Directorio de artículos
Introducción básica al flujo IO
Descripción general de los flujos de E/S :
I significa entrada, que es el proceso de lectura de datos del archivo del disco duro en la memoria, que se llama entrada y es responsable de la lectura.
O significa salida, que es el proceso de los datos del programa de memoria desde la memoria hasta la escritura en el archivo del disco duro, llamado salida, responsable de la escritura.

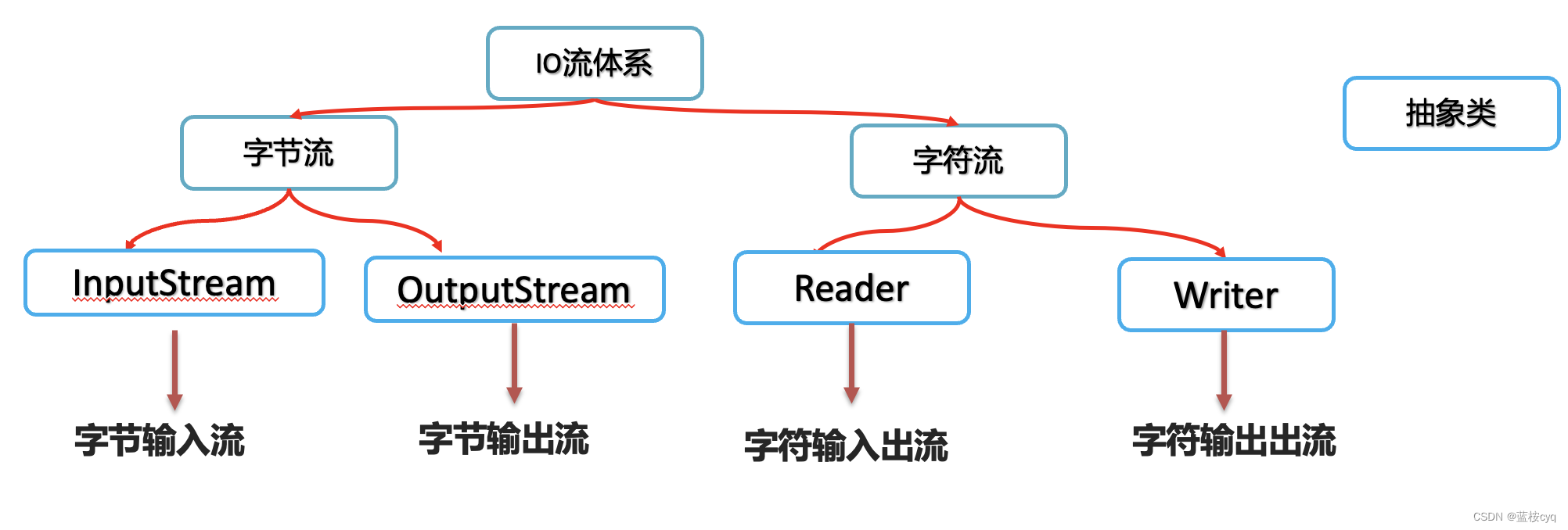
Clasificación de flujos IO :
Clasificados por dirección:
- flujo de entrada
- flujo de salida
De acuerdo con la unidad de datos más pequeña en la secuencia, se divide en:
- Flujo de bytes: puede operar todo tipo de archivos ( incluidos audio, video, imágenes de pantalla, etc. )
- Flujo de caracteres: solo puede operar en archivos de texto sin formato ( incluidos archivos java, archivos txt, etc. )
Para resumir las cuatro categorías principales de flujos :
Flujo de entrada de bytes: según la memoria, el flujo en el que los datos de los archivos de disco/redes se leen en la memoria en forma de bytes se denomina flujo de entrada de bytes.
Flujo de salida de bytes: según la memoria, el flujo que escribe los datos en la memoria en un archivo de disco o red en bytes se denomina flujo de salida de bytes.
