Lección 08: Cómo dividir la aplicación de muestra en microservicios
Después de presentar los conceptos básicos del diseño basado en dominios en la lección 07, esta lección presentará cómo aplicar las ideas relacionadas con el diseño basado en dominios en la división de microservicios.
división de microservicios
En el diseño e implementación de aplicaciones de arquitectura de microservicios, si desea averiguar la tarea más importante, debe ser la división de los no microservicios . El núcleo de la arquitectura de microservicios es un sistema distribuido compuesto por múltiples microservicios que cooperan. Solo después de completar la división de los microservicios, se pueden aclarar las responsabilidades de cada microservicio y determinar el modo de interacción entre los microservicios, y luego continuar con el diseño de la API. cada microservicio es la implementación, prueba y despliegue final de cada microservicio.
Como se puede ver en el proceso anterior, la división de microservicios es el primer eslabón en toda la cadena de diseño e implementación de aplicaciones. Los cambios en cada eslabón de la cadena tendrán un impacto en los eslabones subsiguientes.Como primer eslabón de la división de microservicios, si hay un cambio, afectará a todos los eslabones posteriores. Lo último que desea es darse cuenta de que alguna funcionalidad debe migrarse a otros microservicios durante la implementación de los microservicios. Si esto sucede, será necesario modificar tanto la API como la implementación del microservicio asociado.
Por supuesto, en el desarrollo real, no es realista evitar por completo los cambios en la división de microservicios. En la etapa de división de microservicios, si dedica suficiente energía al análisis, los beneficios que obtiene son absolutamente enormes.
Microservicios y contextos acotados
En la clase 07, presentamos el concepto de contexto definido en el diseño basado en dominios. Si la idea de diseño basado en dominios se aplica a la arquitectura de microservicios, podemos hacer una correspondencia uno a uno entre los microservicios y el contexto definido. . Cada contexto acotado corresponde directamente a un microservicio y luego usa el patrón de mapeo de contexto para definir la forma de interacción entre los microservicios.
De esta forma, el problema de dividir los microservicios se transforma en el problema de dividir el contexto definido en el diseño dirigido por el dominio. Si ya tiene una comprensión sólida del diseño basado en dominios, eso será una ventaja; si no, el contenido de la lección 07 puede ayudarlo a comenzar rápidamente.
Tomemos la aplicación de muestra en esta columna como ejemplo para una explicación específica.
Particionamiento de microservicios de la aplicación de muestra
La Lección 06 presenta los escenarios de usuario de la aplicación de muestra, en función de estos escenarios, se puede determinar el dominio de la aplicación. En el desarrollo de aplicaciones reales, generalmente se requiere que participen expertos en dominios y personal comercial. A través de la comunicación con el personal comercial, podemos tener una comprensión más clara del dominio. En cuanto a la aplicación de ejemplo, dado que el dominio de la aplicación está relativamente cerca de la vida, y para simplificar la introducción relacionada, realizaremos un análisis de dominio por nosotros mismos. Sin embargo, esto tiene una desventaja, es decir, el análisis de dominio realizado por los desarrolladores no refleja necesariamente el proceso comercial real. Sin embargo, para la aplicación de muestra, esto es lo suficientemente bueno.
El diseño dirigido por el dominio toma el dominio como el núcleo, y el dominio se divide en el espacio del problema y el espacio de la solución .
El espacio del problema nos ayuda a pensar a nivel empresarial y es la parte del dominio de la que depende el dominio central, que incluye el dominio central y otros subdominios según sea necesario. El dominio central debe crearse desde cero, porque ese es el núcleo del sistema de software que desarrollaremos; es posible que ya existan otros subdominios o que también deban crearse desde cero. El tema central del espacio del problema es cómo identificar y dividir los subcampos.
El espacio de la solución consiste entonces en uno o más contextos acotados y los modelos dentro de los contextos. Idealmente, existe una correspondencia uno a uno entre los contextos definidos y los subdominios. De esta manera, la división se puede iniciar desde el nivel de negocio y luego se puede adoptar el mismo método de división en el nivel de implementación, de modo que se pueda lograr la integración perfecta del espacio del problema y el espacio de la solución. En la práctica real, es poco probable que exista una correspondencia uno a uno entre contextos y subcampos definidos. En la implementación de un sistema de software, generalmente debe integrarse con sistemas heredados existentes y sistemas externos, y estos sistemas tienen sus propios contextos definidos. En la práctica, es más realista que múltiples contextos acotados pertenezcan al mismo subcampo, o que un contexto acotado corresponda a múltiples subcampos.
La idea del diseño dirigido por dominio es comenzar desde el dominio, primero dividir el subdominio y luego abstraer el contexto definido y el modelo en el contexto del subdominio.Cada contexto definido corresponde a un microservicio.
áreas centrales
El dominio central es donde existe el valor del sistema de software y también es el punto de partida del diseño. Antes de iniciar el sistema de software, debe tener una comprensión clara del valor central del sistema de software. Si no es así, primero debe considerar los puntos de venta del sistema de software. Los diferentes sistemas de software tienen diferentes áreas centrales. Como aplicación de solicitud de taxis, su área central es cómo hacer que los pasajeros viajen de manera rápida, cómoda y segura, que también es el área central de las aplicaciones de solicitud de taxis como Didi Taxi y Uber. Para la aplicación Happy Travel como ejemplo, un área central de este tipo es un poco demasiado grande. La aplicación Happy Travel simplifica el área central y solo se enfoca en cómo hacer que los pasajeros viajen rápidamente.
Necesitamos darle al dominio central un nombre apropiado. El área central de los viajes felices es cómo hacer coincidir rápidamente entre los pasajeros que necesitan llamar a un automóvil y los conductores que brindan servicios de viaje. Después de que el usuario crea el itinerario, el sistema lo distribuye a los conductores disponibles.Después de que el conductor recibe el itinerario, el sistema selecciona un conductor para distribuir el itinerario. El área central se enfoca en despachar itinerarios, de ahí el nombre de distribución de itinerarios .
conceptos en el campo
Luego enumeramos los conceptos en el dominio. Este es un proceso de lluvia de ideas que se puede llevar a cabo en una pizarra para enumerar uno por uno todos los conceptos relacionados que se te ocurran. Los conceptos son sustantivos. El primer concepto es itinerario, lo que significa un viaje desde un punto de partida determinado hasta un punto final. A partir del itinerario, se puede derivar el concepto de pasajeros y conductores. El pasajero es el iniciador del itinerario, y el conductor es el que completa el itinerario. Cada itinerario tiene un punto de partida y un punto final, y el concepto correspondiente es la dirección. Los conductores usan vehículos personales para completar los viajes, por lo que los vehículos son otro concepto.
Encontramos otros subcampos basados en conceptos, y el concepto de viaje pertenece al campo central. Los conductores y los pasajeros deben pertenecer a varios subdominios independientes y luego gestionarse por separado, lo que da como resultado dos subdominios de gestión de pasajeros y gestión de conductores . El concepto de dirección pertenece al subcampo de gestión de direcciones ; el concepto de vehículo pertenece al subcampo de gestión de conductores.
Después de dividir los subdominios por los conceptos del dominio, el siguiente paso es continuar descubriendo nuevos subdominios a partir de las operaciones en el dominio. En el escenario de usuario se menciona que es necesario verificar el itinerario, y esta operación tiene su correspondiente subcampo verificación de itinerario . Una vez finalizado el viaje, el pasajero debe realizar un pago, y esta operación tiene su correspondiente subcampo de gestión de pagos .
La siguiente figura muestra los subámbitos en la aplicación de ejemplo.
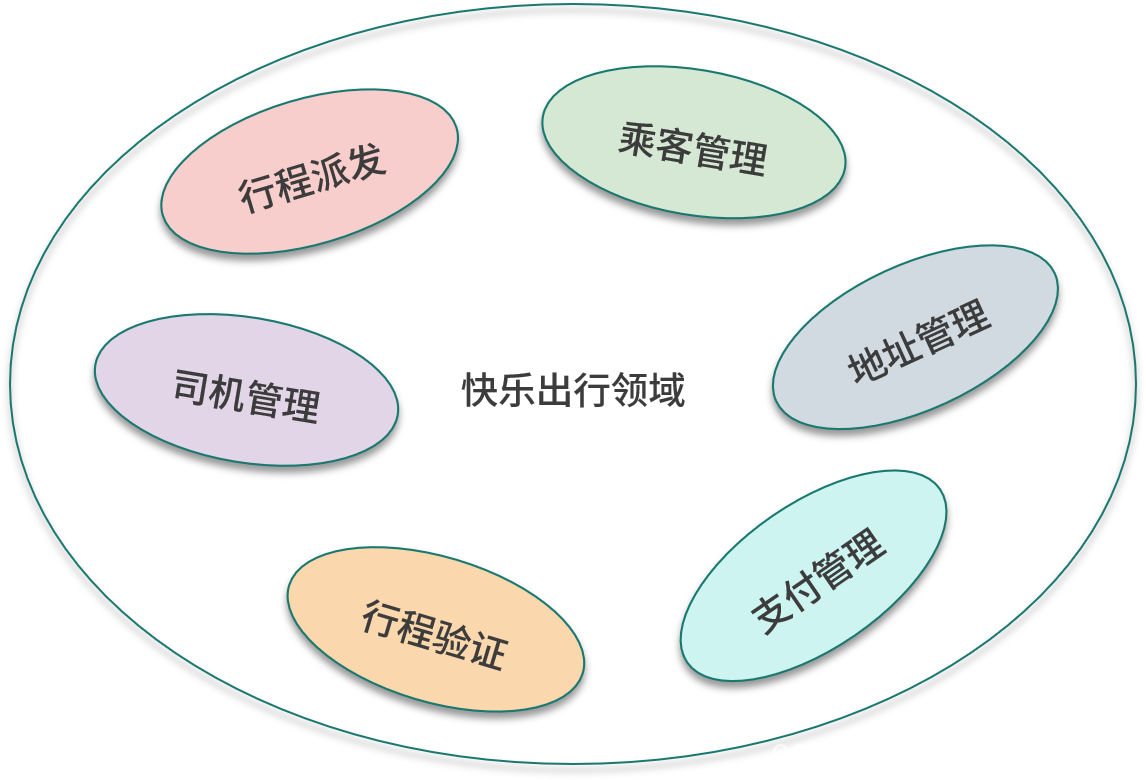 

