이 글은 일종의 ViT 교육입니다.강화 방법 LV-ViT. 이전 Vision Transformer 분류 작업에서는 클래스 토큰만 사용하여 최종 분류를 위한 전역 정보를 수집했습니다. 저자는 손실 계산으로 패치 토큰을 사용할 것을 제안합니다. 이미지의 분류 문제를 각 토큰의 인식 문제로 변환하는 것과 동일하며 각 토큰의 분류 레이블은 기계에서 감독합니다.
원본 링크: 모든 토큰의 중요성: 더 나은 비전 트랜스포머 교육을 위한 토큰 라벨링
다른 버전: 토큰 라벨링: ImageNet에서 56M 매개변수로 85.5% Top-1 정확도 비전 트랜스포머 교육
출처 주소: https://github.com/zihangJiang/TokenLabeling
모든 토큰의 중요성: 더 나은 비전 트랜스포머 교육을 위한 토큰 라벨링[NIPS2021]
추상적인
본 논문에서는 고성능 VIT(Vision Transformer)의 학습을 위한 새로운 학습 목표인 토큰 라벨링을 제안한다. ViTs의 표준 교육 목표는 추가 교육 가능한 클래스 토큰에 대한 분류 손실을 계산하는 것이며 제안된 목표는 所有的图像patch token密集地计算训练损失.
즉, 이미지 분류 문제를 다중 토큰 수준 인식 문제 로 재구성 하고 각 패치 토큰에 기계 주석자가 생성한 별도의 위치별 감독을 할당합니다.
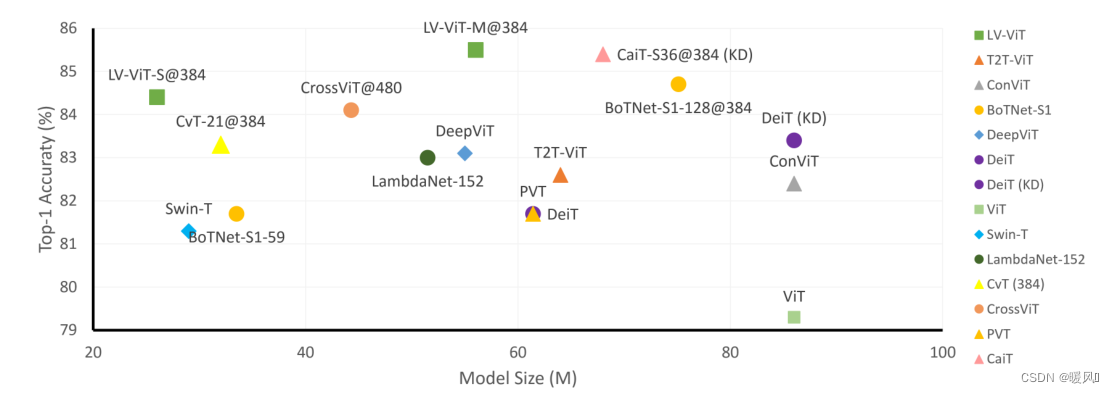
26M Transformer 모델은 ImageNet에서 84.4% Top-1 정확도를 달성할 수 있는 Token Labeling을 사용합니다.
모델 크기를 150M로 약간 확장하면 결과는 86.4%로 더 증가하여 이전 모델(250M 이상) 중 86%가 가장 작은 크기의 모델이 됩니다.
1. 소개
최근의 비전 변환기는 일반적으로 클래스 토큰을 사용하여 출력 클래스를 예측하는 반면, 각각의 로컬 이미지 패치 에 대한 풍부한 정보를 인코딩하는 다른 패치 토큰의 역할을 무시합니다 .
본 논문에서는 Vision Transformer라는 새로운 훈련 방법을 제안한다.LV-ViT, 패치 토큰과 클래스 토큰을 모두 사용합니다. 이 방법은 머신 어노테이터가 생성한 K차원 분수 맵을 감독으로 채택하여 모든 토큰을 조밀한 방식으로 감독합니다 . 여기서 K는 대상 데이터 세트의 범주 수입니다. 이러한 방식으로 각 패치 토큰은 해당 이미지 패치 내에서 대상 개체의 존재를 나타내는 단일 위치별 감독과 명시적으로 연결되어 무시할 수 있는 계산 오버헤드로 Vision Transformer의 개체 인식 기능을 향상시킵니다. 이것은 이미지 분류에서 비전 트랜스포머에 유익한 것으로 首次입증된 작업입니다.密集监控
그림과 같이 LV ViT에는 56M 매개변수가 있고 ImageNet에서 85.4%의 상위 1 정확도를 생성하여 최대 100M 매개변수로 다른 모든 Transformer 기반 모델을 능가합니다. 모델 크기를 150M로 확대하면 결과를 86.4%까지 더 향상시킬 수 있습니다.
