La función de activación se revisa en el artículo " Funciones de activación comunes en redes neuronales ". La siguiente figura es un subconjunto de la función de activación:
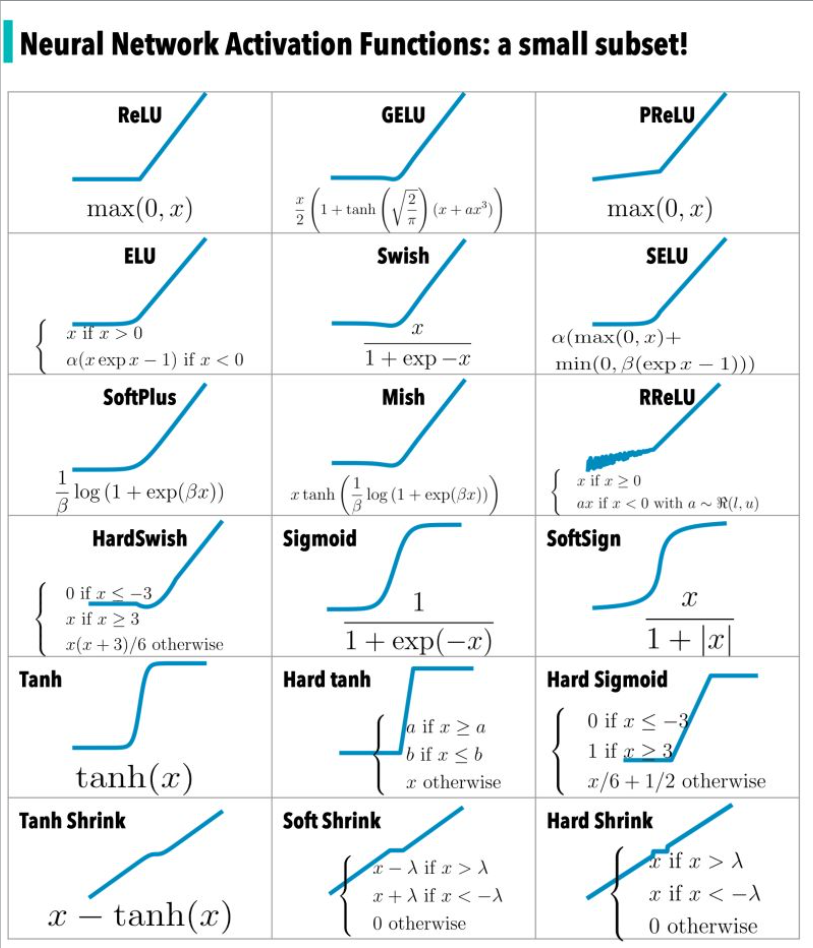
Otra función importante en el campo de las redes neuronales es la función de pérdida, entonces, ¿qué es la función de pérdida?
La función de pérdida es una función que asigna eventos aleatorios o sus variables aleatorias relacionadas a números reales no negativos para representar el "riesgo" o la "pérdida" del evento aleatorio, y se usa para medir el grado de desviación entre el valor predicho y el valor real En el aprendizaje automático, una función de pérdida es parte de una función de costo, que es un tipo de función objetivo. En las aplicaciones, las funciones de pérdida a menudo se asocian con problemas de optimización como criterios de aprendizaje, es decir, resolver y evaluar modelos minimizando la función de pérdida.

Aquí hay una breve revisión de algunas funciones de pérdida comunes y sus casos de uso concisos. Para facilitar la comprensión, las funciones de pérdida se dividen en dos categorías: funciones de pérdida orientadas a la clasificación y funciones de pérdida orientadas a la regresión. Para facilitar la comparación de diferentes funciones de pérdida, a menudo se expresa como una función univariada, que es y−f(x) en problemas de regresión e yf(x) en problemas de clasificación.
Funciones de pérdida orientadas a la clasificación
Para problemas de clasificación binaria, y∈{−1,+1}, la función de pérdida a menudo se expresa como una forma monótonamente decreciente con respecto a yf(x). yf(x) se denomina margen, y la minimización de la función de pérdida también puede verse como un proceso de maximización del margen. Cualquier función de pérdida de clasificación calificada debería imponer una penalización mayor a las muestras con margen <0.
Función de pérdida de pérdida de entropía cruzada
La entropía en física representa el grado de desorden en un sistema termodinámico. Para resolver el problema de la medición cuantitativa de la información, Shannon propuso el concepto de "entropía de la información" en 1948, utilizando una función logarítmica para representar la medición de la incertidumbre. Cuanto mayor sea la entropía, más información se puede transmitir, y cuanto menor sea la entropía, menos información se puede transmitir.La entropía se puede entender directamente como la cantidad de información.
La entropía cruzada (cross-entropy, CE) describe la distancia entre dos distribuciones de probabilidad y es más adecuada para problemas de clasificación, porque la entropía cruzada expresa la probabilidad de predecir que una muestra de entrada pertenece a una determinada clase.
