 > demo10.n2etc., que están involucradas en estas condiciones两个表, y analizaremos cuidadosamente cómo se usa esta condición de filtro más adelante.
A continuación, veremos 过滤条件的连接查询el proceso de ejecución general llevado a cabo, como la siguiente declaración de consulta:
mysql> select * from demo9, demo10 where demo9.m1 > 1 and demo9.m1 = demo10.m2 and demo10.n2 < 'd';
En esta consulta, especificamos esto 三个过滤条件:
demo9.m1 > 1demo9.m1 = demo10.m2demo10.n2 < 'd'
Entonces el proceso general de ejecución de esta consulta es el siguiente:
paso uno:
En primer lugar 确定第一个需要查询的表, se llama a la tabla 驱动表. Ya hemos hablado de cómo ejecutar declaraciones de consulta en una sola tabla, MySQLsolo necesita seleccionar 代价最小la 访问方法que desea ejecutar 单表查询语句(es decir, seleccionar el método de ejecución menos costoso de const, ref, ref_or_null, range, para ejecutar la consulta) index. Suponiendo que se alluse aquí , es necesario encontrar registros satisfactorios en la tabla , porque los datos en la tabla son demasiado pequeños y no hemos establecido un índice secundario en la tabla, por lo que el método de acceso de la tabla de consulta aquí es establecido en , Esa es la forma en que se ejecuta . Hablaremos sobre cómo mejorar el rendimiento de las consultas de conexión más adelante, pero primero aclaremos los conceptos básicos. Entonces, el proceso de consulta es como se muestra en la siguiente figura:demo9驱动表demo9demo9.m1>1demo9all全表扫描单表查询
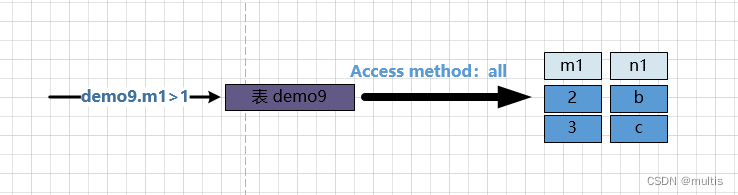
Podemos ver que hay registros coincidentes demo9en la tabla .demo9.m1 > 1两条
Segundo paso:
Para los registros del paso anterior 驱动表产生的结果集中的每一条记录,分别需要到demo10表中查找匹配的记录, los llamados registros coincidentes se refieren a 符合过滤条件的记录. Dado que demo9los registros de la tabla se encuentran en función de demo10los registros de la tabla, demo10la tabla también se puede llamar 被驱动表. En el paso anterior, se obtuvo 2un registro de la tabla de controladores, por lo que debe consultarse 2次demo10表. En este punto, la condición de filtro que involucra las columnas de las dos tablas demo9.m1=demo10.m2es útil:
-
En ese momento
demo9.m1 = 2, filtre las condicionesdemo9.m1 = demo10.m2就相当于demo10.m2 = 2, por lo que en este momentodemo10la tabla es equivalente a tenerdemo10.m2 = 2,demo10.n2 < 'd'esto两个过滤条件, y luegodemo10ejecutar en la tabla单表查询 -
En ese momento
demo9.m1 = 3filtrar condicionesdemo9.m1 = demo10.m2就相当于demo10.m2 = 3, por lo que en este momentodemo10la tabla es equivalente a tenerdemo10.m2 = 3、demo10.n2<'d'esto两个过滤条件, y luego ir ademo10la tabla a ejecutar单表查询
Así que todo el 连接查询proceso de ejecución se muestra en la siguiente figura:
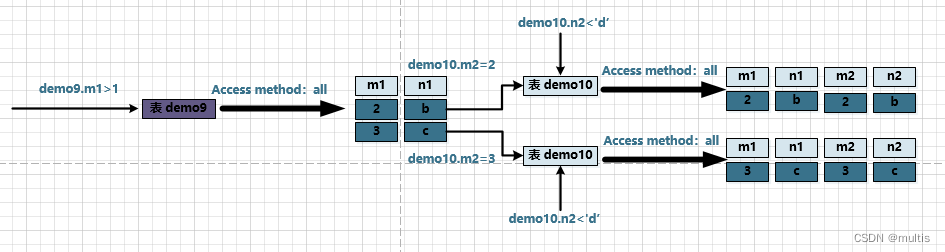
Es decir 整个连接查询最后的结果只有两条符合过滤条件的记录:
mysql> select * from demo9, demo10 where demo9.m1 > 1 and demo9.m1 = demo10.m2 and demo10.n2 < 'd';
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows in set (0.00 sec)
Como se puede ver en los dos pasos anteriores, nuestra consulta de combinación de dos tablas anterior requiere un total de 查询1次demo9表. 2次demo10表Por supuesto, esto es el resultado de una condición de filtro específica. Si eliminamos demo9.m1 > 1esta condición, demo9habrá un registro de la tabla 3y debemos consultar 3次demo10la tabla. Es decir, en la consulta de unión entre dos tablas, 驱动表只需要访问⼀次,被驱动表可能被访问多次.
