navegación:
Tabla de contenido
1. Pasos de optimización del servidor de base de datos
2. Ver los parámetros de rendimiento del sistema
2.1 MOSTRAR ESTADO COMO 'parámetros'
2.2 Comprobar el coste de consulta de SQL
3. Localice el SQL que se ejecuta lentamente: registro de consulta lenta
3.1 Habilitar parámetros de registro de consultas lentas
3.2 Ver el número de consultas lentas
3.5 Herramienta de análisis de registro de consultas lentas: mysqldumpslow
3.6 Desactivar el registro de consultas lentas
3.7 Eliminar registros de consultas lentas
4. Localice declaraciones de consulta lentas y vea los costos de ejecución de SQL: muestre el perfil
5. Plan de ejecución: EXPLIQUE
5.3 Introducción al Calendario de Ejecución
5.4 EXPLICAR cuatro formatos de salida
5.5 Uso de MOSTRAR ADVERTENCIAS
6. Analizar el plan de ejecución del optimizador: rastrear
7. Esquema view-sys de análisis de monitoreo de MySQL
1. Pasos de optimización del servidor de base de datos
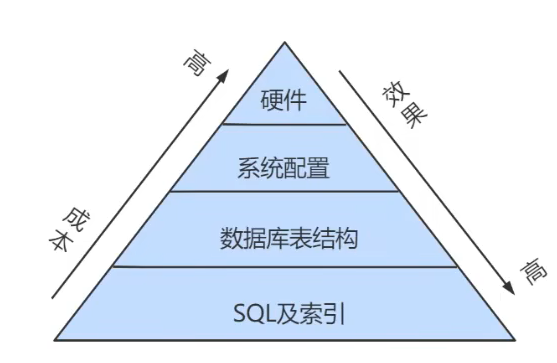
En el ajuste de la base de datos, nuestro objetivo es un tiempo de respuesta más rápido y un mayor rendimiento . El uso de herramientas de monitoreo macro y análisis de micro registros puede ayudarnos a encontrar rápidamente ideas y métodos para el ajuste.
Proceso de sintonización:
- SHOW STATUS observa el estado del servidor, si hay fluctuaciones periódicas, si las hay, optimiza el caché ;
- Si todavía hay un retraso o demora irregular, inicie una consulta lenta y explique la declaración de la consulta ;
- Si encuentra que el tiempo de espera de sql es largo, ajuste los parámetros del servidor ; si encuentra que el tiempo de ejecución de sql es largo, optimice el índice y la tabla;
- Si todavía hay retrasos o bloqueos irregulares, observe si la consulta SQL ha llegado al cuello de botella; si es así, separe la lectura y la escritura, y divida las bases de datos y las tablas.
Tres herramientas de análisis (tres pasos para el ajuste de SQL): consulta lenta, EXPLAN, MOSTRAR PERFIL
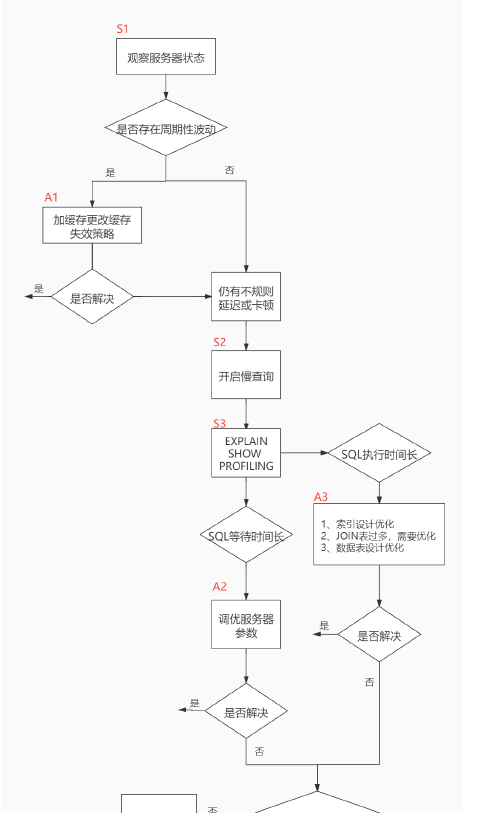

Todo el proceso se divide en dos partes: observación (Mostrar estado) y acción (Acción). La parte con la letra S significa observación (se utilizará la herramienta de análisis correspondiente), y la parte con la letra A es acción (la acción que se puede tomar según el análisis).
2. Ver los parámetros de rendimiento del sistema
2.1 MOSTRAR ESTADO COMO 'parámetros'
En MySQL, puede usar la declaración SHOW STATUS para consultar los parámetros de rendimiento y la frecuencia de ejecución de algunos servidores de bases de datos MySQL.
La sintaxis de la sentencia SHOW STATUS es la siguiente:
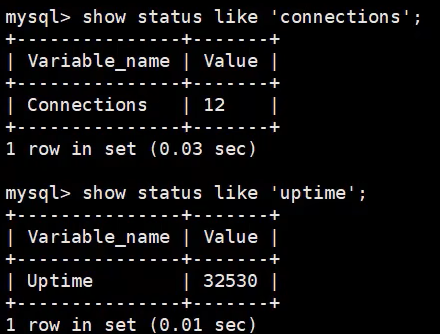
SHOW [GLOBAL|SESSION] STATUS LIKE '参数';Por ejemplo, verifique la cantidad de conexiones a la base de datos y el tiempo de ejecución:
Los corchetes significan que se puede omitir.
Algunos parámetros de rendimiento comúnmente utilizados son los siguientes:
• Conexiones: El número de conexiones al servidor MySQL.
• Uptime: El tiempo en línea del servidor MySQL. Se restablecerá después de reiniciar el servidor.
• Slow_queries: el número de consultas lentas . La duración de la consulta supera el tiempo especificado, y cuantas menos veces, mejor.
• Innodb_rows_read: el número de filas devueltas por la consulta Select
• Innodb_rows_inserted: el número de filas insertadas por la operación INSERT
• Innodb_rows_updated: el número de filas actualizadas por la operación UPDATE
• Innodb_rows_deleted: el número de filas eliminadas por la operación DELETE
• Com_select: El número de operaciones de consulta.
• Com_insert: El número de operaciones de inserción. Para las operaciones de INSERCIÓN de inserción por lotes, solo acumule una vez.
