Directorio de artículos
-
- descripción general
- Descripción general de la programación del kernel
- Primeros pasos con Azkaban
- Azkaban avanzado
- programación de proyectos
descripción general
Azkaban es un programador de tareas de flujo de trabajo por lotes lanzado por Linkedin, que se utiliza para ejecutar un conjunto de trabajos y procesos en un orden específico dentro de un flujo de trabajo. Azkaban utiliza archivos de configuración de trabajos para establecer dependencias entre tareas y proporciona una interfaz de usuario web fácil de usar para mantener y realizar un seguimiento de su flujo de trabajo.
¿Por qué necesita un sistema de programación de flujo de trabajo?
- Un sistema completo de análisis de datos suele constar de un gran número de unidades de tareas:
programas Shell script, programas Java, programas MapReduce, scripts Hive, etc. - Hay dependencias secuenciales en el tiempo y de adelante hacia atrás entre las unidades de tareas;
- Para organizar bien un plan de ejecución tan complejo, se necesita un sistema de programación de flujo de trabajo para programar la ejecución;

Sistema de programación de flujo de trabajo común
- Programación de tareas simple: use directamente Crontab de Linux para definir;
- Programación de tareas complejas: desarrolle una plataforma de programación o utilice sistemas de programación de código abierto listos para usar, como Ooize, Azkaban, Airflow, DolphinScheduler, etc.
Azkaban contra Oozie

En general, en comparación con Azkaban, Ooize es un sistema de programación de tareas pesado con funciones integrales, pero su configuración es más complicada . Si no puede preocuparse por la falta de algunas funciones, el programador ligero Azkaban es un buen candidato.
arquitectura
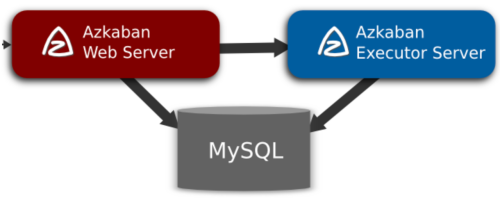
(1) Servidor Web de Azkaban
**AzkabanWebServer es el administrador principal de todo el sistema de flujo de trabajo de Azkaban. Es responsable de una serie de tareas, como la administración de proyectos, la autenticación de inicio de sesión de usuario, la ejecución programada del flujo de trabajo y el seguimiento del progreso de la ejecución del flujo de trabajo. **Al mismo tiempo, también proporciona una interfaz para operaciones de servicios web. Con esta interfaz, los usuarios pueden usar curl u otros métodos ajax para realizar operaciones relacionadas con azkaban.
Las operaciones incluyen: inicio de sesión de usuario, creación de proyecto, carga de flujo de trabajo, ejecución de flujo de trabajo, consulta del progreso de ejecución de flujo de trabajo, eliminación de flujo de trabajo y una serie de operaciones, y los resultados devueltos de estas operaciones están todos en formato json. Y Azkaban es fácil de usar. Azkaban usa el archivo de atributo clave-valor con el sufijo .job para definir cada tarea en el flujo de trabajo, y usa el atributo de dependencias para definir la cadena de dependencia entre trabajos. Estos archivos de trabajo y los códigos asociados finalmente se cargan en el servidor web a través de la interfaz de usuario de Azkaban en forma de *.zip.
(2) AzkabanExecutorServer
La versión anterior de Azkaban tenía las funciones de AzkabanWebServer y AzkabanExecutorServer en un solo servicio. Actualmente, Azkaban ha separado AzkabanExecutorServer en servidores independientes. Las razones para dividir AzkabanExecutorServer son las siguientes:
- Después de que falla un flujo de tareas, puede ser más conveniente volver a ejecutarlo
- Facilidad de actualizaciones de Azkaban
AzkabanExecutorServer es el principal responsable del envío y ejecución de flujos de trabajo específicos y puede iniciar varios servidores de ejecución, que coordinan la ejecución de tareas y logran una alta disponibilidad a través de la base de datos mysql.
(3) Base de datos relacional (MySQL)
Azkaban usa una base de datos para almacenar la mayor parte de su estado, y tanto AzkabanWebServer como AzkabanExecutorServer necesitan acceder a la base de datos.
