CAP theorem
CAP theorem (CAP theorem), also known as Brewer's theorem, is a conjecture proposed by Eric Brewer, a computer scientist at the University of California, Berkeley, at the ACM PODC in 2000. In 2002, Seth Gilbert and Nancy Lynch of the Massachusetts Institute of Technology published a proof of Brewer's conjecture, making it a recognized theorem in the field of distributed computing.
CAP (Consistency、Availability、Partition Tolerance)
At the beginning, CAP was just a conjecture of Brewer, and did not define the definitions of these three words in detail. When looking for the definition of CAP, it would be confusing, because different materials have some subtle differences in the detailed definition of CAP. For example:
- Consistency: where all nodes see the same data at the same time.
- Availability: which guarantees that every request receives a response about whether it succeeded or failed.
- Partition tolerance: where the system continues to operate even if any one part of the system is lost or fails.
IBM Cloudant文档之CAP定理
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a (non-error) response – without
guarantee that it contains the most recent write.- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
维基百科之CAP定理
- Consistency: all nodes have access to the same data simultaneously.
- Availability: a promise that every request receives a response, at minimum whether the request succeeded or failed.
- Partition tolerance: the system will continue to work even if some arbitrary node goes offline or can’t communicate.
Team-Silverbacks之CAP定理
Robert Greiner's article Introduction to Robert Greiner is understood as a reference basis. He wrote two articles to explain the CAP theory. The first article is marked as "outdated" (some Chinese translation articles refer to the first article), and the before and after comparison will be made. The difference between the two explanations is to understand the CAP theory more deeply through comparison.
CAP theory
The first edition explains:
Any distributed system cannot guarantee C,A,and P simultaneously.
CAP theory: explanation
The simple translation is: For a distributed computing system, it is impossible to satisfy the three design constraints of consistency (Consistence), availability (Availability), and partition tolerance (Partition Tolerance) at the same time.
The second edition explains:
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance —— one of them must be sacrificed.
CAP理论:重论
Simply translated as: In a distributed system (referring to a collection of nodes connected to each other and sharing data), when it comes to read and write operations, only Consistence, Availability, and Partition Tolerance can be guaranteed. ) of the three, the other must be sacrificed.
The second edition defines what is the distributed system discussed by CAP theory, emphasizing two points: interconnected and shared data, why should these two points be emphasized? Because distributed systems do not necessarily interconnect and share data . The simplest
clusters, such as Memcache, do not connect and share data with each other. Therefore, distributed systems such as Memcache clusters do not meet the object of CAP theory discussion; load-balanced cluster nodes are not interconnected.
The MySQL cluster is interconnected and data replicated, so it is the object of CAP theory.
In the second edition, the write/read pair is emphasized, which is actually in line with the previous difference. In other words, CAP focuses on reading and writing operations on data, rather than all functions of a distributed system . For example, ZooKeeper's election mechanism is not the subject of CAP discussion.
The definitions and explanations in the second edition are more rigorous, but the content is more difficult to remember than the first edition, so when most technicians talk about the CAP theory, they still follow the definitions and explanations of the first edition. , because the first version, although not rigorous,
is very simple and easy to remember. In addition to the basic concepts in the second edition, three basic design constraints have also been reformulated.
Consistency
① All nodes see the same data at the same time;
all nodes can see the same data at the same time.
② A read is guaranteed to return the most recent write for a given client;
for a specified client, the read operation is guaranteed to return the latest write operation result.
The key word in ① is see, which is actually not exact, because the node node owns data, not sees the data. Even if you want to describe it, you use have; it emphasizes having the same data at the same time (same time + same data) The key word in ②
is read. The consistency is described from the perspective of reading and writing of the client, and the definition is more precise.
This means that in fact, nodes may have different data (same time + different data) at the same time, which is different from the consistency we usually understand. Why make such a change? In fact, it has been mentioned in the detailed explanation of the first edition, and the specific content is as follows:
A system has consistency if a transaction starts with the system in a consistent state, and ends with the system in a consistent state.
In this model, a system can (and does) shift into an inconsistent state during a transaction, but the entire transaction gets rolled back
if there is an error during any stage in the process.
Referring to the above explanation, for the system to execute transactions, the system is actually in an inconsistent state during the transaction execution process, and the data of different nodes are not completely consistent , so the first version of the explanation "All nodes see the same data at the same time" is imprecise.