La función de pérdida de entropía cruzada, o pérdida logarítmica negativa, mide el rendimiento de un modelo de clasificación cuyo resultado es un valor de probabilidad entre 0 y 1, y se usa a menudo en problemas binarios y de clasificación múltiple. La pérdida de entropía cruzada aumenta a medida que los valores de probabilidad pronosticados se alejan de las etiquetas reales. Un modelo perfecto tendría cero pérdidas porque los valores predichos coincidirían con los valores reales.
Para la clasificación binaria, la fórmula para la pérdida de entropía cruzada es la siguiente:
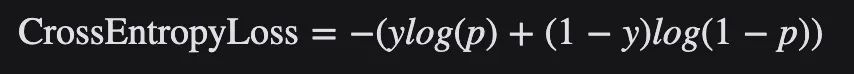
En tareas de clasificación múltiple, a menudo se usa la función de activación softmax + la función de pérdida de entropía cruzada, porque la entropía cruzada describe la diferencia entre dos distribuciones de probabilidad, pero la salida de la red neuronal es un vector, no en forma de distribución de probabilidad. . Por lo tanto, se requiere la función de activación softmax para "normalizar" un vector en la forma de una distribución de probabilidad y luego usar la función de pérdida de entropía cruzada para calcular la pérdida.
Para la clasificación múltiple, la fórmula para la pérdida de entropía cruzada es la siguiente:
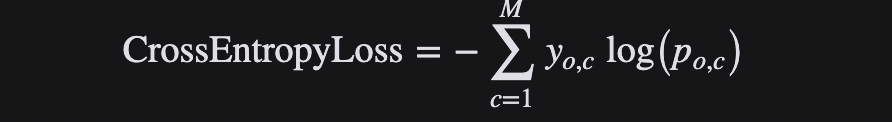
Función de pérdida de pérdida focal
La función de pérdida de pérdida focal es para resolver el problema del desequilibrio extremo entre las muestras positivas y negativas en la detección de objetivos de una etapa. Es una función de pérdida para la detección de objetivos densos. Esta es una de las opciones más comunes cuando se entrenan redes neuronales profundas para problemas de clasificación y detección de objetos.
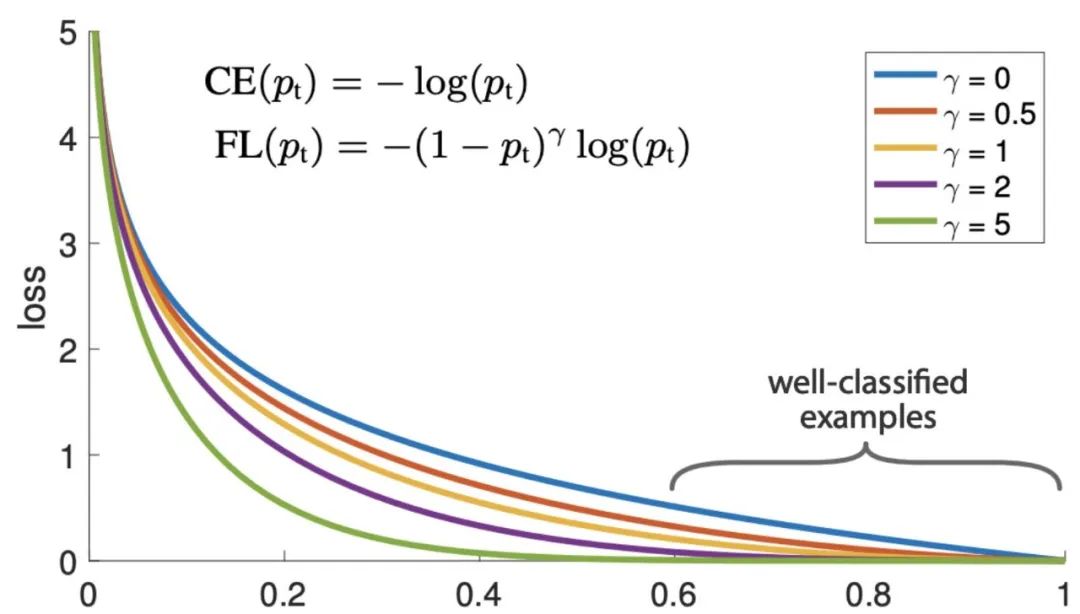
La función de pérdida de pérdida focal se basa en la entropía cruzada binaria. A través de un factor de escala dinámico, el peso de las muestras fáciles de distinguir se puede reducir dinámicamente durante el entrenamiento, de modo que el centro de gravedad se pueda enfocar rápidamente en aquellas que son difíciles de distinguir. -distinguir muestras. Esas muestras pueden ser muestras positivas o muestras negativas, pero todas son muestras útiles para entrenar la red.
