Directorio de artículos
Conceptos básicos de Airflow
descripción general
Airflow es una plataforma para crear, programar y monitorear flujos de trabajo mediante programación.
Usa Airflow para escribir un flujo de trabajo en un gráfico acíclico dirigido (DAG) de tareas. El programador de Airflow ejecuta tareas en un conjunto de subprocesos de trabajo simultáneamente mientras sigue las dependencias especificadas. Las utilidades de comandos enriquecidos hacen que sea muy fácil realizar una programación compleja en los DAG. Una interfaz de usuario enriquecida facilita ver las canalizaciones en ejecución en producción, monitorear el progreso y solucionar problemas si es necesario.
sustantivo
(1) Dinámico : la configuración del flujo de aire requiere Python práctico, lo que permite canalizaciones de producción dinámicas. Esto permite escribir dinámicas. Esto permite escribir código que puede crear instancias dinámicamente de canalizaciones.
(2) Extensible : defina fácilmente sus propios operadores, ejecute programas y amplíe la biblioteca para adaptarla a su entorno.
(3) Elegante : Airlfow está optimizado, utiliza el potente motor de plantillas Jinja, con parametrización de secuencias de comandos integrada en el núcleo de Airflow.
(4) Escalable : Airflow tiene una arquitectura de bloque de plantilla y utiliza colas de mensajes para programar cualquier cantidad de tareas de trabajo.
Instalación de flujo de aire
Instalar el entorno de Python
Superset es una aplicación web escrita en lenguaje Python y requiere un entorno Python3.8.
Instalar Miniconda
Conda es un administrador de paquetes y entornos de código abierto que se puede usar para instalar diferentes versiones de Python de paquetes de software y sus dependencias en la misma máquina, y puede cambiar entre diferentes entornos de Python. Anaconda incluye Conda, Python y muchos kits de herramientas instalados, tales como: numpy, pandas, etc. Miniconda incluye Conda y Python.
Aquí no necesitamos tantos juegos de herramientas, así que elegimos MiniConda.
(1) Descargar Miniconda (versión Python3)
Dirección de descarga: https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
(2) Instalar Miniconda
Ejecute el siguiente comando para instalar y siga las indicaciones hasta que se complete la instalación.
[atguigu@hadoop102 lib]$ bash Miniconda3-latest-Linux-x86_64.sh
Durante el proceso de instalación, cuando aparezca el siguiente mensaje, puede especificar la ruta de instalación:
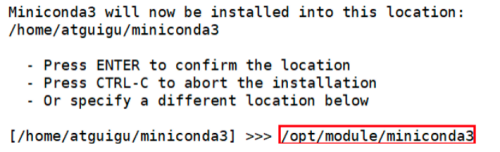
(3) Cargue el archivo de configuración de la variable de entorno para que tenga efecto
[atguigu@hadoop102 lib]$ source ~/.bashrc
(4) Desactivar el entorno base
Una vez completada la instalación de Miniconda, cada vez que se abra el terminal se activará su entorno base predeterminado, podemos deshabilitar la activación del entorno base predeterminado a través del siguiente comando.
[atguigu@hadoop102 lib]$ conda config --set auto_activate_base false
Crear un entorno Python3.8
(1) Configurar la duplicación nacional de conda
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
(base) [atguigu@hadoop102 ~]$ conda config --set show_channel_urls yes
(2) Crear un entorno python3.8
(base) [atguigu@hadoop102 ~]$ conda create --name airflow python=3.8
Descripción: Comandos comunes para la gestión del entorno conda:
- Crear entorno: conda create -n env_name
- Ver todos los entornos: conda info --envs
- Eliminar un entorno: conda remove -n env_name --all
(3) Activar el entorno de flujo de aire.
(base) [atguigu@hadoop102 ~]$ conda activate airflow
Descripción: Salir del entorno actual.
