

1. ¿Qué es un hilo?
2. Cómo crear un hilo
2.1 Creando hilos en JAVA
/*** 继承Thread类,重写run方法*/class MyThread extends Thread {public void run() {System.out.println("myThread..." + Thread.currentThread().getName());} }/*** 实现Runnable接口,实现run方法*/class MyRunnable implements Runnable {public void run() {System.out.println("MyRunnable..." + Thread.currentThread().getName());} }/*** 实现Callable接口,指定返回类型,实现call方法*/class MyCallable implements Callable<String> {public String call() throws Exception {return "MyCallable..." + Thread.currentThread().getName();} }
2.2 Pruébalo
public static void main(String[] args) throws Exception {MyThread thread = new MyThread();thread.run(); //myThread...mainthread.start(); //myThread...Thread-0MyRunnable myRunnable = new MyRunnable();Thread thread1 = new Thread(myRunnable);myRunnable.run(); //MyRunnable...mainthread1.start(); //MyRunnable...Thread-1MyCallable myCallable = new MyCallable();FutureTask<String> futureTask = new FutureTask<>(myCallable);Thread thread2 = new Thread(futureTask);thread2.start();System.out.println(myCallable.call()); //MyCallable...mainSystem.out.println(futureTask.get()); //MyCallable...Thread-2}
2.3 Problema
2.4 Análisis de problemas
class Thread implements Runnable { //Thread类实现了Runnalbe接口,实现了run()方法private Runnable target;public synchronized void start() {...boolean started = false;try {start0(); //可以看到,start()方法真实的调用时start0()方法started = true;} finally {...}}private native void start0(); //start0()是一个native方法,由JVM调用底层操作系统,开启一个线程,由操作系统过统一调度public void run() {if (target != null) {target.run(); //操作系统在执行新开启的线程时,回调Runnable接口的run()方法,执行我们预设的线程任务}}}
2.5 Resumen
-
JAVA no puede crear subprocesos directamente para realizar tareas, sino que llama al sistema operativo para iniciar el subproceso creando un objeto Thread, y el sistema operativo vuelve a llamar al método run () de la interfaz Runnable para realizar la tarea; -
La forma de implementar Runnable separa las tareas de devolución de llamada reales que ejecutará el subproceso, desacoplando así el inicio del subproceso de las tareas de devolución de llamada; -
La forma de implementar Callable es usar el modo Futuro no solo para desacoplar el inicio del hilo de la tarea de devolución de llamada, sino también para obtener el resultado de la ejecución una vez completada la ejecución;
1. ¿Qué es el subproceso múltiple?
2. ¿Cuáles son los beneficios del subproceso múltiple?
2.1 Procesamiento en serie
public static void main(String[] args) throws Exception {System.out.println("start...");long start = System.currentTimeMillis();for (int i = 0; i < 5; i++) {Thread.sleep(2000); //每个任务执行2秒System.out.println("task done..."); //处理执行结果}long end = System.currentTimeMillis();System.out.println("end...,time = " + (end - start));}//执行结果start...task done...task done...task done...task done...task done... end...,time = 10043
2.2 Procesamiento paralelo
public static void main(String[] args) throws Exception {System.out.println("start...");long start = System.currentTimeMillis();List<Future> list = new ArrayList<>();for (int i = 0; i < 5; i++) {Callable<String> callable = new Callable<String>() {@Overridepublic String call() throws Exception {Thread.sleep(2000); //每个任务执行2秒return "task done...";}};FutureTask task = new FutureTask(callable);list.add(task);new Thread(task).start();}list.forEach(future -> {try {System.out.println(future.get()); //处理执行结果 } catch (Exception e) {}});long end = System.currentTimeMillis();System.out.println("end...,time = " + (end - start));}//执行结果start...task done...task done...task done...task done...task done... end...,time = 2005
2.3 Resumen
-
El subproceso múltiple puede dividir una tarea en varias subtareas y se pueden ejecutar varias subtareas al mismo tiempo. Cada subtarea es un subproceso. -
El subproceso múltiple consiste en completar múltiples tareas simultáneamente, no para mejorar la eficiencia operativa, sino para mejorar la eficiencia del uso de recursos para mejorar la eficiencia del sistema.
