La diferencia entre el aprendizaje profundo y el aprendizaje automático
Contenido de este artículo:
1. Extracción de características
1.3 Extracción de funciones de aprendizaje automático
1.4, extracción de funciones de aprendizaje profundo
1.5 Ejemplo de extracción de funciones de aprendizaje profundo
2. Requisitos de rendimiento informático y volumen de datos
3. Representante del algoritmo
3.1 Algoritmo bayesiano ingenuo
1. Extracción de características
1.1 Aprendizaje automático
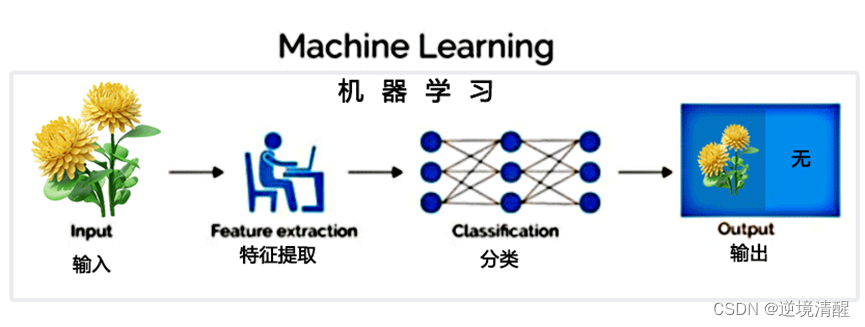
El aprendizaje automático es una técnica de inteligencia artificial que, dado un conjunto de datos, aprende automáticamente patrones y utiliza los resultados del aprendizaje para predecir o tomar decisiones. Se basa en algoritmos matemáticos y estadísticos para construir modelos que permitan a las computadoras aprender de forma autónoma sin ser programadas explícitamente.
El aprendizaje automático es una rama de la inteligencia artificial que se refiere a la capacidad de los sistemas informáticos para identificar y predecir patrones automáticamente mediante el análisis y el aprendizaje de grandes cantidades de datos.
En términos simples, el aprendizaje automático es permitir que las computadoras aprendan de los datos para realizar tareas al nivel de la inteligencia humana.
Estos son algunos conceptos de uso común en el aprendizaje automático:
- Conjunto de datos: se refiere a los datos utilizados para entrenar y probar algoritmos de aprendizaje automático.
- Características: Se refiere a la descripción del conjunto de datos, que puede estar en formato digital o de texto.
- Modelo: una implementación concreta de un algoritmo de aprendizaje automático que se puede entrenar en función de características y valores objetivo.
- Aprendizaje supervisado: predecir la salida de datos desconocidos entrenando la coincidencia de datos de entrada y resultados conocidos.
- Aprendizaje no supervisado: descubrimiento de patrones en datos no etiquetados para inferir la estructura y las relaciones de los datos.
- Aprendizaje profundo: una tecnología de aprendizaje automático basada en redes neuronales que puede simular la estructura de la red neuronal del cerebro humano y usar múltiples capas ocultas para aprender y clasificar datos.
El aprendizaje automático se usa ampliamente en muchos campos, como el comercio electrónico, las finanzas, la atención médica, el procesamiento del lenguaje natural, la visión por computadora y los vehículos autónomos, entre otros. Los algoritmos comunes de aprendizaje automático incluyen árboles de decisión, regresión logística, máquinas de vectores de soporte, redes neuronales y bosques aleatorios.
El paso de ingeniería de características del aprendizaje automático se realiza manualmente y requiere mucha experiencia en el dominio.
1.2 Aprendizaje profundo
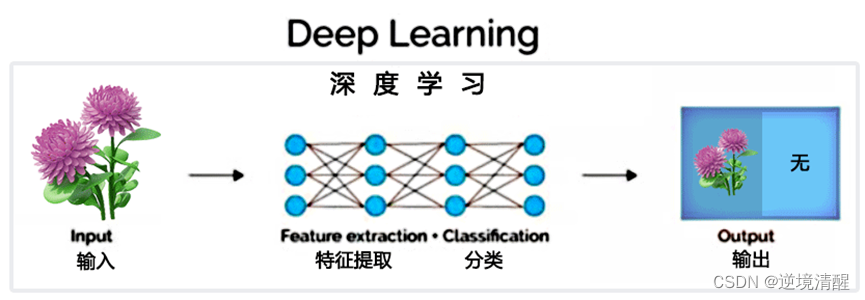
El aprendizaje profundo es un método de aprendizaje automático que utiliza redes neuronales compuestas de múltiples capas para simular y resolver problemas complejos. Su idea central es mejorar gradualmente la capacidad del modelo para representar y predecir datos a través del aprendizaje jerárquico y la extracción de características. En el aprendizaje profundo, las tecnologías centrales incluyen el algoritmo de retropropagación, la red neuronal convolucional, la red neuronal recurrente, la red de confrontación generativa, etc. El aprendizaje profundo tiene una amplia gama de escenarios de aplicación, como reconocimiento de imágenes, reconocimiento de voz, procesamiento de lenguaje natural, inteligencia artificial y otros campos.