AzkabanWebServer utiliza la base de datos por los siguientes motivos:
- Gestión de proyectos: proyectos, permisos de proyectos y archivos cargados.
- Estado del flujo de ejecución: rastrea el flujo de ejecución y qué flujo está ejecutando el ejecutor.
- Procesos/Trabajos Anteriores: busque entre trabajos anteriores y ejecuciones de procesos y acceda a sus archivos de registro.
- Programador: conserva el estado de los trabajos programados.
- SLA: mantener todas las reglas de SLA
AzkabanExecutorServer usa la base de datos por las siguientes razones:
- Acceder al proyecto: recupera el archivo del proyecto de la base de datos.
- Ejecutar proceso/trabajo: recuperar y actualizar datos para la secuencia de trabajos en ejecución
- Registro: almacene registros de salida de trabajos y flujos de trabajo en la base de datos.
- Dependencias de interacción: si un flujo de trabajo se ejecuta en un ejecutor diferente, obtendrá el estado de la base de datos
Proceso de ejecución del flujo de trabajo de Azkaban
De acuerdo con el estado de los recursos de cada Ejecutor almacenado en caché en la memoria (el servidor web tiene un hilo que atraviesa cada ejecutor activo para enviar una solicitud http para obtener su información de estado de recursos almacenada en caché en la memoria), de acuerdo con la estrategia de selección (incluido el recurso del ejecutor estado, el número de flujo de ejecución más reciente, etc.) Seleccione un ejecutor para entregar el flujo de trabajo; el ejecutor determina si establecer la distribución de granularidad del trabajo:
- Si no se establece la asignación de granularidad del trabajo, todos los trabajos se ejecutarán en el ejecutor actual;
- Si se establece la asignación de granularidad del trabajo, el nodo actual se convertirá en el que toma las decisiones sobre la asignación del trabajo, es decir, el nodo de asignación; el nodo de asignación obtiene la información del estado de los recursos de cada ejecutor de zookeeper y luego selecciona un ejecutor para asignar el trabajo según a la política; el ejecutor asignado al trabajo se convierte en un nodo de ejecución, ejecuta el trabajo y luego actualiza la base de datos.
Tres modos de funcionamiento de la arquitectura Azkaban
En la versión 3.0, Azkaban proporciona los siguientes tres modos:
-
modo de servidor solo: el modo más simple, la base de datos H2 integrada, AzkabanWebServer y AzkabanExecutorServer se ejecutan en un solo proceso, y este modo se puede usar para proyectos con una pequeña cantidad de tareas.
-
dos modos de servidor: la base de datos es MySQL, y el servidor de administración y el servidor de ejecución están en diferentes procesos.En este modo, AzkabanWebServer y AzkabanExecutorServer no se afectan entre sí.
-
modo de ejecutor múltiple: en este modo, AzkabanWebServer y AzkabanExecutorServer se ejecutan en diferentes hosts, y puede haber varios AzkabanExecutorServers.
La plataforma de big data requiere alta disponibilidad, por lo que actualmente adoptamos el método de modo de múltiples ejecutores, implementando múltiples AzkabanExecutorServers en diferentes hosts para manejar la ejecución de tareas programadas altamente simultáneas, reduciendo así la presión en un solo servidor. El siguiente es el diagrama de la arquitectura del clúster:
Descripción general de la programación del kernel
Resumen general
Azkaban WebServer debe seleccionar un Executor Server apropiado para ejecutar WorkFlow en función de la información de estado de ejecución del Executor Server y luego programar el WorkFlow enviado a la cola para que se ejecute en el Executor Server seleccionado. Clasificamos los diversos componentes relacionados con la programación central, incluidos principalmente Azkaban WebServer y Azkaban ExecutorServer. La relación entre ellos se muestra en la siguiente figura:

De hecho, desde la perspectiva de la programación, la interacción entre Azkaban WebServer y Executor Server es muy simple, a través de la API REST. El modo básico es que Azkaban WebServer llama activamente al REST expuesto por Executor Server de acuerdo con las necesidades de programación. API para obtener la información de recursos correspondiente, como la información de estado del Executor Server, asignar WorkFlow a un Executor Server específico, etc.
Podemos ver en el método QueueProcessorThread.selectExecutorAndDispatchFlow(), la implementación de seleccionar Executor Server y la programación, el fragmento de código es el siguiente:
final Executor selectedExecutor = selectExecutor(exflow, availableExecutors);
if (selectedExecutor != null) {
try {
dispatch(reference, exflow, selectedExecutor);
ExecutorManager.this.commonMetrics.markDispatchSuccess();
} catch (final ExecutorManagerException e) {
ExecutorManager.this.commonMetrics.markDispatchFail();
logger.warn(String.format(
"Executor %s responded with exception for exec: %d",
selectedExecutor, exflow.getExecutionId()), e);
handleDispatchExceptionCase(reference, exflow, selectedExecutor,
availableExecutors);
}
}
QueueProcessorThread es un subproceso que se ejecuta en el lado del servidor web de Azkaban. Se define en ExecutorManager y es el subproceso central en la programación interna.
El método selectExecutor() maneja cómo seleccionar un Executor Server adecuado y luego distribuye el flujo de trabajo que debe ejecutarse en el Executor Server a través del método dispatch().
Seleccionar servidor ejecutor
Azkaban WebServer selecciona Executor y llama al método selectExecutor() La implementación es la siguiente:
private Executor selectExecutor(final ExecutableFlow exflow,
final Set<Executor> availableExecutors) {
Executor choosenExecutor =
getUserSpecifiedExecutor(exflow.getExecutionOptions(),
exflow.getExecutionId());
// If no executor was specified by admin
if (choosenExecutor == null) {
logger.info("Using dispatcher for execution id :"
+ exflow.getExecutionId());
final ExecutorSelector selector = new ExecutorSelector(ExecutorManager.this.filterList,
ExecutorManager.this.comparatorWeightsMap);
choosenExecutor = selector.getBest(availableExecutors, exflow);
}
return choosenExecutor;
}
- En primer lugar, compruebe si es necesario programar el exflow para ejecutarse en el Executor Server especificado en la configuración actual de exflow. Si es así, devolverá la información del Executor Server especificado y luego lo programará directamente en el Executor Server; de lo contrario, seguirá las Ciertas reglas de cálculo se utilizan para seleccionar un Servidor Ejecutor.
- Al crear un ExecutorSelector, pase el valor del parámetro ExecutorManager.this.filterList, que lee el valor de configuración de azkaban.executorselector.filters del archivo azkanban.properties y crea un objeto ExecutorFilter, que contiene un conjunto de FactorFilter .
- Use ExecutorSelector para seleccionar un Executor Server Para la lógica de selección específica, podemos verificar el método ExecutorSelector.getBest().
Primero, preseleccione a través del CandidateFilter definido (es una clase abstracta, y la clase de implementación específica es ExecutorFilter) :
for (final K candidateInfo : candidateList) {
if (this.filter.filterTarget(candidateInfo, dispatchingObject)) {
filteredList.add(candidateInfo);
}
}
El filtro anterior es una instancia de la clase FactorFilter. Azkaban define internamente los siguientes tres tipos:
private static final String STATICREMAININGFLOWSIZE_FILTER_NAME = "StaticRemainingFlowSize";
private static final String MINIMUMFREEMEMORY_FILTER_NAME = "MinimumFreeMemory";
private static final String CPUSTATUS_FILTER_NAME = "CpuStatus";
Actualmente, la versión 3.40.0 no admite la personalización y solo puede usar la implementación integrada. Si necesita agregar un nuevo FactorFilter, puede realizar una modificación simple sobre esta base y configurarlo para usar su propio FactorFilter definido. FactorFilter es una clase genérica: FactorFilter<Executor, ExecutableFlow>, que realiza un prefiltro en Executor Server de acuerdo con los tres indicadores definidos anteriormente, y aquellos que cumplan con los requisitos se compararán más adelante y se agregarán al conjunto de candidatos de Executor Server para programar la ejecución de WorkFlow.
Luego, seleccione el Executor Server apropiado comparando y ordenando de la siguiente manera:
// final work - find the best candidate from the filtered list.
final K executor = Collections.max(filteredList, this.comparator);
logger.debug(String.format("candidate selected %s",
null == executor ? "(null)" : executor.toString()));
return executor;
La clave aquí es this.comparator, que tiene una clase de implementación ExecutorComparator, que brinda los indicadores que deben compararse de manera integral entre los dos Executor Servers, es decir, la definición de un conjunto de comparadores. tipo considerado de comparador:
private static final String NUMOFASSIGNEDFLOW_COMPARATOR_NAME = "NumberOfAssignedFlowComparator";
private static final String MEMORY_COMPARATOR_NAME = "Memory";
private static final String LSTDISPATCHED_COMPARATOR_NAME = "LastDispatched";
private static final String CPUUSAGE_COMPARATOR_NAME = "CpuUsage";
Como se puede ver en el código anterior, al elegir programar un WorkFlow para un Executor Server en el clúster de Azkaban, es necesario comparar los siguientes cuatro indicadores del Executor Server:
- La capacidad restante que puede ejecutar WorkFlow, cuanto mayor sea el valor, mejor
- El uso de memoria restante, cuanto mayor sea el valor, mayor será la prioridad
- El momento en que el Flujo se asignó recientemente, cuanto mayor sea el valor, mayor será la prioridad
- Uso de la CPU, cuanto menor sea el valor, mayor será la prioridad