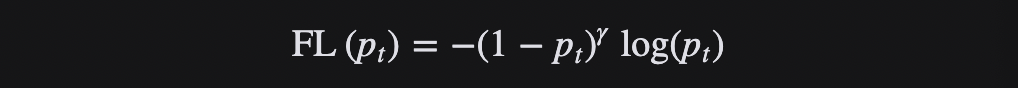
La función de pérdida focal calcula una pérdida de entropía cruzada escalada dinámicamente, donde el factor de escala decae a cero, a medida que aumenta la confianza de la clase correcta.
Función de pérdida de polipérdida
La función de pérdida de entropía cruzada y la función de pérdida de pérdida focal son las opciones más utilizadas en el entrenamiento de problemas de clasificación de redes neuronales profundas. Sin embargo, en general, una buena función de pérdida puede adoptar una forma más flexible y debe adaptarse a diferentes tareas y conjuntos de datos.
La función de pérdida se puede considerar como una combinación lineal de funciones polinómicas, y la función se aproxima mediante la expansión de Taylor. Bajo la expansión polinómica, la pérdida focal es el desplazamiento horizontal de los coeficientes polinómicos en relación con la pérdida de entropía cruzada. Si se modifican verticalmente los coeficientes del polinomio, se obtiene la fórmula de cálculo de Polyloss:
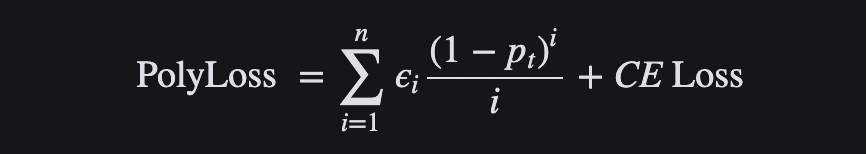
Polyloss es una forma generalizada de la función de pérdida de pérdida de entropía cruzada.
Función de pérdida de pérdida de bisagra
La función de pérdida de bisagra Hinge suele ser adecuada para escenarios de clasificación binaria y se puede utilizar para resolver el problema de la maximización de intervalos. Se utiliza a menudo en el famoso algoritmo SVM.
La función de pérdida de bisagra es una función convexa que es buena en la clasificación de "margen máximo", por lo que muchos optimizadores convexos que se usan comúnmente en el aprendizaje automático pueden aprovecharla.
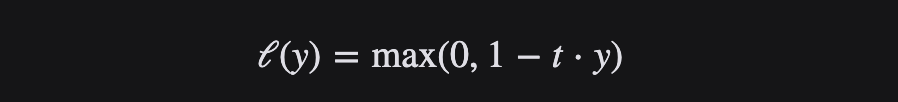
La función de pérdida de bisagra toma la diferencia o la distancia desde el límite de clasificación en el cálculo del costo. Incluso si las nuevas observaciones se clasifican correctamente, se penalizan con una pérdida linealmente creciente si la brecha entre los límites de decisión no es lo suficientemente grande.
Función de pérdida de pérdida de extremo a extremo generalizada
La función de pérdida de extremo a extremo generalizada (GE2E para abreviar) es una función de pérdida de extremo a extremo generalizada para la verificación de altavoces.
La verificación del locutor se refiere a la tarea de verificar si una voz de entrada pertenece a un locutor específico. Aquí hay dos conceptos: locución de inscripción y locución de verificación. El primero puede entenderse como una "huella de voz" reservada, mientras que el segundo se usa para la verificación. voz. Se subdivide además en dos tareas: verificación del hablante dependiente del texto (TD-SV) y verificación independiente del texto (TI-SV). TD-SV tiene ciertas restricciones en el contenido de la voz utilizada para la verificación. Un ejemplo común es Siri. En este momento, se debe pronunciar una oración fija "Oye, siri". Por el contrario, TI-SV no impone ninguna restricción sobre el contenido del discurso.
GE2E hace que el entrenamiento del modelo de verificación de locutor sea más eficiente que la función de pérdida de pérdida de extremo a extremo (TE2E) basada en tupla, y tiene las ventajas de una convergencia rápida y una implementación simple.
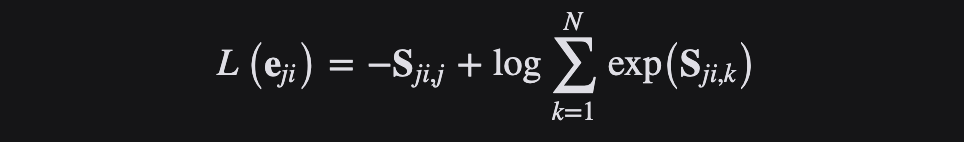
GE2E hará que la red se centre en datos que no se distinguen fácilmente al actualizar los parámetros y no requieren una selección de ejemplos antes del entrenamiento. Además, GE2E Loss no requiere una selección de ejemplos en la etapa inicial.
Función de pérdida de pérdida de margen angular aditivo
La pérdida de margen angular aditivo (AAM) se utiliza principalmente en el reconocimiento facial, pero también se ha aplicado en otros campos, como el reconocimiento de voz.
