Tabla de contenido
- Descripción general de la capa de aplicación
- 1. Modelo de aplicación de red
- 1.1 Modelo C/S (cliente/servidor, modelo cliente/servidor)
- 1.2 Modelo P2P (peer to peer) y distribución de archivos P2P
- 1.3 Híbridos: arquitecturas cliente-servidor y punto a punto
- 2. Relacionado con la aplicación
- 2.1 Web y HTTP
- 2.2 Protocolo de transferencia de archivos FTP
- 2.3 Correo electrónico Correo electrónico
-
- 2.3.1 Descripción general del correo electrónico
- 2.3.2 Estructura del sistema de correo electrónico
- 2.3.3 Formato de mensaje de correo electrónico
- 2.3.4 Protocolo simple de transferencia de correo SMTP
- 2.3.5 La tercera versión del protocolo de oficina postal POP3
- 2.3.6 Extensión multimedia MIME
- 2.3.7 Protocolo de acceso al correo de Internet IMAP
- 2.3.8 Correo electrónico basado en web
- 2.4 DNS (Sistema de nombres de dominio)
- 2.5 CDN
Descripción general de la capa de aplicación

- Características
- Sin software de capa de aplicación en el núcleo de la red
- El núcleo de la red no tiene funcionalidad de capa de aplicación
- Las aplicaciones de red solo existen en el sistema final, desarrollo e implementación rápidos de aplicaciones de red.
1. Comunicación del proceso
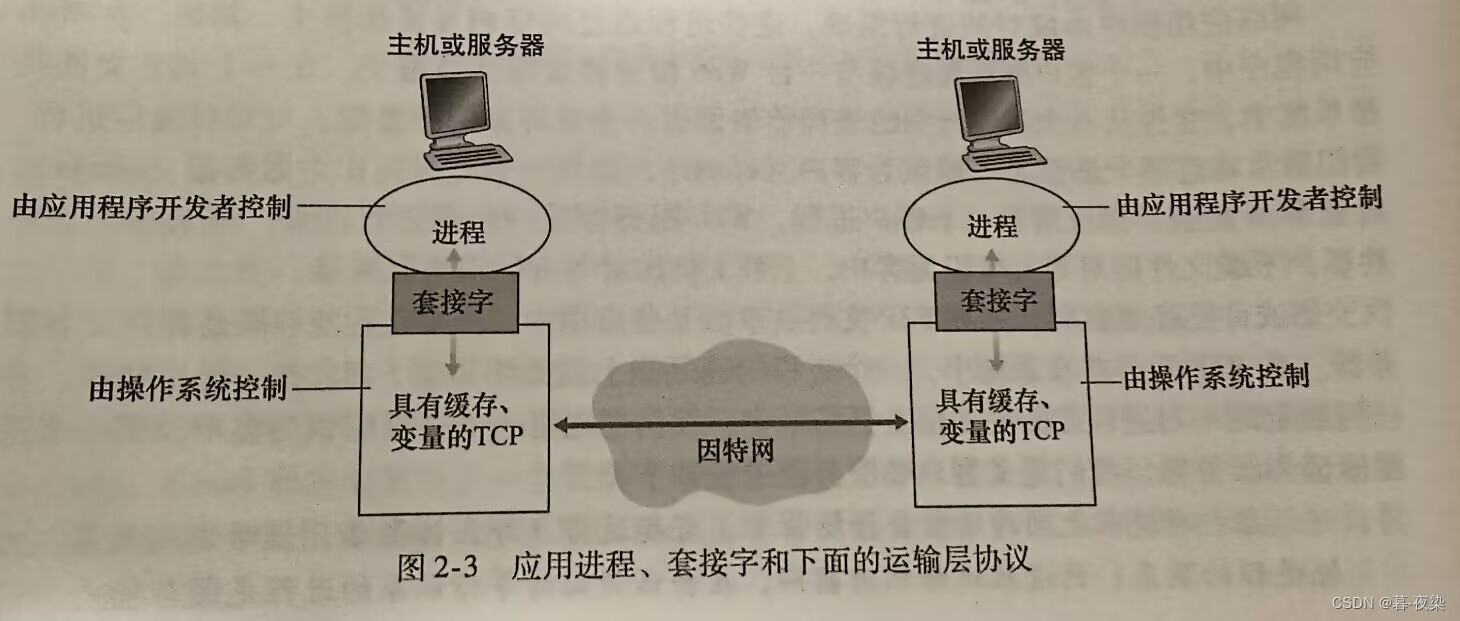
En una red informática, se comunican procesos , no programas . Los procesos en diferentes sistemas finales se intercambian a través de una red informática.mensajeY comunicarse entre sí.
- Interfaz de proceso y red informática.
-
El proceso se llamaenchufeLa interfaz del software envía y recibe mensajes de la red. El socket equivale a la "puerta" de la "casa" del proceso. Los sockets también pueden denominarse Interfaz de programación de aplicaciones (API, Interfaz de programación de aplicaciones) .
-
El desarrollador de la aplicación tiene control sobre todo lo que se encuentra en el lado de la capa de aplicación del socket , pero el control sobre la capa de transporte se limita a:
- Seleccionar protocolo de capa de transporte
- Quizás se puedan establecer algunos parámetros de la capa de transporte, como el almacenamiento en búfer máximo y la longitud máxima del segmento.
-
- direccionamiento del proceso
- Para identificar el proceso de recepción, se define: ① La dirección del host; ② El identificador del proceso de recepción designado en el host de destino.
- Un host se identifica de forma única por su dirección IP (una cantidad de 32 bits)
- El número de puerto se puede utilizar para especificar el proceso de recepción (socket de recepción) del host de destino.
Puede encontrar una lista de números de puertos conocidos para todos los protocolos estándar de Internet en: http://www.iana.org.
- Para identificar el proceso de recepción, se define: ① La dirección del host; ② El identificador del proceso de recepción designado en el host de destino.
2. Servicios de transporte para uso de aplicaciones
- Los paquetes de transferencia de datos confiables
pueden perderse en las redes informáticas debido a un desbordamiento del buffer del enrutador o corrupción de bits .- Durante el proceso de transmisión de datos de algunas aplicaciones, una pequeña parte de la pérdida de datos no tendrá un gran impacto en los archivos, como en las aplicaciones multimedia (audio/vídeo, etc., las pequeñas interferencias no tendrán un gran impacto).
- Pero para algunas aplicaciones como el correo electrónico, la transferencia de archivos, el acceso remoto a host, la transferencia de documentos web y las aplicaciones financieras, la pérdida de datos tendrá consecuencias catastróficas, por lo que es necesario proporcionarTransmisión de datos confiable para garantizar la integridad de los datos。
- Rendimiento
- Las aplicaciones sensibles al ancho de banda
tienen requisitos específicos de rendimiento , y si el rendimiento es menor que el rendimiento requerido, los datos se codificarán a una velocidad más baja o se entregarán (el rendimiento es demasiado bajo para ser de poca o poca importancia). es inútil). Tales como: Aplicaciones de telefonía por Internet. - Las aplicaciones elásticas
utilizan el rendimiento disponible en función del ancho de banda disponible (más siempre es mejor, por supuesto). Tales como: correo electrónico, transferencia de archivos, transferencia web.
- Las aplicaciones sensibles al ancho de banda
- seguridad
- El protocolo de transporte cifra los datos antes de enviarlos al host y los descifra antes de entregarlos al proceso de recepción. (Proporciona confidencialidad entre el envío y la recepción)
- Los protocolos de transporte también proporcionan integridad de datos y autenticación de puntos finales.
3. Servicios de transporte proporcionados por Internet
- servicio TCP

-
Características
-
servicios orientados a la conexión(Después del protocolo de enlace de tres vías, se establece una conexión TCP para transmitir datos)
-
Servicio de transferencia de datos confiable
- Entrega de datos sin errores y en el orden correcto
- Sin pérdida de bytes ni redundancia
-
conexión dúplex completa
-
La conexión debe ser desmantelada después de enviar el mensaje.
-
-
Mecanismo de control de congestión TCP
- Cuando se produce una congestión en la red, TCP inhibirá el proceso de envío .
- El control de congestión también intenta limitar cada conexión TCP para queDistribución justa del ancho de banda de la red。
-
No necesariamente aporta beneficios al proceso de comunicación, pero sí a Internet en su conjunto.
-
Servicio UDP
Un protocolo de transporte liviano que no proporciona servicios innecesarios y solo proporciona servicios mínimos.- Características:
- sin conexión(por lo que no hay proceso de apretón de manos)
- transferencia de datos no confiable
- Se pueden perder datos
- Los datos pueden llegar desordenados
- Sin mecanismo de control de congestión
- El remitente puede seleccionar cualquier velocidad para inyectar datos en la capa de red ( el rendimiento real puede ser menor que esta velocidad debido al ancho de banda limitado o a la congestión en el enlace intermedio ) .
- Características:
-
otro

1. Modelo de aplicación de red
1.1 Modelo C/S (cliente/servidor, modelo cliente/servidor)
definición
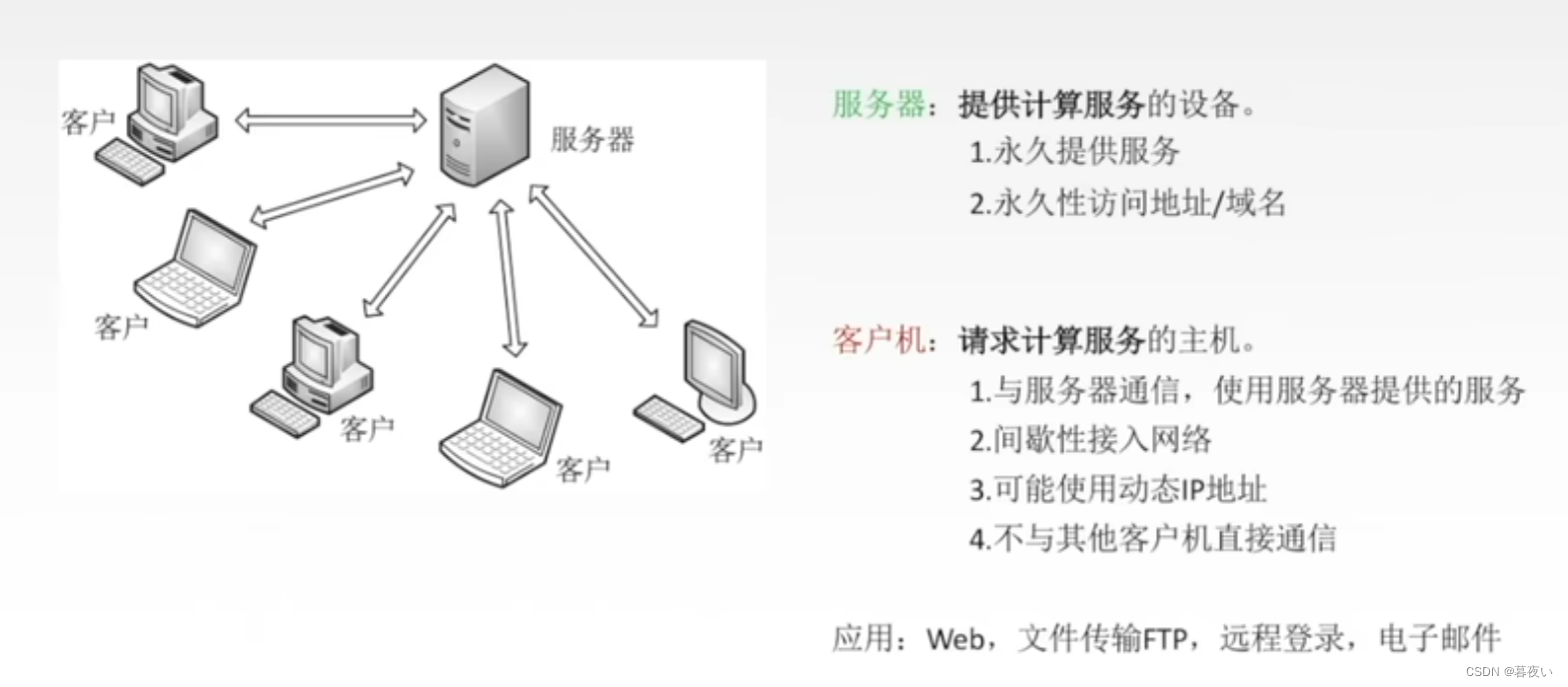
El modelo C/S se refiere al modelo Cliente/Servidor, que es una arquitectura de aplicación de red común. En este modelo hay unPrograma cliente (Cliente) y un programa servidor (Servidor), cliente y servidorComunicarse a través de protocolos específicos。
principio de funcionamiento
En este modelo, el programa cliente envía una solicitud al servidor, el servidor recibe la solicitud y devuelve una respuesta, y el cliente realiza las operaciones correspondientes en función de la respuesta. El modelo C/S se puede implementar a través de la red, de modo que el cliente y el servidor puedan ubicarse en diferentes computadoras .从而实现分布式计算和数据存储
Características
-
cliente:
- Comunicarse activamente con el servidor.
- Conexión intermitente a Internet.
- Posiblemente una dirección IP dinámica
- No se comunica directamente con otros clientes.
-
servidor:
- Necesidad de seguir funcionando para brindar servicios.
- Dirección IP fija y número de puerto conocido (convención)
- expansión del centro de datos
Ventaja
- Interactividad : el cliente puede interactuar con el servidor en tiempo real para lograr el intercambio de datos en tiempo real.
- Escalabilidad : el modelo C/S tiene buena escalabilidad y se pueden agregar clientes o servidores según sea necesario para lograr la escalabilidad del sistema.
- Seguridad : Porque entre el cliente y el servidor
通信是加密的, la transmisión de datos es relativamente segura.
solicitud
El modelo C/S se usa ampliamente, como la banca en línea, las compras en línea, las redes sociales, etc., todos requieren el uso de este modelo.
En el modelo C/S, los clientes normalmente necesitan instalar aplicaciones independientes, mientras que el servidor es un lugar que proporciona servicios públicos y al que pueden acceder varios clientes al mismo tiempo.
Por ejemplo, juegos online, banca online, comercio electrónico, etc.
1.2 Modelo P2P (peer to peer) y distribución de archivos P2P
2.1 modelo P2P
definición
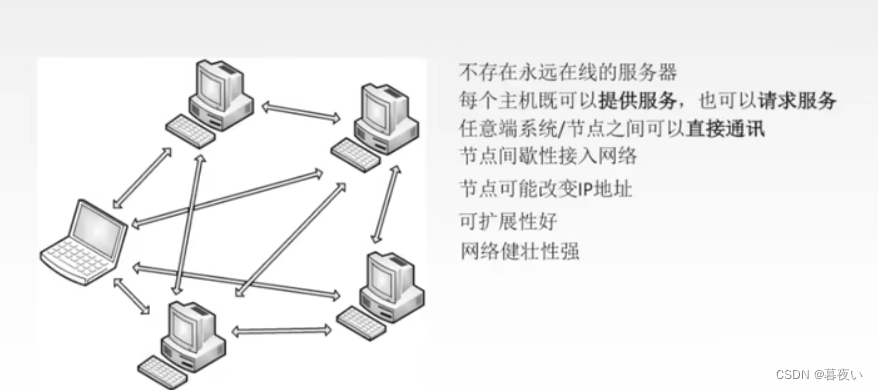
El modelo P2P se refiere al modelo peer-to-peer (modelo Peer-to-Peer). Este es un patrón de arquitectura de red,Cada nodo actúa como cliente y servidor y puede solicitar y proporcionar servicios a otros nodos.. para que cada nodo de la redPueden comunicarse directamente entre sí., sin necesidad de retransmisión a través de un servidor central .
Características
- Dirección IP modificable: los nodos pueden tener direcciones IP dinámicas
可扩展性好: El modelo P2P se puede ampliar infinitamente y no está limitado por la cantidad de servidores , lo que hace posible la computación distribuida y el intercambio de archivos a gran escala.网络健壮性强:La red no se paraliza fácilmente, cada nodo en la red P2P puede proporcionar datos, por lo que cuando algunos hosts o nodos fallan o una gran cantidad de hosts ingresan a la red, los hosts aún pueden solicitar y brindar servicios normalmente (los recursos son suficientes y el ancho de banda no está limitado). la funcionalidad de toda la red.- (Casi) ningún "servidor" se ejecuta todo el tiempo
-
Es posible la comunicación entre cualquier sistema final.
-
Autoescalabilidad: los nuevos nodos pares aportan nuevas capacidades de servicio y, por supuesto, nuevas solicitudes de servicio.
-
Los hosts participantes están conectados de forma intermitente y pueden cambiar las direcciones IP
-
El modelo P2P también tiene desventajas :
- 1. Eficiencia de búsqueda: en el modelo P2P
搜索特定资源需要遍历整个网络,Menos eficiente。 - 2. Problema de intercambio de recursos: en el modelo P2P,El intercambio de recursos requiere ancho de banda de la red y recursos informáticos del nodo, lo que puede afectar el rendimiento de la red.。
- 3. Difícil de gestionar
- Las principales razones son las siguientes:
- Descentralización: El modelo P2P cancela el servidor central, y cada nodo actúa como cliente y servidor, haciendo la gestión descentralizada y compleja.
- Anonimato de los nodos: en el modelo P2P, la comunicación entre nodos suele basarse en el anonimato, lo que dificulta a los administradores identificar y localizar nodos específicos.
- Dinámico: los nodos en el modelo P2P cambian dinámicamente y pueden unirse o abandonar la red en cualquier momento, lo que dificulta a los administradores rastrear y monitorear el estado de la red.
- Problemas de uso compartido de recursos: en el modelo P2P, el uso compartido de recursos requiere ancho de banda de la red y recursos informáticos del nodo, lo que puede afectar el rendimiento de la red. Al mismo tiempo, también existen algunos problemas de intercambio de recursos, como infracción de derechos de autor, contenido ilegal, etc.
- Las principales razones son las siguientes:
- 1. Eficiencia de búsqueda: en el modelo P2P
Por tanto, la gestión del modelo P2P requiere de algunas medidas especiales, como sistemas basados en reputación, filtros, revisión de contenidos, etc., para conseguir una gestión eficaz de la red P2P.
solicitud
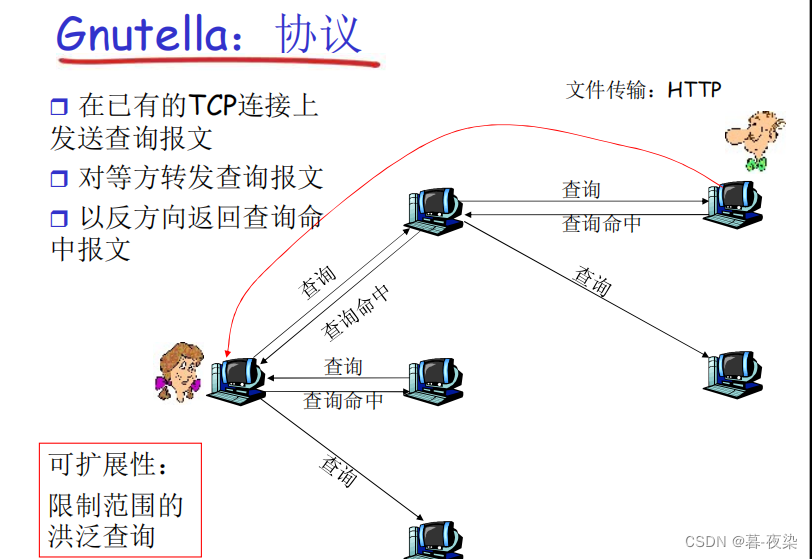
El modelo P2P se puede aplicar a diversos campos, como el intercambio de archivos, la informática distribuida, el almacenamiento en red, etc. El modelo P2P es adecuado para escenarios de intercambio de archivos e informática distribuida a gran escala, como BitTorrent, Emule y otros programas de intercambio de archivos.
* Ejemplo: Gnutella, Trueno
2.2 Distribución de archivos P2P
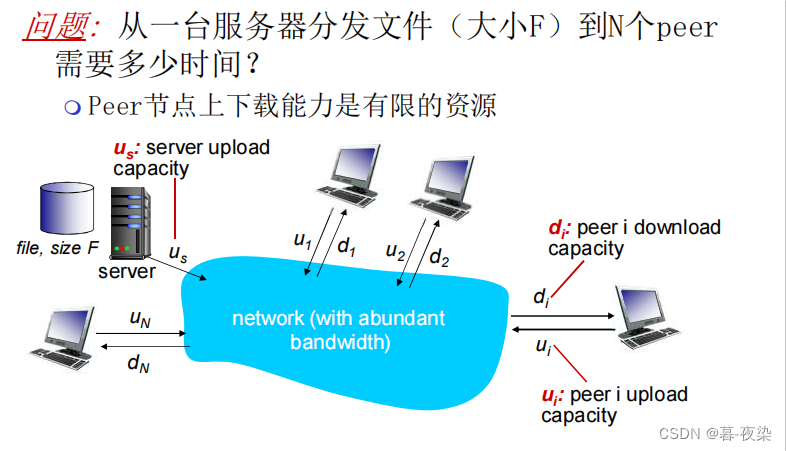
- Tiempo de distribución:
EnC/S(客户端/服务器)模型, el tiempo de distribución generalmente se refiere al tiempo que tarda el cliente en solicitar datos o servicios del servidor, y que el servidor responde y devuelve los datos o servicios .
EnP2P模型, se refiere al tiempo necesario para que N pares obtengan una copia del archivo. - F: longitud del archivo
- dn: tasa de descarga del enésimo nodo
- un: tasa de carga del enésimo nodo
1. Extensibilidad de la arquitectura P2P
Distribución de archivos: C/S vs P2P

