La observabilidad es un superconjunto de monitoreo. Proporciona una descripción general de alto nivel del estado del sistema, además de proporcionar información detallada sobre los modos de falla implícitos. Además, los sistemas observables proporcionan un repositorio de su funcionamiento interno, lo que permite descubrir problemas sistémicos más profundos.
Una vez que el servicio se implementa en producción, queremos saber cómo se está desempeñando en términos de solicitudes por segundo, utilización de recursos, etc. Además, desea recibir alertas de inmediato si algo sale mal, como una instancia de servicio que falla o se queda sin espacio en disco, idealmente antes de que afecte la experiencia del usuario. Si algo sale mal, debemos poder solucionar el problema y hacer un RCA ( Análisis de causa raíz ).
Como desarrolladores de servicios, debemos implementar varios patrones para facilitar la gestión de servicios y la resolución de problemas. Los siguientes cinco patrones pueden ayudarnos a diseñar servicios observables:
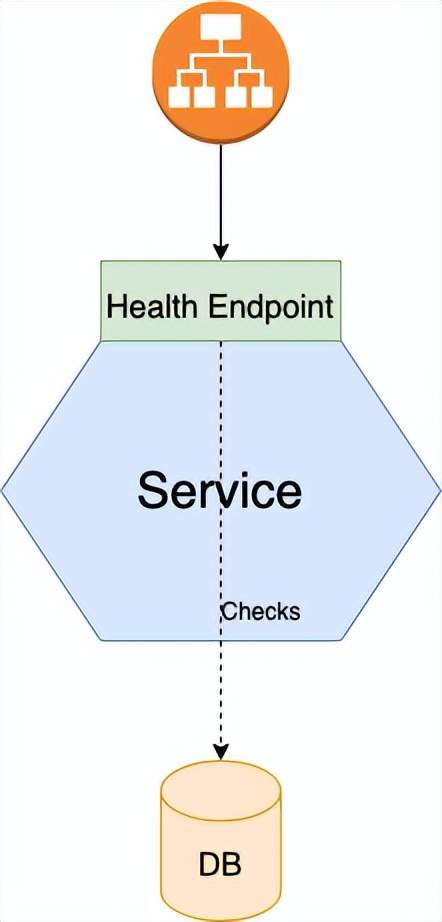
- Health Check API : proporciona un punto final que devuelve el estado de salud del servicio.
- Agregación de registros : puede registrar la actividad del servicio y almacenar registros en un servidor de registro centralizado que proporciona capacidades de alerta y búsqueda.
- Seguimiento distribuido : identifique cada solicitud externa con una identificación única y rastree las solicitudes a medida que fluyen entre los servicios.
- Seguimiento de excepciones : las excepciones deben informarse a un servicio de seguimiento de excepciones, que elimina los duplicados de excepciones, alerta a los desarrolladores y realiza un seguimiento de cómo se resuelven.
- Métricas de la aplicación : el servicio mantiene las métricas, como los contadores y los indicadores, y las expone al servidor de métricas.
- Registro de auditoría : seguimiento de las acciones del usuario

1. Modo API de verificación de estado
Ocasionalmente, un servicio puede estar ejecutándose pero no puede procesar solicitudes. Una instancia de servicio recién iniciada aún puede estar inicializándose y realizando algunas comprobaciones antes de procesar las solicitudes. No tiene sentido que la infraestructura de implementación enrute las solicitudes HTTP a las instancias de servicio hasta que estén listas para manejarlas.
También puede suceder que la instancia del servicio falle sin que se termine, por ejemplo, todas las conexiones de la base de datos se agotan y no se puede acceder a la base de datos. La infraestructura de implementación no debe enrutar las solicitudes a una instancia de servicio fallida pero aún en ejecución; si la instancia de servicio no se puede recuperar, se debe finalizar y crear una nueva instancia. Una instancia de servicio debe poder decirle a la infraestructura de implementación si puede manejar la solicitud. Puede usar Spring Boot Actuator, que implementa puntos finales de estado para implementar puntos finales de verificación de estado para sus servicios.
2. Modo de agregación de registros
El modo de agregación de registros se puede utilizar para solucionar problemas. Si desea determinar qué está mal con su aplicación, los archivos de registro son un buen lugar para comenzar. Iniciar sesión en una arquitectura de microservicios puede ser un desafío porque el contenido del registro está disperso en los archivos de registro de diferentes servicios.
La agregación de registros es la solución. El servicio de agregación de registros envía los registros de todas las instancias de servicio a un servidor de registro centralizado. Cuando los registros son almacenados por el servidor de registro, se pueden ver, buscar y analizar. También es posible configurar una alerta para que se active cuando aparezcan ciertos mensajes en el registro.
La infraestructura de registro es responsable de agregar registros, almacenarlos y usarlos para realizar búsquedas. Muchas herramientas populares brindan agregación de registros, como Splunk, Fluentd, ELK stack, Graylog, etc.

