Regresión lineal con series de tiempo
Esta serie registra el número de libros de tapa dura vendidos en una tienda minorista en un período de 30 días. Tenga en cuenta que tenemos una columna de observaciones de tapa dura con fechas indexadas en el tiempo.
import pandas as pd
df = pd.read_csv("../input/ts-course-data/book_sales.csv",
index_col="Date",#指定某列为行索引,否则自动索引0, 1, .....
parse_dates=["Date"],#parse_dates=[0,1,2,3,4] : 尝试解析0,1,2,3,4列为时间格式;
).drop("Paperback", axis=1)#删除列
df.head()#df.head(n):该方法用于查看dataframe数据表中开头n行的数据,若参数n未设置,即df.head(),则默认查看dataframe中前5行的数据。Las características de paso de tiempo son características que podemos derivar directamente del índice de tiempo. La función de paso de tiempo más básica es la variable ficticia de tiempo, que cuenta los pasos de tiempo en la secuencia de principio a fin.
import numpy as np
df['Time'] = np.arange(len(df.index))#函数返回一个有终点和起点的固定步长的排列,如[1,2,3,4,5],起点是1,终点是6,步长为1。
df.head()La variable ficticia de tiempo nos permite ajustar una curva a la serie de tiempo en un gráfico de tiempo, donde el tiempo forma el eje x.
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("seaborn-whitegrid")
plt.rc(
"figure",
autolayout=True,
figsize=(11, 4),
titlesize=18,
titleweight='bold',
)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=16,
titlepad=10,
)
%config InlineBackend.figure_format = 'retina'#避免绘制模糊图像,JuypterNotebook中的默认绘图看起来有些模糊。
fig, ax = plt.subplots()
ax.plot('Time', 'Hardcover', data=df, color='0.75')
ax = sns.regplot(x='Time', y='Hardcover', data=df, ci=None, scatter_kws=dict(color='0.25'))
ax.set_title('Time Plot of Hardcover Sales');Para crear características retrasadas, cambiamos las observaciones de la serie objetivo para que parezcan ocurrir en un momento posterior. Aquí creamos una función de retraso de 1 paso, aunque también son posibles movimientos de varios pasos.
df['Lag_1'] = df['Hardcover'].shift(1)#Pandas dataframe.shift()函数根据需要的周期数移动索引,并带有可选的时间频率。该函数采用称为周期的标量参数,该参数表示要在所需轴上进行的平移次数。
df = df.reindex(columns=['Hardcover', 'Lag_1'])#reindex重新构建索引
df.head()Por lo tanto, la función de retraso nos permite ajustar una curva a un gráfico de retraso, donde cada observación de la serie corresponde a la observación anterior.
fig, ax = plt.subplots()
ax = sns.regplot(x='Lag_1', y='Hardcover', data=df, ci=None,
scatter_kws=dict(color='0.25'))#sns.regplot():绘图数据和线性回归模型拟合,ci置信区间,一般为None
ax.set_aspect('equal')#设置图形的宽高比,equal为1:1
ax.set_title('Lag Plot of Hardcover Sales');Puede ver en el gráfico de retraso que las ventas en un día determinado (tapa dura) están relacionadas con las ventas del día anterior (Lag_1). Cuando ve una relación como esta, sabe que una función de retraso puede ser útil.
En términos más generales, las funciones de retraso le permiten modelar dependencias en serie. Una serie de tiempo tiene dependencia serial cuando las observaciones se pueden predecir a partir de observaciones anteriores. En las ventas de tapa dura, podemos predecir que las ventas altas de un día generalmente significarán ventas altas al día siguiente.
La adaptación de algoritmos de aprendizaje automático a problemas de series de tiempo se trata principalmente de ingeniería de características con índices de tiempo y retrasos.
