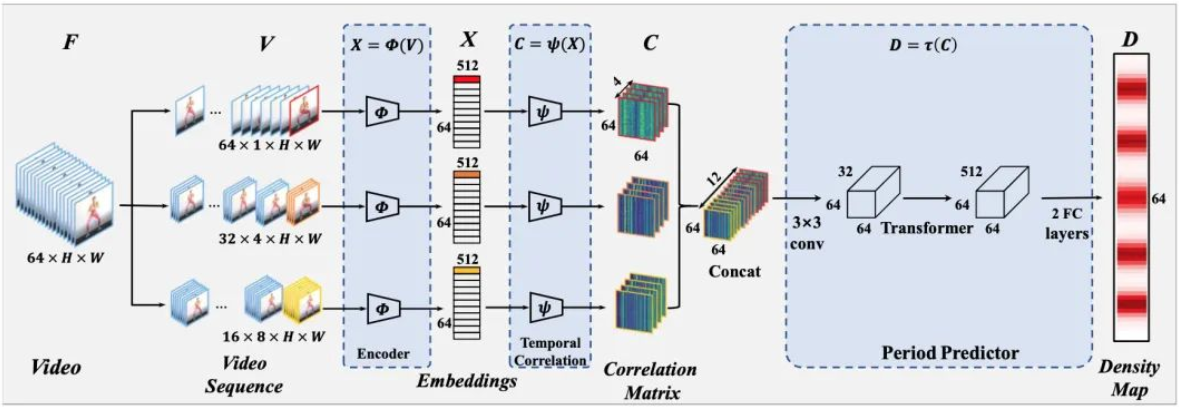
TransRAC: Codificación de correlación temporal multiescala con transformadores para el conteo de acciones repetitivas, CVPR 2022 Oral
论文: https://arxiv.org/abs/2204.01018 [2204.01018] TransRAC: codificación de correlación temporal multiescala con transformadores para el conteo de acciones repetitivas (arxiv.org)
Código: https://github.com/SvipRepetitionCounting/TransRAC GitHub - SvipRepetitionCounting/TransRAC: (CVPR 2022 Oral) Implementación oficial: TransRAC Conjunto de datos: https://svip-lab.github.io/dataset/RepCount_dataset.html
Laboratorio de visión y percepción inteligente de Shanghaitech (SVIP) (svip-lab.github.io)
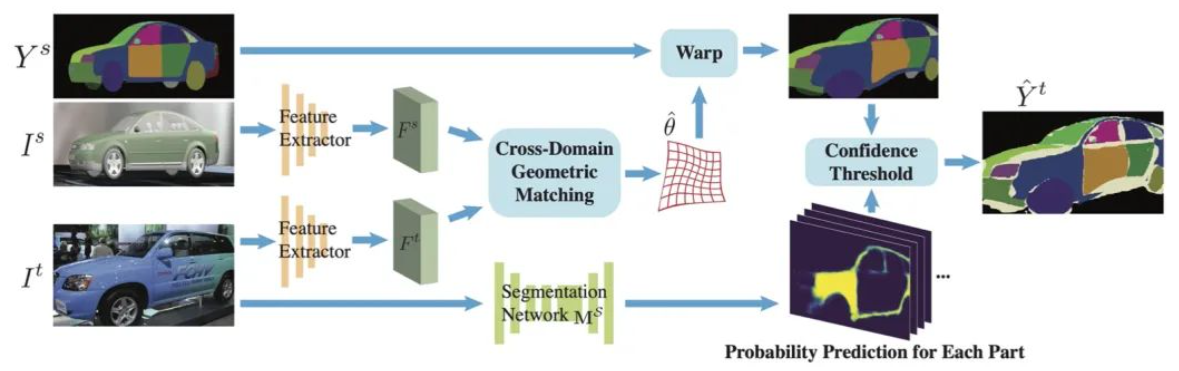
Segmentación de piezas de aprendizaje a través de la adaptación de dominio no supervisada de vehículos sintéticos, CVPR 2022 Oral
Papel: https://arxiv.org/abs/2103.14098
Código: GitHub - qliu24/render-3d-segmentation
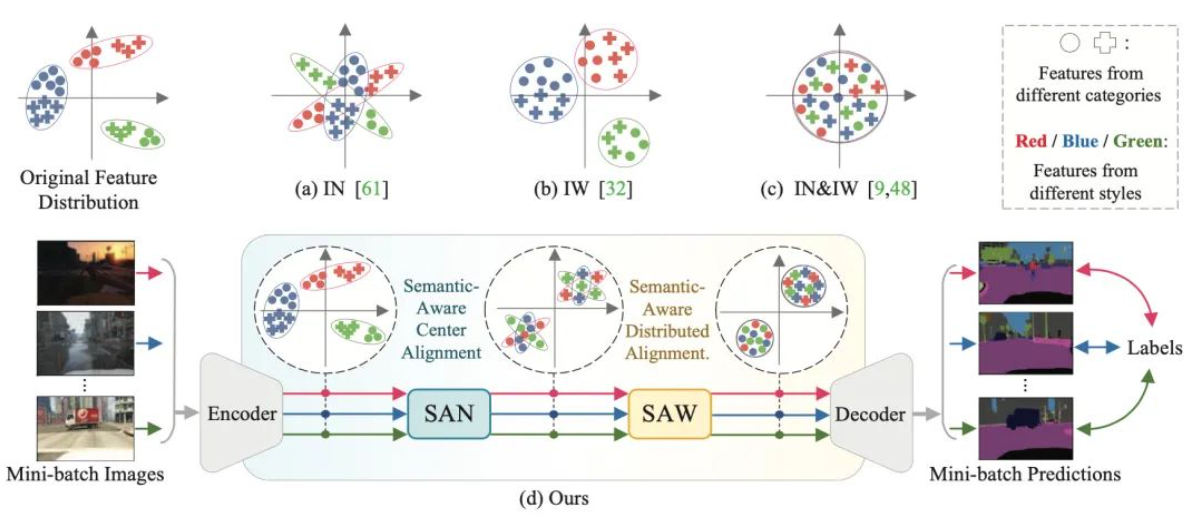
Segmentación generalizada de dominio consciente de la semántica, CVPR 2022 Oral
Documento: [2204.00822] Segmentación generalizada de dominio con conciencia semántica (arxiv.org)
Código:
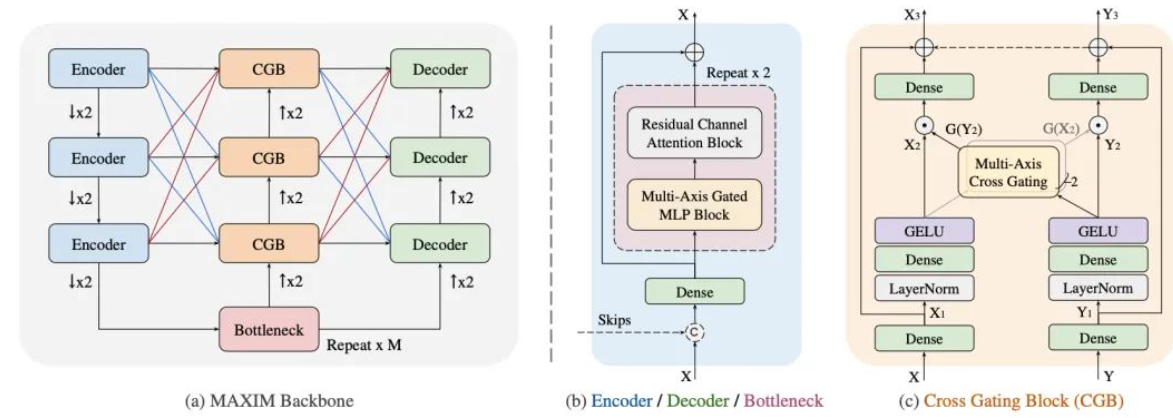