2.4 Problemas con subprocesos múltiples
1. Cómo diseñar un grupo de subprocesos
1.1 Funciones básicas del grupo de subprocesos
-
Los subprocesos múltiples crearán una gran cantidad de subprocesos para agotar los recursos, por lo que el grupo de subprocesos debe limitar la cantidad de subprocesos para garantizar que los recursos del sistema no se agoten; -
Cada vez que se crea , aumentará la sobrecarga de creación, por lo que el grupo de hilos debe reducir la creación de hilos e intentar reutilizar los hilos ya creados;
1.2 El grupo de subprocesos enfrenta problemas
-
Sabemos que los hilos se reciclarán después de completar sus tareas, entonces, ¿cómo reutilizamos los hilos? -
Hemos especificado el número máximo de subprocesos. Cuando el número de tareas excede el número de subprocesos, ¿cómo debemos manejarlo?
1.3 La innovación viene de la vida
-
Cuando llegó la mercancía todavía no teníamos camiones, tuvimos que comprar un camión por cada lote de mercancías a transportar; -
Cuando se complete el transporte del camión y el siguiente lote de mercancías aún no haya llegado, el camión se estacionará en el almacén y podrá transportarse inmediatamente cuando lleguen las mercancías; -
Cuando tengamos una cierta cantidad de autos y creamos que son suficientes, ya no compraremos autos. Si llegan nuevos productos en este momento, primero los pondremos en el almacén y esperaremos a que los autos regresen. entrega; -
Cuando llega la gran venta del 618, hay demasiadas mercancías para entregar, los autos están en la carretera y los almacenes están llenos. ¿Qué debemos hacer? Elegimos alquilar temporalmente algunos autos para ayudar con la entrega y mejorar la eficiencia de entrega; -
Sin embargo, todavía hay demasiadas mercancías. Hemos agregado camiones temporales, pero todavía no pueden entregarlas. En este momento, no tenemos más remedio que hacer que los clientes hagan cola o no aceptarlas en absoluto. -
Después de completar con éxito la gran venta , se entregaron los bienes acumulados y, para reducir costos, devolvimos todos los autos alquilados temporalmente;
1.4 La tecnología proviene de la innovación
-
Cuando llega una tarea y aún no tenemos un hilo, debemos crear un hilo para ejecutar la tarea; -
Cuando se completa la tarea del subproceso, el subproceso no se libera y espera a que entre la siguiente tarea y luego la ejecuta; -
Cuando el número de subprocesos creados alcanza una cierta cantidad, almacenamos nuevas tareas y esperamos a que se ejecuten los subprocesos inactivos, lo que requiere que el grupo de subprocesos tenga un contenedor para almacenar tareas; -
Cuando el contenedor está lleno, necesitamos agregar algunos subprocesos temporales para mejorar la eficiencia del procesamiento; -
Cuando una tarea no se puede procesar después de agregar un hilo temporal, la tarea debe rechazarse; -
Cuando se completen todas las tareas, los subprocesos temporales deben liberarse para evitar sobrecargas innecesarias;
2. Análisis detallado del grupo de subprocesos.
2.1 ¿Cómo se diseña el grupo de subprocesos en JAVA?
