1. Antecedentes
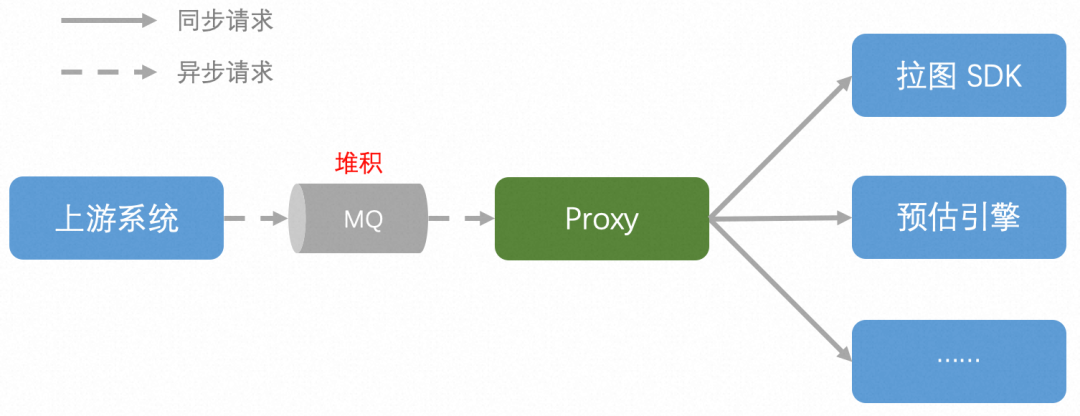
Los enlaces del sistema involucrados en este problema se muestran en la figura anterior, y las responsabilidades básicas de cada sistema son:
- Proxy: proporcione el servicio de proxy de solicitud. Agente unificado de varias solicitudes enviadas al sistema descendente, de modo que el sistema ascendente no necesite percibir la diferencia en el uso de los servicios descendentes; al mismo tiempo, proporciona funciones de servicio refinadas como limitación y desvío de corriente;
- Latu SDK: proporciona una función de descarga de imágenes unificada para cada plataforma de almacenamiento. Por lo general, se organiza junto con el modelo de algoritmo de imagen;
- Motor de estimación: Proporciona servicios de razonamiento modelo. Apoyar la implementación de ingeniería de varios modelos de algoritmos de aprendizaje automático y aprendizaje profundo;
2. Resolución de problemas
Nota: La cola de mensajes utilizada en este artículo se denomina internamente MetaQ y la versión externa de código abierto es RocketMQ, a la que nos referiremos como "MQ" a continuación.
2.1 Descripción del problema
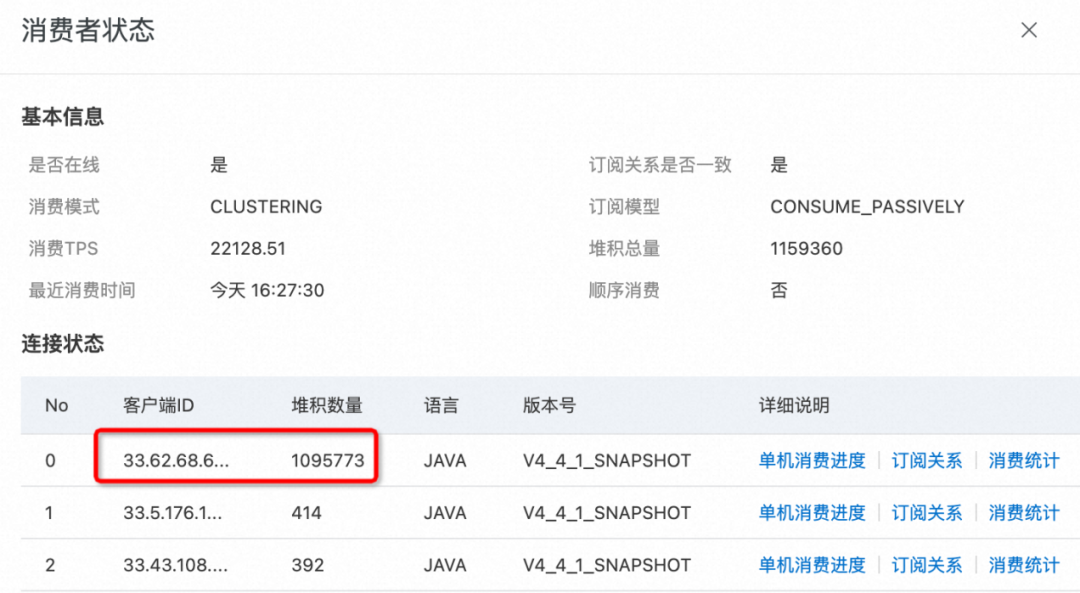
Una mañana, recibí una notificación de alarma, indicando que la entrada MQ del sistema Proxy se había acumulado. Abra la consola y descubra que entre las 500 máquinas Proxy, 1 máquina tiene una acumulación grave, mientras que el resto de las máquinas funcionan normalmente:
2.2 Causa raíz de una oración
Vayamos directamente al grano y hablemos directamente sobre la causa raíz del problema (consulte el siguiente contenido para obtener información detallada sobre el proceso de solución de problemas):
- Acumulación máquina individual: la máquina tiene un hilo de consumo que está atascado, aunque el resto de hilos consumen normalmente, pero el mecanismo MQ decide que la posición de consumo no avanza;
- La descarga de HTTP está atascada: la versión de HttpClient utilizada tiene un error y el tiempo de espera no surte efecto en determinadas circunstancias, lo que puede hacer que el hilo se atasque todo el tiempo;
2.3 Proceso de solución de problemas
1. ¿La velocidad de consumo de la máquina es demasiado lenta?