contexto acotado
Después de identificar el dominio central y otros subdominios, el siguiente paso puede ser pasar del espacio del problema al espacio de la solución. En primer lugar, los subdominios se asignan al contexto delimitado, y el contexto delimitado tiene el mismo nombre que el subdominio; luego, se modela el contexto delimitado y la tarea principal del modelado es concretar los conceptos relacionados.
Distribución de itinerarios
La entidad importante en el modelo de despacho de itinerarios es el itinerario, que también es la raíz del agregado en el que reside el itinerario. Un viaje tiene sus ubicaciones de inicio y finalización, expresadas como direcciones de objetos de valor. El itinerario lo inicia el pasajero, por lo que la entidad del itinerario debe tener una referencia al pasajero. Cuando el sistema selecciona un conductor para aceptar el itinerario, la entidad del itinerario tiene una referencia al conductor. Durante todo el ciclo de vida, el viaje puede estar en diferentes estados, y existe un atributo y su tipo de enumeración correspondiente para describir el estado del viaje.
La siguiente figura muestra las entidades y los objetos de valor en el modelo.
 

gestión de pasajeros
La entidad importante en el modelo de Gestión de Pasajeros es el Pasajero, que también es la raíz del Agregado en el que reside el Pasajero. Los atributos de la entidad del pasajero incluyen nombre, dirección de correo electrónico, número de contacto, etc. La entidad del pasajero tiene una lista de direcciones guardadas asociadas, y la dirección es una entidad.
La siguiente figura muestra las entidades en el modelo.
 

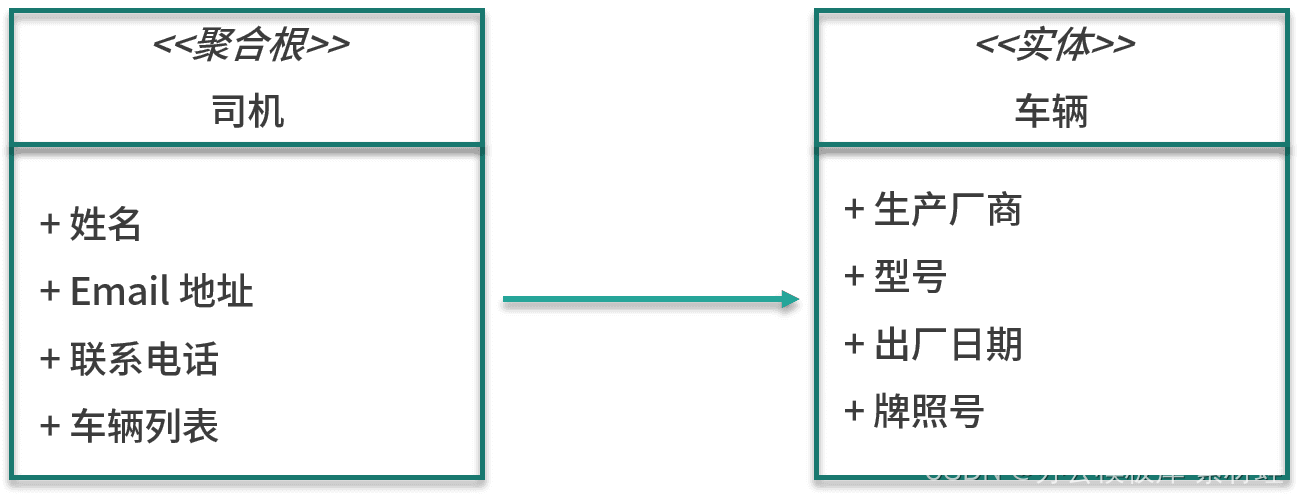
gestión de conductores
La entidad importante en el modelo de gestión de controladores es el controlador, que también es la raíz del agregado en el que reside el controlador. Los atributos de la entidad del conductor incluyen el nombre, la dirección de correo electrónico, el número de contacto, etc. Además de la entidad del conductor, la agregación también incluye la entidad del vehículo. Los atributos de la entidad del vehículo incluyen el fabricante, el modelo, la fecha de fabricación y la licencia. numero de placa
La siguiente figura muestra las entidades en el modelo.

gestión de direcciones
La entidad importante en el modelo de gestión de direcciones es la dirección, que es jerárquica, desde provincias, municipios y regiones autónomas hasta pueblos y calles. Además de la dirección jerárquica, existe otro dato importante, es decir, las coordenadas de ubicación geográfica, incluyendo longitud y latitud.
verificación de itinerario
El modelo de verificación de itinerario no contiene entidades específicas, sino servicios e implementaciones de algoritmos relacionados que verifican el itinerario.
gestión de pagos
Una entidad importante en el modelo de gestión de pagos es el registro de pago, que contiene información como referencias a itinerarios y estado de pago.
Interacción entre contextos acotados
En el modelo de nuestro contexto definido, la entidad de itinerario del modelo de despacho de itinerario debe hacer referencia a la entidad raíz del "pasajero" agregado en el modelo de gestión de pasajeros, y la entidad raíz del "conductor" agregado en el modelo de gestión de conductores. . En la Lección 07, mencionamos que los objetos externos solo pueden hacer referencia a la entidad raíz del agregado y, al hacer referencia, se debe hacer referencia al identificador de la entidad raíz del agregado, no a la entidad en sí. Los identificadores de la entidad Pasajero y la entidad Conductor son tipos de cadena, por lo que la entidad Viaje contiene dos propiedades de tipo Cadena para referirse a la entidad Pasajero y la entidad Conductor respectivamente.
Cuando el mismo concepto aparece en modelos en diferentes contextos delimitados, se requiere el mapeo y podemos usar el modo de mapeo de contexto mencionado en la Lección 07 para el mapeo.
Tanto en la gestión de direcciones como en el contexto de envío de itinerarios, existe la noción de una dirección. La entidad de dirección en la gestión de direcciones es una estructura compleja, que incluye nombres geográficos de diferentes niveles, que sirve para realizar la selección de direcciones y la consulta de direcciones en varios niveles. En el contexto de un envío de itinerario, una dirección consiste simplemente en un nombre completo y coordenadas de ubicación geográfica. Para establecer un mapa entre los dos contextos, podemos agregar una capa anticorrosión al contexto de despacho de viajes para la conversión del modelo.
Migración de aplicaciones monolíticas existentes
La aplicación de muestra en esta columna es una nueva aplicación creada desde cero, por lo que no existe una implementación a la que referirse cuando se dividen los microservicios. Al migrar una aplicación monolítica existente a una arquitectura de microservicios, la división de microservicios será más rastreable. A partir de la implementación existente de la aplicación monolítica, puede obtener información sobre la interacción real de cada parte del sistema, lo que lo ayudará a comprender más. es bueno dividirlos según sus responsabilidades. Los microservicios divididos de esta manera están más cerca de la situación de operación real.
Sam Newman de ThoughtWorks compartió su experiencia en la división de microservicios del producto SnapCI en su libro "Building Microservices". Debido a la experiencia relevante del proyecto de código abierto GoCD, el equipo de SnapCI dividió rápidamente los microservicios de SnapCI. Sin embargo, existen algunas diferencias entre los escenarios de usuario de GoCD y SnapCI. Después de un período de tiempo, el equipo de SnapCI descubrió que la división de microservicios actual ha traído muchos problemas. A menudo necesitan hacer algunos cambios en múltiples microservicios, lo que resulta en una gran sobrecarga. . .
Lo que hizo el equipo de SnapCI fue fusionar estos microservicios nuevamente en un solo monolito, lo que les dio más tiempo para comprender cómo funcionaba realmente el sistema. Un año después, el equipo de SnapCI volvió a dividir este sistema monolítico en microservicios.Después de esta división, los límites de los microservicios se volvieron más estables. Este ejemplo de SnapCI ilustra que el conocimiento del dominio es fundamental al particionar microservicios.
Resumir
La partición de microservicios es crucial en el desarrollo de aplicaciones de la arquitectura de microservicios. Al aplicar la idea de diseño dirigido por dominio, la división de microservicios se transforma en la división de subdominios en diseño dirigido por dominio, y luego los conceptos en el dominio se modelan a través del contexto definido. Las transformaciones de modelos se pueden realizar a través de patrones de mapeo entre contextos definidos.
Clase 09: Marco y entorno de desarrollo de implementación rápida
Esta clase presentará el contenido relacionado con el "entorno y marco de desarrollo de implementación rápida".
En las horas de clase anteriores, presentamos los conocimientos previos relacionados con la arquitectura de microservicios nativos de la nube, y las próximas horas de clase entrarán en el desarrollo real de microservicios. Esta clase es la primera clase relacionada con el desarrollo de microservicios. Se centrará en cómo preparar el entorno de desarrollo local y presentará el marco, las bibliotecas de terceros y las herramientas utilizadas en la aplicación de muestra.
Necesario para el desarrollo
Los requisitos previos de desarrollo se refieren a aquellos necesarios para el entorno de desarrollo.
Java
Los microservicios de la aplicación de muestra se desarrollan en base a Java 8. A pesar de que se lanzó Java 14, la aplicación de muestra todavía usa la versión anterior de Java 8, porque esa versión todavía se usa ampliamente y las nuevas funciones agregadas después de Java 8 no son útiles para la aplicación de muestra. Si JDK 8 no está instalado, se recomienda que vaya al sitio web de AdoptOpenJDK para descargar el instalador de OpenJDK 8. En MacOS y Linux, puede usar SDKMAN! para instalar JDK 8 y administrar diferentes versiones de JDK.
La siguiente es la salida de java -version:
openjdk versión "1.8.0_242" OpenJDK Runtime Environment (AdoptOpenJDK)(compilación 1.8.0_242-b08) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(compilación 25.242-b08, modo mixto)
Experto
La herramienta de compilación utilizada por la aplicación de muestra es Apache Maven. Puede instalar manualmente Maven 3.6 o usar el Maven integrado en el IDE para compilar el proyecto. Se recomienda HomeBrew para MacOS y Linux , y Chocolatey para Windows .
Entorno de desarrollo integrado
Un buen IDE puede mejorar en gran medida la productividad del desarrollador. En términos de IDE, hay principalmente dos opciones: IntelliJ IDEA y Eclipse; en términos de elección de IDE, no hay mucha diferencia entre los dos. Yo uso IntelliJ IDEA Community Edition 2020.
Estibador
El entorno de desarrollo local necesita usar Docker para ejecutar los servicios de soporte requeridos por la aplicación, incluido el middleware de mensajes y bases de datos. A través de Docker se soluciona el problema de instalación de diferentes servicios de software, haciendo muy sencilla la configuración del entorno de desarrollo. Por otro lado, el entorno de producción y ejecución de la aplicación es Kubernetes, que también se despliega mediante contenedorización, lo que asegura la consistencia entre el entorno de desarrollo y el entorno de producción. Para simplificar el proceso de desarrollo local, Docker Compose se utiliza en el entorno local para la orquestación de contenedores.
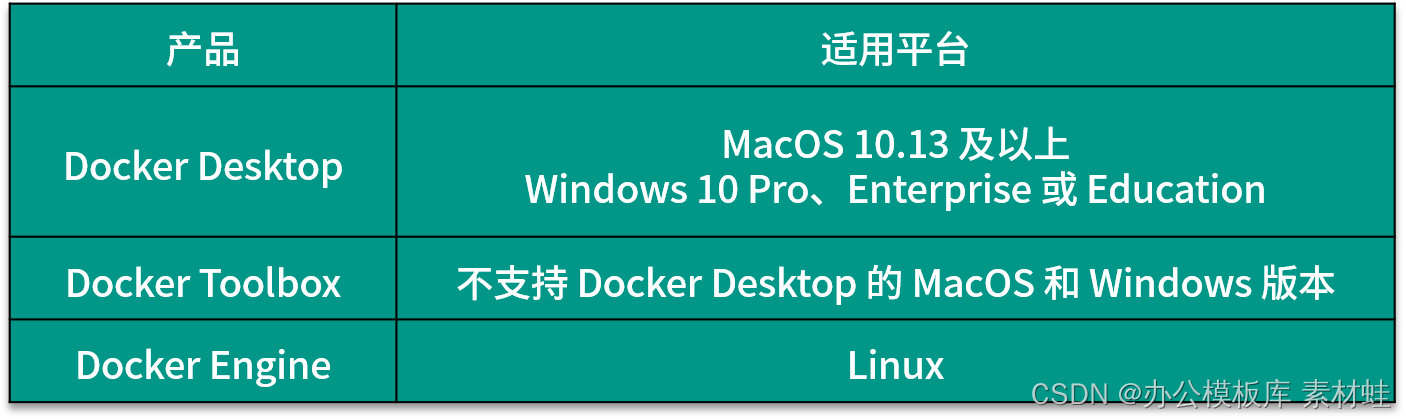
Dependiendo del sistema operativo del entorno de desarrollo, la forma de instalar Docker es diferente. Hay 3 productos Docker diferentes que se pueden usar para instalar Docker, a saber, Docker Desktop, Docker Toolbox y Docker Engine. La siguiente tabla muestra las plataformas aplicables de estos 3 productos. Para MacOS y Windows, si la versión lo admite, primero se debe instalar Docker Desktop y luego se debe considerar Docker Toolbox.