MAXIM: MLP multieje para procesamiento de imágenes, CVPR 2022 Oral
Documento: [2201.02973] MAXIM: Multi-Axis MLP for Image Processing (arxiv.org)
Código: https://github.com/google-research/maxim
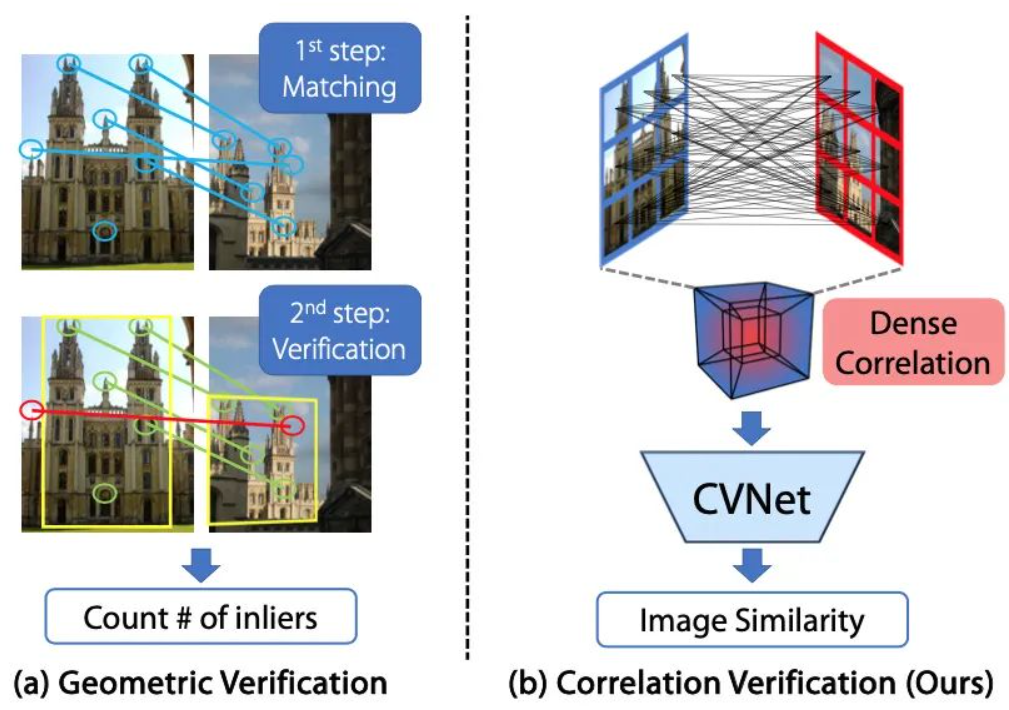
Verificación de correlación para recuperación de imágenes, CVPR 2022 Oral
论文:[2204.01458] Verificación de correlación para recuperación de imágenes (arxiv.org)
代码:GitHub - sungonce/CVNet: Implementación oficial de PyTorch de verificación de correlación para recuperación de imágenes, CVPR 2022 (presentación oral)
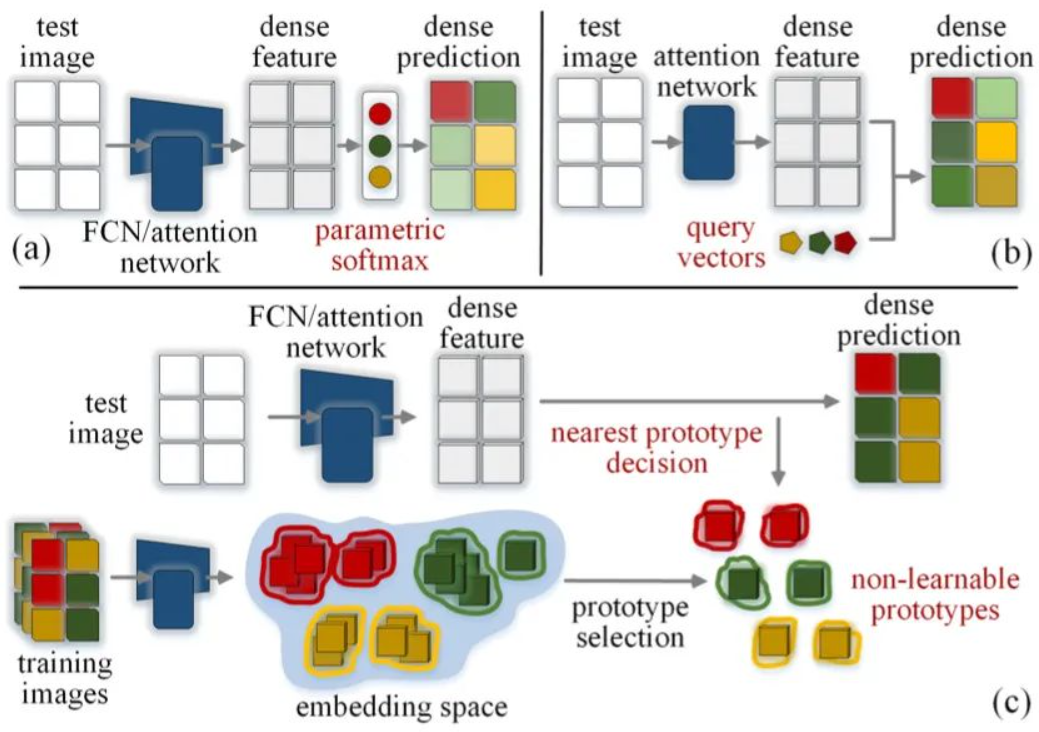
Repensar la segmentación semántica: una vista de prototipo, CVPR 2022 Oral
论文:[2203.15102] Repensar la segmentación semántica: una vista de prototipo (arxiv.org)
代码:GitHub - tfzhou/ProtoSeg: CVPR2022 (Oral) - Repensar la segmentación semántica: una vista de prototipo
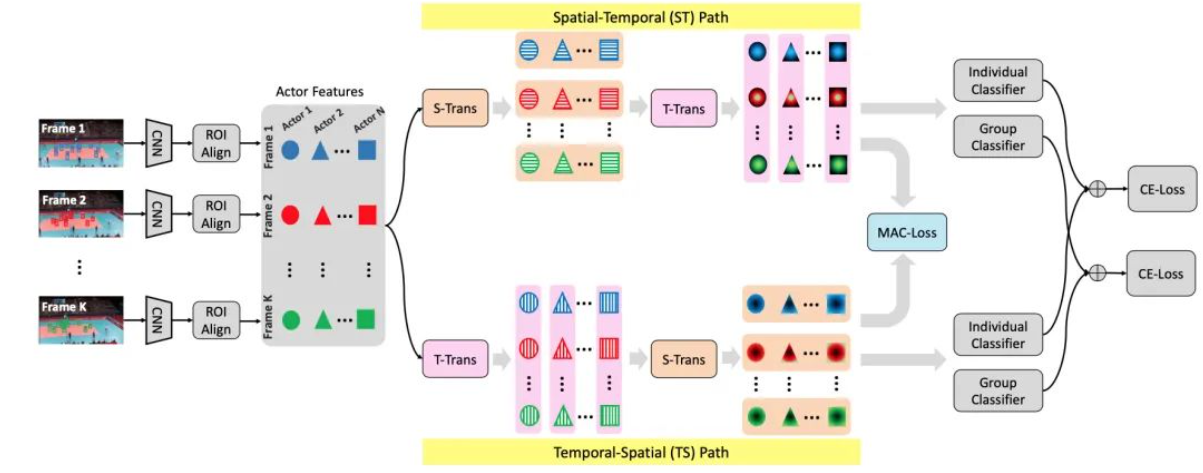
Dual-AI: Aprendizaje de interacción de acción de doble ruta para el reconocimiento de actividades grupales, CVPR 2022 Oral
论文:[2204.02148] IA dual: Aprendizaje de interacción de actores de doble ruta para el reconocimiento de actividades grupales (arxiv.org)
