This article just briefly introduces the algorithm and network structure of these articles. The details can be found in my blog . SRLUT is relatively new in these articles (2021).
Original link:
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks
SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table [CVPR2021]
ESPCN: Real-Time Single Image and Video Super-Resolution Using an Efficient Sub- Pixel Convolutional Neural Network
VESPCN: Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
RCAN
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks
This article network is the deepest so far (referring to the time of this article).
The main purpose of the article is to go in depth, train one 非常深的网络, put forward RIR结构, put forward 通道注意力机制CA.

There are two main points in this article:
- Through multi-layer nesting dolls (three times), a very deep network (over 400 layers) was trained, and the proposedRIR structure。
- The author believes that different channels of the feature image contain information of different importance, so he proposesChannel Attention Mechanism CA。
RCAN mainly includes four parts: shallow feature extraction , Residual in Residual (RIR) deep feature extraction , upsampling and reconstruction .
The focus of this article is on the RIR part, and other parts are basically the same as EDSR and RDN , so I won't introduce more.
The overall structure of the RIR part: RIRwith RG as the basic module, it is composed of multiple residual group RG connected by a long jump LSC . Each RGcontains a number of channel residual blocks RCAB with short skip connections SSC . Each channel attention residual block consists RCABof a simple residual block BN and a channel attention mechanism CA.
-
First look at the first layer (the outermost layer):
RIRRG is used as the basic module, and it is composed of G residual group RG connected by a long jump connection LSC .
Long skip connections (LSC) can stabilize the training of ultra-deep networks, simplify the information flow between RGs, and integrate shallow and deep information to enhance image information and reduce information loss.
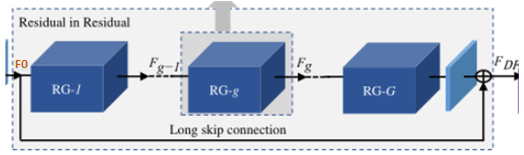
-
The second layer: Each
RGcontains a short skip connection SSC and B channel residual block RCAB .
Short skip connection (SSC), which can fuse local feature information at different levels.
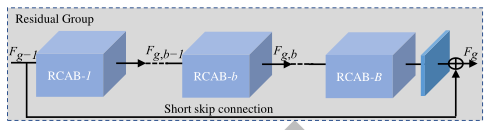
-
Before talking about the third layer, let me introduce the channel attention mechanism CA , because it is used in the innermost structure.
The feature information contained in different channels is different, so it is necessary to assign different weights to each channel, so that the network can pay more attention to some channels containing important information, so it is introduced注意力机制.
Use全局平均池化to convert the global spatial information of each channel into a channel descriptor (a constant, which is actually a weight value for each channel).
First, the features of each channel are transformed into a constant through global pooling, and then convolution 1 ( WD W_DWD)+ReLU+Volume 2( WU W_UWU)+sigmoid to get the final weight value s.
Convolution 1 reduces the number of channels to C r \frac{C}{r}rC, Convolution 2 amplifies the number of channels back to C. The final weight s is multiplied by the original feature x to obtain the feature after weight distribution.
CA adaptively redistributes the weights of channel features by focusing on the interdependencies between channels.

-
Layer 3: Each channel attention residual block consists
RCABof a simple residual block BN and a channel attention mechanism CA. (Innermost layer)
Ordinary residual block is composed of convolution + ReLU + convolution layer, connected in series with a channel attention mechanism CA, and a skip connection.

Review the RCAN structure: shallow feature extraction, Residual in Residual ( RIR ) deep feature extraction, upsampling and reconstruction. RIRWith RG as the basic module, it is composed of multiple residual group RG connected by a long jump LSC . Each RGcontains a number of channel residual blocks RCAB with short skip connections SSC . Each channel attention residual block consists RCABof a simple residual block BN and a channel attention mechanism CA.
Summary: The depth of the network proposed in this article is very deep , and generally very deep networks are difficult to train. The author increases the stability of network training and simplifies information flow by nesting multiple block structures and using long and short jump connections. Another feature of the article is to propose a channel attention mechanism , which assigns different weight values to different channels and optimizes the performance of the network.
SRLUT
SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table [CVPR2021]
This article is the first time it will be 查表法introduced into the SR field. The scaled pixel values trained by the SR network are stored in the table, and the image reconstruction task can be completed only by looking up the corresponding value in the table during the test phase. The test phase can be 脱离CNNnetworked. Since this method does not require a lot of floating point operations, it can be executed very quickly.