Uno de los principales desafíos en el aprendizaje de características para el reconocimiento facial a gran escala utilizando una red neuronal convolucional profunda (DCNN) es cómo diseñar una función de pérdida adecuada para mejorar la capacidad de reconocimiento. La pérdida del centro penaliza la distancia entre las características profundas y sus correspondientes centros de clase en el espacio euclidiano para lograr la compacidad intraclase. Se supone que la matriz de mapeo lineal en la última capa completamente conectada se puede usar para representar los centros de clase en el espacio del ángulo, y el ángulo entre las características profundas y sus pesos correspondientes se penaliza multiplicativamente. Una dirección de investigación popular es incorporar márgenes reservados en funciones de pérdida establecidas para maximizar la separabilidad de las caras.
AAM Loss (ArcFace) obtiene características altamente discriminatorias con una interpretación geométrica clara (superando otras funciones de pérdida) debido a la correspondencia precisa con distancias geodésicas en hiperesferas. ArcFace supera constantemente a la tecnología de punta y se puede implementar fácilmente con una sobrecarga computacional insignificante.
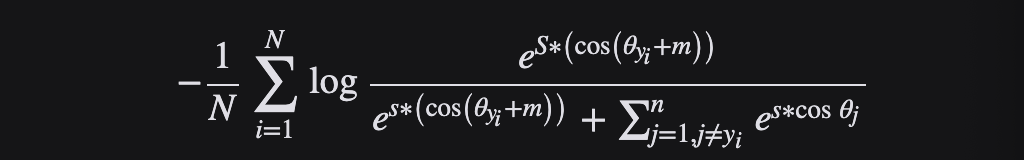
Específicamente, el arco cos(θ+m) propuesto maximiza directamente el límite de decisión en el espacio del ángulo (arco) basado en pesos y características normalizados L2.
Función de pérdida de pérdida de triplete
Triplet Loss se usó originalmente para aprender el reconocimiento facial de la misma persona en diferentes poses y ángulos. Triplet Loss es una función de pérdida para algoritmos de aprendizaje automático en los que una entrada de referencia (llamada ancla) se compara con una entrada coincidente (llamada valor positivo) y una entrada no coincidente (llamada valor negativo).
Considere la tarea de entrenar una red neuronal para reconocer rostros (como ingresar a un área de alta seguridad). Un clasificador entrenado debe volver a entrenarse cada vez que se agrega una nueva persona a la base de datos de rostros. Esto se puede evitar haciendo que el problema sea un problema de aprendizaje de similitud en lugar de un problema de clasificación. Aquí, la red se entrena (usando una pérdida de contraste) para generar una distancia que es pequeña si la imagen pertenece a una persona conocida y grande si la imagen pertenece a una persona desconocida. Sin embargo, si queremos generar la imagen más cercana a una imagen determinada, queremos saber una clasificación, no solo una similitud. En este caso se utiliza la pérdida triple.
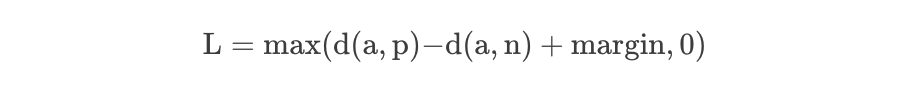
Donde d representa la función de distancia, que generalmente se refiere al cálculo de la distancia euclidiana en Incrustación. Obviamente, Triplet-Loss espera que la distancia entre ayp sea lo más pequeña posible, mientras que la distancia entre ayn sea lo más grande posible.
Una opción importante para usar la pérdida de tripletes en el entrenamiento es que necesitamos seleccionar muestras negativas, lo que se denomina selección de muestras negativas o colección de tripletes. La estrategia elegida puede tener un impacto significativo en la eficiencia del entrenamiento y en los resultados finales de rendimiento. Una estrategia obvia es: los triples simples deben muestrearse tanto como sea posible, porque su pérdida es 0, lo que no ayuda a la optimización.
Función de pérdida InfoNCE Loss
La función de pérdida InfoNCE Loss es una función de pérdida basada en el contraste, que se desarrolla a partir de la función de pérdida NCE Loss.
NCE es un método basado en muestreo que convierte problemas de clasificación múltiple en problemas de clasificación binaria. Tomando el modelo de lenguaje como ejemplo, el uso de NCE puede transformar el problema de clasificación múltiple de predecir una determinada palabra del vocabulario en un problema de clasificación binaria de distinguir palabras objetivo de palabras irrelevantes. Una clase es la muestra de datos de categoría de datos y la otra La clase es una muestra ruidosa de categoría de ruido, aprendiendo la diferencia entre muestras de datos y muestras de ruido, comparando muestras de datos con muestras de ruido, es decir, "ruido contrastivo (ruido contrastivo)", para descubrir algunas características en los datos.