2.1.1 Diseño del grupo de subprocesos
public class ThreadPoolExecutor extends AbstractExecutorService {//线程池的打包控制状态,用高3位来表示线程池的运行状态,低29位来表示线程池中工作线程的数量private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));//值为29,用来表示偏移量private static final int COUNT_BITS = Integer.SIZE - 3;//线程池的最大容量private static final int CAPACITY = (1 << COUNT_BITS) - 1;//线程池的运行状态,总共有5个状态,用高3位来表示private static final int RUNNING = -1 << COUNT_BITS; //接受新任务并处理阻塞队列中的任务private static final int SHUTDOWN = 0 << COUNT_BITS; //不接受新任务但会处理阻塞队列中的任务private static final int STOP = 1 << COUNT_BITS; //不会接受新任务,也不会处理阻塞队列中的任务,并且中断正在运行的任务private static final int TIDYING = 2 << COUNT_BITS; //所有任务都已终止, 工作线程数量为0,即将要执行terminated()钩子方法private static final int TERMINATED = 3 << COUNT_BITS; // terminated()方法已经执行结束//任务缓存队列,用来存放等待执行的任务private final BlockingQueue<Runnable> workQueue;//全局锁,对线程池状态等属性修改时需要使用这个锁private final ReentrantLock mainLock = new ReentrantLock();//线程池中工作线程的集合,访问和修改需要持有全局锁private final HashSet<Worker> workers = new HashSet<Worker>();// 终止条件private final Condition termination = mainLock.newCondition();//线程池中曾经出现过的最大线程数private int largestPoolSize;//已完成任务的数量private long completedTaskCount;//线程工厂private volatile ThreadFactory threadFactory;//任务拒绝策略private volatile RejectedExecutionHandler handler;//线程存活时间private volatile long keepAliveTime;//是否允许核心线程超时private volatile boolean allowCoreThreadTimeOut;//核心池大小,若allowCoreThreadTimeOut被设置,核心线程全部空闲超时被回收的情况下会为0private volatile int corePoolSize;//最大池大小,不得超过CAPACITYprivate volatile int maximumPoolSize;//默认的任务拒绝策略private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();//运行权限相关private static final RuntimePermission shutdownPerm =new RuntimePermission("modifyThread");...}
-
Proporciona gestión de la creación, el número y el tiempo de supervivencia de subprocesos; -
Proporciona gestión de la transferencia de estado del grupo de subprocesos; -
Se proporcionan varios contenedores para el almacenamiento en caché de tareas; -
Proporciona un mecanismo para manejar tareas redundantes; -
Proporciona funciones ;
2.1.2 Constructor de grupo de subprocesos
//构造函数public ThreadPoolExecutor(int corePoolSize, //核心线程数int maximumPoolSize, //最大允许线程数long keepAliveTime, //线程存活时间TimeUnit unit, //存活时间单位BlockingQueue<Runnable> workQueue, //任务缓存队列ThreadFactory threadFactory, //线程工厂RejectedExecutionHandler handler) { //拒绝策略if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
-
El constructor nos dice cómo usar el grupo de subprocesos y qué características del grupo de subprocesos podemos controlar;
2.1.3 Ejecución del grupo de subprocesos
2.1.3.1 Método de enviar tarea
-
ejecución pública nula (comando ejecutable); -
Futuro<?> enviar (tarea ejecutable); -
Envío futuro (tarea ejecutable, resultado T); -
Envío futuro (tarea invocable);
public Future> submit(Runnable task) {if (task == null) throw new NullPointerException();RunnableFuture<Void> ftask = newTaskFor(task, null);execute(ftask);return ftask;}
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();//第一步:创建核心线程if (workerCountOf(c) < corePoolSize) { //worker数量小于corePoolSizeif (addWorker(command, true)) //创建workerreturn;c = ctl.get();}//第二步:加入缓存队列if (isRunning(c) && workQueue.offer(command)) { //线程池处于RUNNING状态,将任务加入workQueue任务缓存队列int recheck = ctl.get();if (! isRunning(recheck) && remove(command)) //双重检查,若线程池状态关闭了,移除任务reject(command);else if (workerCountOf(recheck) == 0) //线程池状态正常,但是没有线程了,创建workeraddWorker(null, false);}//第三步:创建临时线程else if (!addWorker(command, false))reject(command);}
-
Si la cantidad de subprocesos principales es insuficiente, cree subprocesos principales; -
Cuando el subproceso principal está lleno, se agrega a la cola de caché; -
