
Auteur | Fei Binjie, PDG d'Entropy Technology
Depuis le lancement de ChatGPT en décembre de l'année dernière, le développement de l'IA est officiellement entré dans la voie rapide, et l'ensemble de l'industrie a commencé à "itérer quotidiennement". Depuis 1957, après que l'humanité a connu plusieurs séries de vagues d'IA, cette fois l'Intelligence Générale Artificielle (IAG) arrive vraiment.
Notre équipe a publié une analyse approfondie des principes techniques de ChatGPT en février, qui a été largement reconnue par les experts et amis de l'industrie. Mais avec l'approfondissement de la recherche, de plus en plus de problèmes surgissent :
Une raison importante de la puissance de ChatGPT est la capacité émergente du grand modèle de langage (capacités émergentes), alors pourquoi la capacité émergente est-elle apparue ?
Quelles performances inattendues le GPT-5 aura-t-il ?
Où ira AGI, et quel impact aura-t-il sur les activités sociales et économiques ?
Dans cet article, nous menons une discussion approfondie sur les questions ci-dessus et donnons un processus d'analyse aussi détaillé que possible. Cet article condense les résultats de recherche de notre équipe et se divise en quatre parties :
L'essence d'un grand modèle de langage : un puissant compresseur sans perte
L'information visuelle est une riche mine de connaissances : du texte à la multimodalité
Pénurie de données à l'ère du Big Data : utiliser des données synthétiques pour briser la situation
L'impact des AGI sur les activités sociales et économiques humaines : perspective et réflexion
Écrit au recto : Entropy Jane Technology est une société technologique qui aide les institutions de gestion d'actifs à réaliser la numérisation de la recherche en investissement. Ses principaux clients sont CICC, CITIC, GF, Jiantou, Guoxin, China Merchants, Huaxia, Harvest, Yinhua, Bosera , Huihui Tianfu, Xingquan, E Fund et d'autres titres et sociétés de fonds. Je suis Fei Binjie, le fondateur d'Entropy Jane Technology, mais lorsque j'écris cet article, je suis plus purement un témoin et un participant à la fois excité et nerveux sous la vague des nouvelles technologies, le plus objectivement possible. Examinez et analysez l'impact et l'impact de cette nouvelle technologie sur notre industrie. Le partage suivant est le résultat de la recherche de notre équipe Entropy Jane. Le développement de la technologie LLM change chaque jour qui passe. Il est inévitable que l'analyse à l'heure actuelle soit erronée. Bienvenue pour me corriger.
01
L'essence d'un grand modèle de langage : un puissant compresseur sans perte
Lors de la récente session de partage académique OpenAI, Jack Rae a avancé une conclusion importante : l'essence du grand modèle de langage est en fait un puissant compresseur sans perte de données.
LLM = Compression
Cette affirmation n'est pas très intuitive, mais elle révèle un pan très important de "l'intelligence artificielle générale", qui mérite une grande attention. Afin de permettre à chacun de comprendre ce point de vue, nous discutons à partir de la question de "l'apprentissage" lui-même.
Depuis le siècle dernier, les humains croient généralement que "l'apprentissage" est un talent humain unique et que les machines ne peuvent pas vraiment maîtriser la "capacité d'apprentissage". Avec le développement de la technologie des réseaux de neurones profonds, les gens construisent des "neurones artificiels" pour simuler des "neurones biologiques" dans le cerveau, de sorte que la machine commence à avoir une certaine capacité d'apprentissage .
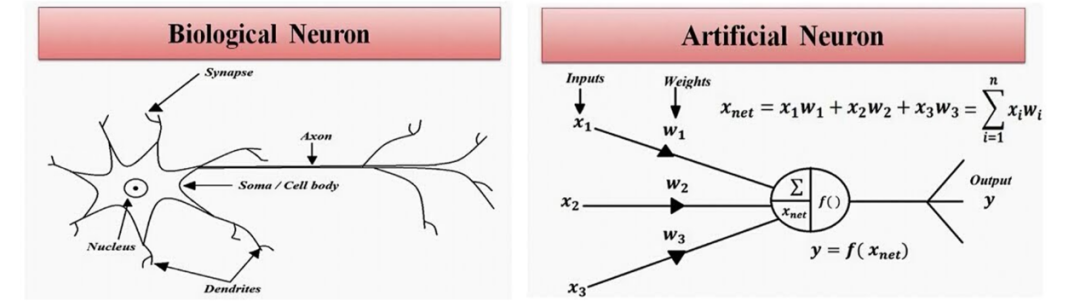
Figure : Comparaison des neurones biologiques (à gauche) et des neurones artificiels (à droite)
Maintenant, OpenAI est arrivé à la dernière conclusion sur "l'apprentissage": "l'apprentissage" lui-même peut être compris comme un processus de compression sans perte d'informations efficaces .