(superset) [atguigu@hadoop102 ~]$ conda deactivate
(4) Ejecute el comando python -V para ver la versión de python
(airflow) [atguigu@hadoop102 software]$ python -V
Python 3.8.13
Instalar flujo de aire
(1) Cambiar la fuente de pip
[atguigu@hadoop102 software]$ conda activate airflow
(airflow) [atguigu@hadoop102 software]$ pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
(airflow) [atguigu@hadoop102 software]$ sudo mkdir ~/.pip
(airflow) [atguigu@hadoop102 software]$ sudo vim ~/.pip/pip.conf
#添加以下内容
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn
(2) Instale el flujo de aire
(airflow) [atguigu@hadoop102 software]$ pip install "apache-airflow==2.4.3"
(3) Inicializar flujo de aire
(airflow) [atguigu@hadoop102 software]$ airflow db init
(4) Ver versión
(airflow) [atguigu@hadoop102 software]$ airflow version
2.4.3
(5) ruta de almacenamiento instalada de flujo de aire
(airflow) [atguigu@hadoop102 airflow]$ pwd
/home/atguigu/airflow
(6) Inicie el servicio web de flujo de aire y visite http://hadoop102:8080 en el navegador después del inicio
(airflow) [atguigu@hadoop102 airflow]$ airflow webserver -p 8080 -D

(7) Iniciar la programación del flujo de aire
(airflow) [atguigu@hadoop102 airflow]$ airflow scheduler -D
(8) Crear una cuenta
(airflow) [atguigu@hadoop102 airflow]$ airflow users create \
> --username admin \
> --firstname atguigu \
> --lastname atguigu \
> --role Admin \
> --email [email protected]
(9) Iniciar y detener secuencias de comandos
[atguigu@hadoop102 bin]$ vim af.sh
#!/bin/bash
case $1 in
"start"){
echo " --------启动 airflow-------"
ssh hadoop102 "conda activate airflow;airflow webserver -p 8080 -D;airflow scheduler -D; conda deactivate"
};;
"stop"){
echo " --------关闭 airflow-------"
ps -ef|egrep 'scheduler|airflow-webserver'|grep -v grep|awk '{print $2}'|xargs kill -15
};;
esac
Modificar la base de datos a MySQL
(1) Construir una base de datos en MySQL
mysql> CREATE DATABASE airflow_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
(2) Si se informa un error Error de Linux: 1425F102: Rutinas SSL: ssl_choose_client_version: protocolo no compatible, puede cerrar el certificado MySQL SSL
查看SSL是否开启 YES为开启
mysql> SHOW VARIABLES LIKE '%ssl%';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| have_openssl | YES |
| have_ssl | YES |
| ssl_ca | ca.pem |
| ssl_capath | |
| ssl_cert | server-cert.pem |
| ssl_cipher | |
| ssl_crl | |
| ssl_crlpath | |
| ssl_key | server-key.pem |
+---------------+-----------------+
(3) Modifique el archivo de configuración my.cnf y agregue el siguiente contenido:
# disable_ssl
skip_ssl
(4) Agregar dependencias de conexión de python:
Hay dos métodos introducidos en el sitio web oficial Aquí elegimos los siguientes conectores.
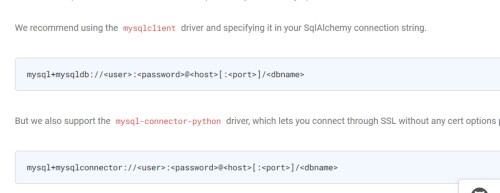
(airflow) [atguigu@hadoop102 airflow]$ pip install mysql-connector-python
(5) Modifique el archivo de configuración de flujo de aire:
[database]
# The SqlAlchemy connection string to the metadata database.
# SqlAlchemy supports many different database engines.
# More information here:
# http://airflow.apache.org/docs/apache-airflow/stable/howto/set-up-database.html#database-uri
#sql_alchemy_conn = sqlite:home/atguigu/airflow/airflow.db
sql_alchemy_conn = mysql+mysqlconnector://root:123456@hadoop102:3306/airflow_db
(6) Cierre el flujo de aire, reinicie después de la inicialización:
(airflow) [atguigu@hadoop102 ~]$ af.sh stop
(airflow) [atguigu@hadoop102 airflow]$ airflow db init
(airflow) [atguigu@hadoop102 ~]$ af.sh start
(7) Error de inicialización 1067: valor predeterminado no válido para 'update_at':
Motivo: el campo 'update_at' es del tipo de marca de tiempo y el rango de valores es: 1970-01-01 00:00:00 a 2037-12-31 23:59:59 (UTC +8 hora de Beijing desde 1970-01- 01 08: 00:00), y aquí se da un valor nulo por defecto, por lo que falla.
