Tabla de contenido
2. Predicción de cuadro delimitador: predicción de cuadro delimitador
3. Reglas de coincidencia de muestras positivas y negativas
prefacio
YOLO v3 ("Yolov3: una mejora incremental") es un artículo de detección de objetivos de una sola etapa publicado por Joseph Redmon en 2018. Este también es el último artículo del autor sobre la serie yolo. Yolo v3 es un modelo relativamente maduro en la serie yolo, y también se usa ampliamente en la industria, por lo que es de gran importancia investigar sobre yolo v3.
En comparación con los anteriores V1 y V2, excepto por la estructura de red, el resto de v3 no ha cambiado mucho. La razón principal es que algunas buenas ideas de detección están integradas en YOLO. Con la premisa de mantener la ventaja de la velocidad, la precisión de detección es mejorado aún más, especialmente para las capacidades de detección de objetos pequeños. Específicamente, YOLOv3 mejora principalmente la estructura de la red, las características de la red y los cálculos posteriores en tres partes.
Mejoras:
- Predicción multiescala (introducción de FPN)
- Mejor red troncal (darknet-53, similar a ResNet que presenta una estructura residual)
- El clasificador ya no usa softmax (usado en darknet-19), y la función de pérdida usa pérdida de entropía cruzada binaria (entropía de pérdida cruzada de dos clases)
1. Arquitectura de red
YOLOv3 continúa basándose en las ideas del excelente marco de detección actual, como la red residual y la fusión de características, etc., y propone la estructura de red que se muestra en la figura a continuación, que se llama DarkNet-53. El autor experimentó con ImageNet y descubrió que darknet-53 no solo es similar en precisión de clasificación en comparación con ResNet-152 y ResNet101, sino que también tiene una velocidad de cálculo mucho más rápida que ResNet-152 y ResNet-101, y el número de capas de red es también menos que ellos.
La estructura del modelo YOLO v3 se muestra en la siguiente figura:

● DBL: representa la combinación de tres capas de convolución, BN y Leaky ReLU, en YOLOv3 aparece en esta combinación la convolución, que constituye la unidad básica de DarkNet. Los números después de DBL representan varios módulos DBL.
● res: res representa el módulo residual, y el número después de res indica que hay varios módulos residuales conectados en serie.
● Sobremuestreo: el método de sobremuestreo es la agrupación, es decir, el método de copia y expansión de elementos aumenta el tamaño del mapa de características y no hay ningún parámetro de aprendizaje.
● Concat: después de aumentar el muestreo, realice la operación Concat en los mapas de características profundas y superficiales, es decir, el empalme de canales, similar a FPN, pero FPN utiliza la adición elemento por elemento.
● Idea residual: DarkNet-53 se basa en la idea residual de ResNet y utiliza una gran cantidad de conexiones residuales en la red básica, por lo que la estructura de la red se puede diseñar en profundidad y se alivia el problema de la desaparición del gradiente en el entrenamiento. , facilitando la convergencia del modelo.
● Mapa de características multicapa: a través de operaciones de sobremuestreo y concatenación, las características profundas y superficiales se fusionan y finalmente se generan mapas de características de tres tamaños para la detección posterior. Los mapas de características de múltiples capas son beneficiosos para la detección de objetos pequeños y objetos de múltiples escalas.
● Sin capa de agrupación: la red YOLO anterior tiene un máximo de 5 capas de agrupación, que se utilizan para reducir el tamaño del mapa de funciones, y la tasa de reducción de resolución es 32, mientras que DarkNet-53 no utiliza la agrupación, pero utiliza un tamaño de paso de 2 Núcleo de convolución para lograr el efecto de reducción de tamaño, el número de reducción de resolución también es 5 veces, y la tasa general de reducción de resolución es 32.
Cabe señalar que la diferencia entre la operación concat y la operación de suma: la operación de suma proviene de la idea de ResNet, y el mapa de características de entrada se agrega a la posición correspondiente de la dimensión correspondiente del mapa de características de salida, es decir, y = f(x) + x; La operación concat se deriva de la idea de diseño de la red DenseNet, y el mapa de características se empalma directamente según la dimensión del canal. Por ejemplo, el mapa de características de 8*8* 16 se empalma con el mapa de características de 8*8*16 para generar el mapa de características de 8*8*32. . Capa de muestreo superior (upsample): La función es generar una imagen de gran tamaño interpolando el mapa de características de tamaño pequeño. Por ejemplo, utilice el algoritmo de interpolación del vecino más cercano para transformar una imagen de 8*8 en una imagen de 16*16. La capa de muestreo ascendente no cambia la cantidad de canales del mapa de características.
