Tabla de contenido
- La función de incremento automático de Redis resuelve la ID única global
- La idea principal de Redis es implementar la venta flash de cupones.
- Problemas que surgen durante la implementación y sus soluciones.
La función de incremento automático de Redis resuelve la ID única global
- Si utiliza la ID de aumento automático de MySQL, la regularidad de la ID es demasiado obvia.Se filtrará alguna información.(Como volumen de ventas, etc.)
- Cuando la cantidad de datos es demasiado grande, no se pueden almacenar en una tabla y se necesitan varias tablas. El crecimiento propio de varias tablas MySQL es independiente.Aparecerán identificaciones duplicadas
- Necesitamos una herramienta que pueda generar una identificación global única en un sistema distribuido. Debe ser única e incremental.
- En un determinado proyecto, no importa cuántas tablas haya en la base de datos, solo hay un Redis, por lo que la ID generada por la función incremental de Redis debe ser globalmente única.
- Para garantizar que el incremento sea simultáneo e irregular, y para garantizar la seguridad, puedeEmpalmar alguna otra información basada en el valor de incremento automático de Redis

La idea principal de Redis es implementar la venta flash de cupones.
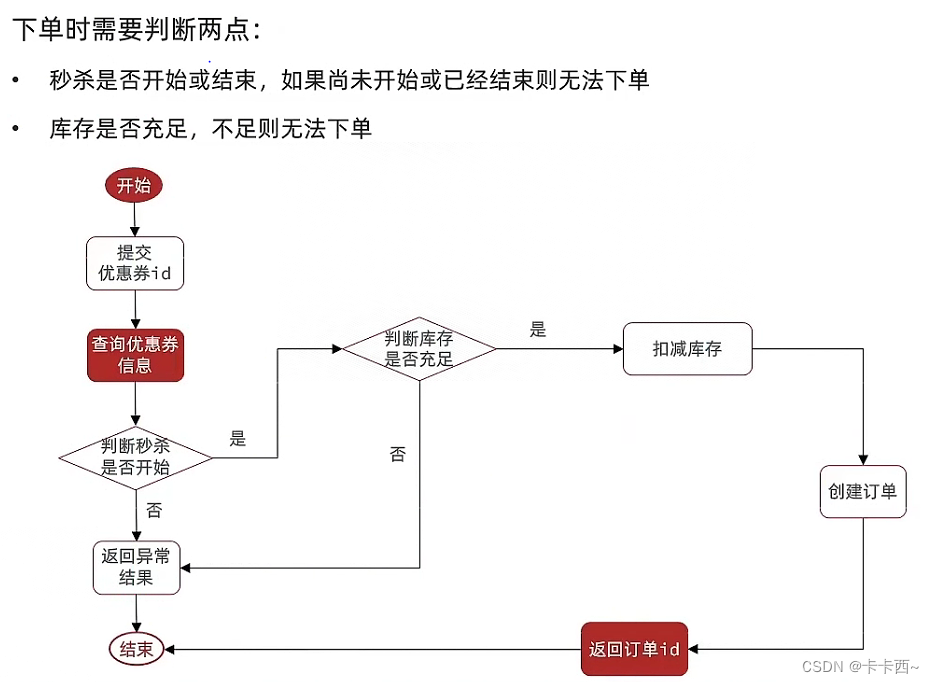
Problemas que surgen durante la implementación y sus soluciones.
problema de sobreventa
- En escenarios de alta concurrencia, varios subprocesos operan recursos compartidos (inventario) al mismo tiempo, lo que hace que la cantidad real vendida supere la cantidad del inventario.
Opción 1 bloqueo pesimista
- La actitud es relativamente pesimista, piensa que definitivamente ocurrirán problemas de seguridad de subprocesos y adquiere bloqueos con anticipación antes de operar los datos.
- Ejemplo: sincronizado, bloqueado
- ventaja: Alta seguridad
- defecto: Bajo rendimiento, implementación simple
Opción 2 Bloqueo optimista
- La actitud es relativamente optimista y creo que es posible que no ocurran problemas de seguridad de subprocesos, por lo que no lo bloqueo y solo lo bloqueo cuando se actualizan los datos.juicio¿Algún otro hilo modificó los datos anteriores? Si no se ha modificado, se considera seguro. Actualice los datos directamente. Si se ha modificado, no es seguro. Reintente o informe una excepción.