Pour mieux comprendre cette idée, faisons une expérience de pensée. Supposons que nous ayons besoin de créer un modèle pour gérer les tâches de traduction de l'anglais vers le chinois.
La manière la plus simple et grossière est de lister les chinois correspondant à chaque mot anglais, c'est-à-dire la cartographie basée sur des règles . Supposons que nous énumérions le tableau de comparaison chinois de tous les mots anglais et écrivions un dictionnaire de 1000 pages.
Mais avec ce dictionnaire, pouvons-nous vraiment accomplir efficacement toutes les tâches de traduction de l'anglais vers le chinois ? la réponse est négative. Parce que le système de mappage basé sur des règles est très fragile , tant qu'un nouveau mot qui n'a pas été rencontré auparavant est rencontré dans le processus de traduction, le système tombera en panne.
Par conséquent, les performances de traduction de ce modèle sont très faibles, ce qui peut être compris comme "le modèle n'a pas vraiment appris à traduire".
Voici le point important, maintenant "compressez sans perte" ce dictionnaire de 1 000 pages en un manuel de 200 pages. Le nombre de mots a été réduit, mais la quantité d'informations ne doit pas être inférieure , vous ne pouvez donc pas simplement extraire 200 pages de 1000 pages pour former un "petit dictionnaire", mais vous devez effectuer un codage de grande dimension sur les données pour obtenir sans perte compression .
Dans ce manuel de 200 pages après compression, il ne s'agit plus d'un simple mappage de mots, mais d'une grammaire anglaise comprenant sujet-verbe-objet, complément défini, mode subjonctif, temps, singulier et pluriel. Comparé à un "dictionnaire" , il ressemble plus à un "manuel" .

Figure : Réduire la longueur de la description de la tâche équivaut à améliorer la compréhension de la tâche
Notez que dans ce processus de compression, "l'apprentissage" en tant que processus implicite joue le rôle d' encodage des connaissances . En compressant un dictionnaire de 1 000 pages dans un manuel de 200 pages, le modèle a « appris » la grammaire anglaise et maîtrisé la traduction de l'anglais vers le chinois. À travers cet exemple, il n'est pas difficile de constater que l'essence de l'apprentissage peut être comprise comme le processus de compression sans perte d'informations efficaces. Plus le taux de compression est élevé, meilleur est l'effet d'apprentissage.
Selon le dernier avis d'OpenAI, le grand modèle de langage basé sur GPT est un compresseur de données aux performances excellentes . L'essence du modèle de langage est de prédire en continu la distribution de probabilité du mot suivant, de manière à terminer la tâche générative.
Mais du point de vue de la "compression sans perte", si le modèle prédit le mot suivant avec plus de précision, cela signifie qu'il a une compréhension plus profonde de la connaissance et obtient ainsi une résolution plus élevée du monde. Au fur et à mesure que la taille du modèle augmente, le taux de compression calculé sur la base de l'entropie de l'information va progressivement augmenter , ce qui explique pourquoi les performances du modèle augmentent avec l'augmentation de la taille.
La méthode d'augmentation du taux de compression du modèle n'est pas le seul moyen "d'augmenter l'échelle" , comme l'a dit Jack Rae : La mise à l'échelle n'est pas tout ce dont vous avez besoin . Une meilleure architecture d'algorithme, l'intégration d'outils basés sur des plugins et l'utilisation de données synthétiques peuvent améliorer efficacement le taux de compression du modèle, améliorant ainsi encore les performances du modèle.
