Explicación: Este es un proyecto práctico de aprendizaje automático (con datos + código + documentación + explicación en video ). Si necesita datos + código + documentación + explicación en video, puede ir directamente al final del artículo para obtenerlo.


1. Antecedentes del proyecto
El algoritmo de búsqueda de gorriones (SSA) es un nuevo tipo de algoritmo de optimización de inteligencia de enjambre, que se propuso en 2020 y se inspira principalmente en el comportamiento de búsqueda de alimento y el comportamiento antidepredación de los gorriones.
En el proceso de búsqueda de alimento, el gorrión se divide en descubridores (exploradores) y seguidores (seguidores). Los buscadores vienen a buscar comida. Para obtener alimento, los gorriones generalmente pueden adoptar dos estrategias de comportamiento: buscar y unirse para buscar alimento. Los individuos de la población monitorean el comportamiento de otros individuos de la población, y los atacantes de la población compiten por los recursos alimentarios con sus pares de alto consumo para aumentar su tasa de depredación. Además, las poblaciones de gorriones adoptan comportamientos antidepredatorios cuando perciben peligro.
Este proyecto optimiza el modelo de regresión de la red neuronal convolucional mediante el algoritmo de búsqueda inteligente de gorriones SSA.
2. Adquisición de datos
Los datos de modelado para este momento provienen de Internet (compilados por el autor de este proyecto) y las estadísticas de los elementos de datos son las siguientes:

Los detalles de los datos son los siguientes (visualización parcial):

3. Preprocesamiento de datos
3.1 Ver datos con las herramientas de Pandas
Utilice el método head() de la herramienta Pandas para ver las primeras cinco filas de datos:

clave:

3.2 Verificar datos faltantes
Utilice el método info() de la herramienta Pandas para ver información de datos:

Como se puede ver en la figura anterior, hay un total de 11 variables, no faltan valores en los datos y un total de 2000 datos.
clave:

3.3 Estadísticas descriptivas de datos
Utilice el método describe() de la herramienta Pandas para ver la media, la desviación estándar, el mínimo, el cuantil y el máximo de los datos.

El código clave es el siguiente:

4. Análisis de datos exploratorios
4.1 Histograma de y variables
Utilice el método hist() de la herramienta Matplotlib para dibujar un histograma:

Como puede verse en la figura anterior, la variable y se concentra principalmente entre -400 y 400.
4.2 Análisis de correlación

Como se puede ver en la figura anterior, cuanto mayor es el valor, más fuerte es la correlación: un valor positivo es una correlación positiva y un valor negativo es una correlación negativa.
5. Ingeniería de funciones
5.1 Establecer datos de características y datos de etiquetas
El código clave es el siguiente:

5.2 División del conjunto de datos
Utilice el método train_test_split() para dividir según el 80% del conjunto de entrenamiento y el 20% del conjunto de prueba. El código clave es el siguiente:

5.3 Aumento de la dimensión de la muestra de datos
La forma de los datos de la muestra de datos después de agregar dimensiones:

6. Construya el algoritmo de búsqueda de gorriones inteligente SSA para optimizar el modelo de regresión CNN
Utilice principalmente el algoritmo de búsqueda inteligente de gorriones SSA para optimizar el algoritmo de regresión CNN para la regresión objetivo.
6.1 Algoritmo de búsqueda inteligente de gorriones SSA para encontrar el valor de parámetro óptimo
Parámetros óptimos:

6.2 Modelo de construcción de valor de parámetro óptimo

6.3 Información resumida del modelo de parámetros óptimos

6.4 Estructura de red del modelo de parámetros óptimo

6.5 Curva de pérdida del conjunto de prueba del conjunto de entrenamiento del modelo de parámetros óptimos

7. Evaluación del modelo
7.1 Indicadores y resultados de la evaluación
Los indicadores de evaluación incluyen principalmente el valor de la varianza explicable, el error absoluto medio, el error cuadrático medio, el valor R cuadrado, etc.

Se puede ver en la tabla anterior que el R cuadrado es 0,9349, que es un buen modelo.
El código clave es el siguiente:

7.2 Cuadro comparativo del valor real y el valor previsto
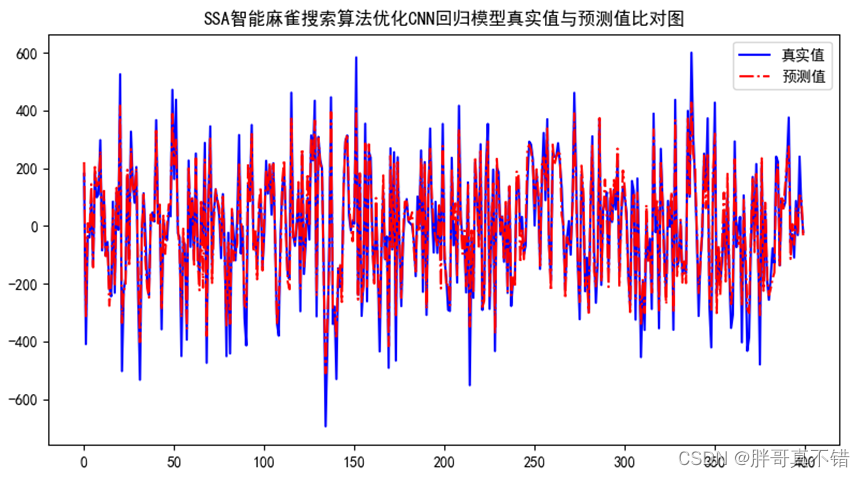
Como se puede ver en la figura anterior, las fluctuaciones del valor real y el valor predicho son básicamente las mismas y el efecto de ajuste del modelo es bueno.
8. Conclusión y perspectivas
En resumen, este artículo utiliza el algoritmo de búsqueda inteligente de gorriones SSA para encontrar los valores de parámetros óptimos del algoritmo de red neuronal convolucional (CNN) para construir un modelo de regresión y finalmente demuestra que el modelo que propusimos funciona bien. Este modelo se puede utilizar para pronosticar productos cotidianos.
# 定义边界函数
def Bounds(s, Lb, Ub):
temp = s
for i in range(len(s)):
if temp[i] < Lb[0, i]: # 小于最小值
temp[i] = Lb[0, i] # 取最小值
elif temp[i] > Ub[0, i]: # 大于最大值
temp[i] = Ub[0, i] # 取最大值
# ******************************************************************************
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
# 提取码:thgk
# ******************************************************************************
# y变量分布直方图
fig = plt.figure(figsize=(8, 5)) # 设置画布大小
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
data_tmp = data['y'] # 过滤出y变量的样本
# 绘制直方图 bins:控制直方图中的区间个数 auto为自动填充个数 color:指定柱子的填充色
plt.hist(data_tmp, bins='auto', color='g')Para obtener más práctica de proyectos, consulte la lista de colecciones de prácticas de proyectos de aprendizaje automático:
Lista de colecciones de combate reales de proyectos de aprendizaje automático
Para consultar y adquirir el código del proyecto, consulte la cuenta oficial a continuación.