Ejemplo: tráfico de túneles
Tunnel Traffic es una serie temporal que describe el número de vehículos que pasan a diario por el túnel de Barreg en Suiza desde noviembre de 2003 hasta noviembre de 2005. En este ejemplo, practicaremos la aplicación de la regresión lineal a las funciones con intervalos de tiempo y rezagadas.
from pathlib import Path
from warnings import simplefilter
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
simplefilter("ignore") # ignore warnings to clean up output cells
# Set Matplotlib defaults
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True, figsize=(11, 4))
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
plot_params = dict(
color="0.75",
style=".-",
markeredgecolor="0.25",
markerfacecolor="0.25",
legend=False,
)
%config InlineBackend.figure_format = 'retina'
# Load Tunnel Traffic dataset
data_dir = Path("../input/ts-course-data")
tunnel = pd.read_csv(data_dir / "tunnel.csv", parse_dates=["Day"])
# Create a time series in Pandas by setting the index to a date
# column. We parsed "Day" as a date type by using `parse_dates` when
# loading the data.
tunnel = tunnel.set_index("Day")
# By default, Pandas creates a `DatetimeIndex` with dtype `Timestamp`
# (equivalent to `np.datetime64`, representing a time series as a
# sequence of measurements taken at single moments. A `PeriodIndex`,
# on the other hand, represents a time series as a sequence of
# quantities accumulated over periods of time. Periods are often
# easier to work with, so that's what we'll use in this course.
tunnel = tunnel.to_period()
tunnel.head()Ejercicio: Regresión Lineal Con Series Temporales
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.time_series.ex1 import *
# Setup notebook
from pathlib import Path
from learntools.time_series.style import * # plot style settings
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.linear_model import LinearRegression
data_dir = Path('../input/ts-course-data/')
comp_dir = Path('../input/store-sales-time-series-forecasting')
book_sales = pd.read_csv(
data_dir / 'book_sales.csv',
index_col='Date',
parse_dates=['Date'],
).drop('Paperback', axis=1)
book_sales['Time'] = np.arange(len(book_sales.index))
book_sales['Lag_1'] = book_sales['Hardcover'].shift(1)
book_sales = book_sales.reindex(columns=['Hardcover', 'Time', 'Lag_1'])
ar = pd.read_csv(data_dir / 'ar.csv')
dtype = {
'store_nbr': 'category',
'family': 'category',
'sales': 'float32',
'onpromotion': 'uint64',
}
store_sales = pd.read_csv(
comp_dir / 'train.csv',
dtype=dtype,
parse_dates=['date'],
infer_datetime_format=True,
)
store_sales = store_sales.set_index('date').to_period('D')
store_sales = store_sales.set_index(['store_nbr', 'family'], append=True)
average_sales = store_sales.groupby('date').mean()['sales']Una ventaja de la regresión lineal sobre los algoritmos más complejos es que los modelos que crea son interpretables, lo que facilita la explicación de la contribución de cada característica a la predicción. En el modelo objetivo = ponderación * función + sesgo, la ponderación indica el cambio promedio en el objetivo por unidad de cambio en la función
fig, ax = plt.subplots()
ax.plot('Time', 'Hardcover', data=book_sales, color='0.75')
ax = sns.regplot(x='Time', y='Hardcover', data=book_sales, ci=None, scatter_kws=dict(color='0.25'))
ax.set_title('Time Plot of Hardcover Sales');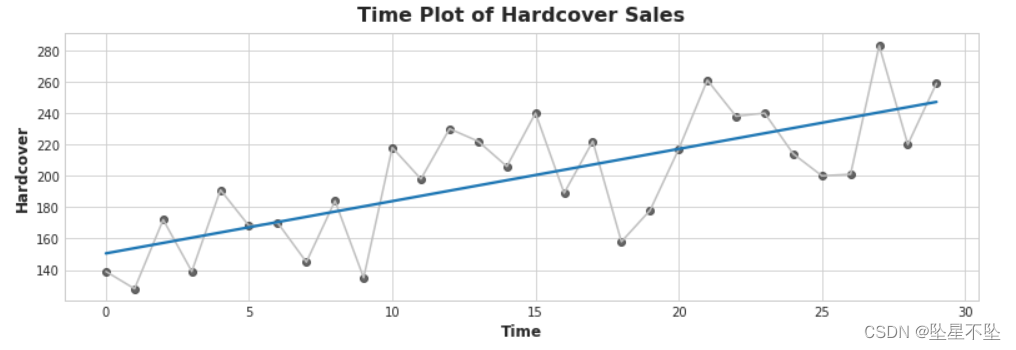
1) Interpretar la regresión lineal usando una variable ficticia de tiempo
La ecuación para la línea de regresión lineal es (aproximadamente) tapa dura = 3,33 * tiempo + 150,5. ¿Cuánto espera que cambien las ventas promedio de libros de tapa dura en 6 días? Después de pensarlo, ejecute la siguiente celda
# View the solution (Run this line to receive credit!)
q_1.check()Un cambio en el tiempo de 6 pasos corresponde a un cambio promedio en las ventas de libros de tapa dura de 6 * 3,33 = 19,98.
