1. Teoría de la decisión bayesiana
La teoría de decisión bayesiana es el método básico para implementar la toma de decisiones en el marco de la probabilidad. Para las tareas de clasificación, en una situación ideal en la que se conocen todas las probabilidades relevantes, la teoría de decisión bayesiana considera cómo elegir la etiqueta de clase óptima en función de estas probabilidades y las pérdidas por juicio erróneo.
fórmula bayesiana:

Entre ellos, P(c) es la probabilidad "previa" de la clase; P(x|c) es la probabilidad condicional de clase de la muestra x relativa a la etiqueta de clase c, o denominada "verosimilitud" (likelihood); P( x) se utiliza en el factor de "evidencia" normalizado. Para una muestra x dada, el factor de evidencia P(x) no tiene nada que ver con la etiqueta de clase, por lo que el problema de estimar P(c|x) se transforma en cómo estimar el P(c) previo y la probabilidad P(x |c).
La probabilidad previa de clase P(c) expresa la proporción de varios tipos de muestras en el espacio muestral De acuerdo con la ley de los grandes números, cuando el conjunto de entrenamiento contiene suficientes muestras independientes e idénticamente distribuidas, P(c) puede pasar la frecuencia de ocurrencia de varios tipos de muestras a estimar.
Para la probabilidad condicional de clase P(x|c) , dado que involucra la probabilidad conjunta de todos los atributos de x, estimarla directamente a partir de la frecuencia de muestras encontrará serias dificultades. Debido a que en aplicaciones prácticas, muchos valores de muestra no aparecen en absoluto en el conjunto de entrenamiento, obviamente no es factible estimar directamente P(x|c) por frecuencia, y la estimación de máxima verosimilitud puede usarse para resolver el problema. problema.
2. Clasificador bayesiano ingenuo
No es difícil encontrar que la principal dificultad para estimar la probabilidad posterior P(c|x) basada en la fórmula bayesiana es que la probabilidad condicional de clase P(x|c) es la probabilidad conjunta de todos los atributos, lo cual es difícil de calcular. estimar directamente a partir de muestras de formación limitadas Y obtener. (La estimación de la probabilidad conjunta directamente basada en muestras de entrenamiento limitadas encontrará el problema de explosión combinatoria en el cálculo y el problema de muestra escasa en los datos; cuantos más atributos, más grave es el problema) Para evitar este obstáculo, la clasificación bayesiana ingenua La ingenua El clasificador de Bayes adopta el "supuesto de independencia condicional de los atributos": para las categorías conocidas, se supone que todos los atributos son independientes entre sí. En otras palabras, se supone que cada atributo afecta el resultado de la clasificación de forma independiente.
Basándose en el supuesto de la independencia condicional de los atributos, la fórmula bayesiana se puede reescribir como:
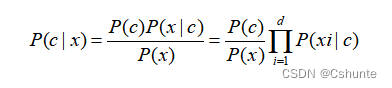
Donde d es el número de atributos y xi es el valor de x en el i-ésimo atributo.
Dado que P(x) es el mismo para todas las categorías, el criterio de decisión bayesiano es:

Esta es la expresión del clasificador Naive Bayes.
Obviamente, el proceso de entrenamiento del clasificador bayesiano ingenuo consiste en estimar la probabilidad previa de clase P(c) en función del conjunto de entrenamiento D y estimar la probabilidad condicional P(xi|c) para cada atributo.
Sea Dc el conjunto de muestras de clase c-ésima del conjunto de entrenamiento D. Si hay suficientes muestras independientes e idénticamente distribuidas, la probabilidad previa de la clase se puede estimar fácilmente:

Para atributos discretos, sea Dc,xi el conjunto de muestras Dc cuyo valor es xi en el atributo i, entonces la probabilidad condicional P(xi|c) se puede estimar como:

Para atributos continuos, se puede considerar la función de densidad de probabilidad, asumiendo p(xi|c)~N(μc,i,σc,i²), donde μc,i y σc,i² son los valores de la c-ésima muestra en la i-ésima media del atributo y la varianza de . Luego están:

Cabe señalar que si un determinado valor de atributo no aparece en el conjunto de entrenamiento al mismo tiempo que una determinada clase, será problemático estimar directamente la probabilidad en función de la probabilidad condicional P(xi|c), y luego juzgar según el criterio bayesiano. Por ejemplo, cuando cierto valor de atributo no aparece al mismo tiempo que cierta clase en el conjunto de entrenamiento, el valor de probabilidad calculado por la fórmula de multiplicación del criterio de decisión bayesiano es cero. Por tanto, sean cuales sean los otros atributos de la muestra, el resultado de la clasificación no se ve afectado. Esto obviamente no es razonable.
Para evitar que la información que llevan otros atributos sea "borrada" por valores de atributo que no aparecen en el conjunto de entrenamiento, se suele realizar un "suavizado" al estimar el valor de probabilidad, y se suele utilizar la corrección laplaciana. Específicamente, si N representa el número de categorías posibles en el conjunto de entrenamiento D, y Ni representa el número de valores posibles del i-ésimo atributo, entonces la probabilidad previa de clase y la probabilidad condicional se pueden modificar como:


Nota: La corrección de Laplace esencialmente asume una distribución uniforme de valores y categorías de atributos, lo cual es un dato previo adicional sobre los datos introducidos en el ingenuo proceso de aprendizaje bayesiano.
Obviamente, la corrección de Laplace evita el problema de la estimación de probabilidad cero debido a muestras de conjuntos de entrenamiento insuficientes. Y cuando el conjunto de entrenamiento se vuelve más grande, la influencia previa introducida por el proceso de corrección se volverá gradualmente insignificante, haciendo que la estimación tienda gradualmente al valor de probabilidad real.
Los clasificadores Naive Bayes se utilizan de muchas maneras en tareas del mundo real. Por ejemplo, si la tarea requiere una alta velocidad de predicción , para un conjunto de entrenamiento dado, todas las estimaciones de probabilidad involucradas en el clasificador Naive Bayesian se pueden calcular y almacenar con anticipación, de modo que solo se necesita una "tabla de búsqueda" al hacer predicciones. se puede discriminar; si los datos de la tarea cambian con frecuencia , puede usar el método de "aprendizaje perezoso", no realizar ningún entrenamiento primero y luego estimar la probabilidad en función del conjunto de datos actual cuando se recibe la solicitud de predicción; si los datos continúan para aumentar Entonces, sobre la base de la valoración existente, el aprendizaje incremental solo se puede realizar contando y corrigiendo la estimación de probabilidad involucrada en el valor del atributo de la muestra recién agregada.
3. Expansión - clasificador bayesiano semi-ingenuo
Para reducir la dificultad de estimar la probabilidad posterior P(c|x) en la fórmula bayesiana, el clasificador naive bayesiano adopta el supuesto de independencia condicional de atributos, pero este supuesto es a menudo difícil de establecer en tareas reales. Por lo tanto, las personas intentan relajar la suposición de la independencia condicional de atributos hasta cierto punto, lo que da como resultado una clase de métodos de aprendizaje llamados "clasificadores bayesianos semi-ingenuos".
La idea básica del clasificador bayesiano semi-ingenuo es considerar adecuadamente la información de interdependencia entre algunos atributos, de modo que no necesite calcular la probabilidad conjunta completa y no ignore por completo las dependencias de atributos relativamente fuertes. One-Dependent Estimator (ODE) es la estrategia más utilizada para los clasificadores bayesianos semi-ingenuos. Como sugiere el nombre, la llamada "dependencia independiente" consiste en suponer que cada atributo depende como máximo de otro atributo fuera de la categoría.

Donde pai es el atributo del que depende el atributo xi, llamado atributo padre de xi. En este momento, para cada atributo xi, si se conoce su atributo padre pai, el valor de probabilidad P(xi|c,pai) se puede estimar utilizando el método de probabilidad condicional de clase modificado por Laplace.
Así, diferentes métodos producen diferentes clasificadores dependientes independientes. Aquí hay un ejemplo simple de dos clasificadores dependientes independientes:
①SPODE(ODE Super-Padre)
Se supone que todos los atributos dependen del mismo atributo, que se denomina "superparental", y luego los atributos superparentales se determinan mediante métodos de selección de modelos, como la validación cruzada.
②AODE(Estimador promedio de un dependiente)
AODE es un clasificador de dependencia independiente más poderoso basado en un mecanismo de aprendizaje conjunto. A diferencia de SPODE, que determina el atributo superparental a través de la selección del modelo. AODE intenta construir SPODE superponiendo cada asiento de atributo y luego integra esos SPODE con suficiente soporte de datos de entrenamiento como resultado final.
Resumir:
Dado que es posible mejorar el rendimiento de la generalización relajando el supuesto de independencia condicional del atributo al supuesto de dependencia independiente, ¿se puede mejorar aún más el rendimiento de la generalización considerando las dependencias de alto orden entre los atributos? Es decir, la ODE se extiende a kDE reemplazando el atributo pai con el conjunto pai que contiene k atributos . Cabe señalar que a medida que aumenta k, la cantidad de muestras de entrenamiento requeridas para estimar con precisión la probabilidad P(xi|y, pa i) aumentará exponencialmente. Por lo tanto, si los datos de entrenamiento son suficientes, el rendimiento de la generalización puede mejorar, pero bajo la condición de muestras limitadas, caerá en el atolladero de la probabilidad conjunta de alto orden.
Consulte el "Aprendizaje automático" de Zhou Zhihua