Nota: La descripción de la abreviatura en este artículo

1. Introducción a la programación de grupos CFS
1.1 Razón de ser
En resumen, se espera que las tareas en diferentes grupos puedan asignar una proporción controlable de recursos de CPU bajo carga alta. ¿Por qué existe tal requisito? Por ejemplo, en un sistema informático multiusuario, todas las tareas de cada usuario se dividen en un grupo. El usuario A tiene 90 tareas idénticas, mientras que el usuario B tiene solo 10 tareas idénticas. Si la CPU está completamente lleno, entonces el usuario A tomará el 90% del tiempo de la CPU, mientras que el usuario B solo tomará el 10% del tiempo de la CPU, lo que obviamente es injusto para el usuario B. O si el mismo usuario quiere compilar rápidamente con -j64, pero no quiere verse afectado por la tarea de compilación, también puede configurar la tarea de compilación en el grupo correspondiente para limitar sus recursos de CPU.
1.2 Estado del grupo en dispositivos móviles

El directorio /dev/cpuctl está representado por struct task_group root_task_group. Cada subdirectorio debajo de él se abstrae en una estructura task_group. Hay algunos puntos a tener en cuenta:
El valor predeterminado del archivo cpu.shares en el grupo raíz es 1024 y no se admite la configuración. La carga del grupo raíz tampoco se actualiza.
El grupo raíz también es un grupo de tareas, y las tareas del grupo raíz también se agrupan y ya no pertenecerán a otros grupos.
El subproceso del núcleo está en el grupo raíz de forma predeterminada y asigna directamente intervalos de tiempo desde la raíz cfs_rq, lo que tiene una gran ventaja: si continúa ejecutándose, casi "se ejecuta todo el tiempo" en el seguimiento, como el subproceso del núcleo kswapd.
Bajo la configuración predeterminada de cpu.shares, si todas las tareas son agradables = 0 y solo se considera un núcleo único, la porción de tiempo que cada tarea en el grupo raíz puede obtener cuando está completamente cargada es igual a la porción de tiempo que se puede asignar a todas las tareas bajo otros grupos Llegó la suma de los intervalos de tiempo.
Nota: tanto la tarea como el grupo de tareas asignan intervalos de tiempo por peso, pero el peso de la tarea proviene de su prioridad, mientras que el peso del grupo de tareas proviene del valor establecido en el archivo cpu.shares en su directorio cgroup. Después de habilitar la programación de grupos, según el intervalo de tiempo asignado a una tarea, no solo puede ver el peso correspondiente a su prioridad, sino también el peso asignado a su grupo de tareas y el estado de ejecución de otras tareas en el grupo. .
Dos, la agrupación de tareas del grupo de tareas
La función de programación de grupos de CFS se refleja principalmente en la agrupación de tareas, y un grupo se representa mediante una estructura task_group.
2.1 Cómo configurar la agrupación
La interfaz de configuración de agrupación de grupos de tareas es exportada al espacio del usuario por el subsistema cgroup cpu a través de la jerarquía de directorios cgroup.

¿Cómo eliminar una tarea de un grupo de tareas? No hay forma de eliminarla directamente. Según la semántica de cgroup, una tarea debe pertenecer a un grupo de tareas en un momento determinado. Solo repitiéndola en otros grupos se puede eliminar del grupo actual. agrupar.eliminar.
2.2 Cómo configurar la agrupación en Android
Process.java proporciona setProcessGroup(int pid, int group) a otros módulos para establecer el proceso pid en el grupo especificado por el parámetro de grupo para que otros módulos llamen y establezcan. Por ejemplo, en OomAdjuster.java, cambie la tarea al frente/fondo y llame al parámetro group=THREAD_GROUP_TOP_APP/THREAD_GROUP_BACKGROUND respectivamente.
libprocessgroup proporciona un archivo de configuración llamado task_profiles.json, en el que el campo de atributo agregado AggregateProfiles configura el comportamiento correspondiente después de configurar la capa superior. Por ejemplo, el atributo de agregación correspondiente a THREAD_GROUP_TOP_APP es SCHED_SP_TOP_APP, y el comportamiento correspondiente al atributo MaxPerformance es unirse al grupo de aplicaciones principales de CPU.

La configuración del atributo "MaxPerformance" es muy legible y se puede ver que se agrega al grupo de aplicaciones principales del subsistema de la CPU.
2.3. Android está configurado como agrupación TOP-APP, lo que está configurado para cgroup
Debido a que hay múltiples subsistemas cgroup, además del subsistema cpu cgroup adjunto a la programación del grupo CFS del que estamos hablando, hay subsistemas cpuset cgroup (que limitan la CPU y los nodos de memoria disponibles que pueden ejecutar las tareas), blkio cgroup subsystems ( El bloque dispositivo io que limita el proceso), el subsistema freezer cgroup (proporciona la función de congelación del proceso), etc. La agrupación de configuración de nivel superior no solo puede cortar un cgroup, sino que los subsistemas que se cortan específicamente se reflejan en los miembros de la matriz del atributo agregado AggregateProfiles. Por ejemplo, los comportamientos correspondientes a los otros dos atributos en el ejemplo anterior son unir el el grupo raíz del subsistema blkio y el timer_slack_ns de la tarea (un parámetro que equilibra la puntualidad y el consumo de energía de hrtimer timing wake-up) se establece en 50000ns.

2.4. Después de que se inicie el servicio, se colocará en el grupo especificado
Use task_profiles para configurar al iniciar el servicio, por ejemplo.

