Resumen: En comparación con el aprendizaje Q, DQN es esencialmente para adaptarse a un entorno más complejo, y después de la mejora continua y la iteración, es básicamente perfecto cuando se trata de Nature DQN (es decir, el artículo de Nature publicado por Volodymyr Mnih).
Este artículo se comparte desde Huawei Cloud Community " Aprendizaje de refuerzo de básico a avanzado: caso y práctica [4.1]: Deep Q Network-DQN Project Combat CartPole-v0 ", autor: Ting.
1. Definir el algoritmo
En comparación con el aprendizaje Q, DQN es esencialmente para adaptarse a un entorno más complejo, y después de la mejora continua y la iteración, es básicamente perfecto cuando se trata de Nature DQN (es decir, el artículo de Nature publicado por Volodymyr Mnih). Hay tres cambios principales en DQN:
- Reemplace la tabla Q original con una red neuronal profunda: esto es fácil de entender por qué
- Uso de la reproducción de experiencia (Búfer de reproducción): esto tiene muchos beneficios. Uno es usar un montón de datos históricos para el entrenamiento, que es mucho mejor que tirarlos después de usarlos una vez antes, lo que mejora en gran medida la eficiencia de la muestra. El otro es a menudo mencionado en entrevistas, reduciendo muestras La correlación entre ellos, en principio, la adquisición de experiencia está separada de la fase de aprendizaje.Los datos de entrenamiento de la serie temporal original pueden ser inestables, y el aprendizaje después de la interrupción puede ayudar a mejorar la estabilidad del entrenamiento, que es similar a la división de entrenamiento y prueba en el aprendizaje profundo.Hay una razón para barajar las muestras durante la recolección.
- Se utilizan dos redes: la red de políticas y la red de destino. Los parámetros de la red de políticas actualizados en cada paso se copian en la red de destino cada pocos pasos. Esto también es para la estabilidad del entrenamiento y para evitar la divergencia del valor Q estimado. . Imagínese si actualmente hay una transición (mencionada en este aprendizaje de Q, ¡debe recordarlo!) Muestras que conducen a una sobreestimación deficiente del valor de Q, si las muestras extraídas de la reproducción de la experiencia son exactamente Si esto sucede varias veces en un fila, es muy probable que el valor de Q diverja (su ave juvenil nunca volverá). Para otro ejemplo, jugamos RPG o juegos de ruptura. Algunas personas a menudo guardan y cargan para romper el récord. Siempre que cometa un error y no esté satisfecho, cargaré el guardado anterior. Supongamos que no está permitido carga, al igual que el algoritmo DQN. Durante el proceso de entrenamiento, no podrá retirarse. En este momento, ¿tiene dos archivos, un archivo se guarda para cada cuadro y el otro archivo se guarda después de un buen resultado? es decir, varios intervalos se guardan de nuevo y, al final, el intervalo es de varios pasos. Los archivos guardados varias veces son generalmente mejores que los archivos guardados cada cuadro. Por supuesto, también puede crear más archivos, es decir, agregar múltiples redes de destino a DQN, pero no es necesario para DQN, y el efecto de más redes puede no ser mucho mejor.
1.1 Definir el modelo
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
!pip uninstall -y parl
!pip install parl
import parl
from parl.algorithms import DQN
class MLP(parl.Model):
""" Linear network to solve Cartpole problem.
Args:
input_dim (int): Dimension of observation space.
output_dim (int): Dimension of action space.
"""
def __init__(self, input_dim, output_dim):
super(MLP, self).__init__()
hidden_dim1 = 256
hidden_dim2 = 256
self.fc1 = nn.Linear(input_dim, hidden_dim1)
self.fc2 = nn.Linear(hidden_dim1, hidden_dim2)
self.fc3 = nn.Linear(hidden_dim2, output_dim)
def forward(self, state):
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x1.2 Definir la reproducción de la experiencia
from collections import deque
class ReplayBuffer:
def __init__(self, capacity: int) -> None:
self.capacity = capacity
self.buffer = deque(maxlen=self.capacity)
def push(self,transitions):
'''_summary_
Args:
trainsitions (tuple): _description_
'''
self.buffer.append(transitions)
def sample(self, batch_size: int, sequential: bool = False):
if batch_size > len(self.buffer):
batch_size = len(self.buffer)
if sequential: # sequential sampling
rand = random.randint(0, len(self.buffer) - batch_size)
batch = [self.buffer[i] for i in range(rand, rand + batch_size)]
return zip(*batch)
else:
batch = random.sample(self.buffer, batch_size)
return zip(*batch)
def clear(self):
self.buffer.clear()
def __len__(self):
return len(self.buffer)1.3 Definir el agente
from random import random
import parl
import paddle
import math
import numpy as np
class DQNAgent(parl.Agent):
"""Agent of DQN.
