En la publicación de blog "En la era posterior a la epidemia, la ciencia de datos potencia la mejora de la calidad del servicio de la industria del turismo" , presentamos los antecedentes y la solución del proyecto de análisis de texto de TripAdvisor y mostramos los resultados finales del análisis. A continuación, para los lectores que estén interesados en la PNL en chino e inglés, explicaremos en detalle los principios y la implementación del código involucrados en los pasos de recopilación de datos, almacenamiento de datos, limpieza de datos y modelado de datos. Debido a limitaciones de espacio, la primera parte se centrará en los tres pasos de recopilación, almacenamiento y limpieza de datos, y la segunda parte explicará el proceso completo de modelado de datos.
recopilación de datos
1. Análisis de orugas
El raspado web es una de las formas de obtener datos de Internet. Para los desarrolladores que usan Python para web scraping, las herramientas más comunes son las siguientes:
hermosa sopa
Beautiful Soup es la biblioteca de raspado web más accesible entre varias herramientas, que puede ayudar rápidamente a los desarrolladores a obtener datos de archivos en formato HTML o XML. En este proceso, Beautiful Soup leerá la estructura de datos de dichos archivos hasta cierto punto y proporcionará muchas ecuaciones relacionadas con la búsqueda y obtención de contenido de datos sobre esta base. Además, la documentación completa y fácil de entender y la comunidad activa de Beautiful Soup permiten a los desarrolladores no solo comenzar rápidamente, sino también dominarla de manera rápida y flexible para usarla en sus propias aplicaciones.
Sin embargo, debido a estas características de funcionamiento, Beautiful Soup también tiene defectos evidentes en comparación con otras bibliotecas. En primer lugar, Beautiful Soup necesita confiar en otras bibliotecas de Python (como Solicitudes) para enviar solicitudes al servidor de objetos para lograr el rastreo del contenido de la página web; también necesita confiar en otros analizadores de Python (como html.parser) para analizar el contenido capturado. En segundo lugar, debido a que Beautiful Soup necesita leer y comprender el marco de datos de todo el archivo con anticipación para encontrar el contenido más tarde, desde la perspectiva de la velocidad de lectura del archivo, Beautiful Soup es relativamente lento. En el proceso de obtener mucha información de la página web, la información requerida puede representar solo una pequeña parte, y tal paso de lectura no es necesario.
raspado
Scrapy es una de las bibliotecas de raspado web de código abierto más populares. Su característica más destacada es su rápida velocidad de rastreo y, debido a que se basa en el marco de trabajo de red asíncrona Twisted, las solicitudes enviadas por los usuarios se envían al servidor de forma no bloqueante. mecanismo, que es mejor que el bloqueo El mecanismo es más flexible y eficiente en recursos. Por lo tanto, Scrapy tiene las siguientes características:
- Para páginas web de tipo HTML, utilice XPath o CSS para expresar el soporte para la obtención de datos
- Puede ejecutarse en una variedad de entornos, no solo limitado a Python. Linux, Windows, Mac y otros sistemas pueden usar la biblioteca Scrapy.
- Fuerte escalabilidad
- Mayor velocidad y eficiencia
- Requiere menos memoria, recursos de CPU
A pesar de que Scrapy es una poderosa biblioteca de web scraping y tiene soporte comunitario relacionado, la documentación desigual y difícil desalienta a muchos desarrolladores y dificulta comenzar.
Selenio
Los orígenes de Selenium se desarrollaron para probar aplicaciones web y obtiene contenido web de una manera muy diferente a otras bibliotecas. El diseño estructural de Selenium es obtener los resultados devueltos por la página web a través de operaciones de página web automatizadas. Tiene buena compatibilidad con Java y puede responder fácilmente a las solicitudes de AJAX y PJAX. Similar a Beautiful Soup, Selenium es relativamente fácil de comenzar, pero en comparación con otras bibliotecas, su mayor ventaja es que puede manejar la entrada de texto para obtener información, o páginas emergentes, etc. que requieren que el usuario esté en el proceso. de rastreo web Hay un caso de acciones de intervención en el navegador. Estas características hacen que los desarrolladores sean más flexibles en los pasos del rastreo web y, por lo tanto, Selenium se ha convertido en una de las bibliotecas de rastreo web más populares.