3. Descripción general de la implementación del kernel
Anteriormente discutimos la configuración de la agrupación de grupos de tareas, esta sección comenzará a ingresar al kernel para comprender su implementación.
3.1 Dependencias funcionales relacionadas
Las dependencias CONFIG_* relacionadas con el kernel son las siguientes:
Figura 1:
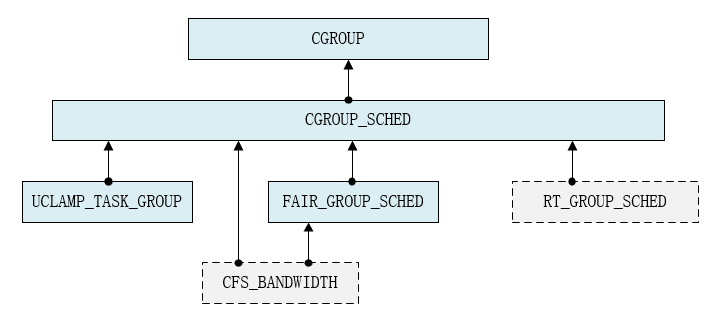
CGROUP proporciona la función de la jerarquía de directorios de cgroup; CGROUP_SCHED proporciona la jerarquía de directorios de cgroup cpu (como /dev/cpuctl/top-app) y proporciona el concepto de grupo de tareas para cada directorio de cgroup cpu; FAIR_GROUP_SCHED proporciona según el grupo de tareas proporcionado por cpu cgroup CFS función de programación de grupos de tareas. El marco punteado gris en la Figura 1 no está habilitado de forma predeterminada en el kernel del teléfono Android.
3.2 Diagrama de estructura de datos del grupo de tareas
Como se muestra en la Figura 2 a continuación, muestra un diagrama de bloques de la estructura de datos principal mantenida por un grupo de tareas en el kernel, que es más fácil de entender al comparar los siguientes conceptos en la figura:
Dado que es imposible determinar en qué CPU se ejecutan las tareas de un grupo, un grupo de tareas mantiene un grupo cfs_rq en cada CPU, porque el grupo de tareas también participa en la programación (primero debe seleccionar el grupo de tareas para seleccionar el grupo cfs_rq en el group cfs_rq task), por lo que también se mantiene un group se en cada CPU.
El miembro my_q de la tarea se es NULL, y el miembro my_q del grupo se apunta a su grupo correspondiente cfs_rq, y las tareas preparadas agrupadas en esta CPU se cuelgan en este grupo cfs_rq.
El grupo de tareas se puede anidar, y los miembros principales/hermanos/secundarios forman una jerarquía de árbol invertido, y el principal del grupo de tareas raíz apunta a NULL.
El cfs_rq raíz de todas las CPU pertenece al grupo de tareas raíz.
Figura 2:
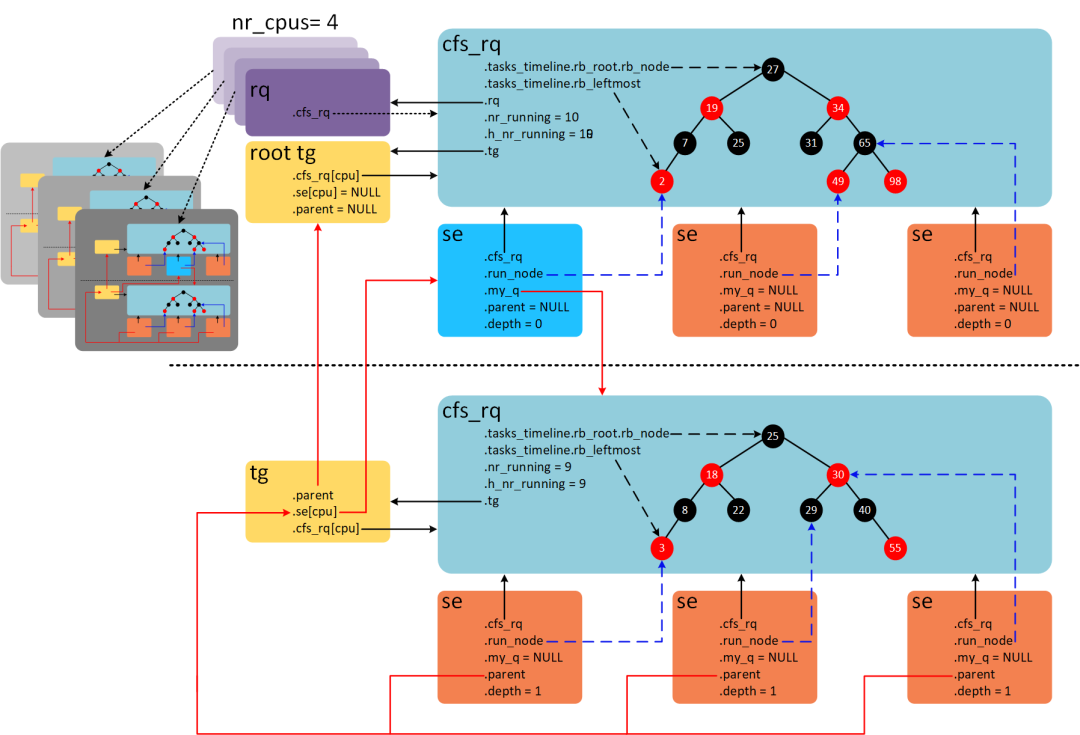
Nota: Es problemático hacer un dibujo, este dibujo está basado en la fosa coclear.
4. Estructuras relevantes
4.1. estructura task_group
Una estructura task_group representa una agrupación cpu cgroup. Cuando FAIR_GROUP_SCHED está habilitado, una estructura task_group representa un grupo de tareas en la programación de grupos de CFS.