- método del número de versión: Agregue un campo de versión al inventario. El subproceso 1 consulta y registra el inventario y el número de versión, y luego establece el inventario -1 y el número de versión +1 para indicar que el subproceso 1 ha modificado los datos una vez y luego determina el número de versión antes. actualizando los datos. ¿Es el número de versión + 1 registrado en ese momento? Si es así, significa que ningún hilo concurrente ha modificado los datos durante el período. Es seguro y puede actualizar con confianza. Si no, significa que hay Resultó ser un subproceso simultáneo que modificó los datos durante el período. No es seguro. Inténtelo de nuevo o informe de excepción.
- Ley CAS: Una versión simplificada del método del número de versión, que elimina el campo redundante del número de versión, reemplaza directamente el número de versión con el inventario en sí y determina si se debe actualizar en función de si el inventario en sí ha cambiado.
- ventaja: Alto rendimiento
- defecto: La implementación es complicada
Una pregunta por persona
- Problema comercial común: un usuario solo puede realizar un pedido con el mismo cupón
- Una vez que el juicio de adecuación del inventario es exitoso, se agrega otro juicio y se consultan conjuntamente la ID del usuario y la ID del cupón para determinar si el usuario ha comprado un cupón.
- En modo autónomo, puede agregar un bloqueo sincronizado para garantizar la seguridad del hilo
- En modo clústerLos bloqueos sincronizados no son válidos y es necesario utilizar bloqueos distribuidos para garantizar la seguridad de los subprocesos. La razón por la cual los bloqueos sincronizados no son válidos es porque cada servidor tiene su propio grupo constante y el monitor de bloqueo se almacena en el grupo constante. Cuando los usuarios intentan obtener el bloqueo, acceden al monitor de bloqueo. Por lo tanto, el problema principal se debe a Los monitores de bloqueo de varios servidores son independientes, por lo que los usuarios de varios servidores pueden adquirir bloqueos al mismo tiempo, lo que provoca problemas de seguridad de subprocesos.
Cerradura distribuida
- En una situación independiente, solo hay una JVM, solo hay un monitor de bloqueo en la JVM y solo un programa puede adquirir el bloqueo. Pero en el caso de un clúster, hay múltiples JVM y múltiples monitores de bloqueo en múltiples JVM. El programa puede adquirir múltiples bloqueos, e incluso el mismo programa puede adquirir múltiples bloqueos, lo que generará problemas de seguridad de subprocesos.
- Necesita hacer uno fuera de múltiples JVMMonitor de bloqueo compartido, visible para múltiples procesos y mutuamente excluyente: bloqueo distribuido
- Hay tres formas principales de implementar bloqueos distribuidos: MySQL, Redis y Zookeeper. MySQL y Zookeeper son más seguros que Redis y Redis tiene mejor rendimiento que ambos.
