Fuente: 2023CVPR
Enlace original: https://arxiv.org/abs/2206.02066
源码:GitHub - XuJiacong/PIDNet: Este es el repositorio oficial de nuestro trabajo reciente: PIDNet
0. Resumen
La estructura de red de doble rama ha demostrado su eficacia y efectividad en tareas de segmentación semántica en tiempo real . Sin embargo, la desventaja de fusionar directamente detalles de alta resolución y contexto de baja frecuencia es que las características detalladas se ven superadas fácilmente por la información contextual circundante. Este fenómeno de exceso limita la mejora de la precisión de segmentación de los modelos de doble rama existentes. En este artículo, vinculamos las redes neuronales convolucionales (CNN) y los controladores proporcional-integral-derivativo (PID) , revelando que las redes de doble rama son equivalentes a los controladores proporcional-integral (PI), que tienen un problema de supersintonía similar. Para abordar este problema, proponemos una nueva estructura de red de tres ramas: PIDNet, que consta de tres ramas para resolver la rama de detalle, la rama de contexto y la información de límites, respectivamente, y utiliza la atención de límites para guiar la fusión de la rama de detalles y la rama de contexto. Nuestra familia de PIDNets logra un compromiso óptimo entre la velocidad de inferencia y la precisión, y su precisión supera a todos los modelos existentes con una velocidad de inferencia similar en conjuntos de datos de paisajes urbanos y CamVid . Entre ellos, la velocidad de inferencia de PIDNet-S en el paisaje urbano es del 78,6 % y la velocidad de inferencia es de 93,2 FPS; la velocidad de inferencia de CamVid es del 80,1 % y la velocidad de inferencia es de 153,7 FPS.
1. Introducción
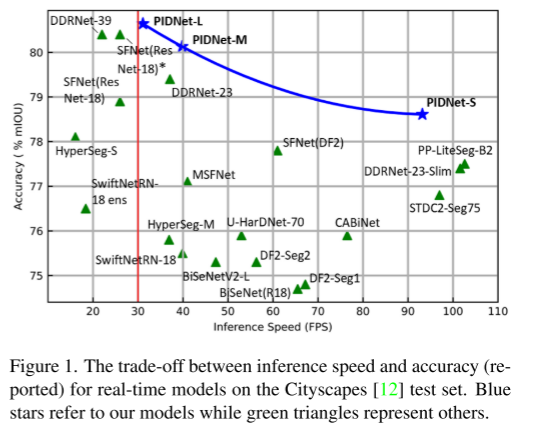
El controlador proporcional-integral-derivativo (PID) es un concepto clásico que se ha utilizado ampliamente en los sistemas y procesos dinámicos modernos, como la manipulación robótica [3], los procesos químicos [24] y los sistemas de potencia [25]. Aunque en los últimos años se han desarrollado muchas estrategias de control avanzadas con un mejor rendimiento de control, los controladores PID siguen siendo la primera opción para la mayoría de las aplicaciones industriales debido a su simplicidad y robustez. Además, la idea de controlador PID se ha extendido a muchos otros campos. Por ejemplo, los investigadores han introducido el concepto PID en la eliminación de ruido de imágenes [32], el hundimiento de gradiente estocástico [1] y la optimización numérica [50] para mejorar el rendimiento del algoritmo. En este artículo, diseñamos una nueva arquitectura de tarea de segmentación semántica en tiempo real utilizando el concepto básico del controlador PID y demostramos a través de extensos experimentos que nuestro modelo supera todos los trabajos anteriores, logrando velocidad y precisión de inferencia. se muestra en la Figura 1.
La segmentación semántica es una tarea fundamental en el análisis de escenas visuales, donde el objetivo es asignar una etiqueta de clase específica a cada píxel en una imagen de entrada. Con la creciente demanda de inteligencia, la segmentación semántica se ha convertido en un componente de percepción básico para aplicaciones como la conducción autónoma [16], el diagnóstico por imágenes médicas [2] y las imágenes de teledetección [54]. A partir de FCN [31], la convolución profunda ha mejorado mucho los métodos tradicionales y ha dominado gradualmente el campo de la segmentación semántica, proponiendo muchos modelos representativos [4, 6, 40, 48, 59, 60]. Para lograr un mejor rendimiento, presentamos varias estrategias para equipar estos modelos para aprender la correlación contextual entre píxeles a escala sin perder detalles importantes. Si bien la precisión de segmentación de estos modelos es alentadora, el costo computacional prohibitivo dificulta gravemente su aplicación en escenarios en tiempo real, como automóviles autónomos [16] y cirugía robótica [44].