1.3 Unión interna y unión externa
Para aprender mejor el siguiente contenido, primero creamos dos tablas realistas:
mysql> create table student (
number int not null auto_increment comment '学号',
name varchar(5) comment '姓名',
major varchar(30) comment '专业',
primary key (number)
) comment '学生信息表';
Query OK, 0 rows affected (0.02 sec)
mysql> create table score (
number int comment '学号',
subject varchar(30) comment '科目',
score tinyint comment '成绩',
primary key (number, score)
) comment '学生成绩表';
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values(1,'张三','软件学院'),(2,'李四','计算机科学与工程'),(3,'王五','计算机科学与工程');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into score values(1,'MySQL是怎样运行的',78),(1,'MySQL实战45讲',88),(2,'MySQL是怎样运行的',78),(2,'MySQL实战45讲',100);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Creamos uno nuevo 学⽣信息表y 一个学生成绩表luego insertamos algunos datos en las dos tablas anteriores, los datos en las dos últimas tablas son los siguientes:
mysql> select * from student;
+--------+--------+--------------------------+
| number | name | major |
+--------+--------+--------------------------+
| 1 | 张三 | 软件学院 |
| 2 | 李四 | 计算机科学与工程 |
| 3 | 王五 | 计算机科学与工程 |
+--------+--------+--------------------------+
3 rows in set (0.00 sec)
mysql> select * from score;
+--------+-------------------------+-------+
| number | subject | score |
+--------+-------------------------+-------+
| 1 | MySQL是怎样运行的 | 78 |
| 1 | MySQL实战45讲 | 88 |
| 2 | MySQL是怎样运行的 | 98 |
| 2 | MySQL实战45讲 | 100 |
+--------+-------------------------+-------+
4 rows in set (0.00 sec)
Ahora, si queremos consultar los puntajes de las pruebas de cada estudiante, debemos conectar las dos tablas (debido a que scoreno hay información de nombre, no podemos simplemente consultar scorela tabla). El proceso de conexión consiste studenten tomar registros de la tabla y scorebuscar numberlos mismos registros de calificación en la tabla, por lo que la condición de filtro es student.number =socre.number, la declaración de consulta completa es así:
mysql> select * from student,score where student.number=score.number;
+--------+--------+--------------------------+--------+-------------------------+-------+
| number | name | major | number | subject | score |
+--------+--------+--------------------------+--------+-------------------------+-------+
| 1 | 张三 | 软件学院 | 1 | MySQL是怎样运行的 | 78 |
| 1 | 张三 | 软件学院 | 1 | MySQL实战45讲 | 88 |
| 2 | 李四 | 计算机科学与工程 | 2 | MySQL是怎样运行的 | 98 |
| 2 | 李四 | 计算机科学与工程 | 2 | MySQL实战45讲 | 100 |
+--------+--------+--------------------------+--------+-------------------------+-------+
4 rows in set (0.00 sec)
Hay muchos campos, podemos consultar algunos campos menos:
mysql> select s1.number,s1.name,s2.subject,s2.score from student s1 ,score s2 where s1.number=s2.number;
+--------+--------+-------------------------+-------+
| number | name | subject | score |
+--------+--------+-------------------------+-------+
| 1 | 张三 | MySQL是怎样运行的 | 78 |
| 1 | 张三 | MySQL实战45讲 | 88 |
| 2 | 李四 | MySQL是怎样运行的 | 98 |
| 2 | 李四 | MySQL实战45讲 | 100 |
+--------+--------+-------------------------+-------+
4 rows in set (0.00 sec)