Dado que es necesario lidiar con la entrada de la barra de búsqueda, las páginas emergentes y el cambio de página en el proceso de obtener reseñas de lugares escénicos, en este proyecto usaremos Selenium para capturar datos de texto de páginas web.
2. Comprensión preliminar de los datos y la estructura de la página web
Cada sitio web tiene su propia estructura y lógica únicas en el proceso de desarrollo. La misma página web basada en HTML, incluso si la interfaz de usuario es la misma, la relación jerárquica detrás de ella puede ser bastante diferente. Esto significa que para aclarar la lógica del rastreo web, no solo debemos comprender las características de la página web de destino, sino también comprender la actualización de la misma URL en el futuro y las características de las páginas web en otras plataformas del mismo tipo, y ordenar uno relativamente flexible mediante la comparación de partes similares.
Los pasos de rastreo web del sitio web de la versión internacional de TripAdvisor son similares a los del sitio web de la versión china. Aquí tomamos www.tripadvisor.cn como ejemplo para observar los pasos generales desde la página de inicio hasta las reseñas de lugares pintorescos.
Paso 1: ingrese a la página de inicio, ingrese el nombre de la atracción que desea buscar en la barra de búsqueda y presione Entrar

Paso 2: La página se actualiza, aparece una lista de atracciones, seleccione la atracción de destino

Después de buscar el nombre de la atracción, debemos bloquear la atracción objetivo en la lista que se muestra en la figura. Puede haber dos capas de superposición lógica aquí para ayudarnos a lograr este objetivo:
- El propio motor de búsqueda de TripAdvisor comparará el nombre de la atracción con la entrada de búsqueda y utilizará su propia lógica interna para clasificar las atracciones elegibles en la parte superior.
- Después de que aparezcan los resultados, podemos usar información como provincias y ciudades para filtrar las atracciones objetivo.
Paso 3: haga clic en la atracción objetivo, aparecerá una nueva página, cambie a esta página y busque comentarios relevantes
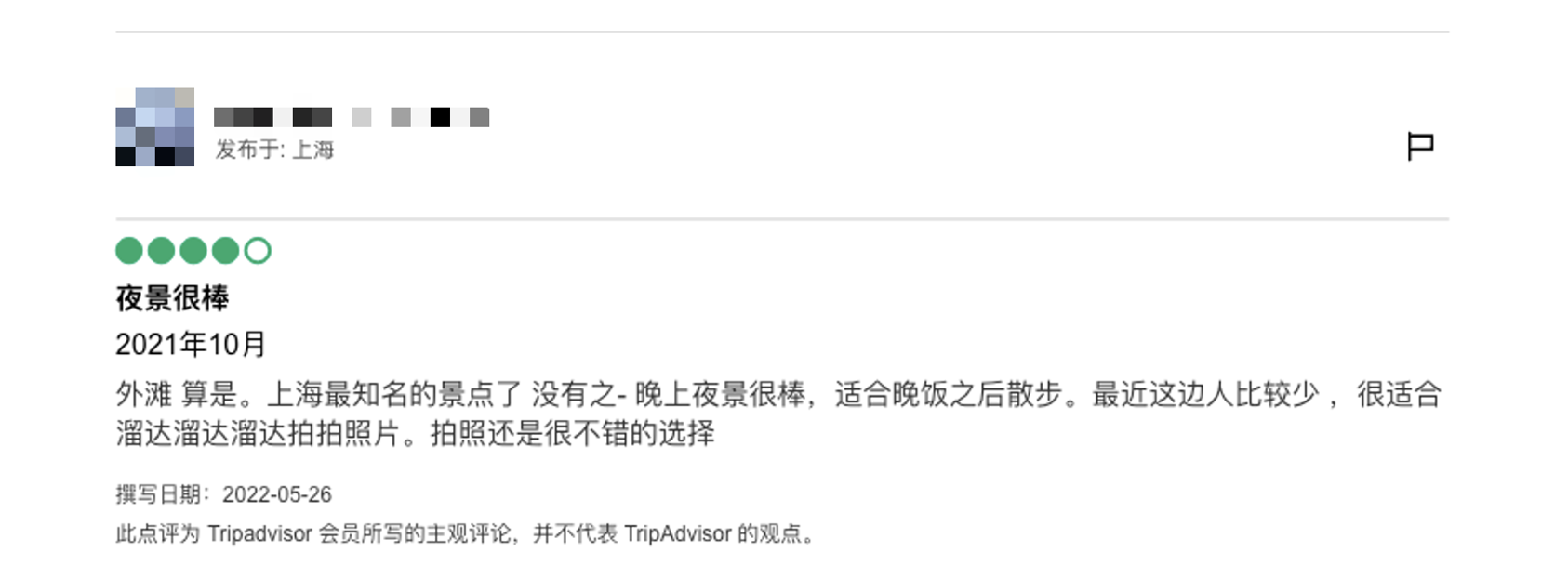
Según las características del formato de comentario, la información que podemos capturar es la siguiente:
- usuario
- ubicación del usuario
- puntaje
- Título de Revisión
- Fecha de visita
- tipo de viaje
- Comentarios detallados
- fecha de escritura
Paso 4: Pasa la página para obtener más comentarios

Se puede ver que hay muchas acciones que el navegador debe completar en el proceso de obtener páginas web relacionadas, razón por la cual elegimos Selenium. Por lo tanto, nuestro rastreador web realiza los mismos pasos antes del raspado de datos.