• Com_update: El número de operaciones de actualización.
• Com_delete: el número de operaciones de eliminación.
• last_query_cost: el costo de una consulta en el optimizador de consultas y el número de páginas de datos utilizadas en la última eliminación.
2.2 Comprobar el coste de consulta de SQL
SHOW STATUS LIKE 'last_query_cost';
La consulta SQL es un proceso dinámico, desde el punto de vista de la carga de la página:
1. La eficiencia de la consulta del grupo de búfer es mejor que la consulta del disco
Si la página está en el grupo de búfer de la base de datos, entonces la eficiencia es la más alta , de lo contrario, debe leerse desde la memoria o el disco. Por supuesto, para leer una sola página, si la página existe en la memoria, será más rápido que leer del disco La eficiencia de extracción es mucho mayor.
El grupo de búfer de MySQL se divide en varios grupos de búfer diferentes, que incluyen:
- Caché de consultas: se utiliza para almacenar en caché los resultados de las consultas.
- Grupo de caché de InnoDB: se utiliza para almacenar en caché las tablas activas y las páginas de datos de índice.
- Grupo de caché MyISAM: se utiliza para almacenar en caché los bloques de datos de la tabla.
Cuando se ha almacenado una gran cantidad de datos en el grupo de búfer, MySQL utilizará un método llamado algoritmo de reemplazo del grupo de búfer para reemplazar parte de los datos almacenados en caché para dejar espacio para que se almacenen nuevos datos en caché.
El grupo de búfer de MySQL usa el algoritmo LRU (usado menos recientemente) , que almacena primero en caché los datos usados más recientemente. Cuando el espacio en el grupo de búfer es insuficiente, MySQL reemplazará los datos menos utilizados del grupo de búfer para dejar espacio para nuevos datos.
2. La consulta secuencial por lotes es más alta en promedio por consulta de página
Si leemos aleatoriamente una sola página del disco, la eficiencia es muy baja (alrededor de 10 ms), pero si usamos la lectura secuencial para leer páginas en lotes , la eficiencia de lectura promedio de una página mejorará mucho, incluso más rápido que una lectura aleatoria. lectura de una sola página en la memoria.
Por lo tanto, no se preocupe por encontrarse con IO, si encuentra el método correcto, la eficiencia sigue siendo muy alta. Primero debemos considerar la ubicación del almacenamiento de datos. Si los datos se usan con frecuencia, debemos colocarlos en el grupo . En segundo lugar, podemos aprovechar al máximo la capacidad de rendimiento del disco para leer datos en lotes en una vez , por lo que la eficiencia de lectura de una sola página también es baja.
El grupo de búfer de prueba almacena en caché las tablas e índices usados en la memoria, lo cual es muy eficiente: el costo de consulta de consultar 900001 y 900001~9000100 es muy diferente, y la velocidad de consulta es similar
Ejemplo de formulario de información del estudiante:
CREATE TABLE `student_info` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `student_id` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL, `course_id` INT NOT NULL , `class_id` INT(11) DEFAULT NULL, `create_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;Si queremos consultar el registro con id=900001 y luego ver el costo de la consulta, podemos buscar directamente en el índice agrupado:
SELECT student_id, class_id, NAME, create_time FROM student_info WHERE id = 900001;Resultado de la ejecución (1 registro, el tiempo de ejecución es de 0,042 s)
Luego mire el costo del optimizador de consultas , de hecho solo necesitamos recuperar una página :
SHOW STATUS LIKE 'last_query_cost';+-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | Last_query_cost | 1.000000 | +-----------------+----------+¿Qué pasa si queremos consultar los registros de estudiantes con id entre 900001 y 9000100 ?
SELECT student_id, class_id, NAME, create_time FROM student_info WHERE id BETWEEN 900001 AND 900100;Resultado de la ejecución (100 registros, el tiempo de ejecución es de 0,046 s):
Luego mire el costo del optimizador de consultas En este momento, necesitamos consultar unas 20 páginas.
mysql> SHOW STATUS LIKE 'last_query_cost'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | Last_query_cost | 21.134453 | +-----------------+-----------+Puede ver que el número de páginas es 20 veces mayor que el de ahora, pero la eficiencia de la consulta no ha cambiado significativamente . De hecho, el tiempo de las dos consultas SQL es básicamente el mismo, porque las páginas se cargan al mismo tiempo. por lectura secuencial al grupo de búfer antes de realizar la búsqueda. Aunque el número de páginas (last_query_cost) ha aumentado mucho , el tiempo de consulta no ha aumentado mucho a través del mecanismo del grupo de búfer.
¿Por qué se verifica directamente desde el grupo de búfer por segunda vez?
Debido a que la estrategia de eliminación de caché mysql lru es la menos utilizada recientemente, los datos de consulta más recientes se almacenarán en caché primero y los datos utilizados menos recientemente se eliminarán primero.
Escenario de uso: Es muy útil para comparar costos, especialmente cuando tenemos varios métodos de consulta para elegir.

3. Localice el SQL que se ejecuta lentamente: registro de consulta lenta
3.0 Introducción
El registro de consultas lentas de MySQL se usa para registrar las declaraciones cuyo tiempo de respuesta excede el umbral en MySQL , específicamente se refiere al SQL cuyo tiempo de ejecución excede el valor de long-query_time , y se registrará en el registro de consultas lentas. El valor predeterminado de long_query_time es 10, lo que significa que se considera que las declaraciones que se ejecutan durante más de 10 segundos (excluyendo 10 segundos) exceden nuestro valor de tiempo de tolerancia máximo.
Su función principal es ayudarnos a encontrar aquellas consultas SOL que tardan mucho tiempo en ejecutarse y optimizarlas de manera específica, mejorando así la eficiencia general del sistema. Cuando nuestro servidor de base de datos está bloqueado y funciona lentamente, verifique el registro de consultas lentas para encontrar esas consultas lentas, lo cual es muy útil para resolver el problema. Por ejemplo, si un sqq se ejecuta durante más de 5 segundos, lo consideraremos como SQL lento. Esperamos recopilar el SQL durante más de 5 segundos y combinarlo con explicación para un análisis completo.
De forma predeterminada, la base de datos MySQL no habilita el registro de consultas lentas y debemos configurar manualmente este parámetro. Si no es necesario para el ajuste, generalmente no se recomienda habilitar este parámetro , ya que habilitar el registro de consultas lentas provocará más o menos cierto impacto en el rendimiento.El
registro de consultas lentas admite la escritura de registros en archivos.
