Haga clic en la tarjeta a continuación para prestar atención a la cuenta pública " Automatic Driving Heart "
Productos secos ADAS Jumbo, puedes conseguirlo
Hoy, Heart of Autonomous Driving tiene el honor de invitar a Wrysunny a compartir el último progreso de la percepción de BEV BEV-IO. Wrysunny también es nuestro autor firmado. Si tiene un trabajo relacionado para compartir, contáctenos al final del artículo.
>>Haga clic para ingresar → El corazón de la conducción autónoma [Percepción BEV] Grupo de intercambio técnico
El corazón del piloto automático Autor | Wrysunny
Editor | El corazón del piloto automático
BEV-IO: la ocupación de instancias lidera una nueva era y libera la inspección 3D bajo BEV

标题:BEV-IO: mejora de la detección 3D a vista de pájaro con ocupación de instancias
Papel: https://arxiv.org/pdf/2305.16829.pdf
guía
En este artículo, proponemos un nuevo método de detección 3D llamado BEV-IO, cuyo objetivo es mejorar la representación de la vista de pájaro (BEV) y proporcionar información más completa sobre la estructura de la escena 3D. Las representaciones BEV tradicionales mapean características de imágenes 2D en un espacio frustum y se basan en distribuciones de profundidad predichas explícitamente. Sin embargo, la distribución de profundidad solo puede caracterizar la información geométrica 3D de la superficie de los objetos visibles y no puede capturar su espacio interno y su estructura geométrica general , lo que genera representaciones 3D escasas e insatisfactorias. Para abordar este problema, BEV-IO presenta un nuevo método de detección 3D que aumenta las representaciones de BEV con información de ocupación de instancias. En el corazón del método se encuentra un módulo de Predicción de ocupación de instancias (IOP) recientemente diseñado, que tiene como objetivo inferir el estado de ocupación a nivel de punto de cada instancia en el espacio frustum . Para garantizar la eficiencia del entrenamiento y mantener la flexibilidad expresiva, el módulo se entrena con una combinación de supervisión explícita e implícita . Con la información de ocupación prevista, diseñamos un mecanismo de propagación de características (GFP) consciente de la geometría, que realiza operaciones de autoatención basadas en la distribución de ocupación en cada rayo en el frustum para garantizar la consistencia de características a nivel de instancia. Al combinar el módulo IOP con el mecanismo GFP, el detector BEV-IO puede generar estructuras de escenas 3D altamente informativas con representaciones BEV más completas. Los resultados experimentales muestran que BEV-IO es capaz de superar los métodos de última generación mientras agrega solo parámetros insignificantes (0,2 %) y sobrecarga computacional (0,24 % de aumento en GFLOP).
motivación de investigación
Los métodos BEV se utilizan ampliamente en la inspección 3D, y los métodos basados en cámaras son más rentables que los métodos basados en LiDAR y muestran un gran potencial en aplicaciones prácticas como la conducción autónoma y la robótica. Los métodos basados en cámaras se dividen principalmente en dos escuelas, que difieren en si estiman explícitamente la distribución de la profundidad de la escena.
Los métodos implícitos evitan estimar las distribuciones de profundidad mediante el uso de mecanismos de consulta y atención de BEV para generar implícitamente características de BEV a partir de imágenes de vistas múltiples. Sin embargo, la falta de información de profundidad hace que los métodos implícitos sean propensos a sobreajustarse a los casos extremos.
Los métodos explícitos logran representaciones BEV mapeando primero las características de la imagen 2D en el espacio frustum de acuerdo con la profundidad estimada y luego proyectando las características en el espacio BEV. Este enfoque utiliza explícitamente información de profundidad para generar representaciones BEV, lo que permite una detección 3D más confiable.
En general, el enfoque basado en cámaras es relativamente más rentable y muestra ventajas potenciales en muchas aplicaciones prácticas. Sin embargo, el método implícito tiene el riesgo de sobreajuste, mientras que el método explícito puede obtener una representación precisa de BEV de manera más confiable. Necesitamos sopesar las diferentes ventajas y desventajas al elegir un método y decidir qué método usar de acuerdo con los requisitos específicos de la aplicación.
Los enfoques explícitos en la construcción de características BEV involucran principalmente dos aspectos clave: la forma de mapear características 2D al espacio BEV y qué características mapear . La clave del primero radica en la percepción geométrica 3D. Los métodos LSS anteriores proponen un proceso de mapeo 2D-BEV y aprenden implícitamente la profundidad a través de la realidad básica de los cuadros delimitadores de BEV. LSS carece del valor real de la profundidad, se centra principalmente en la profundidad del área del objeto y tiene un rendimiento de profundidad deficiente en toda la escena. Algunos estudios han intentado utilizar valores de verdad de terreno dispersos para supervisar la estimación de profundidad, lo que mejora significativamente la precisión de la estimación de profundidad.