"""
def __init__(self, algorithm, memory,cfg):
super(DQNAgent, self).__init__(algorithm)
self.n_actions = cfg['n_actions']
self.epsilon = cfg['epsilon_start']
self.sample_count = 0
self.epsilon_start = cfg['epsilon_start']
self.epsilon_end = cfg['epsilon_end']
self.epsilon_decay = cfg['epsilon_decay']
self.batch_size = cfg['batch_size']
self.global_step = 0
self.update_target_steps = 600
self.memory = memory # replay buffer
def sample_action(self, state):
self.sample_count += 1
# epsilon must decay(linear,exponential and etc.) for balancing exploration and exploitation
self.epsilon = self.epsilon_end + (self.epsilon_start - self.epsilon_end) * \
math.exp(-1. * self.sample_count / self.epsilon_decay)
if random.random() < self.epsilon:
action = np.random.randint(self.n_actions)
else:
action = self.predict_action(state)
return action
def predict_action(self, state):
state = paddle.to_tensor(state , dtype='float32')
q_values = self.alg.predict(state) # self.alg 是自带的算法
action = q_values.argmax().numpy()[0]
return action
def update(self):
"""Update model with an episode data
Args:
obs(np.float32): shape of (batch_size, obs_dim)
act(np.int32): shape of (batch_size)
reward(np.float32): shape of (batch_size)
next_obs(np.float32): shape of (batch_size, obs_dim)
terminal(np.float32): shape of (batch_size)
Returns:
loss(float)
"""
if len(self.memory) < self.batch_size: # when transitions in memory donot meet a batch, not update
return
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
self.global_step += 1
state_batch, action_batch, reward_batch, next_state_batch, done_batch = self.memory.sample(
self.batch_size)
action_batch = np.expand_dims(action_batch, axis=-1)
reward_batch = np.expand_dims(reward_batch, axis=-1)
done_batch = np.expand_dims(done_batch, axis=-1)
state_batch = paddle.to_tensor(state_batch, dtype='float32')
action_batch = paddle.to_tensor(action_batch, dtype='int32')
reward_batch = paddle.to_tensor(reward_batch, dtype='float32')
next_state_batch = paddle.to_tensor(next_state_batch, dtype='float32')
done_batch = paddle.to_tensor(done_batch, dtype='float32')
loss = self.alg.learn(state_batch, action_batch, reward_batch, next_state_batch, done_batch) 2. Definir entrenamiento
def train(cfg, env, agent):
''' 训练
'''
print(f"开始训练!")
print(f"环境:{cfg['env_name']},算法:{cfg['algo_name']},设备:{cfg['device']}")
rewards = [] # record rewards for all episodes
steps = []
for i_ep in range(cfg["train_eps"]):
ep_reward = 0 # reward per episode
ep_step = 0
state = env.reset() # reset and obtain initial state
for _ in range(cfg['ep_max_steps']):
ep_step += 1
action = agent.sample_action(state) # sample action
next_state, reward, done, _ = env.step(action) # update env and return transitions
agent.memory.push((state, action, reward,next_state, done)) # save transitions
state = next_state # update next state for env
agent.update() # update agent
ep_reward += reward #
if done:
break
steps.append(ep_step)
rewards.append(ep_reward)
if (i_ep + 1) % 10 == 0:
print(f"回合:{i_ep+1}/{cfg['train_eps']},奖励:{ep_reward:.2f},Epislon: {agent.epsilon:.3f}")
print("完成训练!")
env.close()
res_dic = {'episodes':range(len(rewards)),'rewards':rewards,'steps':steps}
return res_dic
def test(cfg, env, agent):
print("开始测试!")