El producto Docker Desktop consta de muchos componentes, incluidos Docker Engine, Docker Command Line Client, Docker Compose, Notary, Kubernetes y Credential Helper. La ventaja de Docker Desktop es que puede usar directamente el soporte de virtualización proporcionado por el sistema operativo, lo que puede proporcionar una mejor integración. Además, Docker Desktop también proporciona una interfaz de administración gráfica. La mayoría de las veces, operamos Docker a través de la línea de comandos de Docker. Si el comando docker -v puede mostrar la información de versión correcta, significa que Docker Desktop se instaló correctamente.
La siguiente figura muestra la información de la versión de Docker Desktop.
 

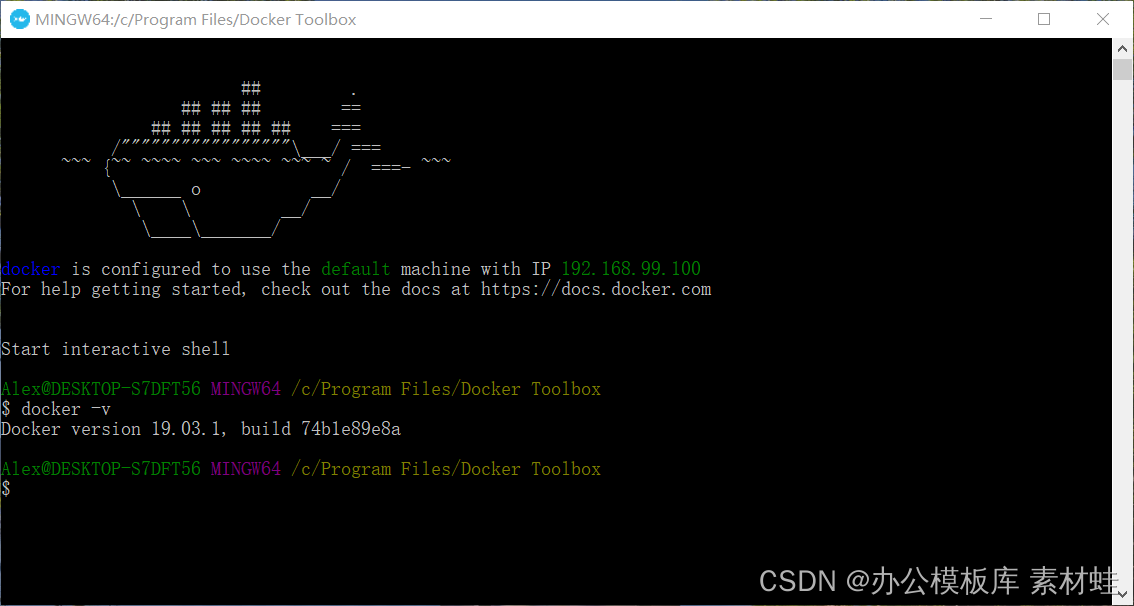
Docker Toolbox es el predecesor de Docker Desktop. Docker Toolbox usa VirtualBox para la virtualización, que tiene requisitos de sistema bajos. Docker Toolbox consta de Docker Machine, Docker Command Line Client, Docker Compose, Kitematic y Docker Quickstart Terminal. Una vez completada la instalación, inicie un terminal a través de Docker Quickstart para ejecutar los comandos de Docker.
La siguiente figura es el efecto de ejecución del terminal Docker Quickstart.