css: la información de estado de cgroup correspondiente al grupo de tareas, a través del cual se adjunta a la jerarquía de directorios de cgroup.
se: grupo se, es un puntero de matriz, el tamaño de la matriz es el número de CPU. Debido a que hay varias tareas en un grupo de tareas y pueden ejecutarse en todas las CPU, cada CPU debe tener un se del grupo de tareas.
cfs_rq: el cfs_rq del grupo se es el cfs_rq del grupo de tareas en cada CPU, y también es un puntero de matriz, y el tamaño de la matriz es la cantidad de CPU. Cuando la tarea de este grupo de tareas esté lista, cuélguese de este cfs_rq. Su puntero correspondiente en cada CPU tiene el mismo puntero que se->my_q del grupo de tareas en cada CPU, consulte init_tg_cfs_entry().
acciones: el peso del grupo de tareas, el valor predeterminado es scale_up (1024). Similar al peso de la tarea se, cuanto mayor sea el valor, más segmentos de tiempo de CPU puede obtener el grupo de tareas. Pero a diferencia de la tarea, el grupo de tareas tiene un grupo se en cada CPU, por lo que debe asignarse al grupo se en cada CPU de acuerdo con ciertas reglas.Las reglas de asignación se explicarán a continuación.
load_avg: la carga de este grupo de tareas, y es solo una variable load_avg (a diferencia de se y cfs_rq son una estructura), que se explicará a continuación. Tenga en cuenta que no es por CPU. La tarea de este grupo de tareas lo actualizará cuando se actualice en cada CPU, por lo que debe prestar atención al impacto en el rendimiento.
padre/hermanos/hijos: La jerarquía que conforma el grupo de tareas.
Hay una variable global struct task_group root_task_group en el núcleo, que representa el grupo raíz. Su cfs_rq[] es el cfs_rq de cada CPU, y su se[] es NULL. No se permite establecer sus pesos, consulte sched_group_set_shares(). La carga tampoco se actualiza, consulte update_tg_load_avg().
Todas las estructuras de grupos de tareas del sistema se agregarán a la lista vinculada task_groups, que se utiliza en el control de ancho de banda de CFS.
Los principiantes pueden confundir los dos conceptos de programación grupal y programación grupal, así como la diferencia entre struct task_group y struct sched_group. La programación de grupos corresponde a struct task_group, que se usa para describir un grupo de tareas. Se usa principalmente para util uclamp (para sujetar los requisitos de potencia de cómputo de un grupo de tareas) y restricciones de uso de recursos de CPU, que también es el contenido a ser explicado en este artículo. El grupo de programación corresponde a struct sched_group, que es un concepto en la topología de CPU sched_domain.Se utiliza para describir los atributos de una CPU (nivel MC)/clúster (nivel DIE), y se utiliza principalmente para la selección de núcleos y el equilibrio de carga.
4.2. estructura sched_entity
Una sched_entity puede representar no solo un se de tarea, sino también un se de grupo. A continuación, se presentan principalmente algunos miembros nuevos después de habilitar la programación de grupos.

load: indica el peso de se. Para gse, se inicializa en NICE_0_LOAD cuando es nuevo, consulte init_tg_cfs_entry().
profundidad: indica la profundidad de anidamiento del grupo de tareas, la profundidad del se debajo del grupo raíz es 0 y se incrementa en 1 por cada nivel de anidamiento más profundo. Por ejemplo, hay un directorio tg1 en el directorio /dev/cpuctl y un directorio tg2 en el directorio tg1. La profundidad del grupo se correspondiente a tg1 es 0, la profundidad de la tarea se en tg1 es 1 y la la profundidad de la tarea se bajo tg2 es 2. . Consulte init_tg_cfs_entry()/attach_entity_cfs_rq() para conocer la ubicación de la actualización.
padre: apunta al nodo principal SE, tanto el nodo principal como el secundario corresponden a la misma CPU. La tarea bajo el grupo raíz apunta a NULL.
cfs_rq: El cfs_rq en el que está montado este se. Para las tareas del grupo raíz que apuntan a cfs_rq de rq, las tareas del grupo no raíz apuntan a su padre->my_rq, consulte init_tg_cfs_entry().
my_q: El cfs_rq de este se, solo el grupo se tiene cfs_rq, y la tarea se es NULL.La macro entity_is_task() juzga si es una tarea se o un grupo se a través de este miembro.
runnable_weight: almacena en caché el valor de gse->my_q->h_nr_running, que se usa al calcular la carga ejecutable de gse.
avg: La carga de se, para tse se inicializará como su peso (se supone que su carga es alta cuando se crea), y para gse se inicializará a 0, consulte init_entity_runnable_average(). Existe una cierta diferencia entre el se de tarea y el se de grupo, que se explicará en el Capítulo 5 a continuación.
4.3. estructura cfs_rq
struct cfs_rq puede representar tanto la cola lista para CFS de por CPU como la cola my_q de gse. Algunos miembros que son más críticos para la programación de grupos se enumeran a continuación para explicar.