1.1 red troncal
YOLOv3 introdujo el módulo residual basado en Darknet-19 propuesto por YOLOv2 y profundizó aún más la red. La red mejorada tiene 53 capas convolucionales, denominadas Darknet-53, y la estructura de la red es la siguiente:

El autor utiliza Darknet-53 como red de extracción de características y elimina las capas Avgpool, Connected y Softmax de la red.
En toda la estructura v3, no hay una capa de agrupación y una capa totalmente conectada . En el proceso de propagación directa, la transformación del tamaño del tensor se realiza cambiando el tamaño de paso del kernel de convolución, como zancada=(2, 2), lo que equivale a reducir la longitud del lado de la imagen a la mitad (es decir, el área se reduce al 1/4 original). En yolo_v3, después de 5 reducciones, el mapa de características se reducirá a 1/32 del tamaño de entrada original. La entrada es 416x416, la salida es 13x13 (416/32=13).
2. Predicción de cuadro delimitador: predicción de cuadro delimitador
2.1 Predicción multiescala
A partir de la estructura del modelo, se puede encontrar que YOLOv3 genera 3 mapas de características de diferentes tamaños, correspondientes a las características profundas, medias y superficiales de arriba a abajo. El tamaño de la característica de la capa profunda es pequeño y el campo receptivo es grande, lo que favorece la detección de objetivos a gran escala. El mapa de características de escala media se usa para detectar objetivos de tamaño mediano, y el mapa de características de poca profundidad se usa para detectar objetivos a pequeña escala.Esto es similar a la estructura FPN.
Se preestablece un conjunto de bordes con diferentes tamaños y relaciones de aspecto en cada celda de la cuadrícula para cubrir diferentes posiciones y múltiples escalas de toda la imagen. Cada escala predice 3 cajas, y todavía se usa el método de diseño de anclaje 聚类(obtenga 9 centros de conglomerados, divídalos en 3 escalas según su tamaño y use las capas de características de estas tres escalas para predecir el marco .
2.2 Predicción del desplazamiento de la cuadrícula de anclaje
De la explicación en la parte anterior, se puede ver que cada punto Yolo Headen la salida es tridimensional w,h correspondiente a la cuadrícula dividida por la imagen original, channelcorrespondiente al anchorvalor predicho, entonces, ¿cómo calculamos anchorla posición específica?
La idea de yolo es dividir una imagen en W*Wcuadrículas, y cada cuadrícula es responsable del objetivo donde cae el punto central de la cuadrícula. Cada cuadrícula puede considerarse como un área de interés. Ya que es un área, es necesario calcular el anchorpredicho bboxdewLa suma hchannel
= tx + ty + tw + th + obj + numclasses channel =t_x+t_y+t_w+t_h+obj+num_{classes} channel=tx+ty +tw+th+obj +
numclasses El valor predicho tx,tyno son las coordenadas del ancla, sino anchorel desplazamiento del mismo tw, th t_w,t_h tw,thEs el factor de escala del cuadro anterior, y el el tamaño del cuadro anterior está determinado por el archivo de etiquetas k-meansde agrupamiento. xmlSe obtienen las posiciones de coordenadas guardadas, cada una anchortiene tres fotogramas anteriores de diferentes tamaños, y Yoloheadhay tres capas de predicción, y el número total de fotogramas anteriores es tres veces el número total de rejillas