The second edition emphasizes that there is no problem if the client read operation can obtain the latest write results, because the client cannot read the uncommitted data during the execution of the transaction, and the client can only read the transaction write data after the transaction is committed. If the transaction fails, it will be rolled back, and
the client will not read the data written in the middle of the transaction.
Availability
① Every request gets a response on success/failure.
Each request can get a response on success or failure.
② A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout). A
non-failing node will return a reasonable response within a reasonable amount of time (not an error and timeout response).
The difference between the two lies in:
① It is every request, which is imprecise, because only non-faulty nodes can meet the availability requirements. If the node itself fails, the request sent to the node may not get a response. Response is divided into success and failure. The definition is too broad. In almost any situation, whether it conforms to the CAP theory or not, we can say that the request succeeds or fails, because timeout is also considered failure, error is also considered failure, exception is also considered failure, and the result is incorrect. is also a failure; even a successful response is not necessarily correct. For example, it should return 100, but it actually returns 90, which is a successful response, but it doesn't get the correct result.
②A non-failing node is emphasized. ②Two reasonable are used: reasonable response and reasonable time, and special emphasis is placed on no error or timeout.
The explanation clarifies that there is no timeout and no error, and the result is reasonable. Note that there is no "correct" result . For example, returning 90 when it should have returned 100 is certainly an incorrect result, but could be a reasonable result.
Partition Tolerance
① System continues to work despite message loss or partial failure.
The system can continue to operate when a message is lost or a partition error occurs.
② The system will continue to function when network partitions occur.
When a network partition occurs, the system will continue to "perform its duties".
Their main differences are as follows:
① work is used, and work emphasizes "running". As long as the system does not crash, it can be said that the system is working, returning errors is also work, and denial of service is also work; partitioning uses message loss or Partial failure, direct reason, that is, message loss caused partition, but the definition of message loss is a bit narrow, because usually what we call message loss (packet loss) is only one of network failures.
② use function. The emphasis on "functioning" and "performing duties" is in line with usability. In other words, it is only a function that returns a reasonable response. In contrast, ② explains more clearly. Network partitions are used to describe partitions, that is, partitions
occur . No matter what the reason is, it may be packet loss, connection interruption, or congestion. As long as the network partition is caused, it will be included.
CAP application
Although the theoretical definition of CAP is that only two of the three elements can be selected, when we think about it in a distributed environment, we will find that we must choose the P (partition tolerance) element, because the network itself cannot be 100% reliable and may fail. So partitioning is an inevitable phenomenon. If we choose CA and give up P, then when a partition occurs, in order to ensure C, the system needs to prohibit writing. When there is a write request, the system returns an error (for example, the current system does not allow writing), which in turn It conflicts with A, because A requires no error and no timeout to be returned. Therefore, it is theoretically impossible for a distributed system to choose a CA architecture, but only a CP or AP architecture.
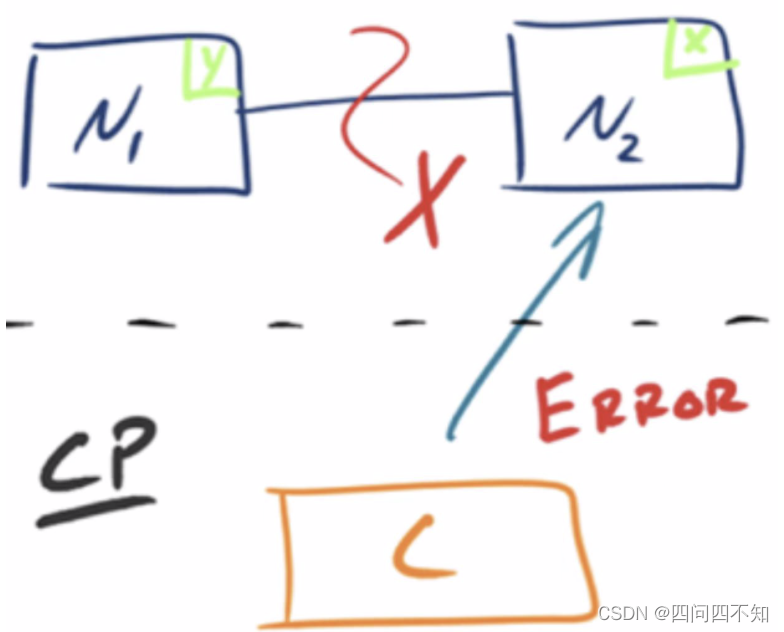
CP - Consistency/Partition Tolerance
As shown in the figure below, in order to ensure consistency, when the partition phenomenon occurs, the data on the N1 node has been updated to y, but due to the interruption of the replication channel between N1 and N2, the data y cannot be synchronized to N2, and the data on the N2 node Still x. At this time, when client C accesses N2, N2 needs
to return Error, prompting client C that "an error has occurred in the system." This processing method violates the requirements of availability (Availability), so the three CAPs can only satisfy CP.