Modo C/S
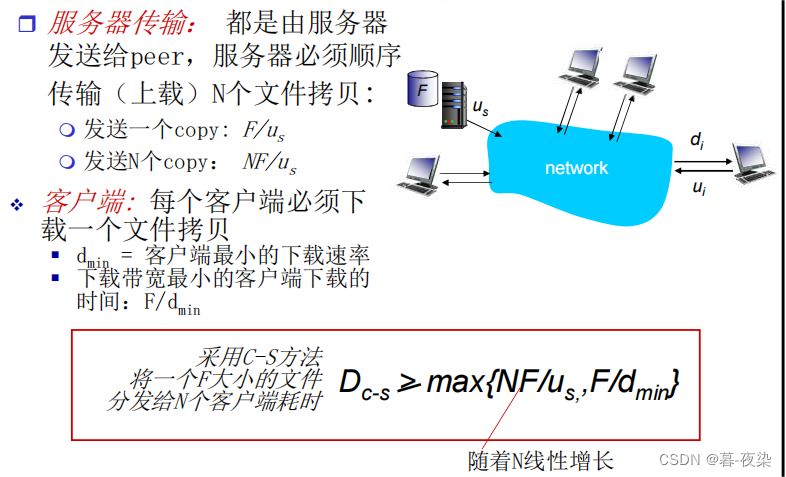
modelo p2p

2.Bittorrent
2.1 Descripción general
- Definición: Un protocolo P2P popular para distribución de archivos.
- Torrent: en términos de Bittorrent, una colección de todos los pares que participan en la distribución de un archivo específico.
Un par puede abandonar el torrent en cualquier momento con sólo un subconjunto de bloques.
Compara en un archivo de descarga de torrent fragmentos de igual longitud, siendo la longitud típica de un fragmento de 256 KB.
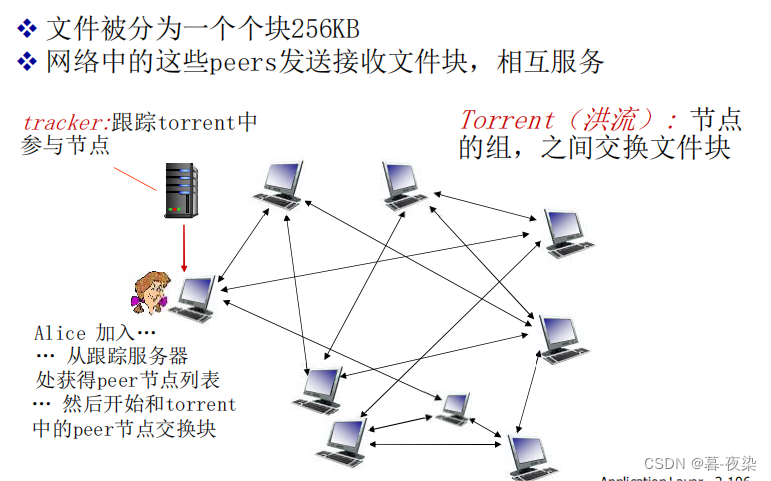

2.2 Solicitar, enviar bloque de archivos
- Primera técnica más escasa: un par solicita primero los bloques con el menor número de réplicas entre sus vecinos, para igualar el número de réplicas de cada bloque en la inundación.




2.3 Otros






*2.4 DHT
DHT (Distributed Hash Table) es un modelo P2P estructurado.
Entre cada nodo se mantiene una topología ordenada en árbol o en anillo. Cada nodo tiene su propia dirección IP codificada como un valor de ID de 16 bytes.
Tomando la topología de anillo como ejemplo, cada nodo forma un anillo según su valor de ID para formar una topología de red ordenada.
El contenido del archivo también se convierte en un valor hash de 16 bytes como valor de ID. 6-88 se mantiene en la ubicación del nodo 88. Al buscar el archivo, solicite directamente al nodo 88 que encuentre la ubicación del archivo.

1.3 Híbridos: arquitecturas cliente-servidor y punto a punto
definición
Híbrido: la arquitectura cliente-servidor y peer-to-peer es un patrón de estructura de red que combina el modelo cliente-servidor y la arquitectura peer-to-peer. En un híbrido, la comunicación entre el cliente y el servidor y la comunicación entre nodos pares pueden ocurrir simultáneamente, cooperando entre sí para completar tareas específicas .
- Ejemplos de aplicaciones híbridas de arquitectura C/S y P2P
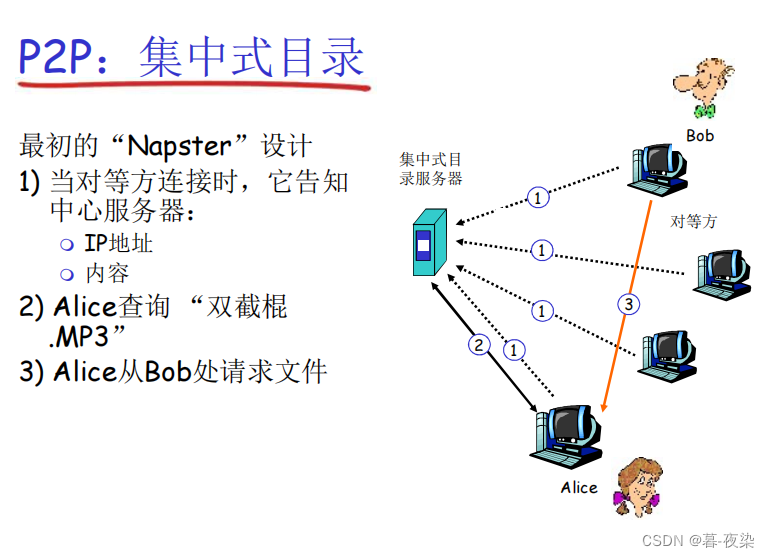
- Napster (software de descarga de MP3)
- Búsqueda de archivos: centralizada
- El host registra sus recursos en el servidor central.
- El host consulta al servidor central la ubicación de los recursos.
- Transferencia de archivos: P2P
- Entre cualquier nodo par
- Búsqueda de archivos: centralizada
- Mensajería instantánea
- Pruebas en línea: centralizadas
- Cuando un usuario se conecta, registra su dirección IP en el servidor central
- Los usuarios contactan con un servidor central para encontrar la ubicación de sus amigos en línea.
- Chat entre dos usuarios: P2P
- Pruebas en línea: centralizadas
- Napster (software de descarga de MP3)
ventaja
La estructura híbrida tiene las siguientes ventajas:
Escalabilidad : la estructura híbrida tiene buena escalabilidad y se pueden agregar nuevos nodos o componentes en cualquier momento para mejorar el rendimiento y la capacidad del sistema.
Gran flexibilidad : los nodos en la estructura híbrida pueden comunicarse entre sí directamente sin pasar por un servidor central, lo que hace que las conexiones de red sean más flexibles.
Alta confiabilidad : cada nodo de la estructura híbrida soporta una carga determinada, lo que hace que la red sea más confiable y estable.
defecto
Sin embargo, las estructuras híbridas también tienen algunas desventajas:
Alta complejidad: La estructura híbrida necesita manejar la comunicación cliente-servidor y la comunicación entre nodos pares al mismo tiempo, y el diseño y la implementación del sistema son relativamente complejos.
Problemas de intercambio de recursos: En una estructura híbrida, el intercambio de recursos requiere ancho de banda de la red y recursos informáticos del nodo, lo que puede afectar el rendimiento de la red .
solicitud
La estructura híbrida es adecuada para escenarios que necesitan admitir tanto la comunicación cliente-servidor como la comunicación entre nodos pares, como algunas aplicaciones como informática distribuida, intercambio de archivos y redes sociales.
2. Relacionado con la aplicación
2.1 Web y HTTP
1.1 Algunos términos
concepto basico
- Página web: (también llamado documento) consta de algunos objetos.
- Objeto: Pueden ser HTML, imágenes JPEG, subprogramas de Java, archivos de clips de sonido, etc.
- La página web contiene unArchivo HTML básico, el archivo HTML también contiene referencias a varios objetos (
链接). Las páginas web están anidadas con enlaces a muchos objetos, en lugar de los objetos mismos.
Número de objetos en una página web = archivos básicos HTML + número de otros (imágenes, videos, etc.) - Haciendo
URLuna referencia (acceso) a cada objeto访问协议,用户名,口令,端口等
WWW
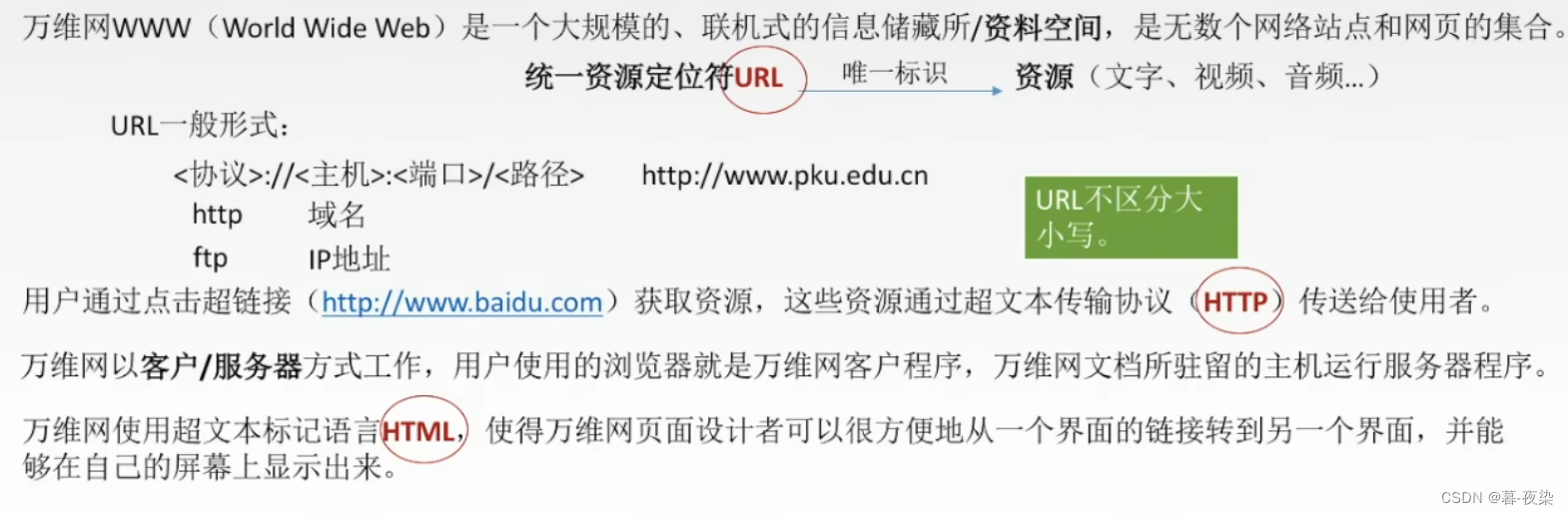
URL
-
Definición:
El localizador uniforme de recursos (URL) es el localizador uniforme de recursos de Internet.Se utiliza para especificar la ubicación de la información en el servidor World Wide Web (www)método de expresión -
Formato:
El formato de sintaxis general de la URL es:
protocol :// hostname[:port] / path / [:parameters][?query]#fragment
Los que están entre corchetes son opcionales.- protocolo: Se utiliza para especificar el protocolo utilizado. Por ejemplo, los nombres de protocolo más utilizados son: HTTP (Protocolo de transferencia de hipertexto), HTTPS (Protocolo seguro de transferencia de hipertexto), FTP (Protocolo de transferencia de archivos), FTPS (Protocolo seguro de transferencia de archivos), SFTP (SSH). protocolo de transferencia de archivos), etc.
HTTPS es un canal HTTP destinado a la seguridad: en pocas palabras, es una versión segura de HTTP. Utiliza Secure Socket Layer (SSL) para el intercambio de información, por lo que los detalles de cifrado requieren SSL.
Las URL con el prefijo https:// utilizan el protocolo de seguridad SSL/TLS para cifrar entre solicitudes y respuestas.
La función principal del protocolo HTTPS es cifrar el protocolo http y garantizar la seguridad de la transmisión de datos estableciendo un canal seguro.
Durante la comunicación HTTPS, se utilizan certificados digitales para la autenticación y la comunicación cifrada.
Los certificados digitales son emitidos por una organización externa de confianza y se utilizan para verificar la legitimidad de las identidades de ambas partes que se comunican.
HTTPS usa el puerto 443, no el puerto 80 como HTTP.-
nombre de host:Se refiere aEl nombre de host del sistema de nombres de dominio (DNS) o la dirección IP del servidor que aloja el recurso.. Algunos sitios web admiten el acceso anónimo, mientras que otros requieren un nombre de usuario y contraseña para acceder.
在主机名前包含连接到服务器所需的用户名和密码(格式:username:password@hostname)。 -
puerto (número de puerto) : utilizado paraEspecifique el número de puerto donde se encuentra el recurso.。
默认情况下,HTTP 使用的端口号是80,HTTPS 使用的端口号是443。
En la sintaxis de URL estándar , el número de puerto se coloca después del nombre del host , no al final de la URL. Por ejemplo, la siguiente es una URL que contiene un número de puerto:
http://www.example.com:8080/index.html
En este ejemplo, el nombre de host es www.example.com, el número de puerto es 8080 y la ruta es /index.html.
Sin embargo, algunas URL no estándar pueden poner el número de puerto al final , pero esta no es la sintaxis de URL estándar. Una URL de este tipo puede funcionar bien en algunos casos específicos, pero puede causar problemas en la mayoría de los casos .
Por lo tanto, se recomienda seguir las especificaciones de sintaxis de URL estándar y colocar el número de puerto después del nombre del host.-
camino: Se utiliza para especificar la ruta donde se encuentra el recurso, es decir, la ruta relativa del archivo o directorio.
-
parámetros (parámetros de consulta) : se utiliza para especificar algunos parámetros de consulta para pasar información adicional al servidor al realizar la solicitud.
-
consulta :
opcional, se utiliza para pasar parámetros a páginas web dinámicas (como páginas web producidas con CGI, ISAPI, PHP/JSP/ASP/ASP.NET y otras tecnologías). Puede haber varios parámetros, separados por el símbolo "&". En encendido, el nombre y el valor de cada parámetro están separados por el símbolo "=" . -
fragmento (identificador de fragmento): Se utiliza para especificar una parte de un recurso, como una marca de tiempo en un video o un número de página en un documento, etc.
1.2 Descripción general de HTTP
HTTP frente a HTTPS
 RFC explicado
RFC explicado
"Hyper Text" (HT) es la abreviatura china de Hyper Text.
- El hipertexto es un texto en red que utiliza hipervínculos para organizar la información del texto en varios espacios. Mostrar texto y contenido relacionado con el texto.
- El texto contiene enlaces a otras ubicaciones o documentos.,Conecte diferentes
对象enlaces para formar una estructura de red., lo que le permite cambiar directamente desde la posición de lectura actual a la posición a la que apunta el enlace de hipertexto.
Protocolo de transferencia de hipertexto (HTTP)
- Protocolo simple de solicitud-respuesta
- Normalmente se ejecuta sobre TCP .
- Especifica qué tipo de mensajes puede enviar el cliente al servidor y qué tipo de respuesta obtiene.
请求和响应消息的头以ASCII形式给出;- El contenido del mensaje tiene un formato similar a MIME.

- Socket es una abstracción de puntos finales para la comunicación bidireccional entre procesos de aplicaciones en diferentes hosts de la red.
- TCP (Protocolo de control de transmisión): es unFiable y orientado a la conexiónprotocolo de transporte, puedeRealizar funciones tales como transmisión confiable y control de flujo de paquetes de datos.。
- UDP (Protocolo de datagramas de usuario):
es unprotocolo sin conexión poco confiable,Se puede lograr una transferencia de datos rápida, pero puede haber problemas como la pérdida de datos.。
- El servicio sin conexión
significa que las partes que se comunican no necesitan establecer una línea de comunicación por adelantado , sino que cada paquete (grupo de mensajes) con una dirección de destino se envía a la línea y el sistema selecciona de forma independiente una ruta para la transmisión.
- Servicio orientado a la conexión
Al comunicarse, ambas partes deben establecer una línea de comunicación con anticipación , el proceso es el siguiente:Establecer conexiones, usar conexiones y liberar conexiones.tres procesos
En las redes informáticas,Con estado y sin estado se refieren a si el protocolo de red guarda información sobre el estado de la conexión de red.。
1. Protocolo sin estado significa que el protocolo no guarda información sobre el estado de la conexión de red.Los protocolos sin estado no mantienen registros de solicitudes o respuestas anteriores, se requiere información completa para cada solicitud. Por ejemplo, el protocolo HTTP es un protocolo sin estado, no guarda la información de la solicitud enviada por el cliente y cada solicitud es independiente.
2. Los protocolos con estado se refieren a protocolos que guardan información sobre el estado de las conexiones de red.Los protocolos con estado mantienen registros de solicitudes o respuestas anteriores., para su posterior procesamiento. Por ejemplo, el protocolo FTP es un protocolo con estado que guarda la información del estado de la conexión del cliente en el servidor para su posterior procesamiento.
En las redes informáticas, los protocolos con y sin estado tienen ventajas y desventajas. El protocolo sin estado puede admitir mejor el procesamiento concurrente y el equilibrio de carga , porque el protocolo sin estado no guarda la información del estado de la conexión, por lo que es más fácil procesar múltiples solicitudes y puede admitir más usuarios bajo las mismas condiciones de recursos del servidor .
Los protocolos con estado pueden admitir mejor escenarios en los que es necesario guardar información del estado de la conexión, como aplicaciones web que necesitan mantener sesiones.
Cabe señalar que los protocolos con estado son vulnerables a ataques si no se manejan adecuadamente. Por ejemplo, los derechos de acceso anónimo a un servidor FTP pueden provocar fácilmente un ataque al servidor FTP. Por tanto, en aplicaciones prácticas, es necesario seleccionar un protocolo adecuado según la situación específica.
1.3 conexión HTTP
Las conexiones HTTP se dividen en 持续(持久)连接y非持续(非持久)连接
Si desea ver qué método se utiliza para una determinada conexión HTTP, puede capturar el paquete y juzgar según el valor de Conexión en la solicitud HTTP o el mensaje de respuesta.
-
conexión no persistente
-
conexión persistente
Connection: Keep-Alive
3.1 HTTP con conexiones no persistentes
Una conexión no persistente significa que después de que el cliente y el servidor establecen una conexión, el cliente y el servidor solo pueden comunicarse entre una solicitud y una respuesta (es decir, la conexión TCP solo realiza una transmisión de datos) y luego la conexión se cerrará.
- Como máximo solo
一个对象se envía mediante conexión TCP - La descarga de varios objetos requiere varias conexiones TCP
- HTTP/1.0 utiliza conexiones no persistentes
Ejemplo de diagrama de flujo para transferir datos a través de una conexión no persistente :