carga: Indica el peso de cfs_rq, ya sea la raíz cfs_rq o grq, el peso aquí es igual a la suma de los pesos de todas las tareas colgadas en su cola.
nr_running: la suma del número de tareas y grupos de tareas en el nivel actual.
h_nr_running: la suma del número de tareas se en el nivel actual y todos los subniveles, excluyendo el grupo se.
promedio: carga de cfs_rq. A continuación se explicará la carga comparando task se, group se y cfs_rq.
eliminado: cuando una tarea sale o migra a otras CPU después de activarse, la carga que trajo la tarea debe eliminarse del cfs rq de la CPU original. Esta acción de eliminación primero registrará la carga eliminada en el miembro eliminado y luego la eliminará la próxima vez que se llame a update_cfs_rq_load_avg() para actualizar la carga de cfs_rq. nr indica el número de se que se eliminarán y *_avg indica la suma de varias cargas que se eliminarán.
tg_load_avg_contrib: Es un caché para grq->avg.load_avg, que indica el valor de contribución de la carga actual de grq a tg. Se utiliza para reducir el número de accesos a tg->load_avg mientras se actualiza tg->load_avg. También se usa en el algoritmo aproximado al calcular la cuota de peso que gse obtiene de tg, consulte calc_group_shares()/update_tg_load_avg().
propagate: Marque si hay una carga que necesita ser propagada a la capa superior. La Sección 7.3 a continuación lo explicará.
prop_runnable_sum: cuando la carga se propaga a la capa superior a lo largo de la jerarquía del grupo de tareas, indica el valor de load_sum del tse/gse que se cargará.
h_load: Jerarquía de carga, que indica el valor de contribución de load_avg de cfs_rq de esta capa a load_avg de CPU, utilizada principalmente en la ruta de equilibrio de carga. Se explicará a continuación.
last_h_load_update: Indica la última vez que se actualizó h_load (jiffies unitarios).
h_load_next: Apunte al sub-gse, para obtener la carga de jerarquía de la tarea (función task_h_load), es necesario actualizar el h_load de los cfs rq de cada nivel de arriba hacia abajo. Por lo tanto, h_load_next aquí es para formar una cadena de relaciones cfs rq--se--cfs rq--se desde la parte superior de cfs rq hasta la parte inferior de cfs rq.
rq: este miembro se agrega después de habilitar la programación de grupos. Si la programación de grupos no está habilitada, cfs_rq es un miembro de rq y container_of se usa para el enrutamiento. Después de habilitar la programación de grupos, se agrega un miembro de rq a la ruta de cfs_rq a rq .
on_list/leaf_cfs_rq_list: intente conectar leaf cfs_rq en serie y utilícelos en la lógica relacionada con el equilibrio de carga y el control de ancho de banda de CFS.
tg: El grupo de tareas al que pertenece el cfs_rq.
Cinco, peso del grupo de tareas
El peso del grupo de tareas está representado por el miembro compartido de la estructura task_group y el valor predeterminado es scale_load(1024). Puede leer y escribir a través del archivo cpu.shares en el directorio cgroup, echo weight > cpu.shares es para configurar el peso del grupo de tareas como peso, y el valor guardado en la variable miembro de acciones es scale_load(peso). root_task_group no admite la configuración de pesos.
El peso de los diferentes grupos de tareas indica qué grupo de tareas puede ejecutar más y qué grupo de tareas debe ejecutar menos después de que la CPU del sistema esté llena.
5.1 Peso de gse
El grupo de tareas tiene un se de grupo en cada CPU, por lo que es necesario asignar el peso tg->shares del grupo de tareas a cada gse de acuerdo con ciertas reglas. La regla es la fórmula (1):
* tg->peso * grq->carga.peso
* ge->carga.peso = ----------------------------------------- ( 1)
* \Sum grq->load.peso
Entre ellos, tg->weight es tg->shares, y grq->load.weight representa el peso grq de tg en cada CPU. Es decir, cada gse asigna el peso de tg según la relación de peso de su cfs_rq. El peso de cfs_rq es igual a la suma de los pesos de las tareas montadas en él. Supongamos que el peso de tg es 1024 y solo hay 2 CPU en el sistema, por lo que hay dos gse, si el estado de la tarea en grq es como se muestra en la Figura 3, entonces el peso de gse[0] es 1024 * (1024 +2048+3072) /(1024+2048+3072+1024+1024) = 768; el peso de gse[1] es 1024 * (1024+1024)/(1024+2048+3072+1024+1024) = 256.
imagen 3:
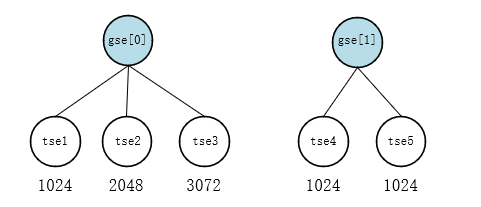
La función de actualización de peso de gse es update_cfs_group(), consulte su implementación específica a continuación:

La distribución del peso de tg a gse[X] se realiza en calc_group_shares().
\Sum grq->load.weight se usa en la fórmula (1), lo que significa que la actualización de un peso gse necesita acceder al grq en cada CPU, y el costo de la competencia de bloqueo es relativamente alto, por lo que una serie de cálculos aproximados se realizan.
Primero haz el reemplazo:
* grq->load.weight --> grq->avg.load_avg (2)
y luego obtener:
* tg->peso * grq->avg.load_avg
* ge->carga.peso = ---------------------------------------- (3 )
* tg->cargar_avg
*
* Donde: tg->load_avg ~= \Sum grq->avg.load_avg
Dado que cfs_rq->avg.load_avg = cfs_rq->avg.load_sum/divider. Y cfs_rq->avg.load_sum es igual a cfs_rq->load.weight multiplicado por la progresión geométrica en el estado no inactivo. Esta aproximación es estrictamente igual bajo la premisa de que la serie temporal del estado no inactivo de grq en cada CPU de tg es la misma. Es decir, cuanto más consistente sea el estado de ejecución de las tareas tg en cada CPU, más se acercará a este valor aproximado.
Cuando el grupo de tareas esté inactivo, inicie una tarea. grq->avg.load_avg toma tiempo para compilar, en el caso especial del tiempo de compilación, la Ecuación 1 se simplifica a:
* tg->peso * grq->carga.peso
* ge->carga.peso = --------------------------------------- = tg- >peso (4)
* grp->carga.peso
Es equivalente al estado de un sistema de un solo núcleo. Para acercar la fórmula (3) a la fórmula (4) en este caso especial, se hace otra aproximación para obtener:
* tg->peso * grq->carga.peso
* ge->carga.peso = ------------------------------------------ -------------------------- (5)
* tg->load_avg - grq->avg.load_avg + grq->load.peso
Pero debido a que no hay una tarea en grq, grq->load.weight puede caer a 0, lo que resulta en una división por cero, debe usar grq->avg.load_avg como su límite inferior y luego dar:
* tg->peso * grq->carga.peso
* ge->carga.peso = ------------------------------------------ (6)
* tg_load_avg'
*
* en:
* tg_load_avg' = tg->load_avg - grq->avg.load_avg + max(grq->load.weight, grq->avg.load_avg)
max(grq->load.weight, grq->avg.load_avg) generalmente toma grq->load.weight, porque solo cuando siempre hay tareas ejecutándose+ejecutables en grq, se acercará a grq->load.weight.
La función calc_group_shares() aproxima el peso de cada gse a través de la fórmula (6):