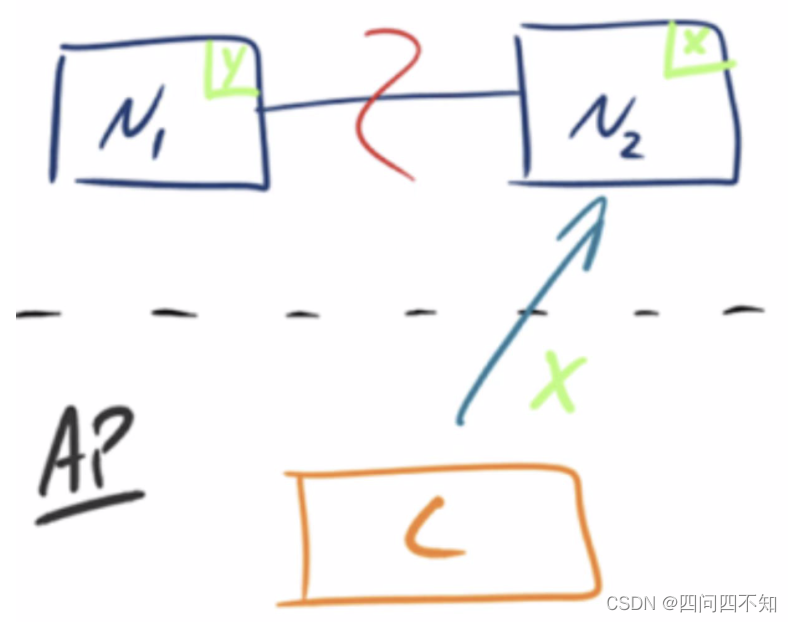
AP - Availability/Partition Tolerance
As shown in the figure below, in order to ensure availability, when the partition phenomenon occurs, the data on the N1 node has been updated to y, but because the replication channel between N1 and N2 is interrupted, the data y cannot be synchronized to N2, and the data on the N2 node is still x. At this time, when client C accesses N2, N2 returns the current data x to client C, but in fact the latest data is already y, which does not meet the consistency (Consistency) requirements, so The three of CAP can only satisfy AP. Note: Here the N2 node returns x, although it is not a "correct" result, but a "reasonable" result, because x is old data, not a messy value, but not the latest data.
CAP key details
- CAP focuses on the granularity of the data, not the entire system
The trade-off between C and A can occur repeatedly in the same system at a very fine granularity, and each decision may affect users or data due to specific operations.
When CAP theory is put into practice, we need to classify the data in the system according to different application scenarios and requirements, and choose different strategies (CP or AP) for each type of data, rather than directly restricting all data in the entire system to the same strategy .
- CAP ignores network latency.
This is a very implicit assumption that Brewer does not take latency into account when defining consistency. That is, when a transaction is committed, the data can be replicated to all nodes instantaneously. But in reality, it always takes a certain amount of time to copy data from node A to node B. If it is the same computer room, the time-consuming may be a few milliseconds; if it is a cross-regional computer room, for example, the synchronization between the Beijing computer room and the Guangzhou computer room may take tens of milliseconds. This means that C in CAP theory cannot be perfectly realized in practice. During the process of data replication, the data of node A and node B are not consistent.
Don't underestimate the inconsistency of these few milliseconds or tens of milliseconds. For some demanding business scenarios, such as user balances related to money, or commodity inventory related to panic buying, it is technically impossible to achieve perfection in distributed scenarios. of consistency. In business, consistency must be required. Therefore, the balance of a single user and the inventory of a single commodity require the selection of CP in theory, but in fact CP cannot do it, and only CA can be selected. In other words, it can only be written at a single point, and other nodes can be used as backups, and multi-point writing cannot be done in a distributed manner.
It should be noted that this does not mean that this type of system cannot apply a distributed architecture, it just means that "single user balance, single commodity inventory" cannot be distributed, but the system as a whole can still apply a distributed architecture. For example, the architecture diagram below is a common distributed architecture that partitions users.