De los resultados de la consulta anterior, podemos ver que se han encontrado los puntajes de cada materia correspondiente a cada estudiante, pero hay un problema, Wang Wu, es decir, el estudiante con el número de estudiante 3 no tomó el examen por algunos motivo, por lo que scoreno hay un registro de calificación correspondiente en la tabla Luego, si el profesor desea verificar los puntajes de todos los estudiantes, incluso los estudiantes que no asistieron a la prueba deben mostrarse, pero la consulta de conexión que hemos presentado hasta ahora no puede cumplir con ese requisito. Pensemos un poco en este requisito. La esencia es que, incluso si los registros en la tabla de control no tienen registros coincidentes en la tabla de control, aún deben agregarse al conjunto de resultados. Para resolver este problema, existe el concepto de 内连接suma 外连接:
- Para
内连接的两个表el registro en la tabla de control, no se puede encontrar ningún registro coincidente en la tabla de control, y el registro no se agregará al conjunto de resultados final. Las conexiones que mencionamos anteriormente son todas las llamadas conexiones internas. - Para
外连接的两个表los registros en la tabla de control, incluso si no hay un registro coincidente en la tabla de control, aún debe agregarse al conjunto de resultados
En MySQL, de acuerdo con la selección de la tabla de conducción, la conexión externa todavía se puede subdividir en dos tipos:
左外连接: seleccione la tabla de la izquierda como la tabla del conductor右外连接: seleccione la tabla de la derecha como tabla de controladores
Pero todavía hay problemas, incluso para 外连接nosotros, a veces no lo hacemos 不想把驱动表的全部记录都加入到最后的结果集. Esto es difícil. A veces, la coincidencia no se agrega al conjunto de resultados y, a veces, no se agrega al conjunto de resultados. ¿Qué debo hacer? Dividir las condiciones de filtro en dos tipos resolverá este problema, por lo que las condiciones de filtro se colocan en diferentes lugares. tienen semántica diferente:
-
where子句中的过滤条件:whereLas condiciones de filtro en la cláusula son las que solemos ver. Ya sea una conexión interna o una conexión externa, todos loswhereregistros que no cumplan con las condiciones de filtro en la cláusula no se agregarán al conjunto de resultados final. -
ON子句中的过滤条件: Para el registro de la tabla de control de la conexión externa, si无法在被驱动表中找到匹配ON子句中的过滤条件的记录, el registro se agregará al conjunto de resultados y cada campo del registro de la tabla de control correspondiente se llenará conNULLvalores.Cabe señalar que esta
ONcláusula se propone específicamente para el registro en la tabla controladora de combinación externa. Cuando la tabla controlada no puede encontrar un registro coincidente, el registro debe agregarse al conjunto de resultados. Por lo tanto, si la cláusula se coloca en EnONel conexión interna,MySQLse trataráwhereigual que la cláusula, es decir: las cláusulas y las cláusulas内连接en son equivalentes.whereON
En circunstancias normales, nos referimos solo a implicación 单表的过滤条件放到where子句中y nos referimos a implicación 两表的过滤条件都放到ON子句y, en general, también nos ONreferimos a las condiciones de filtro que se colocan en la cláusula 连接条件.
小提示:
La combinación externa izquierda y la combinación externa derecha se conocen como combinación izquierda y combinación derecha.