代码:IA dual: Aprendizaje de interacción de actores de doble ruta para el reconocimiento de actividades grupales (mingfei.info)
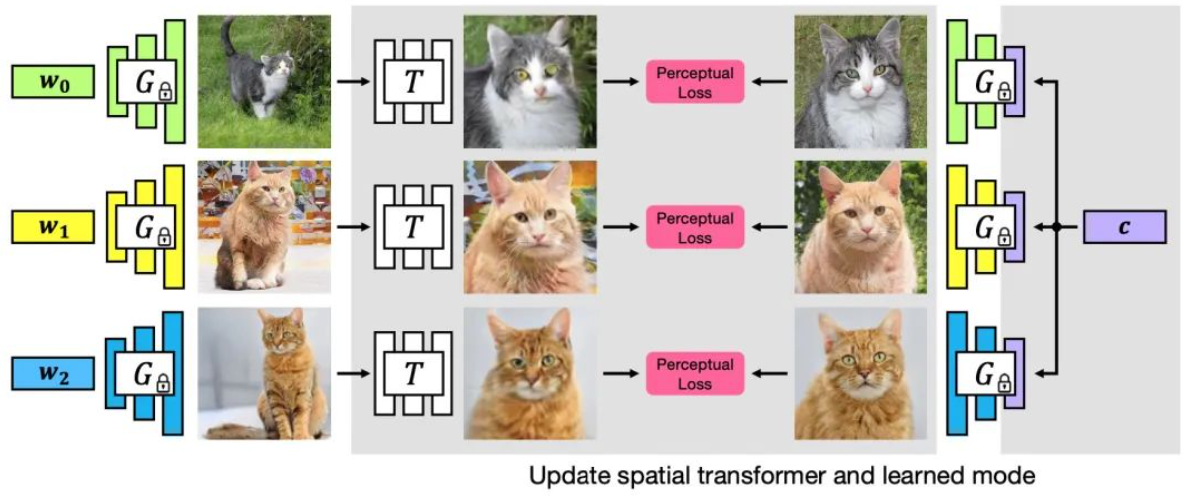
Alineación visual densa supervisada por GAN, CVPR 2022 Oral
Documento: [2112.05143] Alineación visual densa supervisada por GAN (arxiv.org)
Código: https://github.com/wpeebles/gangealing
Proyecto: Alineación visual densa supervisada por GAN (wpeebles.com)
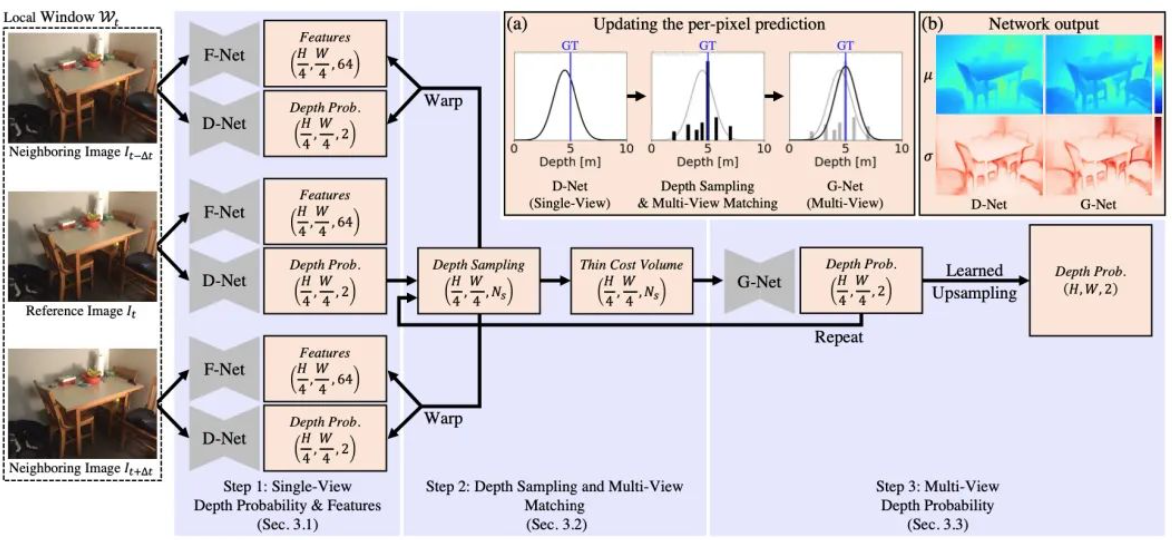
Estimación de profundidad de vista múltiple mediante la fusión de probabilidad de profundidad de vista única con geometría de vista múltiple, CVPR 2022 Oral
论文:[2112.08177] Estimación de profundidad de múltiples vistas fusionando la probabilidad de profundidad de una sola vista con geometría de múltiples vistas (arxiv.org)
代码:GitHub - baegwangbin/MaGNet: (CVPR 2022 - oral) Estimación de profundidad de múltiples vistas fusionando una Ver probabilidad de profundidad con geometría multivista
SeqFormer: Transformador secuencial para segmentación de instancias de video, ECCV 2022 Oral
SeqFormer: https://arxiv.org/abs/2112.08275
ÍDOLO: https://arxiv.org/abs/2207.10661
Dirección del código oficial: https://github.com/wjf5203/VNex