El aprendizaje profundo generalmente consta de múltiples capas, que a menudo combinan modelos más simples, pasando datos de una capa a otra para construir modelos más complejos. El modelo se obtiene automáticamente entrenando una gran cantidad de datos, sin necesidad de extracción manual de características.
Los algoritmos de aprendizaje profundo intentan aprender características de alto nivel de los datos, lo cual es una parte única del aprendizaje profundo. Así, se reduce la tarea de desarrollar un nuevo extractor de características para cada problema. Es adecuado para campos de procesamiento de imágenes, voz y lenguaje natural en los que es difícil extraer características.
1.3 Extracción de funciones de aprendizaje automático
La extracción de características de aprendizaje automático se refiere a la extracción de características útiles de datos sin procesar para el entrenamiento de algoritmos de aprendizaje automático y el establecimiento de modelos. Estas características pueden ser valores numéricos, texto, imágenes o incluso sonidos. A través de la extracción de características, puede ayudar a los algoritmos de aprendizaje automático a comprender mejor los datos y lograr un mejor análisis y clasificación de datos.
El objetivo de la extracción de características es encontrar un conjunto de características que representen mejor los datos, y estas características pueden permitir que los algoritmos de aprendizaje automático aprendan información más significativa de los datos.
El proceso de extracción de características incluye pasos como el preprocesamiento de datos, la selección de características, la extracción de características y la representación de características. En estos procesos se deben considerar factores como el tipo, cantidad, calidad y distribución de los datos, así como la aplicabilidad y demanda de algoritmos de aprendizaje automático.
1.4, extracción de funciones de aprendizaje profundo
La extracción de características de aprendizaje profundo se refiere al proceso de usar el modelo de red neuronal profunda para aprender y extraer automáticamente características de los datos originales, de modo que los datos originales se puedan representar mejor como un conjunto de características abstractas de alto nivel, que pueden ser mejores. aplicado a clasificación y reconocimiento, detección y otras tareas.
La extracción de funciones de aprendizaje profundo se usa ampliamente en visión por computadora, procesamiento de lenguaje natural, reconocimiento de voz y otros campos. Los métodos específicos de extracción de funciones de aprendizaje profundo incluyen la red neuronal convolucional (CNN), la red neuronal recurrente (RNN), etc. Mediante el uso de redes neuronales profundas para extraer características de los datos, la precisión y la solidez del modelo se pueden mejorar considerablemente.
El aprendizaje profundo puede aprender características complejas de los datos de entrada al apilar varias capas de redes neuronales.
En el aprendizaje profundo, cada capa de la red neuronal se puede considerar como un mapeo de datos de entrada, y la salida de cada capa se puede usar como entrada de la siguiente capa. Al apilar continuamente múltiples capas de redes neuronales y entrenar los pesos, se pueden extraer gradualmente características más complejas para lograr una clasificación y predicción más precisas.
1.5 Ejemplo de extracción de funciones de aprendizaje profundo
El siguiente es un modelo de aprendizaje profundo implementado con Keras para clasificar dígitos escritos a mano.
El modelo contiene dos capas convolucionales y dos capas totalmente conectadas, que pueden aprender automáticamente a extraer las características de los dígitos escritos a mano y clasificarlos como uno de los dígitos del 0 al 9.
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from keras.utils import np_utils
# Cargar el conjunto de datos MNIST y preprocesarlo
# 加载MNIST数据集并进行预处理
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
# Construya un modelo de aprendizaje profundo
# 构建深度学习模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
# Compilar el modelo
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# entrenar el modelo y evaluar el rendimiento
# 训练模型并评估性能
model.fit(X_train, y_train, epochs=10, batch_size=32, verbose=1)
score = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
En este ejemplo, usamos capas convolucionales y de agrupación máxima para extraer características visuales de dígitos escritos a mano, que luego se transformaron en predicciones de etiquetas de dígitos a través de capas completamente conectadas. Al entrenar los pesos a través del algoritmo de retropropagación, podemos dejar que el modelo aprenda automáticamente el proceso de extracción de características, para lograr una clasificación más eficiente y precisa.