1.4 Unión exterior izquierda
La sintaxis de la combinación externa izquierda es bastante simple, por ejemplo, si queremos demo9unir demo10dos tablas 左外连接, podemos escribirlo así:
select * from demo9 left [outer] join demo10 on 连接条件 [where 普通过滤条件]
Las palabras entre paréntesis outerpueden omitirse. Para left joinuna conexión de tipo, ponemos 左边的表lo que llamamos 外表或者驱动表, 右边的表llámalo 内表或者被驱动表. Así que en el ejemplo anterior demo9es 外表或者驱动表, demo10es 内表或者被驱动表. Cabe señalar que para la combinación externa izquierda y la combinación externa derecha, 必须使用on子句来指出连接条件. Después de comprender la gramática básica de la combinación externa izquierda, volvamos al problema real anterior y veamos cómo escribir declaraciones de consulta para consultar toda la información de calificaciones de los estudiantes.Incluso los candidatos que perdieron el examen deben colocarse en el conjunto de resultados:
mysql> select s1.number,s1.name,s2.subject,s2.score from student s1 left join score s2 on s1.number=s2.number;
+--------+--------+-------------------------+-------+
| number | name | subject | score |
+--------+--------+-------------------------+-------+
| 1 | 张三 | MySQL是怎样运行的 | 78 |
| 1 | 张三 | MySQL实战45讲 | 88 |
| 2 | 李四 | MySQL是怎样运行的 | 98 |
| 2 | 李四 | MySQL实战45讲 | 100 |
| 3 | 王五 | NULL | NULL |
+--------+--------+-------------------------+-------+
5 rows in set (0.01 sec)
En el conjunto de resultados se puede ver que, aunque Wang Wu no tiene un registro de puntuación correspondiente, todavía se coloca en el conjunto de resultados debido al uso de , 连接类型为左外连接pero las columnas del registro de puntuación correspondiente NULLestán llenas de valores.
1.5 Unión exterior derecha
Los principios de la combinación externa derecha y la combinación externa izquierda son los mismos, y la sintaxis simplemente se reemplaza leftpor right:
select * from demo9 right [outer] join demo10 on 连接条件 [where 普通过滤条件]
Es solo que la mesa de conducción es la mesa de la derecha y la mesa de conducción es la mesa de la izquierda, por lo que no lo explicaré en detalle.
1.6 Uniones internas
内连接和外连接的根本区别就是在驱动表中的记录不符合on子句中的连接条件时不会把该记录加入到最后的结果集, los tipos de consultas de combinación que aprendimos al principio son todos 内连接. Sin embargo, antes solo mencioné la sintaxis de unión interna más simple, que consiste en colocar directamente varias tablas que deben unirse detrás de la cláusula from. De hecho 针对内连接,mysql提供了好多不同的语法, tomemos el reloj demo9como demo10ejemplo:
select * from demo9 [inner|cross] join demo10 [on 连接条件] [where 普通过滤条件];
Es decir, en MySQL, los siguientes métodos de escritura de conexiones internas son equivalentes:
select * from demo9 join demo10;
select * from demo9 inner join demo10;
select * from demo9 cross join demo10;
Los métodos de escritura anteriores son equivalentes a poner directamente el nombre de la tabla que se va a conectar fromdespués de la declaración :逗号,分隔开
select * from demo9,demo10;
Aunque hemos presentado muchas formas de escribir enlaces internos, es bueno estar familiarizado con una Aquí recomendamos inner joinescribir enlaces internos principalmente porque inner joinla semántica es muy clara y se puede distinguir fácilmente de left joiny . right joinCabe señalar aquí que, dado que las cláusulas y las cláusulas son equivalentes en 内连接el medio , no se requiere en la conexión interna .onwhere强制写明on子句
Como dijimos anteriormente, 连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户. No importa qué mesa se utilice como mesa de conducción, la conexión entre las dos mesas 笛卡尔积debe ser la misma. En cuanto a 内连接来说,由于凡是不符合on子句或where子句中的条件的记录都会被过滤掉, en realidad es equivalente a eliminar los registros que no cumplen las condiciones del filtro del producto cartesiano de la conexión entre las dos tablas, por lo que 对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果. Pero para él 外连接, 由于驱动表中的记录即使在被驱动表中找不到符合ON子句条件的记录时也要将其加入到结果集entonces la relación entre la mesa de conducción y la mesa de conducción es muy importante en este momento, es decir 左外连接和右外连接的驱动表和被驱动表不能轻易互换.
