
¡Hola a todos, soy Piao Miao!
Creo que durante la entrevista, normalmente te preguntarán "¿qué es un índice?" y definitivamente puedes dejar escapar: un índice es una estructura de datos que mejora la velocidad de consulta . La razón por la que el índice puede mejorar la velocidad de consulta es que ordena los datos al insertarlos.
En los negocios reales, encontraremos muchos escenarios complejos, como consultar varias columnas. En este momento, es posible que se le solicite al usuario que cree un índice compuesto por varias columnas, como el índice compuesto creado por las columnas a y b, pero si debe crear un índice de (a, b) o un índice de (b, a ) es completamente diferente, diferente.
Hoy, hablemos del índice compuesto que está más cerca del negocio real, y sintamos juntos el poder del índice compuesto. (Por supuesto, el índice mencionado en el artículo se refiere al índice del árbol B+, que es el hombre bajo y gordo)
índice compuesto
Un índice compuesto se refiere a un índice de árbol B+ compuesto por varias columnas. Es exactamente lo mismo que el índice de árbol B+, excepto que un índice de una sola columna ordena una columna y ahora ordena varias columnas.
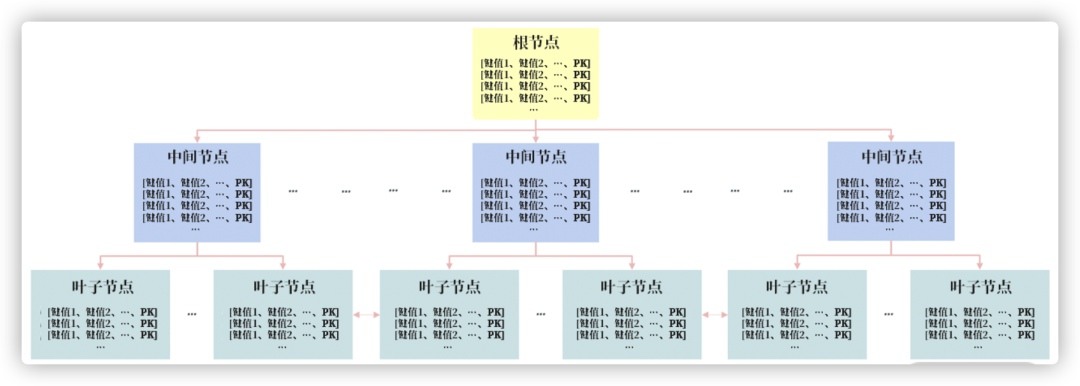
Como se puede ver en la figura anterior, el índice compuesto solo cambia el valor de la clave ordenada de uno a varios, y es esencialmente un índice de árbol B+. Pero debe tener en cuenta que los resultados de clasificación de índices compuestos como (a, b) y (b, a) son completamente diferentes.
Si existe la siguiente tabla test, se crea un índice compuesto para ella union_index.
create table test
(
id int auto_increment primary key,
name varchar(50) null,
workcode varchar(50) null,
age int null
);
create index union_index on test (name, workcode);
Para el índice combinado (nombre, código de trabajo), debido a que ordena el nombre y el código de trabajo, puede optimizar las siguientes dos consultas
select * from test where name = 'zhang' ;
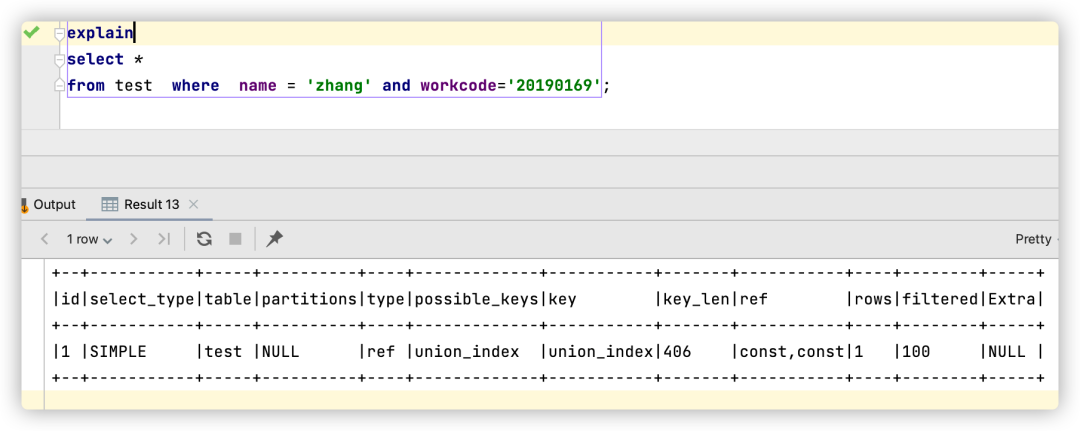
select * from test where name = 'zhang' and workcode='20190169';
Vale la pena señalar que el orden del nombre de la columna de consulta y el código de trabajo después de donde es irrelevante, incluso si está escrito, where workcode = '20190169' and name ='zhang'aún se puede usar el índice compuesto (nombre, código de trabajo).
