Este artículo
Este artículo se basa en el principio de tecnología de big data y el MOOC de aplicación de la Universidad de Xiamen, y recomienda a los estudiantes que tienen suficiente tiempo para estudiar cuidadosamente.
https://www.icourse163.org/course/XMU-1002335004
Descripción general de grandes datos
Arquitectura de procesamiento Hadoop
Sistema de archivos distribuido HDFS
Base de datos distribuida HBASE
Introducción
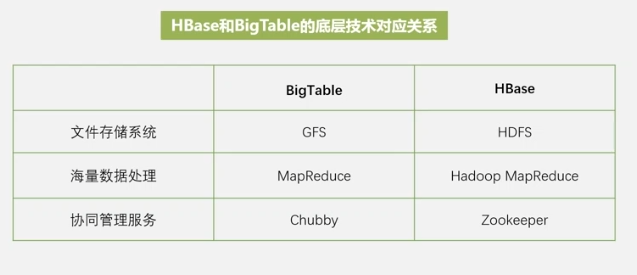
Google usó anteriormente BigTable para la búsqueda web interna a gran escala, y HBASE es una implementación de código abierto de BigTable.
HBASE es una base de datos distribuida que se puede utilizar para almacenar datos sueltos no estructurados y semiestructurados.
La importancia del nacimiento de HBASE

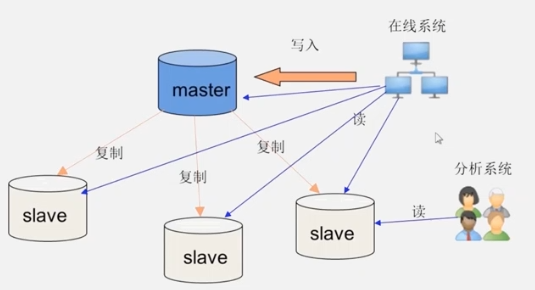
Para las bases de datos tradicionales, cuando aumenta la cantidad de datos, se utiliza el método de "servidor maestro-esclavo" para optimizar, de modo que la carga de lectura se distribuya a los servidores esclavos con el mismo contenido para lograr una expansión del rendimiento. Sin embargo, la carga de "escritura" no se puede optimizar.
Otro esquema de optimización es
- Sub-biblioteca: una biblioteca para cada departamento comercial (no se puede resolver fundamentalmente, y seguirá aumentando)
- Cortar e implementar manualmente en diferentes servidores (problemático, operación manual, baja eficiencia)
La diferencia entre HBASE y la base de datos tradicional

- Operaciones de datos: HBASE descarta operaciones que consumen mucho tiempo, como conexiones
- Indexación de datos: solo se admite la indexación simple en claves de fila
- Mantenimiento de datos: las versiones antiguas se conservan, con sellos de tiempo, y se eliminan después de su vencimiento.
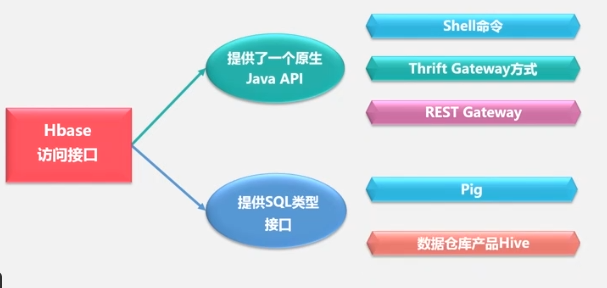
Interfaz de acceso HBASE:
modelo de datos HBASE
Tabla de asignación ordenada multidimensional dispersa
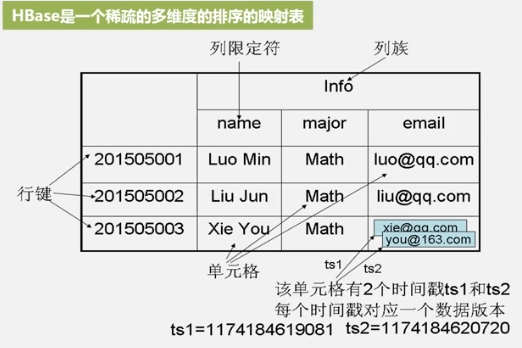
- Mediante clave de fila + familia de columnas + calificador de columna + marca de tiempo = un dato específico.
