Este artículo registra principalmente alguna experiencia al ver la codificación de Kobayashi, y registrará algunos puntos de conocimiento y sentimientos que creo que son importantes.
Conceptos básicos de la red
osi protocolo de siete capas
tcp/ip protocolo de cuatro capas capa de aplicación capa de transporte capa de red capa de interfaz de red
escena real:
- URL de salida al proceso de visualización de la página web
- Análisis de URL (protocolo + servidor web + ruta de origen de datos)
- Generar mensaje de solicitud http
- Consulta de la dirección del servidor (dns) para obtener la dirección IP
Primero visite el dns local para verificar si hay un caché Si no, puede usar la consulta recursiva o la consulta iterativa para almacenar en caché los resultados finales de la consulta en el dns local - Llame a la pila de protocolos
La pila de protocolos incluye partes superior e inferior, la parte superior es tcp/udp y la parte inferior es ip para la transmisión de paquetes de red y la determinación de rutas - El envío de tcp agrega un protocolo de enlace de tres vías del encabezado tcp para establecer la segmentación de datos de conexión y otras operaciones para generar un mensaje tcp
- ip enviar agregar encabezado ip y usar la tabla de enrutamiento para determinar la tarjeta de red (ip de origen)
- Si el encabezado mac contiene la dirección mac del receptor en el caché arp, sáquelo y utilícelo; si no incluye arp para transmitir, obtenga la dirección mac del receptor
- Tarjeta de red, agregar encabezado y carácter de cuadro de inicio, verificar secuencia
- El interruptor (dirección mac), el enrutador busca la dirección del siguiente salto de acuerdo con la tabla de enrutamiento
- El servidor recibe la solicitud del cliente, la desempaqueta, encapsula la información requerida y luego la envía al cliente
Proceso de envío y recepción de paquetes de red de Linux
- Para recibir datos
, el marco recibido en la tarjeta de red se escribirá en la memoria especificada (búfer de anillo) en forma de DMA. Luego inicie una interrupción a la CPU para notificar a la CPU que han llegado datos. Cuando la CPU recibe una solicitud de interrupción, llamará al controlador de interrupción registrado por el controlador de red. La función de procesamiento de interrupciones de la tarjeta de red no hace demasiado trabajo, envía una solicitud de interrupción suave y luego libera la CPU lo antes posible. Cuando ksoftirqd detecta que llega una solicitud de interrupción suave, llama a sondeo para comenzar a sondear y recibir paquetes (sk_buff), y después de recibirlo, se entrega a las pilas de protocolos en todos los niveles para su procesamiento. Para los paquetes UDP, se colocarán en la cola de recepción del socket del usuario.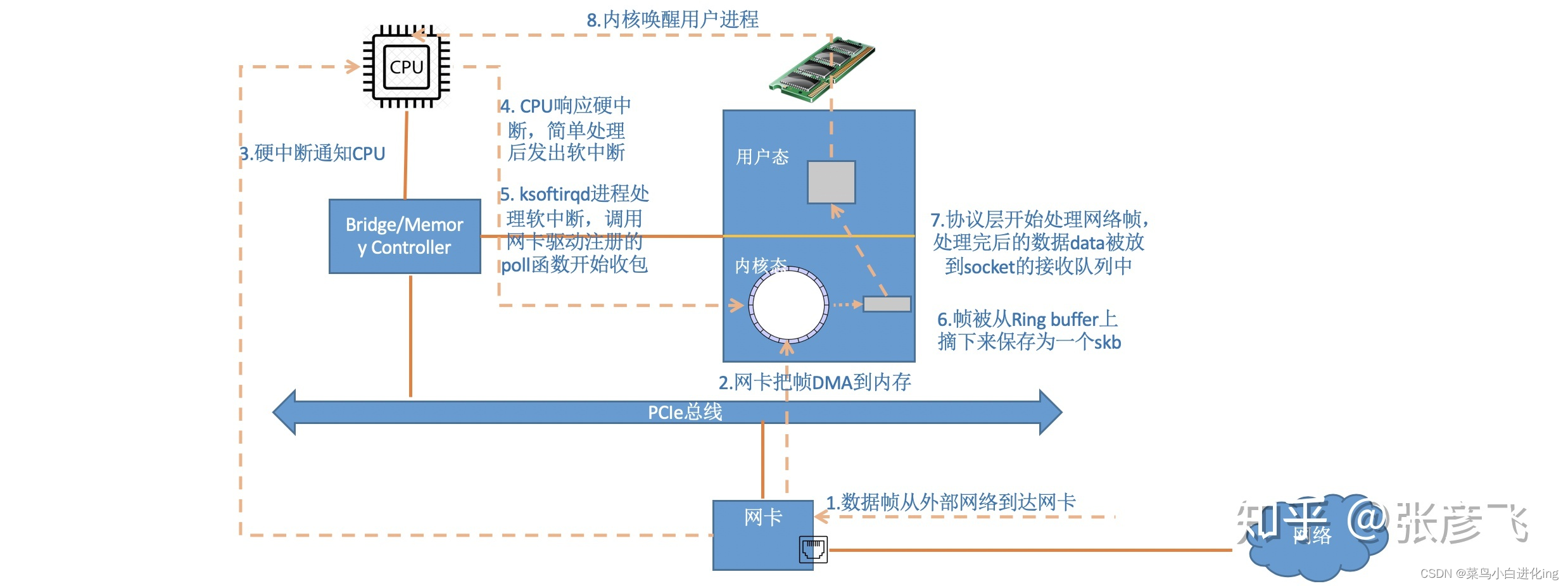