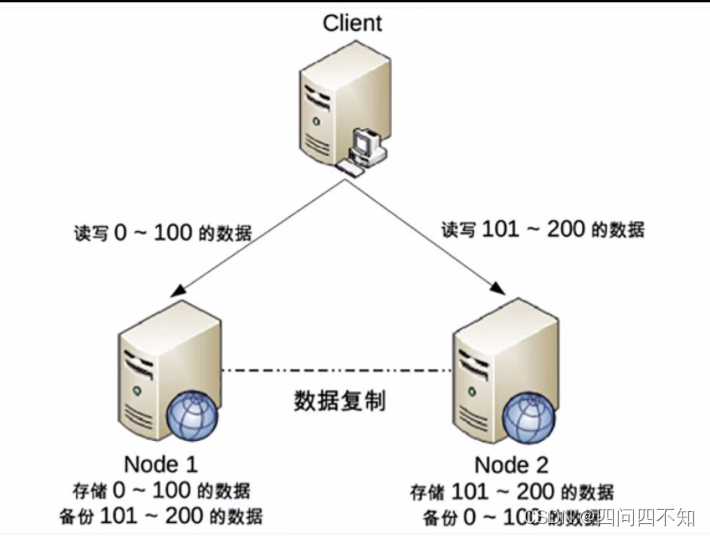
We can store the data with user id 0 ~ 100 in Node 1, store the data with user id 101 ~ 200 in Node 2, and the Client decides which Node to visit according to the user id. For a single user, read and write operations can only be performed on a certain node; for all users, some users' read and write operations are on Node 1, and some users' read and write operations are on Node 2.
An obvious problem with this design is that when a node fails, users on this node cannot perform read and write operations, but on the whole, this design can reduce the number of users affected when a node fails And scope, after all it's better to affect only 20% of users than to affect all users. This is why after the excavator dug out the optical cable, only some Alipay users experienced business abnormalities, not all users' business abnormalities.
- Giving up does not mean doing nothing, but you need to prepare for the recovery of the partition.
The CAP theory tells us that we can only take two of the three, and we need to "sacrifice" the other one. The "sacrifice" here is somewhat misleading, because "sacrifice" makes many people understand it as doing nothing. In fact, the "sacrifice" of the CAP theory just means that we cannot guarantee C or A during the partition process, but it does not mean that nothing is done. Because in the entire operating cycle of the system, most of the time is normal, and the time for partitioning to occur is not long. For example, a system with 99.99% availability (commonly known as 4 9s) will be unavailable for only 50 minutes after one year of operation; a system with 99.999% availability (commonly known as 5 9s) will be unavailable for only 5 minutes after one year of operation. minute. Abandoning C or A during the partition does not mean giving up C and A forever. We can perform some operations during the partition, so that the system can reach the state of CA again after the partition failure is resolved.
ACID
- Atomicity
All operations in a transaction are either all completed or not completed, and will not end at a certain link in the middle. If an error occurs during the execution of the transaction, it will be rolled back to the state before the transaction started, as if the transaction had never been executed.
- Consistency
The integrity of the database is not compromised before the transaction begins and after the transaction ends.
- Isolation
The ability of a database to allow multiple concurrent transactions to read, write, and modify data at the same time. Isolation can prevent data inconsistency caused by cross-execution when multiple transactions are executed concurrently. Transaction isolation is divided into different levels, including read uncommitted (Read uncommitted), read committed (read committed), repeatable read (repeatable read) and serialization (Serializable).
- Durability
After the transaction processing is completed, the modification to the data is permanent, even if the system fails, it will not be lost. It can be seen that the meanings of A (Atomicity) in ACID and A (Availability) in CAP are completely different, and the names of C in ACID and C in CAP are consistent, but their meanings are completely different. The C in ACID refers to data integrity of the database, while the C in CAP refers to data consistency among distributed nodes. Considering that the application scenario of ACID is database transactions, CAP focuses on the difference between reading and writing data in distributed systems. In fact, the comparison between CAP and ACID is similar to that of Guan Gong fighting Qin Qiong. much comparability.
BASE
BASE refers to Basic Available (Basically Available), Soft State (Soft State), and Eventual Consistency (Eventual Consistency). The core idea is that even if strong consistency cannot be achieved (CAP consistency is strong consistency), applications can adopt Appropriate way to achieve eventual consistency.