Modelo de tiempo de respuesta y RTT
- RTT incluye: agrupaciónretardo de propagación, los paquetes se enrutan en enrutadores y conmutadores intermediosRetraso en la cola, gruporetraso en el procesamiento。
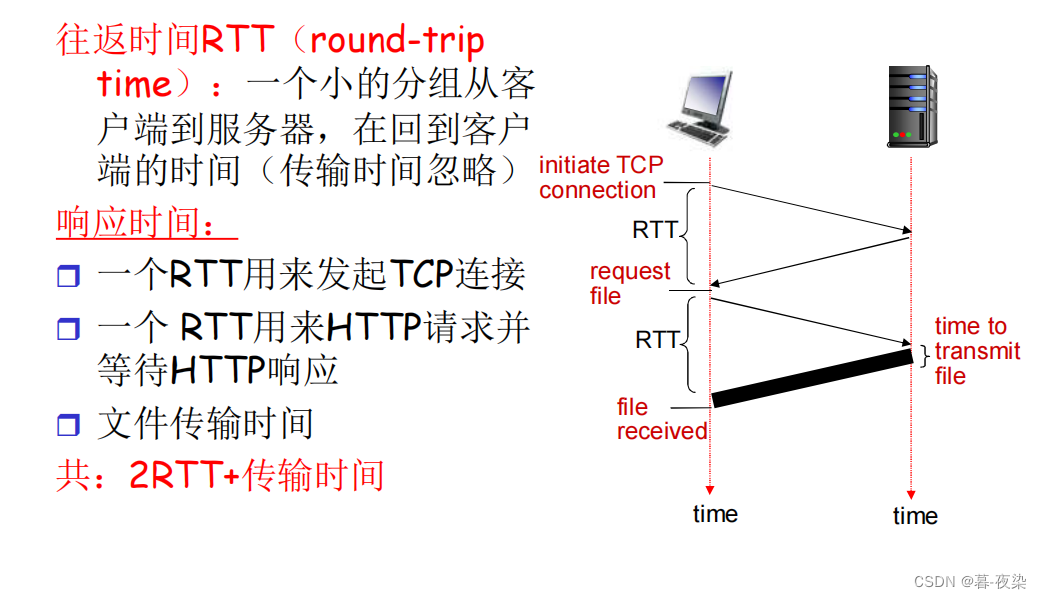
3.2 HTTP con conexiones persistentes
- La conexión persistente se refiere aLas solicitudes y respuestas se pueden entrelazar y se transfieren varios objetos en una única conexión TCP (entre el cliente y el servidor). Todas las solicitudes/respuestas se envían a través de la misma conexión TCP.
- HTTP/1.1 usa conexiones persistentes de forma predeterminada

1.4 Formato de mensaje HTTP
La especificación HTTP [RFC:1945; RFC2616; RFC7540] contiene la definición del formato de mensaje HTTP.
Tipo de mensaje HTTP:
- mensaje de solicitud
- mensaje de respuesta
4.1 Mensaje de solicitud HTTP

1. Formato común de mensajes de solicitud HTTP
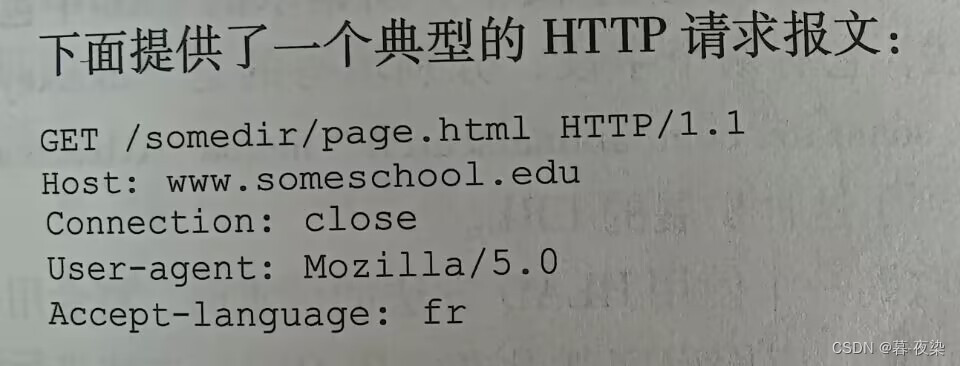
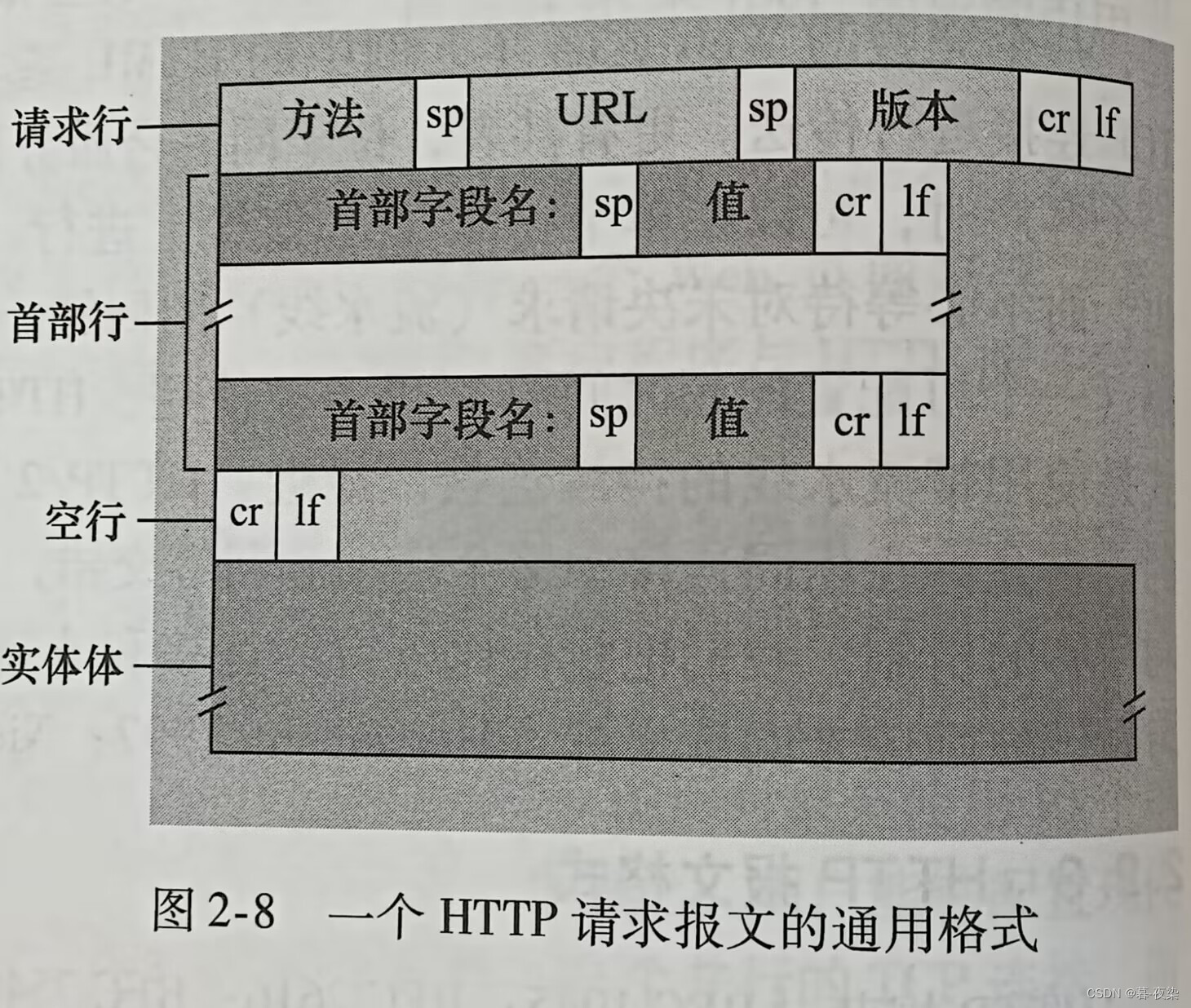
实体体在使用POST方法时被才会被使用,当使用GET方法时实体体为空。
- Línea de solicitud HTTP: campo de método, campo de URL, campo de versión HTTP
- Tipos de campos de método: GET, POST, HEAD, PUT, DELETE
-
OBTENER: Se utiliza a menudo en formularios HTML e incluye los datos ingresados en la URL solicitada (en el campo del formulario).Los datos de entrada y la URL normal deben estar separados por signos de interrogación (?) en inglés, y se deben combinar múltiples parámetros con &., juntos forman el enlace URL expandido. Por ejemplo: http://www.somesite.com/animalsearch?monkey&bananas.
-
POST: los clientes HTTP suelen utilizar el método POST cuando un usuario envía un formulario. existirEl cuerpo de la entidad del mensaje de solicitud contiene el valor ingresado por el usuario en el campo del formulario. (Algunos sitios web cifrarán el valor ingresado, como se muestra a continuación, contraseña)
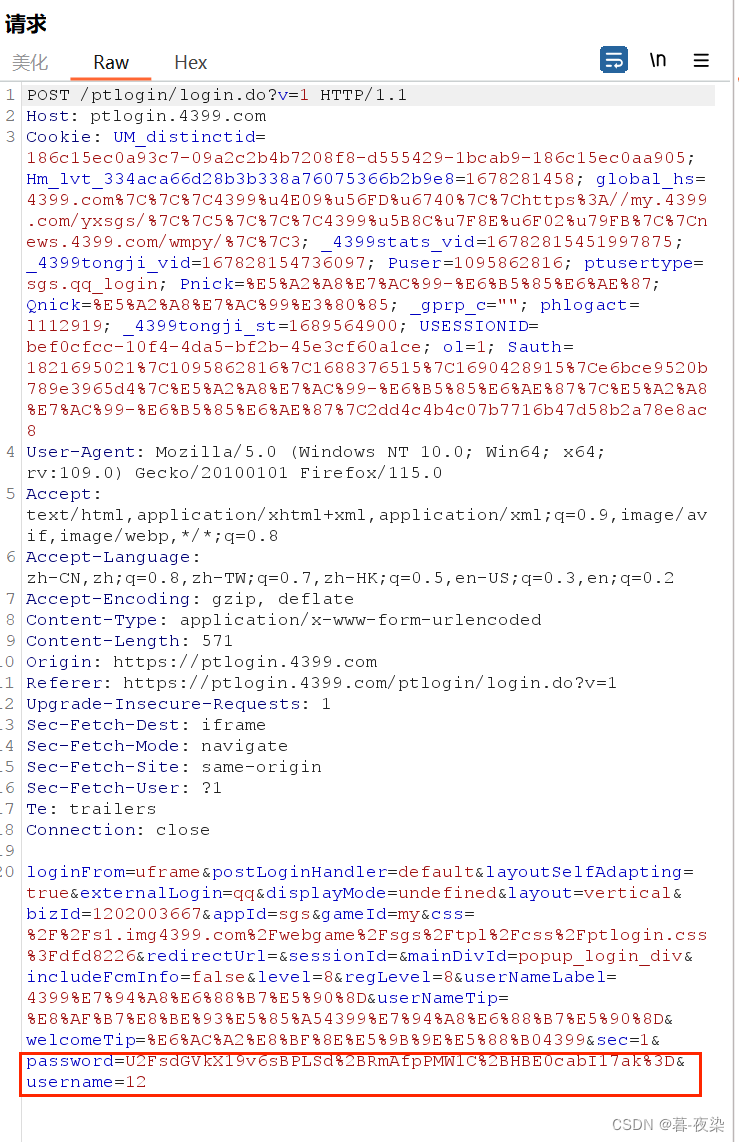
-
CABEZA: Similar a OBTENER. cuandoservidorDespués de recibir un mensaje de solicitud del método HEAD,Responderá con un mensaje HTTP, pero no devolverá el objeto de solicitud.. Comúnmente utilizado para depurar rastros de aplicaciones web.
-
PUT: A menudo se utiliza junto con herramientas de publicación web, lo que permite a los usuariosCargue objetos en la ruta (directorio) especificada del servidor web especificado。
-
ELIMINAR: Permitir usuario o aplicaciónEliminar objetos en el servidor web。
-
- Tipos de campos de método: GET, POST, HEAD, PUT, DELETE
- Línea de cabecera:
- HOST: El host donde se encuentra el objeto.
- Conexión: si se deben utilizar conexiones persistentes
- Agente de usuario: agente de usuario (es decir, el tipo de navegador que el navegador envía solicitudes al servidor)
- Aceptar idioma: indica la versión del objeto que el usuario desea obtener (si el objeto existe), fr indica que desea obtener la versión en francés.
2. Envíe la entrada del formulario

3. Tipo de versión HTTP

4.2 Mensaje de respuesta HTTP
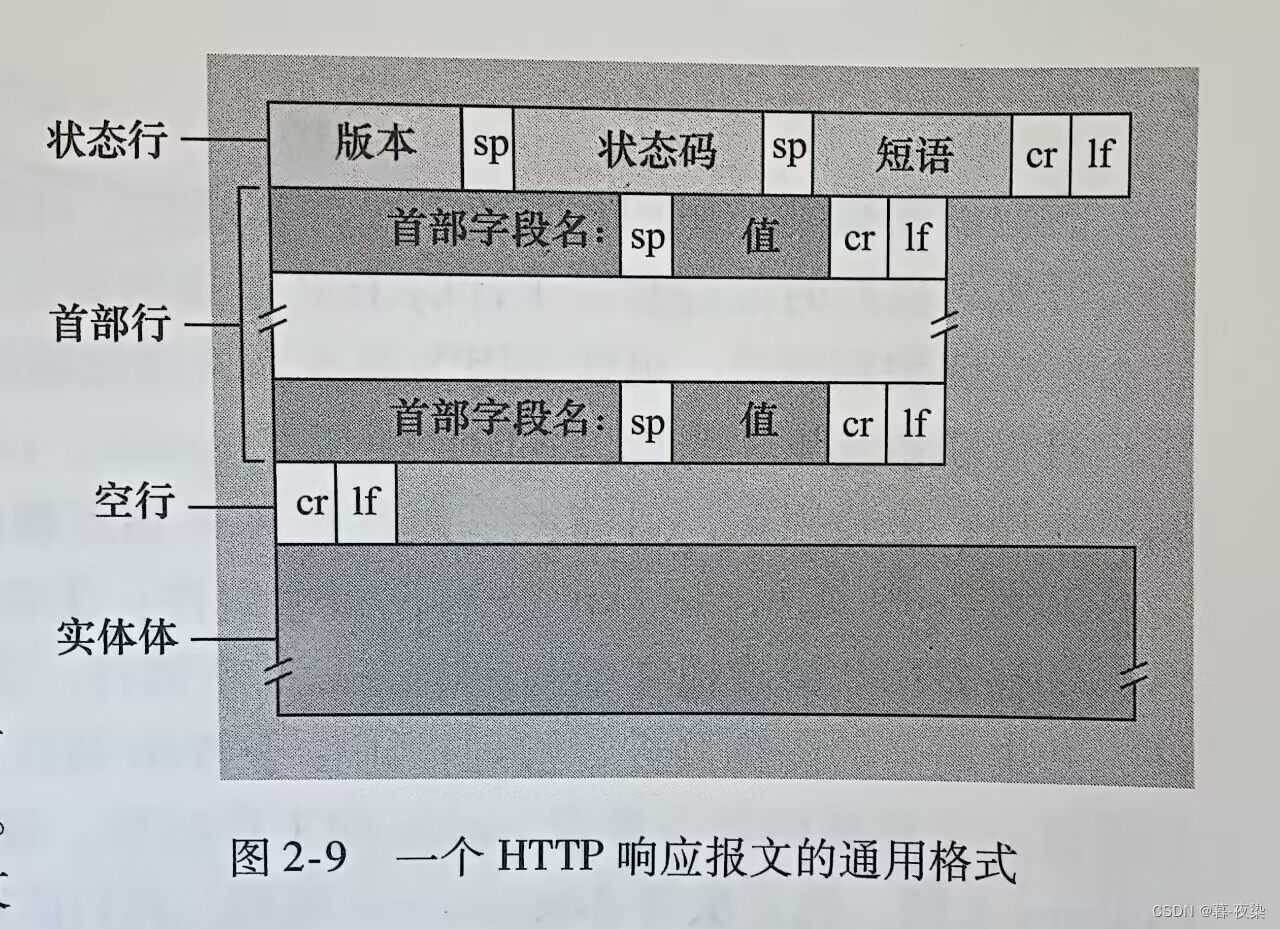
1. Formato del mensaje de respuesta
-
Formato de mensaje de respuesta común
-
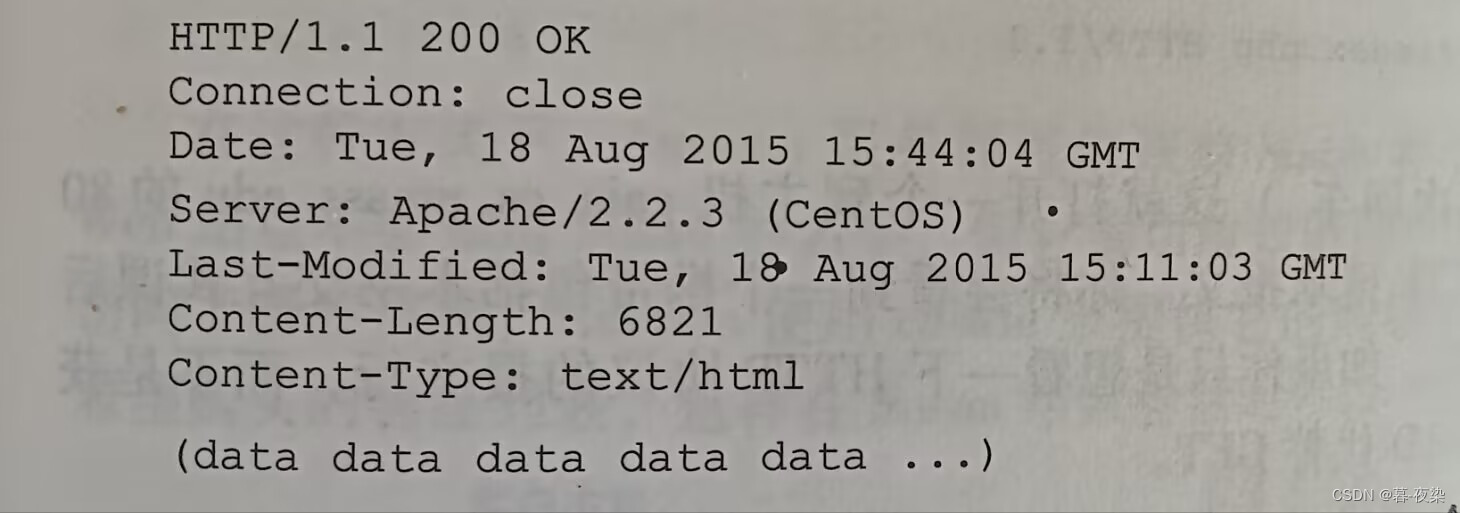
La siguiente figura muestra el mensaje de respuesta del mensaje de solicitud en el ejemplo anterior.
-
Línea de estado HTTP
- Versión: HTTP/1.1
- Código de estado: 200, declaración: OK
-
Línea de cabecera:
- Conexión : Modo de conexión (persistente, no persistente).
- Fecha : La fecha y hora en que el servidor generó y envió el mensaje de respuesta (
服务器从它的文件系统中检索到对象,将该对象插入到响应报文并发送该响应报文的时间). - Servidor : el servidor que genera mensajes (respuesta), similar al agente de usuario en el mensaje de solicitud.
- Última modificación :La fecha y hora en que se creó o modificó por última vez el objeto.。
- Longitud del contenido : enviarEl número de bytes en el objeto.。
- Tipo de contenido : indicaciónFormato de texto para objetos en entidades.. (La imagen muestra texto HTML)
2. Código de estado de respuesta