La pérdida de información NCE es una variante simple de NCE. Piensa que si solo piensa en el problema como una categoría de dos, con solo muestras de datos y muestras de ruido, puede que no sea amigable para modelar el aprendizaje, porque muchas muestras de ruido pueden no serlo. una clase en absoluto. , por lo que es más razonable considerarlo como un problema de clasificación múltiple.
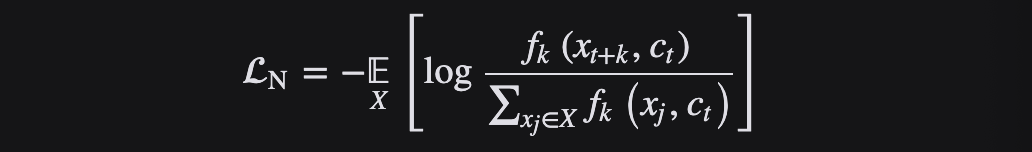
InfoNCE, que significa Noise Contrastive Estimation, es una función de pérdida contrastiva para el aprendizaje autosupervisado que utiliza la pérdida de entropía cruzada categórica para identificar muestras positivas en un conjunto de muestras ruidosas no correlacionadas. InfoNCE Loss consiste en dividir N muestras en K categorías, en lugar de la clasificación binaria de NCE Loss o la clasificación completa de la función de pérdida de entropía cruzada.
Función de pérdida de pérdida de dados
La función de pérdida de Dice se deriva del coeficiente de Sørensen-Dice, un método estadístico desarrollado en la década de 1940 para medir la similitud entre dos muestras. Un valor mayor del coeficiente de Dice significa que las dos muestras son más similares.
La pérdida de dados se usa a menudo en problemas de segmentación semántica. Para el problema de segmentación de dos categorías, la etiqueta de segmentación real tiene solo dos valores de 0 y 1. Para el problema de segmentación de múltiples categorías, Dice Loss se deriva de la optimización directa de la puntuación F1, que es una gran abstracción de la puntuación F1.
En 2016, Milletari y otros lo introdujeron en la comunidad de visión artificial para la segmentación de imágenes médicas en 3D. Para evitar que el término del denominador sea 0, generalmente agregaremos un número pequeño como coeficiente de suavizado tanto al numerador como al denominador, también conocido como el término de suavizado de Laplace. Dice Loss tiene las siguientes características principales:
Es beneficioso para la situación en la que las muestras positivas y negativas están desequilibradas, centrándose en la extracción de prospectos;
Durante el proceso de entrenamiento, es probable que ocurra una oscilación cuando hay muchos objetivos pequeños;
En casos extremos, se produce una saturación de gradiente.
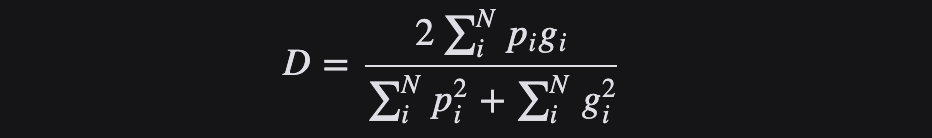
Desde el punto de vista de la teoría de conjuntos, DSC es una medida de la superposición entre dos conjuntos. Por ejemplo, si dos conjuntos A y B se superponen por completo, el valor máximo del coeficiente Dice es 1. De lo contrario, el coeficiente de Dice comienza a disminuir y el valor mínimo del coeficiente de Dice es 0 si los dos conjuntos no se superponen en absoluto.
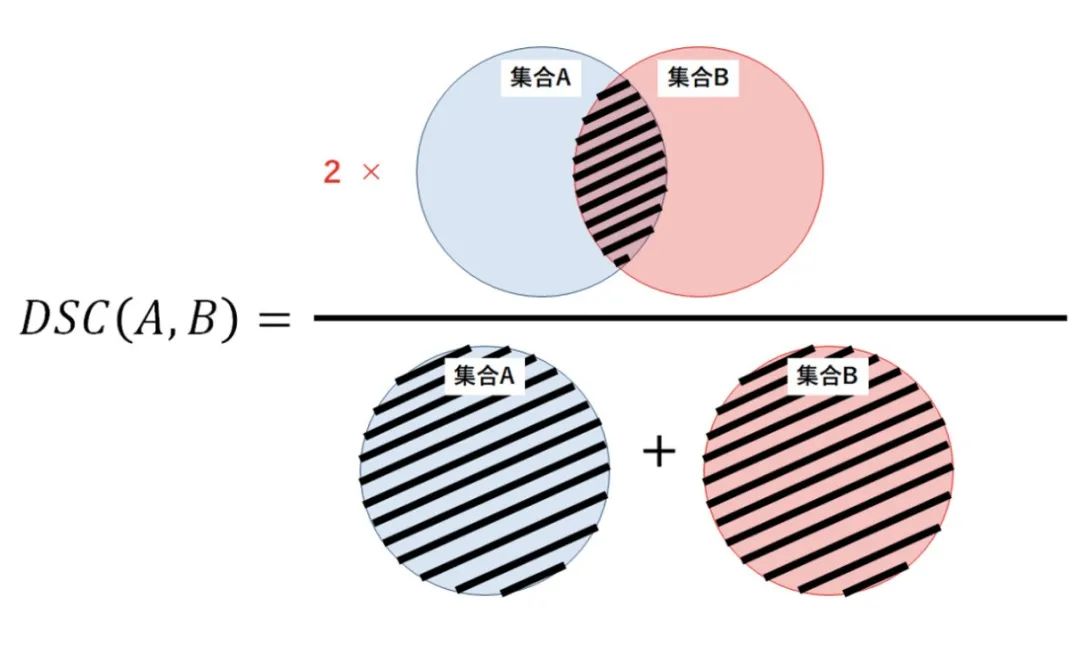
Por lo tanto, el rango de DSC está entre 0-1, cuanto más grande, mejor. Por lo tanto, podemos usar 1-DSC como la pérdida de dados para maximizar la superposición entre los dos conjuntos.