resumen
Mucho se ha dicho anteriormente, pero no es muy intuitivo para todos. Escribimos directamente los tres métodos de conexión de tablas demo9y demo10sumas juntos, para que todos puedan entenderlo fácilmente:
mysql> select * from demo9 inner join demo10 on demo9.m1 = demo10.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows inset (0.00 sec)
mysql> select * from demo9 left join demo10 on demo9.m1 = demo10.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| 1 | a | null | null |
+------+------+------+------+
3 rows inset (0.00 sec)
mysql> select * from demo9 right join demo10 on demo9.m1 = demo10.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| null | null | 4 | d |
+------+------+------+------+
3 rows inset (0.00 sec)
2. El principio de conexión
Las introducciones anteriores son solo para despertar la memoria de todos los conceptos de 连接, 内连接, y estos conceptos básicos son para allanar el camino para la entrada real en el tema de este capítulo. 外连接El punto real es MySQLqué tipo de algoritmo se usa para unir las tablas. Después de comprender esto, puede comprender por qué algunas consultas de unión se ejecutan tan rápido como un rayo, mientras que otras son tan lentas como un caracol.
2.1 Unión de bucle anidado
Como decíamos antes, para la conexión entre dos mesas, 驱动表只会被访问一遍,但被驱动表却要被访问到好多遍el número concreto de visitas depende del par 驱动表执行单表查询后的结果集中的记录条数. 对于内连接来说,选取哪个表为驱动表都没关系, 而外连接的驱动表是固定的,也就是说左外连接的驱动表就是左边的那个表,右外连接的驱动表就是右边的那个表. Ya hemos presentado brevemente el proceso general de realizar consultas de unión interna demo9en tablas y demo10tablas.
选取驱动表, utilizando los criterios de filtro asociados con la tabla de controladores, seleccione代价最低的单表访问方法来执行对驱动表的单表查询.- Para cada registro en el conjunto de resultados obtenido al consultar la tabla de unidades en los pasos anteriores
分别到被驱动表中查找匹配的记录,
El proceso de unir las dos mesas a través se muestra en la siguiente figura:
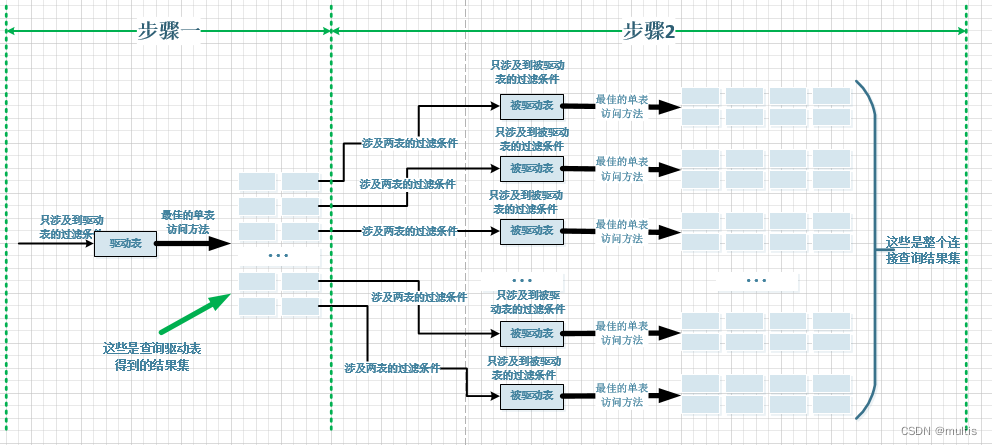
Si es así 3个表进行连接的话,那么步骤2中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表, repita el proceso anterior, es decir, para cada registro en el conjunto de resultados obtenido en el paso 2, debe demo11encontrar si hay un registro coincidente en la tabla. Use pseudocódigo para expresar este proceso de la siguiente manera:
for each row in demo9 { #此处表示遍历满足对demo9单表查询结果集中的每一条记录
for each row in demo10 { #此处表示对于某条demo9表的记录来说,遍历满足对demo10单表查询结果集中的每一条记
for each row in demo11 { #此处表示对于某条demo9和demo10表的记录组合来说,对demo11表进行单表查询
if row satisfies join conditions, send to client
}
}
}
Este proceso es como one 嵌套的循环, por lo que solo se accede a la tabla de control una vez, pero se puede acceder a la tabla de control varias veces. La cantidad de visitas depende de la cantidad de registros en el resultado de la consulta de una sola tabla en la tabla de control. it 嵌套循环连接( Nested-Loop Join), este es el algoritmo de consulta de combinación más simple y torpe.