Se recomienda modificar el formato de la marca de tiempo de almacenamiento mysql:
mysql> set GLOBAL sql_mode ='STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
Reiniciar MySQL invalidará los parámetros. Se recomienda escribir los parámetros en el archivo de configuración my.cnf.
sql_mode = STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
(8) Volver a crear el inicio de sesión de la cuenta:
(airflow) [atguigu@hadoop102 airflow]$ airflow users create \
--username admin \
--firstname atguigu \
--lastname atguigu \
--role Admin \
--email [email protected]
Modificar el ejecutor
El sitio web oficial no recomienda el uso de ejecutores secuenciales en el desarrollo, lo que provocará el bloqueo de la programación de tareas.
Modifique el archivo de configuración de flujo de aire :
[core]
# The executor class that airflow should use. Choices include
# ``SequentialExecutor``, ``LocalExecutor``, ``CeleryExecutor``, ``DaskExecutor``,
# ``KubernetesExecutor``, ``CeleryKubernetesExecutor`` or the
# full import path to the class when using a custom executor.
executor = LocalExecutor
Se pueden usar o personalizar varios actuadores recomendados oficialmente. Aquí elegimos al ejecutor local.
despliegue
(1) Iniciar el entorno de prueba
Esta prueba utiliza el caso oficial de Spark, todos los servidores históricos que necesitan iniciar Hadoop y Spark.
[atguigu@hadoop102 bin]$ myhadoop.sh start
[atguigu@hadoop102 bin]$ cd /opt/module/spark-yarn/sbin/start-history-server.sh
(2) Ver el archivo de configuración de Airflow
(python3) [root@airflow work-py]# vim ~/airflow/airflow.cfg
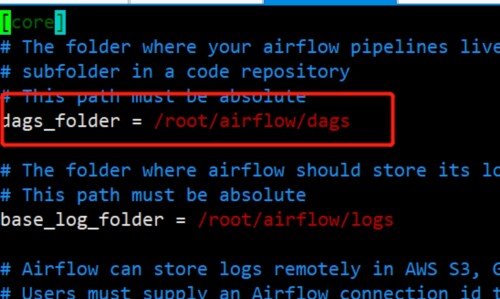
(3) Escriba un script .py y cree un directorio de trabajo-py para almacenar scripts de programación de python
(airflow) [atguigu@hadoop102 airflow]$ mkdir ~/airflow/dags
(airflow) [atguigu@hadoop102 airflow]$ cd dags/
(airflow) [atguigu@hadoop102 dags]$ vim test.py
#!/usr/bin/python
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = {
# 用户
'owner': 'test_owner',
# 是否开启任务依赖
'depends_on_past': True,
# 邮箱
'email': ['[email protected]'],
# 启动时间
'start_date':datetime(2022,11,28),
# 出错是否发邮件报警
'email_on_failure': False,
# 重试是否发邮件报警
'email_on_retry': False,
# 重试次数
'retries': 1,
# 重试时间间隔
'retry_delay': timedelta(minutes=5),
}
# 声明任务图
dag = DAG('test', default_args=default_args, schedule_interval=timedelta(days=1))
# 创建单个任务
t1 = BashOperator(
# 任务id
task_id='dwd',
# 任务命令
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
# 重试次数
retries=3,
# 把任务添加进图中
dag=dag)
t2 = BashOperator(
task_id='dws',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
t3 = BashOperator(
task_id='ads',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
# 设置任务依赖
t2.set_upstream(t1)
t3.set_upstream(t2)
-
El paquete debe ser importado
from airflow import DAG from airflow.operators.bash_operator import BashOperator -
default_args establece los argumentos predeterminados.
-
depend_on_past Si habilitar las dependencias de tareas.
-
schedule_interval frecuencia de programación.
-
reintentos El número de reintentos.
-
start_date hora de inicio.
-
BashOperator ejecuta específicamente la tarea. Si es verdadero, la tarea previa debe completarse con éxito antes de pasar a la siguiente tarea dependiente. Si es falso, ignorará si se completó con éxito.