La primera reacción es que el consumo de esta máquina es demasiado lento. La misma cantidad de información puede ser digerida rápidamente por otras máquinas, pero continúa acumulándose debido al lento consumo. Sin embargo, después de una comparación detallada en la consola MQ, se encuentra que el tiempo de procesamiento comercial y el TPS de consumo de esta máquina son similares a los de otras máquinas, y las especificaciones de las diferentes máquinas también son las mismas:
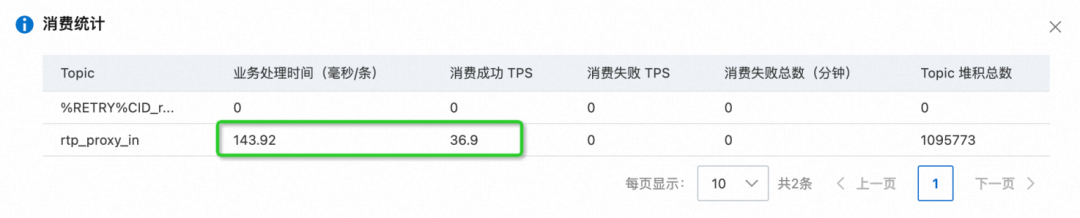
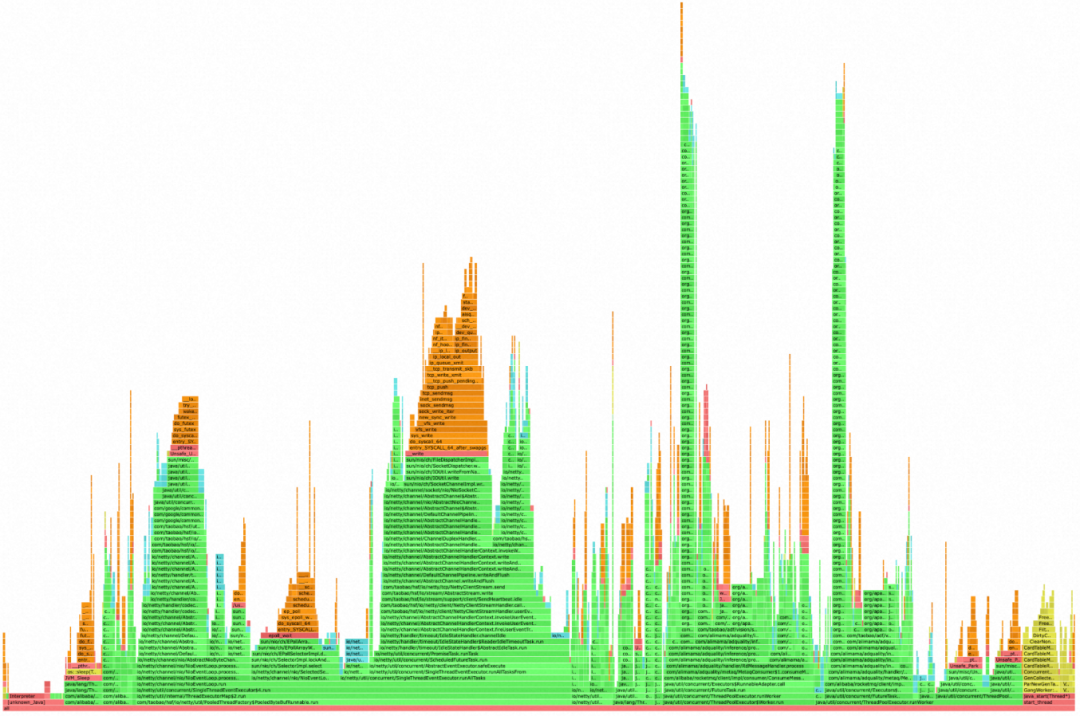
En segundo lugar, observe el diagrama de llamas dibujado por Arthas. Las dos llamas delgadas a la derecha son la lógica comercial de nuestro sistema (cuanto más alta es la llama porque la pila de llamadas RPC es más profunda). En la figura se puede ver que no hay un "efecto de superficie plana" obvio en el gráfico de llama, y el ancho de la llama es relativamente estrecho, lo que también muestra que la máquina no tiene puntos de atascamiento obvios que consumen mucho tiempo al ejecutar lógica de negocios Demuestre que la máquina no se acumula debido a un procesamiento comercial lento:
2. ¿Son normales los indicadores del sistema?