2.2 Uso de índices para acelerar las conexiones
Sabemos que en la conexión de bucle anidado 步骤2中可能需要访问多次被驱动表, si 被驱动表的方式都是全表扫描se accede, tendrá que escanear muchas veces ~ Pero no olvide, la demo10tabla de consulta es en realidad equivalente a una vez 单表扫描, y podemos usarla 索引来加快查询速度. Repasemos el ejemplo de unión interna entre demo9tablas presentado al principio :demo10
mysql> select * from demo9, demo10 where demo9.m1 > 1 and demo9.m1 = demo10.m2 and demo10.n2 < 'd';
En realidad, estamos usando 嵌套循坏连接la consulta de conexión ejecutada por el algoritmo, y luego desplegamos la tabla del proceso de ejecución de consultas anterior para mostrarle:
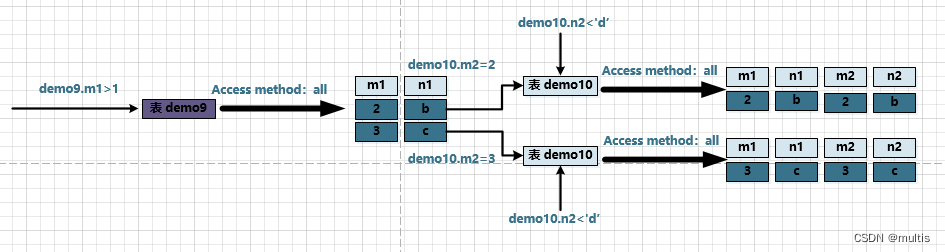
demo9Hay dos registros en el conjunto de resultados después de consultar la tabla de control , 嵌套循坏连接el algoritmo necesita 对被驱动表查询两次:
primero:
En ese momentodemo9.m1 = 2 , para demo10volver a consultar la tabla, demo10la declaración de consulta es equivalente a:
select * from demo10 where demo10.m2 = 2 and demo10.m2 < 'd';
la segunda vez:
En ese momentodemo9.m1 =3 , para demo10volver a consultar la tabla, demo10la declaración de consulta es equivalente a:
select * from demo10 where demo10.m2 = 3 and demo10.m2 < 'd';
Se puede ver que la demo9.m1 = demo10.m2condición de filtro original que involucra dos tablas ya ha determinado las condiciones sobre la tabla demo10al consultar la tabla , por lo que solo necesitamos optimizar la consulta en la tabla.En las dos declaraciones de consulta anteriores en la tabla, las columnas utilizadas son y columnas, podemos:demo9demo10demo10m2n2
-
在m2列上建立索引, porque sím2列的条件是等值查找, comodemo10.m2 = 2,demo10.m2 = 3etc., por lo que el método de acceso que se puede usarref, suponiendo querefel método de acceso se use para ejecutardemo10la consulta en la tabla, debe volver a la tabla antes de juzgardemo10.n2 < dsi esta condición es verdadera.Hay un caso especial aquí, es decir, suponiendo que
m2la columna esdemo10la clave principal de la tabla o la única columna de índice secundaria, entonces el costo de usardemo10.m2 = 常数值tales condicionesdemo10para encontrar registros de la tabla es常数级别. Sabemos在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称之为constque MySQL se refiere a la forma de ejecutar la tabla impulsada en la consulta de conexión使用主键值或者唯一二级索引列的值进行等值查找的查询como:eq_ref. -
Para crear un índice en
n2una columna, las condiciones involucradas son el método de acceso quedemo10.n2 < 'd'se puede usar Suponiendo que el método de acceso usado se usa para consultar la tabla demo10, es necesario volver a la tabla antes de juzgar si la condición en la columna es verdad.rangerangem2
Suponiendo que hay índices en las columnas m2y , entonces debe elegir uno de estos dos . Por supuesto, el índice no necesariamente usa el índice, solo el índice .n2代价更低的去执行对demo10表的查询在二级索引 +回表的代价比全表扫描的代价更低时才会使用索引