Sin embargo, estos métodos todavía se enfrentan a dos problemas importantes.
En primer lugar, la información de profundidad solo puede caracterizar la superficie de los objetos visibles, pero no puede capturar su espacio interno o su geometría general , lo que da como resultado representaciones 3D escasas en el espacio BEV.
En segundo lugar, muchas instancias son relativamente pequeñas y lejanas, y la densidad de los puntos LiDAR reales es muy baja , y las estimaciones de profundidad aprendidas de estas escasas supervisiones pueden no ser óptimas.
En resumen, los problemas que enfrentan los métodos explícitos en la construcción de características BEV son la precisión de la estimación de profundidad y la escasez de representación.
Contribuyó a este artículo
El método BEV-IO propuesto en este documento tiene como objetivo resolver los dos problemas anteriores mediante el uso de información de ocupación de instancias. La ocupación de instancias representa la probabilidad de que un punto 3D esté ocupado por un objeto. A diferencia de la profundidad, puede capturar la información geométrica espacial 3D integral de la escena.
Presenta un módulo de predicción de ocupación de instancias (IOP), y el IOP se entrena a través de métodos de entrenamiento explícitos e implícitos. El enfoque de entrenamiento explícito aprovecha las anotaciones de los cuadros delimitadores 3D como una fuerte señal de supervisión, mientras que la estrategia de entrenamiento implícita mejora el rendimiento de la predicción de ocupación a través de la optimización de extremo a extremo, lo que da como resultado un entrenamiento más flexible. Al combinar estrategias de entrenamiento explícitas e implícitas, el módulo IOP puede poblar la estructura interna de los objetos y generar una representación BEV más completa y específica de la instancia, independiente de la verdad del terreno disperso.
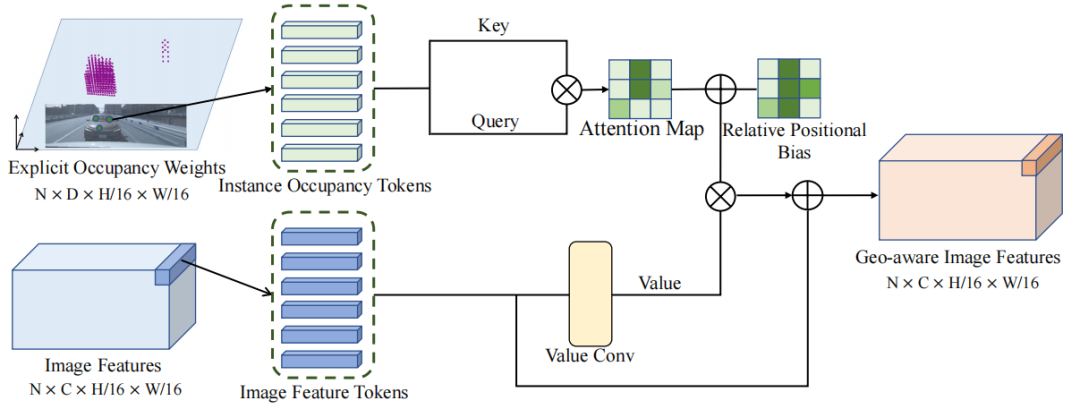
Para la segunda pregunta (qué características mapear): un mecanismo de propagación de características consciente de la geometría (GFP) está diseñado como una alternativa, utilizando señales geométricas para propagar características contextuales de la imagen, a lo largo de cada rayo de entrada con distribución de ocupación autoatención a la imagen Las características se transfieren e incorporan a la información de la estructura geométrica ocupada para capturar mejor la estructura espacial interna del objeto.
Mire la figura a continuación, (a) use el peso de profundidad estimado para mapear las características de la imagen en el espacio BEV, el peso de profundidad solo contiene la información de la superficie visible y no puede proporcionar información completa de la estructura geométrica; (b) introduce la ocupación peso sobre el peso de profundidad, además de transmitir características de imagen conscientes de la geometría a través de señales de ocupación.