Una manera muy conveniente de ubicar el contenido requerido en el código HTML al desarrollar un programa de rastreo web es mover el mouse al área donde se encuentra el contenido en el navegador, hacer clic con el botón derecho y seleccionar "Inspeccionar", el navegador mostrará el Elemento HTML de la página web y Localice el código que es relevante para el contenido. Según este enfoque, podemos usar Selenium para la automatización y el raspado de datos.
Tomando el comentario anterior como ejemplo, su posición en la estructura HTML es la siguiente:
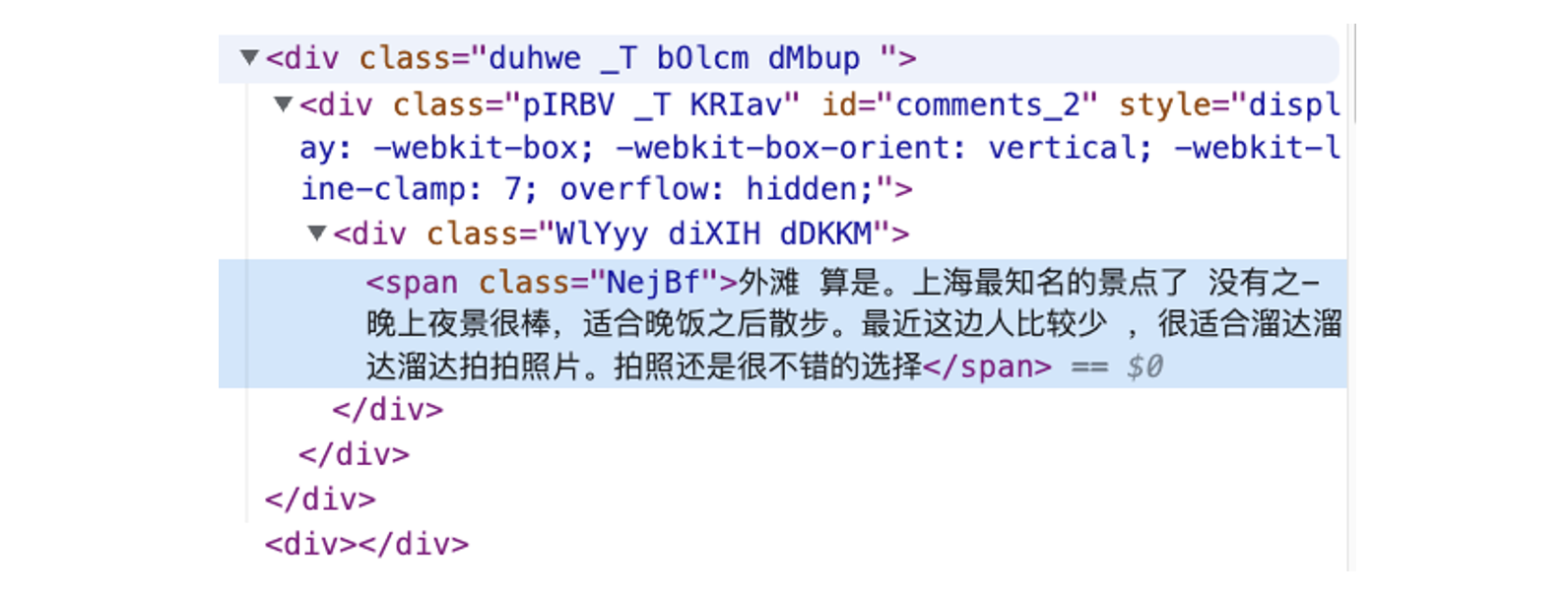
Al usar Selenium, las categorías de elementos y los nombres de clases pueden ayudarnos a localizar contenido relevante, realizar más operaciones y obtener datos de texto relevantes. Podemos utilizar estos dos métodos de posicionamiento: CSS o XPATH, los desarrolladores pueden elegir según sus propias necesidades. En última instancia, el proceso de web scraping que realizamos se puede dividir aproximadamente en dos pasos:
- Paso 1: envíe una solicitud, use Selenium para operar el navegador para encontrar la página de comentarios del lugar escénico especificado
- Paso 2: ingrese a la página de comentarios y tome los datos del comentario
3. Obtener datos de comentarios
La implementación de la función de esta parte necesita instalar e importar primero las siguientes bibliotecas de Python:
from selenium import webdriver
import chromedriver_binary
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import datetime
import re
import pandas as pd
from utility import print_log_message, read_from_configEntre ellos, la utilidad es un módulo auxiliar que contiene ecuaciones para imprimir sesiones y tiempos de ocurrencia, y ecuaciones para leer información del programa desde archivos de configuración ini. Las ecuaciones auxiliares en la utilidad se pueden repetir en tantos módulos como sea necesario.
#utility.py
import time
import configparser
def print_log_message(app_name, procedure, message):
ts = time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S", ts) + " **" + app_name + "** " + procedure + ":", message)
return
def read_from_config(file_name, section, var):
config = configparser.ConfigParser()
config.read(file_name)
var_value = config.get(section, var)
return var_valueAntes de comenzar el rastreo web, debemos iniciar un proceso de sesión web.
# Initiate web session
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--window-size=1920,1080')
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome(ChromeDriverManager().install(),chrome_options=chrome_options)
wd.get(self.web_url)
wd.implicitly_wait(5)