3.1 Habilitar parámetros de registro de consultas lentas
0. Si la consulta lenta está habilitada
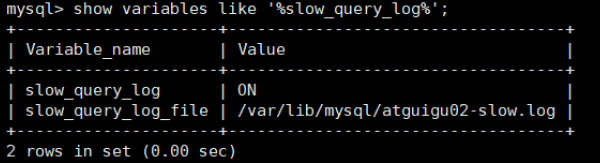
show variables like '%slow_query_log';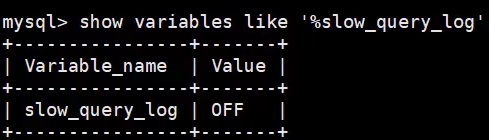
Ubicación del registro de consultas lentas:
show variables like '%slow_query_log%';
Umbral de consulta lenta:

1. Habilitar el registro de consultas lentas slow_query_log
set global slow_query_log='ON';Luego, verifiquemos si el registro de consultas lentas está habilitado y la ubicación del archivo de registro de consultas lentas:
Puede ver que el análisis de consultas lentas se ha habilitado en este momento y el archivo se guarda en el archivo /var/lib/mysql/atguigu02-slow.log
medio.
2. Modificar el umbral de consulta lenta long_query_time
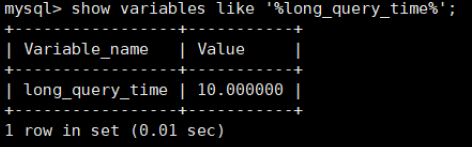
Ver el umbral de tiempo para consultas lentas:
show variables like '%long_query_time%';Compruebe el umbral de tiempo de consulta lento global:
show global variables like '%long_query_time%';
Modificar temporalmente el umbral de tiempo para consultas lentas:
sesión actual:
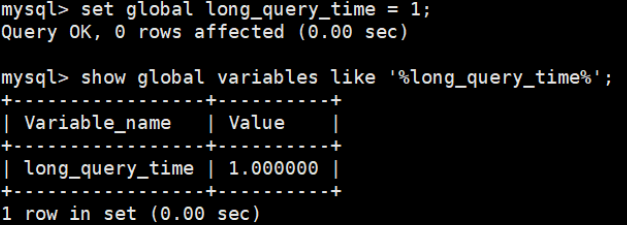
set long_query_time = 1; global:
set global long_query_time = 1; Para la opción "global", un parámetro de configuración a nivel global. Se puede establecer en el archivo de configuración de MySQL al iniciar el servidor MySQL o instalar MySQL, o se puede cambiar en tiempo de ejecución con el comando SET GLOBAL. Los parámetros de configuración de nivel global son válidos para todas las conexiones MySQL.
Modificación permanente (todavía válida después de reiniciar la base de datos, no se recomienda la modificación permanente , solo se abre durante la optimización, rendimiento de consulta lento):
Modificar mi.cnf
[mysqld]
slow_query_log=ON # 开启慢查询日志的开关
slow_query_log_file=/var/lib/mysql/atguigu-slow.log #慢查询日志的目录和文件名信息
long_query_time=3 #设置慢查询的闽值为3秒,超出此设定值的SQL即被记录到慢查询日志
log_output=FILEAviso:
#测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并 执行下述语句 set global long_query_time = 1; #设置全局慢查询阈值1s show global variables like '%long_query_time%'; #全局1s set long_query_time=1; show variables like '%long_query_time%'; #当前会话10s
3.2 Ver el número de consultas lentas
Consulta cuántos registros de consulta lenta hay en el sistema actual
SHOW GLOBAL STATUS LIKE '%Slow_queries%';3.5 Herramienta de análisis de registro de consultas lentas: mysqldumpslow
`mysqldumpslow` es una herramienta de línea de comandos para analizar los registros de consultas lentas de MySQL. Al analizar el registro de consultas lentas, puede comprender los problemas de rendimiento de la base de datos y optimizarla.
Ver la información de ayuda de mysqldumpslow
mysqldumpslow --help
Los parámetros específicos del comando mysqldumpslow son los siguientes:
-a: no abstraer números en N, abstraer cadenas en S
-s: indica de qué manera ordenar:
- c: número de visitas
- l: tiempo de bloqueo
- r: registro de retorno
- t: tiempo de consulta
- al: tiempo promedio de bloqueo
- ar: el número promedio de registros devueltos
- at: tiempo medio de consulta (modo predeterminado)
- ac: promedio de consultas
-t: es devolver el número anterior de datos;
-g: seguido de un patrón de coincidencia regular, no distingue entre mayúsculas y minúsculas;
caso:
Ejemplo: ordene por tiempo de consulta, verifique las primeras cinco declaraciones SQL de consulta lenta, simplemente escriba así:
mysqldumpslow -s t -t 5 /var/lib/mysql/atguigu01-slow.log
Por ejemplo, suponga que desea ver las 10 consultas más lentas, puede usar el siguiente comando:
mysqldumpslow -s t -t 10 /var/log/mysql/mysql-slow.logEste comando significa ordenar por tiempo y mostrar las 10 consultas más lentas. /var/log/mysql/mysql-slow.log es la ruta del registro de consultas lentas de MySQL.
Además, si necesita filtrar consultas específicas, puede usar el parámetro `-g`, como:
mysqldumpslow -s t -t 10 -g "SELECT * FROM user" /var/log/mysql/mysql-slow.logEste comando se ordena por tiempo y muestra las 10 consultas más lentas, donde la palabra clave es "SELECCIONAR * DEL usuario".
En general, el comando `mysqldumpslow` proporciona una forma simple y rápida de ayudar a los desarrolladores y administradores de bases de datos a analizar problemas de consultas lentas de MySQL y optimizar el rendimiento de la base de datos.

Otros casos de uso comunes:
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
3.6 Desactivar el registro de consultas lentas
Hay dos formas de detener la función de registro de consultas lentas del servidor MySQL:
Vía 1: Vía permanente
[mysqld]
slow_query_log=OFF
Mysql cierra el registro de consultas lentas de forma predeterminada , o comenta o elimina el elemento slow_query_log
[mysqld]
#slow_query_log =OFF
Reinicie el servicio MySQL y ejecute la siguiente declaración para consultar la función de registro lento.