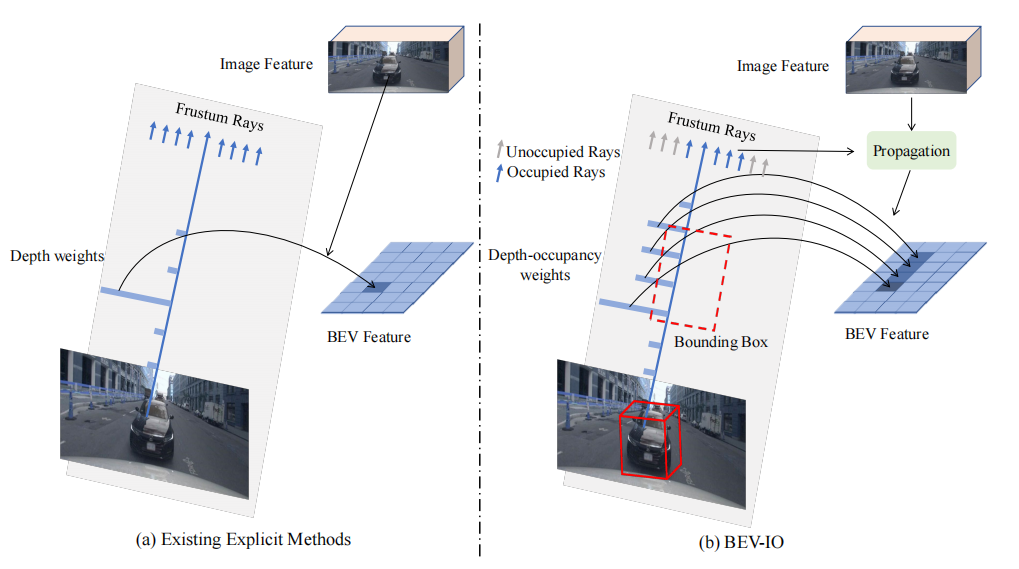
Introducción a los métodos existentes
1. Detección de objetos 3D de vista múltiple
Todos los métodos existentes siguen un paradigma unificado: características de la imagen del proyecto en el espacio BEV para la detección. Estos métodos se pueden dividir en métodos explícitos y métodos implícitos según sus diferentes métodos de proyección. Los métodos explícitos proyectan características de imagen al espacio BEV a través de mapas de características, mientras que los métodos implícitos lo hacen mediante consultas de características. La introducción de los dos es la siguiente:
(1) Método de detección implícito basado en BEV
El método implícito no se basa en información geométrica explícita, sino que utiliza un mecanismo de atención para obtener características BEV. Los métodos implícitos existentes incluyen BEVFormer, BEVFormerv2, PETR, DA-BEV, OA-BEV y FrustumFormer, entre otros. Manejan las funciones BEV de diferentes maneras. Por ejemplo, BEVFormer utiliza una estructura de columnas para un mecanismo de atención cruzada deformable, BEVFormerv2 introduce un detector de perspectiva, PETR mejora la percepción geométrica de las características de BEV a través de la codificación posicional, DA-BEV mejora aún más la relación entre la información espacial de BEV y la profundidad prevista, OA -BEV aprovecha las características de la nube de puntos de instancia para mejorar el rendimiento de detección, mientras que FrustumFormer aprovecha las máscaras de instancia y las máscaras de ocupación de BEV para mejorar las interacciones de características entre instancias. A diferencia de las máscaras de ocupación de BEV en FrustumFormer, BEV-IO predice directamente la ocupación de nivel de punto en el espacio 3D para ayudar mejor al proceso de extracción de características en métodos explícitos.
(2) Método de detección explícito basado en BEV
La idea central de los métodos de detección explícitos basados en BEV es usar información geométrica para mapear características de imágenes 2D en el espacio BEV. Algunos métodos (LSS) utilizan ponderaciones de profundidad para mapear entidades en el espacio frustum y luego proyectar en el espacio BEV; mientras que otros (BEVDepth) utilizan la supervisión de profundidad GT para mejorar la precisión de la estimación de profundidad; además, existen algunos métodos que introducen información temporal ( BEVDet4D) o mecanismos multivista (BEVStereo, STS) mejoran aún más el rendimiento. Todos estos métodos tienen ciertas limitaciones: no pueden representar de forma completa y precisa la estructura geométrica en el espacio BEV.
2. Predicción de ocupación
La predicción de ocupación es predecir el estado de ocupación de un punto 3D o vóxel en un espacio determinado. En la detección de objetos 3D basada en BEV, el objetivo de la predicción de ocupación es estimar la probabilidad de que un punto o vóxel 3D esté ocupado por un objeto. Proporciona información sobre qué partes del espacio es probable que contengan objetos y qué partes es probable que estén vacías o en segundo plano.