- Enviar datos
Los datos se copian al kernel sk_buff, y tcp copiará una copia para la retransmisión de tiempo de espera para agregar el
encabezado, la interrupción suave notifica al controlador de la tarjeta de red y sk_buff se coloca en el búfer de anillo
http
http es un protocolo bidireccional
código de estado
Los códigos de estado 1xx pertenecen a la información de solicitud, que es un estado intermedio en el procesamiento del protocolo y rara vez se usan en la práctica.
Los códigos de estado 2xx indican que el servidor ha procesado con éxito la solicitud del cliente, que es el estado que más deseamos ver.
-
"200 OK" es el código de estado de éxito más común, lo que indica que todo está bien. Si se trata de una solicitud que no es HEAD, el encabezado de respuesta devuelto por el servidor tendrá datos del cuerpo.
-
"204 Sin contenido" también es un código de estado de éxito común, que es básicamente lo mismo que 200 OK, pero el encabezado de respuesta no tiene datos de cuerpo.
-
"206 Contenido parcial" se aplica a la descarga fragmentada HTTP o a la carga reanudable, lo que indica que los datos del cuerpo devueltos por la respuesta no son todos los recursos, sino una parte de ellos, que también es el estado del procesamiento exitoso del servidor.
El código de estado 3xx indica que el recurso solicitado por el cliente ha cambiado, y el cliente necesita reenviar la solicitud para obtener el recurso con una nueva URL, es decir, redirigir.
-
"301 Movido permanentemente" indica una redirección permanente, lo que indica que el recurso solicitado ya no existe y se debe acceder nuevamente con una nueva URL.
-
"302 Encontrado" indica una redirección temporal, lo que indica que el recurso solicitado todavía está allí, pero otra URL necesita acceder a él temporalmente.
Tanto el 301 como el 302 usan el campo Ubicación en el encabezado de la respuesta para indicar la URL que se va a redirigir, y el navegador redirigirá automáticamente a la nueva URL.
-
"304 no modificado" no tiene el significado de salto, lo que indica que el recurso no se ha modificado, redirigiendo el archivo de búfer existente, también conocido como redirección de caché, es decir, diciéndole al cliente que continúe usando el recurso de caché para el control de caché .
El código de estado 4xx significa que el mensaje enviado por el cliente es incorrecto y el servidor no puede procesarlo, que es el significado del código de error.
-
"400 Bad Request" indica que hay un error en el mensaje solicitado por el cliente, pero es solo un error general.