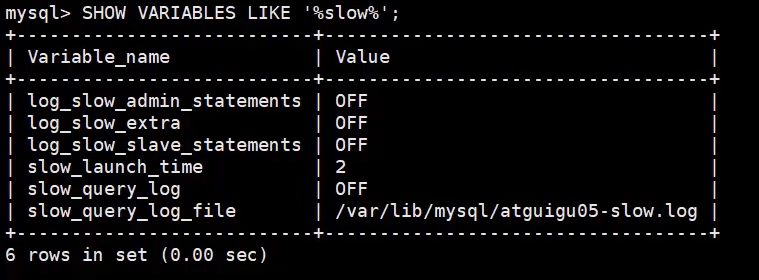
SHOW VARIABLES LIKE '%slow%'; #查询慢查询日志所在目录
SHOW VARIABLES LIKE '%long_query_time%'; #查询超时时长
Método 2: método temporal
Use la declaración SET para establecer.
Detenga la función de registro de consultas lentas de MySQL, la instrucción SQL específica es la siguiente.
SET GLOBAL slow_query_log=off;
golbal es válido globalmente.
Reinicie el servicio MySQL , use la instrucción SHOW para consultar la información de la función de registro de consultas lentas y descubra que el registro de consultas lentas se ha cerrado correctamente.
SHOW VARIABLES LIKE '%slow%'; #发现关闭成功 #慢查询阈值 SHOW VARIABLES LIKE '%long_query_time%'; #10s。前面改的时候没有加global,所以重启服务器后阈值恢复10s。
3.7 Eliminar registros de consultas lentas
eliminar manualmente
Utilice la declaración SHOW para mostrar información de registro de consultas lentas.La declaración SQL específica es la siguiente.
SHOW VARIABLES LIKE `slow_query_log%`;
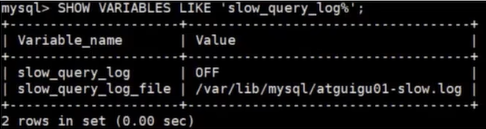
Se puede ver a partir de los resultados de la ejecución que el directorio de registro de consultas lentas tiene como valor predeterminado el directorio de datos de MySQL, y puede eliminar manualmente los archivos de registro de consultas lentas en este directorio.
eliminar automáticamente
Utilice el comando mysqladmin flush-logs para regenerar el archivo de registro de consultas.Después de la ejecución, el archivo de registro de consultas lentas se regenerará en el directorio de datos.
Regenerar archivos de registro de consultas lentas (eliminar los antiguos directamente)
mysqladmin -uroot -p flush-logs slow
pista
Los registros de consultas lentas se eliminan y reconstruyen mediante el comando mysqladmin flush-logs . Al usarlo, se debe tener en cuenta que una vez que se ejecuta este comando, el registro de consultas lentas solo existirá en el nuevo archivo de registro. Si se necesita el registro de consultas antiguo, se debe hacer una copia de seguridad con anticipación.
4. Localice declaraciones de consulta lentas y vea los costos de ejecución de SQL: muestre el perfil
show profile es una herramienta de consumo de recursos proporcionada por MySQL que se puede usar para analizar lo que ha hecho SQL en la sesión actual y ejecutarlo.Se puede usar para medir el ajuste de SQL. Está desactivado de forma predeterminada y guarda los resultados de las últimas 15 ejecuciones.
SHOW PROFILE es un comando de MySQL para ver información de perfiles para consultas ejecutadas por una sesión. Puede ayudar a los desarrolladores y administradores de bases de datos a analizar los cuellos de botella en la ejecución de consultas y descubrir qué partes deben optimizarse.
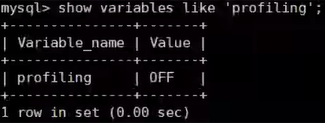
Compruebe si el perfil está habilitado en la configuración:
mysql > show variables like 'profiling';
- SHOW VARIABLES muestra las variables de configuración actuales del servidor MySQL, incluidas las variables de configuración global y las variables de configuración de sesión, y sus valores. SHOW VARIABLES se utiliza para ver la información detallada de los parámetros del sistema de configuración de MySQL y modificar los parámetros del sistema.
- SHOW STATUS muestra los parámetros de rendimiento del servidor, incluida la información de estado sobre conexiones, subprocesos, consultas, etc., y sus valores.
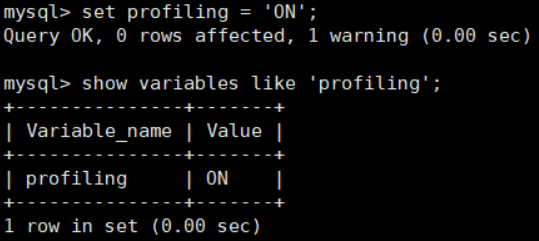
Abrir perfil de espectáculo:
mysql > set profiling = 'ON';
Luego ejecute la declaración de consulta relevante:
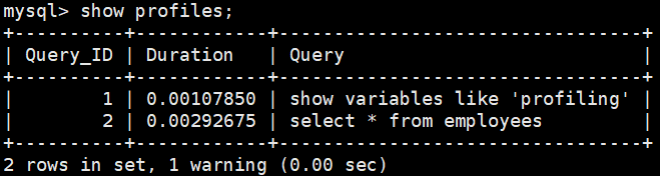
select * from employeesmostrar perfiles; consultar la duración de todas las declaraciones de consulta en la sesión actual
mysql > show profiles;
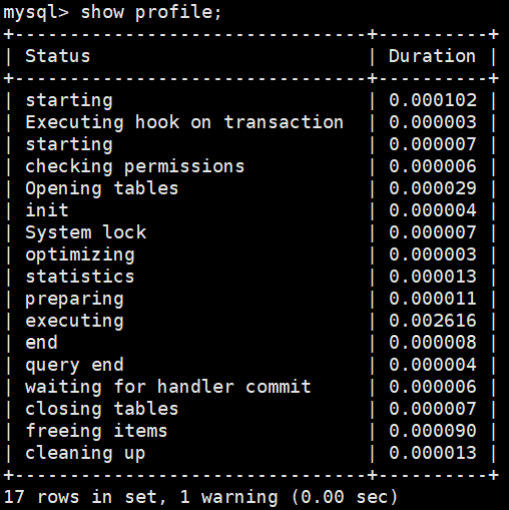
show profile; consulta el costo de ejecución de la última instrucción SQL en la sesión actual:
Puede ver que la sesión actual tiene un total de 2 consultas. Si queremos ver el costo de la consulta más reciente, podemos usar:
mysql > show profile;
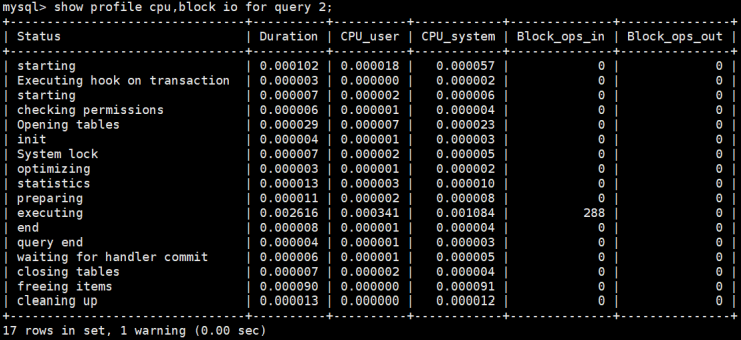
muestre la cpu del perfil para 2; consulte la información de la cpu del QueryID especificado:
Puede ver la sobrecarga del QueryID especificado, como mostrar el perfil para la consulta 2. En MOSTRAR PERFIL, puede ver la sobrecarga de diferentes partes, como cpu, block.io, etc.:
mysql> show profile cpu,block io for query 2
Parámetros de consulta comunes para mostrar perfil:
① TODO: muestra toda la información general.