En Linux, solo podemos instalar Docker Engine directamente y también necesitamos instalar Docker Compose manualmente.
Hay una diferencia significativa en el uso de Docker Desktop y Docker Toolbox. El contenedor que se ejecuta en Docker Desktop puede usar la red en el host del entorno de desarrollo actual, y se puede acceder al puerto expuesto por el contenedor mediante localhost; el contenedor que se ejecuta en Docker Toolbox en realidad se ejecuta en una máquina virtual de VirtualBox, a la que se debe acceder a través de la dirección IP de la máquina virtual para acceder. Podemos obtener la dirección IP a través del comando docker-machine ip en el terminal iniciado por Docker Quickstart, como 192.168.99.100. Se debe acceder al puerto expuesto por el contenedor mediante esta dirección IP, que no es fija. La práctica recomendada es agregar un nombre de host llamado dockervm en el archivo de hosts y apuntar a esta dirección IP. Utilice siempre el nombre de host de dockervm cuando acceda a servicios en contenedores. Cuando cambia la dirección IP de la máquina virtual, solo se debe actualizar el archivo de hosts.
Kubernetes
Al implementar aplicaciones, necesitamos un clúster de Kubernetes disponible. Generalmente, hay tres formas de crear un clúster de Kubernetes.
La primera forma es usar la plataforma en la nube para crear archivos . Muchas plataformas en la nube brindan soporte para Kubernetes. La plataforma en la nube es responsable de la creación y administración de los clústeres de Kubernetes. Solo necesita usar la interfaz web o las herramientas de línea de comandos para crear rápidamente los clústeres de Kubernetes. La ventaja de usar la plataforma en la nube es que ahorra tiempo y esfuerzo, pero es costoso.
La segunda forma es instalar un clúster de Kubernetes en una máquina virtual o bare metal físico . La máquina virtual puede ser proporcionada por la plataforma en la nube, o puede ser creada y administrada por sí misma, y también es posible usar el clúster físico sin sistema operativo mantenido por ella misma. Hay muchas herramientas de instalación de Kubernetes de código abierto disponibles, como RKE , Kubespray , Kubicorn , etc. La ventaja de este método es que los gastos generales son relativamente pequeños, pero la desventaja es que requiere una instalación previa y un mantenimiento posterior.
La tercera forma es instalar Kubernetes en el entorno de desarrollo local . Docker Desktop ya viene con Kubernetes, solo necesitas habilitarlo, además, también puedes instalar Minikube . La ventaja de este enfoque es que tiene los gastos generales más bajos y es altamente controlable. La desventaja es que consumirá una gran cantidad de recursos en el entorno de desarrollo local.
Entre los tres métodos anteriores, el método de la plataforma en la nube es adecuado para la implementación del entorno de producción. Para el entorno de prueba y preparación de la entrega (puesta en escena), puede elegir una plataforma en la nube o puede optar por crear el entorno usted mismo desde la perspectiva del costo. Kubernetes en el entorno de desarrollo local también es necesario en muchos casos.
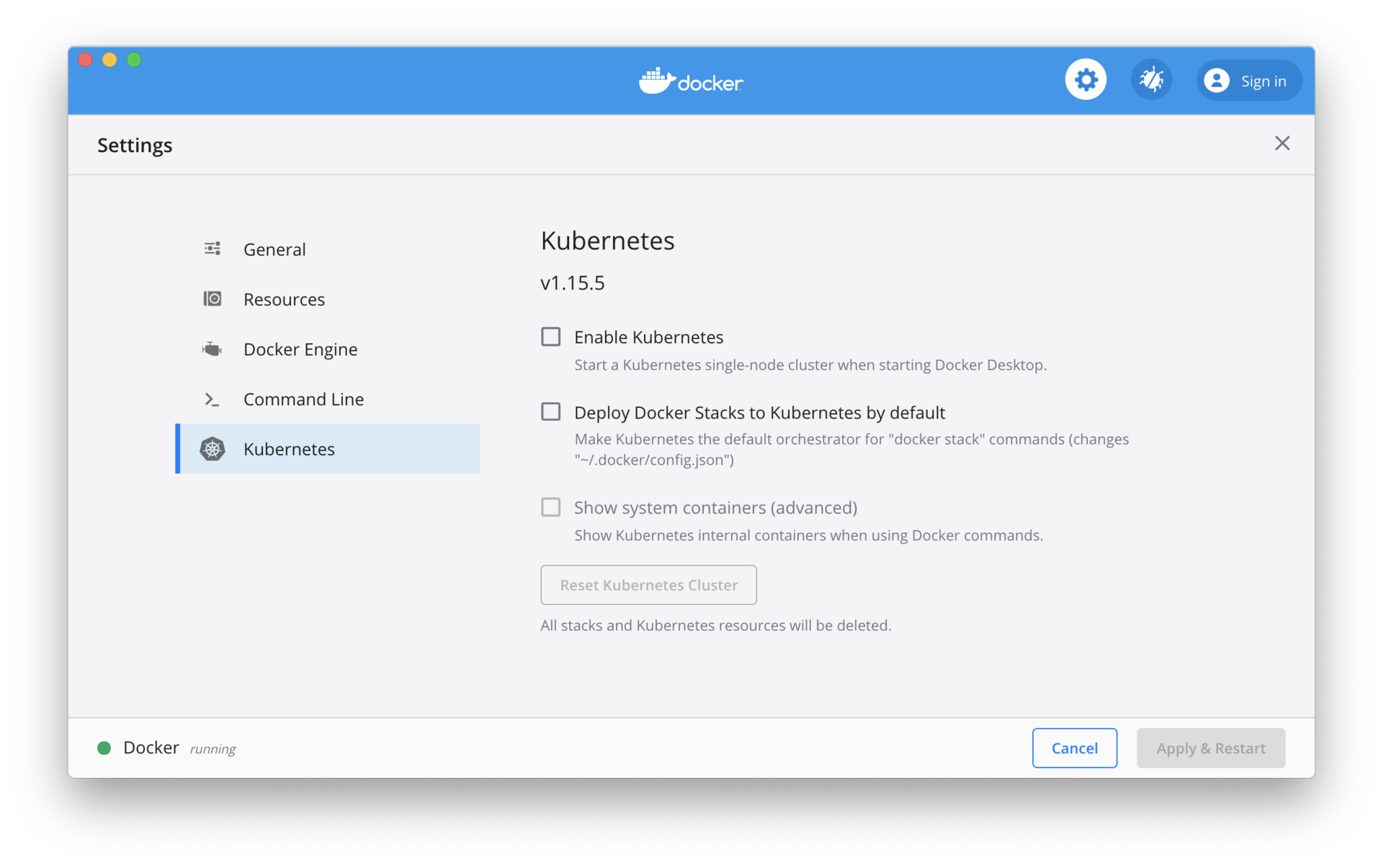
En un entorno de desarrollo local, Kubernetes para Docker Desktop debe habilitarse manualmente. Para Minikube, puede consultar la documentación oficial para instalarlo. La diferencia entre los dos es que la versión de Kubernetes que viene con Docker Desktop generalmente tiene algunas versiones menores por detrás. Como se muestra en la figura a continuación, marque la opción "Habilitar Kubernetes" para iniciar el clúster de Kubernetes. La versión de Kubernetes que viene con Docker Desktop es la 1.15.5 y la última versión de Kubernetes es la 1.18.

Frameworks y bibliotecas de terceros
La aplicación de ejemplo utiliza algunos marcos y bibliotecas de terceros, que se presentan brevemente a continuación.
Spring Framework y Spring Boot
Es difícil desarrollar aplicaciones Java sin el framework Spring. Spring Boot también es una de las opciones populares para desarrollar microservicios en Java en la actualidad. La introducción de Spring y Spring Boot está fuera del alcance de esta columna. Los microservicios de la aplicación de muestra usarán algunos subproyectos en el marco Spring, incluidos Spring Data JPA, Spring Data Redis y Spring Security.
Tranvía Eventuate
Eventuate Tram es un marco de mensajes transaccionales utilizado por la aplicación de ejemplo. El modo de mensajes transaccionales desempeña un papel importante en el mantenimiento de la coherencia de los datos. Eventuate Tram brinda soporte para patrones de mensajería transaccional y también incluye soporte para mensajería asíncrona. Eventuate Tram se integra con PostgreSQL y Kafka.
Servidor y marco Axon
La aplicación de muestra también utiliza tecnología de abastecimiento de eventos y CQRS, y la implementación de abastecimiento de eventos utiliza el servidor Axon y el marco Axon. El servidor Axon proporciona almacenamiento de eventos; el marco Axon se conecta al servidor Axon y proporciona compatibilidad con CQRS.
Servicios y herramientas de soporte
Los servicios de soporte de la aplicación de muestra son necesarios en el tiempo de ejecución y las herramientas relacionadas se pueden usar en el desarrollo.
Apache Kafka y ZooKeeper
La aplicación de ejemplo utiliza mensajes asincrónicos entre diferentes microservicios para garantizar la coherencia final de los datos, por lo que se requiere un middleware de mensajes. Apache Kafka es el middleware de mensajes que se usa en la aplicación de muestra y ZooKeeper es necesario para ejecutar Kafka.
postgresql
Algunos de los microservicios de la aplicación de muestra usan una base de datos relacional para almacenar datos. Entre muchas bases de datos relacionales, se elige PostgreSQL como base de datos para algunos microservicios en la aplicación de ejemplo.
herramienta de gestión de base de datos
En desarrollo, es posible que necesitemos ver datos en una base de datos relacional. Hay muchos clientes PostgreSQL disponibles, incluidos DBeaver , pgAdmin 4 , OmniDB, etc. También puede usar complementos IDE, como el complemento Database Navigator en IntelliJ IDEA.
Cartero
En el desarrollo y las pruebas, a menudo necesitamos enviar solicitudes HTTP para probar los servicios REST. Existen muchas herramientas relacionadas con las pruebas de los servicios REST, como Postman , Insomnia y Advanced REST Client . Recomiendo usar Postman porque puede importar directamente los archivos de especificación de OpenAPI y generar las plantillas de solicitud REST correspondientes. Dado que nuestros microservicios adoptan un enfoque de diseño basado en API, cada API de microservicio tiene un archivo de especificación de OpenAPI correspondiente. Durante el desarrollo, solo necesitamos importar el archivo OpenAPI en Postman, y luego podemos comenzar a probar, ahorrando el trabajo de crear solicitudes manualmente.
Resumir
Antes de explicar el combate real, primero debemos preparar el entorno de desarrollo local. Esta clase primero presenta cómo instalar y configurar Java, Maven, el entorno de desarrollo integrado, Docker y Kubernetes; luego, presenta brevemente el marco y las bibliotecas de terceros utilizadas en la aplicación de muestra; finalmente, presenta los servicios de soporte utilizados por la aplicación de muestra y el herramientas necesarias para el desarrollo.
Clase 10: Diseño basado en API con OpenAPI y Swagger
A partir de esta clase, entraremos en el desarrollo real de aplicaciones de arquitectura de microservicios nativas de la nube.Antes de presentar la implementación específica de microservicios, la primera tarea es diseñar y determinar la API abierta de cada microservicio . La API abierta ha sido muy popular en los últimos años, y muchos servicios en línea y agencias gubernamentales han proporcionado API abierta, que se ha convertido en una función estándar de los servicios en línea. Los desarrolladores pueden usar la API abierta para desarrollar varias aplicaciones.
Aunque existe cierta relación entre la API abierta en la aplicación de microservicio y la API abierta en el servicio en línea, sus funciones son diferentes. En la aplicación de la arquitectura de microservicios, los microservicios solo pueden interactuar a través de la comunicación entre procesos, generalmente mediante REST o gRPC. Dicho método de interacción debe corregirse de manera formal, formando una API abierta. Una API abierta de un microservicio protege los detalles de implementación interna del servicio de los usuarios externos, y también es la única forma en que los usuarios externos interactúan con él ( por supuesto, aquí se refiere a la integración entre microservicios solo a través de API, si se utilizan eventos asíncronos para la integración, estos eventos también son interactivos). A partir de esto podemos ver la importancia de la API de microservicio. Desde la perspectiva de la audiencia, los usuarios de las API de microservicios son principalmente otros microservicios, es decir, principalmente usuarios internos de la aplicación, a diferencia de las API de servicios en línea, que están orientadas principalmente a usuarios externos. Además de otros microservicios, la interfaz web de la aplicación y los clientes móviles también necesitan usar la API del microservicio, pero generalmente usan la API del microservicio a través de una puerta de enlace API.
Debido a la importancia de la API de microservicios, necesitamos diseñar la API muy temprano, es decir, la estrategia API-primero.
Una estrategia API-primero
Si tiene experiencia en el desarrollo de API de servicios en línea, encontrará que, por lo general, la implementación es lo primero, seguida de la API pública. Esto se debe a que la API pública no se consideró antes del diseño, sino que se agregó más tarde. El resultado de este enfoque es que la API abierta solo refleja la implementación real actual, no lo que debería ser la API. El método de diseño de la API primero (API First) es anteponer el diseño de la API a la implementación específica. API first enfatiza que el diseño de la API debe considerarse más desde la perspectiva de los usuarios de la API.
Antes de escribir la primera línea del código de implementación, el proveedor de API y el usuario deben tener una discusión completa sobre la API, combinar las opiniones de los dos lados, finalmente determinar todos los detalles de la API y arreglarlo en un formato formal para convertirse en una especificación API. Después de eso, el proveedor de la API se asegura de que la implementación real cumpla con los requisitos de la especificación de la API y el usuario escribe la implementación del cliente de acuerdo con la especificación de la API. La especificación API es un contrato entre el proveedor y el usuario, y la estrategia API first se ha aplicado en el desarrollo de muchos servicios en línea. Una vez diseñada e implementada la API, la interfaz web y la aplicación móvil del propio servicio en línea, al igual que otras aplicaciones de terceros, se implementan utilizando la misma API.
La estrategia API-first juega un papel más importante en la implementación de aplicaciones de la arquitectura de microservicios. Aquí es necesario distinguir dos tipos de API: una es la API proporcionada para otros microservicios y la otra es la API proporcionada para la interfaz web y los clientes móviles. Al presentar el diseño basado en dominios en la clase 07, mencioné el servicio de host abierto y el lenguaje público en el modo de mapeo del contexto acotado, y los microservicios corresponden al contexto acotado uno a uno. Si combina el servicio de host abierto con el lenguaje común, obtiene la API del microservicio y el lenguaje común es la especificación de la API.
A partir de aquí podemos saber que el propósito del primer tipo de API de microservicio es el mapeo de contexto, que es significativamente diferente del rol del segundo tipo de API. Por ejemplo, el microservicio de gestión de pasajeros proporciona funciones para gestionar pasajeros, incluido el registro de pasajeros, la actualización de información y la consulta. Para la App del pasajero, estas funciones requieren el soporte de la API. Si otros microservicios necesitan obtener información del pasajero, también deben llamar a la API del microservicio de gestión de pasajeros. Esto es para mapear el concepto de pasajeros entre diferentes microservicios.
implementación de API
En la implementación de la API, uno de los primeros problemas es elegir el método de implementación de la API. En teoría, las API internas de los microservicios no tienen altos requisitos de interoperabilidad y pueden usar formatos privados. Sin embargo, para utilizar la cuadrícula de servicios, se recomienda utilizar un formato estándar común. La siguiente tabla muestra el formato API común. Por lo general, elija entre REST y gRPC, excepto que use menos SOAP. La diferencia entre los dos es que REST usa un formato de texto y gRPC usa un formato binario; los dos difieren en popularidad, dificultad de implementación y rendimiento. En resumen, REST es relativamente más popular y menos difícil de implementar, pero su rendimiento no es tan bueno como el de gRPC.
 