-
"403 Prohibido" significa que el servidor prohíbe el acceso a los recursos, no que la solicitud del cliente sea incorrecta.
-
"404 Not Found" significa que el recurso solicitado no existe o no se encuentra en el servidor, por lo que no se puede proporcionar al cliente.
El código de estado 5xx indica que el mensaje de solicitud del cliente es correcto, pero ocurrió un error interno durante el procesamiento del servidor, que pertenece al código de error del lado del servidor.
-
"Error interno del servidor 500" y los tipos 400 son códigos de error generales y comunes. No sabemos qué error ocurrió en el servidor.
-
"501 No implementado" significa que la función solicitada por el cliente aún no es compatible, similar a "apertura pronto, espérelo con ansias".
-
"502 Bad Gateway" suele ser un código de error devuelto por el servidor como puerta de enlace o proxy, lo que indica que el servidor en sí funciona normalmente y que se produjo un error al acceder al servidor back-end.
-
"503 Servicio no disponible" significa que el servidor está actualmente ocupado y temporalmente no puede responder al cliente, similar a "el servicio de red está ocupado, inténtelo de nuevo más tarde".
campos comunes
- anfitrión
- contentlength (para resolver el problema de los paquetes pegados de tcp, longitud del cuerpo)
- mantener vivo (http 1.1)
- GET POST
Si observa la semántica definida por la especificación RFC:
el método GET es seguro e idempotente, porque es una operación de "solo lectura", no importa cuántas veces se realice la operación, los datos en el servidor están seguros , y cada vez que el resultado es Son iguales. Por lo tanto, puede almacenar en caché los datos de la solicitud GET. Este caché se puede hacer en el propio navegador (para evitar que el navegador envíe solicitudes por completo), o en el proxy (como nginx), y la solicitud GET en el navegador puede guardarse como marcador.
Debido a que POST es una operación de "agregar o enviar datos", modificará los recursos en el servidor, por lo que no es seguro, y enviar datos varias veces creará múltiples recursos, por lo que no es idempotente. Por lo tanto, los navegadores generalmente no almacenan en caché las solicitudes POST, ni pueden guardarlas como marcadores.
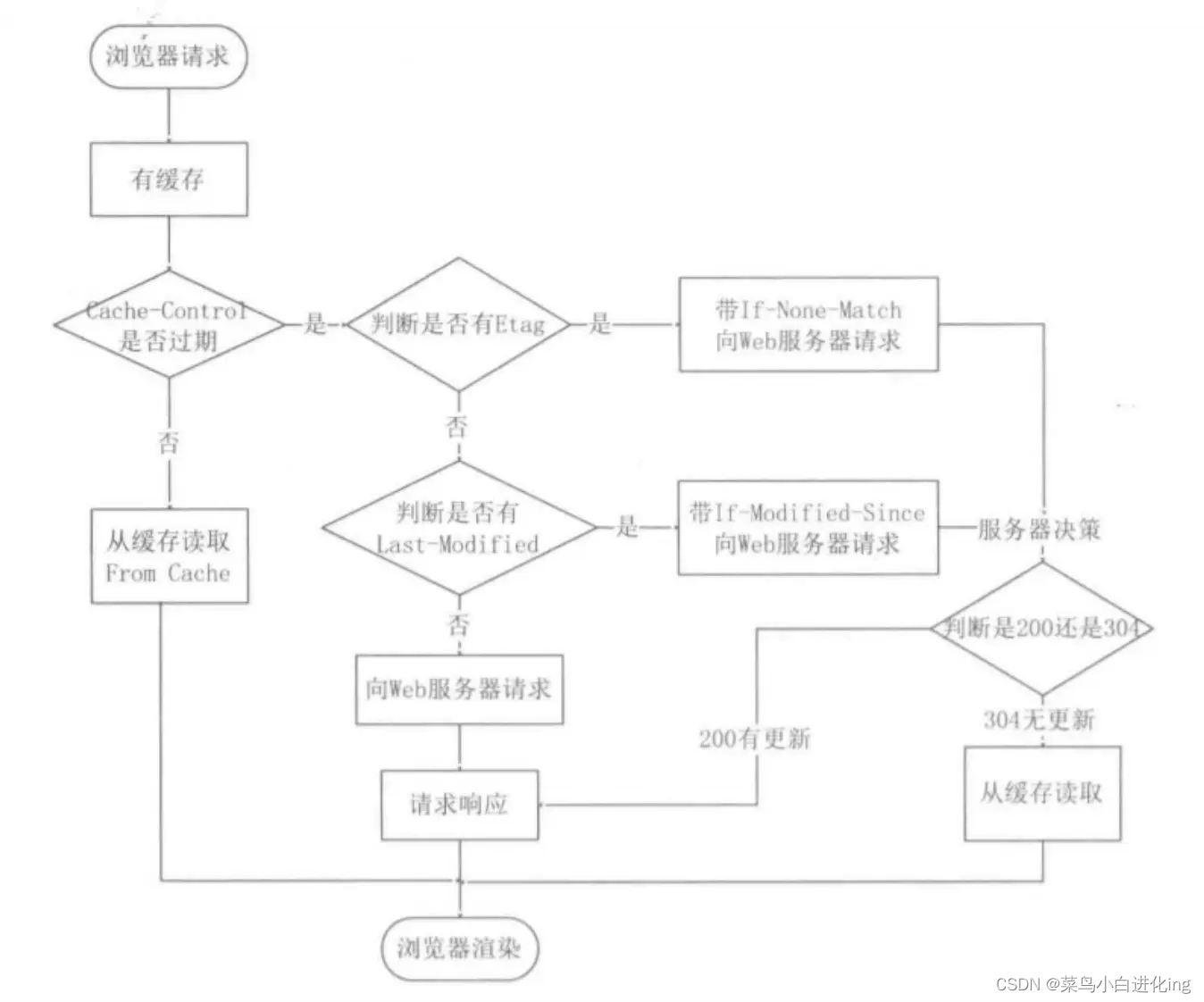
cache
- Almacenamiento en caché obligatorio Siempre que la caché no haya caducado, utilice directamente el código de estado de caché del navegador 200.
Utilice el control de caché y caduca para controlar el período de validez de la caché. La prioridad del control de caché es mayor que la de caduca. - El campo de código de estado de caché de negociación 304 si ninguno coincide y si se modificó desde
la última modificación indica la hora de la última modificación
Goose Soup identifica de forma única el recurso correspondiente (prioridad más alta)
protocolo http
http1.1
Ventajas: header+body es fácil de entender, simple y fácil de expandir, ampliamente utilizado y multiplataforma
Desventajas: sin estado (puede agregar información de caché de cookies), transmisión de código claro, inseguro (solución https)
