Una colección de todos los documentos sobre C++ en pytorch
Bienvenido a Tutoriales de PyTorch — documentación de Tutoriales de PyTorch 2.0.0+cu117
1. Condiciones previas
Use el editor clion, instale cudatoolkit, cudnn, el entorno pytorch, la herramienta de compilación gcc, etc.
Recuerde configurar las variables de entorno y la biblioteca de enlaces dinámicos de cudatoolkit, de modo que se puedan encontrar cudatoolkit y cudnn en ese momento.
Se puede ver el tutorial de instalación.
https://mp.csdn.net/mp_blog/creation/editor/new/129111146
Tenga en cuenta que si queremos usar la versión en lenguaje C de pytorch, no necesitamos instalar libpytorch adicional, porque pytorch los integrará automáticamente al descargar.
tutorial oficial
proyectos CUDA | Documentación de CLion
Instalación de distribuciones C++ de PyTorch — Documentación maestra de PyTorch
2. Cree un proyecto ejecutable cuda a través de clion
参照Instalación de distribuciones C++ de PyTorch — Documentación maestra de PyTorch
estos dos archivos
![]()
Y no necesitamos CMakeLists.txt, usamos setup.py en lugar de CMakeLists.txt
configuración.py
Consulte la documentación oficial.
2. Escribir el script de instalación — Documentación de Python 3.6.15
Y el tutorial setup.py de pytorch, escrito con gran detalle
Extensiones personalizadas de C++ y CUDA — Documentación de PyTorch Tutorials 2.0.0+cu117
estructura del proyecto de archivos
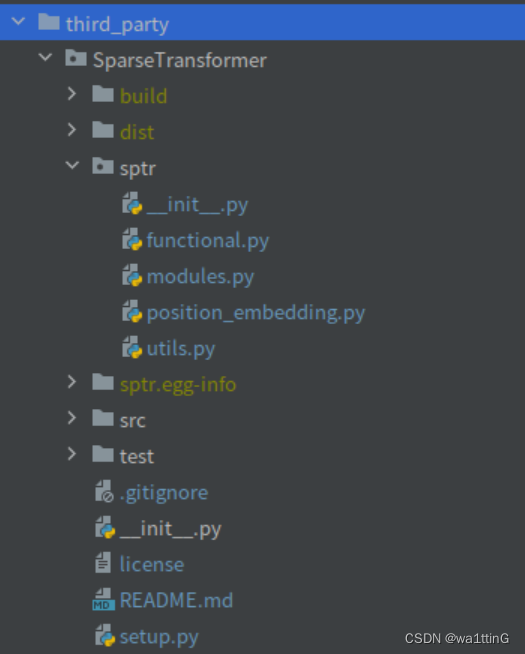
Plantilla de código de configuración para setup.py
#python3 setup.py install
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
import os
from distutils.sysconfig import get_config_vars
(opt,) = get_config_vars('OPT')
os.environ['OPT'] = " ".join(
flag for flag in opt.split() if flag != '-Wstrict-prototypes'
)
setup(
name='sptr',
ext_modules=[
CUDAExtension('sptr_cuda', [
'src/sptr/pointops_api.cpp',
'src/sptr/attention/attention_cuda.cpp',
'src/sptr/attention/attention_cuda_kernel.cu',
'src/sptr/precompute/precompute.cpp',
'src/sptr/precompute/precompute_cuda_kernel.cu',
'src/sptr/rpe/relative_pos_encoding_cuda.cpp',
'src/sptr/rpe/relative_pos_encoding_cuda_kernel.cu',
],
extra_compile_args={'cxx': ['-g'], 'nvcc': ['-O2', '-g', '-G']}
)
],
cmdclass={'build_ext': BuildExtension}
)
- la configuración es un paquete, qué paquete instalar es el nombre de la biblioteca de vínculos dinámicos que queremos generar
- name='spr' es el nombre del paquete, ejecutar python3 setup.py install instalará un paquete llamado sptr
- ext_modules indica el módulo que quiero generar, el módulo es el que puede ser llamado por el código python, ¡no por el paquete! , por ejemplo yo escribo
- import sptr no puede encontrar el módulo, ¡porque no es un módulo en absoluto! , llamar a import sptr_cuda será válido.
- CUDAExtension es un módulo de extensión. Por ejemplo, tengo el módulo sptr_cuda. Escribí qué archivos cpp están vinculados a él. Con pointops_api.cpp (es decir, la primera línea), la interfaz cpp especificada puede exponerse a sptr_cuda Se puede llamar al módulo, haciendo código python.