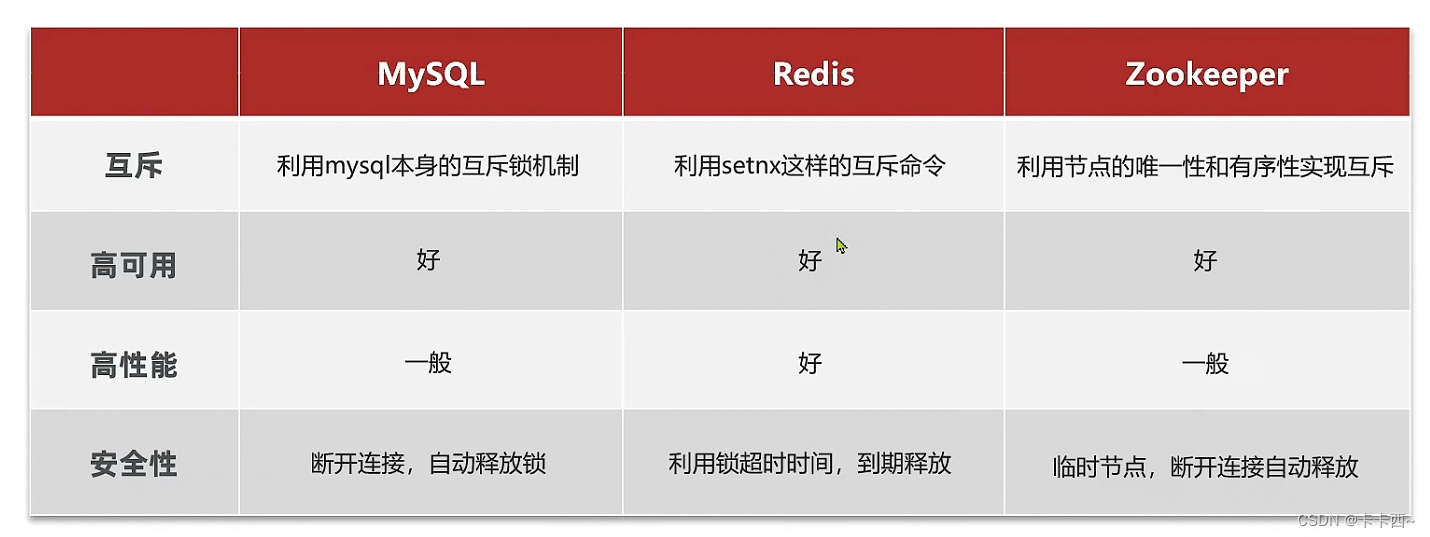
¿Cómo implementar bloqueos distribuidos con Redis?
- Obtener bloqueo mutex: SET lock thread1 NX EX 10, NX es mutuamente excluyente, lo que garantiza que solo un subproceso pueda obtener el bloqueo, EX es para establecer el tiempo de espera.
- desbloquear bloqueo: Eliminar directamente manualmente.
- problema de punto muerto: Si el hilo se cae después de adquirir el bloqueo, es probable que se produzca un punto muerto. Se debe aumentar el tiempo de vencimiento y el bloqueo se liberará automáticamente después del tiempo de espera.
- Problema de eliminación accidental: Si el subproceso 1 adquiere el bloqueo, pero el tiempo de ejecución del negocio es demasiado largo y excede el TTL, el bloqueo se liberará automáticamente. En este momento, el subproceso 2 intenta adquirir el bloqueo con éxito y ejecuta el negocio normalmente. Sin embargo, durante el Durante el período, el subproceso 1 completa la ejecución comercial y libera el bloqueo normalmente, en este momento el bloqueo del subproceso 2 se eliminará por error. Para evitar esta situación, se debe agregar una identificación al adquirir el candado para indicar quién ocupa el candado y solo él está calificado para desbloquearlo, por lo que es necesario agregar un paso de juicio antes de liberar el candado.
- Problemas con bloqueos distribuidos implementados basados en setnx: Sin reentrada (el mismo subproceso no puede adquirir el mismo bloqueo varias veces), sin reintento (solo intente adquirir el bloqueo una vez, no reintente si falla), liberación de tiempo de espera (un tiempo de ejecución comercial prolongado hará que se libere el bloqueo, hay peligro oculto de seguridad)
- Componente de redistribución: Una colección de herramientas distribuidas implementadas basadas en Redis.
Venta flash de optimización de Redis
- La idea principal de la optimización: utilizar operaciones que requieren mucho tiempo, como la reducción de inventario y la creación de pedidos, que involucran la base de datos.asincrónicoLos subprocesos independientes lo hacen lentamente: Redis solo necesita determinar si el usuario lo captó con éxito y devolver el resultado.
- El proceso de venta flash original: principalmente una serie de operaciones en Tomcat, cuatro de las cuales operan directamente la base de datos, lo que lleva mucho tiempo. Es equivalente a un restaurante. Cuando llega un cliente, se asigna un camarero para brindarle un servicio integral. Desde realizar pedidos (verificar las calificaciones de venta flash) hasta cocinar (reducir el inventario y crear pedidos), este camarero es muy eficiente. bajo.