Características: conexión larga, reduce la sobrecarga causada por la conexión tcp al establecimiento repetido, reduce la carga, desconecta automáticamente si no hay conexión durante mucho tiempo
Cuello de botella de rendimiento:
- La misma información de encabezado es redundante y derrochadora
- Causas del modo de solicitud-respuesta de bloqueo de cabeza de línea
- servidor pasivo
mejoramiento:
- Fusionar solicitudes: reemplace las solicitudes de múltiples recursos pequeños con una solicitud de recursos grande
- compresión de datos
http2.0
- Compresión de encabezado: el servidor y el cliente del algoritmo hpack mantienen una tabla de información al mismo tiempo, envían un número de índice para mejorar la velocidad
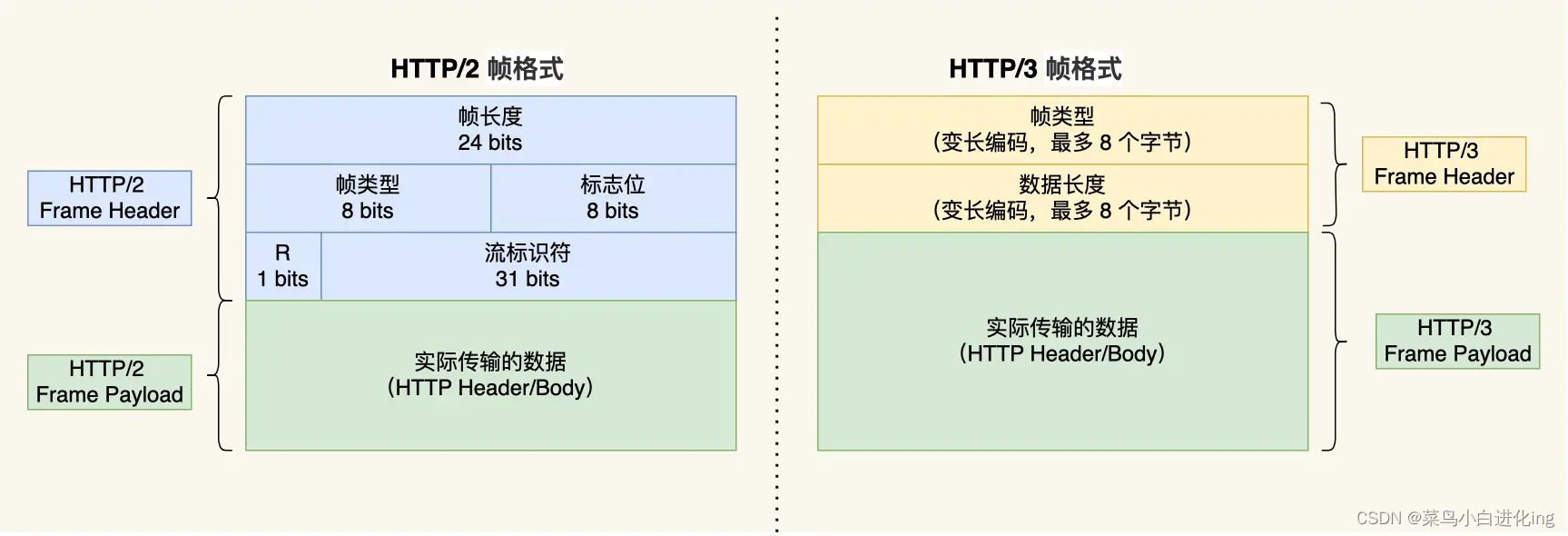
- Formato binario: transmisión de tramas, dividida en trama de información de cabecera y trama de datos
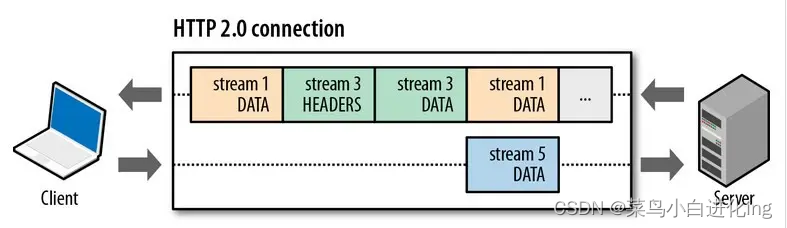
- Transmisión concurrente: múltiples flujos se multiplexan en una conexión tcp
, y diferentes solicitudes HTTP se distinguen por ID de flujo únicos. El extremo receptor puede ensamblar ordenadamente mensajes HTTP a través de ID de flujo. Los marcos de diferentes flujos se pueden enviar fuera de orden, por lo que diferentes flujos pueden ser concurrente, es decir, HTTP/2 puede enviar solicitudes y respuestas en paralelo e intercaladas.
- Server Push
Tanto el cliente como el servidor pueden crear un flujo, y la ID del flujo también es diferente. El flujo creado por el cliente debe ser un número impar, mientras que el flujo creado por el servidor debe ser un número par.