Cuando la cola de caché está llena, se agregan subprocesos no centrales; -
Si los subprocesos también están llenos, la tarea será rechazada;
2.1.3.2 Crear hilos
private boolean addWorker(Runnable firstTask, boolean core) {retry:for (;;) {int c = ctl.get();int rs = runStateOf(c);//等价于:rs>=SHUTDOWN && (rs != SHUTDOWN || firstTask != null || workQueue.isEmpty())//线程池已关闭,并且无需执行缓存队列中的任务,则不创建if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;for (;;) {int wc = workerCountOf(c);if (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;if (compareAndIncrementWorkerCount(c)) //CAS增加线程数break retry;c = ctl.get(); // Re-read ctlif (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop}}//上面的流程走完,就可以真实开始创建线程了boolean workerStarted = false;boolean workerAdded = false;Worker w = null;try {w = new Worker(firstTask); //这里创建了线程final Thread t = w.thread;if (t != null) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// Recheck while holding lock.// Back out on ThreadFactory failure or if// shut down before lock acquired.int rs = runStateOf(ctl.get());if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive()) // precheck that t is startablethrow new IllegalThreadStateException();workers.add(w); //这里将线程加入到线程池中int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}if (workerAdded) {t.start(); //添加成功,启动线程workerStarted = true;}}} finally {if (! workerStarted)addWorkerFailed(w); //添加线程失败操作}return workerStarted;}
-
Aumentar el número de hilos; -
Cree una instancia de trabajador de subprocesos y únase al grupo de subprocesos; -
Únase para completar el hilo de apertura; -
Si el inicio falla, el proceso adicional se revertirá;
2.1.3.3 Implementación de subprocesos de trabajo
private final class Worker //Worker类是ThreadPoolExecutor的内部类extends AbstractQueuedSynchronizerimplements Runnable{final Thread thread; //持有实际线程Runnable firstTask; //worker所对应的第一个任务,可能为空volatile long completedTasks; //记录执行任务数Worker(Runnable firstTask) {setState(-1); // inhibit interrupts until runWorkerthis.firstTask = firstTask;this.thread = getThreadFactory().newThread(this);}public void run() {runWorker(this); //当前线程调用ThreadPoolExecutor中的runWorker方法,在这里实现的线程复用}...继承AQS,实现了不可重入锁...}
-
Esta clase contiene un hilo de trabajo y procesa continuamente las nuevas tareas que obtiene. El hilo que contiene es un hilo reutilizable; -
Esta clase puede considerarse como una clase de adaptación: en el método run (), en realidad se llama al método runWorker () para obtener continuamente nuevas tareas y completar la reutilización de subprocesos;
final void runWorker(Worker w) { //ThreadPoolExecutor中的runWorker方法,在这里实现的线程复用Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true; //标识线程是否异常终止try {while (task != null || (task = getTask()) != null) { //这里会不断从任务队列获取任务并执行w.lock();//线程是否需要中断if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {beforeExecute(wt, task); //执行任务前的Hook方法,可自定义Throwable thrown = null;try {task.run(); //执行实际的任务} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {afterExecute(task, thrown); //执行任务后的Hook方法,可自定义}} finally {task = null; //执行完成后,将当前线程中的任务制空,准备执行下一个任务w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly); //线程执行完成后的清理工作}}
-
循环从缓存队列中获取新的任务,直到没有任务为止; -
使用worker持有的线程真实执行任务; -
任务都执行完成后的清理工作;
2.1.3.5、队列中获取待执行任务
private Runnable getTask() {boolean timedOut = false; //标识当前线程是否超时未能获取到task对象for (;;) {int c = ctl.get();int rs = runStateOf(c);// Check if queue empty only if necessary.if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {decrementWorkerCount();return null;}int wc = workerCountOf(c);// Are workers subject to culling?boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;if ((wc > maximumPoolSize || (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c)) //若线程存活时间超时,则CAS减去线程数量return null;continue;}try {Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : //允许超时回收则阻塞等待workQueue.take(); //不允许则直接获取,没有就返回nullif (r != null)return r;timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}}