1.5 Interacción usuario-servidor: Cookies
5.1 Estado Usuario-Servidor: Cookies

-
Cuando un usuario visita por primera vez un comercio electrónico que utiliza cookies, el servidor le asigna un ID (para asociar el comportamiento del usuario, y resumir su comportamiento posterior y su información de usuario bajo un ID para facilitar la prestación de servicios personalizados al usuario). La información del usuario también se guarda para su identificación).
-
Las solicitudes posteriores enviadas al servidor llevarán una cookie en la línea de encabezado: xxx. (código numérico o alfabético)
-
Debido a la función de las cookies para almacenar información del usuario, HTTP se puede cambiar de un protocolo sin estado a un "protocolo con estado" para admitir más aplicaciones y proporcionar más servicios.
5.2 Cookies: mantenimiento del estado
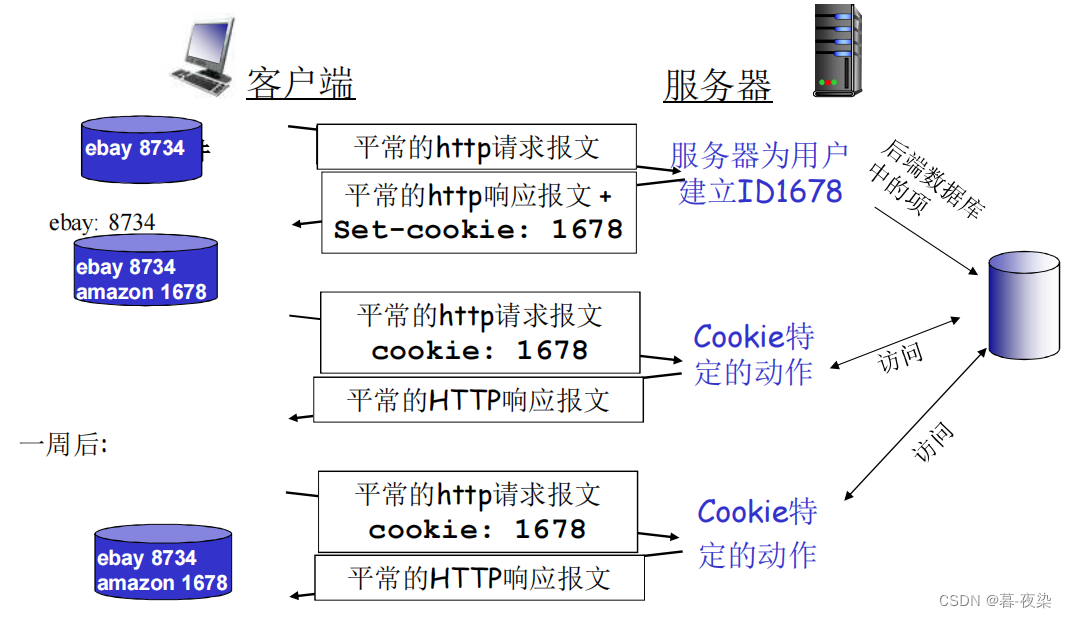
- Utilice cookies para rastrear el estado del usuario:
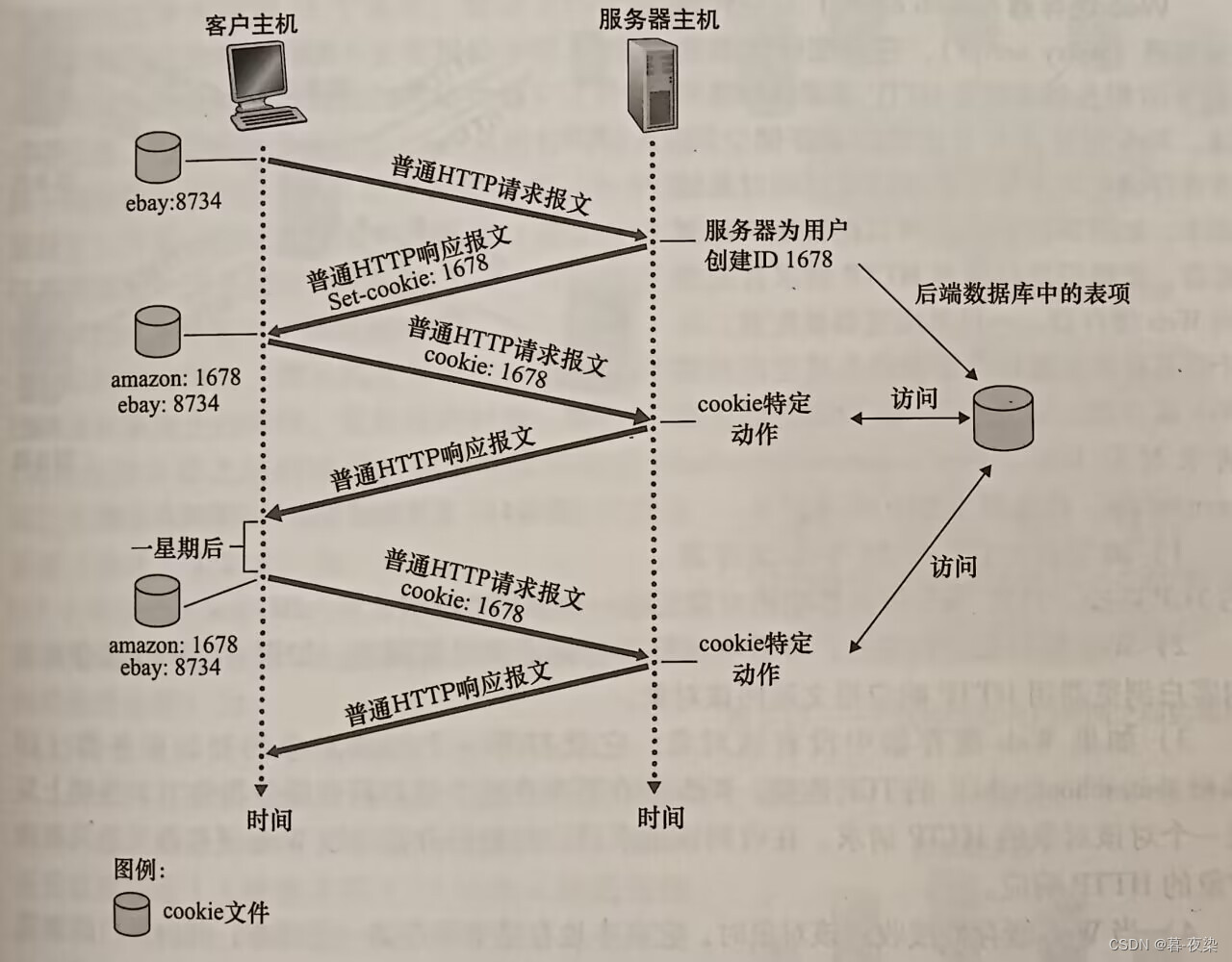
5.3 Cuestiones de privacidad y conveniencia de las cookies

1.6 Almacenamiento en caché web
6.1 Definición y explicación
- Caché web: también llamado servidor proxy, es una entidad de red que puede reemplazar el servidor inicial para satisfacer las solicitudes HTTP.
- La caché web tiene su propio almacenamiento en disco y guarda una copia del objeto solicitado más recientemente.
- Proceso de trabajo:
- Cuando un objeto solicitado está en el cachéexistirhora,El caché web está directamenteUtilice un mensaje de respuesta HTTP para el navegador del clientedevolverel objeto
- en caché webCuando no existe tal objeto,Abre una conexión TCP al servidor inicial del objeto.. Envíe una solicitud HTTP para este objeto en la conexión TCP del caché al servidor de origen.
- bufferDespués de recibir la respuesta a la solicitud, almacene una copia en el espacio de almacenamiento local.,yA través de una conexión TCP entre el navegador del cliente y la caché webEnviar al navegador del cliente。
- En este proceso, el caché web es tanto un cliente como un servidor.

Caché push versus pull
El caché de inserción y el caché de extracción son tipos de caché de red que se utilizan principalmente para aliviar los retrasos de la red y aumentar la velocidad de transmisión de datos.
El almacenamiento en caché push se refiere a enviar datos desde el servidor al navegador del cliente , cuandoCuando el cliente necesita estos datos, el navegador los obtiene directamente del caché sin volver a descargarlos del servidor.. Algunos navegadores almacenan en caché localmente las páginas web visitadas con frecuencia para reducir la latencia de la red y aumentar la velocidad de acceso.
Pull cache significa que cuando el navegador del cliente inicia una solicitud, el servidor almacena en caché los datos en la red local .Cuando los clientes necesitan estos datos, pueden obtenerlos directamente de la red local sin necesidad de descargarlos nuevamente del servidor.. Este método se utiliza a menudo para almacenar en caché grandes datos, como vídeos e imágenes, lo que puede reducir la latencia de la red y aumentar la velocidad de transmisión de datos.
En general, el caché de inserción y el caché de extracción tienen como objetivo mejorar el rendimiento de la red, reducir la latencia de la red y aumentar la velocidad de transmisión de datos.
6.2 Ejemplo de almacenamiento en caché
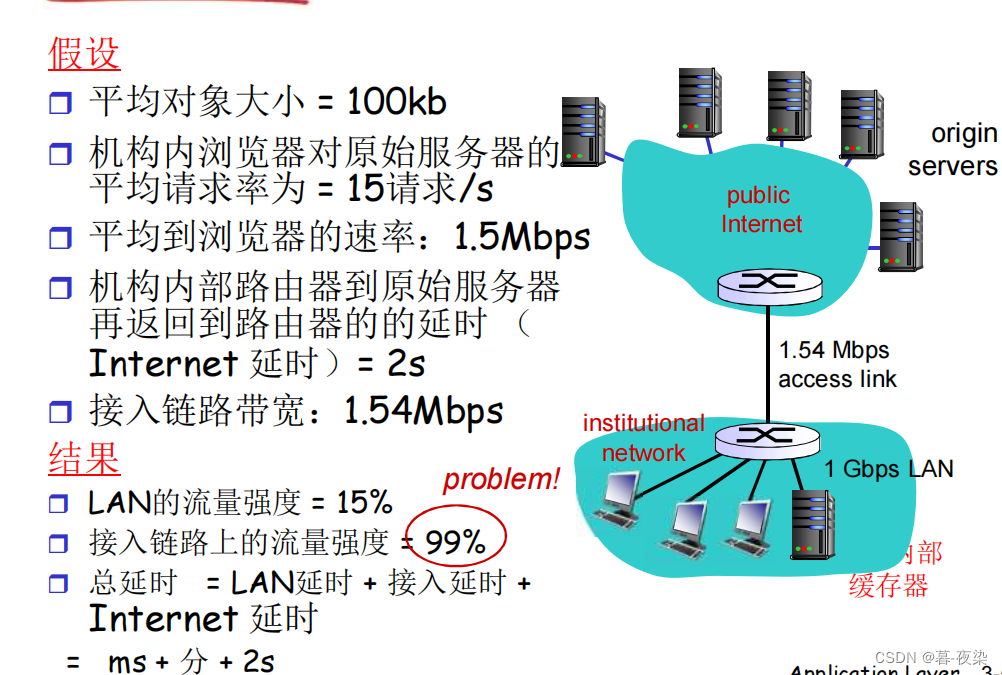
1. Enlaces de acceso más rápidos
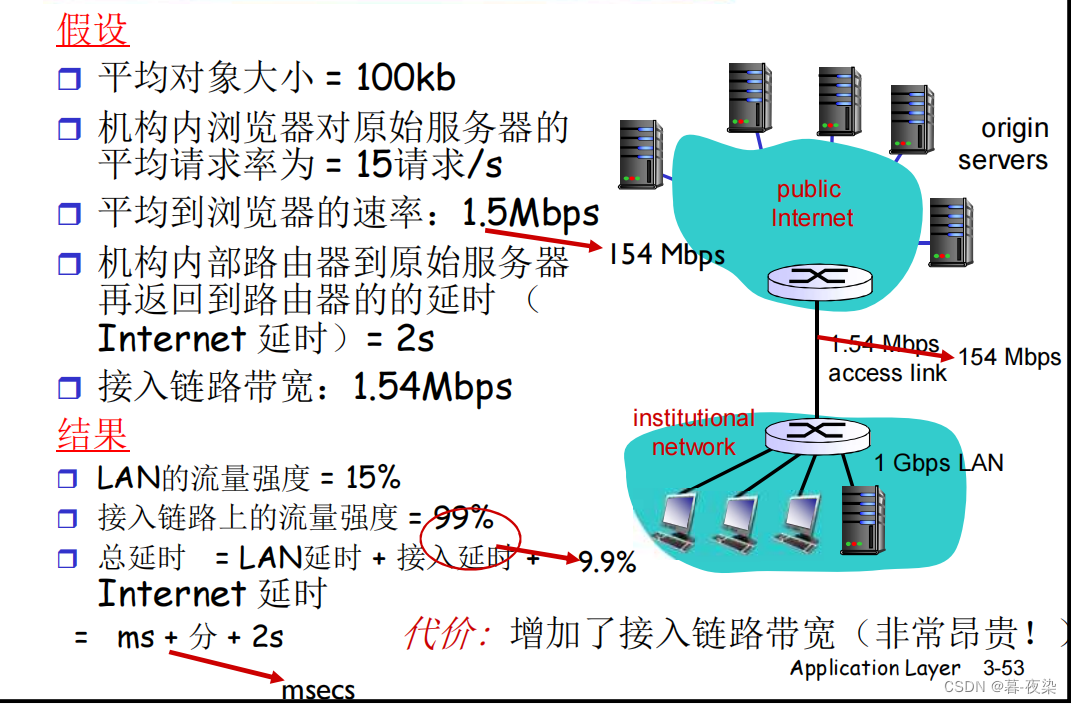
2. Instalar caché local
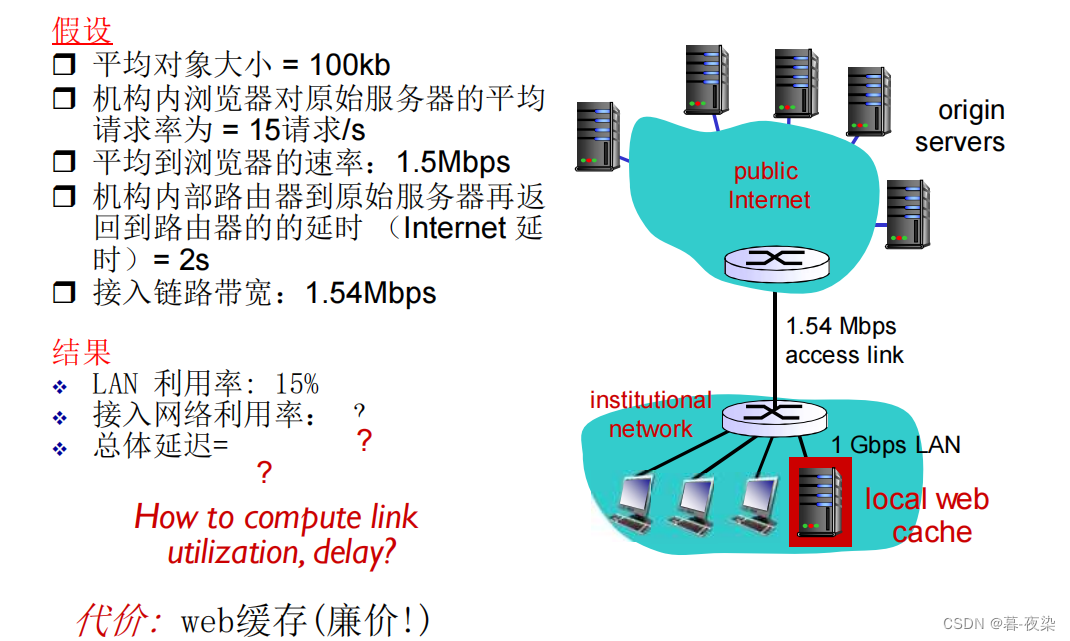
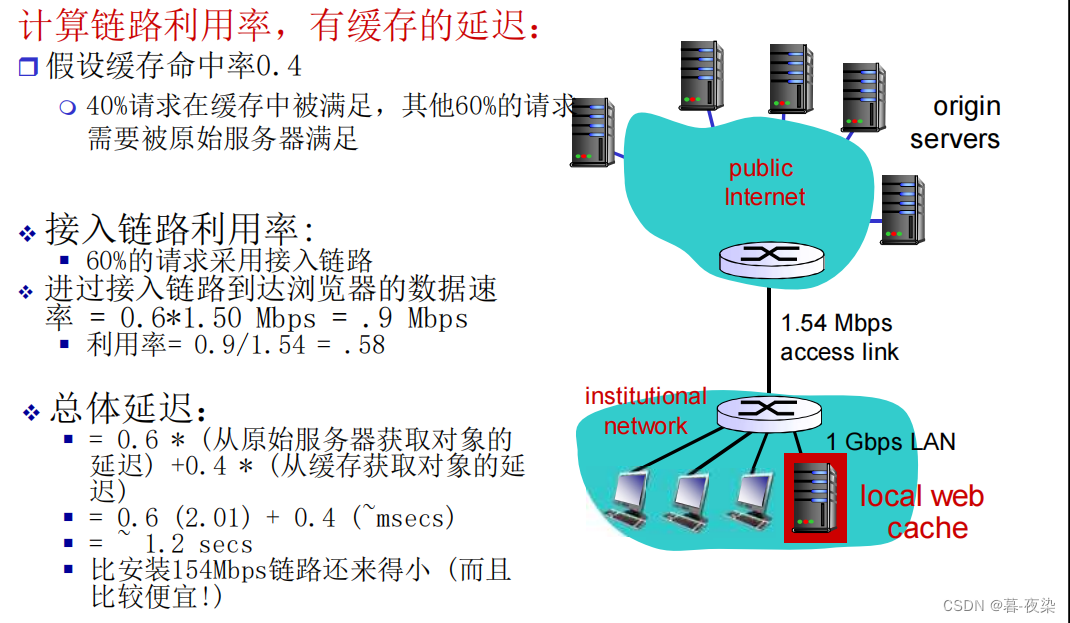
1.7 Método GET condicional
- Generación:
aunque el almacenamiento en caché puede reducir el tiempo de respuesta, la copia del objeto almacenado en el caché puede estar obsoleta. Para garantizar que el objeto esté actualizado, HTTP introduce el método GET condicional.
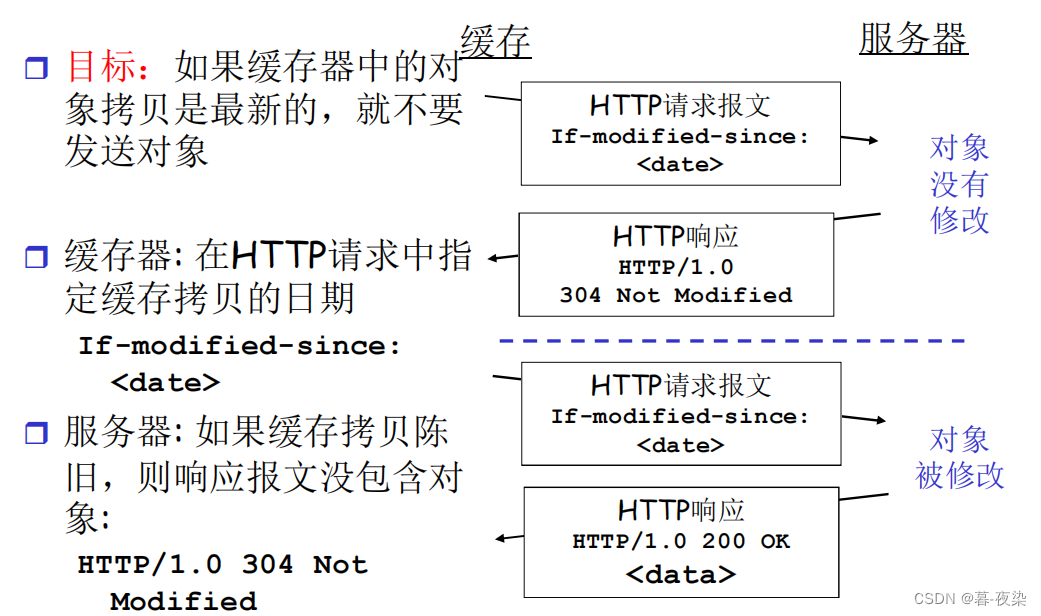
- Condiciones de composición:
- mensaje de solicitudUtilice el método GET
- mensaje de solicitudContiene una línea de encabezado "If-Modified-Since"
If-Modified-Since首部行的值为服务器发送的响应报文中 Last-Modified 首部行的值
- Este mensaje de solicitud le dice al servidor,Enviar el objeto solo si ha sido modificado desde la fecha especificada
- Si el objeto ha sido modificado, envíe el objeto modificado y actualice el caché
- De lo contrario, el objeto no se enviará y el mensaje de respuesta será como se muestra en la siguiente figura:

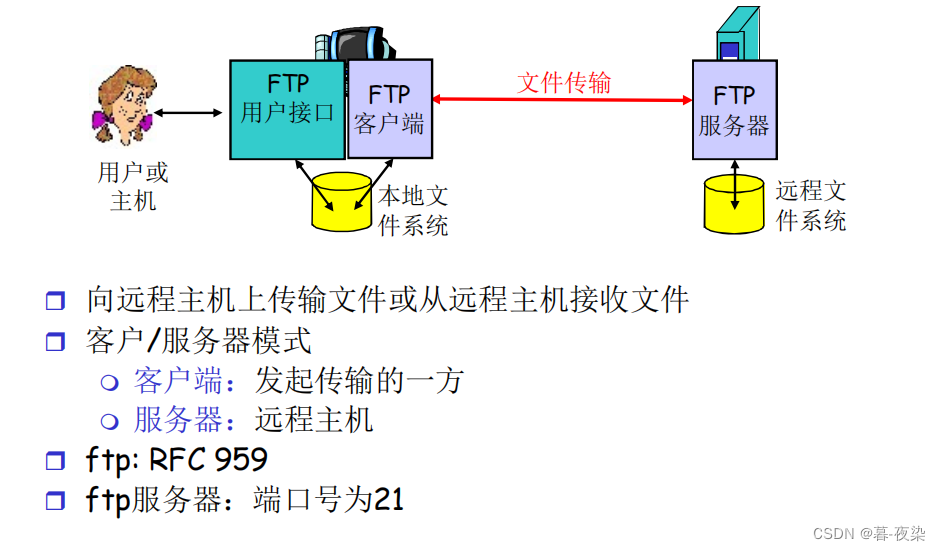
2.2 Protocolo de transferencia de archivos FTP
2.2.1 Definición
- Función:
uso tempranocompartir archivosprotocolo (incluida la carga y descarga de archivos), la función de los servidores FTP, como los actuales Thunder, Baidu y Cloud Disk
Los administradores de red mantienen servidores FTP. El que comparte (un usuario) carga (carga) archivos para compartir a través de un cliente FTP. Otros usuarios acceden a este contenido a través de clientes FTP.
- Constituye
una interfaz de usuario, una interfaz de archivos local. El servidor FTP tiene un disco duro de almacenamiento (disco duro en la nube) y transfiere archivos entre archivos locales y directorios de archivos del servidor.
TFTP:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是TCP/IP协议族中的一个用来在客户机与服务器之间进
行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。
TFTP通常用于从TFTP服务器下载或上传文件,
例如操作系统引导程序、配置文件等。TFTP客户端和TFTP服务器之间的通信是基于UDP协议进行的,端口号为69。
与FTP协议相比,TFTP协议更加简单和轻量级,但功能较少。TFTP协议不支持用户认证,只能以匿名方式进行文件传输。
此外,TFTP协议不支持文件目录操作,只能进行文件传输。
在TFTP协议中,有两种传输模式,分别是读写模式(读写模式)和只读模式(只读模式):
读写模式:客户端可以从服务器下载文件,也可以向服务器上传文件。
只读模式:客户端只能从服务器下载文件,不能向服务器上传文件。
需要注意的是,由于TFTP协议的安全性较低,因此在实际应用中,通常会使用FTP协议来代替TFTP协议。
- Servidor y cliente FTP

El sistema Windows viene con comando FTP
Los usuarios pueden utilizar el comando FTP mediante los siguientes pasos:
打开命令提示符。
输入“ftp”并按下回车键,进入FTP模式。
输入FTP服务器的地址,并按照提示进行操作。
Cabe señalar que al utilizar comandos FTP, los usuarios deben tener ciertos conocimientos y habilidades informáticas básicas, así como medidas de seguridad y procedimientos operativos correctos para garantizar la seguridad y confiabilidad de los datos2.
2.2.2 Etapas de trabajo

1. Establecer una conexión
Cuando FTP客户端向FTP服务器发送连接请求时,FTP服务器会向客户端发送连接应答,建立起FTP控制连接.
Luego, el cliente FTP debe enviar el nombre de usuario y la contraseña al servidor FTP para su autenticación. Si la autenticación es exitosa, se pueden iniciar operaciones como la transferencia de archivos.
2. Verificación de identidad
La autenticación de usuario pertenece a la conexión de control.El contenido se ejecuta después de que se establece la conexión. Consulte lo siguiente para controlar la conexión.
- Ingrese el nombre de usuario y la contraseña para iniciar sesión (el servidor FTP realizaEl nombre de usuario y la contraseña se transmiten en texto claro, que plantea un riesgo de seguridad y puede ser interceptado fácilmente por piratas informáticos utilizando herramientas de captura de paquetes)
- Iniciar sesión de forma anónima

3. Operación y transmisión de archivos.
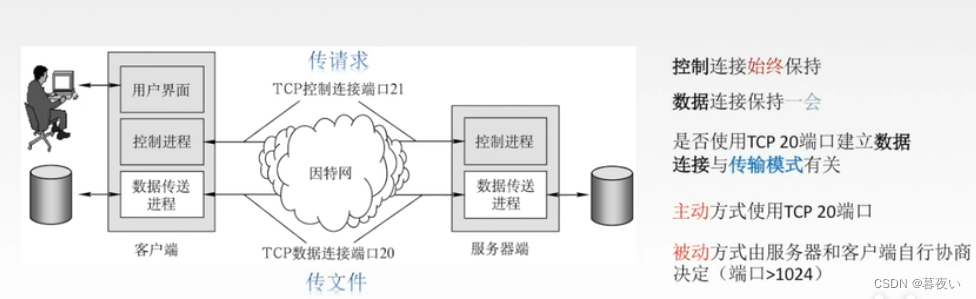
Una vez establecida la conexión, dos diferentesconexión TCP, respectivamente llamadoconexión de controlyConexiones de datos.
Las instrucciones se transmiten en la conexión de control y los datos del archivo se transmiten en la conexión de datos.
2.2.3 Conexión de control FTP y conexión de datos
FTP控制连接与数据连接分开
conexión de control
existirconexión de controlsuperior
-
Usuario de autenticación de usuario
, contraseña使用的是明文传输 -
El cliente envía instrucciones al servidor, como instrucciones para cambiar de directorio, eliminar, cargar y descargar archivos.
La transmisión de comandos de datos se denomina "fuera de banda".
Ejemplo de explicación del código de estado de respuesta y comando FTP:
 Las palabras en minúscula en el ejemplo de comando en la figura anterior son parámetros variables y valores específicos. Las palabras en mayúscula son nombres propios y son fijas.
Las palabras en minúscula en el ejemplo de comando en la figura anterior son parámetros variables y valores específicos. Las palabras en mayúscula son nombres propios y son fijas.
La instrucción RETR (recuperación) es una instrucción para descargar un archivo del servidor y especifica un determinado nombre de archivo.
Carga de STOR (carga).
Cuando el cliente envía el comando de descarga del archivo al servidor, 服务器的使用自己的20号端口主动与客户端建立数据连接。
Conexiones de datos
existirConección de datos:
- Realice la descarga, carga (carga) de archivos y otras transmisiones de flujo de datos.
La transmisión de datos se realiza a través de la conexión de datos. La transferencia de datos se llama "dentro de banda"
Durante el proceso de conexión de datos FTP, el cliente envía un comando FTP al servidor para indicarle que necesita transmitir o recibir datos. Después de recibir el comando, el servidor utilizará su propio puerto 20 para enviar una respuesta de confirmación al cliente. Después de recibir la respuesta, el cliente abre una conexión de transferencia de datos y envía una solicitud de conexión de datos al servidor. Después de recibir la solicitud, el servidor utilizará su propio puerto 20 para establecer una conexión de transferencia de datos con el proceso del cliente.
Cabe señalar que el puerto de conexión de datos FTP se asigna dinámicamente y no es un puerto fijo 20. Pero en términos generales, el puerto de conexión de datos de FTP es el puerto 20, porque el protocolo FTP estipula que el puerto 20 se utiliza para la conexión de datos.
FTP es un protocolo con estado, el servidor necesita mantener el estado del cliente.
La transmisión HTTP está enUna conexión TCPllevado a cabo en. El diseño inicial de HTTP fuesin EstadoSí, se puede convertir en un protocolo con estado mediante la función de cookies.
Ilustración
El proceso de trabajo específico se puede ver en la siguiente figura:

En las redes informáticas,Con estado y sin estado se refieren a si el protocolo de red guarda información sobre el estado de la conexión de red..
Un protocolo sin estado significa que el protocolo no guarda información sobre el estado de la conexión de red.Los protocolos sin estado no mantienen registros de solicitudes o respuestas anteriores, se requiere información completa para cada solicitud. Por ejemplo, el protocolo HTTP es un protocolo sin estado, no guarda la información de la solicitud enviada por el cliente y cada solicitud es independiente.
Los protocolos con estado se refieren a protocolos que guardan información sobre el estado de las conexiones de red.Los protocolos con estado mantienen registros de solicitudes o respuestas anteriores., para su posterior procesamiento. Por ejemplo, el protocolo FTP es un protocolo con estado que guarda la información del estado de la conexión del cliente en el servidor para su posterior procesamiento.
En las redes informáticas, los protocolos con y sin estado tienen ventajas y desventajas. Los protocolos sin estado pueden admitir mejor el procesamiento simultáneo y el equilibrio de carga porque no guardan la información del estado de la conexión, lo que facilita el manejo de múltiples solicitudes. Los protocolos con estado pueden admitir mejor escenarios en los que es necesario guardar información del estado de la conexión, como aplicaciones web que necesitan mantener sesiones.
Cabe señalar que los protocolos con estado son vulnerables a ataques si no se manejan adecuadamente. Por ejemplo, los derechos de acceso anónimo a un servidor FTP pueden provocar fácilmente un ataque al servidor FTP. Por tanto, en aplicaciones prácticas, es necesario seleccionar un protocolo adecuado según la situación específica.
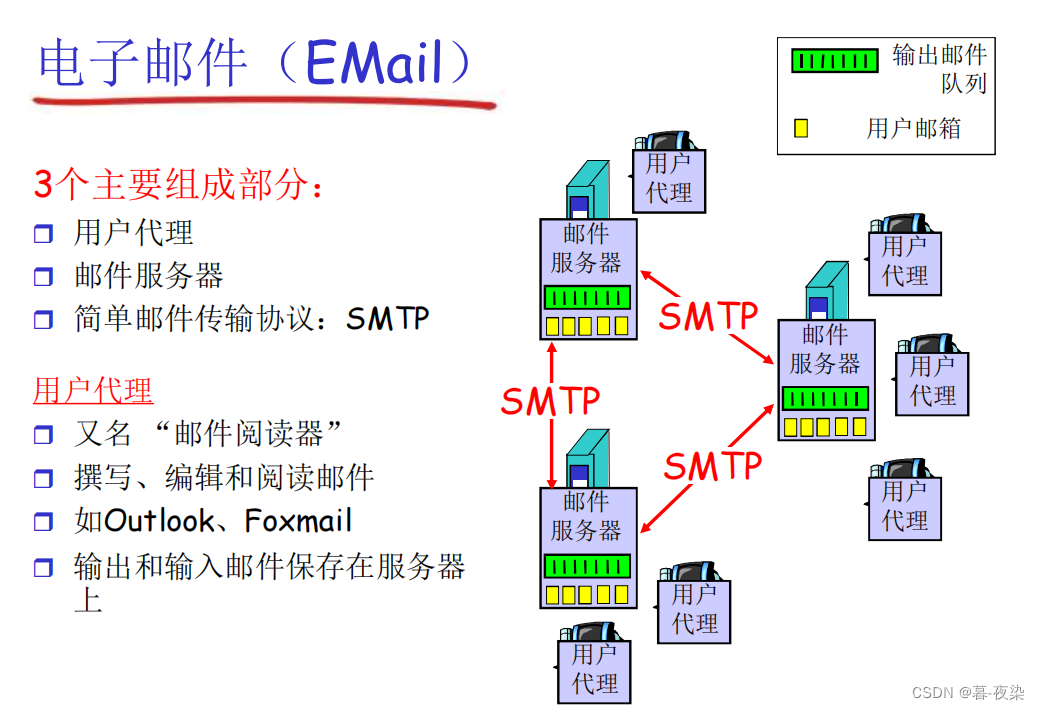
2.3 Correo electrónico Correo electrónico
2.3.1 Descripción general del correo electrónico
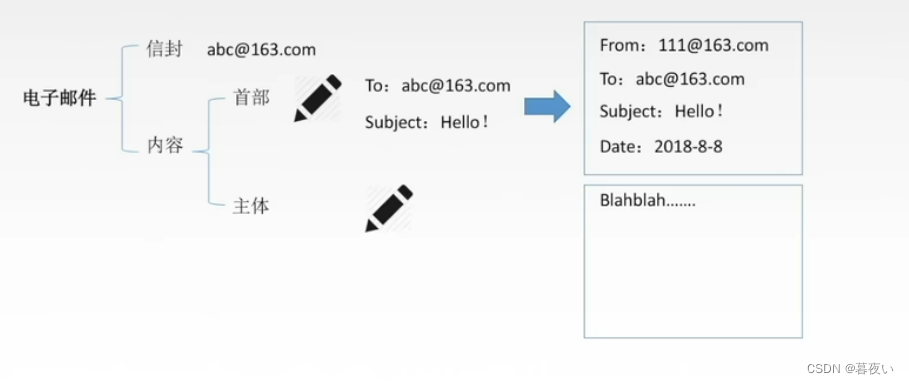
El correo electrónico es una forma de comunicación que utiliza redes informáticas que se pueden utilizar para enviar y recibir información digital a través de Internet.
Los componentes básicos de un correo electrónico incluyen un encabezado de correo electrónico y un cuerpo de correo electrónico. El encabezado de correo electrónico incluye el remitente, el destinatario, el asunto, la fecha y otra información. El cuerpo del correo electrónico es la parte principal del contenido del correo electrónico y puede contener texto, imágenes y enlaces. y otros elementos.
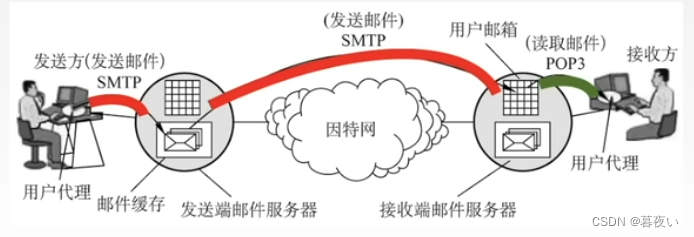
El proceso de enviar y recibir correos electrónicos generalmente requiere tres pasos: el usuario escribe el correo electrónico y lo envía al servidor de envío, el servidor de envío reenvía el correo electrónico al servidor de transferencia según la dirección del destinatario, y el servidor de transferencia luego reenvía el correo electrónico a el destinatario final.servidor de archivos.
El destinatario puede conectarse al servidor receptor a través de un programa cliente (como Outlook, Thunderbird, etc.) y descargar el correo electrónico y luego leer el contenido del correo electrónico.
El uso del correo electrónico requiere la configuración de protocolos como SMTP y POP3, que estipulan los estándares de transmisión y recepción del correo electrónico.
2.3.2 Estructura del sistema de correo electrónico
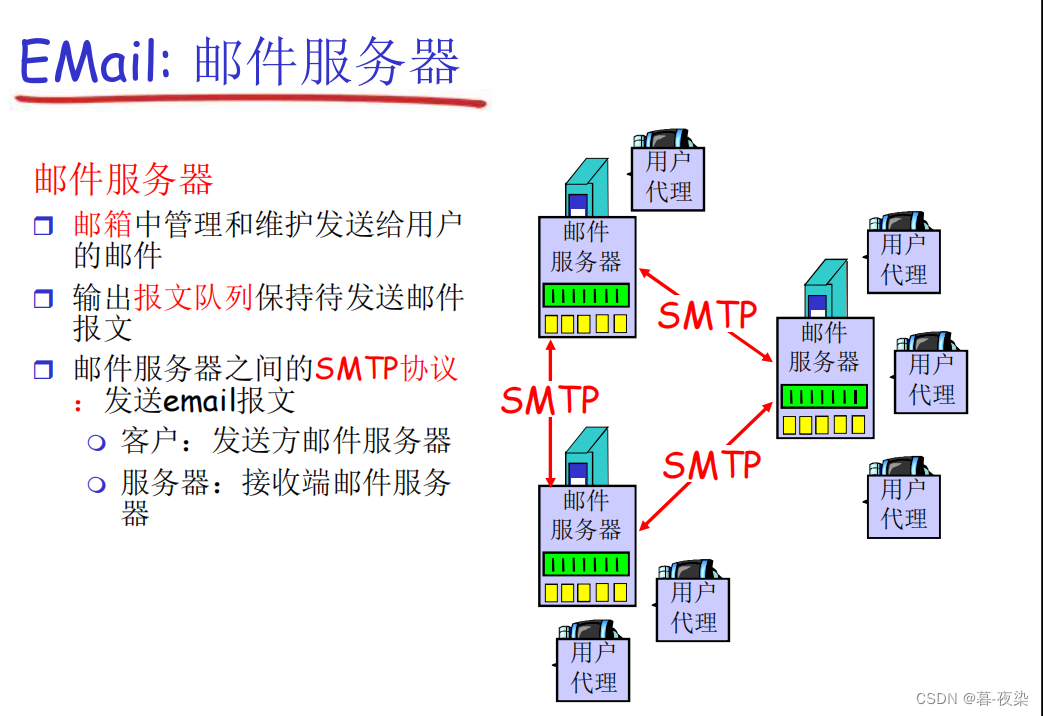
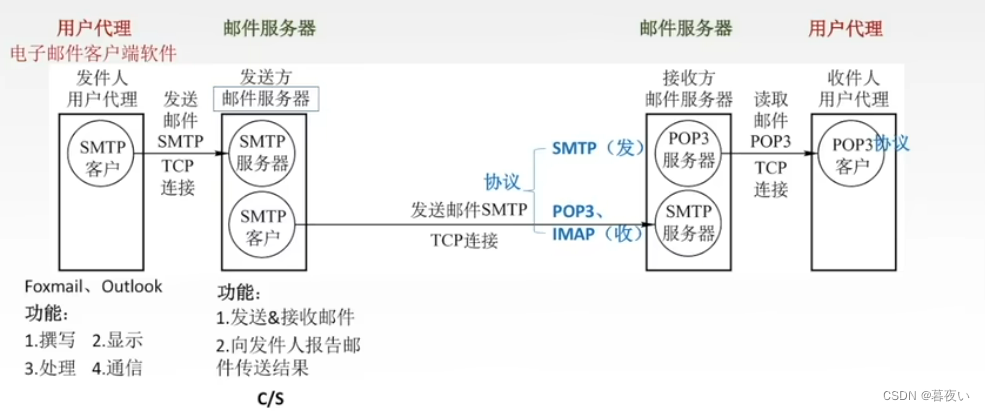
El correo electrónico incluye:Agente de usuario, servidor de correo, protocolo.
Los protocolos de correo electrónico incluyenProtocolos de envío (SMTP) y protocolos de extracción (POP3, IMAP, HTTP). Dado que el envío y la recepción de correos electrónicos son operaciones push y pull, también se les puede denominar protocolos "push" y protocolos "pull".
Remitente (agente de usuario), 发送协议SMTPservidor de correo del remitente, SMTP协议servidor de correo del receptor, 拉取协议receptor (agente de usuario).
SMTP es un protocolo "push", donde el remitente envía datos de correo electrónico a la cola de mensajes salientes del servidor SMTP;
HTTPprincipalEs un protocolo "pull" que extrae archivos del servidor en cualquier momento a través del cliente del navegador. En el correo electrónico basado en navegador web, el protocolo HTTP también puede funcionar como protocolo de envío.
- Flujo de trabajo general
2.3.3 Formato de mensaje de correo electrónico
2.3.4 Protocolo simple de transferencia de correo SMTP
SMTP (Protocolo simple de transferencia de correo) es un protocolo utilizado para la transmisión de correo electrónico.
El protocolo SMTP define el protocolo de comunicación entre el remitente y el receptor del correo electrónico durante el proceso de transmisión del correo electrónico, incluidas regulaciones sobre el formato del correo electrónico, el método de transmisión, el mecanismo de autenticación, etc.
1.Protocolo SMTP funcionando
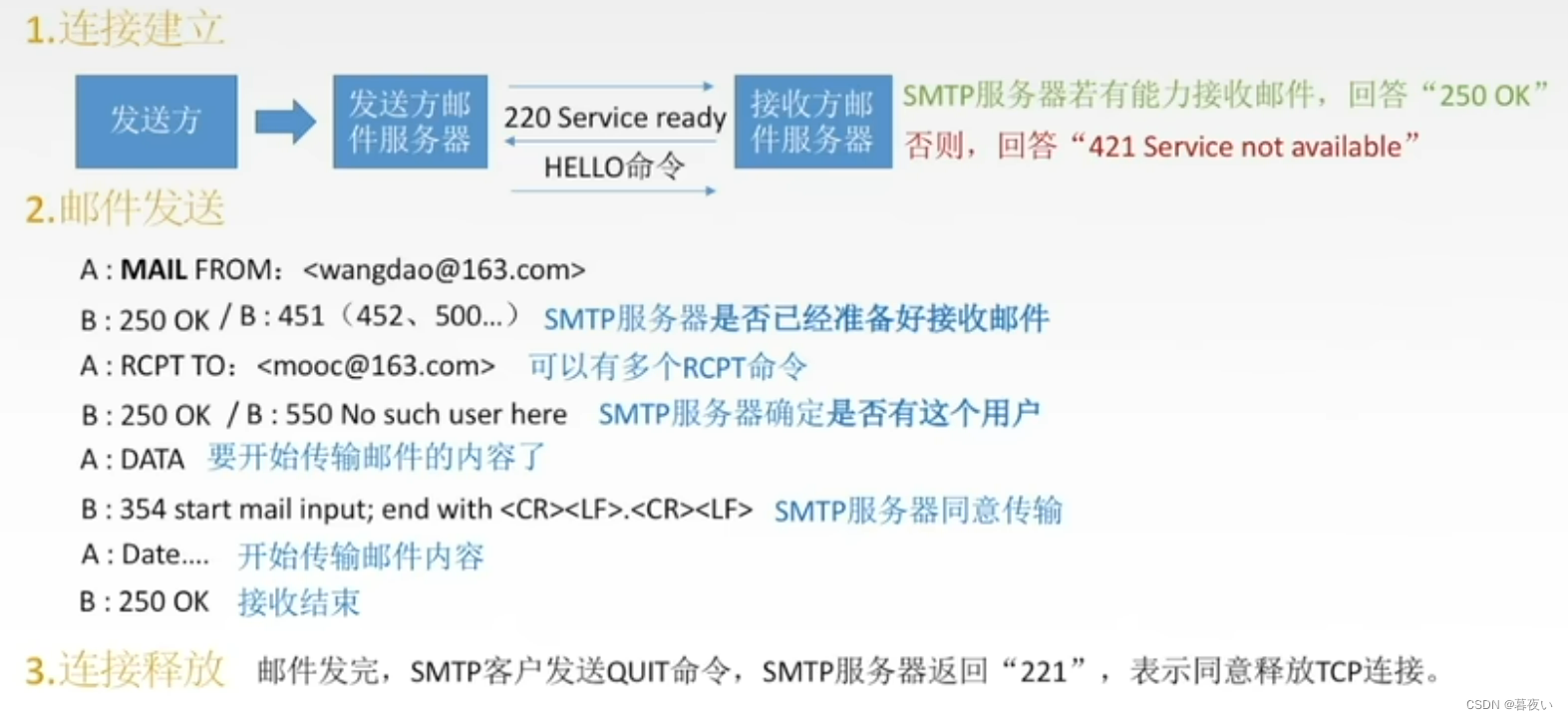
El flujo de trabajo del protocolo SMTP es el siguiente:
Protocolo de enlace de tres vías TCP.
Enviar solicitud de conexión SMTP HELO.
Enviar información del remitente CORREO SMTP DESDE.
Enviar información del destinatario SMTP RCPT A.
Enviar comando de contenido de correo electrónico DATOS SMTP.
Enviar contenido de correo electrónico.
Transferencia de correo completada, SMTP SALIR.
Hay algunos comandos de protocolo importantes en SMTP, como por ejemplo:
HELO: El nombre de host utilizado para identificarse ante el servidor receptor.
CORREO DE: Se utiliza para especificar la dirección del remitente.
RCPT TO: Se utiliza para especificar la dirección del destinatario.
DATOS: El comando SMTP DATA se utiliza para especificar el comienzo del cuerpo del correo electrónico y le indica al servidor SMTP que comience a recibir el contenido del correo electrónico. Los DATOS deben ir seguidos del texto del correo electrónico y terminar con una sola línea "."
Puntos clave:
- C/S: modo cliente/servidor
- conexión TCP
- transferencia directa
Transmisión directa desde el servidor emisor al servidor receptor, sin transferir a otros servidores para su almacenamiento. - El número de puerto
Utilice el puerto 25 por defectoLos mensajes se transmiten entre el cliente y el servidor. - etapa de comunicacion
- Conexión establecida (apretón de manos)
- Envío de correos electrónicos (transmisión de mensajes)
- Conexión liberada (cerrada)
- interacción comando/respuesta
- Comandos: texto ASCII (14 comandos, varias letras)
- Respuesta: código de estado e información de estado (21 tipos de información de respuesta: código de tres dígitos + descripción de texto simple)
- límite
- El mensaje debe ser un código ASCII de 7 bits.
- conexión persistente
- Una conexión TCP puede enviar varios correos electrónicos en secuencia y la conexión se cierra después de enviarlos todos.
2. Limitaciones