- extra_compile_args es un parámetro de compilación adicional pasado a gcc, por ejemplo, puede pasar un -std=c++11
Aquí, el compilador del lenguaje c usa cxx, lo que significa que gcc no sabe por qué se llama cxx, nvcc es el compilador del código cu y también puede compilar el lenguaje c++.
'nvcc': ['-O2', '-g', '-G'] -O2 parámetro que significa O2 Esta opción de optimización sacrificará parte de la velocidad de compilación, además de realizar todas las optimizaciones realizadas por -O1, también use casi Todas las configuraciones de destino admiten algoritmos de optimización para mejorar la velocidad de ejecución del código de destino.
-g,-G
NVCC, el controlador del compilador NVIDIA CUDA, proporciona un mecanismo para generar la información de depuración necesaria para que CUDA-GDB funcione correctamente. El
-g -Gpar de opciones debe pasarse a NVCC cuando se compila una aplicación para facilitar la depuración con CUDA-GDB; Por ejemplo,Eso es para generar información de depuración. Solo cuando nvcc agrega estas dos opciones, se puede vincular para generar un archivo ejecutable que se puede depurar con cuda-gdb.

gcc -g es solo un compilador. Al compilar, genera información de depuración. En términos generales, gdb puede depurar el archivo ejecutable generado más tarde. Si no se agrega -g, gdb no puede depurar.
¿Cuál es el principio de optimización -O1 -O2 -O3 en GCC? - saber casi
- cmdclass pasado en la clase BuildExtension,
-
torch.utils.cpp_extension.BuildExtension(dist,** kw)
En pocas palabras, proporciona parámetros, solo los escribimos directamente
Extensiones de compilación personalizadas
setuptools.
setuptools.build_extLas subclases son responsables de pasar los argumentos de compilación mínimos requeridos (por ejemplo-std=c++11), así comoC ++/CUDAla compilación mixta (yCUDAsoporte para archivos en general).Cuando se usa
BuildExtension, proporcionará unextra_compile_argsdiccionario para (no una lista simple) para proporcionar al compilador a través del mapeo de idioma (cxxo ) a la lista de argumentos. Esto permite dar diferentes parámetros al compiladorcudadurante la compilación híbrida .C ++CUDA
(opt,) = get_config_vars('OPT')
os.environ['OPT'] = " ".join(
flag for flag in opt.split() if flag != '-Wstrict-prototypes'
) #设置环境变量opt
Propósito: crear una variable de entorno opt, que contiene los parámetros predeterminados que se pasan al ejecutar setup.py
Wstrict-prototypes: determina si se debe advertir sobre funciones declaradas o definidas sin especificar tipos de parámetros
La opción original era la cadena '-DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes'
Como resultado, os.environ['OPT'] es '-DNDEBUG -g -fwrapv -O3 -Wall', que elimina -Wstrict-prototypes, y los demás son iguales a get_config_vars('OPT'), pero este tipo de advertencia no se emite.
Ejecutar la instalación
python3 setup.py instalar
Puede ver que nuestro sptr instalado está en la misma ubicación que otros paquetes

El paquete es una carpeta llamada sptr-0.0.0-py3.7-linux-x86_64.egg

Después de abrir, podemos ver el módulo que exportamos. Lo que importamos es sptr_cuda.py, y luego apunta a la biblioteca de enlaces dinámicos sptr_cuda.cpython-37m-x86_64-linux-gnu.so, que es nuestra biblioteca de enlaces dinámicos compilada ( es decir, para encontrar dinámicamente el contenido compilado correspondiente a la implementación del archivo de encabezado en tiempo de ejecución ), y el archivo pycache es el archivo pyc correspondiente de sptr_cuda.py.