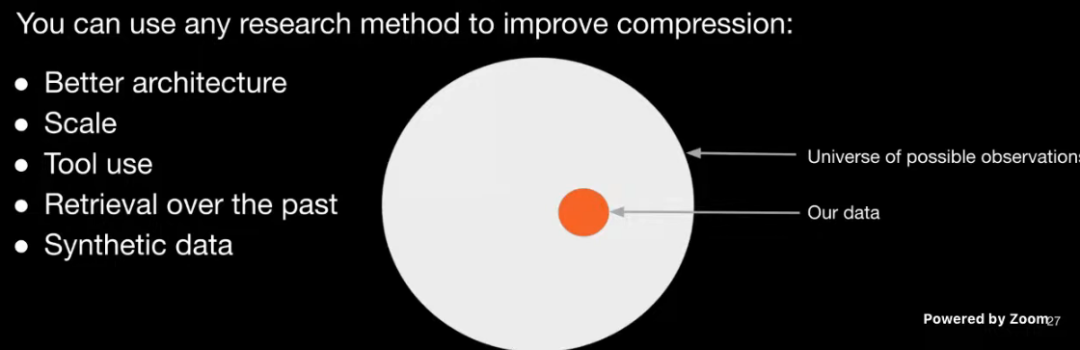
Figure : Plusieurs façons d'améliorer le taux de compression du modèle
02
L'information visuelle est une riche mine de connaissances : du texte à la multimodalité
Puisque le but du développement de grands modèles de langage est d'améliorer continuellement le taux de compression des informations efficaces. Alors naturellement, comment obtenir autant d'informations efficaces que possible est devenu une proposition importante .
Les humains sont des animaux visuels dotés de capacités linguistiques, et environ un tiers de notre cortex cérébral est utilisé pour l'analyse de l'information visuelle . Par conséquent, l'information visuelle est une riche mine de connaissances humaines .
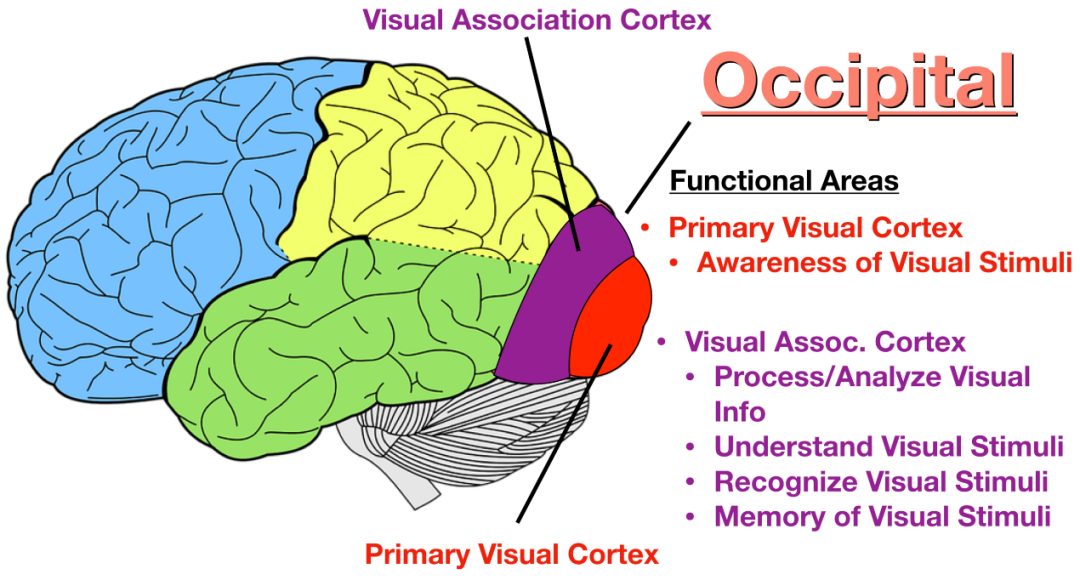
Figure : Le centre du signal visuel dans le cortex cérébral
Par exemple, nous savons tous que "le soleil se lève à l'est et se couche à l'ouest", ce qui relève du bon sens. Mais si vous analysez comment nous avons appris cette connaissance, je crois que la plupart des gens l'ont vue de leurs propres yeux, pas seulement apprise à travers des livres.