Además, a veces 连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部分,这种情况下即使不能使用eq_ref、ref、ref_or_null或者range这些访问方法执行对被驱动表的查询的话,也可以使用索引扫描, es decir, indexel método de acceso a la consulta 被驱动表. Por lo tanto, sugerimos que en el trabajo real 最好不要使用*作为查询列表, es mejor usar 真实用到的列作为查询列表.
2.3 Bloque de unión de bucle anidado
El proceso de escanear una tabla es en realidad poner esto primero 表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足. Las tablas en la vida real no son como las tablas demo9con demo10solo 3 registros, las decenas de miles de registros son raras y las tablas con millones, decenas de millones o incluso cientos de millones de registros están en todas partes. Es posible que la memoria no pueda almacenar por completo todos los registros de la siguiente tabla, por lo que al escanear los primeros registros de la tabla, es posible que los últimos registros aún estén en el disco y, cuando se escanean los últimos registros, es posible que no haya memoria suficiente. , por lo que los registros anteriores deben moverse desde la liberación en la memoria. Como dijimos anteriormente, en el proceso de unir dos tablas utilizando el algoritmo de unión de bucle anidado, se debe acceder a la tabla controlada muchas veces. Si los datos en la tabla controlada son demasiado grandes y no se puede acceder a ellos mediante un índice, es equivalente El costo de leer muchas veces esta tabla desde el disco I/Oes muy alto, por lo que tenemos que encontrar una manera: minimizar el número de accesos a la tabla manejada.
Cuando被驱动表 hay muchos datos en él, cada vez que se accede a ellos 被驱动表, 被驱动表los registros se cargarán en la memoria 内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉. Luego 驱动表tome otro registro del conjunto de resultados, 被驱动表grábelo nuevamente 加载到内存中y repita, 驱动表tantos registros como haya en el conjunto de resultados, debe 被驱动表cargarlo del disco a la memoria tantas veces. Entonces, ¿podemos hacer coincidir los registros en el registro al 被驱动表mismo tiempo cuando cargamos los registros en la memoria , de modo que el costo de cargar repetidamente la tabla controlada desde el disco se puede reducir considerablemente? 多条驱动表Por lo tanto , MySQLse propone un join bufferconcepto join buffer, que consiste en solicitar una memoria de tamaño fijo antes de ejecutar la consulta de conexión, primero instalar varios registros en el conjunto de resultados de la tabla de control y luego comenzar a escanear la join buffertabla de control y cada registro del control de control. table join bufferHaga coincidir varios registros de la tabla de controladores en una suma única , porque el proceso de coincidencia se realiza todo en la memoria, por lo que este es el caso 可以显著减少被驱动表的I/O代价. El proceso utilizado join bufferse muestra en el siguiente diagrama:
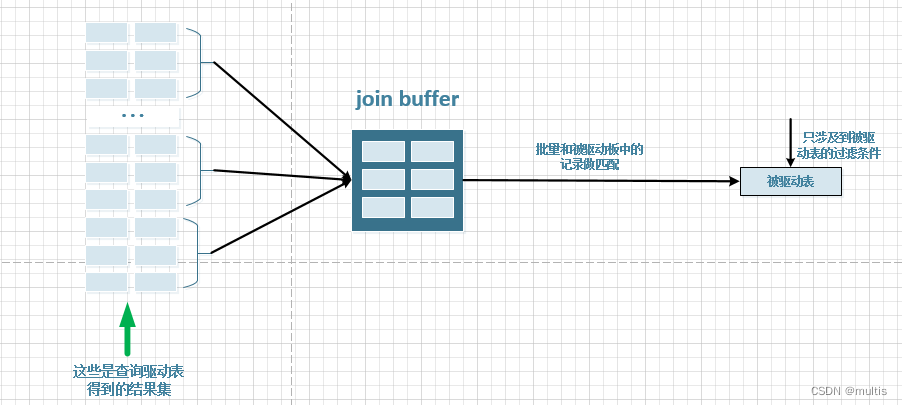