# Uncomment the next line for a hint
#q_1.hint()La interpretación de los coeficientes de regresión puede ayudarnos a identificar dependencias seriales en gráficas de tiempo. Considere el objetivo del modelo = peso * lag_1 + error, donde el error es ruido aleatorio y el peso es un número entre -1 y 1. En este caso, el peso le dice qué tan probable es que el próximo paso de tiempo tenga el mismo signo que el paso de tiempo anterior, un peso cercano a 1 significa que es probable que el objetivo tenga el mismo signo que el paso anterior, y un peso cercano a -1 significa que los objetivos pueden tener signos opuestos.
2) Interpretación de la regresión lineal con características rezagadas
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(11, 5.5), sharex=True)
ax1.plot(ar['ar1'])
ax1.set_title('Series 1')
ax2.plot(ar['ar2'])
ax2.set_title('Series 2');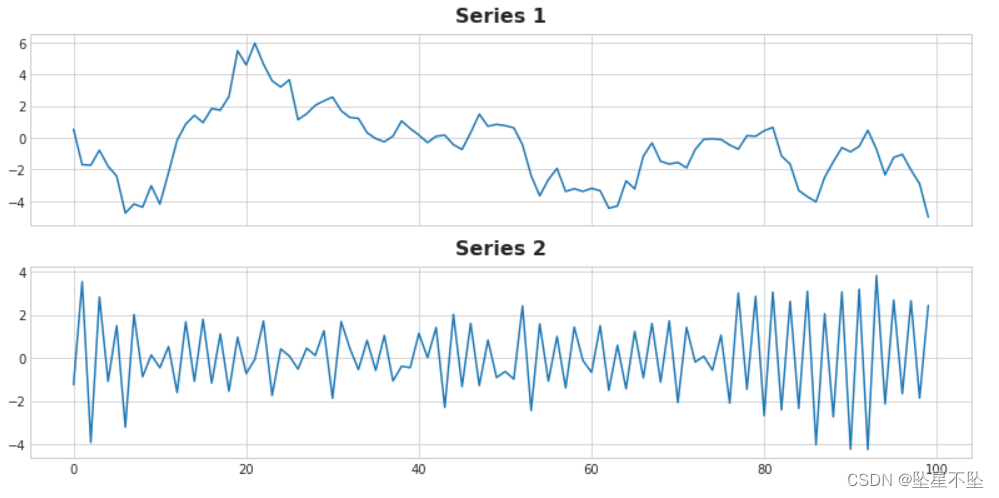
Una de las series tiene la ecuación objetivo = 0,95 * lag_1 + error y la otra tiene la ecuación objetivo = -0,95 * lag_1 + error, que difieren solo en el signo de la función de retraso. ¿Puedes nombrar las ecuaciones para cada serie?
# View the solution (Run this cell to receive credit!)
q_2.check()# Uncomment the next line for a hint
#q_2.hint()Ahora comenzaremos a competir con los datos usando Store Sales - Time Series Forecasting. El conjunto de datos completo contiene casi 1800 colecciones que registran las ventas en tiendas en varias líneas de productos desde 2013 hasta 2017. En esta lección, solo trataremos con una sola serie (average_sales) que promedia las ventas por día.
3) Características del paso de tiempo de ajuste
Complete el código a continuación para crear un modelo de regresión lineal que presente una serie de pasos de tiempo de ventas promedio de productos. Los objetivos se encuentran en una columna denominada "Ventas".
from sklearn.linear_model import LinearRegression
df = average_sales.to_frame()
# YOUR CODE HERE: Create a time dummy
time = ____
df['time'] = time
# YOUR CODE HERE: Create training data
X = ____ # features
y = ____ # target
# Train the model
model = LinearRegression()
model.fit(X, y)
# Store the fitted values as a time series with the same time index as
# the training data
y_pred = pd.Series(model.predict(X), index=X.index)
# Check your answer
q_3.check()# Lines below will give you a hint or solution code
#q_3.hint()
#q_3.solution()
ax = y.plot(**plot_params, alpha=0.5)
ax = y_pred.plot(ax=ax, linewidth=3)
ax.set_title('Time Plot of Total Store Sales');