- Cada valor es una matriz de bytes no interpretada, que el desarrollador debe analizar.
- Una fila tiene una clave de fila y columnas.
- La familia de columnas admite expansión dinámica, aumento y disminución, y admite la retención de versiones antiguas (HDFS solo permite la adición, no la modificación).
- Los calificadores de columna admiten la expansión dinámica, el aumento y la disminución.
- Una celda contiene datos para varias marcas de tiempo.
Localizar un dato requiere 4 claves

Vista conceptual de datos
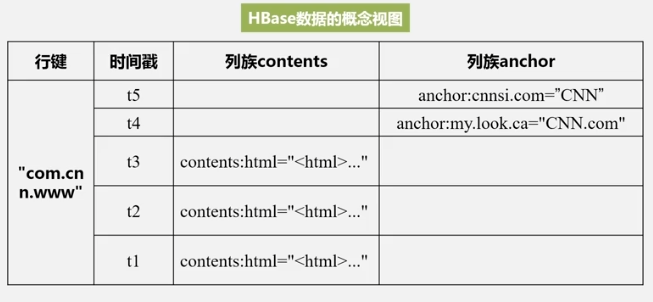
El contenido es la familia de columnas, html es el calificador de columna y las comillas son los valores. Puede ver que las 4 claves determinan un dato y es escaso, por lo que se denomina tabla de mapeo ordenada multidimensional dispersa. .
Vista de almacenamiento físico de datos

Se puede ver que HBASE es almacenamiento en columnas. La ventaja del almacenamiento en columnas es que al obtener datos, generalmente se extrae un determinado atributo para el análisis. Por ejemplo, solo se necesitan las calificaciones del estudiante y no se necesita otra información de columna, como la dirección y la ciudad natal. El almacenamiento basado en filas necesita obtener un fila y luego extraer algunos datos, se escanea cada línea, lo que equivale a recorrerlas todas.
Además, los tipos de datos de una columna de datos generalmente están relacionados y el almacenamiento de la columna puede generar una alta tasa de compresión de datos.
¿Cómo elegir un método de almacenamiento?
Si la aplicación se basa principalmente en el análisis, se utiliza el almacenamiento en columnas.
Si hay muchas operaciones transaccionales, utilice el almacenamiento de filas.
El principio de realización de HBASE
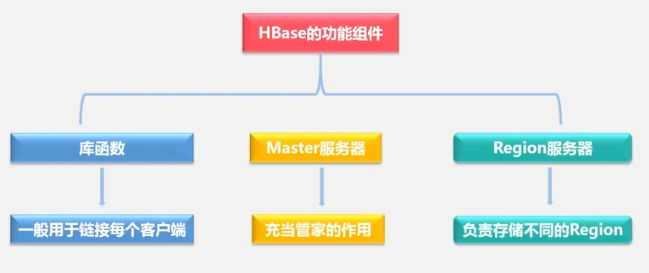
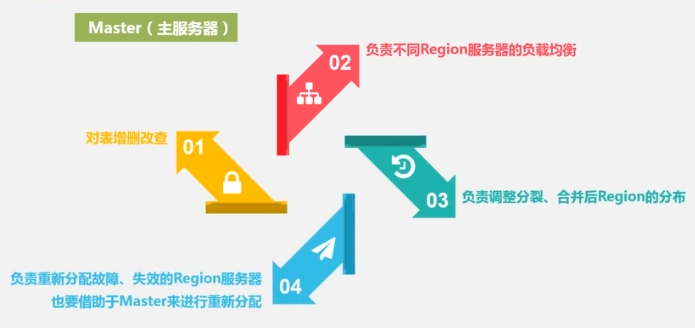
El servidor maestro es responsable de:
- Gestión y mantenimiento de información de particiones
- Mantenimiento de la lista de servidores de la región
- Qué servidores regionales están funcionando y cuáles se mantienen.
