I. Resumen
Definición: Un programa en ejecución y los recursos que ocupa (CPU, memoria, recursos del sistema, etc.) se denominan procesos.
El archivo c escrito se denomina código fuente (altamente legible para los humanos, pero irreconocible para la computadora) y compilado para generar un programa ejecutable binario reconocible por la CPU, que se almacena en un medio de almacenamiento (generalmente una memoria externa). en este momento se genera un programa en lugar de un proceso. Una vez que el programa comienza a ejecutarse, el programa en ejecución y los recursos que ocupa se denominan procesos.
El concepto de un proceso es para el sistema, no para el usuario.
Los procesos ocupan cuatro tipos de recursos:
- El comando lscpu de la CPU (Unidad central de procesamiento) puede ver la información detallada de la CPU
- El comando Memory (memory) free -h puede ver el tamaño de la memoria del sistema
- Disco _
- Red _
En un sistema operativo tradicional, un programa no puede ejecutarse de forma independiente y la unidad básica para la asignación de recursos y la operación independiente es un proceso .
Un programa se puede ejecutar varias veces, lo que también significa que varios procesos pueden ejecutar el mismo programa.
2. Distribución de la memoria del espacio de proceso
Los objetos de la gestión de la memoria de procesos de Linux son la memoria virtual .
Cada proceso tiene su propio espacio de memoria virtual de 0-4G que no interfiere entre sí. 0-3G es el espacio de usuario para ejecutar el propio código del usuario, el espacio superior de 1 GB es el espacio del kernel para ejecutar la llamada al sistema Linux x, donde se almacena el código de todo el kernel y todos los módulos del kernel, y lo que el usuario ve y toques es la dirección virtual , no la dirección física real de la memoria .
En Linux, un proceso tiene tres partes de datos en la memoria, a saber, "segmento de código", "segmento de pila" y "segmento de datos" . La CPU general tiene los tres registros de segmento anteriores para facilitar el funcionamiento del sistema operativo. Estas tres partes son las partes necesarias para formar una secuencia de ejecución completa.
"Segmento de código" : Almacena los datos del código del programa.Si hay varios procesos ejecutando el mismo programa en la máquina, pueden usar el mismo segmento de código.
"Segmento de pila" : Almacena la dirección de retorno de la subrutina, los parámetros de la subrutina, las variables locales del programa y la dirección de la memoria solicitada dinámicamente por malloc().
"Segmento de datos" : el espacio de memoria para almacenar las variables globales del programa, variables estáticas y constantes.
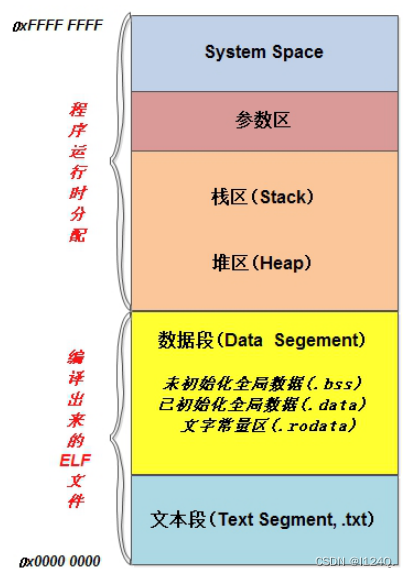
- Pila : pila estática, el valor de la variable en la pila es un valor aleatorio. El compilador completa la memoria de pila durante la etapa de compilación del programa. El espacio de pila del proceso se encuentra en la parte superior del espacio de usuario del proceso y crece hacia abajo. Cada llamada de cada función abrirá su propio espacio de pila en el espacio de pila. Los parámetros de la función, las variables locales, la dirección de retorno de la función, etc., se insertarán en la pila de funciones en el orden en que el primero esté en la parte superior de la pila. Después de que la función regrese, el espacio de la pila de la función desaparece, por lo que la dirección de la variable local devuelta en la función es ilegal.
- Montón : Montón dinámico. La memoria del montón se asigna durante la ejecución del programa y se usa para almacenar variables que se asignan dinámicamente durante la operación del proceso. El tamaño no es fijo. El montón se encuentra entre el segmento de datos no inicializados y la pila, y se usa durante el uso. cerca del espacio de la pila. Cuando un proceso llama a una función como malloc para asignar memoria, la memoria recién asignada no está en el marco de la pila de la función, sino que se agrega dinámicamente al montón, y el montón se expande a una dirección alta en este momento; cuando se usa un función como libre para liberar la memoria, la memoria liberada se elimina del montón y el montón se reduce. Debido a que la memoria asignada dinámicamente no está en el marco de la pila de funciones, incluso si la función devuelve esta memoria, no desaparecerá.