Varios estudios proponen diferentes enfoques para predecir el estado de ocupación de los elementos espaciales:
MonoScene propone un método para predecir estados de ocupación mediante la estimación de troncos de profundidad;
OccDepth utiliza antecedentes de visión estéreo para estimar la profundidad métrica, lo que mejora la precisión de la predicción del estado de ocupación;
Voxformer es un enfoque de dos etapas que separa la predicción del estado de ocupación de la predicción de la clase de objeto;
TPVFormer propone un método para estimar el estado de ocupación utilizando características de tres vistas;
OpenOccupancy realiza una anotación densa de los estados de ocupación en el conjunto de datos nuscenes.
Método en este documento
Basado en BEV explícito
Primero, las imágenes de seis vistas se ingresan en un codificador de imágenes previamente entrenado para obtener las características de la imagen, donde , y denotan la altura, el ancho y la dimensión del mapa de características, respectivamente. A diferencia del método implícito, el método explícito estima el tronco de profundidad para cada vista, donde el tronco de profundidad representa la probabilidad de diferentes intervalos de profundidad establecidos manualmente a lo largo de cada rayo en el tronco, y representa el número de intervalos de profundidad. La característica de la imagen frustum se puede obtener ponderando las características de la imagen con la profundidad frustum:
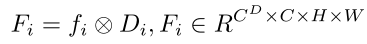
Los frustums de características de imagen desde múltiples perspectivas se asignan para obtener las representaciones de espacio 3D correspondientes, y se proyectan a BEV mediante el espacio de operación de agrupación de vóxeles (combinación de valores de vóxeles en múltiples espacios 3D en un solo valor), la descripción matemática es la siguiente:
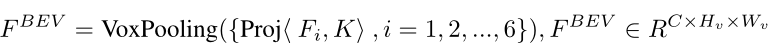
En los métodos basados en cámaras, la matriz intrínseca K de la cámara se utiliza para convertir las coordenadas de píxeles de la imagen en direcciones de rayos en el espacio 3D. Los parámetros internos de la cámara incluyen información como la distancia focal, las coordenadas del punto principal y los parámetros de distorsión de la cámara, que describen las características geométricas internas de la cámara.
La operación de proyección (Proj) utiliza la matriz de parámetros intrínsecos K de la cámara y la información de profundidad para mapear las características de la imagen del espacio de imagen 2D al espacio 3D. Específicamente, para cada punto de píxel (x, y) de la imagen, la operación de proyección puede calcular la dirección del rayo correspondiente, es decir, asignar las coordenadas bidimensionales a un rayo en el espacio tridimensional. La dirección de este rayo se puede determinar mediante los parámetros intrínsecos de la cámara y la información de profundidad, para asignar las características de la imagen a las posiciones espaciales tridimensionales correspondientes.
La agrupación de vóxeles (VoxPooling) es el proceso de convergencia de valores de características en un espacio tridimensional en un espacio BEV. En este proceso, los valores de las características de los vóxeles adyacentes (píxeles de volumen en el espacio 3D) se fusionan para generar características BEV. La agrupación de vóxeles se puede realizar de diferentes maneras, como la agrupación promedio o la agrupación máxima, para la reducción de la dimensionalidad y la agregación de características de vóxeles para generar representaciones BEV.
Arquitectura BEV-IO
Consta de tres partes principales: codificador de imagen, convertidor de vista y cabezal de detección. Aquí, el codificador de imagen y el cabezal de detección son los mismos que BEVDepth, por lo que no presentaré demasiado, principalmente el convertidor de vista. El convertidor de vista emplea dos ramas: rama de geometría 3D y rama de propagación de características.
(1) La rama de geometría 3D consta de un decodificador de profundidad y dos decodificadores de predicción de ocupación de instancia. El decodificador de profundidad se usa para predecir ponderaciones de profundidad, mientras que el decodificador de predicción de ocupación de instancias se usa para predecir ponderaciones de ocupación de instancias dentro del espacio frustum. Estos decodificadores están supervisados y comparados con GT. Las ponderaciones de profundidad y las ponderaciones de ocupación de instancias se fusionan en ponderaciones de ocupación de profundidad, que proyectan características de imagen en un espacio frustum.
(2) El núcleo de la rama de propagación de características es el módulo de propagación de características consciente de la geometría (GFP). Este módulo toma pesos de ocupación de instancias explícitos y características de imagen como entrada para generar características con reconocimiento de geometría. Estas características se proyectarán en el espacio frustum, formando características BEV.