3. Modo de seguimiento distribuido
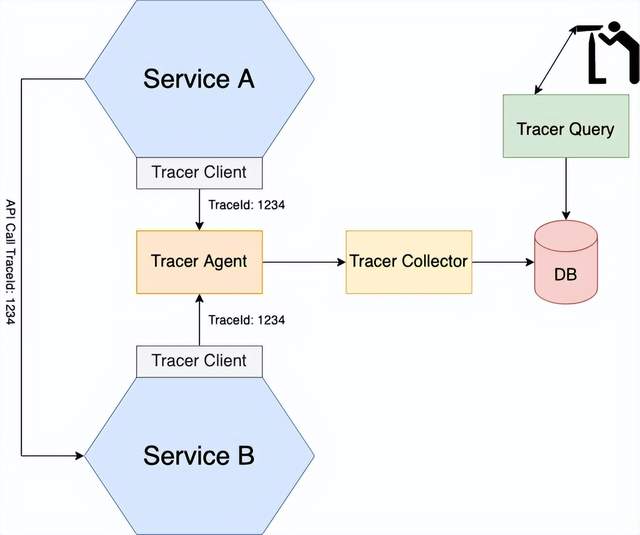
Supongamos que está solucionando un problema con una respuesta API lenta, que puede involucrar varios servicios. Utilice el seguimiento distribuido para obtener información sobre lo que está haciendo su aplicación. Un trazador distribuido es similar a un generador de perfiles en una aplicación monolítica. Registra información sobre las llamadas de servicio realizadas durante el procesamiento de una solicitud. A continuación, puede ver cómo interactúan los servicios durante el procesamiento de solicitudes externas y cuánto tiempo se dedica a cada servicio.
A cada solicitud externa se le asigna una identificación única y se realiza un seguimiento a medida que fluye de un servicio a otro en un servidor centralizado que proporciona visualización y análisis. Los servidores de rastreo distribuidos incluyen Zipkin, Jaeger, OpenTracing, OpenCensus, New Relic, etc.
4. Modo de seguimiento de excepciones
El registro de servicio es anormal y es importante ayudar a determinar la causa. Las excepciones indican un problema o un error del programa. El registro se usa para ver excepciones, e incluso se puede configurar un servidor de registro para recordar al personal de operación y mantenimiento cuando ocurre una excepción. Sin embargo, hay algunas desventajas a tener en cuenta:
- Los archivos de registro constan de entradas de registro de una sola línea, mientras que las excepciones tienen varias líneas.
- En los archivos de registro, no existe ningún mecanismo para rastrear la resolución de excepciones. La excepción debe copiarse/pegarse manualmente en el rastreador de problemas.
- Actualmente no hay forma de tratar automáticamente las excepciones repetidas como una excepción.
El servicio de seguimiento de excepciones es un muy buen método de seguimiento de excepciones. Los servicios informan las excepciones a un servicio centralizado que deduplica, genera alertas y administra las excepciones. Los servicios de seguimiento de excepciones se pueden implementar utilizando Honeybadger, Sentry, etc.

5. Aplicar patrones métricos
El monitoreo y las alertas son componentes críticos de los entornos de producción. Un sistema de monitoreo recopila métricas de todas las partes de su pila de tecnología que brindan información crítica sobre el estado de una aplicación. Estas métricas van desde métricas de nivel de infraestructura, como CPU, memoria y uso de disco, hasta métricas de nivel de aplicación, como la latencia de solicitud de servicio y la cantidad de solicitudes procesadas.
Las métricas son responsabilidad del desarrollador del servicio, de dos maneras. Primero, el servicio debe estar instrumentado para recopilar indicadores de comportamiento relevantes. En segundo lugar, estas métricas de servicio, así como las métricas de la JVM y el marco de la aplicación, deben exponerse al servidor de métricas. El servicio de métricas de aplicaciones puede sondear los puntos de enlace para recuperar métricas al igual que el servicio AWS CloudWatch o el servidor Prometheus. Grafana es una herramienta de visualización de datos que se puede usar para ver métricas en Prometheus.

6. Modo de registro de auditoría
La operación de cada usuario se registra en el registro de auditoría. Por lo general, los registros de auditoría se utilizan para brindar asistencia al cliente, garantizar el cumplimiento y detectar actividades sospechosas. Las entradas del registro de auditoría registran quiénes son los usuarios, las acciones que realizan y los objetos comerciales involucrados. Los registros de auditoría generalmente se almacenan en tablas de bases de datos.
Los registros de auditoría se pueden implementar de varias maneras diferentes:
- Agregar código de registro de auditoría a la lógica empresarial : cada método de servicio puede crear una entrada de registro de auditoría y guardarla en la base de datos.
- Programación orientada a aspectos (AOP) : puede usar un marco AOP como Spring AOP para definir recomendaciones que intercepten cada llamada de método de servicio y mantengan las entradas del registro de auditoría.
- Aproveche el origen de eventos : de forma predeterminada, el origen de eventos proporciona registros de auditoría para operaciones de creación y actualización.
Los patrones de observabilidad, por definición, no se tratan de registros, métricas o seguimiento, sino de estar basados en datos durante la depuración y usar comentarios para iterar y mejorar el producto.