Para satisfacer las necesidades de tiempo real o movilidad, los investigadores han propuesto muchos modelos eficientes de segmentación semántica de palabras. Específicamente, ENet [36] emplea un decodificador liviano para reducir la muestra de los mapas de características en una etapa temprana. ICNet [58] codifica entradas pequeñas en rutas profundas complejas para analizar la semántica de alto nivel. MobileNet [21, 42] reemplaza las convoluciones tradicionales con convoluciones separables en profundidad. Estos primeros trabajos redujeron la latencia y el uso de memoria de los modelos de segmentación, pero la baja precisión limitó severamente sus aplicaciones en el mundo real. Recientemente, se han propuesto en la literatura muchos modelos novedosos y prometedores basados en la arquitectura Two-Branch Network (TBN), logrando un compromiso SOTA entre velocidad y precisión [15, 20, 38, 39, 52].
En este documento, observamos la arquitectura de TBN desde la perspectiva del controlador PID y señalamos que TBN es equivalente al controlador PI, que tiene el problema de sobreimpulso como se muestra en la Fig. 2. Para resolver este problema, diseñamos una nueva estructura de red de tres ramas, PIDNet, y demostramos su superioridad en conjuntos de datos de paisaje urbano [12], CamVid [5] y PASCAL Context [33]. También proporcionamos estudios de ablación y visualizaciones de funciones para comprender mejor la función de cada módulo en PIDNet. Se puede acceder al código fuente a través de https://github.com/XuJiacong/PIDNet
Las principales contribuciones de este trabajo se encuentran en tres aspectos:
- Vinculación de CNN profundas con controladores PID y propuesta de una red de tres ramas basada en la arquitectura del controlador PID
- Proponer módulos eficientes, como el módulo Bag Fusion que equilibra detalles y características contextuales, para mejorar el rendimiento de PIDNets
- PIDNet logra el mejor compromiso entre velocidad de inferencia y precisión entre todos los modelos existentes. Entre ellos, sin herramientas de aceleración, PIDNet-S logró un 78,6 % mIOU en el conjunto de prueba cityapes y la velocidad alcanzó los 93,2 FPS, mientras que PIDNet-L logró la mayor precisión (80,6 % mIOU).
2. Trabajo relacionado
En esta sección, se analizan métodos representativos para lograr requisitos de alta precisión y tiempo real, respectivamente.
2.1 Segmentación semántica de alta precisión
Los primeros enfoques de la segmentación semántica se basaron en arquitecturas de codificador-decodificador [4, 31, 40], en las que el codificador amplía gradualmente su campo receptivo a través de operaciones de agrupación o convolución estriada, y el decodificador utiliza deconvolución o muestreo ascendente de detalles de recuperación semántica avanzada. Sin embargo, los detalles espaciales se pasan por alto fácilmente durante la reducción de muestreo de la red de códecs. Para paliar este problema, se proponen circunvoluciones dilatadas [53] para ampliar el campo de visión sin reducir la resolución espacial. Sobre esta base, la serie DeepLab [7-9] utiliza convoluciones dilatadas con diferentes tasas de expansión en la red, que ha mejorado mucho en comparación con trabajos anteriores. Tenga en cuenta que la convolución dilatada no es adecuada para la implementación de hardware debido a su acceso a la memoria no secuencial. PSPNet [59] presenta un Módulo de agrupación piramidal (PPM) para resolver información contextual de múltiples escalas, mientras que HRNet [48] utiliza conexiones bilaterales y de múltiples rutas para aprender y fusionar representaciones en diferentes escalas. Inspirándose en las capacidades de análisis de dependencia a largo plazo del mecanismo de atención [47] en las máquinas de lenguaje, las operaciones no locales [49] se introducen en la visión artificial, lo que lleva a muchos modelos precisos [17, 23, 55].
2.2 Segmentación semántica en tiempo real
Se han propuesto muchas arquitecturas de red para lograr un equilibrio óptimo entre la velocidad de inferencia y la precisión, que se pueden resumir aproximadamente de la siguiente manera.