Dado que cada tarea en tg contribuye al peso de gse, el peso de gse debe actualizarse cuando cambia el número de tareas en grq. La carga de se se usa en el proceso de aproximación, y también se realiza una actualización en entity_tick(). Ruta de llamada:

5.2 El peso asignado a cada tse en gse
A las tareas del grupo de tareas también se les asigna el peso de gse según su relación de peso. Como se muestra en la Figura 2 anterior, para las tres tareas que cuelgan del grq de gse[0], el peso de tse1 es 768*1024/(1024+2048+3072)=128, y el peso de tse2 es 768*2048/ (1024+ 2048+3072)=256, el peso de tse3 es 768*3072/(1024+2048+3072)=384.
Cuando las tareas en tg asignan los intervalos de tiempo asignados por tg, se utilizará este peso proporcional. Cuanto más profundo sea el anidamiento del grupo, menor será el peso que se puede asignar proporcionalmente Se puede ver que las tareas en el grupo de tareas no conducen a la asignación de segmentos de tiempo bajo una carga alta.
Seis, intervalo de tiempo del grupo de tareas
6.1 Asignación de segmentos de tiempo
Si la programación de grupos CFS está habilitada, los segmentos de tiempo asignados por la capa superior se asignarán capa por capa a través de la proporción de peso de arriba a abajo. La función de asignación es sched_slice(). Pero no es conveniente atravesar de arriba hacia abajo, por lo que se cambia a atravesar de abajo hacia arriba.Después de todo, A*B*C y C*B*A son iguales.

La ruta principal de sched_slice es la siguiente:

En la interrupción de tick, si se encuentra que el tiempo de ejecución de se ha excedido su intervalo de tiempo asignado, activará la preferencia para que pueda renunciar a la CPU.
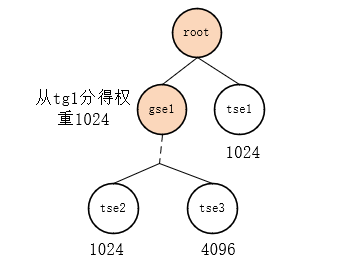
Como se muestra en la Figura 4, suponiendo que tg está anidado con 2 capas, y el peso de cada capa de gse de tg en la CPU actual es 1024, y suponiendo que el período se calcula directamente por el número de tareas, 5 tse, período es 3 * 5 = 15ms entonces:
tse1 obtiene 1024/(1024+1024) * 15 = 7,5 ms;
tse2 obtiene [1024/(1024+1024+1024)] * {[1024/(1024+1024)] * 15 }= 2.5ms
tse4 obtiene [1024/(1024+1024)] * {[1024/(1024+1024+1024)] * [1024/(1024+1024)] * 15} = 1,25 ms
Figura 4:
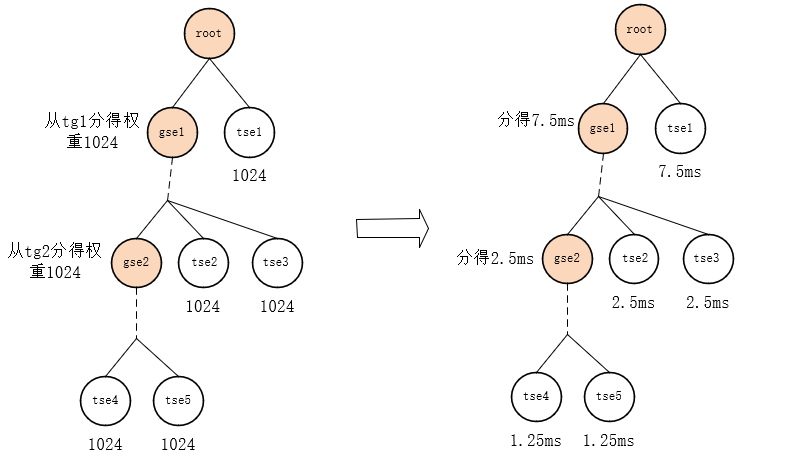
Nota: Los pesos de tg1 y tg2 se configuran a través del archivo cpu.shares, y luego gse en cada cpu distribuye el peso de acuerdo con la proporción de peso de grq en él desde el peso configurado por cpu.shares. El peso de gse ya no está vinculado al valor agradable.
6.2 Conducción en tiempo de ejecución
pick_next_task_fair() dará prioridad a la selección de se con el menor tiempo virtual. ¿Cómo se actualiza la hora virtual de gse? El tiempo virtual se actualiza en update_curr(), y luego el tiempo virtual de gse se actualiza capa por capa a través de for_each_sched_entity. Si tse se ejecuta durante 5 ms, cada gse de su nivel principal se ejecuta durante 5 ms, y luego cada nivel actualiza el tiempo virtual de acuerdo con su propio peso.