- Segmento de datos no inicializados (.bss) : se utiliza para almacenar variables globales no inicializadas y variables estáticas estáticas. Y antes de que el programa comience a ejecutarse, es decir, antes de main(), el kernel inicializará los datos en este segmento a 0 o un puntero nulo.
- Segmento de datos inicializados (.data) : se utiliza para mantener variables globales inicializadas y variables estáticas estáticas.
- Área constante de texto (.rodata) : almacena constantes de texto, como hola en char * str = "hola";
- Segmento de texto (segmento de código) : esta es la parte de las instrucciones de la máquina en un archivo ejecutable que ejecuta la CPU. La sección de texto a menudo es de solo lectura para evitar que un programa modifique accidentalmente su propia ejecución.
PD: asignación de memoria en Linux :
La idea básica de la gestión de memoria de Linux es establecer un mapeo físico de una dirección solo cuando se accede realmente a una dirección.
Hay tres formas de asignar el lenguaje Linux C/C++:
(1) Asignado desde el área de almacenamiento estático . Es la asignación de memoria del segmento de datos.Esta memoria ha sido asignada durante la etapa de compilación del programa y existe a lo largo de la ejecución del programa, como variables globales y variables estáticas.
(2) Creado en la pila . Cuando se ejecuta una función, las unidades de almacenamiento de las variables locales en la función se pueden crear en la pila y estas unidades de almacenamiento se liberan automáticamente cuando finaliza la ejecución de la función. La operación de asignación de memoria de la pila está integrada en el conjunto de instrucciones del procesador, que es muy eficiente, pero la capacidad de memoria asignada en la pila del sistema es limitada. Por ejemplo, una matriz grande reventará el espacio de la pila y provocará una falla de segmentación.
(3) Asignación desde el montón , también conocida como asignación de memoria dinámica. Cuando el programa se está ejecutando, use malloc o new para solicitar cualquier cantidad de memoria, y el programador es responsable de cuándo usar free o delete para liberar la memoria. La vida útil de la memoria dinámica la determinamos nosotros. Es muy flexible de usar, pero también tiene la mayoría de los problemas. Por ejemplo, si el valor del puntero que apunta a un determinado bloque de memoria cambia y no hay otro puntero que apunte a este memoria, no se puede acceder a esta memoria y se produce una fuga de memoria.
3. Características del proceso
1. Características estructurales
Por lo general, los procesos no se pueden ejecutar simultáneamente. Para que el programa se ejecute de forma independiente, se debe configurar un bloque de control de proceso (PCB). La entidad del proceso se compone del segmento del programa, el segmento de datos y el PCB. Por lo general, nos referimos a el proceso como entidad de proceso. , crear un proceso es crear un PCB en la entidad de proceso.
2. Dinámica
La esencia de un proceso es un proceso de ejecución de la entidad del proceso, por lo tanto, la dinámica es la característica más básica de un proceso, que se manifiesta específicamente en: "generado por creación, ejecutado por programación y destruido por cancelación".
3. La concurrencia
se refiere al hecho de que múltiples entidades de proceso coexisten en la memoria y pueden ejecutarse simultáneamente durante un período de tiempo. La concurrencia es una característica importante del proceso y una característica importante del sistema operativo. El propósito de presentar el proceso es por concurrencia.
4. Independencia
Una entidad de proceso es una unidad básica que se ejecuta de forma independiente, asigna recursos de forma independiente y acepta la programación de forma independiente.
5. Asincronía
Las entidades de proceso se ejecutan de forma asíncrona
4. El estado básico del proceso
Hay cinco estados básicos de un proceso, a saber , estado de creación, estado listo, estado de ejecución, estado bloqueado y estado terminado .
Los comunes son listo, ejecutar y bloquear.
- Creación : cuando se crea un proceso, debe solicitar un PCB en blanco, completar la información para controlar y administrar el proceso y completar la asignación de recursos.
- Listo : el proceso está listo, se le han asignado los recursos necesarios y puede ejecutarse inmediatamente siempre que se asigne la CPU.
- Ejecución : después de que el proceso está programado en el estado listo, el proceso ingresa al estado de ejecución.
- Bloqueo : el proceso de ejecución no puede ejecutarse temporalmente debido a algún evento, el proceso está bloqueado.
- Terminación : el proceso finaliza, o se produce un error, o el sistema lo finaliza, ingresa al estado terminado y ya no se puede ejecutar.