- Asigne el servidor de región al que está asignada la tabla Región.
- balanceo de carga
El servidor de región es responsable de:
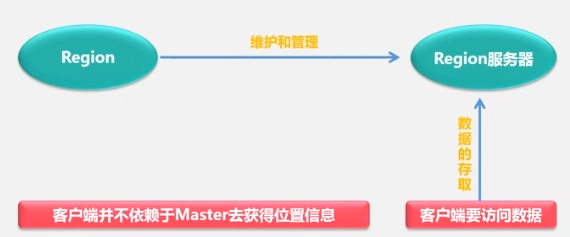
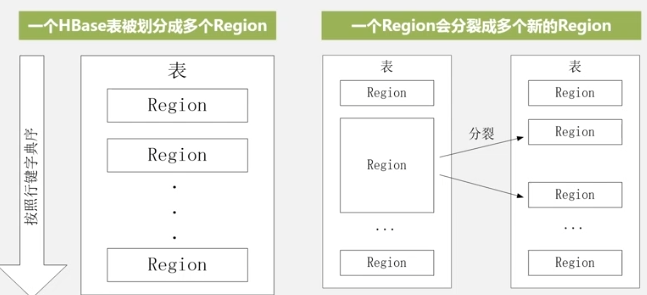
Cuando se crea una tabla por primera vez, solo hay una región. Cuando una región determinada de una tabla determinada es demasiado grande, se divide rápidamente y los datos primero apuntan a la dirección original. Una vez completada la combinación, se crea un nuevo archivo. generado y luego apunta a la nueva dirección. Diferentes regiones pueden estar en diferentes servidores de regiones, pero la misma región debe estar en el mismo servidor de regiones.
Posicionamiento de regiones

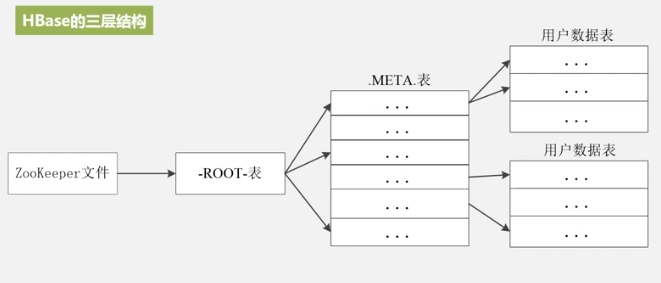
Es decir, visite el servidor de ZooKeeper para saber dónde está la tabla raíz,
verifique la tabla raíz para saber dónde está almacenada la tabla meta
y luego verifique la tabla meta para saber dónde está almacenada la tabla de datos.
Esta es una estructura de tres niveles. .
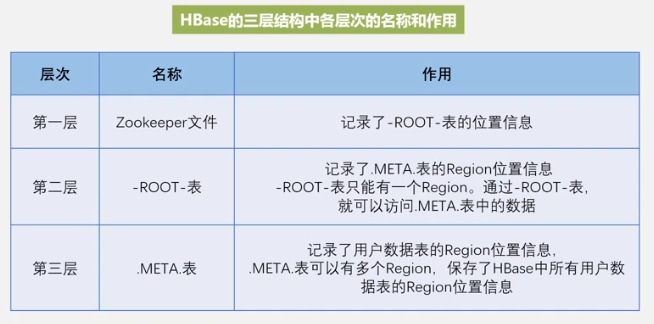
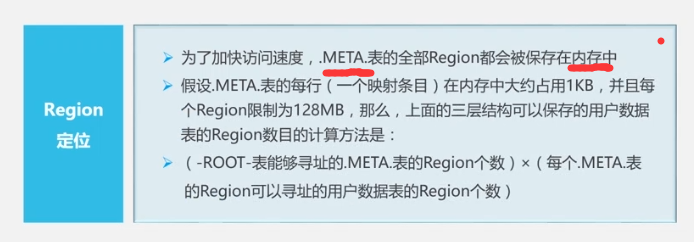
Para acelerar el direccionamiento, el cliente almacenará en caché la información de la ubicación, al mismo tiempo, si ocurre el problema de invalidación de caché, el direccionamiento se repetirá en la tercera capa.