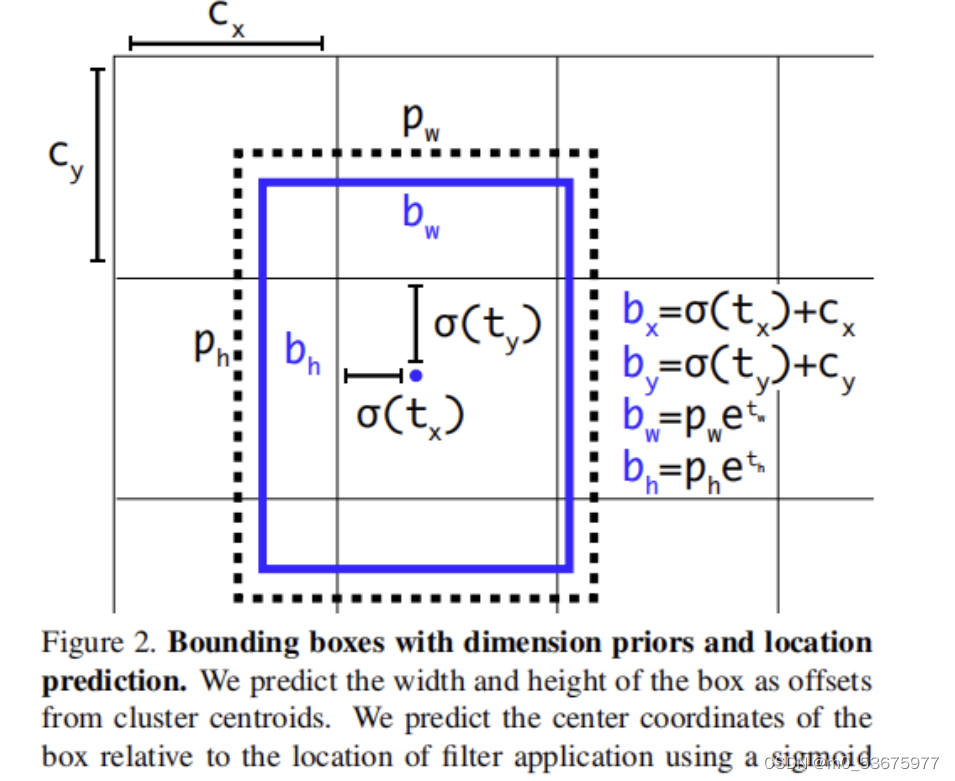
La figura anterior muestra bboxel proceso de regresión cx, cy c_x, c_y cx, cy son las coordenadas de la esquina superior izquierda de la cuadrícula, anchordesplazadas hacia la parte inferior derecha, para evitar que anchorla compensación exceda la cuadrícula y cause una pérdida excesiva de precisión de posicionamiento, se yolov3utilizará (puede acelerar la convergencia de la red), y la coordenada final pronosticada bx, por b_x, b_y bx, por.bbox está determinada por el factor de escala pronosticado tw y th t_w y t_h twy th decisión, pw y ph p_w y p_h pwy ph son el ancho y el alto de la plantilla asignada al mapa de características, y la función exponencial se usa para agrandar tw t_w tw y th t_h th en pw y ph p_w y p_h respectivamente Multiplique pwy phpara obtener la predicción final de w y h.: Los puntos de coordenadas aquí son los valores asignados al mapa de características, no el coordenadas en la imagen original, que debe convertirse a la imagen real. Las coordenadas se dibujan nuevamente.sigmoid[0,1]anchorw与hanchorPSx,yanchorplot bbox
2.3 Cabeza de Yolo
El método utilizado por YOLOv3 es diferente al de SSD. Aunque se usa la información de múltiples mapas de características, las características de SSD se predicen por separado de superficial a profunda, sin fusión profunda y superficial, y la red básica de YOLOv3 se parece más a SSD y FPN combinados. YOLOv3 usa el conjunto de datos COCO de forma predeterminada, un total de 80 categorías de objetos, por lo que un ancla necesita valores de predicción de categoría de 80 dimensiones, predicciones de 4 posiciones y una predicción de confianza. Cada celda tiene tres anclas, por lo que se requiere un total de 3 × (80 + 5) = 255, que es la cantidad de canales pronosticados para cada mapa de funciones.
Cuando la entrada es 416*416, el modelo generará 10647 cuadros de predicción (mapas de características de tres tamaños, tres cuadros de predicción para cada tamaño, un total de (13×13+26×26+52×52)×3=10647) , para cada Cada cuadro de salida se etiqueta de acuerdo con la verdad fundamental en el conjunto de entrenamiento (ejemplo positivo: el IOU con la verdad fundamental es el más grande; ejemplo negativo: IOU<umbral 0.5; ignorar: el marco con el objeto es predicho pero el El IOU no es el más grande y se rechaza en el redondeo NMS). Luego use la función de pérdida para optimizar y actualizar los parámetros de la red.
Como se muestra en la figura anterior: Durante el proceso de entrenamiento, para cada imagen de entrada, yolov3 predecirá tres tensores 3D de diferentes tamaños, correspondientes a tres escalas diferentes. El propósito de diseñar estas tres escalas es detectar objetos de diferentes tamaños. . Aquí tomamos como ejemplo el tensor 13 * 13. Para esta escala, la imagen de entrada original se dividirá en celdas de cuadrícula de 13 × 13, y cada celda de cuadrícula corresponde a un vóxel largo de 1x1x255 en el tensor 3D. 255 se deriva de 3*(4+1+80).Como se puede ver en la figura anterior, N×N en la fórmula N×N×[3×(4+1+80)] representa el tamaño de escala, tal como el mencionado anteriormente 13×13. 3 significa que cada celda de la cuadrícula predice 3 cajas. 4 representa el valor de la coordenada (tx,ty,th,tw). 1 representa el nivel de confianza y 80 representa el número de categorías COCO.