El estado del proceso significa que el ciclo de vida de un proceso se puede dividir en un grupo de estados, que describen todo el proceso, y el estado del proceso refleja el estado de vida de un proceso.
5. Terminación del proceso
Hay 6 formas de finalizar un proceso en Linux:
1. Retorno normal:
(1) Regreso de la función principal;
(2) Funciones de salida de llamada, _salida, _Salida;
(3) El último subproceso regresa del proceso de inicio o llama a la función pthread_exit;
2. Retorno anormal:
(1) Llame a la función de aborto;
(2) recibir una señal;
(3) El último hilo responde a la solicitud de cancelación.
Independientemente de cómo termine el proceso, el kernel cierra todos los descriptores de archivos abiertos, liberando los recursos que estaban usando.
6. Ver el proceso actual del sistema
En Linux, ingrese ps aux en la terminal para ver la información del proceso del nodo de tiempo actual.
Además, utilice comandos como ps aux | grep xiao para encontrar el proceso utilizado por el usuario xiao.
ps le \ps ef (l significa mostrar información detallada, e significa mostrar todos los procesos).

- USUARIO: El proceso fue generado por ese usuario
- PID: número de identificación del proceso
- %CPU: el porcentaje de uso de recursos de CPU del proceso
- %MEM: el porcentaje de recursos de memoria ocupados por el proceso
- VSZ: El tamaño de la memoria virtual del proceso, en KB (convierte parte del espacio del disco en memoria virtual, que se utilizará después de que la memoria física esté llena)
- RSS: el tamaño de la memoria física real ocupada por el proceso, en KB
- TTY: en qué terminal se está ejecutando el proceso (TTY1~TTY6 representa el terminal de la consola local. TTY1 es un terminal de gráficos, TTY2~6 son terminales de interfaz de caracteres locales. PTS/0-255 representa un terminal virtual).
- STAT: Estado del proceso. R: en ejecución, S: suspensión, T: parada, s: contiene procesos secundarios, +: en segundo plano
- INICIO: La hora de inicio del proceso
- TIME: El proceso ocupa el sistema para obtener el tiempo de cómputo (nótese que no es el tiempo del sistema)
- COMANDO: El nombre del comando que generó este proceso
Además, ingrese arriba para ingresar al modo de monitoreo . Después de ingresar al modo de monitoreo, puede ingresar el siguiente comando para operar:
- h: mostrar ayuda;
- P: Ordenar por CPU;
- M: Ordenar por memoria;
- N: Ordenar por PID;
- q: puede salir;
Este comando puede mostrar dinámicamente los cambios de información del proceso.
7. Algunos puntos de conocimiento importantes relacionados con el proceso
1. proceso de inicio
El kernel de Linux creará un proceso de inicio para ejecutar el programa /sbin/init en la etapa final de inicio . Este proceso es el primer proceso que ejecuta el sistema . El número de proceso es 1. Se denomina proceso de inicialización del sistema Linux. Este proceso creará otros subprocesos para iniciar diferentes servicios del sistema de escritura, y cada servicio puede crear diferentes subprocesos para ejecutar diferentes programas. Por lo tanto, el proceso init es el "ancestro" de todos los demás procesos, y el kernel de Linux lo crea para ejecutarse con privilegios de root y no se puede eliminar . Linux mantiene una estructura de datos llamada tabla de procesos, que almacena información sobre todos los procesos actualmente cargados en la memoria, incluido el PID (ID del proceso), el estado del proceso, la cadena de comandos, etc. Se administran y estos PID son índices en el proceso. mesa.
2. Qué hereda el proceso hijo del proceso padre
Los procesos secundarios obtienen una copia de los recursos del proceso principal , no ellos mismos.