2.1.3.6、清理工作
private void processWorkerExit(Worker w, boolean completedAbruptly) {if (completedAbruptly) // If abrupt, then workerCount wasn't adjusteddecrementWorkerCount();final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {completedTaskCount += w.completedTasks;workers.remove(w); //移除执行完成的线程} finally {mainLock.unlock();}tryTerminate(); //每次回收完一个线程后都尝试终止线程池int c = ctl.get();if (runStateLessThan(c, STOP)) { //到这里说明线程池没有终止if (!completedAbruptly) {int min = allowCoreThreadTimeOut ? 0 : corePoolSize;if (min == 0 && ! workQueue.isEmpty())min = 1;if (workerCountOf(c) >= min)return; // replacement not needed}addWorker(null, false); //异常终止线程的话,需要在常见一个线程}}
-
真实完成线程池线程的回收; -
调用尝试终止线程池; -
保证线程池正常运行;
2.1.3.7、尝试终止线程池
final void tryTerminate() {for (;;) {int c = ctl.get();//若线程池正在执行、线程池已终止、线程池还需要执行缓存队列中的任务时,返回if (isRunning(c) ||runStateAtLeast(c, TIDYING) ||(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))return;//执行到这里,线程池为SHUTDOWN且无待执行任务 或 STOP 状态if (workerCountOf(c) != 0) {interruptIdleWorkers(ONLY_ONE); //只中断一个线程return;}//执行到这里,线程池已经没有可用线程了,可以终止了final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) { //CAS设置线程池终止try {terminated(); //执行钩子方法} finally {ctl.set(ctlOf(TERMINATED, 0)); //这里将线程池设为终态termination.signalAll();}return;}} finally {mainLock.unlock();}// else retry on failed CAS}}
-
实际尝试终止线程池; -
终止成功则调用钩子方法,并且将线程池置为终态。
2.2、JAVA线程池总结
2.2.1、主要功能
线程数量及存活时间的管理;
待处理任务的存储功能;
线程复用机制功能;
任务超量的拒绝功能;
2.2.2、扩展功能
-
简单的执行结果统计功能; -
提供线程执行异常处理机制; -
执行前后处理流程自定义; -
提供线程创建方式的自定义;
2.2.3、流程总结
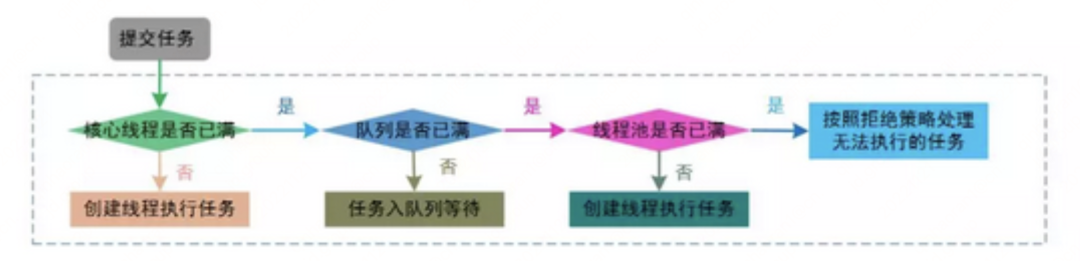
2.3、JAVA线程池使用
public static void main(String[] args) throws Exception {//创建线程池ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 100, TimeUnit.SECONDS, new ArrayBlockingQueue(5));//加入4个任务,小于核心线程,应该只有4个核心线程,队列为0for (int i = 0; i < 4; i++) {threadPoolExecutor.submit(new MyRunnable());}System.out.println("worker count = " + threadPoolExecutor.getPoolSize()); //worker count = 4System.out.println("queue size = " + threadPoolExecutor.getQueue().size()); //queue size = 0//再加4个任务,超过核心线程,但是没有超过核心线程 + 缓存队列容量,应该5个核心线程,队列为3for (int i = 0; i < 4; i++) {threadPoolExecutor.submit(new MyRunnable());}System.out.println("worker count = " + threadPoolExecutor.getPoolSize()); //worker count = 5System.out.println("queue size = " + threadPoolExecutor.getQueue().size()); //queue size = 3//再加4个任务,队列满了,应该5个热核心线程,队列5个,非核心线程2个for (int i = 0; i < 4; i++) {threadPoolExecutor.submit(new MyRunnable());}System.out.println("worker count = " + threadPoolExecutor.getPoolSize()); //worker count = 7System.out.println("queue size = " + threadPoolExecutor.getQueue().size()); //queue size = 5//再加4个任务,核心线程满了,应该5个热核心线程,队列5个,非核心线程5个,最后一个拒绝for (int i = 0; i < 4; i++) {try {threadPoolExecutor.submit(new MyRunnable());} catch (Exception e) {e.printStackTrace(); //java.util.concurrent.RejectedExecutionException}}System.out.println("worker count = " + threadPoolExecutor.getPoolSize()); //worker count = 10System.out.println("queue size = " + threadPoolExecutor.getQueue().size()); //queue size = 5System.out.println(threadPoolExecutor.getTaskCount()); //共执行15个任务//执行完成,休眠15秒,非核心线程释放,应该5个核心线程,队列为0Thread.sleep(1500);System.out.println("worker count = " + threadPoolExecutor.getPoolSize()); //worker count = 5System.out.println("queue size = " + threadPoolExecutor.getQueue().size()); //queue size = 0//关闭线程池threadPoolExecutor.shutdown();}
本文分享自微信公众号 - 京东云开发者(JDT_Developers)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
{{o.name}}
{{m.name}}