Par extension, l'information visuelle est souvent la source de la connaissance humaine . Étant donné que les êtres humains ont la capacité de langage et d'écriture, les gens transformeront lentement les informations obtenues par la vision sous forme de texte et les diffuseront.
Par conséquent, si toutes les connaissances acquises par les êtres humains sont considérées comme un iceberg, alors les données avec "texte" comme support ne sont que la pointe de l'iceberg, tandis que les données avec "image" et "vidéo" comme support sont les véritable mine riche de connaissances humaines . C'est pourquoi le GPT-5 d'OpenAI apprendra sur la base de vidéos Internet massives.
Plus précisément, si on montre au modèle un grand nombre de vidéos d'observations astronomiques, le modèle peut apprendre une loi de Kepler implicite ; si on montre au modèle un grand nombre de trajectoires de particules chargées, le modèle peut apprendre l'expression mathématique de la force de Lorentz ; de Bien sûr, nous pouvons aussi être plus audacieux. Si nous apprenons les données expérimentales massives du collisionneur de hadrons pour le modèle, si le modèle peut percer le secret du boson de Higgs, afin de répondre au mystère de la "masse" de matière, tout tout cela vaut vraiment la peine d'attendre.
 Figure : Modèle de particules élémentaires et particule divine
Figure : Modèle de particules élémentaires et particule divine
03
Pénurie de données à l'ère du Big Data : utiliser des données synthétiques pour briser la situation
Bien que la société humaine soit déjà entrée dans l'ère des mégadonnées, les activités économiques mondiales ont généré un grand nombre d'actifs de données, mais l' ensemble de formation requis par LLM se développe plus rapidement. Selon les prévisions, les données textuelles seront épuisées d'ici 2026 et les données d'image vers 2040.
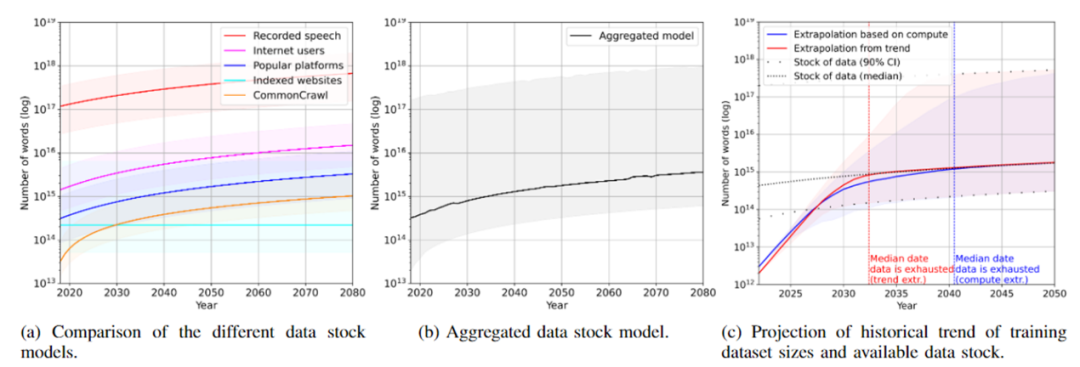
Figure : Prédiction de la consommation de données de stock Internet par grand modèle de langage
Ce n'est pas une bonne nouvelle pour un grand modèle de langage qui "travaille dur pour faire des miracles". Si l'ensemble de formation n'est pas suffisant, le modèle ne peut pas continuer à évoluer, améliorant ainsi continuellement le plafond de performance.
À l'heure actuelle, les "données synthétiques" sont devenues une méthode importante pour casser le jeu. Comme son nom l'indique, les "données synthétiques" font référence à l'ensemble d'apprentissage généré par l'algorithme, plutôt qu'aux échantillons collectés dans le monde réel .
Selon les prévisions de Gartner, 50 % des données d'entraînement des modèles en 2026 seront composées de données synthétiques ; en 2030, la qualité des données synthétiques dépassera largement les données réelles étiquetées par les humains.