Sobre la base de los 4 indicadores anteriores, se crean 4 comparadores, que están representados por FactorComparator. Para un grupo de Executor Servers que deben compararse, estos 4 comparadores se utilizan para la comparación, y se obtiene un valor de puntuación después de la ponderación. De acuerdo con el valor de puntuación Seleccione Executor Server, la lógica central es la siguiente:
final Collection<FactorComparator<T>> comparatorList = this.factorComparatorList.values();
for (final FactorComparator<T> comparator : comparatorList) {
final int result = comparator.compare(object1, object2);
result1 = result1 + (result > 0 ? comparator.getWeight() : 0);
result2 = result2 + (result < 0 ? comparator.getWeight() : 0);
logger.debug(String.format("[Factor: %s] compare result : %s (current score %s vs %s)",
comparator.getFactorName(), result, result1, result2));
}
Lo anterior selecciona el caso en el que los dos Executor Server que se van a comparar no están vacíos, atraviesa cada FactorComparator por separado para la comparación, y acumula y suma los valores de los resultados de comparación de cada Executor Server respectivamente, y obtiene un valor de puntuación por ponderación. De un grupo de Servidores Ejecutores, según el valor de puntuación de la comparación final, el Servidor Ejecutor con el valor de puntuación más alto es el Servidor Ejecutor seleccionado final.
Obtenga las estadísticas de ejecución de Executor Server
Dentro de Azkaban WebServer, se mantendrá la información de estado de ejecución de cada Executor Server en el clúster. La adquisición de esta información se implementa en el subproceso QueueProcessorThread, y la información de estado de ejecución de los Executor Servers mantenidos se actualiza regularmente, como se muestra a continuación:
if (currentTime - lastExecutorRefreshTime > activeExecutorsRefreshWindow
|| currentContinuousFlowProcessed >= maxContinuousFlowProcessed) {
// Refresh executorInfo for all activeExecutors
refreshExecutors();
lastExecutorRefreshTime = currentTime;
currentContinuousFlowProcessed = 0;
}
El método **refreshExecutors()** anterior atraviesa todos los Executor Servers mantenidos en la memoria, llama a la interfaz /serverStatistics de cada Executor Server y extrae la información de estado de ejecución del Executor Server.
Además, Azkaban WebServer también necesita poder obtener la información de estado de WorkFlow que se ejecuta en cada Executor Server. Puede ver la implementación en ExecutorManager.ExecutingManagerUpdaterThread. El fragmento de código es el siguiente:
results = ExecutorManager.this.apiGateway.callWithExecutionId(executor.getHost(),
executor.getPort(), ConnectorParams.UPDATE_ACTION,
null, null, executionIds, updateTimes);
Lo anterior llama a la interfaz /executor?action=update del Executor Server para extraer la información de estado de WorkFlow y luego actualiza la estructura de datos de información de estado mantenida en la memoria. Entre ellos, algunos WorkFlows pueden haber terminado de ejecutarse y necesitan liberar recursos, algunos cambios de estado de WorkFlow y la estructura de datos mantenida en la memoria del Azkaban WebServer también necesita ser actualizada.
Hay tres API:
public static final String DEFAULT_CLUSTER_NAME = "azkaban";
public final static String DEFAULT_EXECUTION_RESOURCE = "executor";
public final static String CONTAINERIZED_EXECUTION_RESOURCE = "container";
Programe WorkFlow para ejecutar en Executor Server
El Executor Server se seleccionó anteriormente. Combinado con el código anterior, se realiza llamando al método ExecutorManager.dispatch() para programar WorkFlow para que se ejecute en el Executor Server seleccionado. El fragmento de código es el siguiente:
try {
this.apiGateway.callWithExecutable(exflow, choosenExecutor,
ConnectorParams.EXECUTE_ACTION);
} catch (final ExecutorManagerException ex) {
logger.error("Rolling back executor assignment for execution id:"
+ exflow.getExecutionId(), ex);
this.executorLoader.unassignExecutor(exflow.getExecutionId());
throw new ExecutorManagerException(ex);
}
Al rastrear la implementación de apiGateway.callWithExecutable(), podemos ver que una interfaz REST API en el lado del servidor ejecutor: finalmente se llama /executor y luego trae los parámetros de solicitud relevantes, como action=execute, execId, etc.
Executor Server ejecuta WorkFlow
Obviamente, después de que Azkaban WebServer programe WorkFlow, Executor Server recibe la solicitud correspondiente en ExecutorServlet, y el método central es el siguiente:
private void handleAjaxExecute(final HttpServletRequest req,
final Map<String, Object> respMap, final int execId) throws ServletException {
try {
this.flowRunnerManager.submitFlow(execId);
} catch (final ExecutorManagerException e) {
e.printStackTrace();
logger.error(e.getMessage(), e);
respMap.put(RESPONSE_ERROR, e.getMessage());
}
}
Después de recibir la solicitud de programación de Azkaban WebServer, Executor Server usa el FlowRunnerManager interno para enviar WorkFlow para su ejecución. En este proceso, primero use ExecutorLoader para leer la información correspondiente a WorkFlow de la base de datos; luego use FlowPreparer para inicializar, crear el directorio de datos correspondiente, etc.; finalmente cree FlowRunner para ejecutar WorkFlow y rastrear su estado de ejecución.
Primeros pasos con Azkaban
instalación en modo clúster
cargar paquete tar
(1) Cargue azkaban-db-3.84.4.tar.gz, azkaban-exec-server-3.84.4.tar.gz, azkaban-web-server-3.84.4.tar.gz a /opt/ del software hadoop102 camino
[atguigu@hadoop102 software]$ ll
总用量 35572
-rw-r--r--. 1 atguigu atguigu 6433 4月 18 17:24 azkaban-db-3.84.4.tar.gz
-rw-r--r--. 1 atguigu atguigu 16175002 4月 18 17:26 azkaban-exec-server-3.84.4.tar.gz
-rw-r--r--. 1 atguigu atguigu 20239974 4月 18 17:26 azkaban-web-server-3.84.4.tar.gz