② E/S DE BLOQUE: Muestra la sobrecarga de E/S del bloque.
③ CAMBIOS DE CONTEXTO: sobrecarga de cambio de contexto.
④ CPU: muestra información sobre la sobrecarga de la CPU.
⑤ IPC: Muestra el envío y la recepción de información general.
⑥ MEMORIA: Muestra información sobre la sobrecarga de la memoria.
⑦ FALLAS DE PÁGINA: muestra información de sobrecarga de fallas de página.
⑧ SOURCE: muestra información general relacionada con Source_function, Source_file, Source_line.
⑨ SWAPS: muestra información de sobrecarga de los tiempos de intercambio.
Preste atención al desarrollo diario:
① converting HEAP to MyISAM: el resultado de la consulta es demasiado grande, la memoria no es suficiente y los datos se mueven al disco.
② Creating tmp table: Crea una tabla temporal. Primero copie los datos en la tabla temporal y luego elimine la tabla temporal después de su uso.
③ Copying to tmp table on disk: Copie la tabla temporal en la memoria al disco, ¡cuidado!
④ locked。
Si cualquiera de los cuatro resultados anteriores aparece en el resultado del diagnóstico de perfil de la demostración, la instrucción SQL debe optimizarse.
Aviso:
Sin embargo, el comando SHOW PROFILE quedará obsoleto y podremos verlo desde la tabla de datos de generación de perfiles en information_schema .
5. Plan de ejecución: EXPLIQUE
5.1 Introducción
EXPLAIN de MySQL es una herramienta para analizar el rendimiento de consultas de sentencias SQL . Cuando ejecutamos una declaración SELECT en MySQL, EXPLAIN puede ayudarnos a ver cómo MySQL ejecuta la consulta, es decir, el plan de ejecución , incluidos los índices que se deben usar, las tablas que se deben seleccionar y cómo leer los datos . Al analizar el resultado de EXPLAIN, podemos optimizar mejor las declaraciones de consulta y mejorar la eficiencia de las consultas.
El uso de EXPLAIN es muy simple, simplemente agregue la palabra clave EXPLAIN delante de la instrucción SELECT , por ejemplo:
EXPLAIN SELECT * FROM my_table WHERE my_column = 'my_value';Después de ejecutar el comando anterior, MySQL devolverá una tabla del plan de ejecución de consultas, que contiene la información detallada de MySQL ejecutando esta consulta. Podemos comprender los cuellos de botella en el rendimiento de las consultas analizando las tablas del plan de ejecución de consultas y cómo optimizar las declaraciones de consulta para mejorar el rendimiento de las consultas.
Aviso:
-
EXPLAIN no considera varios Caché
-
EXPLAIN no puede mostrar el trabajo de optimización realizado por MySQL al ejecutar consultas
-
EXPLAIN no le informará sobre disparadores, procedimientos almacenados o cómo las funciones definidas por el usuario afectan las consultas
-
Algunas estadísticas son estimadas y no exactas.
Después de usar show profile para ubicar la consulta SQL lenta en el paso anterior , podemos usar la herramienta EXPLAIN o DESCRIBE para analizar la declaración de consulta . La sentencia DESCRIBE se utiliza de la misma forma que la sentencia EXPLAIN y los resultados del análisis son los mismos.
Existe un módulo optimizador en MySQL que se encarga de optimizar la sentencia SELECT , su principal función es brindarle al Query solicitado por el cliente el plan de ejecución óptimo (él considera el método óptimo de recuperación de datos) mediante el cálculo y análisis de la información estadística recolectada. en el sistema. , pero no necesariamente el DBA (administrador de la base de datos) piensa que es óptimo, esta parte es la que más tiempo consume).
Este plan de ejecución muestra cómo ejecutar la consulta a continuación , como el orden de las uniones de varias tablas, qué método de acceso se usa para cada tabla para ejecutar la consulta, etc. MySOL nos proporciona la declaración EXPLAIN para ayudarnos a ver el plan de ejecución específico de una determinada declaración de consulta. Si comprende los elementos de salida de la declaración EXPLAIN, puede mejorar el rendimiento de nuestra declaración de consulta de manera específica.
1. ¿Qué se puede hacer?
- orden de lectura de la tabla
- El tipo de operación de la operación de lectura de datos.