La carpeta EGG-INFO almacena información relacionada con el paquete, por ejemplo, la carpeta fuente registra el nombre del código fuente
README.md
setup.py
sptr.egg-info/PKG-INFO
sptr.egg-info/SOURCES.txt
sptr.egg-info/dependency_links.txt
sptr.egg-info/top_level.txt
src/sptr/pointops_api.cpp
src/sptr/attention/attention_cuda.cpp
src/sptr/attention/attention_cuda_kernel.cu
src/sptr/precompute/precompute.cpp
src/sptr/precompute/precompute_cuda_kernel.cu
src/sptr/rpe/relative_pos_encoding_cuda.cpp
src/sptr/rpe/relative_pos_encoding_cuda_kernel.cu
test/test_attention_op_step1.py
test/test_attention_op_step2.py
test/test_precompute_all.py
test/test_relative_pos_encoding_op_step1.py
test/test_relative_pos_encoding_op_step1_all.py
test/test_relative_pos_encoding_op_step2.pyEn base a esto, se puede ubicar la ubicación del código fuente del proyecto (tal vez el posicionamiento del código de depuración posterior también se base en este principio)
El archivo de encabezado está en la carpeta de inclusión, el archivo so está en ld_library_path, y luego se expone la interfaz (usando PYBIND11_MODULE), y finalmente se exporta el módulo. En este momento, python puede llamar a la interfaz del módulo, por lo que el por lo tanto, el archivo también es una función o clase de lenguaje c empaquetada. Los pasos para que python llame a la interfaz de c++ son los siguientes: python importa el módulo, que se encuentra en los paquetes del sitio, como sptr_cuda.py, sptr_cuda.py proxies muchas funciones de c++, y estas implementaciones están en sptr_cuda.cpython-37m -x86_64 -En linux-gnu.so, cuando python llama a una función, busca la implementación aquí.Después de que el archivo so completa el cálculo, regresa a la interfaz y el programa python obtiene el valor de retorno.
pointops_api.cpp
La interfaz cpp especificada se puede exponer al módulo sptr_cuda, de modo que se pueda llamar al código python.
uso específico de pybind11
referencia
Aprenda uno de pybind11 conmigo - Tencent Cloud Developer Community - Tencent Cloud
enlazar funciones simples
Comencemos a crear los enlaces de python con una función extremadamente simple que suma dos números y devuelve el resultado.
int add(int i, int j)
{
return i + j;
}Para simplificar, ponemos la función y el código de enlace example.cppen este archivo.
#include <pybind11/pybind11.h>
namespace py = pybind11;
int add(int i, int j)
{
return i + j;
}
PYBIND11_MODULE(example, m)
{
m.doc() = "pybind11 example plugin"; // 可选的模块说明
m.def("add", &add, "A function which adds two numbers");
}PYBIND11_MODULE()Una función de macro creará una función que se llamará cuando Python emita una declaración (es decir, se genere un módulo). importEl nombre del módulo "ejemplo" se especifica mediante el primer parámetro de la macro (no deben aparecer comillas), por ejemplo, el siguiente código se pasa a sptr . El segundo parámetro "m" define una py::modulevariable, que en realidad es el módulo que llamamos, que se pasa al módulo de python.
m.doc: define la documentación del módulo para este módulo
m.def: define los parámetros de mapeo del módulo, la función py::module::def()genera código vinculante y add()expone la función a Python.
El primer parámetro "agregar" significa que llamaré a la función a través del nombre del módulo. Agregar en python en el futuro
El segundo parámetro &add es para completar el valor de la dirección de la función add para determinar la función enlazada.
El tercer parámetro : es el documento de descripción de la función.
Nota: ¡Solo se necesita una pequeña cantidad de código para completar el enlace de C++ a Python, y todos los detalles sobre los parámetros de la función y los valores devueltos se deducirán automáticamente mediante la metaprogramación de la plantilla! El enfoque general y la sintaxis se toman prestados Boost.Python, pero la implementación subyacente es completamente diferente. ( Es decir, simplemente escriba este archivo para completar el mapeo automático, y no tenemos que preocuparnos por otros detalles )
Ejemplo de uso en nuestro proyecto
#include <torch/serialize/tensor.h>
#include <torch/extension.h>
#include "attention/attention_cuda_kernel.h"
#include "rpe/relative_pos_encoding_cuda_kernel.h"
#include "precompute/precompute_cuda_kernel.h"
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("attention_step1_forward_cuda", &attention_step1_forward_cuda, "attention_step1_forward_cuda");
m.def("attention_step1_backward_cuda", &attention_step1_backward_cuda, "attention_step1_backward_cuda");
m.def("attention_step2_forward_cuda", &attention_step2_forward_cuda, "attention_step2_forward_cuda");
m.def("attention_step2_backward_cuda", &attention_step2_backward_cuda, "attention_step2_backward_cuda");
m.def("precompute_all_cuda", &precompute_all_cuda, "precompute_all_cuda");
m.def("dot_prod_with_idx_forward_cuda", &dot_prod_with_idx_forward_cuda, "dot_prod_with_idx_forward_cuda");
m.def("dot_prod_with_idx_backward_cuda", &dot_prod_with_idx_backward_cuda, "dot_prod_with_idx_backward_cuda");
m.def("attention_step2_with_rel_pos_value_forward_cuda", &attention_step2_with_rel_pos_value_forward_cuda, "attention_step2_with_rel_pos_value_forward_cuda");
m.def("attention_step2_with_rel_pos_value_backward_cuda", &attention_step2_with_rel_pos_value_backward_cuda, "attention_step2_with_rel_pos_value_backward_cuda");
m.def("dot_prod_with_idx_all_forward_cuda", &dot_prod_with_idx_all_forward_cuda, "dot_prod_with_idx_all_forward_cuda");
}
Tenga en cuenta que el archivo de encabezado #include <torch/extension.h> es muy versátil (el código fuente se encuentra a continuación), incluye all.h, python.h y puede importar muchos archivos de encabezado, incluida la función PYBIND11_MODULE, por supuesto. #include <torch/serialize/tensor.h> Creo que no se puede escribir.