Inicie sesión en la máquina y descubra que la CPU, la MEM y la CARGA son normales y similares a la máquina normal, y no se encuentran pistas obvias:
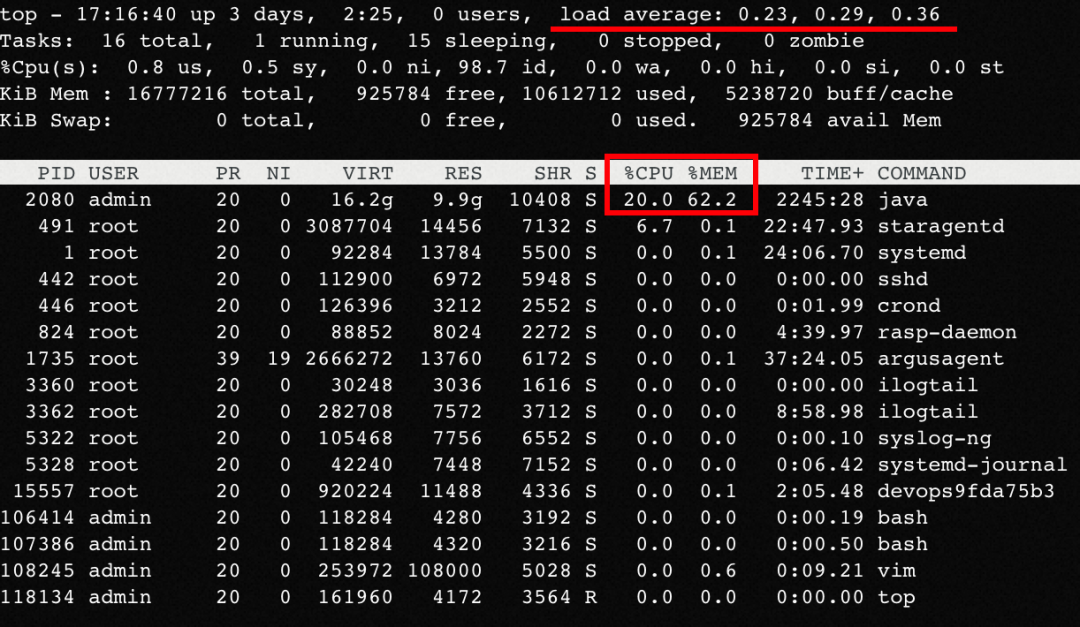
Y la máquina no tiene un GC completo obvio:

3. ¿Causado por limitación de corriente?
Sugerencia: el proxy tiene un mecanismo de limitación de flujo cuando envía solicitudes de proxy, y el tráfico que excede el límite activará la espera de bloqueo, protegiendo así los servicios de sincronización posteriores.
Por lo tanto, si el tráfico del sistema es muy grande hoy y excede el límite que el servicio descendente puede soportar, el exceso de solicitudes activará el límite de flujo de RateLimiter y se bloqueará. Como resultado, se bloquea una gran cantidad de subprocesos de consumidores de MQ, por lo que la velocidad general de consumo de mensajes del sistema Proxy se ralentizará y el resultado final es la acumulación de temas de entrada.