(2) Cree un nuevo directorio /opt/module/azkaban y extraiga todos los paquetes tar a este directorio
[atguigu@hadoop102 software]$ mkdir /opt/module/azkaban
(3) Descomprima azkaban-db-3.84.4.tar.gz, azkaban-exec-server-3.84.4.tar.gz y azkaban-web-server-3.84.4.tar.gz en /opt/module/azkaban Bajo contenido
[atguigu@hadoop102 software]$ tar -zxvf azkaban-db-3.84.4.tar.gz -C /opt/module/azkaban/
[atguigu@hadoop102 software]$ tar -zxvf azkaban-exec-server-3.84.4.tar.gz -C /opt/module/azkaban/
[atguigu@hadoop102 software]$ tar -zxvf azkaban-web-server-3.84.4.tar.gz -C /opt/module/azkaban/
(4) Vaya al directorio /opt/module/azkaban y modifique el nombre a su vez
[atguigu@hadoop102 azkaban]$ mv azkaban-exec-server-3.84.4/ azkaban-exec
[atguigu@hadoop102 azkaban]$ mv azkaban-web-server-3.84.4/ azkaban-web
Configurar MySQL
(1) Instale MySQL normalmente
(2) Inicie MySQL
[atguigu@hadoop102 azkaban]$ mysql -uroot -p000000
(3) Inicie sesión en MySQL y cree una base de datos de Azkaban
mysql> create database azkaban;
(4) Crear usuario azkaban y otorgar permisos
Establezca la longitud efectiva de la contraseña en 4 dígitos o más:
mysql> set global validate_password_length=4;
Establecer el nivel mínimo de la política de contraseñas
mysql> set global validate_password_policy=0;
Cree un usuario de Azkaban, cualquier host puede acceder a Azkaban, la contraseña es 000000
mysql> CREATE USER 'azkaban'@'%' IDENTIFIED BY '000000';
Otorgue a los usuarios de Azkaban permiso para agregar, eliminar, modificar y consultar
mysql> GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
(5) Cree la tabla Azkaban y salga de MySQL después de completar
mysql> use azkaban;
mysql> source /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql
mysql> quit;
(6) Cambiar el tamaño del paquete de MySQL; evitar que Azkaban se conecte a MySQL para bloquear
[atguigu@hadoop102 software]$ sudo vim /etc/my.cnf
Agregue una línea debajo de [mysqld] max_allowed_packet=1024M
[mysqld]
max_allowed_packet=1024M
(8) Reiniciar MySQL
[atguigu@hadoop102 software]$ sudo systemctl restart mysqld
Configuración de servidores ejecutores
Azkaban Executor Server maneja la ejecución real de flujos de trabajo y trabajos.
(1) Editar azkaban.properties
[atguigu@hadoop102 azkaban]$ vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
Modifique las propiedades marcadas en rojo de la siguiente manera:
#...
default.timezone.id=Asia/Shanghai
#...
azkaban.webserver.url=http://hadoop102:8081
executor.port=12321
#...
database.type=mysql
mysql.port=3306
mysql.host=hadoop102
mysql.database=azkaban
mysql.user=azkaban
mysql.password=000000
mysql.numconnections=100
(2) Sincronizar azkaban-exec con todos los nodos
[atguigu@hadoop102 azkaban]$ xsync /opt/module/azkaban/azkaban-exec
(3) Debe ingresar la ruta /opt/module/azkaban/azkaban-exec e iniciar el servidor ejecutor en las tres máquinas respectivamente
[atguigu@hadoop102 azkaban-exec]$ bin/start-exec.sh
[atguigu@hadoop103 azkaban-exec]$ bin/start-exec.sh
[atguigu@hadoop104 azkaban-exec]$ bin/start-exec.sh
Nota: Si el archivo executor.port aparece en el directorio /opt/module/azkaban/azkaban-exec, significa que el inicio se realizó correctamente.
4) Para activar el ejecutor de abajo, necesitas
[atguigu@hadoop102 azkaban-exec]$ curl -G "hadoop102:12321/executor?action=activate" && echo
[atguigu@hadoop103 azkaban-exec]$ curl -G "hadoop103:12321/executor?action=activate" && echo
[atguigu@hadoop104 azkaban-exec]$ curl -G "hadoop104:12321/executor?action=activate" && echo
Si aparecen las siguientes indicaciones en las tres máquinas, la activación se realizó correctamente
{
"status":"success"}
Configurar servidor web
Azkaban Web Server maneja la gestión de proyectos, la autenticación, la programación y la activación de la ejecución.
(1) Editar azkaban.properties
[atguigu@hadoop102 azkaban]$ vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
Modifique las siguientes propiedades:
...
default.timezone.id=Asia/Shanghai
...
database.type=mysql
mysql.port=3306
mysql.host=hadoop102
mysql.database=azkaban
mysql.user=azkaban
mysql.password=000000
mysql.numconnections=100
...
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
ilustrar:
- #StaticRemainingFlowSize: el número de tareas en cola;
- #CpuStatus: uso de CPU;
- #MinimumFreeMemory: uso de memoria. En el entorno de prueba, se debe eliminar la memoria libre mínima, de lo contrario, pensará que los recursos del clúster no son suficientes y no se ejecutará.
(2) Modifique el archivo azkaban-users.xml y agregue el usuario atguigu
[atguigu@hadoop102 azkaban-web]$ vim /opt/module/azkaban/azkaban-web/conf/azkaban-users.xml
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<user password="atguigu" roles="admin" username="atguigu"/>
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
(3) Debe ingresar la ruta /opt/module/azkaban/azkaban-web de hadoop102 e iniciar el servidor web
[atguigu@hadoop102 azkaban-web]$ bin/start-web.sh
(4) Visite http://hadoop102:8081 e inicie sesión con el usuario atguigu
Práctica de caso de flujo de trabajo
caso hola mundo
(1) En el entorno de Windows, cree un nuevo archivo azkaban.project, edite el contenido de la siguiente manera
azkaban-flow-version: 2.0
Nota: La función de este archivo es usar el nuevo método Flow-API para analizar archivos de flujo.
(2) Cree un nuevo archivo basic.flow con el siguiente contenido:
nodes:
- name: jobA
type: command
config:
command: echo "Hello World"
- Nombre: nombre del trabajo
- Tipo: tipo de trabajo. comando indica que la forma en que desea ejecutar el trabajo es un comando
- Config: configuración del trabajo
(3) Comprima los archivos azkaban.project y basic.flow en un archivo zip, y el nombre del archivo debe estar en inglés.
(4) Cree un nuevo proyecto en WebServer: http://hadoop102:8081/index