Desventajas:
El bloqueo de cabeza de línea realmente no se puede resolver debido al problema del protocolo tcp. Una vez que se produce la pérdida de paquetes, se activará el mecanismo de retransmisión TCP, por lo que todas las solicitudes HTTP en una conexión TCP deben esperar a que se retransmita el paquete perdido.
http3.0 (rápido)
- Sin bloqueo de cabeza de cola
QUIC tiene su propio conjunto de mecanismos para garantizar la confiabilidad de la transmisión. Cuando se produce una pérdida de paquetes en un determinado flujo, solo se bloqueará este flujo y los demás flujos no se verán afectados, por lo que no hay problema de bloqueo de cabecera de línea. - Establecimiento de conexión más rápido
El protocolo QUIC de HTTP/3 no está superpuesto con TLS, pero QUIC contiene TLS en su interior, y llevará el "registro" en TLS en su propio marco, además QUIC usa TLS/1.3, por lo que solo se necesita 1 RTT para completar el establecimiento de la conexión y el acuerdo clave "simultáneamente" - Migración de conexión
tcp, cuando la red del dispositivo móvil se cambia de 4G a WIFI, significa que la dirección IP ha cambiado, luego se debe desconectar la conexión y luego restablecerla. El protocolo QUIC usa el ID de conexión para marcar los dos puntos finales de la comunicación. El cliente y el servidor pueden elegir un conjunto de ID para marcarse a sí mismos. Por lo tanto, incluso si la red del dispositivo móvil cambia, resultará en un cambio en el Dirección IP, siempre que la información de contexto (como ID de conexión, clave TLS, etc.), la conexión original se puede reutilizar "sin problemas", eliminando el costo de reconexión, sin la menor sensación de tartamudeo y logrando la función de migración de conexión.
protocolo https
En comparación con http, se agrega el protocolo de seguridad ssl/tsl y el protocolo de número de puerto (443) requiere una garantía de terceros (CA)
- El cifrado híbrido
utiliza cifrado asimétrico para intercambiar claves y utiliza claves de intercambio para transmitir información de forma simétrica. - Algoritmos de resumen y firmas digitales
Compute hashes para garantizar que el contenido de la transferencia no se haya alterado - Proceso de establecimiento de autenticación de terceros
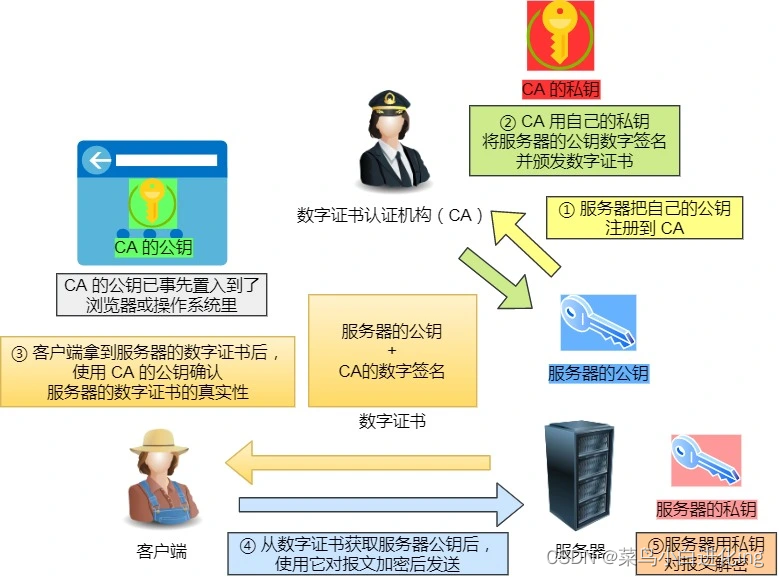
(rsa) de certificado digital: - Enviar versión de protocolo, nonce y conjunto de cifrado
- Confirmar versión, enviar certificado digital más número aleatorio
- Use la clave pública en el navegador para obtener un número aleatorio y cifre otro número aleatorio para enviar
El protocolo HTTPS en sí mismo no tiene lagunas hasta el momento. Incluso si realiza con éxito un ataque de intermediario, esencialmente se aprovecha de las lagunas del cliente (el usuario hace clic para continuar accediendo o se importan maliciosamente certificados raíz falsificados) , y no es que HTTPS no sea lo suficientemente seguro.