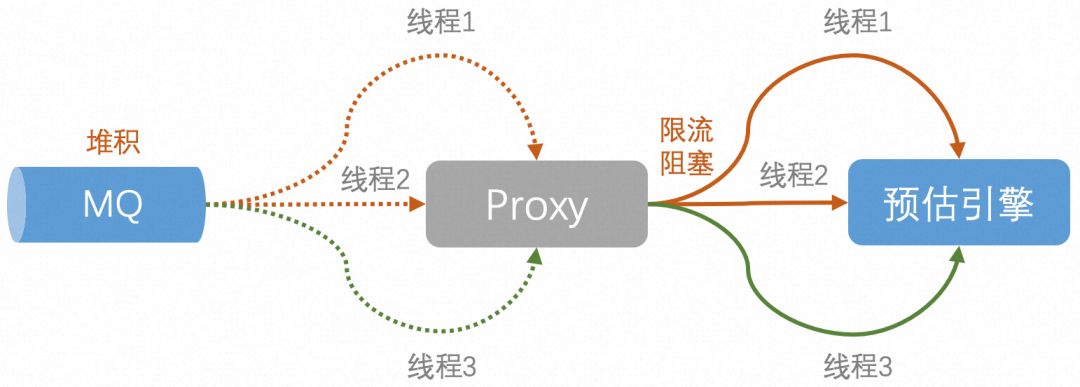
Sin embargo, ya sea que mire los registros o el monitoreo de la máquina, el fenómeno del bloqueo debido a la limitación de corriente no es grave y es relativamente suave:
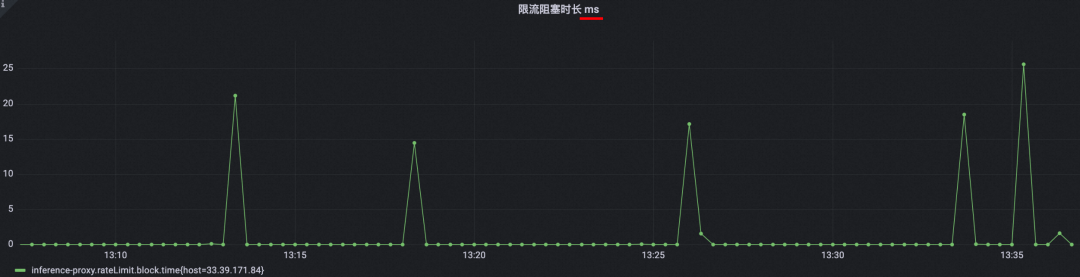
En segundo lugar, si realmente se debe al gran tráfico de entrada del sistema actual, todas las máquinas proxy (consumidores MQ) deberían tener un nivel de acumulación similar. No debe estar todo apilado en la misma máquina, mientras que las otras 499 máquinas son normales. Por lo tanto, verifique la posibilidad de que el flujo de entrada del sistema sea demasiado grande.
4. ¿Sesgo de datos de MQ?
Se espera que 500 máquinas Proxy distribuyan por igual los mensajes en el MQ de ingreso. ¿Es posible que haya un sesgo en la distribución de datos, lo que resulta en demasiados mensajes para esta máquina y pocos mensajes para otras máquinas?
Verifique el código del sistema upstream de Proxy. El sistema no realiza una reproducción aleatoria personalizada cuando envía mensajes a Proxy, por lo que utilizará la estrategia selectOneMessageQueue predeterminada de MQ. Y esta estrategia enviará el mensaje actual a la cola seleccionada según el índice % queue_size. Mirando más a fondo la lógica del índice, se encuentra que comienza con un número aleatorio cuando se inicializa, y aumentará en +1 cada vez que se acceda:
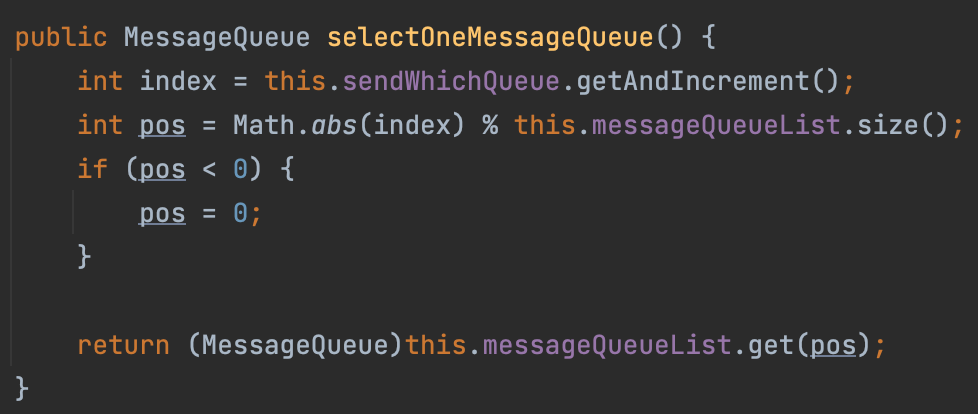
Combinando los dos puntos anteriores, el efecto logrado es: distribuir mensajes uniformemente a cada cola de izquierda a derecha, y realizar circulación automática a través de %:
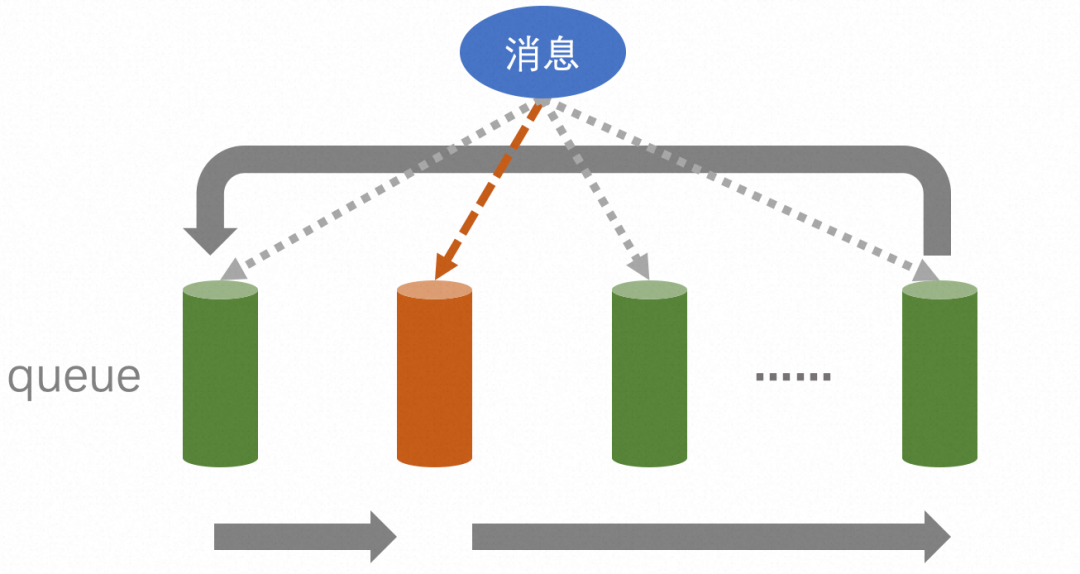
En resumen, la estrategia aleatoria predeterminada de MQ es: dividir los mensajes en cada cola por igual. Por lo tanto, podemos descartar la posibilidad de que nuestra máquina Proxy se acumule debido a datos de mensajes sesgados enviados por MQ.