(5) Nombre el nombre del proyecto y agregue una descripción del proyecto
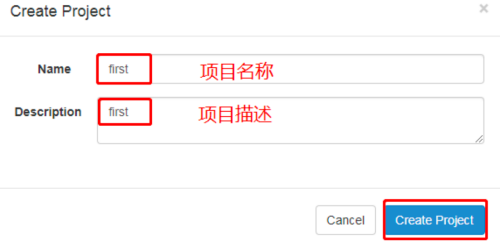
(6) Primera carga del archivo.zip

(7) Seleccione el archivo subido

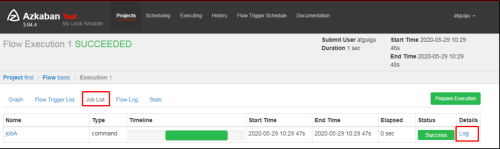
(8) Ejecutar flujo de tareas



(9) En el registro, vea los resultados de ejecución

Caso de dependencia laboral
Requisito: JobC solo se puede ejecutar después de que se ejecuten JobA y JobB
Pasos específicos:
(1) Modificar basic.flow al siguiente contenido
nodes:
- name: jobC
type: command
# jobC 依赖 JobA和JobB
dependsOn:
- jobA
- jobB
config:
command: echo "I’m JobC"
- name: jobA
type: command
config:
command: echo "I’m JobA"
- name: jobB
type: command
config:
command: echo "I’m JobB"
dependOn: Dependencia del trabajo, demostrada en los siguientes casos
(2) Comprima el basic.flow modificado y azkaban.project en un segundo archivo.zip
(3) Repita los pasos de seguimiento anteriores de HelloWorld



Caso de reintento de error automático
Requisito: si la tarea de ejecución falla, debe volver a intentarlo 3 veces y el intervalo de reintento es de 10000 ms
Pasos específicos:
(1) Flujo de compilación y configuración
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
retries: 3
retry.backoff: 10000
Descripción de parámetros:
- reintentos: número de reintentos
- retry.backoff: intervalo de reintento
(2) Comprimir basic.flow y azkaban.project modificados en cuatro archivos.zip
(3) Repita los pasos de seguimiento anteriores de HelloWorld.
(4) Ejecutar y observar un fallo + tres reintentos

(5) También puede hacer clic en Iniciar sesión en la imagen de arriba, y puede ver en el registro de tareas que se ha ejecutado 4 veces en total.

(6) También puede agregar la configuración de reintento de falla de tarea en la configuración global de Flujo, en cuyo caso la configuración de reintento se aplicará a todos los trabajos.
El caso es el siguiente:
config:
retries: 3
retry.backoff: 10000
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
Caso de reintento de error manual
Requisitos: JobA=》JobB (depende de A)=》JobC=》JobD=》JobE=》JobF. En el entorno de producción, cualquier trabajo puede colgarse y el trabajo deseado se puede ejecutar de acuerdo con la demanda.
Pasos específicos:
(1) Flujo de compilación y configuración
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: echo "This is JobC."
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."
- name: JobF
type: command
dependsOn:
- JobE
config:
command: echo "This is JobF."
(2) Comprimir basic.flow y azkaban.project modificados en cinco archivos.zip
(3) Repita los pasos de seguimiento anteriores de HelloWorld


Tanto Habilitar como Deshabilitar tienen los siguientes parámetros:
- Padres: tareas previas de este trabajo
- Ancestros: todas las tareas antes de este trabajo
- Niños: una tarea después de esta tarea
- Descendientes: todas las tareas después de este trabajo
- Habilitar todo: todas las tareas
(4) Las tareas correspondientes pueden ejecutarse selectivamente de acuerdo con los requisitos.

Azkaban avanzado
Caso de tipo de trabajo JavaProcess
El tipo JavaProcess puede ejecutar un método de clase principal personalizado, el tipo de tipo es javaprocess y las configuraciones disponibles son:
- Xms: montón mínimo
- Xmx: montón máximo
- ruta de clases: ruta de clases
- java.class: el objeto Java a ejecutar, que debe contener el método Main
- main.args: los parámetros del método principal
caso:
(1) Crear un nuevo proyecto maven azkaban
(2) Cree un nombre de paquete: com.atguigu
(3) Crear la clase AzTest
package com.atguigu;
public class AzTest {
public static void main(String[] args) {
System.out.println("This is for testing!");
}
}
(4) Empaquetado en el paquete jar azkaban-1.0-SNAPSHOT.jar
(5) Cree un nuevo testJava.flow, el contenido es el siguiente
nodes:
- name: test_java
type: javaprocess
config:
Xms: 96M
Xmx: 200M
java.class: com.atguigu.AzTest
(6) Empaquete el paquete Jar, el archivo de flujo y el archivo de proyecto en javatest.zip
(7) Crear proyecto = "subir javatest.zip =" ejecutar trabajo = "resultados de observación