-
task_id Id. único de la tarea (obligatorio).
-
bash_command Comando de ejecución para tareas específicas.
-
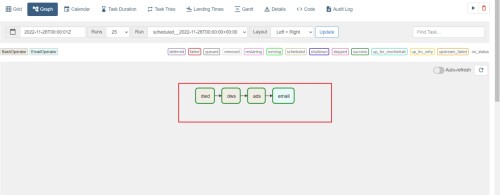
dependencias de configuración set_upstream Como se muestra en la figura anterior, la tarea de anuncios depende de la tarea dws y depende de la tarea dwd.
(4) Espere un momento y actualice la lista de tareas
(airflow) [atguigu@hadoop102 airflow]$ airflow dags list
-------------------------------------------------------------------
DAGS
-------------------------------------------------------------------
example_bash_operator
example_branch_dop_operator_v3
example_branch_operator
example_complex
example_external_task_marker_child
example_external_task_marker_parent
example_http_operator
example_kubernetes_executor_config
example_nested_branch_dag
example_passing_params_via_test_command
example_pig_operator
example_python_operator
example_short_circuit_operator
example_skip_dag
example_subdag_operator
example_subdag_operator.section-1
example_subdag_operator.section-2
example_trigger_controller_dag
example_trigger_target_dag
example_xcom
latest_only
latest_only_with_trigger
test
test_utils
tutorial
(5) Ha aparecido la tarea de prueba, actualice la página
(6) Haga clic para ejecutar

(7) Haga clic en la tarea exitosa para ver el registro

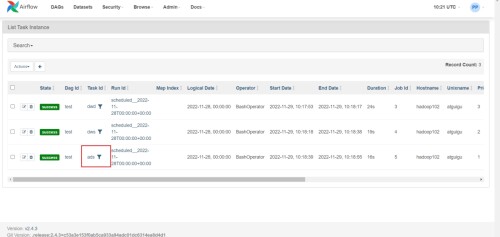

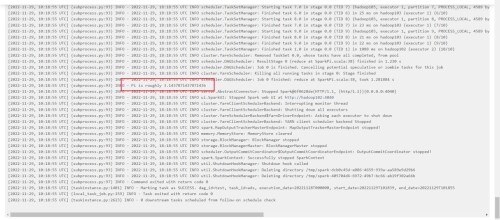
(8) Ver diagrama dag, diagrama de Gantt
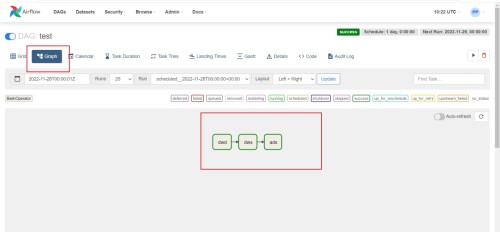
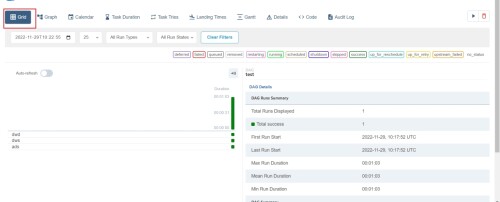
(9) Ver código de secuencia de comandos
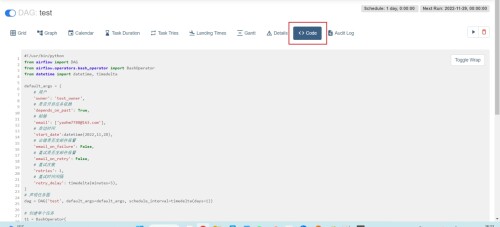
Operación de tarea Dag
Eliminar tarea Dag
La eliminación principal de la tarea DAG no eliminará los archivos subyacentes y se volverá a cargar automáticamente después de un tiempo.