CMakeLists.txt (no necesita ver esto, solo use setup.py para compilar, y no sabe cómo exportar módulos de python con esto)
find_package(PythonInterp REQUIRED)
cmake_minimum_required(VERSION 3.10)
project(untitled LANGUAGES CUDA CXX)
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(untitled main.cu test1.cu pointops_api.cpp)
set(CMAKE_CUDA_STANDARD 17)
set_target_properties(untitled PROPERTIES
CUDA_SEPARABLE_COMPILATION ON)
include_directories(SYSTEM ${TORCH_INCLUDE_DIRS})
target_link_libraries(untitled CUDA "${TORCH_LIBRARIES}")find_package(PythonInterp REQUERIDO)
Agregue el compilador de python; de lo contrario, cmake configuration libtorch informará Error al calcular shorthash para libnvrtc.so
cmake_minimum_required(VERSIÓN 3.10)
La versión mínima de cmake requerida para ser utilizada, cmake inferior a esta versión no puede compilar el proyecto, puede configurarlo usted mismo
proyecto(sin título IDIOMAS CUDA CXX)
untitled es el nombre del proyecto, LANGUAGES CUDA CXX es muy importante, es decir, el código cu en nuestro código, y cpp, cc y otros códigos se pueden compilar normalmente, es decir, la compilación del código CUDA y el código cxx está habilitada en al mismo tiempo.
Si no se agrega CXX, se informará un error
cmake-build-debug Extensión desconocida ".cc" para el archivo
Porque, por ejemplo, se puede compilar cpp file cuda compiler nvcc, pero el archivo .cc es el archivo de código fuente de c ++ y no puede compilarlo. En este momento, se debe habilitar la compilación c ++, es decir, se agrega CXX .
find_package(Antorcha REQUERIDA)
Busque el archivo C++ de pytorch e importe pytorch.
Aquí está el archivo de configuración de pytorch que se encontrará primero, llamado TorchConfig.cmake o torch-config.cmake, este es el archivo de configuración de pytorch sobre cmake, como dónde encontrar archivos de encabezado de pytorch, bibliotecas dinámicas, etc., de lo contrario al compilar No se puede encontrar el archivo de encabezado correspondiente.
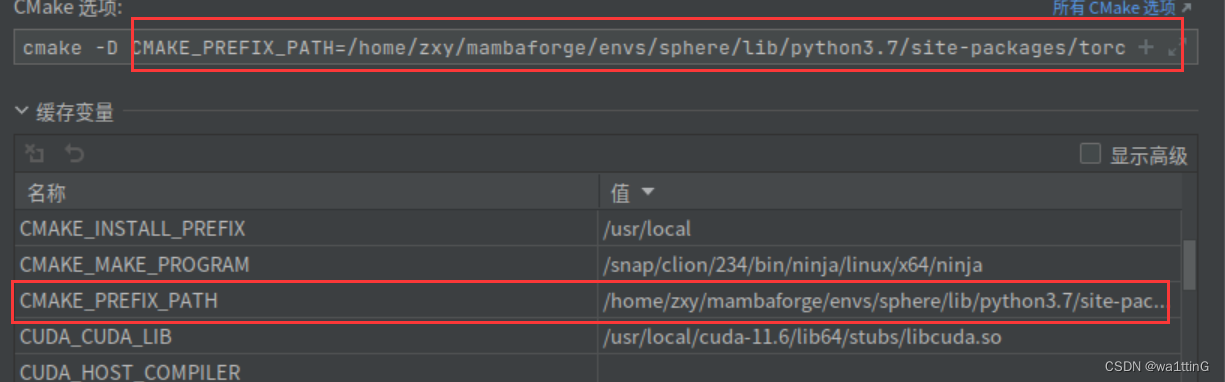
Para encontrar TorchConfig.cmake, debemos configurar una variable de caché CMAKE_PREFIX_PATH para que pueda encontrar la ubicación de TorchConfig.cmake de pytorch.