Codificadores y decodificadores ligeros
SwiftNet [35] usa una entrada de baja resolución para la semántica de alto nivel y otra entrada de alta resolución para proporcionar suficientes detalles para su decodificador liviano. DFANet [27] introduce una columna vertebral ligera al modificar la estructura de Xception [11], que se basa en convoluciones separables en profundidad y reduce el tamaño de entrada para mejorar la velocidad de inferencia. ShuffleSeg [18] utiliza ShuffleNet [57] que integra la transformación de canales y la convolución de grupos como columna vertebral para reducir la cantidad de cómputo. Sin embargo, la mayoría de estas redes aún emplean una arquitectura de codificador-decodificador, lo que requiere un flujo de información a través de un codificador profundo y luego de regreso a través de un decodificador, lo que introduce demasiada latencia. Además, dado que la optimización de las convoluciones separables en profundidad en GPU es inmadura, las convoluciones convencionales son más rápidas con más FLOP y parámetros [35]. Por ello, buscamos modelos más eficientes que eviten las descomposiciones convolucionales y las arquitecturas codificador-decodificador.
Arquitectura de red de sucursal dual
Un gran campo receptivo puede extraer relevancia contextual, y los detalles espaciales son cruciales para la delimitación de límites y el reconocimiento de objetos a pequeña escala. Para equilibrar estos dos aspectos, los autores de BiSeNet [52] proponen una arquitectura de red de dos ramas (TBN), que consta de dos ramas con diferentes profundidades para la incrustación de contexto y el análisis de detalles, y se utiliza un módulo de fusión de características (FFM). para fusionar contexto e información detallada. Con el fin de mejorar la capacidad de representación de esta arquitectura o reducir la complejidad de su modelo, se han propuesto algunos trabajos de seguimiento basados en esta arquitectura [38, 39, 51]. Específicamente, DDRNet [20] introduce conexiones bilaterales para mejorar el intercambio de información entre ramas contextuales y detalladas, logrando resultados de segmentación semántica en tiempo real de última generación. Sin embargo, al fusionar directamente la semántica detallada original y la información contextual de baja frecuencia, existe el riesgo de que los límites de los objetos se erosionen en exceso debido a los píxeles circundantes y los objetos pequeños se vean abrumados por los objetos grandes adyacentes (como se muestra en las Figuras 2 y 3). 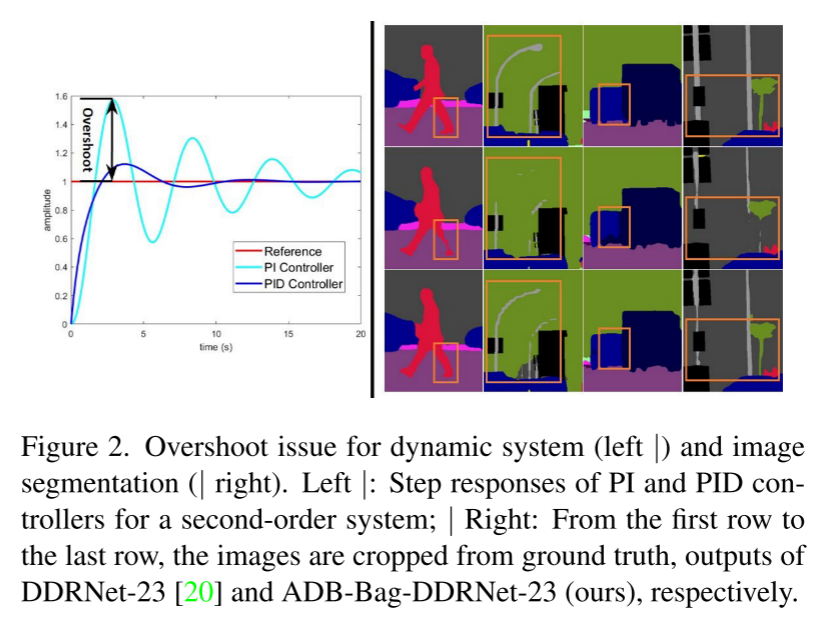
3. Método
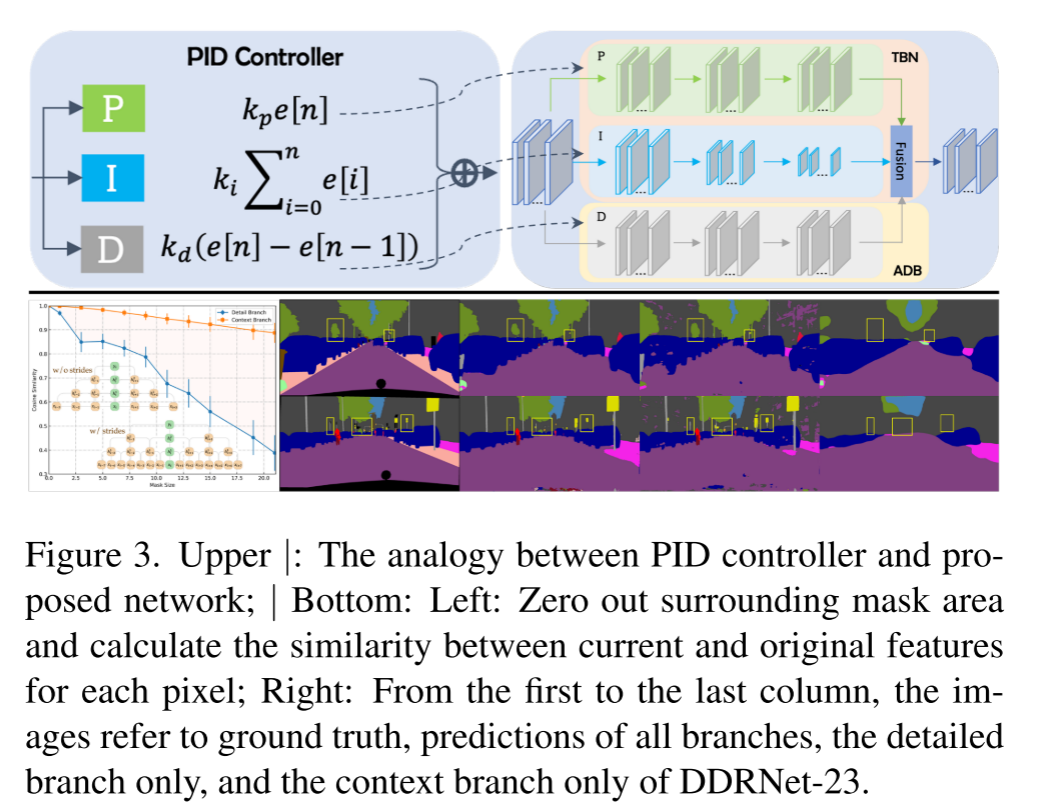
El controlador PID consta de tres partes: controlador proporcional (P), controlador integral (I) y controlador derivado (D), como se muestra en la Fig. 3 superior. La implementación del controlador PI se puede escribir como:

El controlador P se enfoca en la señal actual, mientras que el controlador I acumula todas las señales pasadas. Debido a los efectos de inercia acumulados, la salida de un controlador PI simple se sobrepasa cuando la señal cambia en direcciones opuestas. Luego, introduzca el controlador D, cuando la señal se vuelve más pequeña, el componente D se convierte en un valor negativo, que actúa como un amortiguador para reducir el sobreimpulso. De manera similar, TNS resuelve el contexto y los detalles por separado a través de múltiples capas convolucionales. Considere un ejemplo 1D simple en el que tanto la rama de detalle como la rama de contexto constan de 3 capas sin bn ni ReLU. Entonces, el mapa de salida se puede calcular como:

Entre ellos, kmn es el valor n-ésimo del núcleo de la capa M. Dado que |kmn| se distribuye principalmente en (0,0.01) (DDRNet-23 es 92 %), con 1 como límite, el coeficiente de cada elemento disminuye exponencialmente a medida que aumenta el número de capas. Por lo tanto, para cada vector de entrada, cuanto mayor sea el número de elementos, mayor será la contribución a la salida final. Para la rama de detalle, I[I−1], I[I] y I[I+1] representan más del 70 % del total de entradas, lo que indica que la rama de detalle presta más atención a la información local .
Sin embargo, I[I−1], I[I] e I[I+1] solo representan menos del 26% de las entradas totales de la rama de contexto, por lo que la rama de contexto enfatiza la información circundante .
Como se muestra en la Figura 3-Inferior, la rama de contexto es menos sensible a los cambios de información local que la rama de detalle. La rama de detalle y la rama de contexto del dominio espacial se comportan de manera similar a los controladores P (actual) e I (anterior) del dominio de tiempo.
Reemplace z−1 en la transformada z del controlador PID con e−jω, expresado como:

Cuando la frecuencia de entrada ω aumenta, las ganancias de los controladores I y D se vuelven más pequeñas y más grandes respectivamente, por lo que los controladores P, I y D funcionan como filtros de paso total, paso bajo y paso alto, respectivamente. Dado que el controlador PI presta más atención a la parte de baja frecuencia de la señal de entrada, no puede responder inmediatamente a los cambios rápidos de la señal, por lo que tiene el problema de sobrepasarse. Los controladores D reducen el sobreimpulso al hacer que la salida de control sea sensible a los cambios en la señal de entrada. Figura 3: La parte inferior muestra que la rama de detalle analiza diversa información semántica, aunque de manera imprecisa, mientras que la rama de contexto agrega información contextual de baja frecuencia y, de manera similar, usa un filtro de promedio grande semánticamente. La fusión directa de información de detalle e información de contexto conduce a la pérdida de algunas características de detalle. Por tanto, concluimos que TBN es equivalente a un controlador PI en el dominio de Fourier .