Sin embargo, el siguiente sql no puede usar el índice compuesto (nombre, código de trabajo), porque la clasificación (nombre, código de trabajo) no se puede derivar de la clasificación (código de trabajo, nombre).
select * from test where workcode='20190169';
Además, debido a que el índice (nombre, código de trabajo) está ordenado, el siguiente SQL aún puede usar el índice compuesto (nombre, código de trabajo) para mejorar la eficiencia de las consultas:
select * from test where name = 'zhang' order by workcode;
Por la misma razón, la clasificación de índice (nombre, código de trabajo) no puede dar como resultado la clasificación de (código de trabajo, nombre), por lo que el siguiente SQL no puede usar índice compuesto (nombre, código de trabajo):
select * from test where workcode = '20190169' order by name ;
Hablando de esto, ha dominado el contenido básico del índice compuesto. A continuación, echemos un vistazo a cómo diseñar correctamente el índice compuesto en la práctica comercial.
Práctica de diseño de índices comerciales
evitar la clasificación adicional
En un escenario empresarial real, encontrará una consulta basada en una determinada columna y luego la mostrará en orden inverso en orden de tiempo.
Por ejemplo, en el negocio de Weibo, la visualización de Weibo del usuario es para consultar el Weibo suscrito por el usuario de acuerdo con la identificación del usuario y luego mostrarlo en orden inverso según el tiempo; por ejemplo, en el negocio de comercio electrónico, el usuario La página de detalles del pedido es para consultar al usuario de acuerdo con la identificación del usuario, los datos del pedido y luego mostrarlos en orden inverso de acuerdo con el tiempo de compra.
A continuación, echemos un vistazo a una tabla de oportunidades comerciales reales en nuestra línea. Los campos se han simplificado y solo se reservan algunos campos clave. Al mismo tiempo, más de 700,000 datos se inicializan directamente para la conveniencia de las pruebas.
CREATE TABLE t_opp_base
(
id int primary key auto_increment,
opp_code varchar(50) NOT NULL, -- 商机编码
opp_name varchar(200) NOT NULL,
principal_user varchar(50) NOT NULL, -- 责任人
opp_status char(1) NOT NULL,
opp_amount decimal(15, 2) NOT NULL,
opp_date date NOT NULL,
opp_priority char(15) NOT NULL,
remark varchar(79) NOT NULL,
KEY `idx_opp_code` (opp_code),
KEY `idx_principal_user` (principal_user)
);
en:
-
El campo id es una clave primaria de tipo INT;
-
Los campos opp_code, principal_user han agregado un índice de un solo campo porque hay muchos escenarios de consulta
-
Los campos opp_date, opp_status, opp_amount y opp_priority se utilizan para los detalles básicos de la oportunidad de negocio, indicando respectivamente la hora de la oportunidad de negocio, el estado de la oportunidad de negocio actual, el valor total de la oportunidad de negocio y la prioridad de la oportunidad de negocio.
Después de tener la tabla de oportunidades comerciales anterior, cuando el usuario ve la información de la oportunidad comercial de la que es responsable javadaily y necesita ordenar la consulta de acuerdo con el tiempo de la oportunidad comercial, se puede usar el siguiente SQL:
select * from t_opp_base where principal_user = 'javadaily' order by opp_date DESC
Sin embargo, debido al diseño del índice de la estructura de la tabla anterior, el índice idx_principal_usersolo ordena la columna principal_user, por lo que después de obtener los datos del usuario, se requiere una ordenación adicional para obtener el resultado. Puede verificar el plan de ejecución EXPLAIN para confirmar:
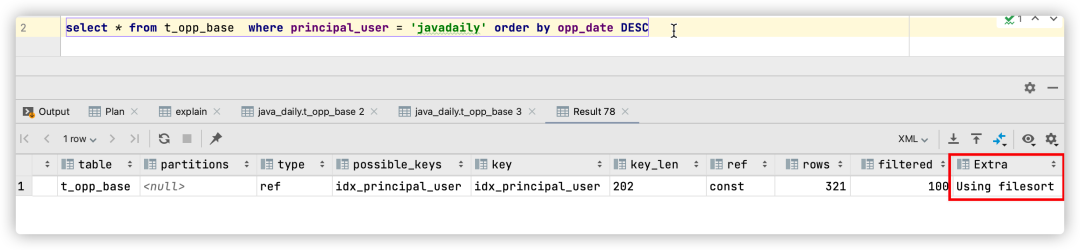
Puede verse en el plan de ejecución anterior que la instrucción SQL puede usar el índice idx_principal_user, pero el uso de clasificación de archivos que se muestra en la columna Extra indica que se requiere una clasificación adicional para obtener el resultado final.