En Defensa de los Modelos Online para la Segmentación de Instancias de Video, ECCV 2022 Oral
En defensa de los modelos en línea para la segmentación de instancias de video - 知乎 (zhihu.com)
https://arxiv.org/abs/2207.10661
Segmentación semántica no supervisada a gran escala,TPAMI2022
Descarga del conjunto de datos: github.com/LUSSeg/ImageNet-S
Código de método convencional: github.com/LUSSeg/ImageNetSegModel
El método propuesto en el documento: github.com/LUSSeg/PASS
Dirección en papel: arxiv.org/pdf/2106.03149.pdf
TPAMI2022: Segmentación semántica no supervisada (LUSS) a gran escala y su conjunto de datos Image-S
Descubrimiento de máscaras de objetos con transformadores para segmentación semántica no supervisada
Dirección en papel: https://arxiv.org/pdf/2206.06363.pdf
Código fuente abierto: https://github.com/wvangansbeke/MaskDistill
StructToken: repensando la segmentación semántica con Structural Prior
https://arxiv.org/pdf/2203.12612.pdf
TokenMix: repensar la mezcla de imágenes para el aumento de datos en los transformadores de visión, ECCV 2022
Dirección en papel: https://arxiv.org/abs/2207.08409 [1]
Dirección del código: https://github.com/Sense-X/TokenMix [2]