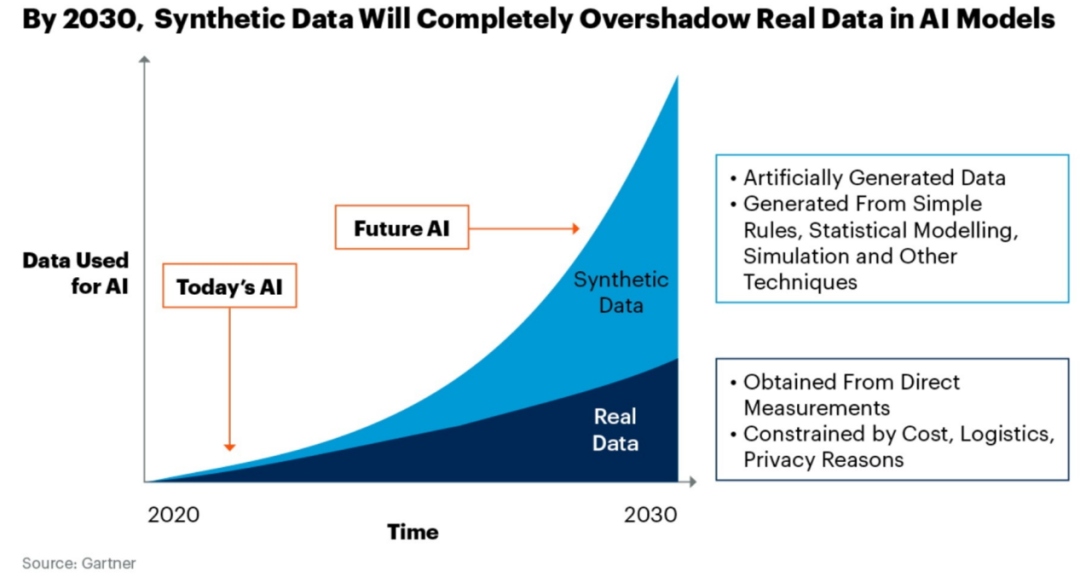
Figure : Prévisions de Gartner pour le développement des données synthétiques
OpenAI se concentre sur l'application de données synthétiques dans la documentation technique de GPT-4, ce qui montre qu'OpenAI attache une grande importance à ce domaine.

Figure : Discussion sur l'application des données synthétiques dans le rapport technique GPT-4
En regardant plus loin, si la qualité des données synthétiques peut complètement surpasser la qualité de l'annotation humaine, alors AGI pourra s'itérer à l'avenir , et la vitesse d'évolution sera grandement améliorée. À ce stade, les humains peuvent devenir le script de démarrage d'AGI (Boot Loader) .
Cela me rappelle la prédiction de Musk en 2014. Il estime que du point de vue de "l'échelle de l'évolution des espèces", la "vie basée sur le carbone" représentée par les êtres humains ne peut être que le scénario de démarrage de la "vie basée sur le silicium" représentée par "l'IA" .
Cette prophétie fait froid dans le dos. En 2014, la plupart des gens penseraient que c'était un discours alarmiste. Mais quand nous revenons maintenant sur ce jugement, il n'est pas difficile de constater qu'il coïncide avec l'objectif de développement des "données synthétiques".
Une percée dans le domaine des données synthétiques peut devenir une étape importante pour AGI pour franchir la singularité , attendons de voir.

Figure : Jugement de Musk sur le développement de l'IA en 2014
04
L'impact des AGI sur les activités sociales et économiques humaines : perspective et réflexion
Lors de la conférence GTC qui vient de se terminer, le PDG de NVIDIA, Huang Renxun, a comparé la naissance de ChatGPT au moment iPhone de l'Internet mobile. Mais du point de vue de l'histoire du développement technologique humain, je pense que la naissance de ChatGPT ressemble plus au début de la "quatrième révolution industrielle", qui entraînera des changements qualitatifs dans la productivité sociale et les relations de production .
Même si c'est un peu inapproprié, si l'on considère l'être humain comme un « ordinateur biochimique » , autant comparer les similitudes et les différences d'efficacité entre l'être humain et l'IAG :
Tout d'abord, du point de vue de "l'efficacité de la communication" , la transmission de données entre les êtres humains repose principalement sur la communication, et l'essence de la communication est d'ondes mécaniques avec l'air comme support . En revanche, la transmission de données entre AGI se fait principalement via NVLink entre GPU, et la bande passante de transmission de données est considérablement améliorée .