review_results = {}Teniendo en cuenta que el entorno operativo no es una PC o una instancia con recursos suficientes, debemos indicar en el código que el programa no tiene requisitos de visualización. ChromeDriverManager() puede ayudar al programa a descargar el archivo del controlador requerido en un entorno sin el controlador de Chrome y pasarlo al proceso de sesión de Selenium.
Tenga en cuenta que muchas páginas web están relacionadas con la versión de Chrome, los recursos, el entorno del sistema y el tiempo. Las páginas utilizadas en este proyecto no se ven afectadas por dicha información o circunstancias, pero están limitadas por la configuración de visualización del navegador, que a su vez afecta lo que se rastrea. Preste atención para verificar si la información que se muestra en la página web es consistente con los datos reales capturados al desarrollar este tipo de programa de rastreo.
Después de ingresar a la página de inicio de TripAdvisor (https://www.tripadvisor.cn/), ingrese el nombre de la atracción objetivo en la barra de búsqueda y presione Enter. Después de ingresar a la nueva página, ordene las atracciones en la lista de acuerdo con el motor de búsqueda. , provincia y ciudad, busque y haga clic para ir a la página de atracción correcta. Aquí, tomamos "El Bund" como ejemplo:
location_name = '外滩'
city = '上海'
state = '上海'# Find search box
wd.find_element(By.CSS_SELECTOR, '.weiIG.Z0.Wh.fRhqZ>div>form>input').click()# Enter location name
wd.find_element(By.XPATH, '//input[@placeholder="去哪里?"]').send_keys(f'{location_name}')
wd.find_element(By.XPATH, '//input[@placeholder="去哪里?"]').send_keys(Keys.ENTER)# Find the right location with city + province info
element = wd.find_element(By.XPATH,
f'//*[@class="address-text" and contains(text(), "{city}") and contains(text(), "{state}")]')
element.click()Después de hacer clic en la atracción de destino, cambie a la nueva página que salta. Después de ingresar a la página de revisión de la atracción, podemos obtener la información requerida de acuerdo con la estructura HTML de la página y la posición de la revisión en su jerarquía de código. Cuando Selenium está buscando un elemento determinado, buscará información relevante en todo el marco de la página web y no puede bloquear una parte determinada como otras bibliotecas de rastreo web y solo buscará el elemento deseado en esta parte. Por lo tanto, necesitamos capturar un tipo de información de manera uniforme y luego eliminar alguna información innecesaria. Este proceso requiere una verificación repetida de la información que se muestra en la página web real para evitar que se capture contenido no deseado y que afecte la calidad de los datos.