Mecanismo operativo HBASE
Arquitectura del sistema HBASE
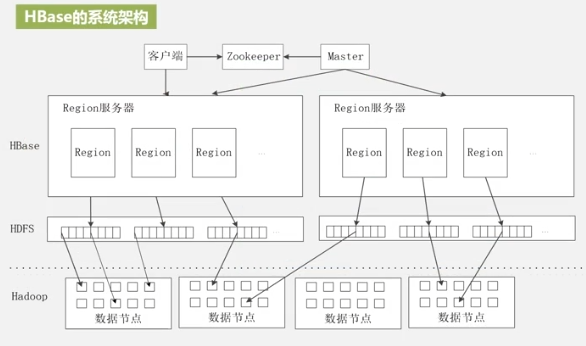
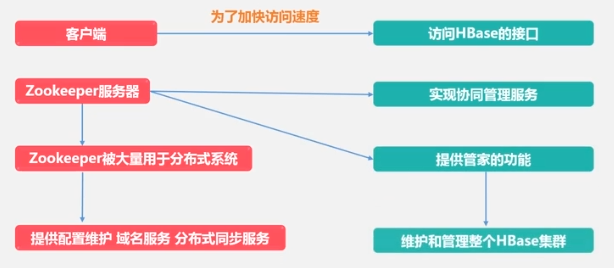
ZooKeeper garantiza que solo un servidor principal (maestro) se está ejecutando actualmente (puede haber varios servidores de reserva).
Principio de funcionamiento del servidor de región
Responsable del almacenamiento y gestión de los datos de los usuarios.

Un clúster de servidores de región tiene de 10 a 1000 servidores de región
. Una tienda representa una familia de columnas. La tienda se escribe primero en MemStore y luego se escribe periódicamente en StoreFile. StoreFile es el formato de almacenamiento de HDFS y utiliza HFile para el almacenamiento.
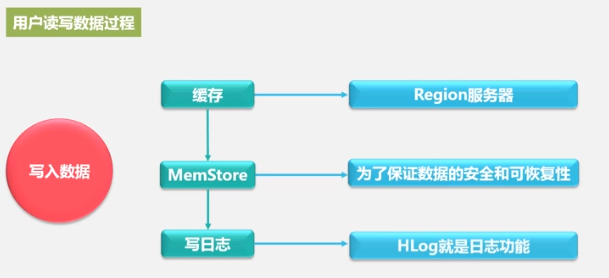
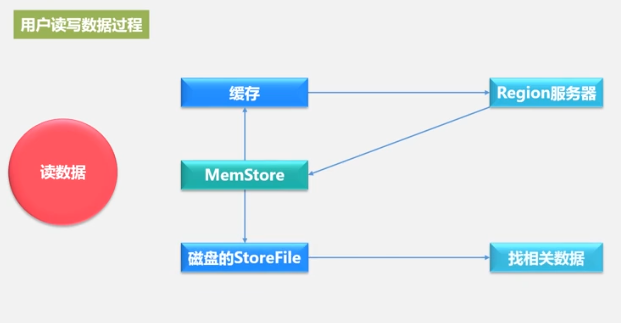
Principio de funcionamiento de la tienda.