Deuxièmement, du point de vue de "l'efficacité du travail" , les êtres humains sont limités par le mécanisme immunitaire complexe, le mécanisme de réparation des neurones et d'autres principes de l'organisme , et doivent maintenir un sommeil suffisant afin d'échanger contre un bon état de fonctionnement pendant la journée. Cependant, AGI n'a besoin que d'un approvisionnement énergétique suffisant pour effectuer des opérations à haute intensité 7*24, améliorant considérablement l'efficacité du travail .
Encore une fois, du point de vue de "l'efficacité de la collaboration" , l'efficacité globale du travail d'une équipe de 100 personnes est souvent inférieure à 10 fois la production totale d'une équipe de 10 personnes. À mesure que la taille de l'organisation augmente, la production par habitant diminuera inévitablement et il est nécessaire d'utiliser "l'art de la gestion expérimentée" pour stimuler la vitalité du travail d'équipe. Au contraire, pour AGI, l'augmentation des nœuds de calcul peut augmenter la capacité de production, et il n'y aura pas de problèmes de gestion et de collaboration d'utilité marginale décroissante .
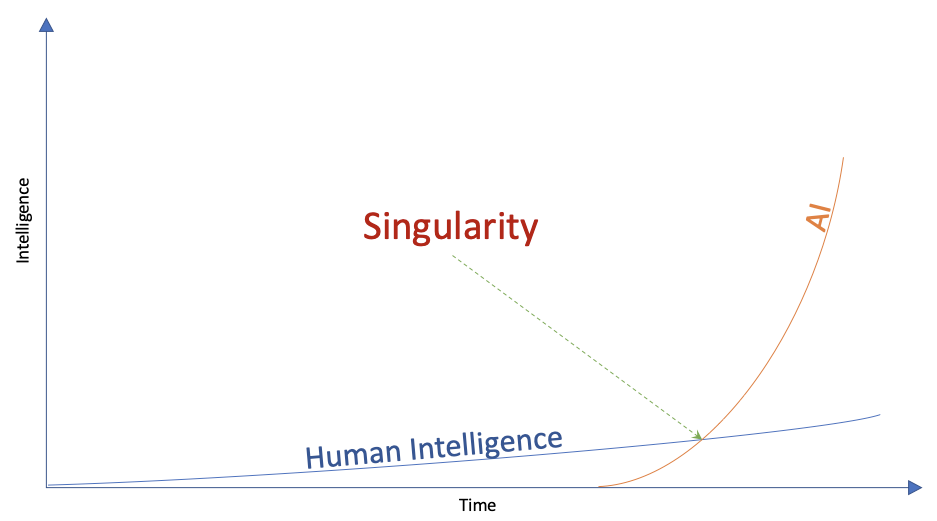
Figure : La courbe de développement de l'intelligence artificielle et de l'intelligence humaine
Ce qui précède analyse les avantages de productivité de l'AGI par rapport aux humains. Cependant, les êtres humains ont toujours une valeur irremplaçable dans les aspects clés suivants :
Tout d'abord, bien que l'IAG dépasse de loin les humains dans l'étendue des connaissances, les humains ont toujours un avantage dans la profondeur des connaissances dans des domaines spécifiques .
En prenant l'investissement financier comme exemple, un gestionnaire d'investissement senior peut faire des inférences floues basées sur des informations de marché incomplètes pour obtenir des rendements excédentaires ; Déduire un nouveau système théorique. Ceux-ci sont actuellement inaccessibles pour AGI.
Deuxièmement, le fonctionnement des activités sociales et économiques est fortement dépendant de la "confiance" entre les personnes , qui ne peut être remplacée par l'IAG. Par exemple, lorsque vous allez à l'hôpital pour voir un médecin, même si l'AGI peut établir un diagnostic assez précis en fonction de la description de vos symptômes, il y a une forte probabilité que vous preniez le résultat du diagnostic pour consulter le médecin humain à côté de vous pour chercher un diagnostic digne de confiance et des conseils de traitement. Des «mécanismes de confiance» similaires constituent une pierre angulaire importante des activités économiques dans les domaines des soins médicaux, de l'éducation et des finances.