Ejemplo de flujo de trabajo condicional
La función de flujo de trabajo condicional permite a los usuarios personalizar las condiciones de ejecución para decidir si ejecutar ciertos trabajos. Las condiciones pueden consistir en parámetros de tiempo de ejecución generados por el trabajo principal del trabajo actual o mediante el uso de macros predefinidas. En estas condiciones, los usuarios pueden obtener más flexibilidad para determinar la lógica de ejecución del trabajo, por ejemplo, el trabajo actual se puede ejecutar siempre que uno de los trabajos principales se realice correctamente.
Caso de parámetro de tiempo de ejecución
(1) Principios básicos
- El trabajo principal escribe los parámetros en el archivo al que apunta la variable de entorno JOB_OUTPUT_PROP_FILE
- El trabajo secundario usa ${jobName:param} para obtener la salida de parámetros del trabajo principal y definir las condiciones de ejecución
(2) Operadores condicionales admitidos:
- == es igual a
- != no igual a
- > mayor que
- >= mayor o igual que
- < menos que
- <= menor o igual que
- && y
- || o
- ! No
(3) Caso:
necesidad:
- JobA ejecuta un script de shell.
- JobB ejecuta un script de shell, pero JobB no necesita ejecutarlo todos los días, solo necesita ejecutarlo todos los lunes.
1) Crear un nuevo JobA.sh
#!/bin/bash
echo "do JobA"
wk=`date +%w`
echo "{
\"wk\":$wk}" > $JOB_OUTPUT_PROP_FILE
2) Crear un nuevo JobB.sh
#!/bin/bash
echo "do JobB"
3) Nueva condición.flujo
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
dependsOn:
- JobA
config:
command: sh JobB.sh
condition: ${
JobA:wk} == 1
4) Empaquete JobA.sh, JobB.sh, condition.flow y azkaban.project en condition.zip
5) Crear proyecto de condición = "cargar archivo condition.zip = "ejecutar trabajo = "resultados de observación
6) Según las condiciones que establezcamos, JobB decidirá si se ejecuta de acuerdo con la fecha actual.

Casos de macros predefinidos
Varias condiciones especiales de juicio están preestablecidas en Azkaban, llamadas macros predefinidas.
La macro predefinida juzgará según el estado de finalización de todos los trabajos principales y luego decidirá si ejecutarla. Las macros predefinidas disponibles son las siguientes:
- all_success: indica que todos los trabajos principales se ejecutaron correctamente (predeterminado)
- all_done: indica que el trabajo principal está completo antes de la ejecución
- all_failed: indica que todos los trabajos principales fallan al ejecutarse
- one_success: indica que al menos uno de los trabajos principales se ejecutó con éxito
- one_failed: indica que al menos uno de los trabajos principales no se pudo ejecutar
(1) caso
necesidad:
-
JobA ejecuta un script de shell
-
JobB ejecuta un script de shell
JobC ejecuta un script de shell y requiere uno de JobA y JobB para ejecutarse correctamente
1) Crear un nuevo JobA.sh
#!/bin/bash
echo "do JobA"
2) Crear un nuevo JobC.sh
#!/bin/bash
echo "do JobC"
3) Nueva macro.flujo
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
config:
command: sh JobB.sh
- name: JobC
type: command
dependsOn:
- JobA
- JobB
config:
command: sh JobC.sh
condition: one_success
4) Los archivos JobA.sh, JobC.sh, macro.flow, azkaban.project se empaquetan en macro.zip.
Nota: No hay JobB.sh.
5) Crear proyecto macro = "subir archivo macro.zip = "ejecutar trabajo = "resultados de observación

Caso de ejecución de tiempo
Requisito: JobA se ejecuta cada 1 minuto;
Pasos específicos:
(1) Azkaban puede ejecutar el flujo de trabajo regularmente. Al ejecutar el flujo de trabajo, seleccione Programar en la esquina inferior izquierda

(2) Tenga en cuenta que la zona horaria en la esquina superior derecha es Shanghái, y luego complete los eventos de ejecución específicos a la izquierda. El método de llenado es consistente con las reglas de tareas de tiempo de configuración de crontab.


(3) Resultados de la observación


(4) Eliminar la programación de tiempo
Haga clic en eliminar programación para eliminar las reglas de programación de la tarea actual.

Caso de alarma por correo electrónico
Registrar correo electrónico:
- Aplicar para registrar un buzón 126
- Haga clic en Cuenta de correo electrónico = "Administración de cuentas"
- Servicio SMTP abierto
- Asegúrese de recordar el código de autorización
De forma predeterminada, Azkaban admite alarmas de tareas fallidas por correo electrónico. El método de configuración es el siguiente:
(1) En el nodo azkaban-web hadoop102, edite /opt/module/azkaban/azkaban-web/conf/azkaban.properties y modifique el siguiente contenido:
[atguigu@hadoop102 azkaban-web]$ vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties
Agregue lo siguiente:
#这里设置邮件发送服务器,需要 申请邮箱,切开通stmp服务,以下只是例子
mail.sender=[email protected]
mail.host=smtp.126.com
mail.user=[email protected]
mail.password=用邮箱的授权码
(2) Guarde y reinicie el servidor web.
[atguigu@hadoop102 azkaban-web]$ bin/shutdown-web.sh
[atguigu@hadoop102 azkaban-web]$ bin/start-web.sh
(3) Editar basic.flow
nodes:
- name: jobA
type: command
config:
command: echo "This is an email test."
(4) Comprimir azkaban.project y basic.flow en email.zip
(5) Crear proyecto = "cargar archivo =" ejecutar trabajo = "ver resultado