Función de pérdida de pérdida de clasificación de margen
Como sugiere el nombre, la función de pérdida Margin Ranking Loss se usa principalmente para clasificar problemas y también se usa en redes de confrontación. Margin Ranking Loss calcula la pérdida de entrada X1, X2 y el tensor de etiqueta y que contiene 1 o -1. Cuando y tiene un valor de 1, se supondrá que la primera entrada es el valor más grande y se clasificará más alto que la segunda entrada. De manera similar, si y = -1, la segunda entrada se clasificará más arriba.
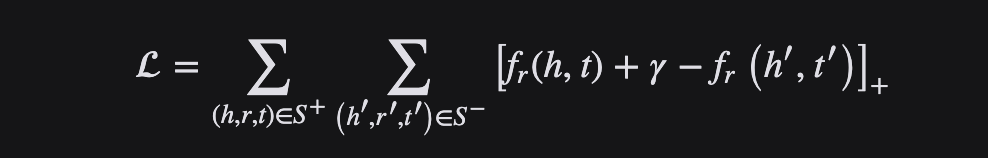
Margin Ranking Loss calcula un criterio para predecir la distancia relativa entre las entradas. Esto difiere de otras funciones de pérdida, como MSE o entropía cruzada, que aprenden a hacer predicciones directamente a partir de un conjunto dado de entradas.
Función de pérdida de pérdida de contraste
Dado el requisito de reducción de dimensionalidad del aprendizaje de mapeos invariantes, la pérdida contrastiva es una función de pérdida alternativa a la entropía cruzada, que hace un uso más eficiente de la información de la etiqueta.
En la red siamesa, la función de pérdida que se utiliza es la pérdida contrastiva. Esta función de pérdida puede tratar de manera efectiva la relación entre datos emparejados en la red neuronal siamesa. No necesariamente tiene que tener dos redes en forma, sino que también puede ser una red y dos fuera.
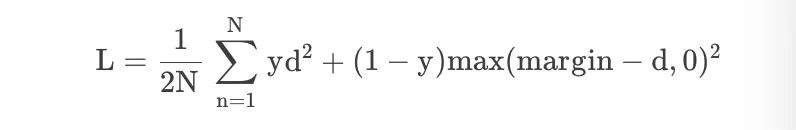
En el espacio de incrustación, los grupos de puntos de la misma clase se juntan mientras que los grupos de muestras de diferentes clases se alejan. Contrastive usa la salida de la red como una muestra positiva, calcula la distancia desde la red a la misma instancia y la compara con la distancia desde la red a la instancia negativa. La pérdida contrastiva calcula la distancia entre ejemplos positivos (ejemplos de la misma clase) y ejemplos negativos (ejemplos de diferentes clases). Por lo tanto, si los ejemplos positivos se codifican (en este espacio de incrustación) en ejemplos similares, y los ejemplos negativos se codifican además en diferentes representaciones, se puede esperar que la pérdida sea baja.
Función de pérdida de pérdida de clasificación negativa múltiple
El núcleo del campo de representación de oraciones es en realidad un ejemplo negativo implícito prescrito, por ejemplo, solo oraciones de anclaje y un ejemplo positivo, y otras oraciones en el mismo lote son ejemplos negativos, o especifican un conjunto de oraciones de anclaje, ejemplos positivos, negativos difíciles ejemplos, etc. Por ejemplo, otras declaraciones en el mismo lote son todos ejemplos negativos, etc. La función de pérdida utilizada es principalmente Pérdida de Clasificación Negativa Múltiple, y la expresión matemática es:
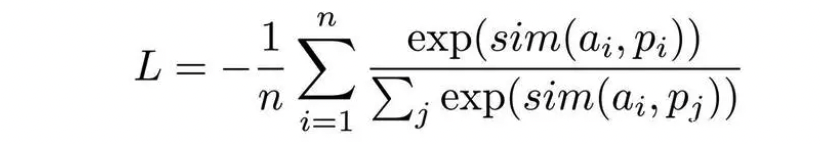
Esta función de pérdida funciona bien para entrenar incrustaciones para usar pares positivos (por ejemplo, consulta, documento_relevante) en una configuración de recuperación porque muestreará aleatoriamente cada lote de n-1 documentos negativos. El rendimiento generalmente mejora con tamaños de lote más grandes.