CMAKE_PREFIX_PATH=/home/zxy/mambaforge/envs/sphere/lib/python3.7/site-packages/torch/share/cmakeLa ruta se puede consultar mediante torch.utils.cmake_prefix_path
Función CMAKE_PREFIX_PATH:
Rutas a usar para búsquedas FIND_XXX(), con los sufijos apropiados.
Especifica una ruta que usarán los comandos FIND_XXX(). Contiene el directorio "base" y los comandos FIND_XXX() agregan los subdirectorios apropiados al directorio base. Por lo tanto, FIND_PROGRAM() agrega /bin a cada directorio en la ruta, FIND_LIBRARY() agrega /lib a cada directorio y FIND_PATH() y FIND_FILE() agregan /include a cada directorio. Por defecto está vacío y su propósito lo establece el proyecto. Consulte CMAKE_SYSTEM_PREFIX_PATH, CMAKE_INCLUDE_PATH, CMAKE_LIBRARY_PATH, CMAKE_PROGRAM_PATH.
FIND_PROGRAM se convierte en torch.utils.cmake_prefix_path/bin
FIND_PATH se convierte en torch.utils.cmake_prefix_path/include
Encuentre el paquete torch y cámbielo a torch.utils.cmake_prefix_path/torch Esto es exactamente lo que necesitamos, y podemos encontrar la antorcha correctamente en este momento
cmake finalmente se escribe de la siguiente manera para agregar variables de caché
cmake -D CMAKE_PREFIX_PATH=/home/zxy/mambaforge/envs/sphere/lib/python3.7/site-packages/torch/share/cmakeNota: si descargó libpytorch (es decir, una biblioteca pytorch c++ independiente, no importe su carpeta cmake, de lo contrario, informará
Libtorch C++ compilación 'NO se pudo encontrar Torch (falta: TORCH_LIBRARY)'
)
add_executable (sin título main.cu test1.cu pointops_api.cpp)
Todo el código que se va a compilar se declara aquí.
include_directories(SISTEMA ${TORCH_INCLUDE_DIRS})
target_link_libraries(sin título CUDA "${TORCH_LIBRARIES}")
Agregue el archivo de encabezado de pytorch a la ruta de búsqueda del archivo de encabezado y agregue el archivo de biblioteca de pytorch a la ruta de búsqueda de enlaces
cmake variable de caché
La variable de caché cmake (Cache Variablel) es equivalente a una variable global. Se puede usar en cualquier parte del mismo proyecto de CMake.
¿Cómo especificar la variable de caché?
- Método 1 Agregue -D al llamar a cmake, este último es la variable de caché
cmake -DCMAKE_PREFIX_PATH=/your/path
cmake -D CMAKE_PREFIX_PATH=/your/pathAmbos están bien
- El método 2 está modificado en clion. Estas dos posiciones están sincronizadas. Solo modifica una de las casillas. De hecho, es el mismo método que el Método 1.