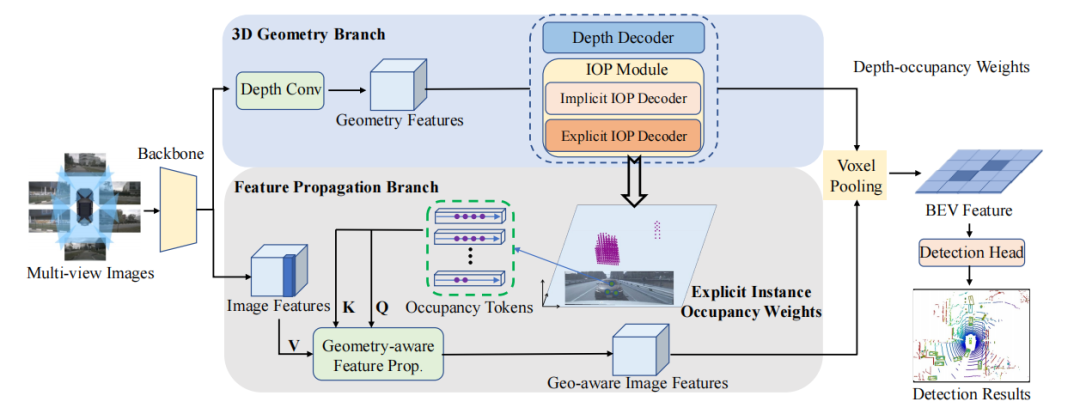
Mirando todo el proceso, la rama de geometría 3D recibe las características de la imagen extraídas por la red troncal como entrada para estimar la profundidad y los pesos de ocupación de instancia explícitos/implícitos. Estos pesos se fusionan para generar pesos de ocupación de profundidad. La rama de propagación de características a continuación también recibe características de imagen y pesos de ocupación de instancia explícitos como entrada, y luego mejora aún más las características de imagen a través de un módulo de propagación con reconocimiento de geometría, que incorpora información geométrica. Posteriormente, las características conscientes de la geometría adquiridas se proyectan en el espacio BEV utilizando pesos de ocupación de profundidad. Finalmente, pase las funciones BEV a través del cabezal de detección para obtener el resultado final.
Rama de geometría 3D
Este documento propone un método que utiliza información de ocupación de instancias a nivel de punto para ayudar a la proyección de características a resolver el problema de la proyección de características incompletas al espacio BEV utilizando solo información de profundidad.
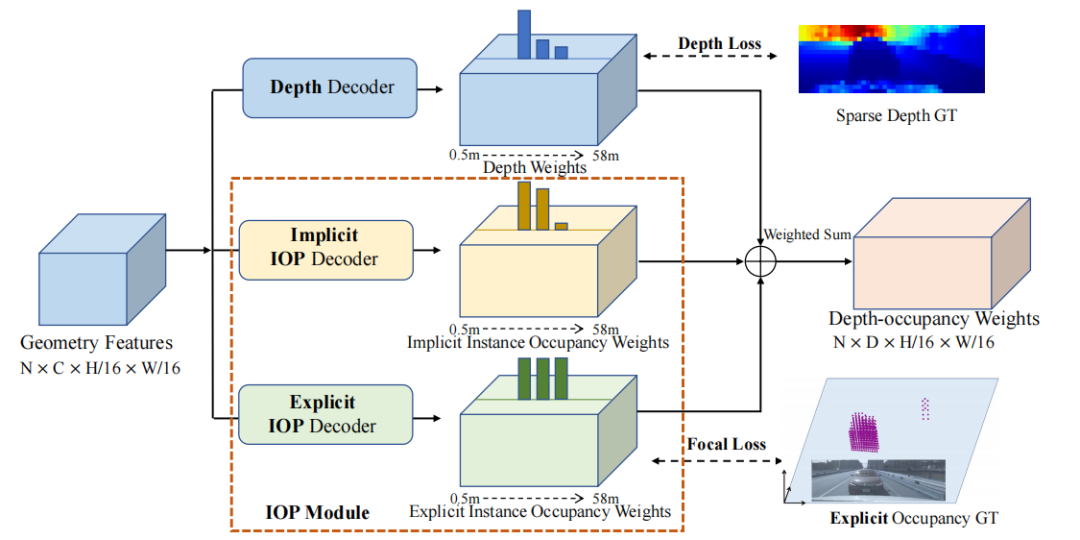
Como se puede ver, la rama de geometría 3D toma las características de la imagen como entrada para predecir la profundidad, los pesos de ocupación de instancias explícitos y los pesos de ocupación de instancias implícitas. Los pesos de ocupación de instancias explícitas y de profundidad son supervisados por la profundidad de GT y la ocupación de instancias explícitas generadas. El peso de ocupación de instancia implícito aprende una representación de ocupación implícita, y el peso de ocupación de profundidad es una suma ponderada de estos tres pesos.