3.1 PIDNet: Una novedosa red de tres ramas
Para aliviar el problema de exceso, adjuntamos una rama diferencial auxiliar (ADB) a TBN para simular un controlador PID y resaltar espacialmente la información semántica de alta frecuencia. Dado que la semántica de los píxeles dentro de cada objeto es consistente, las inconsistencias solo ocurren en los límites de los objetos adyacentes, por lo que solo en los límites de los objetos, la diferencia en la semántica es distinta de cero, ADB apunta a la detección de límites. En consecuencia, construimos una nueva arquitectura de segmentación semántica en tiempo real de tres ramas, la red proporcional-integral-derivada (PIDNet), como se muestra en la Figura 4.

PIDNet tiene tres ramas con funciones complementarias: la rama proporcional (P) analiza y conserva información detallada en mapas de características de alta resolución; la rama integral (I) agrega información contextual local y global para resolver dependencias a largo plazo; la derivada (D) branch extrae características de alta frecuencia y predice regiones límite. Como en [20], también empleamos los bloques residuales en cascada [19] como la columna vertebral para la compatibilidad del hardware. Además, la profundidad de las ramas P, I y D se establece en Moderado, Profundo y Superficial para una alta eficiencia. Por lo tanto, al profundizar y ampliar el modelo, se generaron las series pidnet (PIDNet-S, M y L).
Siguiendo [20, 28, 51], colocamos una cabeza semántica a la salida del primer módulo Pag, generando una pérdida semántica adicional l0 para optimizar mejor toda la red. Se adopta una pérdida de entropía cruzada binaria ponderada l1 para resolver el problema de desequilibrio de la detección de límites en lugar de la pérdida de dados [13]. Porque se inclina más por los límites aproximados para resaltar el área del límite y mejorar las características de los objetivos pequeños. l2 y l3 denotan pérdida de CE, mientras que l3 utiliza la salida de pérdida de CE consciente de los límites [46] del cabezal de límite para coordinar las tareas de segmentación semántica y detección de límites y mejorar la función del módulo Bag. El cálculo de BAS-Loss se puede escribir como:
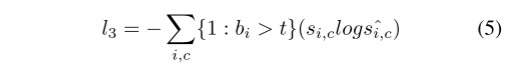
donde t es un umbral predefinido, bi, si,c y ˆsi,c son respectivamente el encabezado de límite del i-ésimo píxel de clase c, la verdad de campo de la segmentación y la salida del resultado de la predicción. Por lo tanto, la pérdida final de PIDNet es:
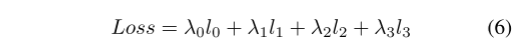
Según la experiencia, establecemos los parámetros de pérdida de entrenamiento de PIDNet como: λ0 = 0,4, λ1 = 20, λ2 = 1, λ3 = 1, t = 0,8.
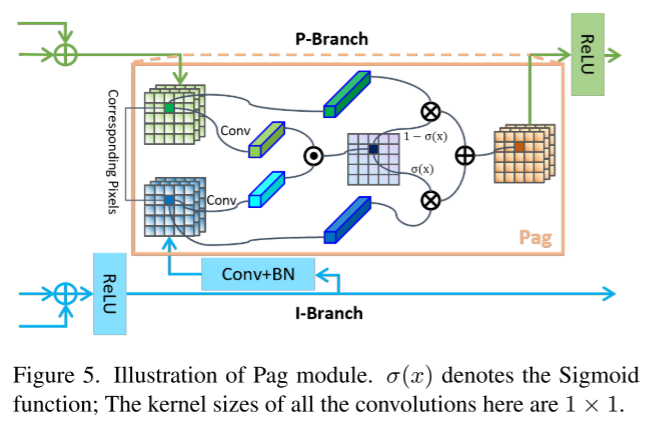
3.2 Pag: Aprendizaje Selectivo de Semántica Avanzada
Las conexiones laterales utilizadas en [20, 35, 48] mejoran la transferencia de información entre mapas de características de diferentes escalas y mejoran la expresividad de los modelos de mapas de características. En PIDNet, la información semántica rica y precisa proporcionada por la rama I es crucial para el análisis detallado y la detección de límites de las ramas P y D, que contienen relativamente pocas capas y canales. Por lo tanto, tratamos la sucursal I como una copia de seguridad de las otras dos y le permitimos brindarles la información requerida. A diferencia del mapa de características proporcionado por la adición directa de la rama D, presentamos el módulo de fusión guiada por atención de píxeles (módulo de fusión guiada por atención de píxeles, Pag) como se muestra en la Figura 5, de modo que la rama P puede ser selectivamente fusionado de la rama I para aprender características semánticas útiles. El concepto básico de Pag se toma prestado del mecanismo de atención [47]. Defina los vectores de los píxeles correspondientes en los mapas de características de la rama P y la rama I como vp y vi respectivamente, luego la salida de la función sigmoidea se puede expresar como:

σ representa la probabilidad de que estos dos píxeles pertenezcan al mismo objeto. Si σ es alto, confiamos más en vi porque la rama I es semánticamente rica y precisa, y viceversa. Por lo tanto, la salida de Pag se puede escribir como:

(Verde y azul corresponden a la parte superior de P e I en la Figura 4. El dibujo es más complicado. De hecho, esto es muy común. La función es fusionar dos características. La relación de fusión σ se calcula con base en los vectores de características de los dos.)