- El protocolo SMTP es insuficiente: sólo puede transmitir datos de correo electrónico ASCII de 7 bits, incluidos los encabezados y cuerpos de los correos electrónicos. Si hay datos en el correo electrónico que no han sido codificados en ASCII, se codificarán antes de la transmisión. Este diseño fue inteligente en los primeros días de Internet, porque nadie transmitía grandes flujos de datos, como vídeos, imágenes, etc., en correos electrónicos.
3. Ejemplo
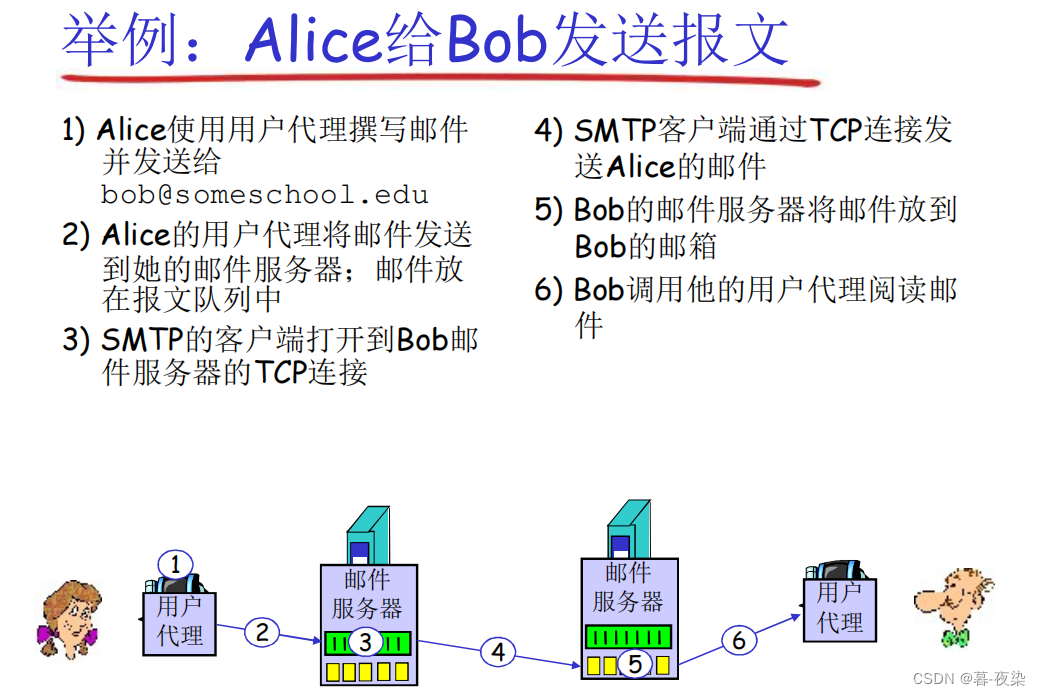
- Interacción SMTP sencilla

4. Formato SMTP
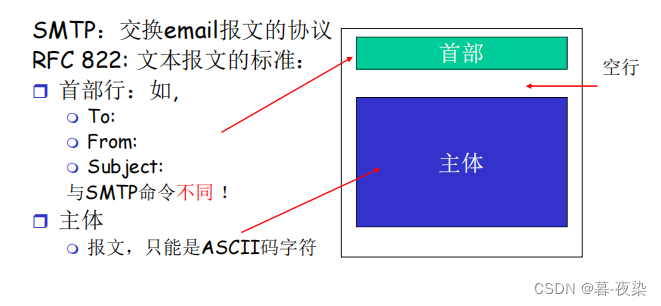
5. Resumen
HTTP es principalmente "pull", pero también puede ser "push".

2.3.5 La tercera versión del protocolo de oficina postal POP3
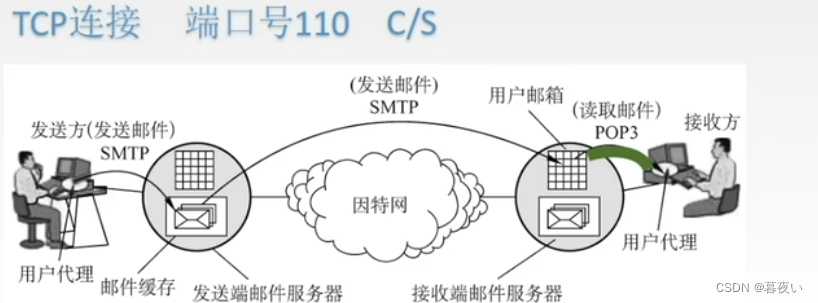
POP3 es un protocolo de acceso al correo electrónico muy simple. Cuando el destinatario lee el correo electrónico, presenta desventajas porque SMTP no admite la extracción de archivos. Nació el protocolo de lectura de correo electrónico de tercera generación POP3, que se utiliza para enviar correos electrónicos desde el servidor SMTP del destinatario al buzón del destinatario.
1. Ilustración de la posición de trabajo.
2. Método de trabajo

POP3 tiene dos modos de trabajo: descargar y retener (retenido en el servidor receptor). Este modo de trabajo permite que múltiples clientes (como teléfonos móviles, Mac, computadoras, máquinas de fax, etc.) descarguen y lean.
El método de trabajo de descarga y eliminación solo admite la descarga una vez y luego la eliminación. Por ejemplo, si recibe un correo electrónico en su teléfono móvil, no podrá recibirlo desde el servidor de correo electrónico de otros dispositivos.
3. Fase de trabajo de POP3
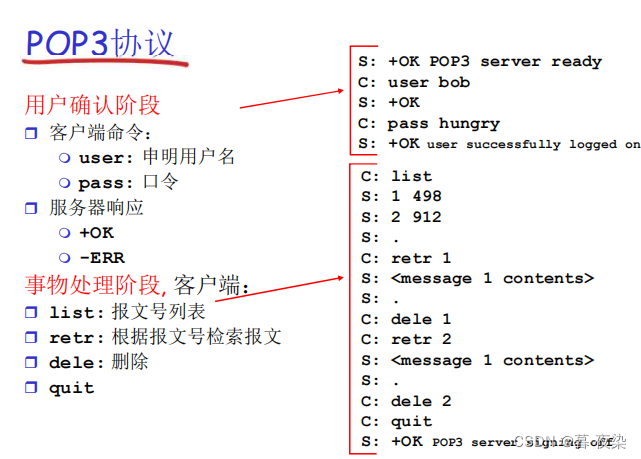
- etapa de concesión
El agente de usuario envía (Texto sin formato) nombre de usuario y contraseña para autenticar al usuario. - Etapa de procesamiento de transacciones
- El agente de usuario devuelve el mensaje
- Marcar el mensaje para eliminarlo y desmarcar el mensaje para eliminarlo
- Obtener estadísticas de correo electrónico
- etapa de actualización: Aparece después de que el usuario emite el comando salir
- Finalizar sesión POP3
- Eliminar mensajes marcados para eliminación
2.3.6 Extensión multimedia MIME
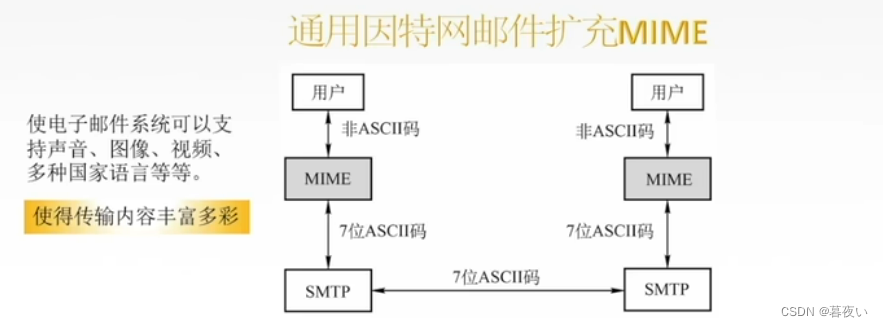
MIME admite la codificación de bytes que no son ASCII y luego los convierte a ASCII para su transmisión a SMTP. Es común codificar caracteres chinos en base64 y luego convertirlos.

2.3.7 Protocolo de acceso al correo de Internet IMAP
El protocolo POP3 no proporciona a los usuarios ningún método para crear carpetas remotas y asignar carpetas a los mensajes, para solucionar este problema se creó el Protocolo de acceso al correo de Internet IMAP.
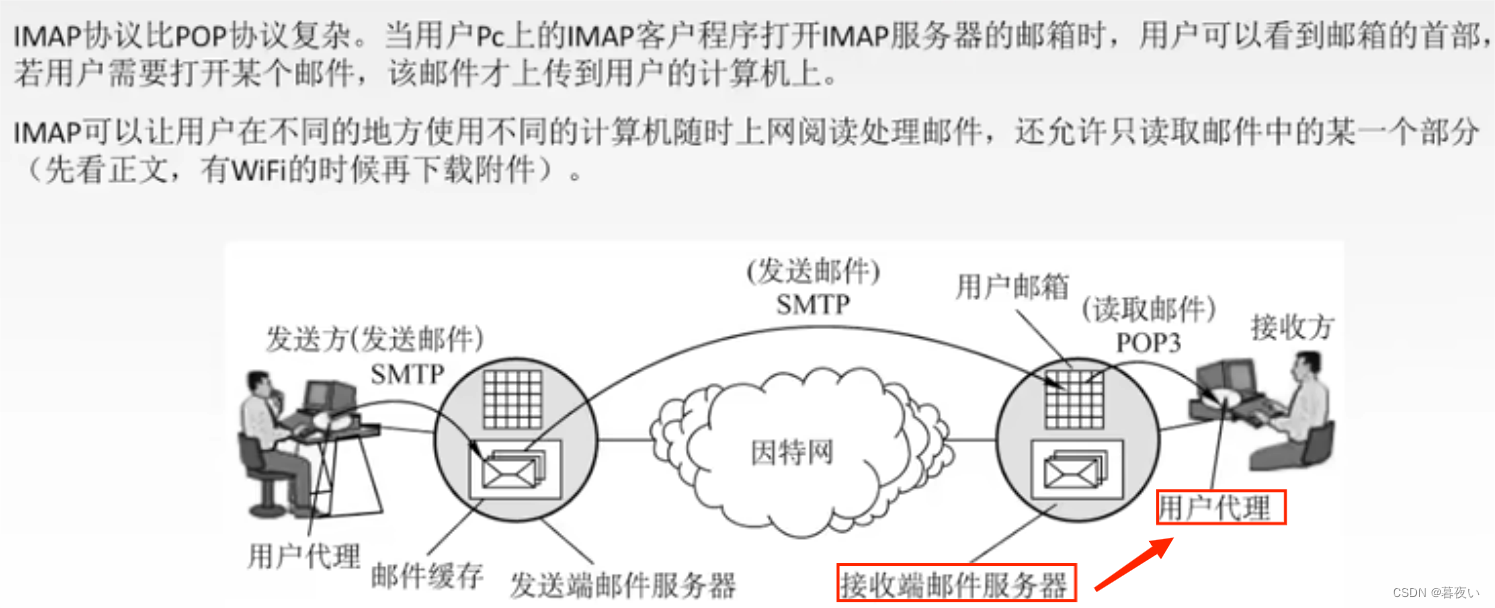
POP3 e IMAP


2.3.8 Correo electrónico basado en web
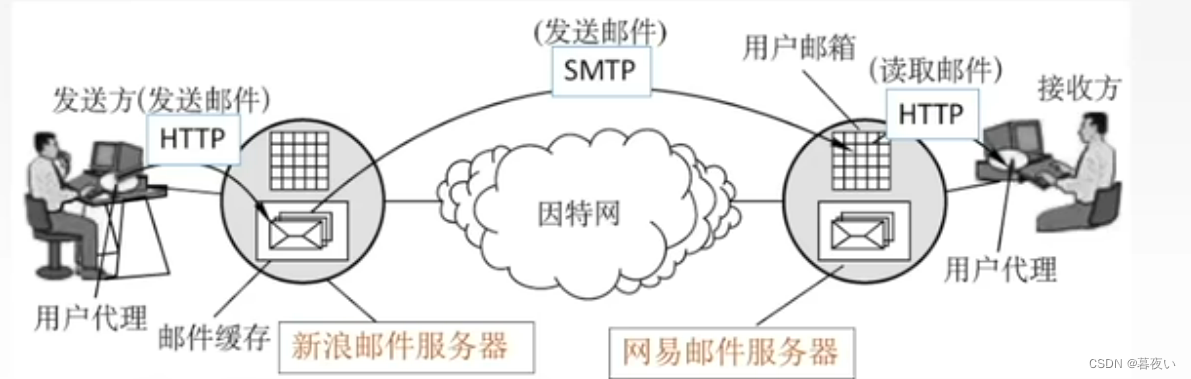
Desde el usuario hasta el servidor de correo se utiliza el protocolo HTTP, incluyendo al remitente y al receptor.. Pero 邮件服务器与邮件服务器之间的传输依然是使用SMTP协议.
2.4 DNS (Sistema de nombres de dominio)
Origen:
Hay dos formas de identificar computadoras: dirección IP y nombre de host.
Los nombres de host generalmente se aceptan porque son fáciles de recordar, pero los nombres de host brindan poca información sobre la ubicación de la computadora en Internet.
Los enrutadores prefieren direcciones IP jerárquicas y de longitud fija.
Para satisfacer estas dos necesidades, se necesita un servicio de directorio que pueda convertir nombres de host en direcciones IP, que es la tarea principal del Sistema de nombres de dominio (DNS).
Características:
- en capas, mecanismo de nomenclatura basado en dominios
- LevementerepartidoLa base de datos completa la conversión de nombres a direcciones IP.
- operandoPuerto 53 en UDPservicios de aplicaciones
- Funcionalidad básica de Internet, pero implementada como protocolos de capa de aplicación.
- Manejar la complejidad en el borde de la red (sistemas finales, capa de aplicación de hosts)
Función:

2.4.1 Nombre de dominio
- definición:
nombre de dominio(Nombre de dominio) es un servicio central de Internet. Es el nombre de una computadora o grupo de computadoras en Internet que consta de una cadena de nombres separados por puntos y adopta una estructura jerárquica.
Los nombres de dominio se componen de dos conjuntos de caracteres diferentes: ASCII y Unicode. El juego de caracteres ASCII incluye 128 caracteres como números, letras y símbolos. El conjunto de caracteres Unicode incluye textos, símbolos y símbolos de casi todos los países y regiones.
En el juego de caracteres ASCII,La longitud de cada nivel de nombre de dominio no excederá los 63 caracteres.. En el juego de caracteres Unicode, aunque no existe un límite claro en la longitud de un nombre de dominio, aún debe cumplir con las restricciones de la Especificación del sistema de nombres de dominio (DNS). Según las especificaciones DNS, la longitud de cada nivel de nombre de dominio no puede exceder los 253 caracteres.
Cabe señalar que, aunque existe un límite en la longitud de cada nivel de nombre de dominio, no existe límite en la longitud de todo el nombre de dominio.
Los nombres de dominio se pueden utilizar enLa ubicación electrónica y, a veces, la ubicación geográfica de una computadora durante la transmisión de datos.
Por ejemplo: nuestros sitios web de portal de uso común, como Sohu, Sina, etc., utilizan letras mayúsculas como nombres de dominio.
- Características
- 1.Los dispositivos de asignación de nombres en un nivel pueden tener muchos nombres duplicados., pero cada host en Internet se puede identificar de forma única combinando el nombre del host y el dominio en el que reside.
- 2.Adopción de DNSNomenclatura de estructura de árbol jerárquicamétodo

- Analiza el problema
Punto único de falla: si solo hay un servidor DNS, una vez que se daña, el impacto será enorme.
Capacidad de comunicación: un servidor DNS maneja todas las consultas DNS, lo cual es una carga de trabajo demasiado pesada.
Problemas de mantenimiento: un servidor DNS necesita mantiene registros de todos los hosts de Internet, lo que hace que la base de datos central sea enorme y también se actualizará a medida que se agreguen nuevos hosts.
Base de datos centralizada remota: Debido a que un servidor DNS no puede estar "cerca" de todos los usuarios, la propagación se producirá a través de enlaces congestionados y de baja velocidad, lo que provocará graves retrasos.