Flujo de entrada de caracteres: según la memoria, el flujo en el que los datos de los archivos de disco/redes se leen en la memoria en forma de caracteres se denomina flujo de entrada de caracteres.
Flujo de salida de caracteres: según la memoria, el flujo que escribe los datos en la memoria en un archivo de disco o medio de red en caracteres se denomina flujo de salida de caracteres.
Uso de flujos de bytes

flujo de entrada de bytes de archivo
Crear flujo de entrada de bytes
Flujo de entrada de bytes de archivo: implementar clase FileInputStream
Función: según la memoria, lea los datos en el archivo del disco en la memoria en bytes.
El constructor es el siguiente :
| constructor | ilustrar |
|---|---|
| FileInputStream público (archivo de archivo) | Cree una canalización de flujo de entrada de bytes para conectarse al objeto del archivo de origen |
| FileInputStream público (nombre de la ruta de la cadena) | Cree una canalización de flujo de entrada de bytes conectada a la ruta del archivo de origen |
Código de muestra:
public static void main(String[] args) throws FileNotFoundException {
// 写法一: 创建字节输入流与源文件对象接通
InputStream inp = new FileInputStream(new File("/file-io-app/src/test.txt"));
}
public static void main(String[] args) throws FileNotFoundException {
// 写法二: 创建字节输入流管道与源文件路径接通
InputStream inp = new FileInputStream("/file-io-app/src/test.txt");
}
leer un byte a la vez
| nombre del método | ilustrar |
|---|---|
| leer() | Devuelve un byte a la vez, o -1 si no hay más bytes para leer |
Por ejemplo, el contenido del archivo del Bloc de notas que leemos es: abcd123
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
int a = inp.read();
System.out.println(a); // 97
System.out.println((char) a); // a
// 一次输入一个字节
System.out.println(inp.read()); // 98
System.out.println(inp.read()); // 99
System.out.println(inp.read()); // 100
System.out.println(inp.read()); // 49
System.out.println(inp.read()); // 50
System.out.println(inp.read()); // 51
// 无字节可读返回-1
System.out.println(inp.read()); // -1
}
Podemos recorrer los bytes en el archivo
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
int b;
while ((b = inp.read()) != -1) {
System.out.print((char) b); // abcd123
}
}
Leer un byte a la vez tiene los siguientes problemas
rendimiento lento
El problema de los caracteres ilegibles no se puede evitar cuando se lee la salida de caracteres chinos.
leer una matriz a la vez
| nombre del método | ilustrar |
|---|---|
| leer (byte [] búfer) | Cada vez que se lee una matriz de bytes, se devuelve el número de bytes leídos y se devuelve -1 si no hay más bytes legibles. |
Defina una matriz de bytes para recibir el número de bytes leídos
Por ejemplo, en el siguiente código, el contenido del archivo es: abcd123, se leen tres bytes cada vez y cada lectura sobrescribirá el contenido de la matriz anterior, pero la tercera lectura solo lee un carácter, por lo que solo sobrescribe la primera elemento de la matriz de caracteres leído la última vez, el resultado es: 312
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个长度为3的字节数组
byte[] arr = new byte[3];
// 第一次读取一个字节数组
int len1 = inp.read(arr);
System.out.println("读取字节数: " + len1); // 读取字节数: 3
// 对字节数组进行解码
String res1 = new String(arr);
System.out.println(res1); // abc
// 第二次读取一个字节数组
int len2 = inp.read(arr);
System.out.println("读取字节数: " + len2); // 读取字节数: 3
// 对字节数组进行解码
String res2 = new String(arr);
System.out.println(res2); // d12
// 第三次读取一个字节数组
int len3 = inp.read(arr);
System.out.println("读取字节数: " + len3); // 读取字节数: 1
// 对字节数组进行解码
String res3 = new String(arr);
System.out.println(res3); // 312
// 无字节可读返回-1
System.out.println(inp.read()); // -1
}
El segundo parámetro de String puede especificar la posición inicial y el tercer parámetro puede especificar la posición final. Estos dos parámetros se pueden usar para resolver las desventajas de la tercera lectura.