3.3 PAPPM: agregación rápida de contexto
Para construir mejor la escena global, PSPNet [59] presenta un módulo de agrupación piramidal (PPM), que concatena mapas de agrupación multiescala antes de capas convolucionales para formar representaciones contextuales locales y globales. El PPM de agregación profunda (DAPPM) propuesto por [20] mejora aún más la capacidad de integración de contexto de PPM y muestra un rendimiento superior. Sin embargo, el proceso de cálculo de DAPPM no se puede paralelizar en profundidad, lleva mucho tiempo y DAPPM contiene demasiados canales en cada escala, lo que puede exceder la capacidad de representación del modelo ligero. Por lo tanto, modificamos las conexiones en DAPPM para hacerlas paralelizables, como se muestra en la Figura 6, y reducimos el número de canales por escala de 128 a 96. Este nuevo módulo de recopilación de contexto se llama Parallel Aggregation PPM (PAPPM) y se aplica a PIDNet-M y PIDNet-S para garantizar su velocidad. Para nuestro modelo profundo: PIDNet-L, considerando la profundidad de DAPPM, seguimos eligiendo DAPPM, pero reducimos su número de canales, de modo que el cálculo sea menor y la velocidad sea más rápida.

3.4 Bolsa: detalles de equilibrio y contexto
Teniendo en cuenta las características de los límites extraídas por ADB, utilizamos la atención de los límites para guiar la fusión de las representaciones de detalle (P) y contexto (I). Específicamente, diseñamos un módulo de fusión guiado por atención de límites (Bolsa), como se muestra en la Fig. 7, que llena regiones de alta y baja frecuencia con características de detalle y características contextuales, respectivamente. Tenga en cuenta que la rama de contexto es semánticamente precisa, pero pierde demasiados detalles espaciales y geométricos, especialmente para las regiones límite y los objetos pequeños. Dado que la rama de detalle conserva mejor los detalles espaciales, obligamos al modelo a confiar en la rama de detalle a lo largo de las regiones fronterizas y rellenar otras regiones con características contextuales. Defina los vectores de píxeles correspondientes a los mapas de características P, I y D como vp, vi y vd, respectivamente, luego las salidas de Sigmoid, Bag y Light-Bag se pueden expresar como:

donde f es una combinación de convolución, normalización por lotes y ReLU. Aunque reemplazamos la convolución de 3 × 3 en Bag con dos convoluciones de 1 × 1 en Light-Bag, las funciones de Bag y Light-Bag son similares, es decir, cuando σ > 0.5, el modelo confía más en las características detalladas, en lugar de Información contextual.

(De hecho, es PDI de arriba a abajo, D se usa como peso σ, y Light-Bag usa 1*1 pequeña convolución para ser más liviano, que es similar a Pag)
4. Experimenta
En esta sección, nuestros modelos se entrenan y prueban en los puntos de referencia de paisaje urbano, CamVid y PASCAL Context.
4.1. conjuntos de datos
paisaje urbano Cityscape [12] es uno de los conjuntos de datos de análisis de escenas urbanas más famosos, que contiene 5000 imágenes recopiladas desde la perspectiva de los automóviles en diferentes ciudades. Estas imágenes se dividen en grupos 2975, 500 y 1525 para entrenamiento, validación y prueba. La resolución de la imagen es de 2048 × 1024, lo cual es un desafío para los modelos en tiempo real. Aquí solo se utilizan conjuntos de datos anotados.