Ruta de llamada principal:

Al seleccionar la próxima tarea a ejecutar, seleccione se con el tiempo virtual más pequeño nivel por nivel.Si se selecciona gse, continúe seleccionando desde su grq hasta que se seleccione tse.
7. Carga PELT del grupo de trabajo
7.1 Calcular la línea de tiempo utilizada por la carga
La línea de tiempo utilizada para calcular la carga es diferente de la línea de tiempo utilizada para calcular el tiempo virtual. La línea de tiempo utilizada al calcular el tiempo virtual es rq->clock_task, que es el tiempo que tarda en ejecutarse. La línea de tiempo utilizada por la carga de cálculo es rq->clock_pelt, que se escala de acuerdo con la potencia informática de la CPU y el punto de frecuencia actual. Cuando la CPU está inactiva, se sincronizará con rq->clock_task. Por tanto, la carga calculada por PELT se puede utilizar directamente, sin necesidad de báscula como la carga calculada por WALT. La función para actualizar la línea de tiempo de rq->clock_pelt es update_rq_clock_pelt()

El delta calculado final= delta * (capacity_cpu / capacity_max(1024)) * (cur_cpu_freq / max_cpu_freq) es el valor de tiempo delta obtenido al ejecutar la CPU actual en el punto de frecuencia actual y escalarlo al punto de frecuencia máxima correspondiente a la frecuencia máxima valor de tiempo delta de la CPU de rendimiento. Luego agregue a clock_pelt. Por ejemplo, ejecutar 5 ms a 1 GHz en un núcleo pequeño solo puede ser equivalente a ejecutar 1 ms en un núcleo súper grande. Por lo tanto, ejecutar el mismo tiempo en núcleos de CPU de diferentes clústeres dará como resultado diferentes aumentos de carga.
7.2 Definición y cálculo de carga
load_avg se define como: load_avg = runnable% * scale_load_down(load).
runnable_avg 定义为:runnable_avg = runnable% * SCHED_CAPACITY_SCALE。
util_avg se define como: util_avg =% en ejecución * SCHED_CAPACITY_SCALE.
Estos valores de carga se almacenan en la estructura struct sched_avg, que está incrustada en las estructuras se y cfs_rq. Además, struct sched_avg también presenta miembros load_sum, runnable_sum, util_sum para ayudar en el cálculo. La carga de diferentes entidades (tse/gse/grq/cfs_rq) es cuánto quiere ejecutar su % ejecutable y cuánto es diferente del % en ejecución. Estos dos factores solo toman el valor [0,1] para tse, y está más allá de este rango para otras entidades.
7.2.1 carga tse
Echemos un vistazo a la fórmula de cálculo de carga tse Para profundizar la impresión, daré un ejemplo de ejecución de un ciclo sin fin. Ver update_load_avg --> __update_load_avg_se() para la función de cálculo.
load_avg: igual al peso * load_sum / divisor, donde peso = sched_prio_to_weight[prio-100]. Dado que load_sum es la progresión geométrica de la tarea en ejecución+estado ejecutable, el divisor es aproximadamente el valor máximo de la progresión geométrica, por lo que el load_avg de una tarea de bucle infinito está cerca de su peso.
runnable_avg: igual a runnable_sum / divisor. Dado que runnable_sum es la progresión geométrica de la tarea en ejecución+estado ejecutable y luego ampliada, el divisor es aproximadamente el valor máximo de la progresión geométrica, por lo que runnable_avg de una tarea de bucle infinito está cerca de SCHED_CAPACITY_SCALE.
util_avg: igual a util_sum / divisor. Dado que util_sum es la progresión geométrica del estado de ejecución de la tarea y luego se amplía, el divisor es aproximadamente el valor máximo de la progresión geométrica, por lo que el util_avg de una tarea de bucle infinito está cerca de SCHED_CAPACITY_SCALE.
load_sum: Es el valor acumulado de la progresión geométrica para el estado simple de ejecución+ejecutable de la tarea. Para un bucle infinito, este valor se aproxima a LOAD_AVG_MAX.
runnable_sum: es el valor acumulativo de la progresión geométrica de la tarea en ejecución + estado ejecutable y luego el valor después de escalar. Para un ciclo infinito, este valor tiende a ser LOAD_AVG_MAX * SCHED_CAPACITY_SCALE.
util_sum: es el valor acumulativo de la progresión geométrica del estado de ejecución de la tarea y luego el valor después de escalar. Para un bucle infinito que monopoliza un determinado núcleo, este valor tiende a ser LOAD_AVG_MAX * SCHED_CAPACITY_SCALE, si no se puede monopolizar, será menor que este valor.
7.2.2 Carga de cfs_rq
Echemos un vistazo a la fórmula de cálculo de carga cfs_rq Para profundizar la impresión, daré un ejemplo de ejecución de un ciclo infinito. Para la función de cálculo, consulte update_load_avg --> update_cfs_rq_load_avg --> __update_load_avg_cfs_rq().
load_avg: directamente igual a load_sum / divisor. cfs_rq se ejecuta por completo (ejecutando un ciclo infinito o varios ciclos infinitos), acercándose al peso de cfs_rq, que es la suma de los pesos de todas las entidades de programación adjuntas, a saber, Sum(sched_prio_to_weight[prio-100]).
runnable_avg: igual a runnable_sum / divisor. cfs_rq se ejecuta por completo (ejecutando un bucle infinito o múltiples bucles infinitos), acercándose al número de tareas en cfs_rq multiplicado por SCHED_CAPACITY_SCALE.
util_avg: igual a util_sum / divisor. cfs_rq se ejecuta por completo (ejecutando un bucle infinito o múltiples bucles infinitos), acercándose a SCHED_CAPACITY_SCALE.
load_sum: El peso de cfs_rq, es decir, la suma de los pesos de todos los ses en este nivel multiplicada por la progresión geométrica en el estado no inactivo. Tenga en cuenta que es este nivel, que es útil cuando se explica el nivel de carga h_load a continuación.
runnable_sum: el número de tareas ejecutables+en ejecución en todos los niveles en cfs_rq multiplicado por la progresión geométrica en el estado no inactivo y luego multiplicado por el valor de SCHED_CAPACITY_SCALE. Consulte __update_load_avg_cfs_rq().
util_sum: la suma de la progresión geométrica de todas las tareas que se ejecutan en cfs_rq multiplicada por SCHED_CAPACITY_SCALE.
load_avg, runnable_avg y util_avg describen la carga de la CPU desde tres dimensiones: peso (prioridad), número de tareas y ocupación del segmento de tiempo de la CPU.
7.2.3 carga gse
En contraste con tse para explicar gse:
(1) gse seguirá el mismo proceso de actualización de carga que tse (actualizando capa por capa, se actualizará a gse).
(2) La carga de funcionamiento de gse es diferente de la de tse. Runnable_sum de tse es el valor acumulativo de la progresión geométrica de la tarea en ejecución+estado ejecutable y luego el valor después de escalar. Y gse es la suma del número de tse de todos los niveles por debajo del nivel actual multiplicado por la progresión geométrica del tiempo y luego aumenta, vea la diferencia en los parámetros ejecutables de la función __update_load_avg_se().
(3) Aunque el load_avg de gse y tse es igual a se->weight * load_sum/divider, vea la diferencia de parámetros de ___update_load_avg(). Pero la fuente de peso es diferente, por lo que puede considerarse como un punto de diferencia.tse->peso proviene de su prioridad, y gse proviene de su cuota asignada de tg.
(4) gse tendrá un proceso de actualización de conducción de carga más que tse, que se explicará a continuación (si la programación del grupo CFS no está habilitada, solo hay una capa y no hay una estructura jerárquica de tg, por lo que no se requiere conducción, solo necesita ser actualizado a cfs_rq puede ser).
7.2.4 carga grq
La carga de grq no es diferente de la carga de cfs_rq en términos de actualizaciones. grq tendrá un proceso de actualización de conducción de carga más que cfs_rq, que se explicará a continuación.
7.2.5 Carga de tg
tg solo tiene una carga, que es tg->load_avg, y el valor es \Sum tg->cfs_rq[]->avg.load_avg, que es la suma de load_avg de grq en todas las CPU de tg. La actualización de carga de tg se implementa en update_tg_load_avg(), que se usa principalmente para asignar pesos a gse[].