El código utilizado para rastrear es el siguiente:
comment_section = wd.find_element(By.XPATH, '//*[@data-automation="WebPresentation_PoiReviewsAndQAWeb"]')# user id
user_elements = comment_section.find_elements(By.XPATH, '//div[@class="ffbzW _c"]/div/div/div/span[@class="WlYyy cPsXC dTqpp"]')
user_list = [x.text for x in user_elements]Para la captura de datos de comentarios en inglés, además de algunas diferencias en el marco de la página web, los datos sobre la ubicación son más complicados y requieren un procesamiento adicional. En el proceso de rastreo, la coma predeterminada es el separador, el valor anterior a la coma es la ciudad y el valor posterior a la coma es el país.
# location
loca_elements = comment_section.find_elements(By.XPATH,
'//div[@class="ffbzW _c"]/div/div/div/div/div[@class="WlYyy diXIH bQCoY"]')
loca_list = [x.text[5:] for x in loca_elements]# trip type
trips_element = comment_section.find_elements(By.XPATH, '//*[@class="eRduX"]')
trip_types = [self.separate_trip_type(x.text) for x in trips_element]Tenga en cuenta que debido a que es relativamente difícil ubicar el tiempo de evaluación, la categoría de clase de texto contendrá información sobre la introducción de las atracciones de la página web, y debemos eliminar esta parte de los datos innecesarios.
# comment date
comments_date_element = comment_section.find_elements(By.CSS_SELECTOR, '.WlYyy.diXIH.cspKb.bQCoY')# drop out the first element
comments_date_element.pop(0)
comments_date = [x.text[5:] for x in comments_date_element]Dado que la calificación del usuario no es texto, necesitamos encontrar el elemento que la representa en la estructura HTML para calcular la calificación de estrellas. En el HTML de la página web de TripAdvisor, el elemento estrella es "burbuja". Necesitamos encontrar el código relevante en la estructura HTML y extraer los datos de la estrella en el código.
# rating
rating_element = comment_section.find_elements(By.XPATH,
'//div[@class="dHjBB"]/div/span/div/div[@style="display: block;"]')
rating_list = []
for rating_code in rating_element:
code_string = rating_code.get_attribute('innerHTML')
s_ind = code_string.find(" bubble_")
rating_score = code_string[s_ind + len(" bubble_"):s_ind + len(" bubble_") + 1]
rating_list.append(rating_score)# comments title
comments_title_elements = comment_section.find_elements(By.XPATH,
'//*[@class="WlYyy cPsXC bLFSo cspKb dTqpp"]')
comments_title = [x.text for x in comments_title_elements]# comments content
comments_content_elements = wd.find_element(By.XPATH,
'//*[@data-automation="WebPresentation_PoiReviewsAndQAWeb"]'
).find_elements(By.XPATH, '//*[@class="duhwe _T bOlcm dMbup "]')
comments_content = [x.text for x in comments_content_elements]La lógica para buscar imágenes en los comentarios es la misma que para buscar clasificaciones por estrellas. Primero debe encontrar la parte que representa imágenes en la estructura HTML y luego verificar si los comentarios contienen información de imágenes en el código.
# if review contains pictures
pic_sections = comment_section.find_elements(By.XPATH,
'//div[@class="ffbzW _c"]/div[@class="hotels-community-tab-common-Card__card--ihfZB hotels-community-tab-common-Card__section--4r93H comment-item"]')
pic_list = []
for r in pic_sections:
if 'background-image' in r.get_attribute('innerHTML'):
pic_list.append(1)
else:
pic_list.append(0)En resumen, podemos obtener e integrar los datos de reseñas del sitio web de TripAdvisor de acuerdo con el nombre de atracción ingresado y el número requerido de páginas de reseñas, y finalmente guardarlo como un marco de datos de Pandas.
Todo el proceso se puede automatizar y empaquetar en un archivo .py llamado data_processor. Para obtener los datos de revisión, solo necesitamos ejecutar la siguiente ecuación para obtener la información de revisión de la atracción en formato Pandas DataFrame.