- Proceso de venta flash optimizado: agregue Redis a NGINX y Tomcat Home para determinar si el usuario puede obtener el cupón y guarde el resultado del juicio junto con la identificación del cupón, la identificación del usuario y la identificación del pedido en la cola de bloqueo, y luego Tomcat leerá los mensajes. de la cola y realizar operaciones que requieren mucho tiempo para reducir el inventario y crear pedidos.
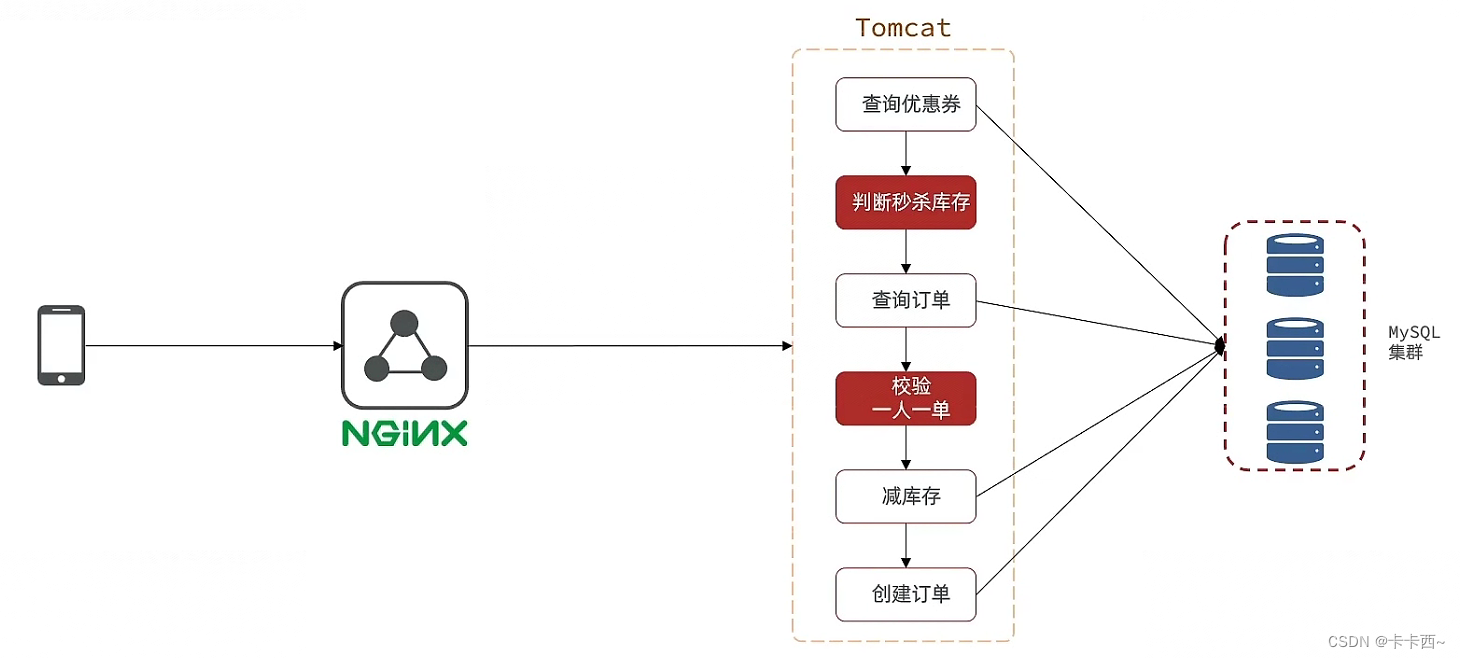
- La operación de Redis para determinar el inventario de venta flash se puede encapsular en un script Lua para su ejecución para garantizar la atomicidad de la operación.