2 방법
기존의 ViT는 이미지를 패치로 나눈 다음 클래스 토큰을 추가하고 여러 번의 유사도 계산을 거쳐 이미지 정보를 클래스 토큰으로 집계합니다. 각 이미지 블록 풍부한 정보 . 여기서 X cls X^{cls}엑스c l s 는 마지막 Transformer Black의 출력,H ( ⋅ , ⋅ ) H(·,·)H ( ⋅,⋅) 는 소프트맥스 교차 엔트로피 손실,yclsy^{cls}와이c ls는 클래스 레이블입니다. 본 논문에서는 패치 토큰과 클래스 토큰 간의 보완 정보를
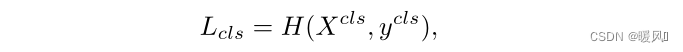
활용한 새로운 학습 대상 토큰 라벨링을 제안한다.
2.1 토큰 라벨링
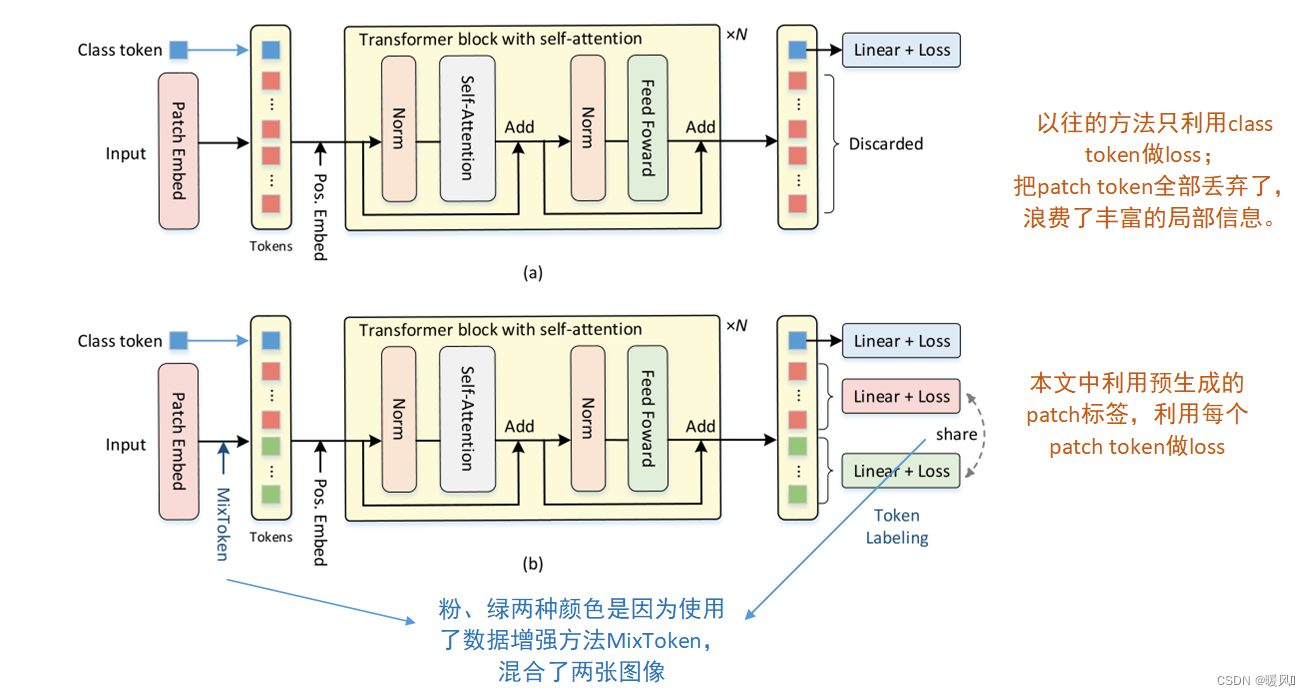
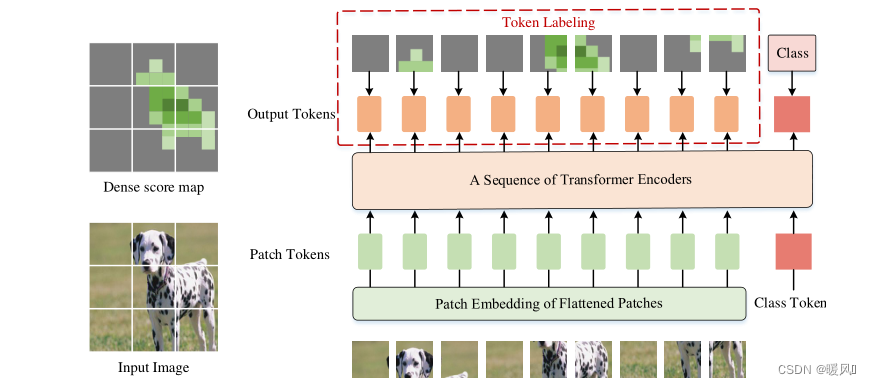
토큰 레이블링은 모든 출력 토큰의 중요성을 강조하고 각 출력 토큰이 단일 위치별 레이블과 연결되어야 한다고 주장합니다. 따라서 입력 이미지의 레이블은 단일 K차원 벡터 yclsy^{cls} 만을 포함하지 않습니다.와이c l s (이미지 수준 레이블),K × NK × N케이×[ y 1 , ... , y N ] [y^1,...,y^N]과같은 N 행렬 또는K 차원 분수 그래프[ y1 ,. . . ,와이N ], 여기서 N은 출력 패치 토큰의 수입니다. 즉,하나의 토큰에는 하나의 레이블이 있으므로 각 토큰은 보조 손실로 사용할 수 있습니다. 