The overall structure of SR_LUT is: training network - storing table - testing (reading table) (the key part is storing table and reading table)
an image is enlarged by r times, which can be regarded as each pixel is enlarged by r times . The article is designed based on this idea, but what each pixel looks like after zooming in is determined by the surrounding pixels (receptive field).
Training network: conventional multiple convolutional layers to obtain a full-map mapping from LR to HR.
Save table:
- Given the size of the receptive field, use the previously trained mapping to obtain the pixel value of the enlarged corresponding area corresponding to the receptive field , and store it in the lookup table . For example, given a 2×2 receptive field. Then corresponding to the size of this area, there are a total of 25 5 4 255^42554 pixel arrangements are possible. In other words, the surrounding environment of this pixel must be this25 5 4 255^4255One of 4 .
每一种像素的排列must be stored in the lookup table, so that no matter how the pixels are arranged in the future, we can restore the reconstructed pixel area according to the lookup table. Therefore, a total of 25 5 n 255^nneeds to be stored in the table255n rows. nn is the specified receptive field size. 放大后对应图像区域仅与放大倍数r有关。Given magnification rrr ,the corresponding area size after each pixel enlargement should be r × rr × rr×r . The size of the receptive field is assigned to each pixel, and it is used to describe the surrounding environment of this pixel. The real subject is still the pixel, so after zooming in, we getr × rr × rr×r size.- So the storage capacity of the entire lookup table is: 25 5 n × r 2 × 8 bit \bm{255^n \times r^2 \times 8bit}255n×r2×8 b i t . (Each pixel occupies 8bit memory)
Table lookup: expand each pixel position in the picture to the size of the receptive field, then find the corresponding area value in the lookup table, and take it out as a reconstruction block.
The above is a conventional network, but considering 25 5 n 255^n255n lines, memory consumption is too much. So the author came up with a way to proposesampled-LUTVariant: Downsample 255 pixel values to reduce the memory occupied by the lookup table. The sampling interval is 2 4 2^424 , Divide the input space into { 0 , 16 , 32 , 48 , 64 , 80 , 96 , 112 , 128 , 144 , 160 , 176 , 192 , 208 , 224 , 240 , 255 }一共17个采样点. So25 5 n 255^n255The n possibilities are reduced to1 7 n 17^n17n , greatly reducing the storage capacity. But this also brings a problem. If the pixel of the input picture is a non-sampling point (decimal)when looking up the table, if the nearest sampling point value is directly replaced, the image will lose a lot of details, and the reconstruction effect will be very poor. So in this part, the author proposes a variety of corresponding receptive fieldinterpolation algorithm。
Summary: The main advantage of this article is the speed , because the test phase is separated from CNN and directly reads the table. Because it is separated from CNN, the network can be used on mobile phones, and its performance is also good. This idea is also quite new.
ESPCN
ESPCN: Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural NetworkThis
article proposes a new upsampling method: sub- pixel convolution (PixelShuffle), for the calculation speed and The reconstruction effect has been greatly improved.