Dado que la columna principal_user ha sido indexada, la instrucción SQL anterior no se ejecutará de manera particularmente lenta, pero en el caso de una alta concurrencia, cada ejecución de SQL debe ordenarse, lo que tendrá un impacto muy obvio en el rendimiento empresarial, como la carga de la CPU. Más alto, QPS más bajo.
Para resolver este problema, la mejor manera es: los resultados ya están opp_dateordenados , por lo que no se requiere una clasificación adicional.
Entonces, creamos un nuevo índice compuesto en la tabla t_opp_base, idx_principal_oppdatepara indexar los campos (principal_user, opp_date).
create index idx_principal_oppdate
on t_opp_base (principal_user,opp_date);
Este es el sql antes de la ejecución, de acuerdo al tiempo muestra el proyecto de oportunidad de negocio que tiene el responsable, el plan de ejecución es:
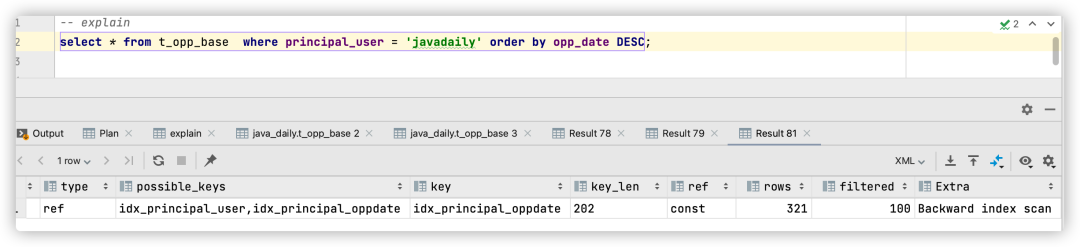
De esta forma, eliminamos Using filesorty mejoramos la eficiencia de ejecución.
Cobertura indexada para no volver a la mesa
“Concepto basico:
SQL requiere una consulta del índice secundario para obtener el valor de la clave principal y luego busca el índice de la clave principal de acuerdo con el valor de la clave principal y finalmente localiza los datos completos. Este proceso se vuelve a la tabla. Sin embargo, dado que los nodos de hoja del índice compuesto secundario incluyen valores de clave de índice y valores de clave principal, si el campo consultado está en los nodos de hoja del índice secundario, los resultados se pueden devolver directamente sin volver a la tabla. Esta técnica de optimización de evitar volver a la tabla mediante la combinación de índices también se denomina cobertura de índice (Índice de cobertura).
”
Por ejemplo, existe el siguiente SQL:
select principal_user,opp_date,opp_amount from t_opp_base where principal_user = 'javadaily' ;
Ver su plan de ejecución:
-> Index lookup on t_opp_base using idx_principal_oppdate (principal_user='javadaily') (cost=312.51 rows=321) (actual time=0.452..0.908 rows=321 loops=1)
Su plan de ejecución muestra que se utiliza el índice combinado creado anteriormente idx_principal_user, sin embargo, dado que los nodos hoja del índice combinado solo contienen el valor del(principal_user,opp_date,id) campo , es necesario encontrar el correspondiente a través de la tabla posterior de id .opp_amountopp_amount
“El plan de ejecución muestra que el costo de ejecución es de 312.51. (cost=312.51 representa el costo de ejecución actual de este SQL. No necesita preocuparse por la unidad de costo específica, solo necesita comprender que cuanto menor sea el costo, menor será la sobrecarga y mayor será la velocidad de ejecución).
”
Si desea evitar volver a la tabla, puede usar la técnica de cobertura de índice para crear (principal_user,opp_date,opp_amount)un índice compuesto, como:
alter table t_opp_base add index
idx_principal_oppdate_amount(principal_user,opp_date,opp_amount);
Vuelva a comprobar el plan de ejecución:
-> Index lookup on t_opp_base using idx_principal_oppdate_amount (principal_user='javadaily') (cost=41.52 rows=321) (actual time=0.149..0.337 rows=321 loops=1)
El costo de ejecución se ha reducido significativamente, de 312,51 a 41,52, y la eficiencia de ejecución ha mejorado considerablemente.