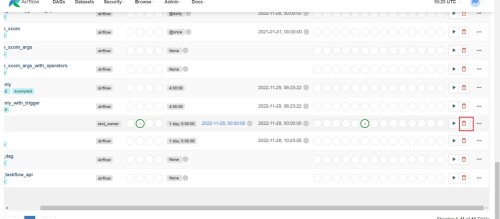
Ver todas las tareas de dag actuales
# 查看所有任务
(airflow) [atguigu@hadoop102 airflow]$ airflow list_dags
# 查看单个任务
(airflow) [atguigu@hadoop102 airflow]$ airflow tasks list test --tree
Configurar servidor de correo
(1) Asegúrese de que el buzón haya abierto el servicio SMTP
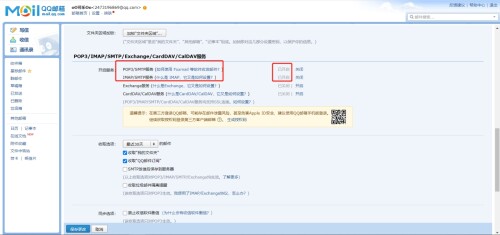
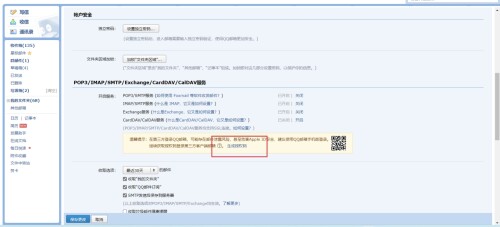
(2) Modifique el archivo de configuración del flujo de aire y use el servicio stmps para corresponder al puerto 587
(airflow) [atguigu@hadoop102 airflow]$ vim ~/airflow/airflow.cfg
smtp_host = smtp.qq.com
smtp_starttls = True
smtp_ssl = False
smtp_user = 403627000@qq.com
# smtp_user =
smtp_password = qluxdbuhgrhgbigi
# smtp_password =
smtp_port = 587
smtp_mail_from = 403627000@qq.com
(3) Reinicie el flujo de aire
[atguigu@hadoop102 bin]$ af.sh stop
[atguigu@hadoop102 bin]$ af.sh start
(4) Edite el script test.py y reemplácelo
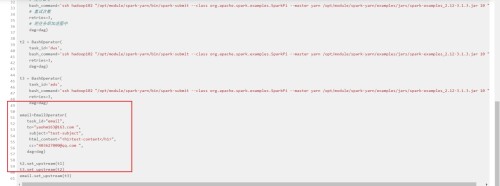
[root@airflow ~]# cd /opt/module/work-py/
[root@airflow work-py]# vim test.py
#!/usr/bin/python
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.email_operator import EmailOperator
from datetime import datetime, timedelta
default_args = {
# 用户
'owner': 'test_owner',
# 是否开启任务依赖
'depends_on_past': True,
# 邮箱
'email': ['[email protected]'],
# 启动时间
'start_date':datetime(2022,11,28),
# 出错是否发邮件报警
'email_on_failure': False,
# 重试是否发邮件报警
'email_on_retry': False,
# 重试次数
'retries': 1,
# 重试时间间隔
'retry_delay': timedelta(minutes=5),
}
# 声明任务图
dag = DAG('test', default_args=default_args, schedule_interval=timedelta(days=1))
# 创建单个任务
t1 = BashOperator(
# 任务id
task_id='dwd',
# 任务命令
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
# 重试次数
retries=3,
# 把任务添加进图中
dag=dag)
t2 = BashOperator(
task_id='dws',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
t3 = BashOperator(
task_id='ads',
bash_command='ssh hadoop102 "/opt/module/spark-yarn/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn /opt/module/spark-yarn/examples/jars/spark-examples_2.12-3.1.3.jar 10 "',
retries=3,
dag=dag)
email=EmailOperator(
task_id="email",
to="[email protected] ",
subject="test-subject",
html_content="<h1>test-content</h1>",
cc="[email protected] ",
dag=dag)
t2.set_upstream(t1)
t3.set_upstream(t2)
email.set_upstream(t3)
(5) Comprobar si la página es válida
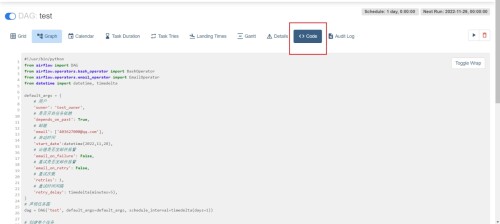
(6) Ejecutar la prueba