Autoatención desviada a través de la agregación de tokens de múltiples escalas
Dirección en papel: https://arxiv.org/pdf/2111.15193.pdf
Dirección del código: https://github.com/OliverRensu/Shunted-Transformer
CVPR2022 Oral - Transformador derivado: Nueva red troncal de transformador visual multiescala
Pérdida de energía del árbol: hacia una segmentación semántica escasamente anotada
Dirección en papel: https://arxiv.org/pdf/2203.10739.pdf
Dirección del código: https://github.com/megvii-research/TreeEnergyLoss
Segmentación semántica débilmente supervisada por contraste de píxel a prototipo
Dirección en papel: https://arxiv.org/pdf/2110.07110.pdf
Dirección de código: no de código abierto
Mapas de reactivación de clase para segmentación semántica débilmente supervisada, CVPR2022
Dirección en papel: https://arxiv.org/pdf/2203.00962.pdf
Dirección del código: https://github.com/zhaozhengChen/ReCAM
Aprendizaje colaborativo de conjuntos de datos cruzados para la segmentación semántica, AAAI 2022
Dirección en papel: https://arxiv.org/pdf/2103.11351.pdf
Dirección del código: https://github.com/wanglixilinx/CDCL
Aprendizaje colaborativo de conjuntos de datos cruzados para la segmentación semántica - 知乎