(6) Observe el buzón y encuentre los correos electrónicos exitosos o fallidos

Caso de alarma de teléfono
Integración de plataforma de alarma de terceros
A veces, la alarma de correo no se recibe a tiempo después de que falla la ejecución de la tarea, por lo que es posible que se requieran otros métodos de alarma, como la alarma telefónica. Si existe una necesidad similar, se puede integrar con una plataforma de alarma de terceros, como Ruixiang Cloud.
(1) Ingrese al sitio web oficial de Ruixianyun para registrar una cuenta e iniciar sesión
Dirección del sitio web oficial: https://www.aiops.com/
(2) Plataforma de alarma integrada, utilizando la integración de correo electrónico

(3) Obtenga la dirección de correo electrónico y la información de la alarma debe enviarse a la dirección de correo electrónico más tarde

(4) Configurar la estrategia de despacho

(5) Configurar la política de notificación


prueba
Ejecute el caso de notificación de correo electrónico anterior y cambie el objeto de notificación al buzón obtenido cuando se acaba de integrar la plataforma de terceros.

Consideraciones sobre el modo multiejecutor de Azkaban
El modo multiejecutor de Azkaban hace referencia a la implementación de ejecutores en varios nodos del clúster. En este modo, el servidor web de Azkaban seleccionará uno de los ejecutores para ejecutar la tarea de acuerdo con la política.
Para garantizar que el Ejecutor seleccionado pueda realizar tareas con precisión, debemos elegir una de las siguientes dos opciones, y se recomienda la segunda opción.
(1) Solución 1: Designe un Ejecutor específico (hadoop102) para ejecutar la tarea.
-
En la tabla de ejecutores de la base de datos azkaban en MySQL, consulte la identificación del Ejecutor en hadoop102.
mysql> use azkaban; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select * from executors; +----+-----------+-------+--------+ | id | host | port | active | +----+-----------+-------+--------+ | 1 | hadoop103 | 35985 | 1 | | 2 | hadoop104 | 36363 | 1 | | 3 | hadoop102 | 12321 | 1 | +----+-----------+-------+--------+ 3 rows in set (0.00 sec) -
Agregue el atributo useExecutor al ejecutar el flujo de trabajo, de la siguiente manera:

(2) Solución 2: Implemente las secuencias de comandos y las aplicaciones necesarias para las tareas en todos los nodos donde se encuentra el Ejecutor.
programación de proyectos
preparación de datos
(1) Preparación de datos de comportamiento del usuario
-
Modifique application.properties en /opt/module/applog
#业务日期 mock.date=2020-06-15Nota: distribuir a otros nodos que necesitan generar datos
[atguigu@hadoop102 applog]$ xsync application.properties -
generar datos
[atguigu@hadoop102 bin]$ lg.shNota: ¡Después de generar los datos, recuerde comprobar si existen datos HDFS!
-
Observe si hay datos en la ruta /origin_data/gmall/log/topic_log/2020-06-15 de HDFS
(2) Preparación de datos comerciales
-
Modifique application.properties en /opt/module/db_log
[atguigu@hadoop102 db_log]$ vim application.properties #业务日期 mock.date=2020-06-15 -
generar datos
[atguigu@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar -
Observe que hay datos de fecha 2020-06-15 en operator_time en la tabla order_infor en SQLyog

Escribir un archivo de configuración de flujo de trabajo de Azkaban
(1) Escriba el archivo azkaban.project, el contenido es el siguiente
azkaban-flow-version: 2.0
(2) Escriba el archivo gmall.flow, el contenido es el siguiente
nodes:
- name: mysql_to_hdfs
type: command
config:
command: /home/atguigu/bin/mysql_to_hdfs.sh all ${
dt}
- name: hdfs_to_ods_log
type: command
config:
command: /home/atguigu/bin/hdfs_to_ods_log.sh ${
dt}
- name: hdfs_to_ods_db
type: command
dependsOn:
- mysql_to_hdfs
config:
command: /home/atguigu/bin/hdfs_to_ods_db.sh all ${
dt}
- name: ods_to_dim_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dim_db.sh all ${
dt}
- name: ods_to_dwd_log
type: command
dependsOn:
- hdfs_to_ods_log
config:
command: /home/atguigu/bin/ods_to_dwd_log.sh all ${
dt}
- name: ods_to_dwd_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dwd_db.sh all ${
dt}
- name: dwd_to_dws
type: command
dependsOn:
- ods_to_dim_db
- ods_to_dwd_log
- ods_to_dwd_db
config:
command: /home/atguigu/bin/dwd_to_dws.sh all ${
dt}
- name: dws_to_dwt
type: command
dependsOn:
- dwd_to_dws
config:
command: /home/atguigu/bin/dws_to_dwt.sh all ${
dt}
- name: dwt_to_ads
type: command
dependsOn:
- dws_to_dwt
config:
command: /home/atguigu/bin/dwt_to_ads.sh all ${
dt}
- name: hdfs_to_mysql
type: command
dependsOn:
- dwt_to_ads
config:
command: /home/atguigu/bin/hdfs_to_mysql.sh all
(3) Comprima los archivos azkaban.project y gmall.flow en un archivo zip y el nombre del archivo debe estar en inglés.
(4) Cree un nuevo proyecto en WebServer: http://hadoop102:8081/index, nombre el proyecto gmall y agregue una descripción del proyecto
(5) carga del archivo gmall.zip
(6) Ver flujo de tareas

(7) Visualización detallada del flujo de tareas

(8) Configurar parámetros de tiempo dt de entrada


(9) Ejecución exitosa