- Qué índices se pueden utilizar
- qué índices se utilizan realmente
- Referencias entre tablas
- Cuántas filas por tabla son consultadas por el optimizador
2. Introducción al sitio web oficial
MySQL :: MySQL 5.7 Manual de referencia :: 8.8.2 EXPLICAR formato de salida
MySQL :: Manual de referencia de MySQL 8.0 :: 8.8.2 EXPLICAR formato de salida
3. Estado de la versión
- Antes de MySQL 5.6.3, solo se puede usar EXPLAIN SELECT ; después de MYSQL 5.6.3, se puede usar EXPLAIN SELECT, UPDATE, DELETE
- En las versiones anteriores a la 5.7, debe usar el comando de particiones de explicación para mostrar las particiones; debe usar el comando extendido de explicación para mostrar las filtradas. Después de la versión 5.7, la explicación predeterminada muestra directamente la información en particiones y filtrada.
5.2 Sintaxis básica
La sintaxis de la instrucción EXPLAIN o DESCRIBE es la siguiente:
EXPLAIN SELECT select_options
#或者
DESCRIBE SELECT select_options
Si queremos ver el plan de ejecución de una determinada consulta, podemos agregar un EXPLAIN antes de la declaración de consulta específica, así:
EXPLAIN SELECT * FROM course_base;
El resultado de la información anterior es el llamado plan de ejecución. Con la ayuda de este plan de ejecución, necesitamos saber cómo mejorar nuestra declaración de consulta para que la consulta se ejecute de manera más eficiente. De hecho, además de la declaración de consulta que comienza con SELECT, el resto de las declaraciones DELETE, INSERT, REPLACE y UPDATE se pueden agregar con EXPLAIN para ver el plan de ejecución de estas declaraciones, pero generalmente estamos más interesados en la declaración SELECT

5.3 Introducción al Calendario de Ejecución
El rol de cada columna en el plan de ejecución
| identificación | A cada cláusula SELECT u operación de combinación se le asignará un número único. Cuanto menor sea el número, mayor será la prioridad. Las declaraciones con el mismo id se pueden considerar como un grupo. Si el id es NULL, significa una subconsulta independiente y la prioridad de la subconsulta es mayor que la de la consulta principal. |
| seleccione tipo | El tipo de consulta. Consulte a continuación para obtener más información. |
| mesa | Nombre de la tabla. Muestra a qué tabla pertenecen los datos de la fila actual. |
| particiones | Información de partición coincidente. NULL si la tabla no está particionada. |
| tipo | Tipo de acceso, la estrategia de optimización de consultas se ejecuta de acuerdo con métodos como la indexación y el escaneo de tablas completas. |
| posibles_claves | Índices que se pueden utilizar. Muestra qué índices MySQL puede usar para consultas. Si solo hay una clave_posible para la columna, generalmente significa que la consulta es eficiente. Si esta columna tiene varias claves_posibles y MySQL solo usa una de ellas, debe considerar si necesita agregar un índice conjunto en esta columna. |
| llave | El índice realmente utilizado. Si no se especifica explícitamente ninguna CLAVE, MySQL seleccionará automáticamente el índice óptimo de acuerdo con las condiciones de la consulta. |
| key_len | La longitud del índice realmente utilizado. Cuanto más corto sea el índice, más rápido será y, en general, cuanto más pequeño sea el campo del índice, mejor. |
| árbitro | Al usar la consulta equivalente de la columna de índice, la información del objeto para la coincidencia equivalente con la columna de índice |
| filas | Número estimado de registros que deben leerse. Cuanto menor sea el valor, mejor, lo que significa que cuanto menor sea el conjunto de resultados, más eficiente será la consulta. |
| filtrado | El porcentaje del número de registros restantes después de filtrar una tabla por la condición de búsqueda. Cuanto menor sea el valor, mejor, lo que indica que los datos se pueden devolver directamente a través del índice. |
| Extra | Alguna información adicional. Como USO DONDE, USO DE ÍNDICE, etc. |
- select_type: El tipo de consulta, con los siguientes valores:
- SIMPLE: una consulta SELECT simple que no usa subconsultas o UNION, y no contiene UNION ALL.
- PRIMARY: la consulta SELECT más externa.
- DERIVED: una declaración SELECT que aparece como una subconsulta en la cláusula FROM.
- UNION: La segunda o posterior consulta SELECT en una UNION.
- RESULTADO DE UNION: SELECCIONE la consulta para obtener datos del conjunto de resultados de UNION.
- SUBCONSULTA: una subconsulta que no aparece en la cláusula FROM, generalmente utilizada en la declaración SELECT.
- SUBCONSULTA DEPENDIENTE: La subconsulta depende del conjunto de resultados de la consulta externa.
- clave: El índice realmente utilizado. La palabra clave INDEX se usa al crear un índice en MySQL, pero en la tabla del plan de ejecución EXPLAIN se muestra KEY, porque MySQL permite especificar información estadística, como valor mínimo, valor máximo, etc., al crear un índice . Se considera como una clave de índice (clave de índice) en el índice , por lo que se muestra como CLAVE en la tabla del plan de ejecución.
- type: tipo de acceso, la estrategia de optimización de consultas se ejecuta de acuerdo con métodos como la indexación y el escaneo de tablas completas. Cuando el valor de la columna de tipo no es constante, debemos centrarnos en el ajuste del rendimiento de los índices y las memorias caché, optimizar las declaraciones SQL y solucionar correctamente los posibles problemas de diseño de datos.
- sistema: Solo se consultará una fila de datos. Este es el tipo de consulta más rápido y normalmente ocurre en consultas en tablas del sistema.
- const: se usa cuando se usa una clave principal o un índice único para encontrar una sola fila. En este momento, la consulta solo puede devolver una fila de datos. Este es un tipo de consulta muy rápido.
- eq_ref: se usa cuando la conexión usa un índice único para encontrar datos que cumplan con las condiciones de la consulta. Cada tipo de conexión necesita usar un índice único para el acceso, que es más rápido que la ref.
- ref: se usa cuando se buscan datos usando un índice no único, el resultado de la consulta es más grande que eq_ref, pero sigue siendo muy rápido.
- rango: se usa cuando se usa el rango de índice para buscar datos, y puede encontrar datos dentro de un cierto rango, como consultas cuando se usan operaciones BETWEEN o > o > <.
- índice: el análisis completo de la tabla se usa cuando no se aplica un buen índice, que es más rápido que el análisis completo de la tabla.
- all: escaneo de tabla, escanea toda la tabla para obtener los datos requeridos, la velocidad es la más lenta y debe evitarse tanto como sea posible.