Clasificación jerárquica de nombres de dominio.
下图中 "叶" 只是一个通用代指,并不是说所有域名都归于一个主机或设备。“根”同理(Hay 13 servidores raíz DNS en total)
Desde la raíz del árbol hasta las hojas, el dominio superior tiene un puntero a su servidor de subdominio.

Los dominios de nivel superior se dividen en dos categorías:
- Genérico
- Países
Hay duplicados en las siguientes imágenes, solo eche un vistazo.
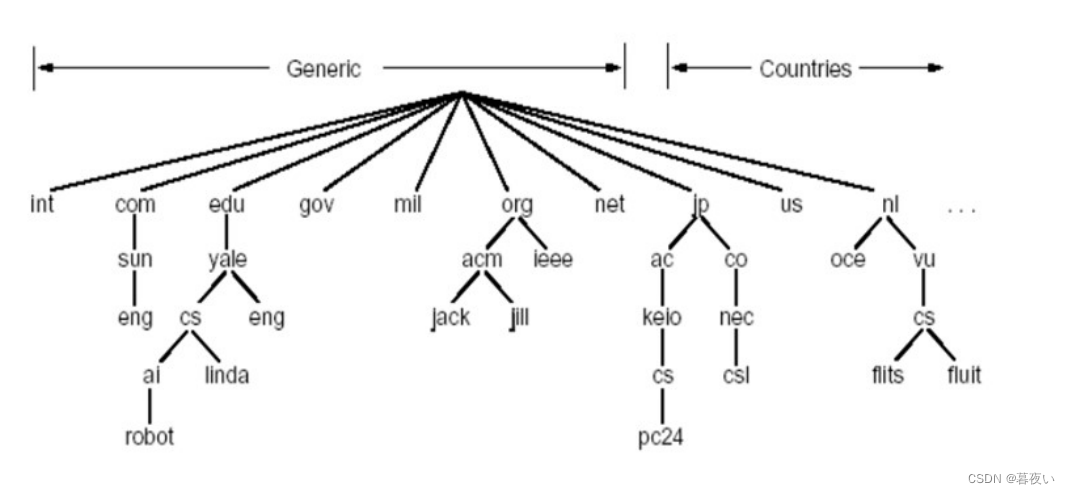
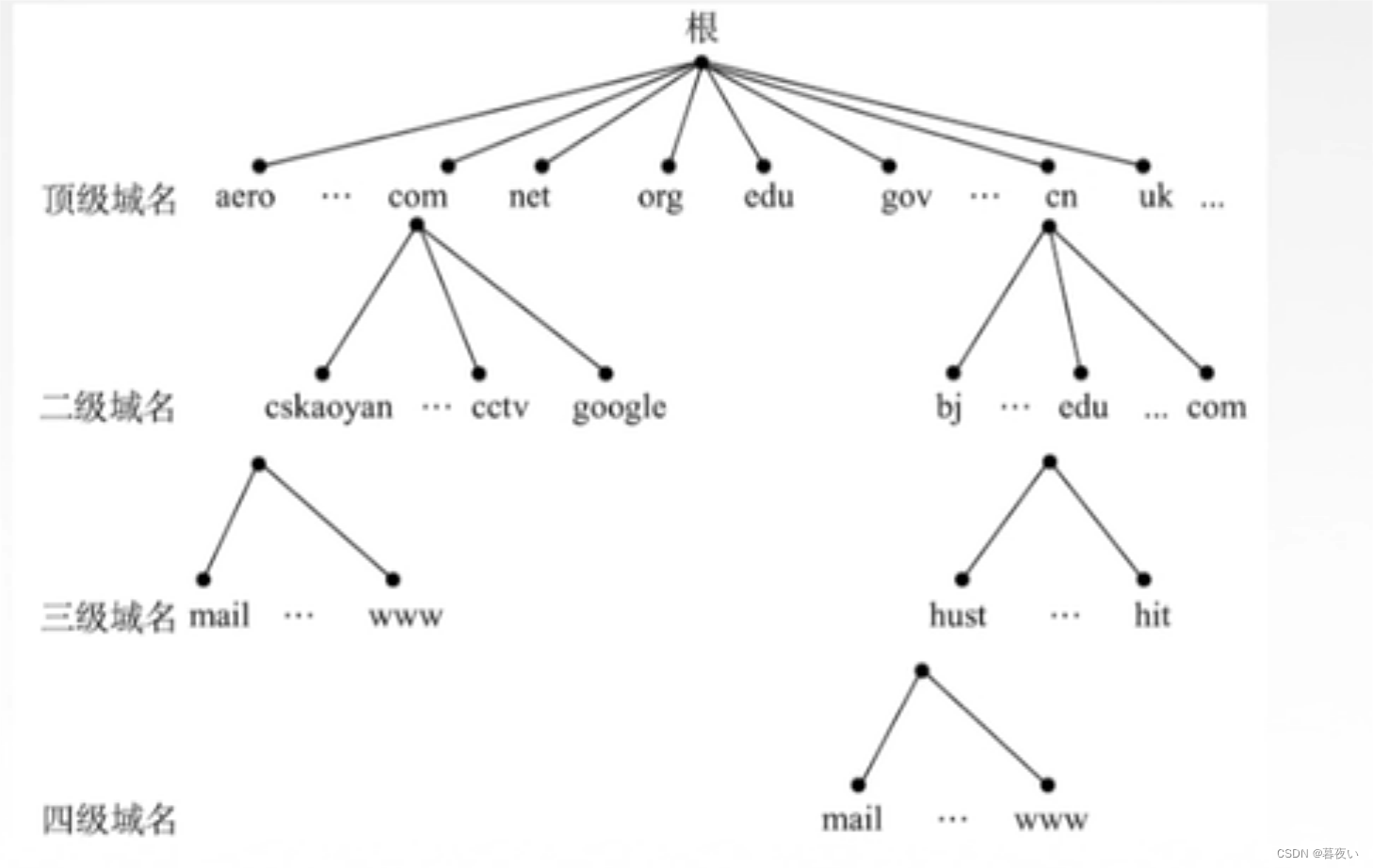
Aparece la siguiente imagenEl nombre de dominio inverso arpa se utiliza para resolver de forma inversa direcciones IP en nombres de dominio.

Las siguientes extensiones están tomadas de Baidu AI:
arpa es la abreviatura de Sistema de nombres de dominio inverso (DNS inverso), que se utiliza para resolver direcciones IP en nombres de dominio.
En Internet, una dirección IP es una dirección que identifica de forma única una computadora o dispositivo, mientras que un nombre de dominio es una cadena de caracteres que se utiliza para que las personas recuerden y accedan más fácilmente a estas direcciones. La función del sistema de nombres de dominio inverso es resolver inversamente el nombre de dominio correspondiente a través de la dirección IP.
El juego de caracteres del nombre de dominio arpa es diferente del juego de caracteres del nombre de dominio general: solo contiene números y letras, y no incluye caracteres especiales como países, regiones o símbolos.
Los nombres de dominio arpa se suelen utilizar en las siguientes situaciones:
Resolución inversa de nombres de dominio: resuelva inversamente el nombre de dominio correspondiente a través de la dirección IP, que puede usarse para la administración de la red y el monitoreo de seguridad.
Lista negra de DNS: agregue la dirección IP de malware o atacantes de red a la lista negra de nombres de dominio arpa para restringir su acceso a los recursos de la red.
Servidor de correo: el nombre de dominio arpa se utiliza para que el servidor de correo facilite la recepción y el envío de correos electrónicos.
Nombre de dominio temporal: cuando un nombre de dominio se elimina o caduca, es posible que aún sea necesario acceder a su dirección IP. En este momento, el nombre de dominio arpa se puede utilizar como reemplazo temporal.
需要注意的是,arpa域名的使用需要遵守特定的规范和标准,例如逆向DNS解析协议(DNS Reverse Resolution Protocol)等。
域名的构成
-
命名设备的域名
主机名.第N级域名.(…).第二级域名.顶级域名
从树叶开始,每过一个层级用句点分隔开。 -
命名一个域的域名(对某个域做标识)
从树枝开始到顶级域。
如:ustc.edu.cn (中国科技大学域名)
注:(少数采用)设备也可以直接挂在顶级域名或二级域名之下,不必非要顺着所有域层级来命名。
如:
- mit.edu
- xxx.gov
域名管理
.cn:中国的一个顶级域名
.jp:日本的一个顶级域名

2.4.2 域名服务器
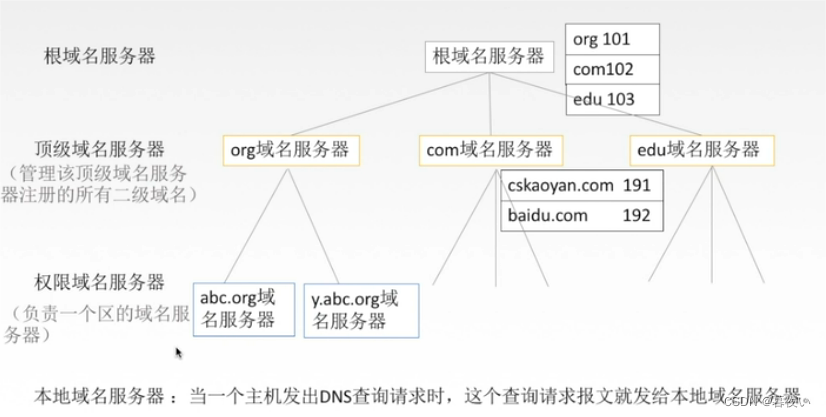
DNS:根名字服务器
互联网共有13个根服务器 (分布在:欧洲,北美(大部分),日本),不同国家域名划分不一定一样。
权威服务器
-
前置
为了解决域名的维护(域名到IP地址转换)和解析问题,划分出区域(zone)的概念:
 下图中每个圈就是一个区域。
下图中每个圈就是一个区域。

-
定义
 是否是某个域的权威DNS服务器看是否维护中这个区域的域名到IP地址对应关系
是否是某个域的权威DNS服务器看是否维护中这个区域的域名到IP地址对应关系
权威服务器 :清楚本区域内部域名与IP对应关系
TLD服务器

本地名字服务器(Local Name Server)
地址使用手工配置或动态配置

名字服务器(Name Server)

2.4.3 DNS工作机理方面
1. DNS缓存
为了改善时延性能并减少在互联网上传输的DNS报文数量,DNS广泛采用了缓存技术。
- 原理
在一个请求链中,DNS服务器收到一个DNS应答(如包含某个主机名到IP地址的映射)时,它能将映射缓存在本地存储器中。
由于主机和主机名与IP地址间的映射不是永久的,DNS服务器在一段时间后(通常设置为两天),将丢弃缓存信息。
- 产生的影响
本地服务器也能缓存 TLD 服务器的 IP 地址,因而允许本地DNS绕过查询链中根DNS服务器。事实上,由于缓存的存在,除了少数DNS查询以外,根服务器被绕过了。
2. 资源记录
共同实现DNS分布式数据库的所有DNS服务器存储了资源记录(Resource Record,RR):提供主机名到IP的映射。
资源记录是一个包含了下列字段的四元组:
(Name,Vaule,Type,TTL),具体见下图:

资源记录可以类比于数据库的记录方法
- TTL(生存时间 time to live):是指某个记录的生存时间,决定了某个资源记录删除的时间。
- 1.TTL为无限大:指权威值
- 2.TTL为有限值: 指缓冲值
下面给出的例子,忽略掉TTL字段。Name和Vaule的值取决于Type:
(结构图)

(原书)

- 资源记录的一个例子:

3. DNS工作过程:
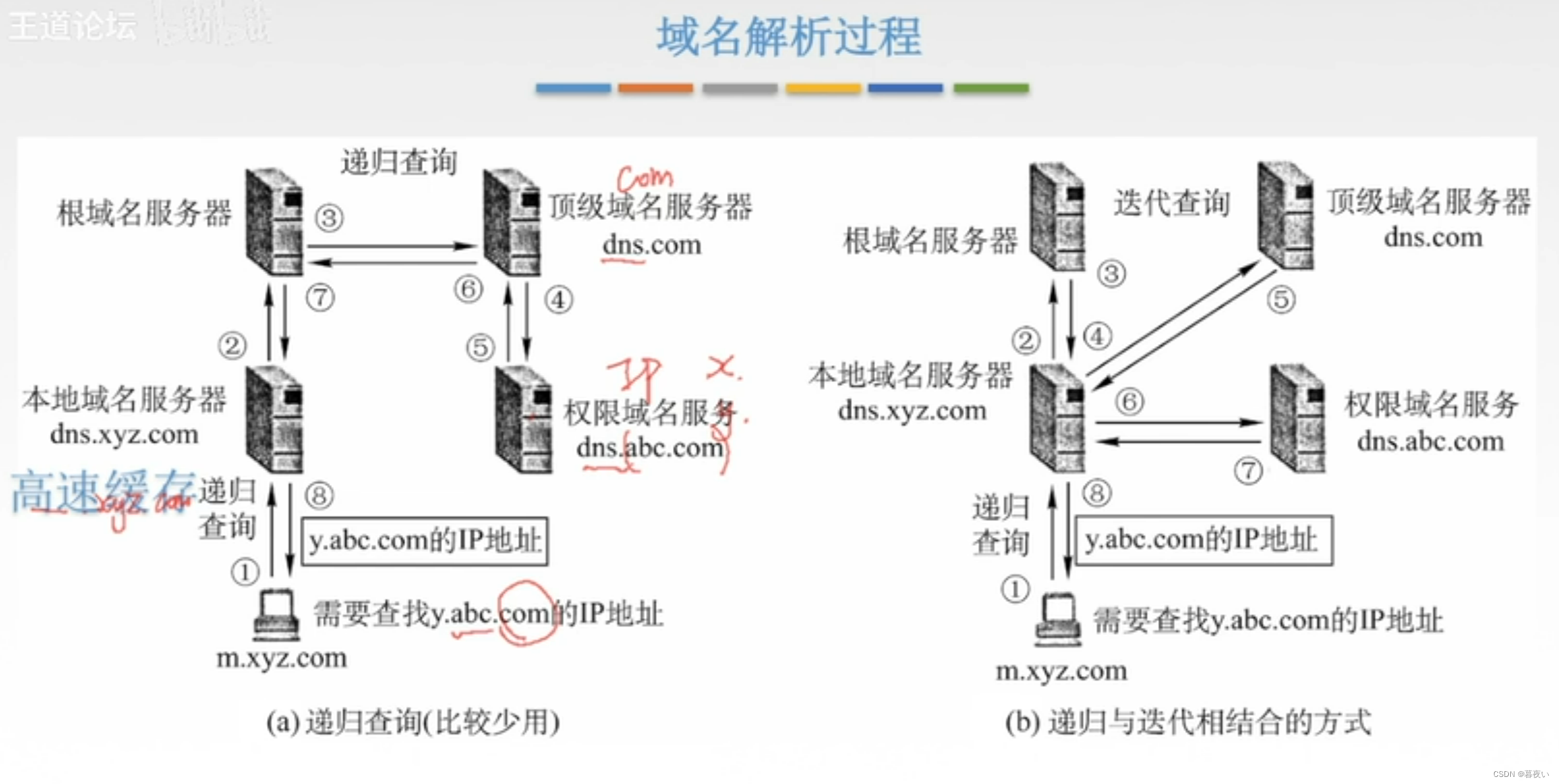
查询
如果本地服务器有缓存,则直接返回缓存信息(主机与IP映射)。如果没有缓存,需要查询具体映射。
查询方法有以下两种:
- 递归查询
- 迭代查询
递归查询
简单来说就是主机任意找一个根服务器,由于通常上一级知道下一级信息,然后从根服务器开始一级一级往下查找,直到最终查到结果。

迭代查询
上一级不会明确下一级的信息,但会有一个指定方向,相当于"踢皮球"。
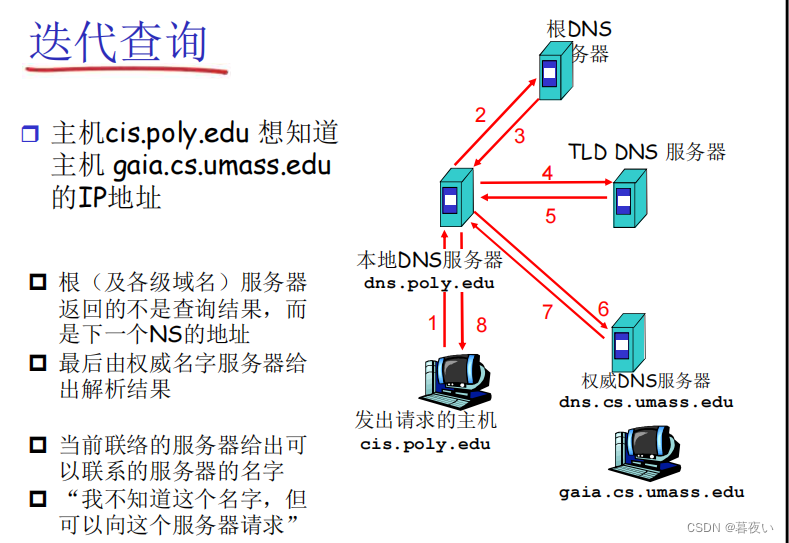
4. DNS协议与报文
DNS报文有查询报文和回答报文两种,它们的格式都是相同的。结构如下图:
idenfication即id号

(原书参考)