- Si el centro del cuadro delimitador correspondiente a una cierta verdad básica en el conjunto de entrenamiento cae en una determinada celda de cuadrícula de la imagen de entrada, entonces esta celda de cuadrícula es responsable de predecir el cuadro delimitador de este objeto, por lo que la confianza correspondiente a esta celda de cuadrícula es 1, la confianza de otras celdas de cuadrícula es 0. A cada celda de la cuadrícula se le darán 3 cajas previas de diferentes tamaños.Durante el proceso de aprendizaje, la celda de la cuadrícula aprenderá a elegir qué tamaño de caja anterior. El autor define la casilla anterior de mayor coincidencia con el pagaré de la verdad del suelo .
- Los tres cuadros previos preestablecidos de diferentes tamaños mencionados anteriormente, ¿cómo se calculan estos tres tamaños? Primero, antes del entrenamiento, todos los bboxes en el conjunto de datos COCO se dividen en 9 categorías utilizando el agrupamiento de k-means, y cada 3 categorías corresponde a una escala, por lo que hay 3 escalas en total Esta información previa sobre el tamaño de la caja ayuda a la red a predecir con precisión el desplazamiento y la coordenada de cada caja. Intuitivamente, un tamaño de caja apropiado hará que la red aprenda con mayor precisión.
en el proceso de previsión
Ingrese la imagen en la red de predicción entrenada, primero emita la información del marco de predicción (obj, tx, ty, th, tw, cls), después de la puntuación de confianza específica de la clase (conf_score = obj * cls) de cada marco de predicción, establezca el umbral , filtre los marcos de predicción con puntajes bajos y realice el procesamiento NMS en los marcos de predicción reservados para obtener el resultado de detección final.
- Procesamiento de umbral: elimine la mayoría de los marcos de fondo que no contienen objetos predichos
- Procesamiento NMS: elimine los cuadros delimitadores redundantes para evitar la predicción repetida del mismo objeto
El proceso de pronóstico resumido es:
Luego atraviesa las tres escalas.
→ recorrer los cuadros de predicción de cada escala
→ Utilice las puntuaciones de clasificación de cuadro de predicción más altas como la categoría de predicción del cuadro
→ Multiplique la confianza del cuadro de predicción con sus puntajes de clasificación de 80 dimensiones
→ Configure nms_thresh e iou_thresh, use nms e iou para eliminar el marco de fondo y repetir el marco
→ Recorra cada cuadro de predicción a la izquierda, visualice
3. Reglas de coincidencia de muestras positivas y negativas
La regla de emparejamiento de muestras positivas y negativas mencionada en el documento de yolov3 es: groundtrue boxasigne una muestra positiva a cada una, y esta muestra positiva es un cuadro de predicción con el área de superposición más grande bboxentre todos, es decir, la predicción con el IOU más grande del gt_box gt_boxcaja.Pero si usa esta regla para encontrar muestras positivas, la cantidad de muestras positivas es muy pequeña, lo que dificultará el entrenamiento de la red.En 如果一个样本不是正样本,那么它既没有定位损失,也没有类别损失,只有置信度损失el artículo de yolov3, el autor intentó usar la pérdida focal para aliviar el problema de desigualdad muestras positivas y negativas, pero La razón es que el valor de la muestra negativa participa en la pérdida de confianza, y el impacto en la pérdida es muy pequeño. El autor primero alinea la esquina superior izquierda de y, y luego calcula bboxel gr_boxy del anchorobjetivo , y establece Establecer un umbral, si el valor es mayor que el umbral, se clasifica como una muestra positiva.bboxgr_boxiouiouanchor templateiou
4. Función de pérdida
Las pérdidas incluyen pérdida de confianza, pérdida de localización y pérdida de predicción de categoría. Entre ellos, la pérdida de confianza considera todas las muestras, la pérdida de localización solo considera muestras positivas y la pérdida de clasificación considera muestras positivas.


5. Estrategia de formación
1. Se utiliza entrenamiento multiescala.
2. Se utiliza el aumento de datos.
3. Se utiliza la normalización estandarizada.