La API para la aplicación de muestra en esta columna se implementa mediante REST, aunque habrá una clase dedicada a gRPC. A continuación, se describe la especificación OpenAPI relacionada con la API REST.
Especificación de API abierta
Para mejorar la comunicación entre los proveedores de API y los usuarios, necesitamos un formato estándar para describir las API. Para las API REST, este formato estándar está definido por la especificación OpenAPI.
La Especificación OpenAPI (OAS) es una especificación de API abierta administrada por la Iniciativa OpenAPI (OAI) bajo la Fundación Linux. El objetivo de la OAI es crear, evolucionar y promover un formato de descripción de API independiente del proveedor. La especificación OpenAPI se basa en la especificación Swagger, donada por SmartBear Corporation.
El documento de OpenAPI describe o define la API, y el documento de OpenAPI debe cumplir con la especificación de OpenAPI. La especificación OpenAPI define el formato de contenido de un documento OpenAPI, es decir, los objetos y sus atributos que pueden estar contenidos en él. Un documento OpenAPI es un objeto JSON que se puede representar en formato de archivo JSON o YAML. La siguiente es una introducción al formato del documento OpenAPI. Todos los ejemplos de código de esta lección usan el formato YAML.
En la especificación OpenAPI se definen varios tipos básicos, a saber, entero, número, cadena y booleano. Para cada tipo básico, el formato específico del tipo de datos se puede especificar a través del campo de formato, por ejemplo, el formato del tipo de cadena puede ser fecha, fecha y hora o contraseña.
Los campos y sus descripciones que pueden aparecer en el objeto raíz del documento OpenAPI se proporcionan en la siguiente tabla.La última versión de la especificación OpenAPI es 3.0.3.
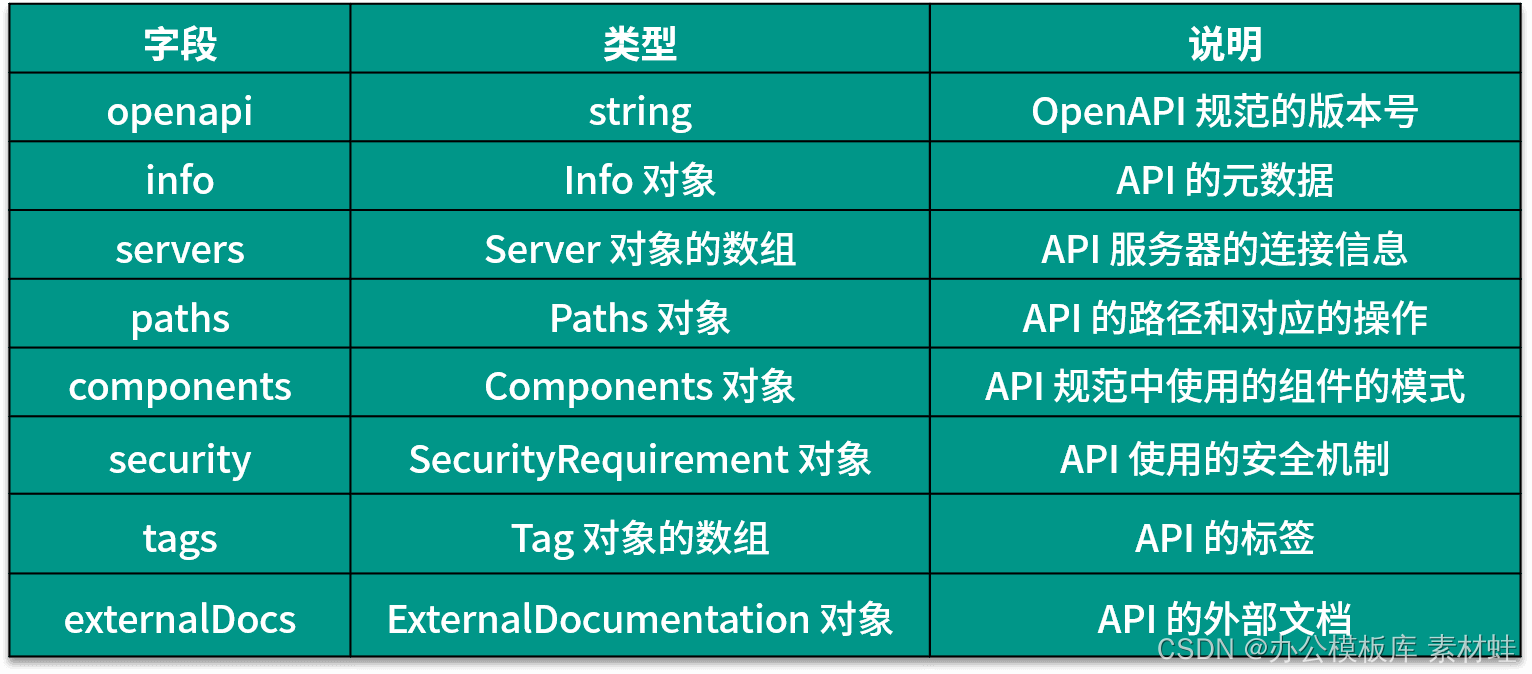 

Objeto de información
El objeto Info contiene los metadatos de la API, que pueden ayudar a los usuarios a comprender mejor la información relevante de la API. La siguiente tabla muestra los campos que se pueden incluir en el objeto Info y sus descripciones.
 