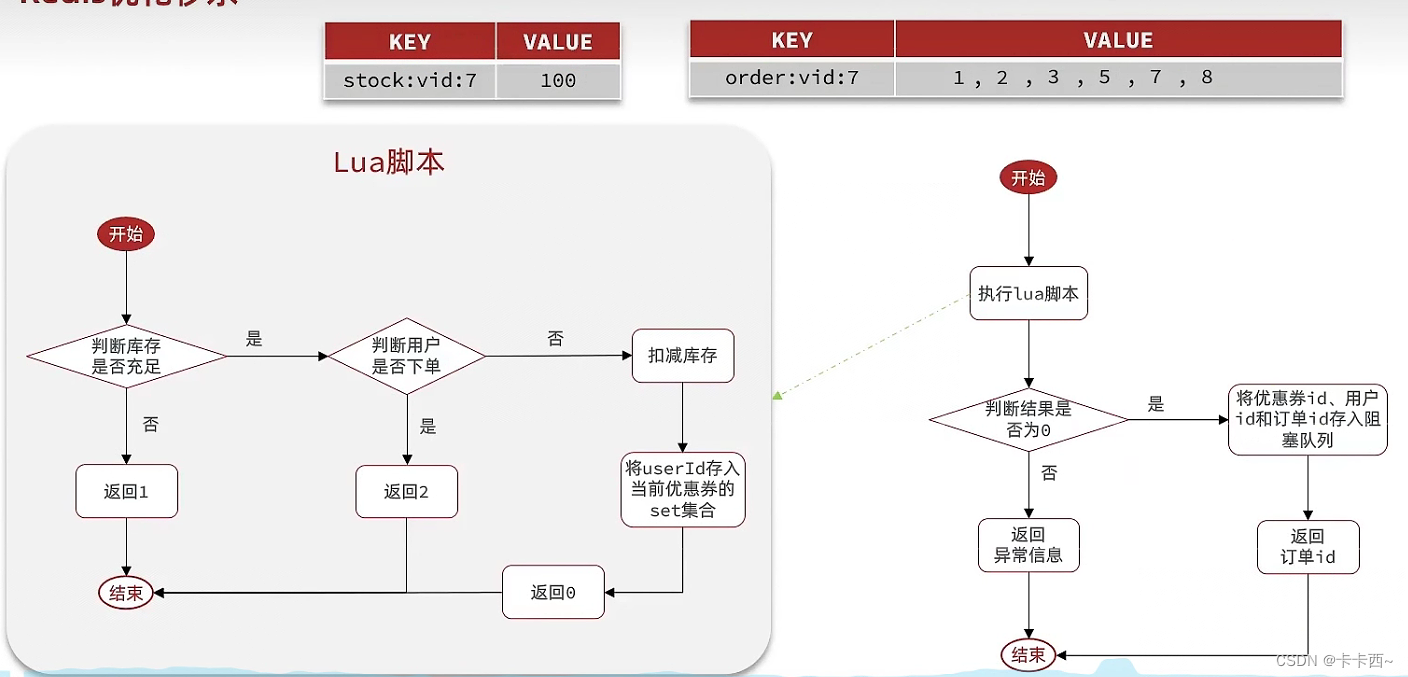
- ¿Cuáles son los problemas con las ventas flash asíncronas basadas en colas de bloqueo?
- Cuando se utiliza la cola de bloqueo en JDK, ocupará la memoria JVM y una gran cantidad de mensajes provocará un desbordamiento de la memoria.
La cola de mensajes implementa la eliminación de flash asíncrona
- Cola de mensajes: almacena y gestiona mensajes.
- Productor: envía mensajes a la cola de mensajes.
- Consumidor: obtiene mensajes de la cola de mensajes y los procesa.
