0. Resumen
Resumen: La percepción robusta del entorno es un gran desafío para los vehículos autónomos, lo que hace que una amplia variedad de sensores como cámaras, LiDAR y radar sean cruciales. La segmentación semántica 3D juega un papel importante en el proceso de comprensión de los datos de sensores registrados. Por lo tanto, este artículo propone una arquitectura de fusión profunda de cámara y lidar basada en pirámide para mejorar la segmentación semántica 3D de las escenas de tráfico. Las redes troncales de sensores independientes extraen mapas de características de las imágenes de la cámara y las nubes de puntos LIDAR. Una novedosa red troncal de fusión de pirámides fusiona estos mapas de características de diferentes escalas y combina características multimodales en pirámides de características para calcular valiosas características multimodales y multiescala. El cabezal de fusión piramidal agrega estas características piramidales y las refina aún más en un paso posterior a la fusión, combinando las características finales de la columna vertebral del sensor. El método se evalúa en dos conjuntos de datos al aire libre desafiantes y se investigan diferentes estrategias y configuraciones de fusión. Supera a los métodos LIDAR basados en vista de rango recientes, así como a todas las estrategias y arquitecturas de fusión propuestas hasta el momento.
1. Introducción
La comprensión de la escena semántica juega un papel crucial en muchas tareas robóticas. Para comprender completamente las escenas 3D complejas, es crucial desarrollar y combinar diferentes modalidades de sensores. La fusión de sensores de cámara y lidar es una combinación complementaria prometedora. Las cámaras proporcionan imágenes de alta resolución pero no información geométrica, mientras que las nubes de puntos LIDAR proporcionan información geométrica 3D valiosa pero escasa que se vuelve más escasa a medida que aumenta la distancia. Por lo tanto, la fusión de imágenes de cámara con nubes de puntos 3D tiene un gran potencial.
Un aspecto importante de la comprensión de la escena 3D es la segmentación semántica 3D, que asigna una etiqueta de clase a cada punto 3D individual. Aunque existen muchos métodos para usar la información de profundidad para mejorar la segmentación semántica de imágenes, existen pocos estudios sobre el uso de la información de la cámara para mejorar la segmentación semántica 3D. En general, para utilizar Redes Neuronales Convolucionales (CNNs) se han propuesto diferentes representaciones de nubes de puntos, como las basadas en proyección [1], [2] o basadas en puntos [3], [4]. Una representación basada en proyección prometedora es la vista de distancia basada en proyección esférica , ya que permite una fusión intuitiva con las imágenes de la cámara.
Las estrategias comúnmente utilizadas [5] son la fusión de datos de entrada sin procesar (fusión temprana), la fusión de mapas de características (fusión profunda) y la fusión de predicciones (fusión tardía) . La fusión temprana y tardía solo se fusionan una vez a una escala, mientras que la fusión profunda ofrece la posibilidad de fusionarse en múltiples ubicaciones y escalas. En el procesamiento de imágenes, las pirámides de características son un método común para identificar contenido de múltiples escalas. Por lo tanto, son un buen punto de partida para la fusión de características profundas a múltiples escalas.

En base a estos hallazgos, proponemos un nuevo método de fusión profunda basado en pirámide, como se muestra en la Figura 1, para mejorar la segmentación semántica 3D mediante la fusión multiescala de LiDAR y cámara . Se utiliza una columna vertebral de fusión de pirámide novedosa para fusionar características LIDAR en el espacio del punto de vista a distancia con características de cámara transformadas en diferentes escalas dentro de una pirámide de características. El cabezal de fusión piramidal propuesto agrega características multimodales y de múltiples escalas y las refina en la etapa posterior de la fusión. Toda la red de fusión piramidal mejora significativamente los resultados. En resumen, nuestras contribuciones son:
- Una arquitectura modular de fusión profunda multiescala que consta de una red troncal de sensor intercambiable y una red de fusión piramidal novedosa .