Store es la familia de columnas. Revise el almacenamiento físico de la familia de columnas:
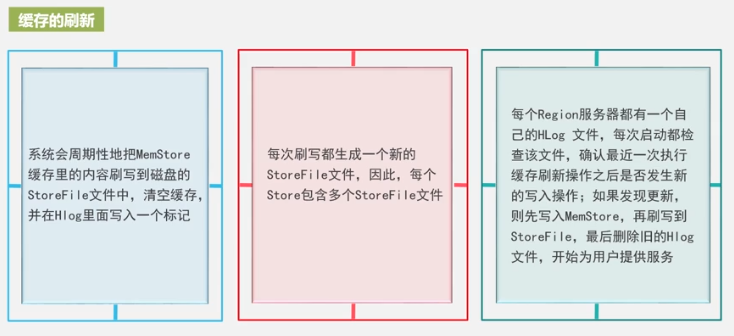
Cada vez se genera un nuevo storeFile Hay demasiados archivos y el recorrido es lento, por lo que se fusionan, y los archivos son grandes, por lo que se dividen. Este es el motivo de la fusión y división de StoreFiles, así como de la fusión y división de Regions.
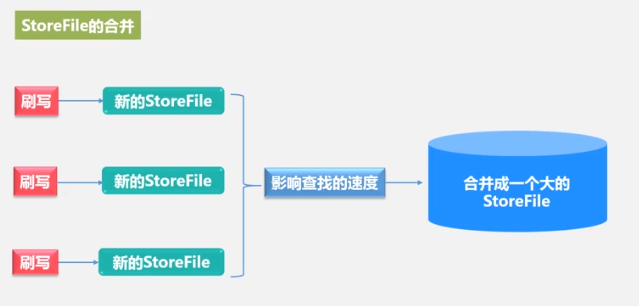
La fusión consume una gran cantidad de recursos y, por lo general, se fusiona cuando la cantidad de archivos de StoreFile supera cierto umbral.
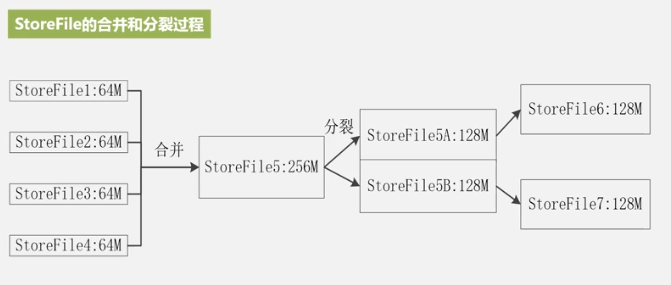
Cómo funciona HLog
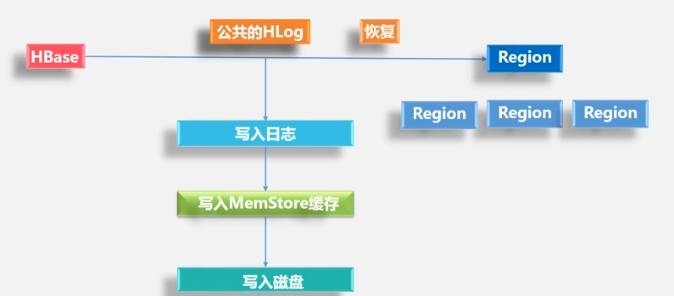
Escriba primero en el registro y luego escriba en MemStore.Un
servidor de región tiene varias regiones, un HLog y un HLog para garantizar un alto rendimiento de escritura.