(1) El proceso hijo hereda del proceso padre a:
- Elegibilidad del proceso (identificadores de usuario (UID) reales/efectivos/guardados e ID de arrendamiento (GID))
- variables de entorno
- la pila
- Memoria
- El descriptor del archivo abierto (tenga en cuenta que la ubicación del archivo correspondiente se comparte entre los procesos principal y secundario, lo que puede causar ambigüedad)
- Indicador de cierre en ejecución durante la ejecución Para obtener detalles, consulte "APUE" WR Stevens, 1993, traducido por You Jinyuan y otros (en lo sucesivo, "Programación avanzada"). Secciones 3.13 y 8.9)
- Ajustes de control de señal (señal)
- valor agradable (el valor agradable lo establece la función agradable, el valor indica la prioridad del proceso, cuanto menor sea el valor, mayor será la prioridad)
- Clase de programación de procesos (clase de programador) (Nota del traductor: la clase de programación de procesos se refiere a la clase a la que pertenece un proceso cuando está programado en el sistema. Las diferentes clases tienen diferentes prioridades. De acuerdo con la clase de programación de procesos y el valor agradable, el programador de procesos puede calcular cada La prioridad global del proceso (prioridad global del proceso), el proceso con mayor prioridad se ejecuta primero)
- número de grupo de proceso
- ID de sesión (Session ID) (Nota del traductor: La traducción está tomada de "Programación avanzada", se refiere a: la ID de sesión (session) ID a la que pertenece el proceso. Una sesión incluye uno o más grupos de procesos. Para más detalles, consulte "APUE" Sección 9.5)
- directorio de trabajo actual
- Directorio raíz (el directorio raíz no es necesariamente "/", se puede cambiar mediante la función chroot)
- Máscara de creación de modo de archivo (umask)
- limitaciones de recursos
- terminal de control
(2) Exclusivo para procesos secundarios
- número de proceso
- Id. de proceso principal diferente
- Copia del propio descriptor de archivo y flujo de directorio
- El proceso secundario no hereda el proceso, el texto, los datos y otros bloqueos de memoria del padre (Nota del traductor: Memoria bloqueada se refiere a páginas de memoria virtual bloqueadas. (página fuera), consulte "Manual de referencia de la biblioteca GNU C" versión 2.2, 1999, sección 3.4.2 para más detalles)
- El tiempo del sistema en la estructura tms (Nota del traductor: La estructura tms se puede obtener mediante la función times, que guarda cuatro datos para registrar el tiempo que el proceso usa la unidad central de procesamiento (CPU; Unidad central de procesamiento), que incluye: tiempo de usuario, tiempo del sistema, el tiempo total de cada subproceso del usuario, el tiempo total de cada subproceso del sistema)
- Utilización de recursos (utilizaciones de recursos) establecida en 0
- El conjunto de señales de bloqueo se inicializa a un conjunto vacío.
- No hereda los temporizadores creados por la función timer_create
- No hereda entrada y salida asíncrona
- El bloqueo establecido por el proceso padre (porque si es un bloqueo exclusivo, es contradictorio si es heredado)
3. Limitaciones del sistema
Un servidor no puede proporcionar servicios a un número ilimitado de clientes. Bajo Linux, cada recurso tiene restricciones blandas y duras relacionadas. Por ejemplo, hay un límite en el número máximo de subprocesos que un solo usuario puede crear, y el número máximo de descripciones de archivos que pueden ser abiertas por el mismo proceso.También hay valores límite correspondientes, que limitan el número de clientes a los que el servidor puede proporcionar acceso simultáneo.
En Linux, puede usar las funciones getrlimit() y setrlimit() para obtener o establecer estos límites:
#include <sys/resource.h>
int getrlimit (int resource , struct rlimit * rlim ); // obtener límite
int setrlimit (int resource , const struct rlimit * rlim ); // establecer límite
(1) Descripción del recurso del parámetro:
- RLIMIT_AS //El espacio máximo de memoria virtual del proceso, en bytes.
- RLIMIT_CORE //La longitud máxima del archivo de volcado del núcleo.
- RLIMIT_CPU //El tiempo de uso de CPU máximo permitido en segundos. Cuando el proceso alcanza el límite suave, el kernel le enviará la señal SIGXCPU, el comportamiento predeterminado de esta señal es terminar la ejecución del proceso.
- RLIMIT DATA //El valor máximo del segmento de datos de proceso.
- RLIMIT_FSIZE //La longitud máxima del archivo que puede crear el proceso. Si el proceso intenta exceder este límite, el núcleo le enviará una señal SIGXFSZ, que terminará la ejecución del proceso por defecto.
- RLIMIT_LOCKS //El valor máximo de bloqueos y concesiones que puede establecer un proceso.
- RLIMIT_MEMLOCK //La cantidad máxima de datos que un proceso puede bloquear en la memoria, en bytes. RLIMIT_MSGQUEUE //El número máximo de bytes que un proceso puede asignar a una cola de mensajes POSIX
- RLIMIT_NICE //El proceso puede establecer el valor perfecto máximo mediante setpriority) o nice (call.
- RLIMIT_NOFILE //Especifique un valor que sea uno más grande que el descriptor de archivo máximo que puede abrir el proceso.Si se excede este valor, se generará un error de EMFILE.
- RLIMIT_NPROC //El número máximo de procesos que puede tener un usuario.