#引入之前定义的Python Class:
from data_processor import WebScrapper
scrapper = WebScrapper()#运行网页抓取方程抓取中文语料:
trip_review_data = scrapper.trip_advisor_zh_scrapper_runner(location, location_city, location_state, page_n=int(n_pages))Donde ubicación representa el nombre de la atracción, ubicación_ciudad y ubicación_estado representan la ciudad y la provincia donde se encuentra la atracción, y página_n representa la cantidad de páginas que se rastrearán.
Almacenamiento de datos
Después de obtener los datos de comentarios capturados, podemos almacenar los datos en la base de datos para compartirlos y realizar más análisis y modelos. Tomando la base de datos PieCloudDB como ejemplo, podemos usar el controlador Postgres SQL de Python para conectarnos a PieCloudDB.
La forma en que este proyecto implementa el almacenamiento de datos es que después de obtener los datos de comentarios e integrarlos en un Pandas DataFrame, usaremos el motor SQLAlchemy para cargar los datos de Pandas en la base de datos a través de psycopg2. Primero, necesitamos definir el motor para conectarse a la base de datos:
from sqlalchemy import create_engine
import psycopg2
engine = create_engine('postgresql+psycopg2://user_name:password@db_ip:port /database')Entre ellos, postgresql + psycopg2 es el controlador que necesitamos usar cuando nos conectamos a la base de datos, user_name es el nombre de usuario de la base de datos, password es la contraseña de inicio de sesión correspondiente, db_ip es la IP de la base de datos o el punto final, port es la interfaz de conexión externa de la base de datos y base de datos es el nombre de la base de datos.
Después de pasar el motor a Pandas, podemos cargar fácilmente Pandas DataFrame en la base de datos para completar la operación de almacenamiento.
data.to_sql(table_name, engine, if_exists=‘replace’, index=False)data son los datos de Pandas DataFrame que necesitamos almacenar, table_name es el nombre de la tabla, engine es el motor SQLAlchemy que definimos antes, if_exists='replace' e index=False son las opciones de la ecuación Pandas to_sql(). El significado de esta opción es que si la tabla ya existe, los datos existentes se reemplazarán con los datos existentes y no es necesario considerar el índice durante el proceso de almacenamiento.
limpieza de datos
En este paso, limpiaremos los datos de comentarios de acuerdo con las características de los datos originales para prepararlos para el modelado posterior. Los datos de comentarios capturados contienen las siguientes tres categorías de información:
- Información del usuario (como ubicación, etc.)
- Información de comentarios (por ejemplo, si incluir información de imágenes, etc.)
- cuerpo de comentarios
Antes de ingresar oficialmente a este paso, debemos importar las siguientes bibliotecas de código, algunas de las cuales se utilizarán en el paso de modelado de datos:
import numpy as np
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
import langid
import re
import emoji
from sklearn.preprocessing import MultiLabelBinarizer
import demoji
import random
from random import sample
import itertools
from collections import Counter
import matplotlib.pyplot as pltLa aplicación de información de usuario e información de comentarios se refleja principalmente en la parte de BI, y la parte de modelado se basa principalmente en los datos del corpus de comentarios. Necesitamos tomar métodos apropiados de limpieza, segmentación de palabras y modelado de acuerdo con el lenguaje del comentario. Primero, recuperamos datos de la base de datos, lo que se puede lograr a través del siguiente código.
Datos de comentarios chinos:
df = pd.read_sql('SELECT * FROM "上海_上海_外滩_source_review"', engine)
df.shape
Datos de revisión en inglés:
df = pd.read_sql('SELECT * FROM "Shanghai_Shanghai_The Bund (Wai Tan)_source_review_EN"', engine)
df.shape
Rastreamos 171 páginas de comentarios en el sitio web de la versión china, con 10 comentarios por página, con un total de 1710 comentarios; en el sitio web de la versión internacional, capturamos 200 páginas de comentarios, con un total de 2000 comentarios.