Y el bucle mejora el código optimizado.
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
byte[] arr = new byte[3];
int len;
while ((len = inp.read(arr)) != -1) {
String res = new String(arr, 0, len);
System.out.print(res); // abcd123
}
}
Las desventajas de leer una matriz a la vez :
Se ha mejorado el rendimiento de lectura.
El problema de los caracteres ilegibles no se puede evitar cuando se lee la salida de caracteres chinos.
Leer todos los bytes a la vez
Para resolver el problema de los caracteres chinos distorsionados, podemos definir una matriz de bytes tan grande como el archivo y leer todos los bytes del archivo a la vez.
Desventaja: si el archivo es demasiado grande, la matriz de bytes puede provocar un desbordamiento de la memoria.
Por ejemplo, lea un archivo como el que se muestra a continuación

Método 1 :
Defina una matriz de bytes usted mismo tan grande como el tamaño del archivo y luego use el método de lectura de la matriz de bytes para completar la lectura única.
public static void main(String[] args) throws Exception {
File file = new File("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
InputStream inp = new FileInputStream(file);
// 创建一个与文件大小一样的字节数组
byte[] arr = new byte[(int) file.length()];
// 读取文件, 获取读取的字节长度
int len = inp.read(arr);
System.out.println(len); // 252
// 对字节数组进行解码
String res = new String(arr);
System.out.println(res);
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
}
Método 2 :
El funcionario proporciona la siguiente API para el flujo de entrada de bytes InputStream, que puede leer directamente todos los datos del archivo en una matriz de bytes
| nombre del método | ilustrar |
|---|---|
| leerTodosBytes() | Lea directamente todos los datos de bytes del objeto de archivo correspondiente al flujo de entrada de bytes actual, luego cárguelo en una matriz de bytes y regrese |
public static void main(String[] args) throws Exception {
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 获取文件的全部字节, 并返回一个字节数组
byte[] arr = inp.readAllBytes();
// 对字节数组进行解码
String res = new String(arr);
System.out.println(res);
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
// abcd123我爱Java学习Java.abcd123我爱Java学习Java.abcd123我爱Java学习Java.
}
flujo de salida de bytes de archivo
Crear un flujo de salida de bytes
Flujo de salida de bytes de archivo: implementar clase FileOutputStream
Función: según la memoria, los datos de la memoria se escriben en el archivo del disco en forma de bytes.
El constructor es el siguiente :
| constructor | ilustrar |
|---|---|
| FileOutputStream (archivo de archivo) | Cree una canalización de flujo de salida de bytes conectada al objeto del archivo de origen |
| FileOutputStream (ruta de archivo de cadena) | Cree una canalización de flujo de salida de bytes conectada a la ruta del archivo de origen |
public static void main(String[] args) throws Exception {
// 写法一: 创建输出流与源文件对象接通
OutputStream oup = new FileOutputStream(new File("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt"));
}
public static void main(String[] args) throws Exception {
// 写法二: 创建输出与源文件路径接通(常用)
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
}
escribir en el flujo de salida del archivo
API para escribir datos del flujo de salida de bytes del archivo :
| nombre del método | ilustrar |
|---|---|
| escribir (int a) | escribir un byte |
| escribir (byte [] búfer) | escribir una matriz de bytes |
| escribir(byte[] buffer , int pos , int len) | Escribe una parte de una matriz de bytes. |
Actualizar transmisión y cerrar API :
| método | ilustrar |
|---|---|
| enjuagar() | Actualizar la transmisión y continuar escribiendo datos |