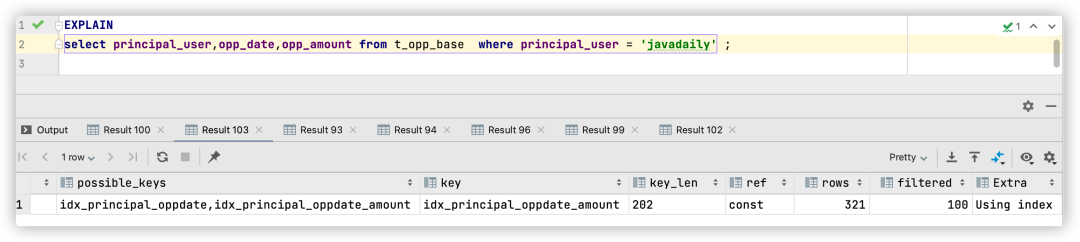
Puede ver que el plan de ejecución selecciona idx_principal_oppdate_amountel índice y la columna Extra se muestra como Using index, lo que significa que se utiliza la tecnología de índice de cobertura.
El SQL anterior devuelve un total de registros 321, lo que significa que antes de que se use la tecnología de cobertura de índice, este SQL debe volver a la tabla 321 veces en total. Cada vez que se leen datos del índice secundario, el campo opp_amount debe ser obtenido a través de la clave primaria. Después de usar la tecnología de cobertura de índice, no hay necesidad de volver a la mesa, lo que reduce el costo de volver a la mesa 321 veces, por lo que el costo de ejecución se reducirá tanto.
A continuación, veamos este SQL
select principal_user,sum(opp_amount) from t_opp_base group by principal_user;
Este SQL se agrupa y resume según el responsable de la oportunidad de negocio, averigua el valor total de la oportunidad de negocio de la que es responsable cada responsable y evalúa al responsable.
Para que todos sientan intuitivamente el poder de la cobertura del índice, primero elimino el índice creado anteriormenteidx_principal_oppdate_amount
ALTER TABLE t_opp_base
drop INDEX idx_principal_oppdate_amount;
Ver su plan de ejecución
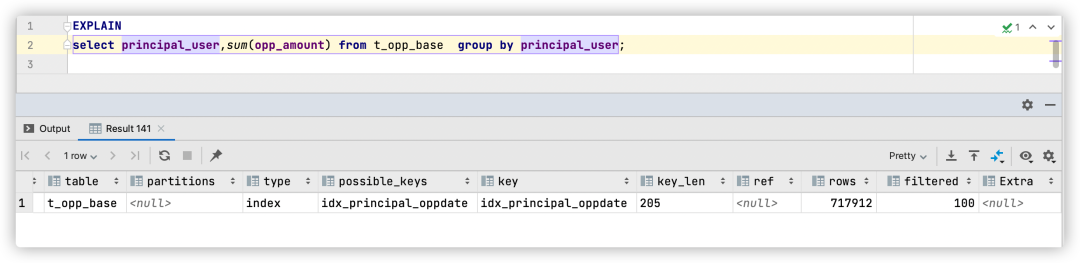
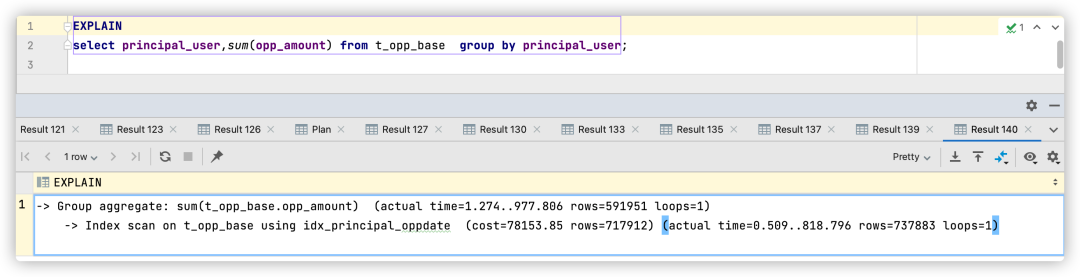
Se puede ver que esta optimización de SQL selecciona el índice idx_principal_oppdate, pero debido a que el índice no contiene el campo opp_amount, necesita volver a la tabla.De acuerdo con las estimaciones de las filas, se estima que la tabla devolverá alrededor de 717912 veces. Al mismo tiempo, también se puede ver que el costo de ejecución es de 76850,31 y el tiempo de ejecución es de 10,9 segundos.