En el mejor de los casos join buffer, es lo suficientemente grande como para acomodar todos los registros en el conjunto de resultados de la tabla de control, de modo que solo se requiere un acceso a la tabla de control para completar la operación de combinación. join buffer的嵌套循环连接算法MySQL llama a esto unirse 基于块的嵌套连接(Block Nested-Loop Join)算法.
El tamaño de este join bufferse puede join_buffer_sizeconfigurar a través de parámetros de inicio o variables del sistema, el tamaño predeterminado es 262144字节(es decir 256KB), el mínimo se puede establecer en 128字节. Por supuesto 对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化,
mysql> show variables like 'join_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
mysql> set persist join_buffer_size=524288;
Query OK, 0 rows affected (0.01 sec)
Sugerencia:
No se recomienda configurar este valor demasiado grande a nivel del sistema, generalmente se puede configurar dentro de 512K, porque la solución final todavía depende del índice para resolverlo, por supuesto, no se descarta que a veces dos las tablas están asociadas y, de hecho, no hay índice disponible
Otra cosa a tener en cuenta es, 驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中así que recuérdanos de nuevo, es mejor 不要把*作为查询列表poner las columnas que nos interesan en la lista de consulta, para que podamos join bufferponer más registros en ella.
Resumir
Hoy aprendimos sobre las conexiones. Conozca la esencia de la conexión, el proceso de la conexión, el método de usar la conexión interna y la conexión externa, y el principio de la conexión. NLJSobre la base del algoritmo original , MySQLse ha diseñado un BNLalgoritmo mejor. Podemos pasar la tabla impulsada 添加关联字段索引的方式来提高查询效率. Si no se puede usar el índice, podemos intentar aumentar Join Bufferel valor ( join_buffer_size). Al usar combinaciones internas, debe prestar atención a:
-
ON子句和where子句是等价的, por lo que no se requiere que la cláusula ON sea obligatoria en la conexión interna -
Para las uniones internas, porque en realidad todo
不符合on子句或where子句中的条件的记录都会被过滤掉es equivalente a expulsar los registros que no cumplen las condiciones de filtrado del producto cartesiano de la unión entre las dos tablas, por lo que para las uniones internas,驱动表和被驱动表是可以互换,并不会影响最后的查询结果.
Hasta ahora, el estudio de hoy ha terminado, espero que te conviertas en un yo indestructible
~~~
No puedes conectar los puntos mirando hacia adelante; solo puedes conectarlos mirando hacia atrás. Así que tienes que confiar en que los puntos se conectarán de alguna manera en tu futuro. Tienes que confiar en algo: tu instinto, destino, vida, karma, lo que sea. Este enfoque nunca me ha defraudado y ha marcado una gran diferencia en mi vida.
Si mi contenido te es útil, por favor 点赞, 评论, 收藏, la creación no es fácil, ¡el apoyo de todos es la motivación para que persevere!
Este artículo se refiere a: Niños "Cómo funciona MySQL"