- Método 3 usando el comando set
set(<variable> <value>... CACHE <type> <docstring> [FORCE]) |
- variable: nombre de la variable
- valor: lista de valores de variables
- CACHE: la bandera de la variable de caché
- tipo: tipo de variable, depende del valor de la variable. Los tipos se dividen en: BOOL, FILEPATH, PATH, STRING, INTERNAL
- docstring: debe ser una cadena, como una descripción resumida de la variable
- FORCE: Opción obligatoria, obliga a modificar el valor de la variable
-
estructura del código
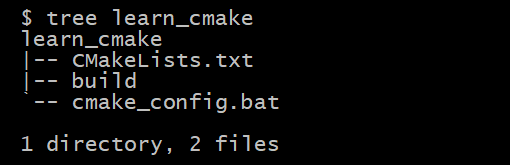
- learn_cmake: para el directorio raíz
- build: configura el directorio de salida para CMake (en este caso donde se genera la solución sln)
- cmake_config.bat: script para ejecutar el proceso de configuración de CMake (doble clic para ejecutar directamente)
- CMakeLists.txt: secuencias de comandos CMake
-
Código de ejemplo (contenido del archivo CMakeLists.txt)
cmake_minimum_required(VERSION 3.18)
# 设置工程名称
set(PROJECT_NAME KAIZEN)
# 设置工程版本号
set(PROJECT_VERSION "1.0.0.10" CACHE STRING "默认版本号")
# 工程定义
project(${PROJECT_NAME}
LANGUAGES CXX C
VERSION ${PROJECT_VERSION}
)
# 打印开始日志
message(STATUS "\n########## BEGIN_TEST_CACHE_VARIABLE")
### 定义缓存变量
# 定义一个STRIING类型缓存变量(不加FORCE选项)
set(MY_GLOBAL_VAR_STRING_NOFORCE "abcdef" CACHE STRING "定义一个STRING缓存变量")
message("MY_GLOBAL_VAR_STRING_NOFORCE: ${MY_GLOBAL_VAR_STRING_NOFORCE}")
# 定义一个STRIING类型缓存变量(加FORCE选项)
set(MY_GLOBAL_VAR_STRING "abc" CACHE STRING "定义一个STRING缓存变量" FORCE)
message("MY_GLOBAL_VAR_STRING: ${MY_GLOBAL_VAR_STRING}")- Método 4 Modificar en CMakeCache.txt. Tenga en cuenta que la prioridad de este tipo es relativamente baja, es decir, las variables definidas por la línea de comando sobrescribirán las variables del mismo nombre en CMakeCache.txt. Se puede decir que la línea de comando La definición sobrescribirá el valor de CMakeCache.txt. Ejecute cmake por primera vez. Por ejemplo, si la línea de comando pasa CMAKE_PREFIX_PATH como aaa, primero modificará CMAKE_PREFIX_PATH de CMakeCache.txt a aaa y luego leerá la memoria caché general. datos de CMakeCache.txt. La cobertura explica el valor que definí en CMakeCache.txt. Si está definido en la línea de comando, como aaa, no importa cómo lo modifiques en CMakeCache.txt, no sirve. Se cambia a bbb, ccc, y es directamente reescrito a aaa después de ejecutar cmake una vez.
Cuando CMake se ejecuta por primera vez en un árbol de compilación vacío, crea un CMakeCache.txtarchivo y lo completa con la configuración personalizable del proyecto. Esta opción se puede utilizar para especificar configuraciones que reemplazan los valores predeterminados del proyecto . CACHEEsta opción se puede repetir para tantas entradas como se desee .

Ejemplo de archivo CMakeCache.txt
//Path to a program.
CMAKE_OBJCOPY:FILEPATH=/usr/bin/objcopy
//Path to a program.
CMAKE_OBJDUMP:FILEPATH=/usr/bin/objdump
//No help, variable specified on the command line.
CMAKE_PREFIX_PATH:UNINITIALIZED=/home/zxy/mambaforge/envs/sphere/lib/python3.7/site-packages/torch/share/cmake
//Value Computed by CMake
CMAKE_PROJECT_DESCRIPTION:STATIC=
//Value Computed by CMake
CMAKE_PROJECT_HOMEPAGE_URL:STATIC=Puede ver las variables en el siguiente formulario, solo escriba en el archivo txt
message("================${CMAKE_CXX_FLAGS}===============")Apéndice: Archivos de encabezado
todo.h
#pragma once
#if !defined(_MSC_VER) && __cplusplus < 201402L
#error C++14 or later compatible compiler is required to use PyTorch.
#endif
#include <torch/cuda.h>
#include <torch/data.h>
#include <torch/enum.h>
#include <torch/fft.h>
#include <torch/jit.h>
#include <torch/linalg.h>
#include <torch/nn.h>
#include <torch/optim.h>
#include <torch/serialize.h>
#include <torch/types.h>
#include <torch/utils.h>
#include <torch/autograd.h>
#include <torch/version.h>extension.h, el archivo de encabezado universal, un archivo que contiene todo lo que se va a usar.
#pragma once
// All pure C++ headers for the C++ frontend.
#include <torch/all.h>
// Python bindings for the C++ frontend (includes Python.h).