5, robo de CPU?
Sugerencia: el robo de CPU indica el porcentaje de tiempo de CPU que el proceso que se ejecuta en la máquina virtual está ocupado por otros procesos/máquinas virtuales en la máquina host. Un valor alto de robo de CPU generalmente significa que el rendimiento del proceso en la máquina virtual está degradado.
Por ejemplo, la especificación de la máquina en sí dice 4C, pero en realidad solo se pueden usar 2C después de ser robados. Entonces, el resultado reflejado es que el RT de una sola solicitud no cambia significativamente (la diferencia entre diferentes C no es grande), pero la cantidad de C disminuye, por lo que el rendimiento general de esta máquina se vuelve más pequeño y la capacidad de consumo se vuelve más débil, resultando en acumulación.
Sin embargo, la investigación encontró que st es normal, y se descarta esta posibilidad:

6. Encuentra pistas: ¡la ubicación de consumo de MQ no ha cambiado!
Revisé y no encontré ningún punto anormal. Dado que el fenómeno del problema es la acumulación de MQ, pensé que podría verificar el registro de middleware para encontrar pistas. Efectivamente, a través de una búsqueda direccional del queueId de la máquina atascada, se encontró que el punto de consumo de esta cola no ha avanzado durante mucho tiempo y se ha quedado atascado en una determinada posición:
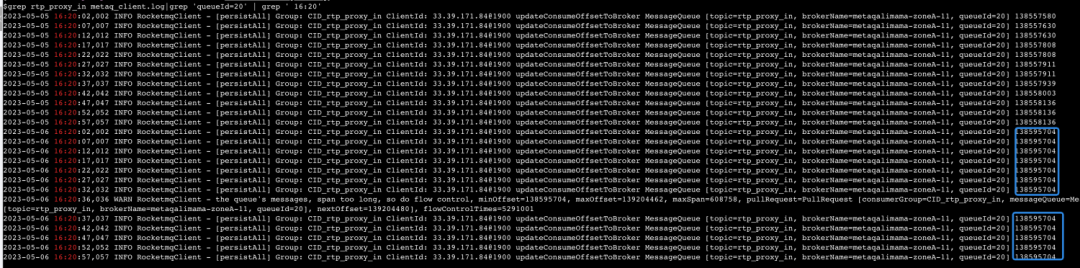
Sugerencia: El mecanismo de extracción de mensajes de MQ es que los mensajes extraídos primero se almacenarán en la caché con una capacidad de 1000 en la memoria, y luego los mensajes en la memoria serán consumidos por el subproceso del consumidor. Cuando la memoria caché esté llena, ya no se extraerá de la cola.
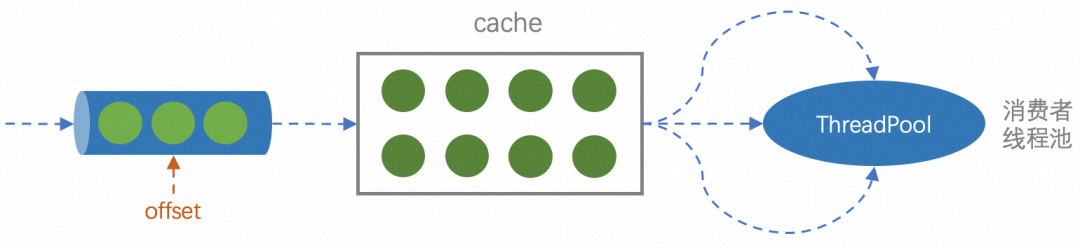
A partir de esto, sospecho: ¿es porque el consumo de Proxy se detiene o el consumo es extremadamente lento, por lo que el caché local siempre está lleno, por lo que MQ dejará de extraer mensajes de la cola, por lo que el desplazamiento no ha cambiado?