Ruta de llamada:

7.3 Conducción de carga
La conducción de carga es un concepto solo después de habilitar la programación de grupos CFS. Cuando se inserta o elimina un tse en la jerarquía tg, la carga de toda la jerarquía cambia, por lo que debe realizarse capa por capa.
7.3.1 Condiciones de activación de conducción de carga
Si se requiere conducción de carga se marca a través del miembro de propagación de struct cfs_rq. El proceso de conducción de carga se activa al agregar/eliminar tse en grq. El valor de load_sum de tse se registrará en el miembro prop_runnable_sum de struct cfs_rq, y luego se conducirá hacia arriba capa por capa. Otras cargas (runnable_*, util_*) se transmitirán capa por capa a través de tse-->grq-->gse-->grq...
Marque la necesidad de conducción de carga en add_tg_cfs_propagate():

Esta ruta de llamada de función:

De lo anterior se puede ver que cuando la clase de programación que no es CSF se cambia a la clase de programación CFS, se mueve al tg actual, la tarea recién creada comienza a colgarse en cfs_rq y migra a la CPU actual, el proceso de transferencia de carga se activará En este momento, se transferirá a toda la jerarquía Conducción agrega la carga que trae esta tarea. Cuando una tarea migra fuera de la CPU actual, se convierte en una clase de programación que no es CFS o migra fuera de tg, la carga reducida al eliminar esta tarea se transferirá a toda la jerarquía.
Tenga en cuenta que la carga de la tarea no se elimina cuando está inactiva, pero su carga no aumenta durante el período de inactividad y decae con el tiempo.
7.3.2 Proceso de conducción de carga
El proceso de conducción de la carga se refleja en el proceso de actualización de la carga capa por capa. De la siguiente manera, se llama a la función de actualización de carga update_load_avg() en cada capa bajo la ruta principal:

La función de transferencia de carga y la función que debe transferirse son las mismas, que es add_tg_cfs_propagate(), y su ruta de llamada es la siguiente:

7.3.2.1 update_tg_cfs_util() Actualiza las cargas útiles util_* de gse y grq, y es responsable de entregar las cargas útiles a la capa superior.

Se puede ver que la carga útil de gse toma directamente la carga útil en su grq durante la conducción. Luego transmita a la capa superior actualizando el util_avg de la capa superior grq.
7.3.2.2 update_tg_cfs_runnable() Actualiza la carga runnable_* de gse y grq, y es responsable de pasar la carga a la capa superior.

Se puede ver que la carga ejecutable de gse también se toma directamente de la carga ejecutable en su grq durante la conducción. Luego diríjase a la capa superior actualizando runnable_avg de la capa superior grq.
7.3.2.3 update_tg_cfs_load() Actualiza la carga load_* de gse y grq, y es responsable de entregar la carga a la capa superior.
La carga de carga es bastante especial. Cuando se transmite la carga, no se toma directamente de la carga de carga de grq, pero el valor de load_sum de tse se registra al agregar/eliminar tareas a grq, y luego se transmite capa por capa en add_tg_cfs_propagate(), y la posición de transmisión se llama ruta:

El marcaje y conducción de las cargas de carga tienen toda esta función:

función de actualización de carga de carga:

La tarea de eliminación es asignar el load_sum promedio de se en grq a gse. La tarea de agregar es agregar directamente el valor delta al load_sum de gse.
load_avg se calcula de la misma manera que tse normal, que es load_sum*se_weight(gse)/divider.
A partir de la comparación, se puede ver que la dirección de conducción de la carga ejecutable y la carga útil es de grq-->gse, respectivamente a través de runnable_avg/util_avg, y gse toma directamente el valor de grq. La dirección de conducción de la carga es conducida por gse-->grq, y es conducida a través de load_sum.
La razón por la que el método de asignación de conducción de carga es diferente de la carga ejecutable y la carga útil puede estar relacionada con su algoritmo estadístico. Para runnable_avg, gse calcula la relación del número de tse en todos los niveles por debajo del nivel actual multiplicado por la serie temporal del estado ejecutable, agregar un tse al nivel superior es equivalente a agregar uno al número de tse; para util_avg, gse calcula la relación entre la progresión geométrica del estado de ejecución de todos los tse y la progresión del tiempo, agregar un tse a la capa superior equivale a aumentar la progresión geométrica del estado de ejecución de tse, y load_avg está relacionado con el peso de se, y el peso de gse y tse Las fuentes de peso son diferentes, la primera proviene de la cuota asignada de tg->shares, mientras que la segunda proviene de la prioridad y no se puede sumar ni restar directamente. Para sí, load_sum es una serie de tiempo simple de estado ejecutable y no implica peso, por lo que tanto tse como gse pueden usarla.
Para la conducción de load_avg, por ejemplo, como se muestra en la Figura 5 a continuación, si ts2 ha estado durmiendo, ts1 y ts3 son dos bucles sin fin, entonces load_avg de grq1 de gse1 se acercará a 4096, y la carga de la raíz cfs_rq se acercará a 2048, si en este momento es necesario migrar ts3. Si desea reducirlo directamente como calcular la carga de ejecutable y útil, el valor delta obtenido es -4096, entonces el load_avg de la raíz cfs_rq será un valor negativo (2048-4096<0), lo que obviamente es incorrecto. razonable. Si se realiza a través de load_sum, es solo una serie temporal, y después de la resta, solo equivale a perder el 50% de la carga en la raíz cfs_rq.
Figura 5:
NOTA: Esta es solo la ruta de actualización de conducción para cargas cuando se agregan/eliminan tareas en la jerarquía de tg, con el tiempo las cargas de gse/grq se actualizarán incluso si no se agregan/eliminan tareas, como actualizaciones de carga normales La función __update_load_avg_se() /update_cfs_rq_load_avg() no distingue entre tse o gse, cfs_rq o grq.
7.4 Carga jerárquica
Durante el equilibrio de carga, la carga en la CPU debe migrarse para lograr el equilibrio.Para lograr este objetivo, las tareas deben migrarse entre CPU. Sin embargo, el promedio de carga de cada tarea se no puede reflejar verdaderamente su contribución de carga a la raíz cfs rq (es decir, la CPU), porque la tarea se/cfs rq siempre calcula su carga promedio en un nivel específico. Por ejemplo, load_avg de grq no es igual a la suma de load_avg de todos los tse conectados a él, porque la serie de tiempo del ejecutable debe ser Sum(tse) > grq (hay un estado de ejecutable esperando para ejecutarse).
Para calcular la carga (h_load) de la tarea en la CPU, se introduce el concepto de carga de jerarquía en cada cfs rq Para el cfs rq de nivel superior, su carga de jerarquía es igual a la carga promedio de cfs rq. A medida que avanza la jerarquía, el cfs rq La carga de la jerarquía se define de la siguiente manera:
El h_load del cfs rq de la siguiente capa = el h_load del cfs rq de la capa anterior x la proporción de gse load en el cfs load de la capa anterior
Al calcular la h_load del tse inferior, usamos la siguiente fórmula:
h_carga de tse = h_carga de grq x carga promedio de tse / carga promedio de grq
La función para obtener y actualizar el h_load de la tarea es la siguiente:

La función para actualizar h_load de grq es la siguiente:

Ruta de llamada:

Se puede ver que se utiliza principalmente en el mecanismo wake_affine_weight y en la lógica de equilibrio de carga. Por ejemplo, en el balanceo de carga donde el tipo de migración es carga, cuánto load_avg se necesita migrar para hacer el balanceo de carga, se usa task_h_load(), consulte detach_tasks().
8. Resumen
Este artículo presenta el motivo de la introducción de la función de programación de grupos CFS, el método de configuración y algunos detalles de implementación. Esta función puede "limitar suavemente" (en comparación con el control de ancho de banda de CFS) la proporción de recursos de CPU utilizados por cada tarea de grupo bajo carga alta, para lograr el propósito de un uso justo de los recursos de CPU entre grupos. En la versión anterior del código nativo de Android, las restricciones sobre la agrupación en segundo plano son estrictas (incluso se establece background/cpu.shares en 52) y el enfoque de los recursos de la CPU se inclina hacia la agrupación en primer plano, pero esta configuración puede aparecer en primer plano en algunos escenarios Cuando la tarea está bloqueada por la tarea en segundo plano, para la configuración universal, en las últimas versiones de Android, el cpu.shares de cada grupo se establece en 1024 para buscar la equidad de los recursos de CPU entre los grupos.
9. Referencia
1. Código fuente del kernel (https://www.kernel.org/) y código fuente de Android (https://source.android.com/docs/setup/download/downloading)
2. Documentación del kernel Documentation/admin-guide/cgroup-v13. Programador CFS (3) - programación de grupos: http://www.wowotech.net/process_management/449.html
4. Análisis del algoritmo PELT: http://www.wowotech.net/process_management/pelt.html

Mantenga presionado para seguir Kernel Craftsman WeChat
Tecnología Linux Kernel Black | Artículos técnicos | Tutoriales destacados