Luego agregamos el índice compuesto nuevamenteidx_principal_oppdate_amount
alter table t_opp_base add index
idx_principal_oppdate_amount(principal_user,opp_date,opp_amount);
Verifique el plan de ejecución nuevamente
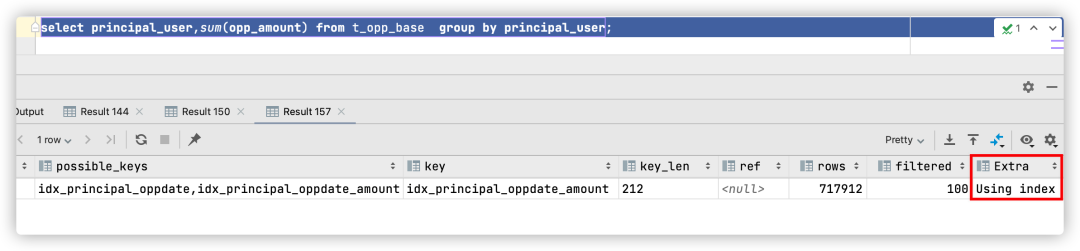
Se puede ver que esta vez la actualización del plan de ejecución usa el índice compuesto idx_principal_oppdate_amount, y Using indexel indicador de indica que se usa la tecnología de cobertura de índice. Al mismo tiempo, el tiempo de ejecución es de 1,74 s y el rendimiento de SQL mejora considerablemente.
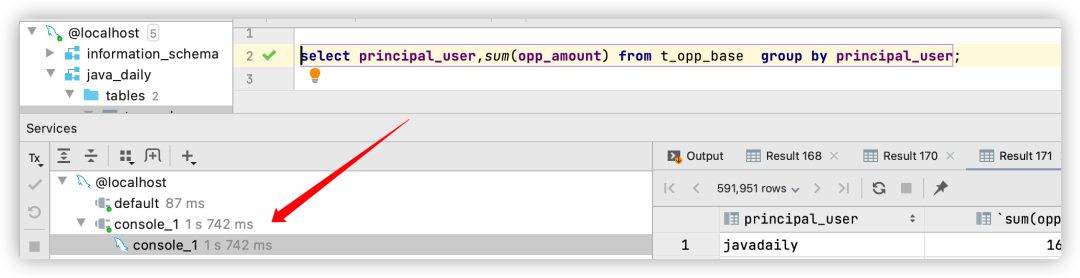
Este es el poder de la tecnología de cobertura de índices, y esto solo se basa en un total de 700 000 registros en la tabla t_opp_base. Si la cantidad de registros en la tabla t_opp_base es mayor, la cantidad de veces para regresar a la tabla será mayor y la mejora del rendimiento a través de la tecnología de cobertura de índice será más obvia.
resumen
Un índice compuesto también es un árbol B+, excepto que las columnas indexadas constan de varias columnas. El índice compuesto puede ser un índice de clave principal o un índice secundario. Los índices compuestos tienen principalmente las siguientes tres ventajas:
-
Cubre varias condiciones de consulta, como (a, b) el índice puede cubrir la consulta a = ? o a = ? y b = ?;
-
Evite la clasificación adicional de SQL para mejorar el rendimiento de SQL,
WHERE a = ? ORDER BY bcomo las condiciones de consulta; -
El uso de la función de que el índice compuesto contiene varias columnas puede implementar la tecnología de cobertura de índice y mejorar el rendimiento de las consultas de SQL. No es difícil mejorar el rendimiento 10 veces utilizando bien la tecnología de cobertura de índice.
Bueno, eso es todo por el artículo de hoy. Espero que a través de este artículo, pueda crear razonablemente índices compuestos en proyectos reales para mejorar la eficiencia de las consultas. Finalmente, soy Piao Miao Jam, un arquitecto que escribe código, un programador que hace arquitectura, y espero su atención. ¡Estamos destinados a verte de nuevo!

Si prestas atención, obtendrás videos didácticos de 10 G. ¿Qué estás esperando? ¿Por qué no te subes al autobús?
Este artículo se comparte desde la cuenta pública de WeChat - JAVA Rizhilu (javadaily).
Si hay alguna infracción, comuníquese con [email protected] para eliminarla.
Este artículo participa en el " Programa de Creación de Fuentes OSC " Le invitamos a unirse y compartirlo.