print(f"环境:{cfg['env_name']},算法:{cfg['algo_name']},设备:{cfg['device']}")
rewards = [] # record rewards for all episodes
steps = []
for i_ep in range(cfg['test_eps']):
ep_reward = 0 # reward per episode
ep_step = 0
state = env.reset() # reset and obtain initial state
for _ in range(cfg['ep_max_steps']):
ep_step+=1
action = agent.predict_action(state) # predict action
next_state, reward, done, _ = env.step(action)
state = next_state
ep_reward += reward
if done:
break
steps.append(ep_step)
rewards.append(ep_reward)
print(f"回合:{i_ep+1}/{cfg['test_eps']},奖励:{ep_reward:.2f}")
print("完成测试!")
env.close()
return {'episodes':range(len(rewards)),'rewards':rewards,'steps':steps}3. Definir el entorno
De hecho, OpenAI Gym integra una gran cantidad de entornos de aprendizaje por refuerzo, que son suficientes para que todos aprendan, pero es inevitable crear el entorno usted mismo en la aplicación del aprendizaje por refuerzo. Por ejemplo, en este proyecto, no es fácil encontrar el entorno en el que Qlearning puede aprender. Qlearning es realmente demasiado débil y necesita un entorno lo suficientemente simple. Por lo tanto, este proyecto ha escrito un entorno. Si está interesado, puede echar un vistazo. Las partes más críticas del entorno general La interfaz se reinicia y se paso.
import gym
import paddle
import numpy as np
import random
import os
from parl.algorithms import DQN
def all_seed(env,seed = 1):
''' omnipotent seed for RL, attention the position of seed function, you'd better put it just following the env create function
Args:
env (_type_):
seed (int, optional): _description_. Defaults to 1.
'''
print(f"seed = {seed}")
env.seed(seed) # env config
np.random.seed(seed)
random.seed(seed)
paddle.seed(seed)
def env_agent_config(cfg):
''' create env and agent
'''
env = gym.make(cfg['env_name'])
if cfg['seed'] !=0: # set random seed
all_seed(env,seed=cfg["seed"])
n_states = env.observation_space.shape[0] # print(hasattr(env.observation_space, 'n'))
n_actions = env.action_space.n # action dimension
print(f"n_states: {n_states}, n_actions: {n_actions}")
cfg.update({"n_states":n_states,"n_actions":n_actions}) # update to cfg paramters
model = MLP(n_states,n_actions)
algo = DQN(model, gamma=cfg['gamma'], lr=cfg['lr'])
memory = ReplayBuffer(cfg["memory_capacity"]) # replay buffer
agent = DQNAgent(algo,memory,cfg) # create agent
return env, agent4. Configuración de parámetros
Incluso si todos los módulos de qlearning se completan aquí, es necesario establecer algunos parámetros a continuación para facilitar la "alquimia" de todos. El valor predeterminado es que el autor lo haya ajustado ~. Además, se define una función de dibujo para describir el cambio de la recompensa.
import argparse
import seaborn as sns
import matplotlib.pyplot as plt
def get_args():
"""
"""
parser = argparse.ArgumentParser(description="hyperparameters")
parser.add_argument('--algo_name',default='DQN',type=str,help="name of algorithm")
parser.add_argument('--env_name',default='CartPole-v0',type=str,help="name of environment")
parser.add_argument('--train_eps',default=200,type=int,help="episodes of training") # 训练的回合数