2. Requisitos de rendimiento informático y volumen de datos
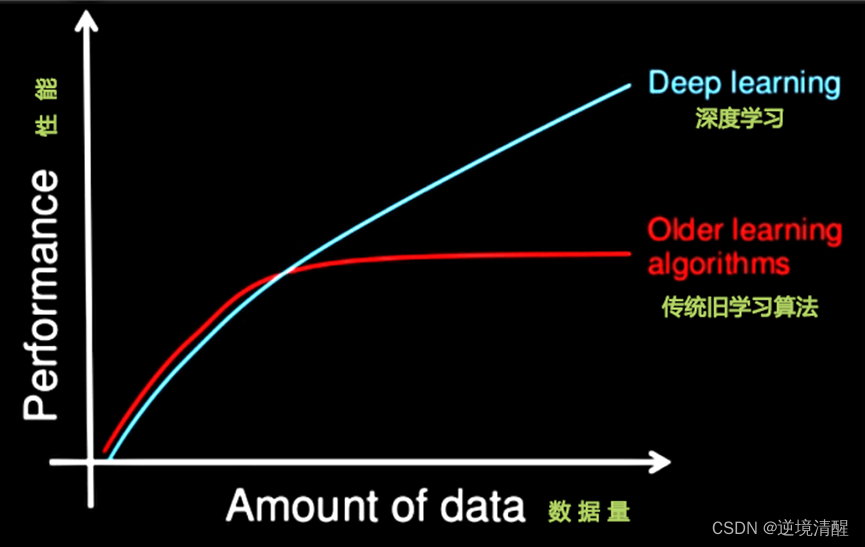
El tiempo de ejecución requerido por el aprendizaje automático es mucho menor que el del aprendizaje profundo. Los parámetros del aprendizaje profundo suelen ser muy grandes y los parámetros deben entrenarse a través de múltiples optimizaciones de una gran cantidad de datos.
Primero, el aprendizaje profundo requiere un gran conjunto de datos de entrenamiento.
En segundo lugar, entrenar una red neuronal profunda requiere mucha potencia informática.
Puede llevar días, o incluso semanas, entrenar una red profunda utilizando un conjunto de datos de millones de imágenes.
Así que el aprendizaje profundo en general.
1. Se requiere un potente servidor GPU para el cálculo.
2. Servicios de predicción y capacitación distribuidos totalmente administrados, como la plataforma de aprendizaje automático en la nube TensorFlow de Google.
3. Representante del algoritmo
Aprendizaje automático: Naive Bayes, árboles de decisión y más
3.1 Algoritmo bayesiano ingenuo
El algoritmo Naive Bayesian es un algoritmo de clasificación basado en el teorema bayesiano y la suposición de independencia de las condiciones de las características. El teorema de Bayes es una teoría de probabilidad que describe la probabilidad de que ocurra otro evento dadas ciertas condiciones.
El algoritmo Naive Bayesian asume que todas las funciones son independientes entre sí, es decir, cada variable de función no tiene nada que ver con otras variables de funciones. Basado en esta suposición, el algoritmo Naive Bayes puede predecir la categoría de etiqueta de nuevos datos al observar el conjunto de datos ya etiquetado.
Los algoritmos de Naive Bayes se usan comúnmente en aplicaciones como la clasificación de texto, el filtrado de correo no deseado y el análisis de sentimientos.
El siguiente es un código de muestra para implementar el modelo de algoritmo Naive Bayes usando Python:
import numpy as np
class NaiveBayes:
def __init__(self, n_classes):
self.n_classes = n_classes
self.priors = None
self.posteriors = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.priors = np.zeros(self.n_classes)
self.posteriors = np.zeros((self.n_classes, n_features))
for c in range(self.n_classes):
X_c = X[y == c]
self.priors[c] = len(X_c) / n_samples
self.posteriors[c] = (X_c.sum(axis=0) + 1) / (len(X_c) + 1)
def predict(self, X):
y_pred = []
for x in X:
posteriors = []
for c in range(self.n_classes):
prior = np.log(self.priors[c])
likelihood = np.sum(np.log(self.posteriors[c]) * x)
posterior = prior + likelihood
posteriors.append(posterior)
y_pred.append(np.argmax(posteriors))
return y_pred
Esta implementación utiliza el suavizado de Laplace para evitar problemas de probabilidad cero y convierte las probabilidades a forma logarítmica para evitar problemas de desbordamiento numérico. El método de ajuste se usa para entrenar el modelo Naive Bayesian, mientras que el método de predicción se usa para clasificar nuevas muestras.