- RLIMIT_RTPRIO //La máxima prioridad en tiempo real que el proceso puede establecer a través de sched_setscheduler y sched_setparam.
- RLIMIT SIGPENDING //El número máximo de señales pendientes que puede tener un usuario.
- RLIMIT_STACK //La pila de procesos más grande, en bytes.
(2) rlim: una estructura que describe los límites blandos y duros de los recursos
struct rlimit { rlim_t rlim_cur;
rlim_t rlim_max;
};
Además de las limitaciones de hardware (CPU, memoria, ancho de banda), un programa de servidor también está limitado por los recursos del sistema Linux. Por lo tanto, si queremos aumentar el número de clientes a los que accede simultáneamente el servidor Linux, debemos modificar estos límites llamando a la función setrlimit() en el programa del servidor.
8. Algunas funciones de uso común relacionadas con el proceso
1. Hay dos llamadas básicas al sistema en Linux que se pueden usar para crear procesos secundarios: fork() y vfork().
(1) bifurcación () llamada al sistema
Dado que la llamada al sistema fork() creará un nuevo proceso, regresará dos veces en este momento. Una devolución es al proceso principal y su valor de devolución es el PID (ID del proceso) del proceso secundario, y la segunda devolución es al proceso secundario y su valor de devolución es 0.
Después de llamar a fork(), necesitamos usar su valor devuelto para determinar si el código actual se está ejecutando en el proceso principal o en el proceso secundario.
El valor devuelto es 0: proceso hijo
Valor de retorno > 0: proceso principal
Valor devuelto < 0: error de llamada al sistema fork()
Hay dos razones principales por las que falla la llamada a la función de bifurcación:
① Ya hay demasiados procesos en el sistema;
② El número total de procesos para este ID de usuario real supera el límite del sistema.
Cada proceso hijo tiene solo un proceso padre , y cada proceso puede obtener su propio PID de proceso a través de getpid(), u obtener el PID del proceso padre a través de getppid(), por lo que es deseable devolver 0 al proceso hijo cuando fork( ) . Un proceso puede crear múltiples procesos secundarios, por lo que para el proceso principal, no tiene una función de API para obtener el ID de proceso de su proceso secundario, por lo que cuando el proceso principal crea un proceso secundario a través de fork(), debe pasar el retorno valor Dígale al proceso principal el PID del proceso secundario que creó. Esta es también la razón del diseño del valor de retorno de la llamada al sistema fork() dos veces.
Aviso:
La llamada al sistema fork() crea un nuevo proceso secundario que es una copia del proceso principal. Esto también significa que después de que el sistema cree con éxito un nuevo proceso secundario, copiará el segmento de texto, el segmento de datos y la pila del proceso principal al proceso secundario, pero el proceso secundario tiene su propio espacio independiente. La modificación no afectará la memoria correspondiente en el espacio de proceso principal. En este momento, dos procesos básicamente idénticos (procesos padre e hijo) aparecen en el sistema. No hay un orden fijo para la ejecución de estos dos procesos. El proceso que se ejecuta primero depende de la política de programación de procesos del sistema. Si es necesario asegurarse de que el proceso principal o el proceso secundario se ejecuten primero, el programador debe implementarlo él mismo a través del mecanismo de comunicación entre procesos en el código.
(2) La llamada al sistema vfork()
vfork) es otra función que se puede usar para crear un proceso. Tiene el mismo uso que fork() y también se usa para crear un nuevo proceso.
vfork() no copia completamente el espacio de direcciones del proceso principal al proceso secundario , porque el proceso secundario llamará a exec o exit() inmediatamente, por lo que no se hará referencia al espacio de direcciones. Sin embargo, antes de que el proceso secundario llame a exec (o exit()), se ejecutará en el espacio del proceso principal, pero si el proceso secundario intenta modificar el dominio de datos (segmento de datos, montón, pila), generará datos desconocidos. resultados, porque los datos que afectan el espacio del proceso principal pueden causar una ejecución anormal del proceso principal.
vfork() se asegurará de que el proceso secundario se ejecute primero, y el proceso principal puede programarse para ejecutarse después de llamar a exec o exit() . Si el proceso hijo depende de otras acciones del proceso padre, se producirá un interbloqueo.
Se utiliza la tecnología Copy on Write (CopyOnWrite) : estas áreas de datos son compartidas por los procesos principal y secundario, y el kernel cambia sus derechos de acceso a solo lectura. Si alguno de los procesos principal y secundario intenta modificar estas áreas, el núcleo entonces modificará el área, haga una copia de ese bloque de memoria .