Pero como se mencionó anteriormente, independientemente de la consola MQ, los indicadores de monitoreo del sistema y los registros de la máquina, la máquina es normal y no se diferencia de otras máquinas. Entonces, ¿por qué el punto de consumo de la máquina no se mueve, lo que hace que la acumulación sea cada vez más grave?
7. Encuentra la causa raíz: un hilo de consumidor está atascado
Sugerencia: para los mensajes en la memoria caché local, MQ abrirá varios subprocesos (el número de subprocesos lo especifica el usuario) para extraer y cancelar el consumo. Y para garantizar que el mensaje no se pierda, el desplazamiento registra solo el mensaje principal.
Primero, el mecanismo es sólido. Porque bajo la semántica Al menos una vez, los mensajes se pueden consumir varias veces, pero no se pueden perder. Suponga que ahora hay dos subprocesos que extraen dos mensajes al mismo tiempo, y el último mensaje se ejecuta primero. Dado que la ejecución del mensaje anterior puede ser anormal, el desplazamiento de este último no puede utilizarse directamente para actualizar el desplazamiento, de lo contrario no se recuperará el mensaje de fallo de consumo. Por lo tanto, el significado de la compensación del punto de consumo es: todos los mensajes en y antes de esta posición se han consumido correctamente (algo similar al mecanismo de marca de agua de Flink).
De acuerdo con el mecanismo anterior, volviendo a esta pregunta, si alguno de los muchos subprocesos de consumo de MQ de esta máquina Proxy está atascado, la posición de consumo de toda la cola siempre permanecerá en el desplazamiento correspondiente al mensaje atascado. En este momento, aunque otros subprocesos siguen consumiendo normalmente, no pueden hacer avanzar el desplazamiento. Por otro lado, debido a que el flujo ascendente sigue enviando mensajes a la cola de forma continua, los mensajes solo se pueden enviar y enviar, y la cantidad acumulada = la compensación del último mensaje entrante: la compensación del sitio de consumo solo aumenta, lo que se refleja en la acumulación en la consola ¡más grave!
Con base en este análisis, verifique el estado de todos los subprocesos de consumo de MQ a través de jstack y, de hecho, descubra que el subproceso n. ° 251 siempre está en estado ejecutable.
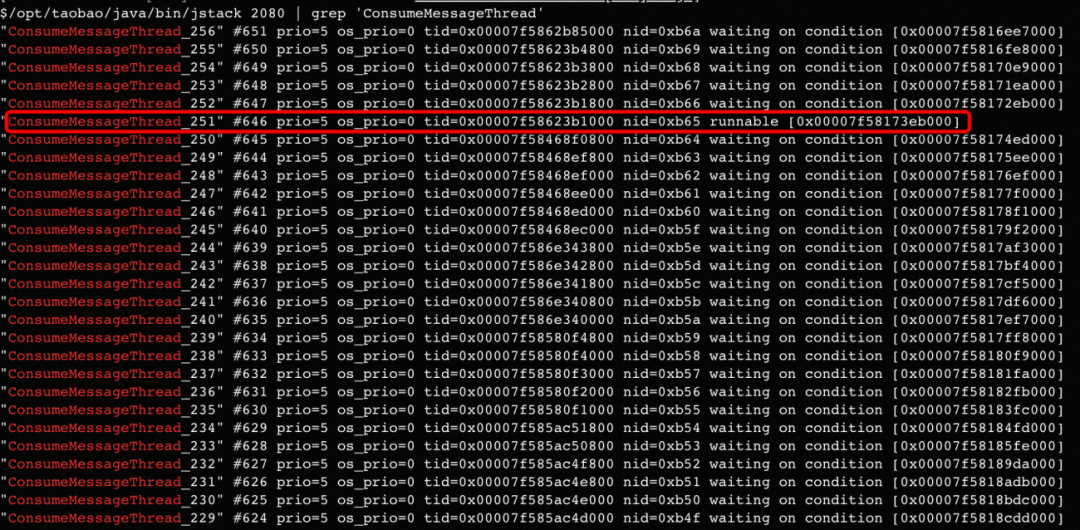
Hay razones para sospechar que es el hilo del consumidor atascado. Debido a que en el escenario comercial del sistema Proxy, la mayor parte del tiempo se dedica a RPC llamando sincrónicamente al modelo de aprendizaje profundo (unos cientos de milisegundos rápido y unos segundos lento), por lo que el subproceso debería estar esperando que regrese la llamada sincrónica. la mayor parte del tiempo ¡El estado de espera! Pero el subproceso 251 aquí siempre se puede ejecutar, por lo que debe haber un problema.