Decodificador de profundidad: basado en BEV depth, se utiliza un decodificador de profundidad para predecir un conjunto de pesos de profundidad correspondientes a un conjunto de intervalos de profundidad diseñados manualmente. Y aprendizaje supervisado a través de pérdida de entropía cruzada binaria:
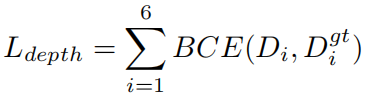
Decodificador IOP implícito: el decodificador de predicción de ocupación de instancia implícita predice la probabilidad de ocupación del intervalo de profundidad del objeto, y el peso de profundidad solo puede capturar la información de la superficie visible del objeto y no puede representar completamente el espacio interno del objeto. Para completar la información faltante, el decodificador IOP implícito predice la probabilidad de ocupación de diferentes intervalos de profundidad en cada rayo a partir de las características de la imagen de entrada de manera integral y reemplaza el entrenamiento supervisado de GT con el objetivo general de optimizar los resultados de detección.
Decodificador de IOP explícito: anotar manualmente la información de ocupación a nivel de punto requiere mucho tiempo y es laborioso. Los autores usan las etiquetas de los cuadros delimitadores 3D para construir etiquetas de ocupación y modelar las etiquetas de ocupación como un problema de clasificación binaria en el espacio frustum: los puntos se etiquetan 1, de lo contrario 0. Sabemos que al ajustar los parámetros α y γ en Focal loss, se puede realizar el ajuste dinámico de los pesos de muestra, de modo que el modelo pueda enfocarse en muestras difíciles, por lo que Focal loss también se usa aquí para reducir el impacto del desequilibrio de categoría:
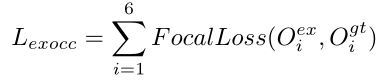
El peso de ocupación de profundidad final se obtiene de la siguiente manera:
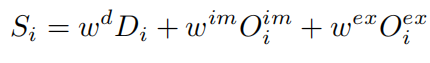
Generación GT de ocupación a nivel de punto: este es un método para entrenar y evaluar modelos que determina el estado de ocupación de los puntos al dividir el cuadro delimitador del objeto 3D en el interior y el exterior del cuadro. Estos son los pasos específicos:
Para cada cuadro delimitador de objeto 3D, su espacio se divide en dos partes dentro y fuera del cuadro. Esto se puede determinar mediante las coordenadas del vértice del cuadro delimitador o las coordenadas mínimas y máximas del cuadro delimitador.
Para cada punto para el que se van a generar etiquetas de ocupación a nivel de punto, calcule su producto escalar con los vectores normales de las seis caras del cuadro delimitador. Este producto escalar se puede utilizar para determinar la posición del punto en relación con el cuadro delimitador.
Si un punto está dentro de las seis caras del cuadro delimitador, es decir, el producto escalar vectorial normal del punto y todas las caras del cuadro delimitador es positivo, entonces se considera que el punto es un punto ocupado por el objeto; a la inversa, si un punto está dentro del cuadro delimitador, es decir, el producto escalar vectorial normal del punto y cualquier cara del cuadro delimitador es negativo, entonces se considera que el punto no está ocupado por ningún objeto.
El pseudocódigo en el documento es el siguiente:

propagación de características
Para cada punto de característica, su peso de ocupación explícito se utiliza como clave y consulta del mecanismo de autoatención. El mecanismo de autoatención puede calcular la salida de acuerdo con la clave de entrada, la consulta y el valor. En este caso, Key y Query se generan a partir de pesos de ocupación, mientras que los valores son características de la imagen. Mediante un mecanismo de autoatención computacional, las características de los puntos característicos se pueden propagar en la misma instancia. Esto significa que los puntos de características con pesos de ocupación similares se influirán entre sí y propagarán las características de los demás, y esta propagación de características basada en información geométrica garantiza la coherencia de las características dentro de la misma área de objeto.
Función de pérdida
La pérdida total es una combinación ponderada de pérdida de detección, pérdida de profundidad y pérdida de ocupación:
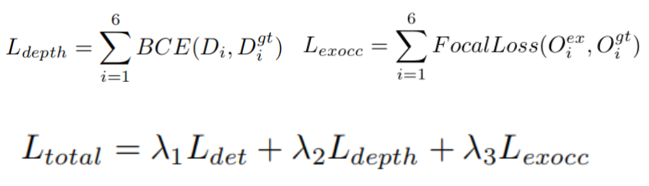
La contribución de cada pérdida se determina ajustando el peso de pérdida λ . El peso específico generalmente se ajusta de acuerdo con las características de tareas específicas y conjuntos de datos. En este artículo, λ se establece de antemano.
experimento
Algunas introducciones:
Conjunto de datos: el conjunto de datos utilizado es el conjunto de datos nuScenes, un conjunto de datos de conducción autónoma a gran escala que contiene escenarios de conducción urbanos complejos con más de 1000 escenas, anotadas con 1,4 millones de cuadros delimitadores 3D en 10 categorías. Estas escenas cubren diferentes climas, condiciones de iluminación y escenarios de tráfico en Boston y Singapur.