CamVid . CamVid [5] proporciona 701 imágenes de escenas de conducción, divididas en 367, 101 y 233 imágenes, para entrenamiento, verificación y prueba. La resolución de la imagen es de 960×720 y hay 32 categorías etiquetadas, 11 de las cuales se comparan con trabajos anteriores.
PASCAL Context proporciona anotaciones semánticas de toda la escena en PASCAL Context [33], que contiene 4998 imágenes para entrenamiento y 5105 imágenes para validación. Aunque este conjunto de datos se usa principalmente para comparar modelos de alta precisión, lo usamos aquí para demostrar la capacidad de generalización de PIDNets. Se evaluaron escenarios de nivel 59 y nivel 60.
4.2. Detalles de implementacion
Entrenamiento previo Antes de ajustar nuestros modelos, los entrenamos previamente a través de ImageNet [41], como en la mayoría de los trabajos anteriores [20, 34, 35]. Eliminamos la rama D en la etapa final y fusionamos directamente las características para construir un modelo de clasificación. El número total de épocas de entrenamiento es 90 y la tasa de aprendizaje se establece inicialmente en 0,1 y se multiplica por 0,1 en las épocas 30 y 60. Las imágenes se recortan aleatoriamente a 224 × 224 y se voltean horizontalmente para aumentar los datos.
Formación Nuestro esquema de formación es casi el mismo que en trabajos anteriores [15, 20, 52]. Específicamente, actualizamos la tasa de aprendizaje con una estrategia de múltiples grupos, recorte aleatorio, inversión horizontal aleatoria y escalado aleatorio en el rango [0.5, 2.0] para el aumento de datos. El número de períodos de entrenamiento, la tasa de aprendizaje inicial, la disminución del peso, el tamaño del cultivo y el tamaño del lote del paisaje urbano, CamVid y PASCAL Context son [484, 1e−2, 5e−4, 1024×1024, 12], [200,1e− 3 ,5e−4960×720,12] y [200,1e−3,1e−4520×520,16]. Siguiendo [20, 51], ajustamos el modelo CamVid preentrenado del paisaje urbano y detenemos el proceso de entrenamiento cuando lr < 5e−4 para evitar el sobreajuste
Inferencia Antes de la prueba, nuestros modelos se entrenan y se valúan en Cityscape y CamVid. Medimos la velocidad de inferencia en una plataforma que consta de RTX 3090, PyTorch 1.8, CUDA 11.2, cuDNN 8.0 y un entorno Windows Conda. Aprovechando los protocolos métricos propuestos en [10] y posteriormente [20, 35, 45], integramos la normalización por lotes en capas convolucionales y establecemos el tamaño del lote en 1 para medir la velocidad de inferencia.
4.3. Estudio de ablación
ADB para redes de dos sucursales
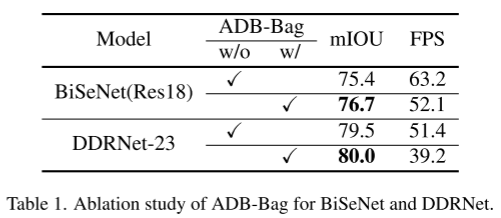
Para demostrar la efectividad del enfoque PID, combinamos ADB y Bag con modelos existentes. Aquí, implementamos dos redes representativas de doble rama: BiSeNet [52] y DDRNet [20] equipadas con ADB y Bag, que logran una precisión mucho mayor que el modelo original en el conjunto de valores del paisaje urbano, como muestra la Tabla 1. Sin embargo, el cálculo adicional ralentiza significativamente su velocidad de inferencia, lo que nos llevó a construir PIDNet.
Colaboración de Pag y Bag
Antes de la etapa de fusión, la rama P usa el módulo Pag para obtener información útil de la rama I sin verse abrumada, e introduce el módulo Bolsa para guiar la fusión de características detalladas y características contextuales. Como se muestra en la Tabla 2, la conexión lateral puede mejorar significativamente la precisión del modelo y el entrenamiento previo puede mejorar aún más el rendimiento del modelo. En nuestro esquema, la combinación de agregar conexiones laterales y módulos de fusión Bag o conexiones laterales Pag y agregar módulos de fusión no tiene sentido, ya que los detalles deben mantenerse consistentes en toda la red. Por lo tanto, solo necesitamos comparar el rendimiento de Add + Add y Pag + Bag. Los resultados experimentales en la Tabla 2 y la Tabla 3 ilustran la superioridad de la sinergia Pag y Bag (o Light-Bag). La visualización del mapa de características en la Figura 8 muestra que en el mapa sigmoideo de la segunda Pag, los objetos pequeños se vuelven mucho más oscuros que los objetos grandes y mi rama pierde más detalles. Además, en la salida del módulo Bolsa, las características de las regiones límite y los objetos pequeños también se mejoran considerablemente, como se muestra en la Figura 9, razón por la cual elegimos la detección de límites gruesos.