El siguiente código es un ejemplo del uso del objeto Info.
título: servicio de prueba descripción: este servicio se utiliza para pruebas simples términos de servicio: http://myapp.com/terms/ contacto: nombre: administrador url: http://www.myapp.com/support correo electrónico: support@myapp .com licencia: nombre: Apache 2.0 url: https://www.apache.org/licenses/LICENSE-2.0.html versión: 2.1.0
Objeto de servidor
El objeto Servidor representa el servidor de la API, la siguiente tabla muestra los campos que se pueden incluir en el objeto Servidor y sus descripciones.
 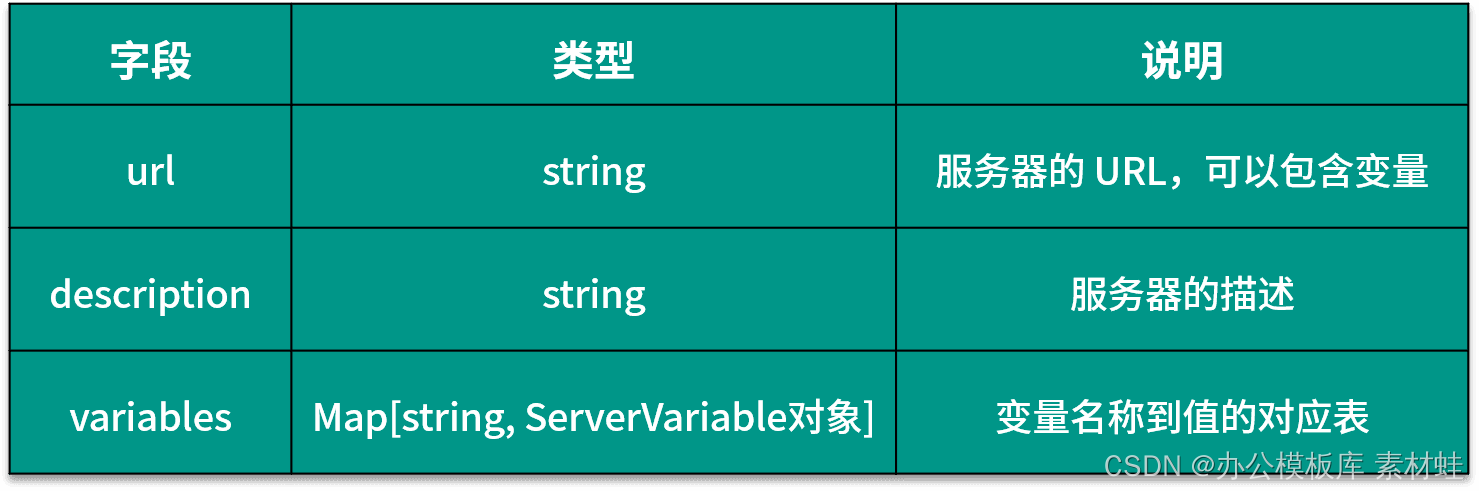

El siguiente código es un ejemplo del uso del objeto Server, donde la URL del servidor contiene dos parámetros, port y basePath, port es un tipo de enumeración y los valores opcionales son 80 y 8080.
url: http://test.myapp.com:{port}/{basePath}
descripción:
variables del servidor de prueba:
puerto:
enumeración:
- '80'
- '8080'
predeterminado: '80'
basePath:
predeterminado: v2
Objeto de rutas
Los campos en el objeto Paths son dinámicos. Cada campo representa una ruta, que comienza con "/", la ruta puede ser una plantilla de cadena que contenga variables. El valor del campo es un objeto PathItem, en el que puede usar campos comunes, como resumen, descripción, servidores y parámetros, y nombres de métodos HTTP, incluidos obtener, poner, publicar, eliminar, opciones, encabezado, parche y rastreo. , que El campo de nombre de método define los métodos HTTP admitidos por la ruta correspondiente.
Objeto de operación
En el objeto Paths, el tipo de valor del campo correspondiente al método HTTP es un objeto Operation, que representa una operación HTTP. En la siguiente tabla se muestran los campos y sus descripciones que se pueden incluir en el objeto Operación, entre estos campos se utilizan más comúnmente los parámetros, requestBody y respuestas.
 

Objeto de parámetro
Un objeto de parámetro representa los parámetros de una operación. La siguiente tabla muestra los campos que se pueden incluir en un objeto Parámetro y sus descripciones.
 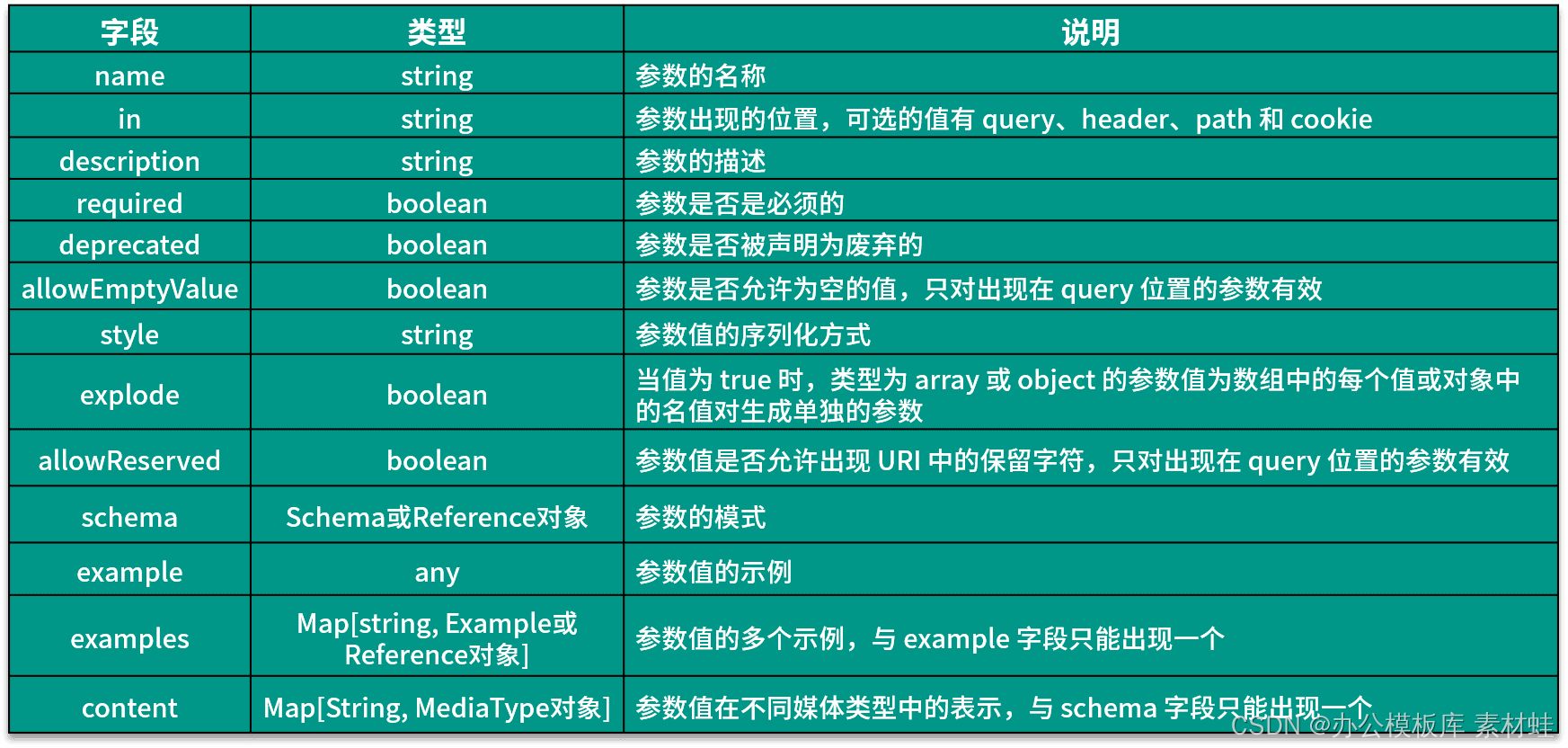

El código siguiente es un ejemplo del uso del objeto Parámetro. El id del parámetro aparece en la ruta y su tipo es cadena.
nombre: id en: ruta descripción: 乘客ID requerido: verdadero esquema: tipo: cadena
Objeto RequestBody
El objeto RequestBody representa el contenido de la solicitud HTTP. La siguiente tabla muestra los campos que se pueden incluir en el objeto RequestBody y sus descripciones.
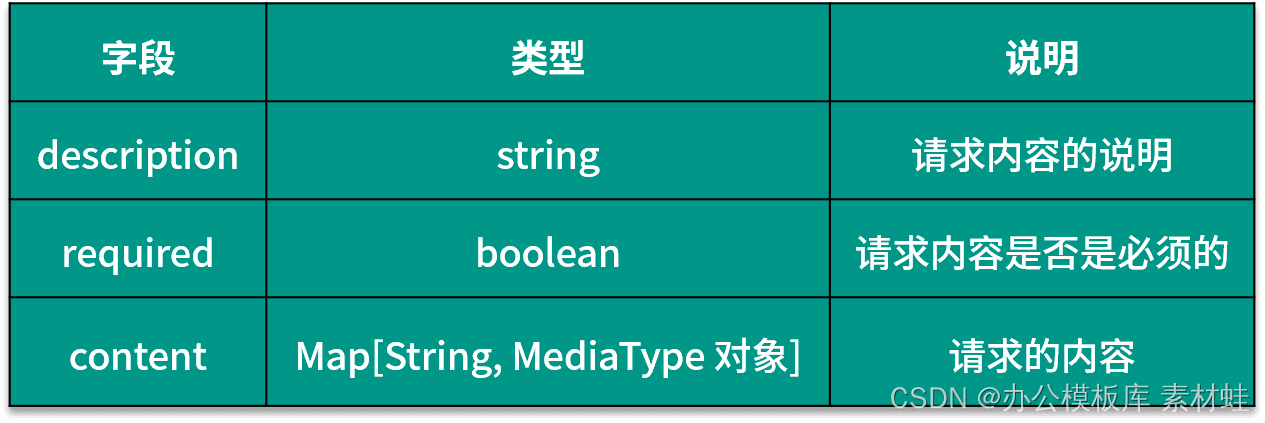 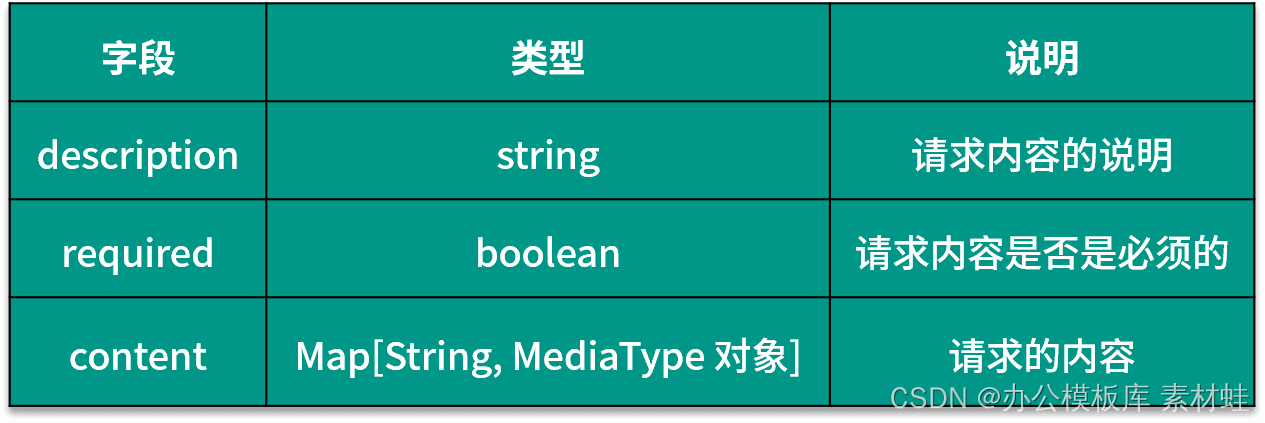