- Basically Available
When a distributed system fails, some availability is allowed to be lost, that is, the core is guaranteed to be available. The key words here are "part" and "core". It is a challenging job to choose which ones can be lost and which ones must be guaranteed. For example, for a user management system, "login" is a core function, while "registration" can be counted as a non-core function. Because unregistered users have not yet used the business of the system, if they fail to register, at most they will lose some users, and the number of these users is relatively small. If the user is registered but cannot log in, it means that the user cannot use the system. For example, games that have been filled with money cannot be played, cloud storage cannot be used... these will cause users
- Soft State
Allows for an intermediate state of the system that does not affect the overall availability of the system. The intermediate state here is the data inconsistency in CAP theory.
- Eventual Consistency
After a certain period of time, all data copies in the system can finally reach a consistent state.
The key words here are "a certain time" and "finally". "A certain time" is strongly related to the characteristics of the data, and different data can tolerate different inconsistent times.
To give an example of a Weibo system, the user account data should preferably reach a consistent state within 1 minute, because after the user registers or logs in at node A, it is unlikely to switch to another node immediately within 1 minute, but after 10 minutes Maybe log in to another node again; and the latest Weibo posted by the user can be tolerated to reach a consistent state within 30 minutes, because for the user, the latest Weibo posted by a celebrity is invisible to the user , will think that the star did not post Weibo. The meaning of "final" is that no matter how long it takes, it will eventually reach a consistent state.
BASE theory is essentially an extension and supplement to CAP, more specifically, a supplement to the AP program in CAP . When analyzing the CAP theory, I mentioned two points related to BASE:
The CAP theory ignores delay, but delay is unavoidable in practical applications.
This means that a perfect CP scenario does not exist. Even if there is a data replication delay of a few milliseconds, the system does not meet the CP requirements within a few milliseconds interval. Therefore, the CP scheme in CAP actually achieves final consistency, but the "certain time" refers to a few milliseconds.
The sacrifice of consistency in the AP scheme only refers to the period of partitioning, rather than giving up consistency forever.
This is actually an extension of the BASE theory. Consistency is sacrificed during partitioning, but after partition failure recovery, the system should achieve final consistency.
Based on the above analysis, ACID is the theory of database transaction integrity, CAP is the theory of distributed system design, and BASE is the extension of the AP scheme in CAP theory.
What the Paxos algorithm itself can provide is a reliable final consistency guarantee. If there are sufficient isolation measures, the intermediate state cannot be read by the client, and strong consistency can be achieved, which belongs to the CP architecture. In other cases, it is the AP architecture.
The Paxos algorithm itself satisfies linear consistency. Linear consistency is the strongest consistency that the actual system can achieve. Most of the implementations of Paxos and its variants in the field of actual engineering have made certain trade-offs, and are not completely linear. For example, zookeeper and Etcd both satisfy linear consistency for write operations (such as elections), but not necessarily linear consistency for read operations. You can choose linear consistent reads or non-linear consistent reads. The non-linear consistent row read here is sequential consistency.
There are many pitfalls in the CAP theorem, which is very puzzling to understand.
1. Applicable scenarios. There are many types of distributed systems, including heterogeneous ones, such as upstream and downstream dependencies between nodes, and isomorphic ones, such as partitioned/sharded and replica-based (master-slave, multi-master). The applicable scenario of the CAP theorem is the copy type.
2. The concept of consistency, from strong to weak, linear consistency, sequential consistency, causal consistency, monotonic consistency, and eventual consistency. Consistency in CAP should refer to sequential consistency.
3. The difference between consistency in CAP and consistency in ACID. Consistency in transactions refers to the satisfaction of integrity constraints, and consistency in CAP refers to read-write consistency.
4. The availability in CAP is different from the high availability we often say. For example, HBase and MongoDB belong to the CP architecture, and Cassandra and CunchDB belong to the AP system. Can it be said that the latter is more usable than the former? Probably not. Availability in CAP means that in a certain read operation, even if an inconsistency is found, a response must be returned, that is, a reasonable response is returned within a reasonable time. We often talk about high availability, which means that some instances can be automatically removed when they are hung up, and other instances continue to provide services. The key is redundancy.
5. Which situations belong to the network partition. The partition caused by network failure belongs to. There is a problem with the node application that causes a timeout, which belongs to. Node downtime or hardware failure does not belong.
Consistency in CAP refers to linear consistency, not sequential consistency.
P requires distributed and data synchronization, C requires the data to be completely consistent, and A requires timely return