#include <torch/python.h>
pitón.h
#pragma once
#include <torch/detail/static.h>
#include <torch/nn/module.h>
#include <torch/ordered_dict.h>
#include <torch/types.h>
#include <torch/csrc/Device.h>
#include <torch/csrc/Dtype.h>
#include <torch/csrc/DynamicTypes.h>
#include <torch/csrc/python_headers.h>
#include <torch/csrc/utils/pybind.h>
#include <iterator>
#include <string>
#include <unordered_map>
#include <utility>
#include <vector>
namespace torch {
namespace python {
namespace detail {
inline Device py_object_to_device(py::object object) {
PyObject* obj = object.ptr();
if (THPDevice_Check(obj)) {
return reinterpret_cast<THPDevice*>(obj)->device;
}
throw TypeError("Expected device");
}
inline Dtype py_object_to_dtype(py::object object) {
PyObject* obj = object.ptr();
if (THPDtype_Check(obj)) {
return reinterpret_cast<THPDtype*>(obj)->scalar_type;
}
throw TypeError("Expected dtype");
}
template <typename ModuleType>
using PyModuleClass =
py::class_<ModuleType, torch::nn::Module, std::shared_ptr<ModuleType>>;
/// Dynamically creates a subclass of `torch.nn.cpp.ModuleWrapper` that is also
/// a subclass of `torch.nn.Module`, and passes it the user-provided C++ module
/// to which it delegates all calls.
template <typename ModuleType>
void bind_cpp_module_wrapper(
py::module module,
PyModuleClass<ModuleType> cpp_class,
const char* name) {
// Grab the `torch.nn.cpp.ModuleWrapper` class, which we'll subclass
// with a dynamically created class below.
py::object cpp_module =
py::module::import("torch.nn.cpp").attr("ModuleWrapper");
// Grab the `type` class which we'll use as a metaclass to create a new class
// dynamically.
py::object type_metaclass =
py::reinterpret_borrow<py::object>((PyObject*)&PyType_Type);
// The `ModuleWrapper` constructor copies all functions to its own `__dict__`
// in its constructor, but we do need to give our dynamic class a constructor.
// Inside, we construct an instance of the original C++ module we're binding
// (the `torch::nn::Module` subclass), and then forward it to the
// `ModuleWrapper` constructor.
py::dict attributes;
// `type()` always needs a `str`, but pybind11's `str()` method always creates
// a `unicode` object.
py::object name_str = py::str(name);
// Dynamically create the subclass of `ModuleWrapper`, which is a subclass of
// `torch.nn.Module`, and will delegate all calls to the C++ module we're
// binding.
py::object wrapper_class =
type_metaclass(name_str, py::make_tuple(cpp_module), attributes);
// The constructor of the dynamic class calls `ModuleWrapper.__init__()`,
// which replaces its methods with those of the C++ module.
wrapper_class.attr("__init__") = py::cpp_function(
[cpp_module, cpp_class](
py::object self, py::args args, py::kwargs kwargs) {
cpp_module.attr("__init__")(self, cpp_class(*args, **kwargs));
},
py::is_method(wrapper_class));
// Calling `my_module.my_class` now means that `my_class` is a subclass of
// `ModuleWrapper`, and whose methods call into the C++ module we're binding.
module.attr(name) = wrapper_class;
}
} // namespace detail
/// Adds method bindings for a pybind11 `class_` that binds an `nn::Module`
/// subclass.
///
/// Say you have a pybind11 class object created with `py::class_<Net>(m,
/// "Net")`. This function will add all the necessary `.def()` calls to bind the
/// `nn::Module` base class' methods, such as `train()`, `eval()` etc. into
/// Python.
///
/// Users should prefer to use `bind_module` if possible.