1. Procesamiento de tipos de datos
Dado que los datos escritos en la base de datos son todos de tipo cadena, primero debemos revisar y convertir el tipo de datos de cada columna de datos. En los datos de comentarios chinos, las variables que deben transformarse son el tiempo de comentario y la calificación.
df['comment_date'] = pd.to_datetime(df['comment_date'])
df['rating'] = df['rating'].astype(str)
df['comment_year'] = df['comment_date'].dt.year
df['comment_month'] = df['comment_date'].dt.month2. Comprender el estado de los datos
Antes de tratar con valores nulos y transformar datos, podemos navegar brevemente por los datos y tener una comprensión preliminar de la situación del valor nulo.
df.isnull().sum()La situación general del valor nulo de los datos de comentarios chinos es la siguiente:

A diferencia de los datos de revisión chinos, los datos de revisión en inglés necesitan procesar más datos en blanco, concentrados principalmente en las dos variables de ubicación del usuario y tipo de viaje.

3. Manejar valores nulos del tipo de viaje
Para variables con valores nulos, podemos obtener una comprensión general de sus características a través de las estadísticas de cada categoría de variables. Tomando como ejemplo el tipo de viaje (trip_type), existen 6 tipos de variables, una de ellas es el tipo de viaje no especificado por el usuario, y este tipo de datos existen en forma de valores nulos:
df.groupby(['trip_type']).size()
Debido a que el tipo de viaje es una variable categórica, en el caso de este proyecto, llenamos los valores nulos con la categoría "desconocido" o "NA".
Datos de comentarios chinos:
df['trip_type'] = df['trip_type'].fillna('未知')Datos de revisión en inglés:
df['trip_type'] = df['trip_type'].fillna('NA')En el análisis de texto de las reseñas chinas, los tipos de viajes se dividen en los siguientes seis tipos, que corresponden al inglés: viajes familiares, viajes de negocios, viajes en pareja, viajes en solitario, viajes con acompañantes y desconocidos. Para facilitar el análisis posterior, necesitamos crear una tabla de búsqueda para que coincida con los tipos de viaje de los dos idiomas.
zh_trip_type = ['全家游', '商务行', '情侣游', '独自旅行', '结伴旅行', '未知']
en_trip_type = ['Family', 'Business', 'Couples', 'Solo', 'Friends', 'NA']
trip_type_df = pd.DataFrame({'zh_type':zh_trip_type, 'en_type':en_trip_type})Luego escriba la tabla en la base de datos para su posterior análisis visual.
trip_type_df.to_sql("tripadvisor_TripType_lookup", engine, if_exists="replace", index=False)4. Procesar la información de ubicación del usuario en datos de comentarios en inglés
En los datos de comentarios en inglés, debido a que la ubicación del usuario es la información que el usuario completa, los datos regionales son muy confusos y no se completan en un cierto orden o lógica. Los campos de ciudad y país no solo deben manejar valores nulos, sino que también deben corregirse. Al obtener datos, nuestra lógica para obtener información de la región es:
- Si la información de la región está separada por comas, la primera palabra es ciudad y la última palabra es país/provincia
- Si no hay coma, la información predeterminada es la información del país.
Para el análisis de revisión de la versión internacional del sitio web, optamos por subdividir la ubicación de los usuarios a nivel de país. Tenga en cuenta que debido a que muchos usuarios tienen problemas con errores de ortografía o con nombres de lugares falsos, nuestro objetivo es corregir la información tanto como sea posible, como corregir mayúsculas, abreviaturas, información de la ciudad correspondiente, etc. Aquí, nuestra solución específica es:
- Extraiga el país/provincia abreviado y procéselo por separado (principalmente Estados Unidos, los usuarios solo completan el nombre del estado cuando completan la información regional)
- Ver información del país que no sea abreviaturas. Si el nombre del país no aparece en la lista de países, se considera que es información de la ciudad
- Si el nombre de la ciudad se completa incorrectamente en el campo del país (como una ciudad grande) y hay errores ortográficos, debe modificarse manualmente
Tenga en cuenta que los nombres de países y regiones utilizados en este proyecto se refieren a la fuente de información de nombres de países y la fuente de los estados de EE. UU . y sus abreviaturas .