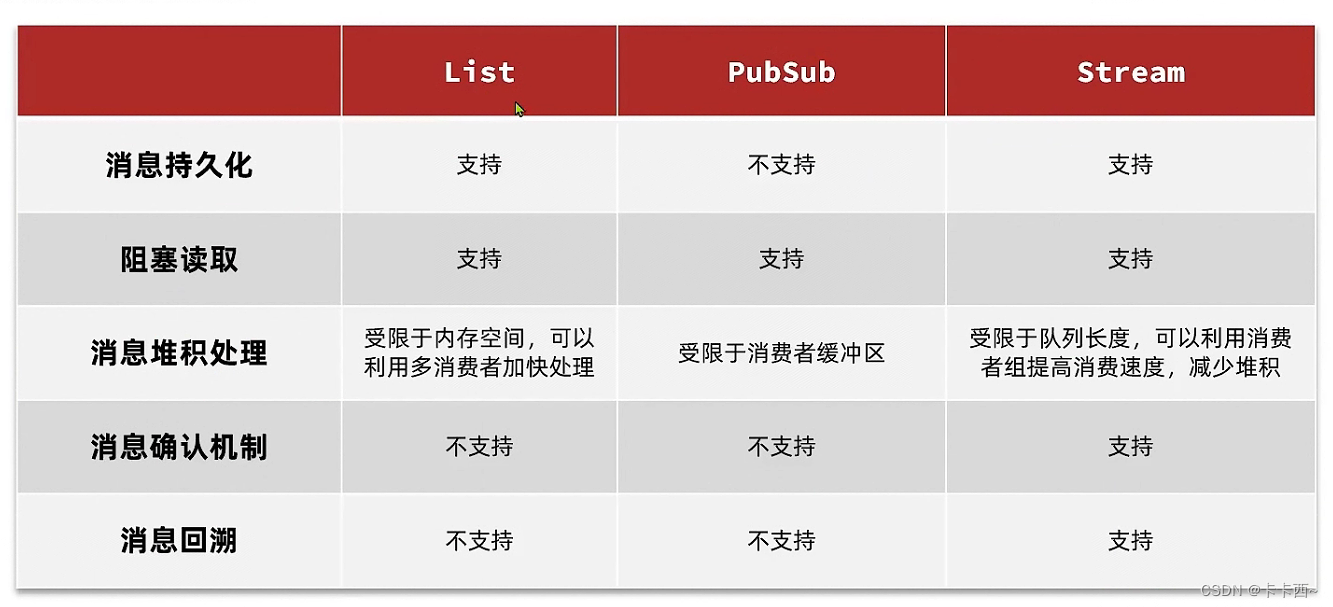
- Redis implementa colas de mensajes de tres maneras: lista, modo de publicación-suscripción y transmisión
Lista
- La cola encadenada de dos extremos usa LPUSH para almacenar y RPOP para recuperar, pero no tiene ningún efecto de bloqueo (no bloqueará la espera cuando la cola esté vacía) y BRPOP tiene un efecto de bloqueo.
- ventaja: Existe independientemente de la JVM, no ocupa memoria de la JVM, no se preocupa por el límite superior, puede persistir y también puede garantizar el orden de los mensajes.
- defecto: No se puede evitar la pérdida de mensajes, solo admite uno a uno
modelo de publicación-suscripción
- Los consumidores se suscriben a uno o más canales y los productores envían mensajes a los canales correspondientes.
- ventaja: Admite uno a muchos, un productor puede enviar mensajes a varios consumidores. Naturalmente apoya el bloqueo
- defecto: No se admite la persistencia de datos, no se puede evitar la pérdida de mensajes y existe un límite superior para la acumulación de mensajes.
Arroyo
- ventaja: Los mensajes se pueden rastrear, admiten uno a muchos, admiten bloqueo de lectura
- defecto: Es posible que se pierdan mensajes
- grupo de consumidores: Divida a varios consumidores en un grupo y escuche la misma cola de mensajes, luego varios consumidores competirán por estos mensajes, lo que puede acelerar el procesamiento de mensajes y evitar la acumulación de mensajes. El grupo de consumidores también mantendrá un identificador para registrar el último mensaje procesado, que puede recuperarse rápidamente de emergencias y evitar mensajes perdidos. Además, después de que el consumidor recibe el mensaje, Redis no lo ignorará directamente, sino que lo pondrá en estado pendiente, lo que indica que el mensaje se ha obtenido pero no se ha procesado. Después del procesamiento, Redis confirmará el mensaje con XACK y márquelo. Una vez que el mensaje haya sido procesado, Redis eliminará de forma segura el mensaje de la cola para evitar su pérdida.
- Ventajas del grupo de consumidores: Los mensajes se pueden rastrear, lo que permite que varios consumidores compitan por los mensajes, acelera el consumo, bloquea la lectura y no pierde mensajes.Existe un mecanismo de confirmación de mensajes para garantizar que los mensajes se consuman al menos una vez.
Resumen comparativo de tres colas de mensajes