| cerca() | Cierre la secuencia, liberando recursos, pero vaciando la secuencia antes de cerrarla . Una vez cerrado, ya no se pueden escribir datos |
Nota: los datos deben actualizarse al escribir datos y la transmisión debe cerrarse después de usarse
escribir un byte
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
oup.write('a');
// 支持写入编码
oup.write(97);
// 汉字占三个字节, 所以该方法不可以写入汉字
// oup.write('我');
// 写数据必须刷新数据
oup.flush();
// 刷新流后可以继续写入数据
oup.write('b');
// 使用完后需要关闭流, 关闭后不能再写入数据
oup.close();
}
escribir una matriz de bytes
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个字节数组
byte[] arr = {
'a', 98, 'b', 'c'};
// 写入中文, 需要将中文编码成字节数组
byte[] chinese = "中国".getBytes();
// 写入英文字节数组
oup.write(arr);
// 写入中文字节数组
oup.write(chinese);
// 关闭流(关闭之前会刷新)
oup.close();
}
escribir parte de una matriz de bytes
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个字节数组
byte[] arr = {
'a', 98, 'b', 'c'};
// 写入数组的第二个和第三个元素
oup.write(arr, 1, 2);
// 关闭流(关闭之前会刷新)
oup.close();
}
Conocimientos complementarios :
Suplemento 1: al escribir contenido, si necesita cambiar la línea, puede convertirlo
\r\n( la ventana admite entrada \n pero algunos sistemas no lo admiten, use \r\n para versatilidad ) en una matriz de bytes y escribirlo para lograr el efecto del salto de linea
public static void main(String[] args) throws Exception {
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt");
// 定义一个字节数组
byte[] arr = {
'a', 98, 'b', 'c'};
oup.write(arr);
// 写入换行
oup.write("\r\n".getBytes());
// 写入数组的第二个和第三个元素
oup.write(arr, 1, 2);
// 关闭流(关闭之前会刷新)
oup.close();
}
Suplemento 2: al escribir un archivo, el archivo original se borrará primero y luego se escribirán nuevos datos.Si queremos agregar nuevos datos basados en los datos del archivo original, entonces debemos establecer el segundo parámetro del conjunto constructor a la verdad
| constructor | ilustrar |
|---|---|
| FileOutputStream (Archivo de archivo, anexo booleano) | Cree una canalización de flujo de salida de bytes conectada al objeto del archivo de origen, y los datos se pueden agregar |
| FileOutputStream (ruta de archivo de cadena, anexo booleano) | Cree una canalización de flujo de salida de bytes conectada a la ruta del archivo de origen, y se pueden agregar datos |
public static void main(String[] args) throws Exception {
// 设置为true即可
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.txt", true);
}
ejercicio de copia de archivos
Requisitos :
Copie el archivo test.pdf al archivo newtest.pdf en otro directorio
Análisis de ideas :
Cree un objeto de flujo de entrada de bytes a partir de una fuente de datos
Cree un objeto de flujo de salida de bytes basado en el destino
Leer y escribir datos, copiar video
liberar recursos
código de muestra :
public static void main(String[] args) {
try {
// 创建要复制文件的字节输入流
InputStream inp = new FileInputStream("/Users/chenyq/Documents/learn_Java/code/file-io-app/src/test.pdf");
// 创建目标路径的字节输出流
OutputStream oup = new FileOutputStream("/Users/chenyq/Documents/newtest.pdf");
// 使用文件输入流获取要复制文件的全部数据的字节数组
byte[] arr = inp.readAllBytes();
// 使用文件输出流将字节数组写入目标文件
oup.write(arr);
System.out.println("复制成功!");
// 释放资源
inp.close();
oup.close();
} catch (IOException e) {
e.printStackTrace();
}
}
Pregunta: ¿Qué tipos de archivos pueden copiar los flujos de bytes?
La capa inferior de cualquier archivo son bytes, y la copia es una transferencia de bytes palabra por palabra. Siempre que el formato y la codificación de los archivos anteriores y posteriores sean consistentes, no hay problema.
Resumen: el flujo de bytes es adecuado para copiar archivos, pero no para la salida en chino