Primero, leemos la información del país del sistema de archivos:
country_file = open("countries.txt", "r")
country_data = country_file.read()
country_list = country_data.split("\n")
countries_lower = [x.lower() for x in country_list]
读取美国州名及其缩写信息:
state_code = pd.read_csv("state_code_lookup.csv")La siguiente ecuación puede leer una cadena de nombres de países y determinar si se necesita limpieza y modificación:
def formating_country_info(s_input):
if s_input is None: #若字符串输入为空值,返回空值
return None
if s_input.strip().lower() in countries_lower: #若字符串输入在国家列表中,返回国家名
c_index = countries_lower.index(s_input.strip().lower())
return country_list[c_index]
else:
if len(s_input) == 2: #若输入为缩写,在美国州名、墨西哥省名和英国缩写中查找,若可以找到,返回对应国家名称
if s_input.strip().upper() in state_code["code"].to_list():
return "United States"
elif s_input.strip().upper() == "UK":
return "United Kingdom"
elif s_input.strip().upper() in ("RJ", "GO", "CE"):
return "Mexico"
elif s_input.strip().upper() in ("SP", "SG"):
return "Singapore"
else:
# could not detect country info
return None
else: #其他情况,需要手动修改国家名称
if s_input.strip().lower() == "caior":
return "Egypt"
else:
return NoneAhora que tenemos una ecuación que limpia un solo valor, podemos aplicar esa ecuación a las columnas de Pandas DataFrame que representan la información del país a través de la función .apply().
df["location_country"] = df["location_country"].apply(formating_country_info)Luego, verifique el resultado de la limpieza:
df["location_country"].isnull().sum()![]()
Notamos que el número de valores nulos ha aumentado, además de corregir algunos datos, para algunos nombres de lugares inexistentes, la ecuación anterior los convertirá en valores nulos. A continuación, tomemos la información de la ciudad y completemos la variable de país con información sobre países que podrían clasificarse como ciudades. Podemos filtrar la información que puede estar fuera de lugar según el nombre del país, y usar este tipo de información como el relleno de la información del país, y el resto son los nombres de las ciudades por defecto.
def check_if_country_info(city_list):
clean_list = []
country_fill_list = []
for city in city_list:
if city is None:
clean_list.append(None)
country_fill_list.append(None)
elif city.strip().lower() in countries_lower: #如城市变量中出现的是国家名,记录国家名称
c_index = countries_lower.index(city.strip().lower())
country_name = country_list[c_index]
if country_name == "Singapore": #如城市名为新加坡,保留城市名,如不是则将原先的城市名转换为空值
clean_list.append(country_name)
else:
clean_list.append(None)
country_fill_list.append(country_name)
else:
# format city string
city_name = city.strip().lower().capitalize()
clean_list.append(city_name)
country_fill_list.append(None)
return clean_list, country_fill_listEjecutando la ecuación anterior, obtendremos dos series, una son los datos limpios de la ciudad y la otra son los datos completos con información del país.
city_list, country_fillin = check_if_country_info(df["location_city"].to_list())Cree una nueva columna en los datos para almacenar la matriz llena de información del país.
df["country_fill_temp"] = country_fillinReemplace la información de la ciudad en los datos de comentarios en inglés, complete la columna recién creada en el valor vacío de la información del país y luego elimine la columna utilizada para completar.
df["location_city"] = city_list
df["location_country"] = df["location_country"].fillna(df["country_fill_temp"])
df = df.drop(columns=["country_fill_temp"])Hasta ahora, hemos explicado y completado los principios y la implementación del código de los pasos de recopilación, almacenamiento y limpieza de datos en este proyecto. Aunque el proceso de procesamiento de datos es arduo y largo, es muy valioso poder transformar grandes cantidades de datos sin procesar en datos útiles. Si está interesado en pasos de modelado de datos más avanzados y desea saber cómo implementar análisis de emoji, palabras clave de segmentación de palabras, análisis de sentimiento de texto, análisis de frecuencia de palabras de parte del discurso y clasificación de texto de modelo de tema de datos de texto, continúe pagando atención a las publicaciones de seguimiento del blog de Data Science Lab.
Referencias:
- Dai Bin | El mercado turístico del Festival de Primavera se abrió alto y la economía turística creció de manera constante durante todo el año
- West Lake Scenic Area recibe 2.9286 millones de turistas durante el Festival de Primavera
- Scrapy Vs Selenium Vs Beautiful Soup para Web Scraping
- Extraiga emojis de cadenas de Python y frecuencia de gráficos usando Spacy, Pandas y Plotly
- Modelado de temas con LSA, PLSA, LDA y lda2Vec
Parte de los datos de este artículo provienen de Internet, si hay alguna infracción, comuníquese para eliminar