Solución de aplicación HLog
optimización del rendimiento
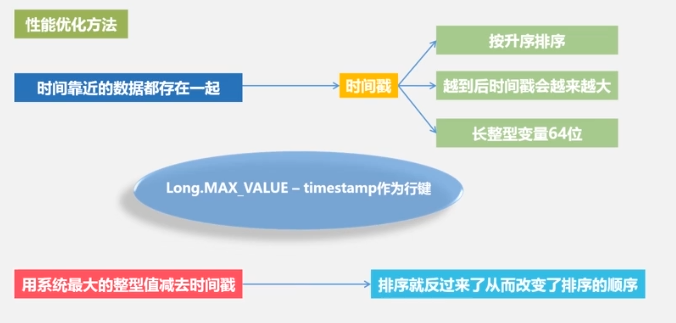
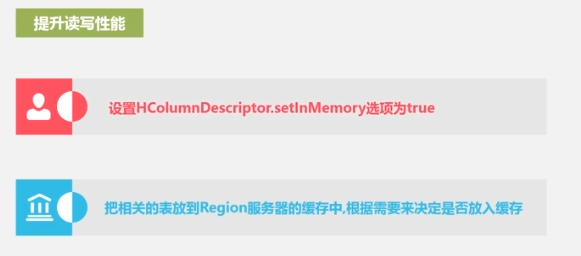

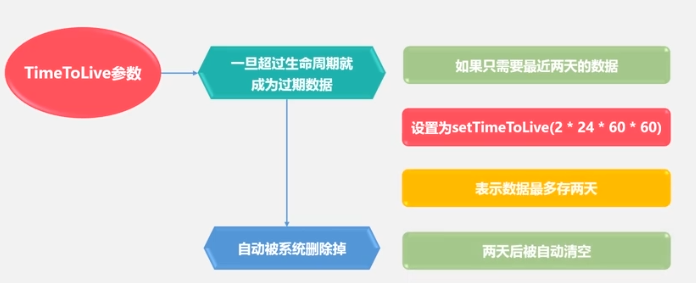
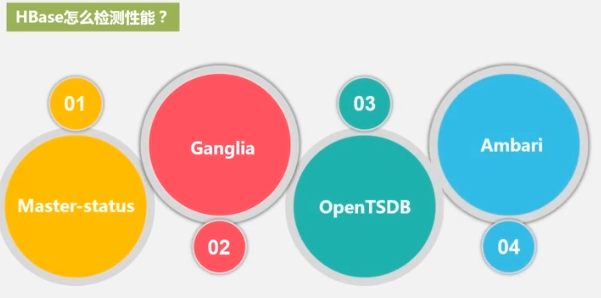
pruebas de rendimiento
Puede usar sentencias SQL para consultar datos en HBase.Índice
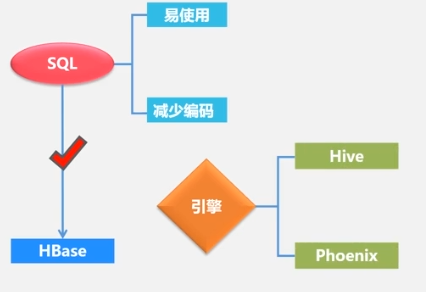
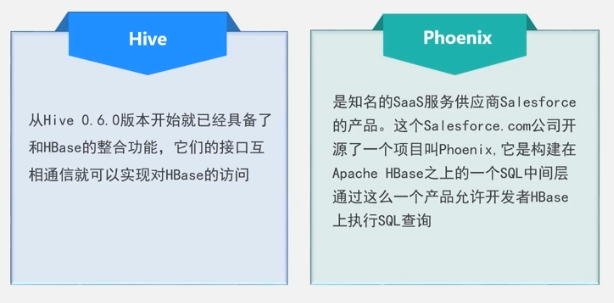
secundario:
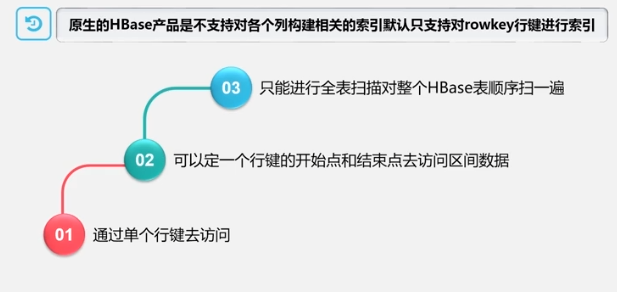
índice a través de la tabla de índice (inserte el índice al mismo tiempo que inserta datos, insértelo dos veces y el rendimiento disminuirá)
funcionar
http://dblab.xmu.edu.cn/blog/2442-2/
Use el comando crear para crear una tabla en HBase, de la siguiente manera:
create 'student','Sname','Ssex','Sage','Sdept','course'

En este punto, se crea una tabla de "estudiante" con atributos: Sname, Ssex, Sage, Sdept, Course. Debido a que habrá un atributo predeterminado del sistema en la tabla HBase como clave de fila, no es necesario que lo cree usted mismo, y el valor predeterminado es el primer dato después del nombre de la tabla en la operación del comando put. Después de crear la tabla "estudiante", puede ejecutar el comando describe para ver la información básica de la tabla "estudiante".