3.2 Árbol de decisión
El árbol de decisión es un modelo de clasificación y regresión basado en la estructura de árbol, que a menudo se usa en el campo de la minería de datos y el aprendizaje automático. Divide recursivamente el conjunto de datos y selecciona características continuamente hasta que finalmente se obtiene un árbol de decisión recursivo.
El nodo del árbol de decisión representa una característica en el conjunto de datos, el borde representa el valor de esta característica y el nodo hoja representa el resultado de la clasificación o el resultado de la regresión.
En el problema de clasificación, el árbol de decisión divide una muestra desde el nodo raíz hasta un nodo hoja específico, y la categoría del nodo hoja es la categoría de la muestra;
En el problema de regresión, el árbol de decisión divide una muestra desde el nodo raíz hasta un nodo hoja específico, y el valor del nodo hoja es el valor predicho de la muestra.
El árbol de decisión tiene las ventajas de una buena interpretabilidad, fácil de entender y usar, y se usa ampliamente en aplicaciones prácticas.
4. Red neuronal
Una red neuronal es un programa informático que simula el funcionamiento del sistema nervioso del cerebro humano. Se compone de una gran cantidad de neuronas artificiales (neuronas biológicas simuladas) a través de un cierto método de conexión. A través del aprendizaje y el entrenamiento, puede identificar, clasificar, simular y predecir varias cosas. Tiene buena adaptabilidad y capacidades de mapeo no lineal. Es ampliamente utilizado en inteligencia artificial, reconocimiento de imágenes, procesamiento de lenguaje natural, reconocimiento de voz y otros campos.
Las redes neuronales incluyen redes neuronales feedforward, redes neuronales recurrentes y otras estructuras, entre las cuales las redes neuronales feedforward son las más comunes.
Código de muestra para red neuronal para implementar lógica y operación
La red neuronal realiza la lógica y el funcionamiento.
La operación lógica AND es una operación en la que el resultado es 1 cuando ambos números binarios son 1 y 0 en caso contrario.
Las redes neuronales pueden implementar la lógica y las operaciones aprendiendo el mapeo entre la entrada y la salida de la lógica y las operaciones.
El siguiente es un código de muestra para una red neuronal simple para implementar operaciones AND lógicas:
import numpy as np# 输入数据和标签
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [0], [0], [1]])
# definir la red neuronal
# 定义神经网络
class NeuralNetwork:
def __init__(self):
np.random.seed(1)
self.weights = 2 * np.random.random((2, 1)) - 1
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1 - x)
def train(self, x, y, iterations):
for i in range(iterations):
output = self.predict(x)
error = y - output
adjustment = np.dot(x.T, error * self.sigmoid_derivative(output))
self.weights += adjustment
def predict(self, x):
return self.sigmoid(np.dot(x, self.weights))
# entrenar la red neuronal
# 训练神经网络
neural_network = NeuralNetwork()
neural_network.train(x, y, 10000)
# predecir
# 预测
print(neural_network.predict(np.array([0, 0])))
print(neural_network.predict(np.array([0, 1])))
print(neural_network.predict(np.array([1, 0])))
print(neural_network.predict(np.array([1, 1])))La salida es:
[0.5]
[0.2689864]
[0.2689864]
[0.11738518]
Dado que la red neuronal es un modelo basado en la probabilidad, los resultados de salida no son completamente precisos,
Pero se puede ver que cuando la entrada es (0, 0), (0, 1) y (1, 0), la salida es cercana a 0,
Cuando la entrada es (1, 1), la salida está cerca de 1, lo que es consistente con el resultado de la operación lógica AND.
Lectura recomendada:








































|
|
|
|
| Tomcat11, configuración de instalación de tomcat10 (entorno Windows) (gráficos detallados) |
Conjunto de resolución de problemas de flashback de inicio de Tomcat (ocho categorías en detalle) |
|