This article is a kind of SISR, but the most worthy of our study is the last layer of the networkThe sub-pixel convolutional layer is Pixel-Shuffle, 上采样method.
The sub-pixel convolutional layer is generally placed at the last layer of the network without requiring additional computation.
In fact, the core idea of the sub-pixel convolution layer is the same as that in SRLUT. Enlarging an image by r times is equivalent to enlarging each pixel by r times.
The number of output channels in the convolution process of the penultimate layer of the network is r 2 r^2r2 The feature image of the same size as the original imageperiodically arrangedthrough the sub-pixel convolutional layerto obtainw × r, h × rw × r, h × rw×r,h×r reconstructs the image.
As shown in the figure, the nine features circled by the red ellipse on the penultimate layer (magnification factor is 3) are arranged to form a small box on the last layer pointed by the arrow, which is the reconstruction of the pixels framed in the original image through the network. piece. These nine pixels just triple the length and width of the original pixel.
It should be noted that although the sub-pixel convolution layer has the word convolution, it does not actually perform operations , but only extracts features and then simply arranges them .
Summary: The training network in this article is not complicated. The essence lies in the way of upsampling , which does not require convolution or even calculation. Simple periodic arrangement greatly reduces the complexity of calculation, and the effect is also very good. In many experiments Convolution-based upsampling is exceeded in Based on this article, the author continued to explore and proposed the following article VESPCN, which uses time information to do video reconstruction.
VESPCN
VESPCN: Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation The
VESPCN model proposed in this paper consists of two aspects: temporal-spatial network and motion compensation mechanism. The key to the article is how to make good use of it 时间信息.

VESPCN is mainly composed of Motion-Estimation network and Spatio-Temporal network. (Alignment + Fusion)
Motion Compensation Network: Based on the STN network, the pixel values of the previous and subsequent frames are predicted.
Temporal spatial network: The Spatio-Temporal network is an SR network based on ESPCN, which mainly uses sub-pixel convolutional layers for upsampling. In addition, this module needs to combine early fusion, slow fusion or 3D convolution to add time information. .
Since the STN network itself is derivable, the training of the entire motion compensation + temporal space network is a single 端对端training. The entire motion compensation network in VESPCN is essentially a time alignment network in VSR, which is based on the Flow-based method and belongs to Image-wise .
In fact, there is no motion compensation module, and only relying on the temporal space network can achieve relatively good reconstruction performance. However, motion compensation makes the content of the front and rear frames more aligned, enhances the correlation, and is more continuous in time .
Network structure:
Multiple frames of adjacent images are aligned to the reference frame through the STN-based motion compensation module, and then input into the ESPCN-based temporal space network to fuse temporal information to extract features, and finally use sub-pixel convolutional layer upsampling to complete SR reconstruction.
Break it down:
- Input three frames of images, the current frame I t LR I_t^{LR}ItLRAs a reference frame, two frames before and after are used as support frames, the previous frame I t − 1 LR I_{t-1}^{LR}It−1LRAnd the next frame I t + 1 LR I_{t+1}^{LR}It+1LRRespectively with the current frame I t LR I_t^{LR}ItLRDo a motion compensation to get two warp images I ' t − 1 LR I'_{t-1}^{LR}I’t−1LR和 I ’ t + 1 L R I’_{t+1}^{LR} I’t+1LR。
The purpose of this process is to make the previous frame I t − 1 LR I_{t-1}^{LR}It−1LRTry to transform to the current frame I t LR I_t^{LR}ItLRs position. Of course the next frame is the same. This is the alignment I have been talking about before . Reduce the offset of the three images and keep them as consistent as possible, so that there are more correlations in content and more continuity in time. Because it is impossible to change the support frame to be exactly the same as the reference frame, there will still be a difference, but the difference becomes smaller, which can be seen as a new frame inserted between the two pictures , so the continuity of the movement is greatly enhanced. The ME module in the figure is a variant based on the STN that adds a time element.
- Input the more similar images obtained after the three warps into the temporal space network for fusion , in fact, combine the three images together
提取特征, and finally use the sub-pixel convolutional layer Pixel-Shuffle to upsample and reconstruct the image output I t SR I_t^{SR}ItSR。
There are three ways in this fusion process: early fusion, slow fusion, and 3D convolution. The simplest early fusion is actually to stitch three images directly in the time dimension, and then extract features together. The fusion part actually refers to how to extract features .
Summary: The video reconstruction task is to add time information on the basis of single image SR, so how to use time information is the key. Aligning multiple frames of images and fusing multiple frames of images are for better extraction of time information.
To be continued~
Finally, I wish you all success in scientific research, good health, and success in everything~