Eficiencia de PAPPM.
Para modelos en tiempo real, un módulo de agregación de contexto pesado puede ralentizar significativamente la inferencia y puede exceder la capacidad de representación de la red. Por lo tanto, proponemos PAPPM que consta de una estructura paralela y un número reducido de parámetros. Los resultados experimentales en la Tabla 3 muestran que en nuestro modelo liviano, PAPPM logra la misma precisión que DAPPM [20], pero con una aceleración de 9.5 FPS.

Efectividad de Pérdidas Extra.
PIDNet introduce tres pérdidas adicionales para facilitar la optimización de toda la red y enfatizar la función de cada componente. En la Tabla 4, se puede ver que para un mejor rendimiento, son necesarias la pérdida de límite l1 y la pérdida consciente de límite l3, especialmente la pérdida de límite (+1,1 % mIOU), lo que demuestra contundentemente la necesidad de la rama d, mientras que la minería de ejemplo difícil en línea ( OHEM) [43] mejora aún más la precisión.
4.4. Comparación
CamVid.
Para el conjunto de datos de CamVid [5], solo la precisión de DDRNet se puede comparar con nuestro modelo, por lo que probamos su velocidad en nuestra plataforma, que es más avanzada que la de ellos para una comparación justa. Los resultados experimentales de la Tabla 5 muestran que la precisión de todos nuestros modelos supera el 80 % mIOU, PIDNet-S-Wider simplemente duplica el número de canales de pidnet, obtiene la mayor precisión y es mucho mejor que los modelos anteriores. Además, PIDNet-S logra una mejora de la precisión del 1,5 % mIOU con respecto al modelo de última generación DDRNet-23-S anterior, con solo ~1 ms de latencia adicional.

Paisajes urbanos.
Los trabajos anteriores en tiempo real utilizan el paisaje urbano [12] como punto de referencia estándar, teniendo en cuenta su interpretación de alta calidad. Como se muestra en la Tabla 6, para una comparación justa, probamos la velocidad de inferencia de los modelos lanzados en los últimos dos años en la misma plataforma sin ninguna herramienta de aceleración. Los resultados experimentales muestran que las PIDNet logran el mejor equilibrio entre la velocidad de inferencia y la precisión de la inferencia. Entre ellos, PIDNet-L superó a SFNet (ResNet18)† y DDRNet-39 en términos de velocidad y precisión, y la precisión de la prueba aumentó del 80,4 % mIOU al 80,64 % mIOU, convirtiéndose en el modelo más preciso en el campo en tiempo real. PIDNet-M y PIDNet-S también brindan una mayor precisión en comparación con otros modelos con una velocidad de inferencia similar. Al eliminar los módulos Pag y Bag de PIDNet-S, brindamos una alternativa más rápida: PIDNet-S-simple, que generaliza menos bien pero aún logra la mayor precisión en modelos con latencia < 10 ms.
Contexto PASCAL.
La ruta Avg(17,8) en PAPPM se elimina porque el tamaño de la imagen es demasiado pequeño en PASCAL Context [33]. A diferencia de los otros dos conjuntos de datos, este documento emplea inferencia invertida y multiescala para comparar con modelos anteriores. A pesar de las anotaciones menos detalladas en PASCAL Context en comparación con los dos conjuntos de datos anteriores, nuestro modelo aún logra un rendimiento competitivo en las redes pesadas existentes, como se muestra en la Tabla 7.
5. Conclusión
Se propone una nueva estructura de red de tres ramas: red de segmentación semántica en tiempo real PIDNet. PIDNet logra un equilibrio óptimo entre el tiempo de inferencia y la precisión. Pero dado que PIDNet utiliza la predicción de límites para equilibrar la información detallada y la información contextual, se requiere una anotación precisa cerca de los límites para un mejor rendimiento, lo que generalmente requiere mucho tiempo.
(La idea es un poco como bmaskrcnn, agregar información de borde, pero ¿está realmente relacionada con PID, o simplemente está tomando prestada esta forma, que no tiene nada que ver con el sentimiento integral y diferencial real, pero tengo que decir que el efecto debe ser bueno)