Pyraformer: atención piramidal de baja complejidad para modelado y pronóstico de series temporales de largo alcance, ICLR 2022 oral
Dirección en papel: https://openreview.net/pdf?id=0EXmFzUn5I
Dirección de github: https://github.com/alipay/Pyraf
Descubriendo y explicando el cuello de botella de representación de las DNN , ICLR 2022 oral
Reconocimiento de conjunto abierto: ¿todo lo que necesita es un buen clasificador de conjunto cerrado? ,ICLR 2022 oral
-
Enlace en papel: https://arxiv.org/abs/2110.06207
-
Enlace del proyecto: https://github.com/sgvaze/osr_closed_set_all_you_need
PICO: DESAMBIGUACIÓN DE ETIQUETAS CONTRASTIVAS PARA EL APRENDIZAJE PARCIAL DE ETIQUETAS, mejor artículo de ICLR 2022
Enlace de descarga: https://openreview.net/pdf?id=EhYjZy6e1gJ
Este artículo|Industry_ICLR 2022 Mejor interpretación de artículo
Aprendizaje no transferible: un nuevo enfoque para la verificación de la propiedad del modelo y la autorización de aplicabilidad, ICLR 2022 oral
ICLR 2022 Oral: Aprendizaje no transferible (aprendizaje antitransferencia) bzdww
ICLR2022 sitio oral: zhuanlan.zhihu.com
blog de referencia
ICLR2022--Presentaciones orales.pdf - Documentación de la Rueda Motian