Evite ser atrapado por el intermediario a través de la autenticación bidireccional HTTPS
rsa da ecdhe
rsa: Debido a que el cliente envía el número aleatorio (una de las condiciones para generar una clave de cifrado simétrica) al servidor mediante el cifrado de clave pública, después de recibirlo, el servidor lo descifra con la clave privada para obtener el número aleatorio. Entonces, una vez que se filtra la clave privada del servidor, se descifrarán todos los textos cifrados de comunicación TLS interceptados por terceros en el pasado.
La diferencia entre el proceso de protocolo de enlace RSA y ECDHE:
- El algoritmo de acuerdo de clave RSA "no admite" secreto hacia adelante, y el algoritmo de acuerdo de clave ECDHE "admite" secreto hacia adelante;
- Se utiliza el algoritmo de acuerdo de clave RSA, y los datos de la aplicación solo se pueden transmitir después de que TLS complete el protocolo de enlace de cuatro vías.Para el algoritmo ECDHE, el cliente puede enviar datos HTTP cifrados por adelantado sin esperar el último protocolo de enlace TLS del servidor, guardando un El tiempo de ida y vuelta del mensaje (no entiendo);
- Usando ECDHE, en el segundo protocolo de enlace TLS, habrá un mensaje de "Intercambio de clave del servidor" enviado por el servidor, pero no hay tal mensaje en el proceso de protocolo de enlace RSA;
rpc
RPC (llamada a procedimiento remoto), también conocida como llamada a procedimiento remoto. No es un protocolo específico en sí mismo, sino un método de llamada.
descubrimiento de servicios
En HTTP, si conoce el nombre de dominio del servicio, puede resolverlo a través del servicio DNS para obtener la dirección IP detrás de él, que es el puerto 80 de forma predeterminada.
Para RPC, suele haber un servicio intermedio dedicado para guardar el nombre del servicio y la información de IP, como Consul o Etcd, o incluso Redis. Para acceder a un servicio, diríjase a estos servicios intermedios para obtener información de IP y puerto. Dado que DNS también es un tipo de descubrimiento de servicios, también hay componentes para el descubrimiento de servicios basados en DNS, como CoreDNS.
forma de conexión subyacente
Tomando como ejemplo el protocolo HTTP/1.1 convencional, mantendrá la conexión (Keep Alive) después de que la conexión TCP subyacente se establezca de manera predeterminada, y las solicitudes y respuestas subsiguientes reutilizarán esta conexión.
El protocolo RPC, similar a HTTP, también establece enlaces largos TCP para la interacción de datos, pero la diferencia es que el protocolo RPC generalmente crea un grupo de conexiones para la multiplexación.
lo que se transmite
Mensaje basado en transmisión TCP, encabezado del mensaje + cuerpo del mensaje.
RPC, con un mayor grado de personalización, puede usar Protobuf más pequeño u otros protocolos de serialización para guardar datos de estructura y no necesita considerar varios comportamientos del navegador como HTTP, como la redirección 302 y los saltos. Por lo tanto, el rendimiento será mejor, lo que también es la principal razón para abandonar HTTP en los microservicios internos de la empresa y optar por utilizar RPC.
http2.0 en realidad puede funcionar mejor, pero debido a razones históricas.
WebSocket
- El protocolo TCP en sí mismo es dúplex completo, pero nuestro HTTP/1.1 más utilizado, aunque es un protocolo basado en TCP, es dúplex medio. No es muy amigable para la mayoría de los escenarios que requieren que el servidor envíe datos activamente al cliente, por lo que debemos usar el protocolo WebSocket que admite dúplex completo.
- En HTTP/1.1, mientras el cliente no pregunta, el servidor no responde. En función de esta característica, para escenarios simples como la página de inicio de sesión, puede usar un sondeo regular o un sondeo largo para lograr el efecto de empuje del servidor (cometa).
- Para escenarios complejos que requieren una interacción frecuente entre el cliente y el servidor, como los juegos web, se puede considerar el protocolo WebSocket.