Imprima más los detalles para encontrar la ubicación del código específico donde está atascado el hilo:
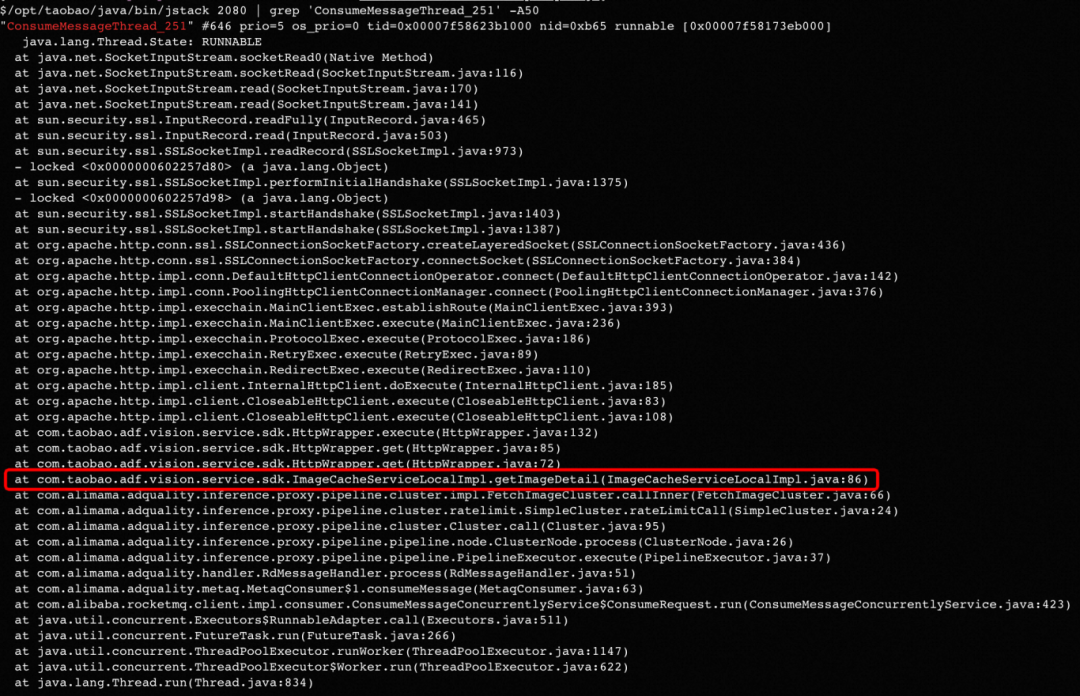
Aquí, el método getImageDetail descarga internamente imágenes a través de HTTP para que el modelo de aprendizaje profundo pueda hacer predicciones. En segundo lugar, al buscar en el registro comercial también se encontró que no se puede encontrar el registro de este hilo. Dado que se atascó a las 10 en punto de anoche, este subproceso no generará ningún registro nuevo. A medida que los registros de la máquina se renueven y limpien, todos los registros ahora contendrán el contenido de este subproceso:

Hasta ahora, se ha encontrado la causa raíz del grave problema de la acumulación de MQ en máquinas individuales en el sistema Proxy: un subproceso de consumo de esta máquina se ha atascado al descargar imágenes a través de HTTP, lo que impide que avance el consumo de toda la cola. , lo que resulta en una acumulación continua.
8. ¿Por qué HTTP sigue atascado?
Hasta ahora, aunque se ha encontrado la causa raíz de la acumulación, y después de intentarlo, se puede solucionar temporalmente reiniciando la aplicación o desconectándose a corto plazo. Pero siempre hay peligros ocultos a largo plazo, porque el mismo problema ha aparecido de vez en cuando cada pocos días recientemente. Es necesario investigar a fondo la causa raíz del bloqueo de HTTP para resolver este problema de manera fundamental.
Después de varias sentadillas, obtuve algunas URL de imágenes que harían que el hilo se atascara. Se encontró que ninguno de ellos eran direcciones de imágenes internas, y las direcciones no se podían abrir, ni terminaban en formato jpg:
https://ju1.vmhealthy.cn
https://978.vmhealthy.cn
https://xiong.bhjgkjhhb.shop
Pero el problema es que, incluso si ingresa una URL tan extrema que no se puede abrir, dado que hemos establecido un tiempo de espera de 5 segundos para HttpClient, se bloqueará como máximo durante 5. ¿Por qué parece que el mecanismo de tiempo de espera no ha tenido efecto y ha estado atascado durante más de diez horas?
Sugerencia: HTTP deberá establecer una conexión antes de la transmisión de datos. Esto corresponde a dos tiempos de espera: 1. Tiempo de espera de conexión, para la etapa de establecimiento de una conexión 2. Tiempo de espera de socket, para el tiempo de espera durante la transmisión de datos.