- subconsulta_única: Al filtrar los resultados de la consulta o usar la operación IN, el optimizador elegirá usar este tipo de consulta.La subconsulta que usa el operador In depende del índice único de la consulta externa.
- index_subquery: se usa el operador In pero la subconsulta usa un índice normal en lugar de un índice único.
- range_check: se usa cuando se usan índices para verificar referencias de claves externas.
5.4 EXPLICAR cuatro formatos de salida
Aquí para hablar sobre el formato de salida de EXPLAIN. EXPLAIN puede generar cuatro formatos : 传统格式, JSON格式y TREE格式. 可视化输出Los usuarios pueden elegir el formato adecuado para ellos según sus necesidades.
1. Formato tradicional
El formato tradicional es sencillo y el resultado es una tabla que resume el plan de consulta.
mysql> EXPLAIN SELECT s1.key1, s2.key1 FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE s2.common_field IS NOT NULL;
2. formato JSON
La salida de la declaración introducida en el primer formato EXPLAINcarece de un atributo importante para medir la calidad de la ejecución: 成本. El formato JSON es el formato de salida entre los cuatro formatos 信息最详尽, que contiene la información del costo de ejecución.
- Formato JSON: agregue FORMAT=JSON entre la palabra EXPLAIN y la instrucción de consulta real.
EXPLAIN FORMAT=JSON SELECT ....
- id: el identificador único (id) correspondiente a la consulta
- select_type: tipo de consulta (tipo)
- table: la tabla a la que se accede (table_name)
- particiones: la partición a la que se accede (partition_name)
- type: el método de acceso utilizado (access_type)
- possible_keys: Posibles índices a utilizar (possible_keys)
- clave: el índice realmente utilizado (clave)
- key_len: longitud del índice (key_length)
- ref: la columna o constante (ref) para que coincida con el índice
- filas: número estimado de filas recuperadas (filas)
- filtrado: después de usar DÓNDE para filtrar, el porcentaje de las filas restantes (filtrado)
- Extra: otra información (extra)
3. formato ÁRBOL
El formato TREE es un nuevo formato introducido después de la versión 8.0.16. Describe 各个部分之间的关系principalmente 各部分的执行顺序cómo consultar en función de la consulta y .
mysql> EXPLAIN FORMAT=tree SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key2 WHERE
s1.common_field = 'a'\G
*************************** 1. row ***************************
EXPLAIN: -> Nested loop inner join (cost=1360.08 rows=990)
-> Filter: ((s1.common_field = 'a') and (s1.key1 is not null)) (cost=1013.75
rows=990)
-> Table scan on s1 (cost=1013.75 rows=9895)
-> Single-row index lookup on s2 using idx_key2 (key2=s1.key1), with index
condition: (cast(s1.key1 as double) = cast(s2.key2 as double)) (cost=0.25 rows=1)
1 row in set, 1 warning (0.00 sec)
4. Salida visual
Salida visual, puede visualizar el plan de ejecución de MySQL a través de MySQL Workbench. Al hacer clic en el icono de lupa de Workbench, se puede generar un plan de consulta visualizado.
3. formato ÁRBOL
El formato TREE es un nuevo formato introducido después de la versión 8.0.16. Describe 各个部分之间的关系principalmente 各部分的执行顺序cómo consultar en función de la consulta y .
mysql> EXPLAIN FORMAT=tree SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key2 WHERE
s1.common_field = 'a'\G
*************************** 1. row ***************************
EXPLAIN: -> Nested loop inner join (cost=1360.08 rows=990)
-> Filter: ((s1.common_field = 'a') and (s1.key1 is not null)) (cost=1013.75
rows=990)
-> Table scan on s1 (cost=1013.75 rows=9895)
-> Single-row index lookup on s2 using idx_key2 (key2=s1.key1), with index
condition: (cast(s1.key1 as double) = cast(s2.key2 as double)) (cost=0.25 rows=1)
1 row in set, 1 warning (0.00 sec)
4. Salida visual
Salida visual, puede visualizar el plan de ejecución de MySQL a través de MySQL Workbench. Al hacer clic en el icono de lupa de Workbench, se puede generar un plan de consulta visualizado.

La figura anterior muestra las tablas en orden de unión de izquierda a derecha. Los cuadros rojos indican "escaneo completo de la tabla", mientras que los cuadros verdes indican el uso de "búsqueda de índice". Para cada tabla, se muestran los índices utilizados. También tenga en cuenta que encima del cuadro de cada tabla hay una estimación de la cantidad de filas encontradas por cada acceso a la tabla y el costo de acceder a esa tabla.
5.5 Uso de MOSTRAR ADVERTENCIAS
En MySQL, SHOW WARNINGS es un comando que puede ver la información de advertencia generada en la declaración ejecutada más recientemente. Cuando MySQL ejecuta una declaración, si encuentra algo que no cumple con las expectativas, generará algunos mensajes de advertencia. Estos mensajes de advertencia pueden incluir errores no fatales, como ciertos tipos de datos que no se pueden convertir implícitamente o que algunos datos se truncan.
Cuando ejecutamos el comando SHOW WARNINGS, MySQL devolverá una lista detallada de información de advertencia, que incluye:
- Advertencia: el tipo de advertencia
- Nivel: El nivel de la advertencia, generalmente Nota, Advertencia o Error
- Código: el código de retorno de la advertencia.
- Mensaje: el contenido del mensaje de advertencia
Puede usar SELECCIONAR para ver la información de advertencia de la última operación:
SHOW WARNINGS;
También puede usar INSERTAR, ACTUALIZAR, ELIMINAR, ALTERAR TABLA y otros comandos para verificar la información de advertencia generada por una operación específica:
INSERT INTO my_table (name, age) VALUES ('John Doe', 150);
SHOW WARNINGS;
En el proceso de desarrollo y depuración, SHOW WARNINGS es muy útil para localizar y resolver algunos problemas, como truncamiento de datos, conversión de tipos y otros problemas.
6. Analizar el plan de ejecución del optimizador: rastrear
En MySQL, puede usar el comando trace para rastrear y analizar el plan de ejecución del optimizador. El comando trace puede mostrar las decisiones tomadas por el optimizador de MySQL al generar un plan de ejecución, incluidas las tablas que se procesan y los índices, algoritmos, etc. que se utilizan.