En el problema de incrustación eficiente de oraciones, el modelo entrenado con la función de pérdida Multiple Negative Ranking Loss tiene ciertas ventajas.
Función de pérdida orientada a la regresión
En el problema de regresión, tanto y como f(x) son números reales ∈ R, por lo que el residuo y−f(x) se usa para medir el grado de inconsistencia entre los dos. Cuanto mayor sea el residual (valor absoluto), mayor será la función de pérdida y peor será el efecto del modelo aprendido (el problema de regularización no se considera aquí).
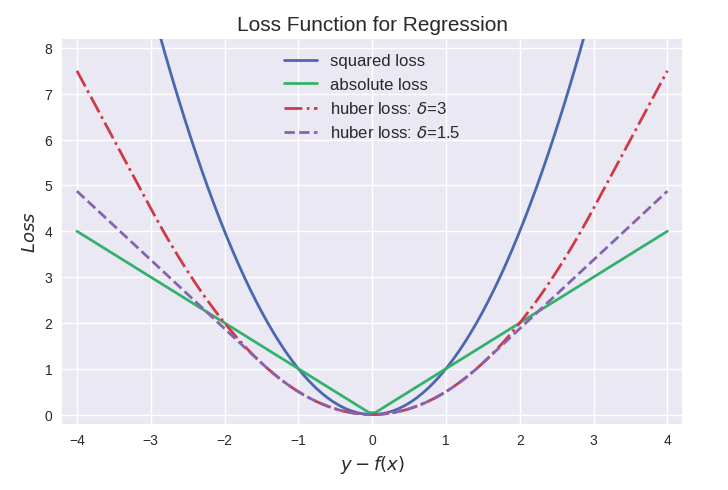
Función de pérdida de pérdida MAE o L1
Como su nombre lo indica, el error promedio promedio (MAE) toma la suma promedio de las diferencias absolutas entre el valor real y el valor pronosticado, también conocido como "función de pérdida L1". Mide el tamaño promedio del error en un conjunto de pronósticos, independientemente de la dirección del error. Si además se considera la dirección, se denominará Mean Bias Error (MBE), que es la suma de los residuos o errores, y su rango de pérdida también es de 0 a ∞.
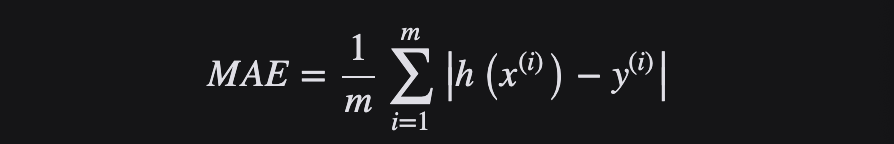
Debido a la presencia de outliers (valores muy diferentes al resto de los datos), los problemas de regresión pueden tener variables que no son estrictamente de naturaleza gaussiana. En este caso, el error absoluto medio sería una opción ideal, ya que no tiene en cuenta la dirección de los valores atípicos (valores positivos o negativos irrealmente altos).
La función de pérdida L1 se utiliza para minimizar el error, tomando el error absoluto como la distancia. L1 no se ve afectado por valores atípicos, por lo que si el conjunto de datos contiene valores atípicos, es preferible L1. Además, su velocidad de convergencia es rápida y puede otorgar pesos de penalización apropiados al gradiente en lugar de "trato igualitario", de modo que la dirección de actualización del gradiente pueda ser más precisa.
Función de pérdida de pérdida MSE o L2
El error cuadrático medio (Mean Squared Error, MSE) es el promedio de la diferencia cuadrática entre el valor real y el valor predicho. Es la función de pérdida de regresión más utilizada, también conocida como "función de pérdida L2". MSE es la suma de las distancias al cuadrado entre la variable objetivo y el valor predicho.
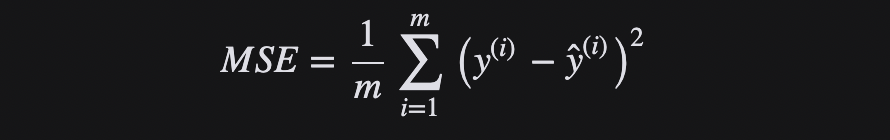
La función de pérdida L2 se utiliza para minimizar el error y también es una función de pérdida de mayor prioridad que L1. Sin embargo, L2 no funcionará bien cuando haya valores atípicos en el conjunto de datos, ya que la diferencia al cuadrado generará errores mayores.
En resumen, usar L2 es más fácil de resolver, pero usar L1 es más robusto para los valores atípicos.