División del conjunto de datos: la escena del conjunto de datos se divide oficialmente en conjuntos de entrenamiento, verificación y prueba, con una proporción de 700/150/150.
Indicadores de evaluación: al evaluar el rendimiento del método BEV-IO, se utilizan una serie de indicadores de evaluación proporcionados oficialmente por el conjunto de datos de nuScenes. Estas métricas incluyen NuScenes Detection Score (NDS) y Mean Mean Precision (mAP), que miden la precisión de las tareas de detección de objetos. Además, se utilizaron el error medio de traducción (mATE), el error medio de escala (mASE), el error medio de orientación (mAOE), el error medio de velocidad (mAVE) y el error medio de atributo (mAAE) para evaluar los errores de localización, escala, orientación y velocidad en propiedades, etc
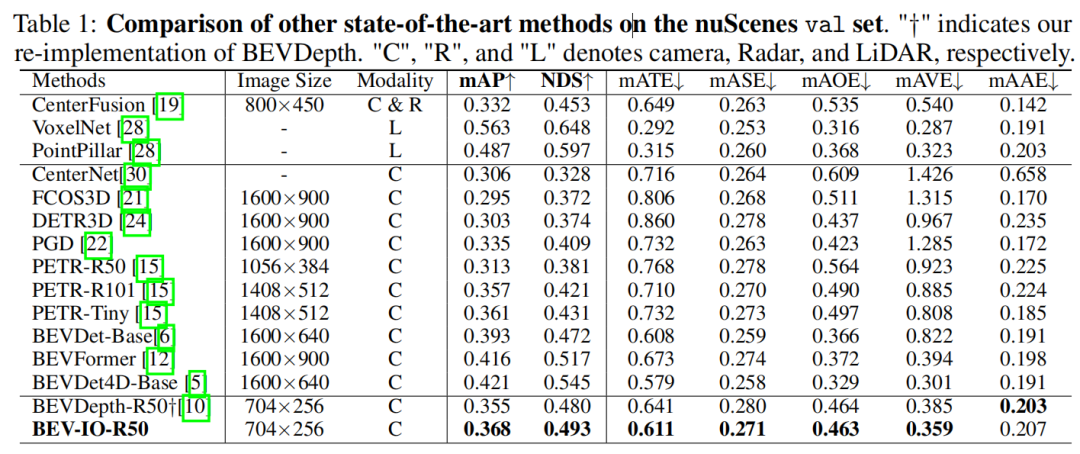
Los experimentos comparativos se llevan a cabo con otros métodos basados en BEV y, para ser justos, todos los métodos se entrenan utilizando la estrategia CBGS. BEV-IO es superior al método BEVDepth, y solo aumenta los parámetros de 0.15M y el cálculo de 0.6 GFLOPS
El siguiente es el experimento de ablación, primero de los tres componentes mencionados por BEV-IO:

Para verificar una pregunta: si aún se requiere información de ocupación de la instancia cuando la profundidad estimada es lo suficientemente precisa. Por lo tanto, el decodificador de profundidad se elimina en BEV-IO, y la profundidad real se usa directamente como entrada de la codificación one-hot.Otro caso es eliminar la información de ocupación de la instancia sobre esta base. En otras palabras, lo primero significa que la información de profundidad es suficiente, y lo segundo significa que la instancia no se utiliza para ocupar la información cuando la información de profundidad es suficiente. La comparación entre los dos es la siguiente. La precisión de todos los aspectos es reducido al eliminar Instancia Occ:

A continuación, la comparación de los parámetros y la complejidad computacional de cada método.Comparado con la línea de base, BEV-IO solo aumenta un 0,2 % los parámetros y un 0,24 % los GFLOP, mientras que otros indicadores han mejorado:

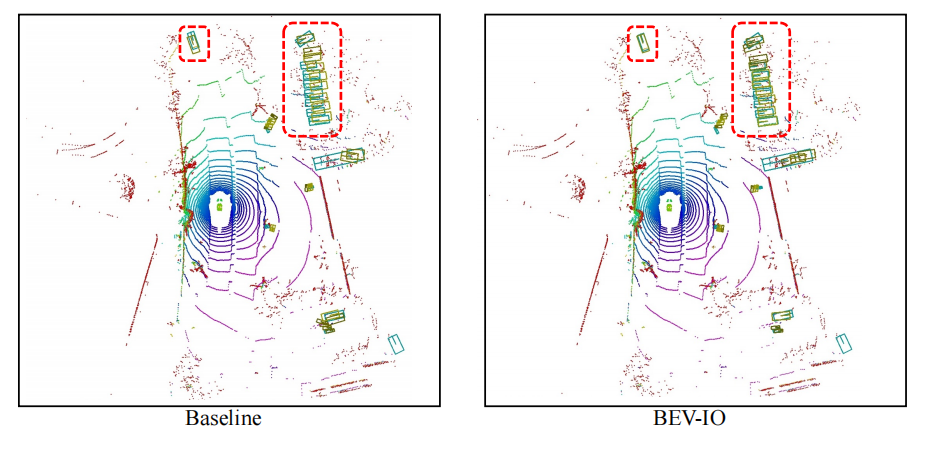
Finalmente, la visualización de los resultados de detección, los resultados de predicción de BEV-IO están más cerca de GT (cuadro amarillo: cuadro de predicción; verde: GT)
Resumir
En este trabajo, los autores proponen el método BEV-IO para abordar la limitación de profundidad al capturar la instancia completa. Diseñan un módulo de predicción de ocupación de instancias que puede estimar explícita e implícitamente la información de ocupación a nivel de punto de instancia, lo que permite una representación de características de BEV más completa. Además, se introduce un mecanismo de propagación de características que tiene en cuenta la geometría para propagar de manera efectiva las características de la imagen mediante la explotación de señales geométricas. Los resultados experimentales muestran que su método supera los métodos actuales de última generación con solo un aumento insignificante en el aumento de parámetros y la sobrecarga computacional, con una mejor compensación en el rendimiento.