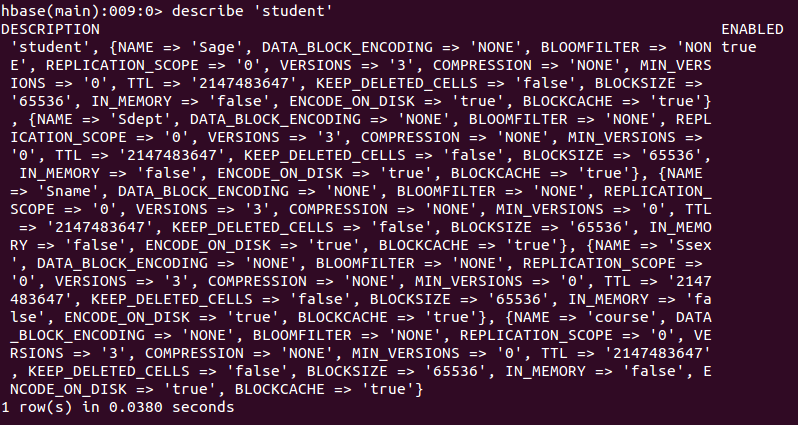
Al agregar datos, HBase agregará automáticamente una marca de tiempo a los datos agregados, por lo que cuando necesite modificar los datos, simplemente agregue los datos directamente y HBase generará una nueva versión para completar la operación de "modificación", y la versión anterior permanecerá Reservado, el sistema reciclará regularmente datos basura, dejando solo las últimas versiones, y la cantidad de versiones guardadas se puede especificar al crear la tabla.
- agregando datos
put 'student','95001','Sname','LiYing'
Es decir, se agrega a la tabla de estudiantes una fila de datos cuyo ID de estudiante es 95001 y cuyo nombre es LiYing, y su clave de fila es 95001.
put 'student','95001','course:math','80'
Es decir, se agrega un dato a la columna matemática de la familia de columnas del curso en la fila 95001.
- borrar datos
delete 'student','95001','Ssex'
Es decir, se eliminan todos los datos de la columna Ssex en la fila 95001 de la tabla de estudiantes.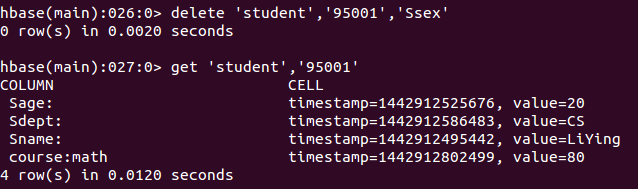
- ver datos
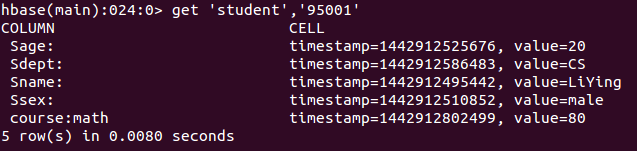
get 'student','95001'
La captura de pantalla de la ejecución del comando es la siguiente, y los datos devueltos son la fila '95001' de la tabla 'estudiante'.