그러나 이 레이블은 대상 개체가 해당 이미지 패치에 존재하는지 여부를 나타냅니다. K-dimension fraction map을 얻는 방법은 기사에 자세히 설명되어 있지 않으며 제 방향을 벗어납니다.관심 있는 학생들은 이Token Labeling 을.
각 훈련 이미지는 조밀한 스코어 맵을 활용하고 각 출력 패치 토큰과 조밀한 스코어 맵의 해당 정렬 레이블 간의 교차 엔트로피 손실을 훈련 단계의 보조 손실로 사용 합니다 . 패치 토큰의 손실 함수는 다음과 같이 정의됩니다.
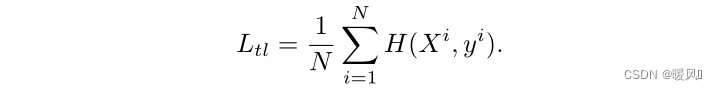
전체 손실 함수는 기존 클래스 토큰 손실에 패치 토큰 손실을 더한 것입니다 . 여기서 β는 이 두 항목의 균형을 맞추기 위한 하이퍼 매개변수입니다. 실험적으로 0.5로 설정했습니다. 공식은 다음과 같습니다.
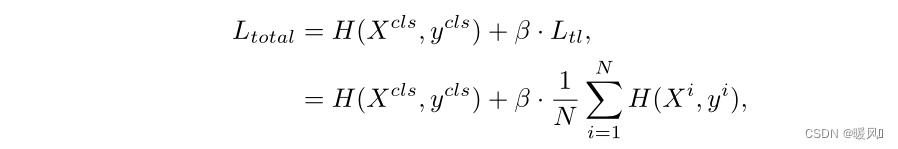
토큰 라벨링에는 다음과 같은 이점이 있습니다.
- 지식 증류 방식은 일반적으로 교사 모델이 온라인에서 감독 레이블을 생성해야 하는 반면 토큰 레이블 지정은 더 간단한 작업입니다. 조밀한 스코어 맵은 사전 훈련된 모델(예: EfficientNet, NFNet)로 생성할 수 있습니다. 훈련 중에는 점수 맵만 자르고 공간 좌표에서 잘린 이미지와 정렬되도록 보간해야 합니다. 따라서 추가 계산 비용은 무시할 수 있습니다.