El colaborador es un invitado especial de " Knowledge Planet of the Heart of Automated Driving ". Si desea compartirlo en la plataforma Heart of Automated Driving, ¡contáctenos!
(1) ¡El video curso está aquí!
El corazón de la conducción autónoma reúne fusión de visión de radar de ondas milimétricas, mapas de alta precisión, percepción BEV, calibración multisensor, despliegue de sensores, percepción cooperativa de conducción autónoma, segmentación semántica, simulación de conducción autónoma, percepción L4, planificación de decisiones, predicción de trayectoria , etc. Videos de aprendizaje en cada dirección, bienvenido a tomarlo usted mismo (escanee el código para ingresar al aprendizaje)

(Escanea el código para conocer el último video)
Sitio web oficial del vídeo: www.zdjszx.com
(2) La primera comunidad de aprendizaje de conducción autónoma en China
Una comunidad de comunicación de casi 1,000 personas y más de 20 rutas de aprendizaje de pila de tecnología de conducción autónoma, desea obtener más información sobre la percepción de conducción autónoma (clasificación, detección, segmentación, puntos clave, líneas de carril, detección de objetos 3D, Ocupación, fusión de sensores múltiples, seguimiento de objetos, estimación de flujo óptico, predicción de trayectoria), posicionamiento y mapeo de conducción automática (SLAM, mapa de alta precisión), planificación y control de conducción automática, soluciones técnicas de campo, implementación de implementación de modelos de IA, tendencias de la industria, publicaciones de trabajo, bienvenido a escanear el Código QR a continuación, Únase al planeta del conocimiento del corazón de la conducción autónoma, este es un lugar con productos secos reales, intercambie varios problemas para comenzar, estudiar, trabajar y cambiar de trabajo con los grandes en el campo, comparta papeles + códigos + videos diarios , esperamos el intercambio!

(3) [ Corazón de la conducción automatizada ] Grupo de intercambio de tecnología de pila completa
El corazón de la conducción autónoma es la primera comunidad de desarrolladores para la conducción autónoma, que se centra en la detección de objetos, la segmentación semántica, la segmentación panorámica, la segmentación de instancias, la detección de puntos clave, las líneas de carril, el seguimiento de objetos, la detección de objetos en 3D, la percepción de BEV, la fusión de sensores múltiples, SLAM, estimación de flujo de luz, estimación de profundidad, predicción de trayectoria, mapa de alta precisión, NeRF, control de planificación, implementación de modelos, prueba de simulación de conducción automática, administrador de productos, configuración de hardware, búsqueda de trabajo y comunicación de IA, etc.;

Agregue la invitación de Autobot Assistant Wechat para unirse al grupo
Observaciones: escuela/empresa + dirección + apodo