Después de la inspección, solo el tiempo de espera del socket está configurado en el código actual y el tiempo de espera de la conexión no está configurado, por lo que sospecho que las solicitudes anteriores están directamente atascadas en la etapa de conexión anterior, y debido a que el tiempo de espera de conexión no está configurado, la solicitud tiene estado atascado? Sin embargo, después de modificar el código e intentar solicitar estas direcciones nuevamente, aún está atascado y necesita más investigación.
9. Encuentra la causa raíz del bloqueo de HTTP
Consejo: encuentre la causa raíz. En una versión específica de HttpClient, hay un error en la solicitud basada en la conexión SSL: de hecho, primero intentará establecer la conexión y luego establecerá el período de tiempo de espera, y el orden se invierte. Por lo tanto, si la conexión se atasca, el tiempo de espera no se ha establecido y esta solicitud HTTP siempre se atascará...

Mirando hacia atrás en las URL atascadas anteriores, ¡todas comienzan con https sin excepción! El caso fue resuelto, resultó que el HttpClient utilizado por el proyecto tenía un error. Después de actualizar la versión de HttpClient, se volvió a emitir la solicitud de prueba de construcción emitida previamente, el hilo ya no estaba atascado y todos se enviaron al entorno en línea. El problema de una pequeña cantidad de acumulaciones de máquinas que ocurrieron con frecuencia recientemente ha nunca más volvió a ocurrir.
Hasta ahora, después de pasar por muchos giros y vueltas, el problema finalmente se ha resuelto por completo.
2.4 Revisión general
Desde la aparición de la acumulación de máquinas individuales en el Proxy más externo, pasé por muchos nodos clave en la investigación interna hasta que encontré la causa raíz. En la actualidad, todos los problemas han sido investigados a fondo, y ahora desde la perspectiva de Dios, la cadena causal completa desde el interior hacia el exterior es la siguiente:
-> El sistema Proxy descargará imágenes basadas en HttpClient y luego llamará al modelo de clase de imagen para la estimación
–> La versión de HttpClient utilizada tiene un error, y al acceder a la dirección https, el tiempo de espera no tendrá efecto
-> El sistema Proxy encontró una pequeña cantidad de direcciones https y se atascó (evento de baja probabilidad), por lo que siempre se atascará porque el tiempo de espera no tiene efecto
–> Basado en el mecanismo At Least Once de MQ, el punto de consumo siempre permanecerá en el desplazamiento correspondiente al mensaje atascado (aunque el resto de los subprocesos consumen normalmente)
-> El sistema ascendente aún envía mensajes al Proxy continuamente, por lo que los mensajes solo pueden entrar y salir, y la acumulación está empeorando
–> Cuando la acumulación supera un cierto umbral, se activa una alarma de monitoreo y el usuario se da cuenta
3. Resumen
El proceso de solución de problemas de este problema es un poco tortuoso, pero también podemos aprender muchas metodologías y lecciones comunes, que se resumen en esta sección:
- **Haga un buen uso de las herramientas de solución de problemas: **Aprenda a usar jstack, Arthas, jprofile y otras herramientas afiladas, y haga un buen uso de las herramientas apropiadas en diferentes escenarios, que pueden encontrar de manera eficiente puntos anormales, encontrar pistas y encontrar gradualmente la raíz causa del problema;
- **Sensibilidad anormal:**A veces, algunas pistas para descubrir el problema se nos muestran antes, pero debido a varias razones (como muchas dudas sobre el problema al principio, muchos factores de interferencia que no han sido descartado, etc.) Para descubrir pistas, se necesita más experiencia;
- ** Búsqueda extensiva de información: ** Además de buscar documentos en la intranet y buscar personal relevante para consulta, también debe aprender a consultar información de primera mano en sitios web externos en inglés;
- **Perseverancia cuando es difícil:** Para algunos problemas ocultos, muchas veces el problema no se puede encontrar y resolver inmediatamente después de que aparece una vez. Puede tomar varias rondas de investigaciones antes y después de encontrar la causa raíz;
- ** Conocimientos subyacentes complementarios: ** Si puede conocer el mecanismo de compensación de MQ desde el principio, algunos problemas no tomarán tantos desvíos. En el proceso de usar varios middleware en el futuro, es necesario aprender más sobre sus principios subyacentes;
- **Sin preguntas metafísicas:** Los códigos y las máquinas no engañarán a las personas Detrás de todas las preguntas "metafísicas" hay un conjunto de causas rigurosas y razonables;
referencia:
- Error de HttpClient: https://issues.apache.org/jira/browse/HTTPCLIENT-1478
- Tiempo de espera de conexión frente a tiempo de espera de socket: https://stackoverflow.com/questions/7360520/connectiontimeout-versus-sockettimeout