Objeto de respuestas
El objeto Respuestas representa la respuesta a la solicitud HTTP y los campos de este objeto son dinámicos. El nombre del campo es el código de estado de la respuesta HTTP y el tipo del valor correspondiente es un objeto Respuesta o Referencia. La siguiente tabla muestra los campos que se pueden incluir en el objeto Respuesta y sus descripciones.
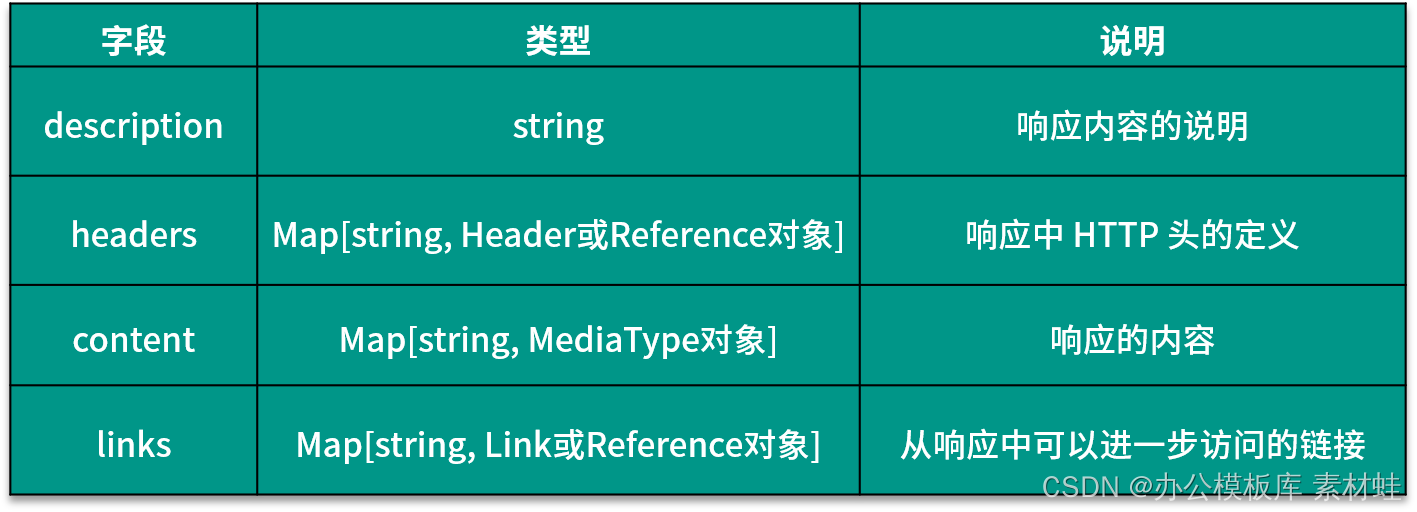 

Objeto de referencia
En la descripción de diferentes tipos de objetos, el tipo del campo puede ser un objeto Reference, que representa una referencia a otros componentes, que solo contiene un campo $ref para declarar la referencia. Las referencias pueden ser a componentes dentro del mismo documento o desde archivos externos. Dentro del documento, se pueden definir diferentes tipos de componentes reutilizables en el objeto Componentes y hacer referencia al objeto Referencia; la referencia dentro del documento es una ruta de objeto que comienza con #, como #/components/schemas/CreateTripRequest.
Objeto de esquema
El objeto Schema se utiliza para describir la definición del tipo de datos. El tipo de datos puede ser un tipo simple, una matriz o un tipo de objeto. El tipo se puede especificar a través del tipo de campo, y el campo de formato indica el formato del tipo. . Si es un tipo de matriz, es decir, el valor de tipo es matriz, debe usar los elementos de campo para representar el tipo de elementos en la matriz; si es un tipo de objeto, es decir, el valor de tipo es objeto , necesita usar las propiedades de campo para representar el tipo de propiedades en el objeto.
Ejemplo de documentación completa
A continuación se muestra un ejemplo de un documento OpenAPI completo. En el objeto de rutas, se definen tres operaciones, y la definición de tipo del contenido de la solicitud de la operación y el formato de respuesta se definen en el campo de esquemas del objeto Componentes. Se hace referencia a los campos requestBody y de respuestas de una operación mediante un objeto Reference.
openapi: '3.0.3'
información:
título:
Versión del servicio de viaje: '1.0'
servidores:
- url: http://localhost:8501/api/v1
etiquetas:
- nombre:
descripción del viaje:
Rutas relacionadas con el viaje:
/:
publicación:
etiquetas:
-
resumen de viaje: crear
ID de operación de viaje: crear
Cuerpo de solicitud de viaje:
contenido:
aplicación/json:
esquema:
$ref: "#/components/schemas/CreateTripRequest"
requerido:
respuestas verdaderas:
'201':
descripción: creado con éxito
/{tripId} :
obtener:
etiquetas:
-
resumen de viaje: obtener
ID de operación de viaje: obtener
parámetros de viaje:
- nombre: ID de viaje
en:
descripción de ruta: ID de viaje
requerido: verdadero
esquema:
tipo:
respuestas de cadena:
'200':
descripción: obtener
contenido de éxito:
aplicación/json:
esquema:
$ref: "#/components/schemas/TripVO"
'404':
descripción: Viaje no encontrado
/{tripId}/aceptar:
publicar:
etiquetas:
- viaje
resumen: 接受行程
tipo: cadena
operationId: acceptTrip
parámetros:
- nombre: tripId
en:
descripción de la ruta: 行程ID
requerido: verdadero
esquema:
tipo: cadena
requestBody:
contenido:
aplicación/json:
esquema:
$ref: "#/components/schemas/AcceptTripRequest"
requerido: verdadero
respuestas:
'200 ':
descripción: 接受成功
components:
esquemas:
CreateTripRequest:
tipo:
propiedades del objeto:
PassengerId:
startPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
requerido:
- PassengerId
- startPos
- endPos
AcceptTripRequest:
tipo:
propiedades del objeto:
driverId:
tipo: cadena
posLng:
tipo:
formato de número: doble
posLat:
tipo:
formato de número: doble
requerido:
- driverId
- posLng
- posLat
TripVO:
tipo: propiedades
del objeto :
id:
tipo: cadena
pasajeroId:
tipo: cadena
conductorId:
tipo: cadena
startPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
estado:
tipo: cadena
PositionVO: tipo:
propiedades
del objeto :
lng:
tipo:
formato de número: doble
lat:
tipo:
formato de número: doble
ID de dirección:
tipo: cadena
requerida:
- lng
- lat
Herramientas de OpenAPI
Podemos usar algunas herramientas para ayudar al desarrollo relacionado con la especificación OpenAPI. Como predecesor de la especificación OpenAPI, Swagger proporciona muchas herramientas relacionadas con OpenAPI.
editor de arrogancia
Swagger Editor es una versión web del editor de documentación de Swagger y OpenAPI. En el lado izquierdo del editor está el editor y en el lado derecho hay una vista previa de la documentación de la API. El editor de Swagger proporciona muchas funciones útiles, incluido el resaltado de sintaxis, la adición rápida de diferentes tipos de objetos, la generación de código de servidor y la generación de código de cliente, etc.
Al usar el editor Swagger, puede usar la versión en línea directamente o ejecutarlo localmente. La forma más fácil de ejecutarlo localmente es usar la imagen Docker swaggerapi/swagger-editor.
El siguiente código inicia el contenedor Docker del editor Swagger. Después de iniciar el contenedor, se puede acceder a él a través de localhost:8000.
docker run -d -p 8000:8080 swaggerapi/swagger-editor
La siguiente figura es la interfaz del editor Swagger.
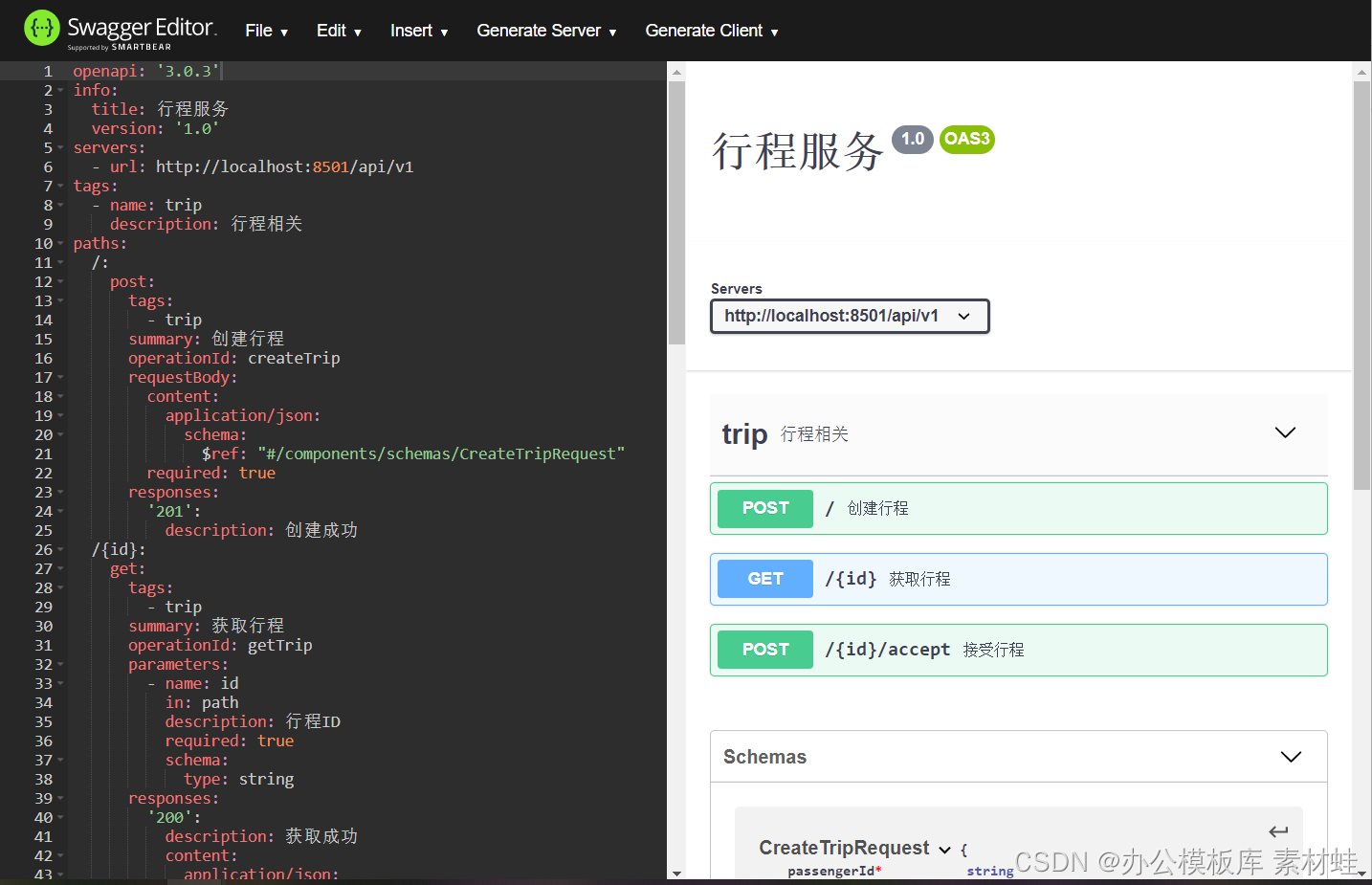 