parser.add_argument('--test_eps',default=20,type=int,help="episodes of testing") # 测试的回合数
parser.add_argument('--ep_max_steps',default = 100000,type=int,help="steps per episode, much larger value can simulate infinite steps")
parser.add_argument('--gamma',default=0.99,type=float,help="discounted factor") # 折扣因子
parser.add_argument('--epsilon_start',default=0.95,type=float,help="initial value of epsilon") # e-greedy策略中初始epsilon
parser.add_argument('--epsilon_end',default=0.01,type=float,help="final value of epsilon") # e-greedy策略中的终止epsilon
parser.add_argument('--epsilon_decay',default=200,type=int,help="decay rate of epsilon") # e-greedy策略中epsilon的衰减率
parser.add_argument('--memory_capacity',default=200000,type=int) # replay memory的容量
parser.add_argument('--memory_warmup_size',default=200,type=int) # replay memory的预热容量
parser.add_argument('--batch_size',default=64,type=int,help="batch size of training") # 训练时每次使用的样本数
parser.add_argument('--targe_update_fre',default=200,type=int,help="frequency of target network update") # target network更新频率
parser.add_argument('--seed',default=10,type=int,help="seed")
parser.add_argument('--lr',default=0.0001,type=float,help="learning rate")
parser.add_argument('--device',default='cpu',type=str,help="cpu or gpu")
args = parser.parse_args([])
args = {**vars(args)} # type(dict)
return args
def smooth(data, weight=0.9):
'''用于平滑曲线,类似于Tensorboard中的smooth
Args:
data (List):输入数据
weight (Float): 平滑权重,处于0-1之间,数值越高说明越平滑,一般取0.9
Returns:
smoothed (List): 平滑后的数据
'''
last = data[0] # First value in the plot (first timestep)
smoothed = list()
for point in data:
smoothed_val = last * weight + (1 - weight) * point # 计算平滑值
smoothed.append(smoothed_val)
last = smoothed_val
return smoothed
def plot_rewards(rewards,cfg,path=None,tag='train'):
sns.set()
plt.figure() # 创建一个图形实例,方便同时多画几个图
plt.title(f"{tag}ing curve on {cfg['device']} of {cfg['algo_name']} for {cfg['env_name']}")
plt.xlabel('epsiodes')
plt.plot(rewards, label='rewards')
plt.plot(smooth(rewards), label='smoothed')
plt.legend()5. Entrenamiento
# 获取参数
cfg = get_args()
# 训练
env, agent = env_agent_config(cfg)
res_dic = train(cfg, env, agent)
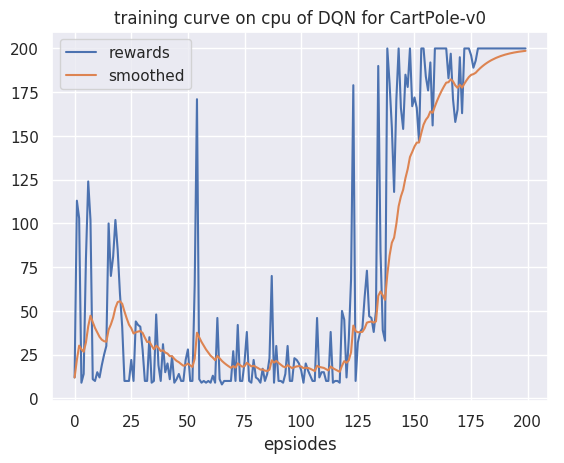
plot_rewards(res_dic['rewards'], cfg, tag="train")
# 测试
res_dic = test(cfg, env, agent)
plot_rewards(res_dic['rewards'], cfg, tag="test") # 画出结果seed = 10
n_states: 4, n_actions: 2
开始训练!
环境:CartPole-v0,算法:DQN,设备:cpu
回合:10/200,奖励:10.00,Epislon: 0.062
回合:20/200,奖励:85.00,Epislon: 0.014
回合:30/200,奖励:41.00,Epislon: 0.011
回合:40/200,奖励:31.00,Epislon: 0.010
回合:50/200,奖励:22.00,Epislon: 0.010
回合:60/200,奖励:10.00,Epislon: 0.010
回合:70/200,奖励:10.00,Epislon: 0.010
回合:80/200,奖励:22.00,Epislon: 0.010
回合:90/200,奖励:30.00,Epislon: 0.010
回合:100/200,奖励:20.00,Epislon: 0.010
回合:110/200,奖励:15.00,Epislon: 0.010
回合:120/200,奖励:45.00,Epislon: 0.010
回合:130/200,奖励:73.00,Epislon: 0.010
回合:140/200,奖励:180.00,Epislon: 0.010
回合:150/200,奖励:167.00,Epislon: 0.010
回合:160/200,奖励:200.00,Epislon: 0.010
回合:170/200,奖励:165.00,Epislon: 0.010
回合:180/200,奖励:200.00,Epislon: 0.010
回合:190/200,奖励:200.00,Epislon: 0.010
Haga clic para seguir y conocer las nuevas tecnologías de Huawei Cloud por primera vez~