Avec le développement d'AGI, les règles du jeu pour de nombreuses activités économiques vont tranquillement changer, et l'opportunité de ce changement de règle sera basée sur AGI dépassant le plus fort parmi les humains dans ce domaine comme ligne de démarcation , tout comme la naissance d'AlphaGo a complètement changé le jeu de Go Les règles sont les mêmes.
05
épilogue
C'était le meilleur des temps, et c'était le pire des temps. Un pessimiste peut toujours avoir raison, mais c'est vraiment inutile.
Tout au long de l'histoire, le développement de l'histoire des sciences humaines et des techniques n'est pas continu, mais sautillant. Peut-être que ce que nous vivons est un saut dans le niveau de la technologie humaine, en tout cas nous avons tous la chance de pouvoir en être témoins et d'y participer.
Enfin, je voudrais partager une phrase que j'aime particulièrement, c'est le conseil de vie que Sam Altman, PDG d'OpenAI, s'est donné à l'occasion de son 30e anniversaire :
Les jours sont longs mais les décennies sont courtes.
06
à propos de nous
Fondée en 2017, Entropy Technology s'est engagée à utiliser les technologies liées à l'intelligence des données pour aider les institutions de gestion d'actifs à réaliser des mises à niveau numériques dans la recherche d'investissement et à construire une nouvelle génération d'infrastructure numérique pour le secteur financier. À l'heure actuelle, la société a servi plus de 70 institutions de gestion d'actifs de première ligne en Chine, et ses principaux clients sont CICC, CITIC, GF, Jiantou, Guoxin, China Merchants, Huaxia, Harvest, Yinhua, Bosera, China Universal, Xingquan, Fonds E et autres titres et sociétés de fonds.
Si vous avez besoin de vous renseigner sur la coopération commerciale, n'hésitez pas à consulter le courrier électronique de l'entreprise : [email protected]

Figure : Qualifications et honneurs de la technologie d'entropie

Figure : Quelques clients et partenaires importants d'Entropy Technology
les références
[1] Puissance, Alethea, et al. "Grokking : généralisation au-delà du surajustement sur de petits ensembles de données algorithmiques." prétirage arXiv arXiv:2201.02177 (2022).
[2] Bubeck, Sébastien, et al. "Étincelles d'intelligence générale artificielle : premières expériences avec gpt-4." prétirage arXiv arXiv:2303.12712 (2023).
[3] Eloundou, Tyna, et al. "Les gpts sont des gpts : un premier aperçu du potentiel d'impact sur le marché du travail des grands modèles linguistiques." prétirage arXiv arXiv:2303.10130 (2023).
[4] Wu, Shijie, et al. "BloombergGPT : un grand modèle de langage pour la finance." prétirage arXiv arXiv:2303.17564 (2023).
[5] Liang, Percy, et al. "Évaluation holistique des modèles de langage." prétirage arXiv arXiv:2211.09110 (2022).
[6] Brown, Tom, et al. "Les modèles de langage sont des apprenants peu nombreux." Avancées dans les systèmes de traitement de l'information neuronale 33 (2020): 1877-1901.
[7] Kaplan, Jared, et al. "Lois d'échelle pour les modèles de langage neuronal." prétirage arXiv arXiv:2001.08361 (2020).
[8] Zhou, Yongchao, et al. "Les grands modèles de langage sont des ingénieurs prompts au niveau humain." prétirage arXiv arXiv:2211.01910 (2022).
[9] Wei, Jason, et al. "Capacités émergentes des grands modèles de langage." prétirage arXiv arXiv:2206.07682 (2022).
[10] Zellers, Rowan et al. « HellaSwag : une machine peut-elle vraiment terminer votre phrase ? » prétirage arXiv arXiv:1905.07830 (2019).
[11] Barocas, Solon, Moritz Hardt et Arvind Narayanan. "L'équité dans l'apprentissage automatique." Tutoriel Nipps 1 (2017): 2017.
[12] Ouyang, Long, et al. "Entraîner des modèles de langage pour suivre les instructions avec une rétroaction humaine." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[13] Devlin, Jacob, et al. "Bert : Pré-formation de transformateurs bidirectionnels profonds pour la compréhension du langage." prétirage arXiv arXiv:1810.04805 (2018).