template <typename ModuleType, typename... Extra>
py::class_<ModuleType, Extra...> add_module_bindings(
py::class_<ModuleType, Extra...> module) {
// clang-format off
return module
.def("train",
[](ModuleType& module, bool mode) { module.train(mode); },
py::arg("mode") = true)
.def("eval", [](ModuleType& module) { module.eval(); })
.def("clone", [](ModuleType& module) { return module.clone(); })
.def_property_readonly(
"training", [](ModuleType& module) { return module.is_training(); })
.def("zero_grad", [](ModuleType& module) { module.zero_grad(); })
.def_property_readonly( "_parameters", [](ModuleType& module) {
return module.named_parameters(/*recurse=*/false);
})
.def("parameters", [](ModuleType& module, bool recurse) {
return module.parameters(recurse);
},
py::arg("recurse") = true)
.def("named_parameters", [](ModuleType& module, bool recurse) {
return module.named_parameters(recurse);
},
py::arg("recurse") = true)
.def_property_readonly("_buffers", [](ModuleType& module) {
return module.named_buffers(/*recurse=*/false);
})
.def("buffers", [](ModuleType& module, bool recurse) {
return module.buffers(recurse); },
py::arg("recurse") = true)
.def("named_buffers", [](ModuleType& module, bool recurse) {
return module.named_buffers(recurse);
},
py::arg("recurse") = true)
.def_property_readonly(
"_modules", [](ModuleType& module) { return module.named_children(); })
.def("modules", [](ModuleType& module) { return module.modules(); })
.def("named_modules",
[](ModuleType& module, py::object /* unused */, std::string prefix) {
return module.named_modules(std::move(prefix));
},
py::arg("memo") = py::none(),
py::arg("prefix") = std::string())
.def("children", [](ModuleType& module) { return module.children(); })
.def("named_children",
[](ModuleType& module) { return module.named_children(); })
.def("to", [](ModuleType& module, py::object object, bool non_blocking) {
if (THPDevice_Check(object.ptr())) {
module.to(
reinterpret_cast<THPDevice*>(object.ptr())->device,
non_blocking);
} else {
module.to(detail::py_object_to_dtype(object), non_blocking);
}
},
py::arg("dtype_or_device"),
py::arg("non_blocking") = false)
.def("to",
[](ModuleType& module,
py::object device,
py::object dtype,
bool non_blocking) {
if (device.is_none()) {
module.to(detail::py_object_to_dtype(dtype), non_blocking);
} else if (dtype.is_none()) {
module.to(detail::py_object_to_device(device), non_blocking);
} else {
module.to(
detail::py_object_to_device(device),
detail::py_object_to_dtype(dtype),
non_blocking);
}
},
py::arg("device"),
py::arg("dtype"),
py::arg("non_blocking") = false)
.def("cuda", [](ModuleType& module) { module.to(kCUDA); })
.def("cpu", [](ModuleType& module) { module.to(kCPU); })
.def("float", [](ModuleType& module) { module.to(kFloat32); })
.def("double", [](ModuleType& module) { module.to(kFloat64); })
.def("half", [](ModuleType& module) { module.to(kFloat16); })
.def("__str__", [](ModuleType& module) { return module.name(); })
.def("__repr__", [](ModuleType& module) { return module.name(); });
// clang-format on
}
/// Creates a pybind11 class object for an `nn::Module` subclass type and adds
/// default bindings.
///
/// After adding the default bindings, the class object is returned, such that
/// you can add more bindings.
///
/// Example usage:
/// \rst
/// .. code-block:: cpp
///
/// struct Net : torch::nn::Module {
/// Net(int in, int out) { }
/// torch::Tensor forward(torch::Tensor x) { return x; }
/// };
///
/// PYBIND11_MODULE(my_module, m) {
/// torch::python::bind_module<Net>(m, "Net")
/// .def(py::init<int, int>())
/// .def("forward", &Net::forward);
/// }
/// \endrst
template <typename ModuleType, bool force_enable = false>
torch::disable_if_t<
torch::detail::has_forward<ModuleType>::value && !force_enable,
detail::PyModuleClass<ModuleType>>
bind_module(py::module module, const char* name) {
py::module cpp = module.def_submodule("cpp");
auto cpp_class =
add_module_bindings(detail::PyModuleClass<ModuleType>(cpp, name));
detail::bind_cpp_module_wrapper(module, cpp_class, name);
return cpp_class;
}
/// Creates a pybind11 class object for an `nn::Module` subclass type and adds
/// default bindings.
///
/// After adding the default bindings, the class object is returned, such that
/// you can add more bindings.
///
/// If the class has a `forward()` method, it is automatically exposed as
/// `forward()` and `__call__` in Python.
///
/// Example usage:
/// \rst
/// .. code-block:: cpp
///
/// struct Net : torch::nn::Module {
/// Net(int in, int out) { }
/// torch::Tensor forward(torch::Tensor x) { return x; }
/// };
///
/// PYBIND11_MODULE(my_module, m) {
/// torch::python::bind_module<Net>(m, "Net")
/// .def(py::init<int, int>())
/// .def("forward", &Net::forward);
/// }
/// \endrst
template <
typename ModuleType,
typename =
torch::enable_if_t<torch::detail::has_forward<ModuleType>::value>>
detail::PyModuleClass<ModuleType> bind_module(
py::module module,
const char* name) {
return bind_module<ModuleType, /*force_enable=*/true>(module, name)
.def("forward", &ModuleType::forward)
.def("__call__", &ModuleType::forward);
}
} // namespace python
} // namespace torch