interfaz arrogante
La interfaz de Swagger proporciona una forma intuitiva de ver e interactuar con la documentación de la API. A través de esta interfaz, puede enviar directamente solicitudes HTTP al servidor API y ver los resultados de la respuesta.
Del mismo modo, podemos usar Docker para iniciar la interfaz de Swagger como se muestra en el siguiente comando. Una vez que se inicia el contenedor, se puede acceder a él a través de localhost:8010.
docker run -d -p 8010:8080 swaggerapi/swagger-ui
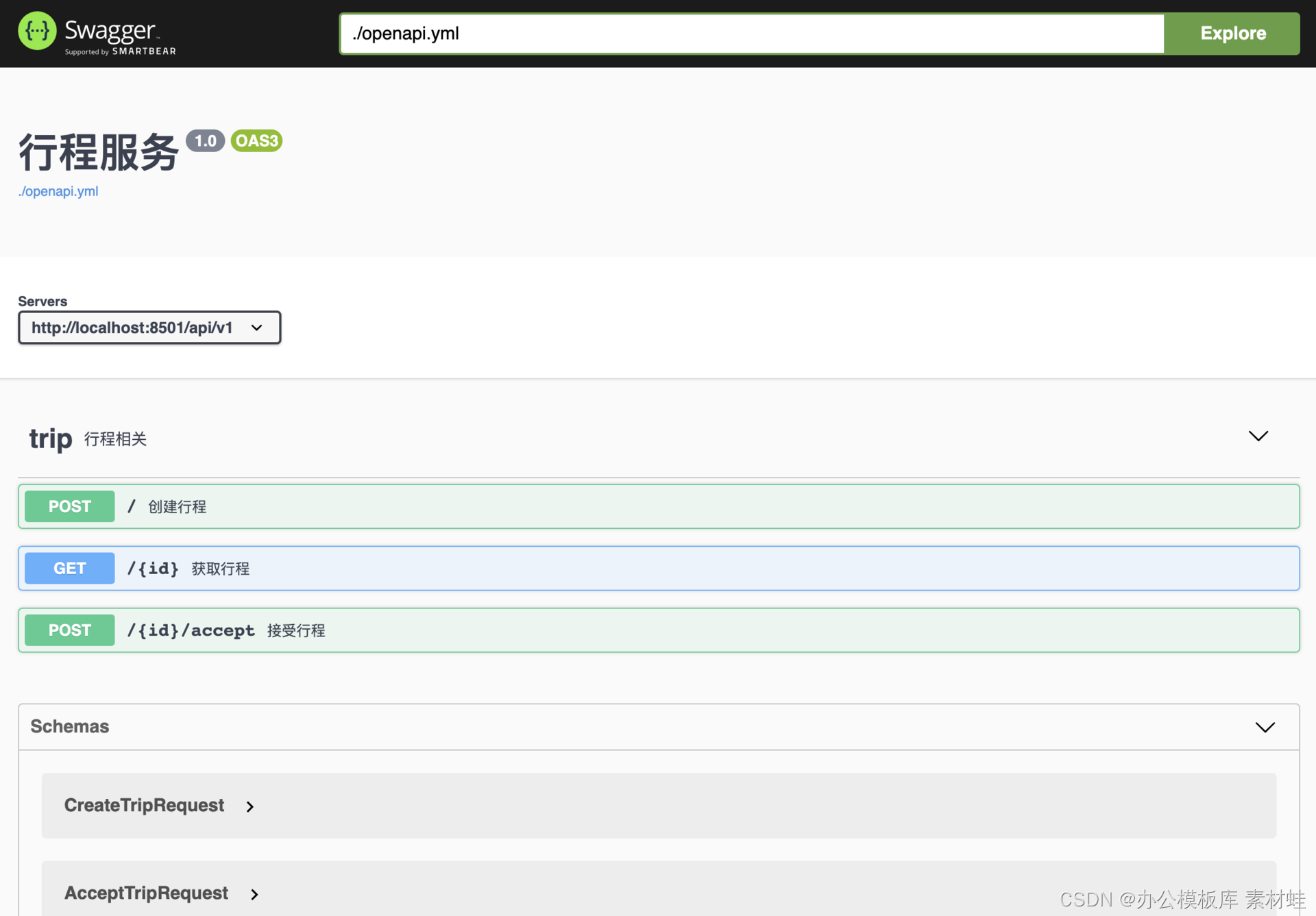
Para la documentación local de OpenAPI, se puede configurar una imagen de Docker para usar esa documentación. Suponiendo que hay un documento OpenAPI openapi.yml en el directorio actual, puede usar el siguiente comando para iniciar la imagen de Docker para mostrar el documento.
docker ejecutar -p 8010:8080 -e SWAGGER_JSON=/api/openapi.yml -v $PWD:/api swaggerapi/swagger-ui
La siguiente figura es una captura de pantalla de la interfaz de Swagger.

codigo de GENERACION
A través del documento OpenAPI, puede usar la herramienta de generación de código proporcionada por Swagger para generar automáticamente el código auxiliar del servidor y el cliente. Se pueden usar diferentes lenguajes de programación y marcos para la generación de código.
Los lenguajes de programación y los marcos compatibles con las herramientas de generación de código se detallan a continuación.
aspnetcore, csharp, csharp-dotnet2, go-server, html dinámico, html, html2, java, jaxrs-cxf-client, jaxrs- cxf, inflector, jaxrs-cxf-cdi, jaxrs-spec, jaxrs-jersey, jaxrs- di, jaxrs-resteasy-eap, jaxrs-resteasy, micronaut , primavera, nodejs-server, openapi, openapi-yaml, kotlin-client, kotlin-server, php, python, python-flask, r, scala, scal a- akka -http-servidor, swift3, swift4, swift5, typescript-angular, javascript
La herramienta de generación de código es un programa Java que se puede ejecutar directamente después de la descarga. Después de descargar el archivo JAR swagger-codegen-cli-3.0.19.jar , puede usar el siguiente comando para generar el código del cliente Java, donde el parámetro -i especifica el documento OpenAPI de entrada, -l especifica el idioma generado y - o especifica la tabla de contenido de salida.
java -jar swagger-codegen-cli-3.0.19.jar generar -i openapi.yml -l java -o /tmp
Además de generar código de cliente, también se puede generar código auxiliar de servidor. El siguiente código es para generar el código auxiliar del servidor NodeJS:
java -jar swagger-codegen-cli-3.0.19.jar generar -i openapi.yml -l nodejs-server -o /tmp
Resumir
La estrategia API first garantiza que la API de microservicio se diseñe teniendo en cuenta las necesidades de los usuarios de la API, lo que hace que la API sea un buen contrato entre el proveedor y el usuario. Esta clase primero presenta la estrategia de diseño de API, luego presenta los diferentes métodos de implementación de API, luego presenta la especificación OpenAPI de REST API y finalmente presenta las herramientas relacionadas de OpenAPI.