- 둘째, 단일 레이블 벡터를 감독으로 사용하는 대부분의 분류 모델 및 재 레이블 지정 전략과 달리 이 방법은 스코어 맵을 활용하여 조밀한 방식으로 모델을 감독하므로 각 패치 토큰의 레이블은
位置特定信息훈련된 모델이 다음을 수행하는 데 도움이 될 수 있습니다. 대상 물체를 쉽게 발견하고 인식 정확도를 향상시킵니다 . - 훈련에 사용되는 조밀한 감독으로 인해 토큰 레이블 지정이 있는 사전 훈련된 모델은 시맨틱 분할과 같은 조밀한 예측이 있는 다운스트림 작업 에 도움이 됩니다.
2.2 MixToken을 사용한 토큰 라벨링
몇 가지 이전 개선 방법을 나열하십시오.
- 혼합: 두 개의 임의 샘플을 비율에 따라 혼합하고 분류 결과는 비율에 따라 분포됩니다.
- 컷아웃: 샘플의 일부 영역을 임의로 잘라내고 0픽셀 값을 채우면 분류 결과가 변경되지 않습니다.
- CutMix: 영역의 일부를 잘라내어 0픽셀을 채우지 않고 training set에 있는 다른 데이터의 영역 픽셀 값을 임의로 채우고, 분류 결과를 일정한 비율에 따라 분포시키는 것입니다.
본 논문에서 저자는 새로운 이미지 향상 방법인 MixToken을 제안하고 이를 CutMix와 비교한다. CutMix가 입력 이미지 에서 작동 한 후 두 이미지의 혼합 영역 , 즉 빨간색 부분을 포함하는 패치를 생성합니다. MixToken의 목표는 패치 삽입 후 토큰을 혼합하는 것입니다 . 이렇게 하면 패치 임베딩 후 각 토큰이 깨끗한 콘텐츠를 갖게 됩니다.

생성 방법: 이미지가 2개인 경우 I 1 , I 2 I1, I2
로 표현I 1 , I 2 는 해당 토큰 레이블 Y 1 = [ y 1 1 , … , y 1 N ] Y_1=[y_1^1,…,y^N_1]을 미리생성했습니다.와이1=[ y11,…,와이1엔]以及Y 2 = [ y 2 1 , … , y 2 N ] Y_2=[y^1_2,…,y^N_2]와이2=[ y21,…,와이2엔]。
패치 포함 모듈에 두 개의 이미지를 입력하여 최종 토큰 시퀀스를 얻습니다: T 1 = [ t 1 1 , … , t 1 N ] T_1=[t^1_1,…,t^N_1]티1=[ 티11,…,티1엔] 와T 2 = [ t 2 1 , … , t 2 N ] T_2=[t^1_2,…,t^N_2]티2=[ 티21,…,티2엔] . 그런 다음 이진 마스크 M을 통해 새로운 토큰 시퀀스가 생성됩니다. 공식: ⊙는 내적이며 마스크 M은 논문 "Regularization strategy to train strong classifiers with localizable features"의 방법에 따라 생성됩니다.
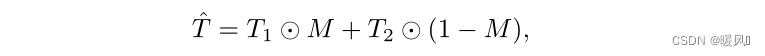
레이블에 대해 동일한 작업을 수행합니다.
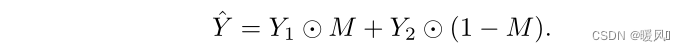
클래스 레이블은 두 이미지 레이블의 평균이 되며 공식은 다음과 같습니다. 여기서 M ˉ \bar M중ˉ 는 M에 있는 모든 요소의 평균값입니다.
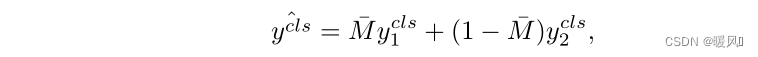
3 결론
- 이 기사의 핵심 아이디어는 이전에 무시된 패치 토큰을 보조 손실로 사용하는 것입니다.
- 각 패치 토큰에 해당하는 레이블은 사전 생성을 통해 획득하며 자세한 방법은 토큰 레이블링을 참조하십시오.
- 새로운 데이터 향상 방법인 MixToken을 사용하여 두 이미지가 결합되는 경계에서 혼합 영역을 방지합니다.
마지막으로 과학 연구의 성공, 건강, 모든 일의 성공을 기원합니다 ~