Para usar el comando trace, primero debe habilitar las dos variables del sistema general_log y performance_schema, y luego debe usar la declaración SET para establecer algunos parámetros, como trace-unique-check, trace-max-protocol, trace-protocol , rastrear-característica, rastrear-característica-verificar espera. Una vez completada la configuración, el formato del resultado de salida se puede seleccionar a través de la instrucción SET global trace_format='json'.
Aquí hay un ejemplo simple del uso del comando trace:
Primero, establezca los parámetros:
SET @trace_feature = 'qa';
SET @max_execution_time=50000;
SET @trace_level = '+ddl,+engine';
SET @trace_feature_check = 1;
SET @trace_unique_check = 1;
SET @trace_protocol = 1;
SET @trace_max_protocol = 6;
Luego, habilite general_log y performance_schema:
SET global general_log = on;
SET global performance_schema = on;
A continuación, ejecute la consulta y vea los resultados:
SELECT *
FROM my_table
WHERE my_column = 'some_value';
SHOW SESSION STATUS LIKE 'Last_Query_Plan';
Finalmente, cierre general_log y performance_schema:
SET global general_log = off;
SET global performance_schema = off;
En la salida del seguimiento, podemos ver detalles como el índice utilizado por el optimizador en el plan de ejecución, el algoritmo de ejecución y la cantidad de filas estimadas. Al analizar los resultados de seguimiento, podemos encontrar la causa raíz de algunos problemas de rendimiento y realizar los ajustes y optimizaciones correspondientes. Sin embargo, debe tenerse en cuenta que el comando de seguimiento puede generar un consumo de rendimiento adicional y una sobrecarga de E/S, y no debe habilitarse en un entorno de producción durante mucho tiempo.
7. Esquema view-sys de análisis de monitoreo de MySQL
7.1 Introducción
MySQL introdujo el esquema sys en la versión 8.0, que contiene vistas y funciones para monitorear y analizar el rendimiento del servidor MySQL. El esquema sys proporciona un conjunto de vistas y funciones fáciles de usar que pueden ayudarnos a comprender y analizar mejor el comportamiento y el rendimiento de las bases de datos MySQL.
Las siguientes son algunas vistas de monitoreo y análisis de uso común en el esquema del sistema:
- sys.statements_with_sorting: muestra qué declaraciones usan operaciones de clasificación, incluidas qué operaciones de clasificación se usan, la cantidad de clasificaciones por declaración y el consumo de recursos de las operaciones de clasificación.
- sys.statements_with_runtimes_in_95th_percentile: muestra la declaración con el tiempo de ejecución más largo.
- sys.io_global_by_file_by_bytes: muestra la cantidad de bytes de E/S de disco por archivo, que se pueden usar para detectar cuellos de botella de E/S.
- sys.memory_by_host_by_current_bytes: muestra el uso de memoria actual de cada cliente, que se puede usar para detectar fugas de memoria o uso elevado de memoria.
- sys.waits_global_by_latency: Muestra qué operaciones de espera toman más tiempo, lo que puede ayudarnos a encontrar el cuello de botella de los problemas de rendimiento.
- sys.processlist: muestra información sobre los subprocesos y procesos que se están ejecutando actualmente, incluidas las declaraciones ejecutadas, el ID de la consulta, el usuario, el host, el ID del subproceso y el estado.
En general, las vistas y funciones contenidas en el esquema sys nos brindan capacidades de monitoreo y análisis de rendimiento de MySQL más profundas, lo que puede ayudarnos a comprender mejor el comportamiento y los cuellos de botella de rendimiento de la base de datos MySQL.
- Relacionado con el host : comience con host_summary, que resume principalmente la información del retraso de E/S.
- Relacionado con innodb : comienza con innodb, resume la información del búfer de innodb y la transacción en espera de la información de bloqueo de innodb.
- Relacionado con E/S : comienza con io y resume la espera de E/S y el uso de E/S.
- Uso de la memoria : comienza con la memoria, muestra el uso de la memoria desde la perspectiva del host, hilo, evento, etc.
- Información de conexión y sesión : la lista de procesos y las vistas relacionadas con la sesión resumen la información relacionada con la sesión.
- Relacionado con la tabla : la vista que comienza con schema_table muestra la información estadística de la tabla.
- Información de índice : cuenta el uso de índices, incluidos los índices redundantes y los índices no utilizados.
- Relacionado con la declaración : comienza con la declaración y contiene información de la declaración para realizar exploraciones de tablas completas, usar tablas temporales, clasificar, etc.
- Relacionado con el usuario : la vista que comienza con el usuario recopila estadísticas sobre la E/S de archivos y la ejecución de declaraciones utilizadas por los usuarios.
- Información relacionada sobre eventos en espera : comienza con espera, que muestra el retraso de los eventos en espera.
7.2 Escenarios de uso
Situación del índice
#1. 查询冗余索引
select * from sys.schema_redundant_indexes;
#2. 查询未使用过的索引
select * from sys.schema_unused_indexes;
#3. 查询索引的使用情况
select index_name,rows_selected,rows_inserted,rows_updated,rows_deleted
from sys.schema_index_statistics where table_schema='dbname';
tabla relacionada
# 1. 查询表的访问量
select table_schema,table_name,sum(io_read_requests+io_write_requests) as io from
sys.schema_table_statistics group by table_schema,table_name order by io desc;
# 2. 查询占用bufferpool较多的表
select object_schema,object_name,allocated,data
from sys.innodb_buffer_stats_by_table order by allocated limit 10;
# 3. 查看表的全表扫描情况
select * from sys.statements_with_full_table_scans where db='dbname';
relacionado con la oración
#1. 监控SQL执行的频率
select db,exec_count,query from sys.statement_analysis
order by exec_count desc;
#2. 监控使用了排序的SQL
select db,exec_count,first_seen,last_seen,query
from sys.statements_with_sorting limit 1;
#3. 监控使用了临时表或者磁盘临时表的SQL
select db,exec_count,tmp_tables,tmp_disk_tables,query
from sys.statement_analysis where tmp_tables>0 or tmp_disk_tables >0
order by (tmp_tables+tmp_disk_tables) desc;
relacionado con IO
#1. 查看消耗磁盘IO的文件
select file,avg_read,avg_write,avg_read+avg_write as avg_io
from sys.io_global_by_file_by_bytes order by avg_read limit 10;
Relacionado con Innodb
#1. 行锁阻塞情况
select * from sys.innodb_lock_waits;