Función de pérdida Huber Loss
Huber Loss es una función de pérdida que combina MSE y MAE y aprovecha las ventajas de ambos.También se denomina Smooth Mean Absolute Error Loss (Smooth L1 loss). Huber Loss también es una función de pérdida utilizada en la regresión que es menos sensible a los valores atípicos en los datos que la pérdida de error al cuadrado. Es insensible a valores atípicos y extremadamente pequeño y diferenciable, lo que hace que la función de pérdida tenga buenas propiedades.
Cuando el error es pequeño, use la parte MSE de Huber Loss, y cuando el error sea grande, use la parte MAE de Huber Loss. Se introduce un nuevo hiperparámetro δ, que le dice a la función de pérdida dónde cambiar de MSE a MAE. Se introduce un término δ en la función de pérdida para suavizar la transición de MSE a MAE. La función de pérdida de Huber describe la pérdida producida por el proceso de estimación.El segmento de pérdida de Huber F define la función de pérdida:
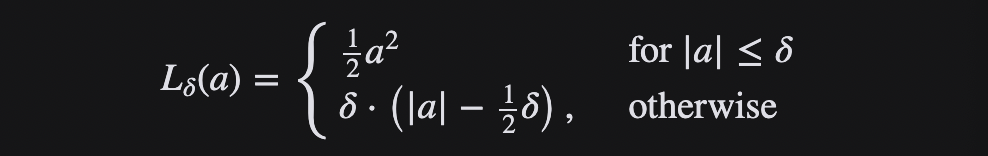
Esta función es cuadrática, con valores iguales y partes diferentes de la pendiente en dos puntos ‖ a ‖ = δ La variable a generalmente se refiere al residual, la diferencia entre los valores observados y predichos A = yf (x) entonces el primero puede extenderse a:
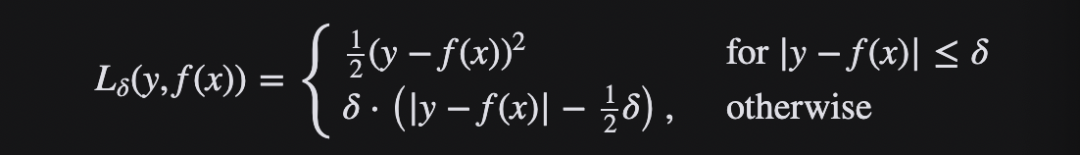
En resumen, Huber Loss mejora la solidez de valores atípicos de MSE y reduce la sensibilidad a los valores atípicos. Cuando el error es grande, el uso de MAE puede reducir la influencia de los valores atípicos y hacer que el entrenamiento sea más sólido. Su velocidad de caída está entre MAE y MSE, lo que compensa la lenta caída de MAE en Loss, y se acerca más a MSE.
resumen
En las redes neuronales, la función de pérdida es una medida de la diferencia entre la salida prevista de la red neuronal y la salida real, calculando la distancia entre la salida actual y la salida esperada. Esta es una forma de evaluar cómo se modelan los datos, proporciona una medida del rendimiento de la red neuronal y se utiliza como objetivo para la optimización durante el entrenamiento. Cuanto menor sea la función de pérdida, mejor será la robustez del modelo, y es la función de pérdida la que guía el aprendizaje del modelo.
[Materiales de referencia y lecturas relacionadas]
PolyLoss: una perspectiva de expansión polinomial de las funciones de pérdida de clasificación, https://arxiv.org/abs/2204.12511
Pérdida focal para detección de objetos densos, https://arxiv.org/abs/1708.02002
Pérdida generalizada de extremo a extremo para la verificación de altavoces, https://arxiv.org/abs/1710.10467
ArcFace: pérdida de margen angular aditivo para reconocimiento facial profundo, https://arxiv.org/abs/1801.07698
FaceNet: una integración unificada para el reconocimiento facial y la agrupación, https://arxiv.org/abs/1503.03832
Codificación predictiva contrastiva, https://arxiv.org/pdf/1807.03748v2.pdf
Replanteamiento de la pérdida de dados para la segmentación de imágenes médicas,https://ieeexplore.ieee.org/document/9338261
Pérdida de clasificación de margen adaptativo para incrustaciones de gráficos de conocimiento a través de una función objetiva de correntropía, https://arxiv.org/pdf/1907.05336.pdf
Pérdida de clasificación negativa múltiple, https://arxiv.org/pdf/1705.00652.pdf
Pérdida contrastiva, http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
20 artículos sobre el aprendizaje sistemático de modelos grandes
Análisis comparativo de arquitecturas de aprendizaje profundo
Un breve análisis del aprendizaje automático y las ecuaciones diferenciales
Modelo grande (LLM) a los ojos de los antiguos programadores
10 elementos de la arquitectura del sistema de aprendizaje automático
¿Gestión de listas? Conjuntos de datos para aprendizaje automático
"Procesamiento del lenguaje natural basado en métodos mixtos" Prefacio del traductor