5. 维护问题:新增域

2.4.4 DNS安全问题

总的来说,DNS比较健壮
2.5 CDN
1. 因特网视频
视频
- 定义:一系列以恒定速率(如每秒24或30张图像)来展现的图像。
- 特点:可以被压缩(因而可以用比特率1来权衡视频质量)
一幅未压缩,数字编码的图像由像素阵列组成,其中每个像素是用来表示颜色和亮度的比特编码。
- 比特率与音、视频压缩的关系:
比特率越高,传送数据速度越快,简单的说就是比特率越高,音、视频的质量就越好,但编码后的文件就越大;如果比特率越少则情况刚好相反。- 例如:低质量视频:100kbps;流式高分辨率电影:超过3Mbps;用于4K流式展望的超过10Mbps。


视频流
视频流是指将视频数据以流的形式进行传输。这种传输方式可以实时观看视频内容,而不需要等待整个视频文件下载完成。视频流技术使用了流媒体协议,例如HTTP Live Streaming(HLS)和Real-time Messaging Protocol(RTMP)等,使得视频可以在各种设备上流畅播放。视频流技术广泛应用于在线视频播放、直播、视频会议等领域。
流式视频
- 定义:
流式视频是指在数据通过互联网到达计算机的同时在显示器上播放的网络视频。与可下载的互联网视频不同,流媒体形式在收到压缩数据后即开始播放,从而消除了下载时可能伴随病毒的担忧。但是,由于视频在接收数据时播放,视频可能会被慢速连接中断,并可能会自动暂停并重新启动,以尝试"缓冲"数据。此外,与可下载视频不同,流式视频不会"保留"在计算机上;只有当主网站决定继续发布视频时,才可以访问流式视频到网站。
因此,视频流是一种传输方式,而流式视频是一种播放方式。视频流可以以流式视频的方式进行播放,而流式视频必须使用视频流技术进行传输。
- 性能度量:平均端到端吞吐量
平均端到端吞吐量是指单位时间内成功地传送数据的数量,也就是传输速率。吞吐量和带宽是两个不同的概念,带宽是指链路的能力,单位是比特每秒(bps),是设计值;而吞吐量是实际测试的传输速率,单位也是bps。平均端到端吞吐量通常用来衡量网络传输性能,可以通过网络延迟、传输速度等指标来评估。
- 例子:使用流式视频的公司:Netflix,YouTube(谷歌),亚马逊和优酷等。
2. HTTP流和DASH
2.1 HTTP流
-
定义:
HTTP流(HTTP streaming)是一种在HTTP协议下进行实时数据传输的技术。它允许服务器将数据以流的形式发送给客户端,而无需等待整个响应完全生成。这种方式可以实现实时性要求较高的应用,如视频直播、音频流传输等。HTTP流可以通过多种方式实现,包括长轮询、服务器推送事件(Server-Sent Events)和WebSocket等。这些技术都允许服务器主动向客户端发送数据,而不需要客户端主动请求。HTTP流的实现可以提供更好的用户体验和更高效的网络通信。 -
特点:
在HTTP流中,视频只是存储在HTTP服务器中作为一个普通文件,每个文件有一个特定的URL -
HTTP流播放视频的工作原理:
-
1.客户端发起请求
客户端使用HTTP协议向服务器发起视频播放请求(TCP连接)。请求中通常包含视频的URL或其他必要的参数。
-
- 服务器响应
服务器接收到客户端的请求后,开始准备视频数据。服务器使用一种支持流式传输的视频格式,如MPEG-DASH(Dynamic Adaptive Streaming over HTTP)或HLS(HTTP Live Streaming)。
-
- 客户端接收和播放
客户端接收的视频字节被收集在应用缓存中,当缓存中的字节数量超过设定门限时,客户应用程序开始播放。特别的,流式视频应用程序周期性的从客户应用程序缓存中抓取帧,对这些帧解压缩并呈现在用户屏幕上,因此,流式视频应用接收到视频就开始播放,同时缓存视频后面部分的帧。
通过以上步骤,HTTP流播放视频实现了实时的视频传输和播放。这种方式可以根据网络条件和设备性能进行自适应调整,提供更好的观看体验。同时,使用分段传输的方式,可以在保证视频连续播放的同时,提高网络传输的效率。
- 缺点:尽管对不同客户或相同客户的不同时间而言,可用带宽大小不同,但是所有用户接收到相同编码的视频。(这导致了新型的基于HTTP流的研发,即DASH)
2.2 DASH
DASH(Dynamic Adaptive Streaming over HTTP)(基于 / 经HTTP的动态适应性流)
使用DASH后,每个视频版本存储在HTTP服务器,每个版本都有一个不同的URL
- 特点:
- 在DASH中,视频编码分为几个不同版本,每个版本具有不同比特率,对应不同的质量水平。
- 客户请求:客户端动态地请求来自不同版本且长度为几秒的视频数据块。
使用HTTP GET请求报文一次选择一个不同的块。 - 带宽与版本:
- 带宽较高时:高速率的版本块
- 带宽较低时:低速率的版本块
- 带宽变化适应性:如果端到端的带宽在会话过程中发生改变,DASH允许客户适应可用带宽。(例如:当移动用户相对基站移动时,能感觉到带宽波动。)
- 告示文件(manifest file):

- 总述


3. 内容分发网CDN
对于一个因特网视频公司提供流式视频服务最直接的方法或许时建立一个单一的大规模数据中心,存储所有视频,并向全世界范围客户传输流式视频。
但存在三个问题:
1.出现停滞时延的可能性随中间通信链路数量增加而增加。
2.流行的视频可能经过相同通信链路多次发送,导致网络带宽的浪费和公司需要给ISP的费用增加。
3.单点故障。数据中心崩溃则无法发送视频。


3.1 CDN

-
定义:
内容分发网 (CDN : Content Delivery Network)是一种分布式网络系统,通过将内容缓存到多个地理位置和服务器上,以提高网站或其他互联网应用的性能和可靠性。 -
分类:
专用CDN,由内容提供商自己所有。例如,谷歌的CDN分发YouTube视频和其他类型内容。
第三方CDN,代表多个内容提供商发表内容。 -
CDN的工作原理:将网站的内容分发到靠近用户的地方,以便用户可以快速获取所需的内容。这可以通过将内容存储在分布在全球的各个节点上实现。
当用户请求网站内容时,CDN会根据用户的地理位置和网络条件选择最合适的节点将内容传递给用户。 -
CDN的主要优点包括:
性能提升:CDN可以将内容存储在靠近用户的地方,从而减少内容的传输延迟和网络拥塞,提高用户访问网站的速度和性能。 可靠性增强:CDN可以通过多个节点同时提供内容,如果某个节点出现故障或网络故障,其他节点可以自动接替, 确保用户可以继续访问网站。 安全性提高:CDN可以提供DDoS攻击防护、CC攻击防护等安全服务,保护网站免受网络攻击。 节省成本: 使用CDN可以减少服务器负载和带宽成本,提高网站的成本效益。
CDN被广泛用于各种互联网应用,如网站、视频流媒体、游戏等,可以提高用户体验和网站性能。
- 服务器安置原则
-
深入

-
邀请做客

-
3.2 CDN操作
客户端使用浏览器指令检索特定视频(由URL标识)时,
CDN必须截获该请求以便能够:
1.确定适合的CDN服务集群。
2.将 客户请求重定向到该集群某台服务器。
大多数CDN利用DNS来截获和重定向请求。如下图示:
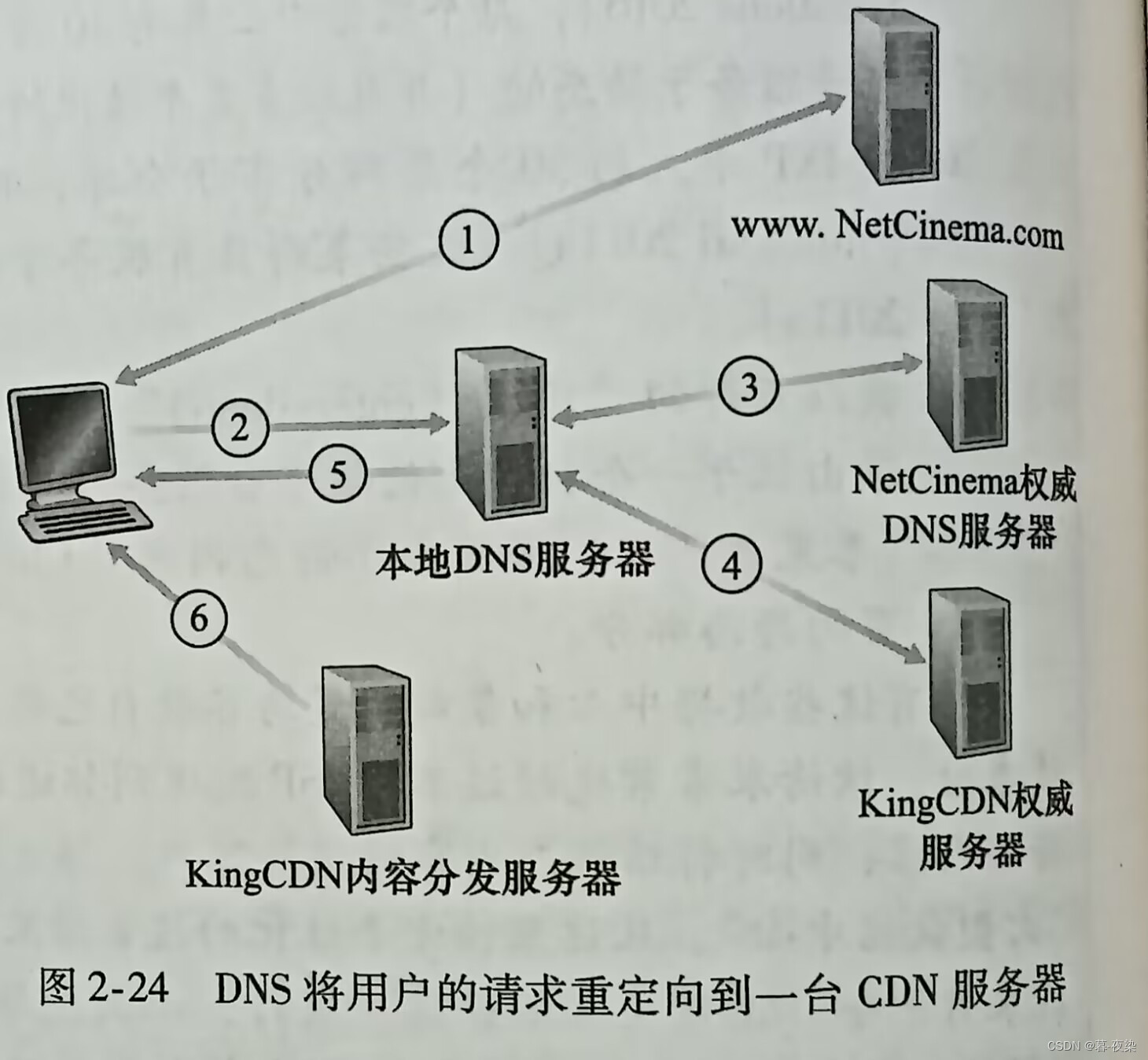
- 1.用户访问目标URL的网页
- 2.用户主机发送DNS请求
- 3.本地DNS服务器(LDNS)把DNS请求中继给权威服务器,并得到一个KingCDN域的主机名
- 4.LDNS发送第二个请求,发送对象为3步骤得到的主机名,并得到IP地址
- 5.LDNS向转发内容服务CDN的IP地址
- 6.客户接受到IP后创建TCP连接,并发送HTTP GET请求。
3.3 集群选择策略
CDN的集群选择策略是CDN部署的核心之一,目的是将客户定向到CDN中某个服务器集群或数据中心的机制。常见的集群选择策略包括:
地理最近策略:指派客户到地理上最为临近的集群,这种选择策略忽略了时延和可用带宽随因特网路径时间而变化,总是为特定的客户指派相同的集群。
实时测量策略:基于集群和客户之间的时延和丢包性能执行周期性检查,这种策略可以实时测量集群和客户之间的网络路径,并根据测量结果选择最优的集群。
此外,还有其他集群选择策略,如基于负载均衡的策略、基于DNS解析的策略等。总之,CDN的集群选择策略是为了提高网站的性能和可靠性,根据不同的因素选择最优的集群,并提供更好的用户体验。
4. 学习案例
4.1 案例学习: Netflix视频分发
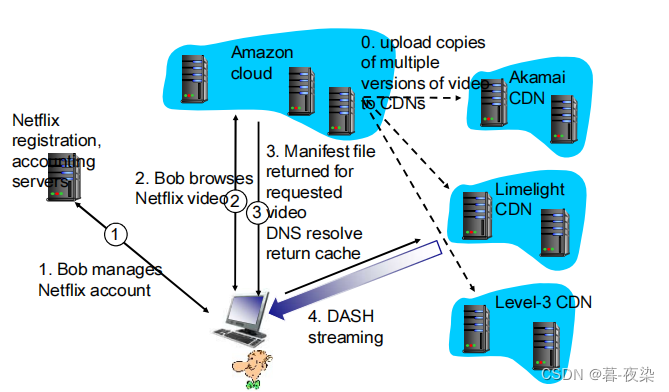
- 主要部件:亚马逊云,专用CDN基础设施
- 亚马逊云处理的关键功能:
- 1.内容摄取:用户分发电影之前,Netflix必须首先获取和处理该电影。接收电影母带并上载到亚马逊云主机。
- 2.内容处理:为每部电影按不同格式和比特率生成不同的版本,允许使用DASH经HTTP适应性播放流。
- 3.向其CDN上载版本:某电影所有版本生成后,亚马逊云中的主机向其CDN上载它们。
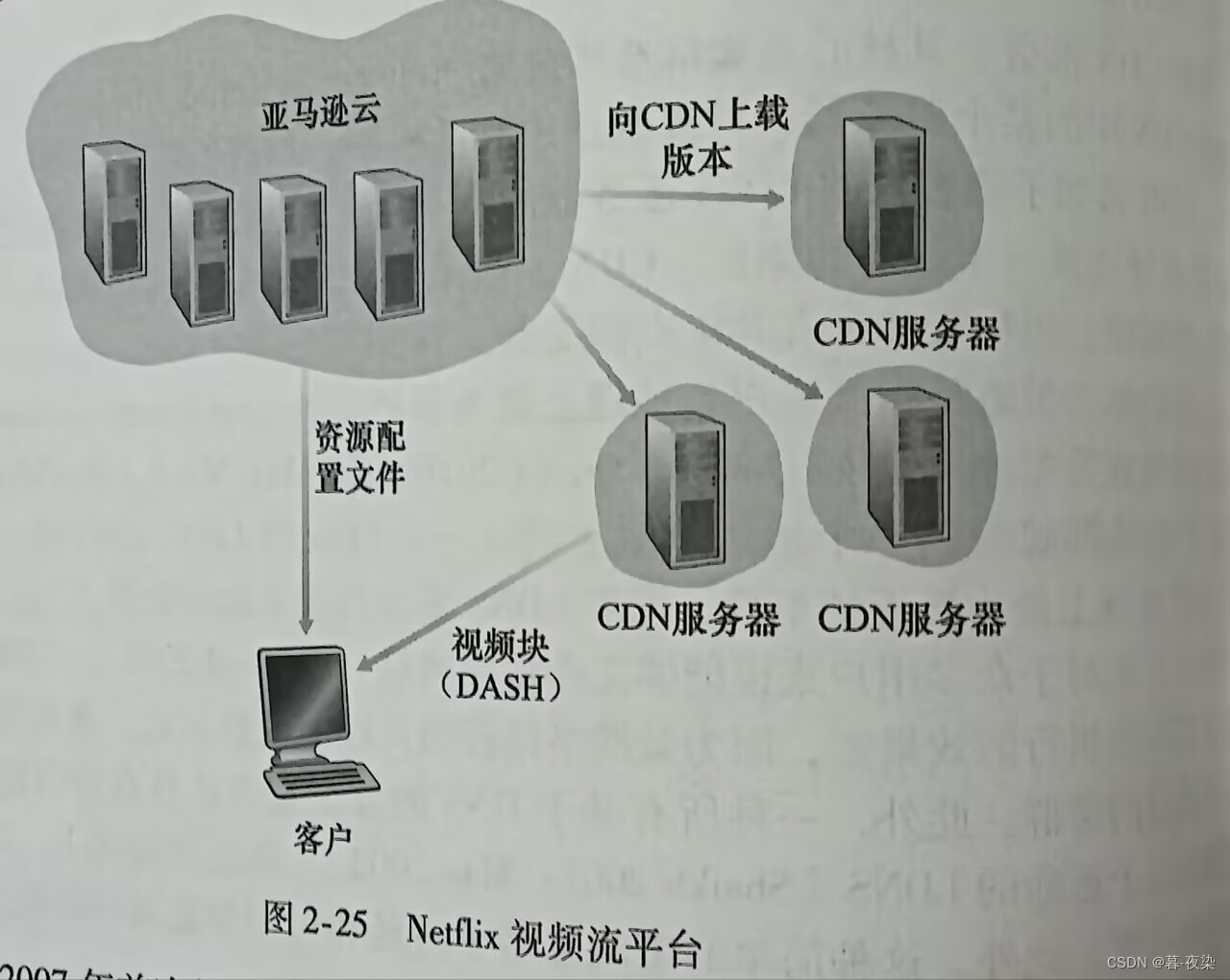
- 补充:Netflix创建了自己专用的CDN,现在它从这些专用CDN发送它所有的视频,(Netflix仍使用Akamai来分发它的Web网页。)所以Netflix已经能够简化并定制其CDN设计。
- 特点:
- 1.包含适应性流和CDN分发
- 2.不需要使用DNS重定向将特殊用户连接到一台CDN服务器;相反,Netflix软件(运行在亚马逊云中)直接告知该用户使用一台特定CDN服务器。
- 3.Netflix CDN使用推高速缓存而不是拉高速缓存:内容在非高峰时段的预定时间被推入服务器,而不是在高峰缓存未命中时动态地被推入。
推高速缓存和拉高速缓存都是网络缓存的一种,主要用来缓解网络延迟和提高数据传输速度。
推高速缓存是指将数据从服务器推到客户的浏览器,当客户需要这些数据时,浏览器直接从缓存中获取,而不需要再次从服务器下载。一些浏览器会将经常访问的网页缓存到本地,以减少网络延迟和提高访问速度。
拉高速缓存是指客户浏览器发起请求时,服务器将数据缓存在本地网络中,当客户需要这些数据时,直接从本地网络中获取,而不需要再次从服务器下载。这种方式常用于视频、图片等大数据的缓存,可以减少网络延迟和提高数据传输速度。
总的来说,推高速缓存和拉高速缓存都是为了提高网络性能,减少网络延迟,提高数据传输速度。
4.2 案例学习: Youtube
2005年4月开始服务,在2006年11月被谷歌公司收购。谷歌/Youtube设计和协议是专用的。
- 特点:
- 谷歌使用专用CDN分发视频,从几百个ISP和IXP位置安装服务器集群及它的数据中心分发Youtube的视频。
- 使用拉高速缓存和DNS重定向
- 选择策略:大部分时间,谷歌的集群选择策略将客户定向到某个集群,使客户与集群之间RTT最低。但有时为了平衡经集群的负载,有时客户经DNS被定向到更远的集群。
- 没有应用适应性流(如DASH),要求用户人工选择版本。
- Para ahorrar
将被重定向或提前终止ancho de banda y recursos del servidor desperdiciados , utilice solicitudes de rango de bytes HTTP para limitar el flujo de datos transmitido después de obtener la cantidad objetivo de vídeo .
4.3 Estudio de caso: Eche un vistazo
Mire (propiedad y administración de Xunlei) que utiliza entrega P2P en lugar de entrega cliente-servidor.
- Funciones de transmisión de vídeo P2P:
- Cuando un par solicita ver un video, se comunica con un rastreador para encontrar otros pares que tengan una copia del video y les solicita fragmentos del video.
- Solicitar que se dé prioridad a los próximos fragmentos para garantizar la reproducción continua

La velocidad de bits se refiere a la cantidad de bits transmitidos por segundo, en bps (bits por segundo). Indica cuántos bits se necesitan para representar los datos de audio y vídeo codificados (comprimidos) por segundo, y el bit es la unidad más pequeña en binario, ya sea 0 o 1. ↩︎