- Pyramid Fusion Backbone para LiDAR y Camera Multi-Scale Feature Fusion en Range Field of View .
- Un cabezal de fusión piramidal para agregar y refinar características piramidales de múltiples modelos y múltiples escalas.
2. Trabajo relacionado
A. Segmentación semántica 2D
Las redes totalmente convolucionales (FCN) [6] son las arquitecturas de red pioneras para tareas de segmentación semántica. Las arquitecturas totalmente convolucionales están diseñadas para la predicción de nivel de píxel de extremo a extremo, ya que reemplazan capas de CNN totalmente conectadas con convoluciones. Dado que el FCN original se esfuerza por capturar el contexto global de una escena [7], han surgido nuevas arquitecturas [7]–[9], basadas en características piramidales para la agregación de contexto de múltiples escalas, que recopila el contexto global y conserva los detalles.
PSPNet [7] aplica un módulo de agrupación piramidal (PPM), que combina diferentes escalas del último mapa de características. Por lo tanto, la red puede capturar el contexto y los detalles de la escena. Otros enfoques como HRNetV2 [9] aprovechan las características piramidales ya existentes en la columna vertebral de extracción de características. Para la tarea relacionada de segmentación de imágenes panorámicas, EfficientPS [8] combina características de abajo hacia arriba y de arriba hacia abajo de diferentes escalas mediante la aplicación de la red piramidal de características bidireccionales (FPN) [10]. Luego use la cabeza semántica para capturar características a gran escala y características a pequeña escala para la segmentación semántica;
B. Segmentación semántica 3D
En contraste con la aplicación de CNN a datos de imágenes dispuestos en una cuadrícula regular, las CNN no se pueden aplicar directamente a nubes de puntos 3D. Por lo tanto, se han desarrollado varias representaciones y arquitecturas especializadas.
Un enfoque pionero para procesar directamente datos en bruto no estructurados es PointNet [3], que aplica un perceptrón multicapa compartido para extraer características para cada punto de entrada. Dado que debe ser invariable a cualquier permutación de entrada, las características se agregan mediante operaciones simétricas. Su sucesor PointNet++ [4] explota la relación espacial entre características a través de la agrupación jerárquica recursiva de puntos.
Los métodos que no procesan nubes de puntos sin procesar las transforman en espacios discretos como mallas 2D o 3D. Una representación eficiente y prometedora de cuadrículas 2D basadas en proyecciones esféricas es la llamada vista a distancia. SqueezeSeg [12] es uno de los primeros métodos en utilizar esta representación para la segmentación de objetos de carretera. El último enfoque es SqueezeSegV3 [13], que utiliza circunvoluciones espacialmente adaptables para contrarrestar las distribuciones de características que varían de una vista a otra. RangeNet++ [1] propone un paso de posprocesamiento eficiente basado en knn para superar algunos inconvenientes que presenta la proyección esférica. En comparación con los métodos anteriores, SalsaNext [2] mejora varios aspectos de la arquitectura de la red, como la capa de barajado de píxeles y el uso de Lov´asz-Softmax-Loss [14] en la decodificación. Otra adaptación de la convolución se usa en [15]. El método utiliza una convolución densa armónica ligera para procesar el mapa de distancia en tiempo real y logra buenos resultados. Además, surgieron métodos híbridos que explotan múltiples representaciones [16], [17].
C. Fusión multisensor 3D
La fusión de múltiples sensores continúa ganando atención para diferentes tareas en la visión por computadora. Resuelve principalmente el problema de la detección de objetivos 3D combinada con cámara y lidar. Para la fusión de características densas requerida para la predicción densa (como la segmentación semántica), solo hay unos pocos trabajos [18]-[21] hasta el momento.
En [18], la fusión basada en regiones de interés densas se aplica a una variedad de tareas, incluida la detección de objetos 3D. Otro método de detección de objetos 3D [19] aplica circunvoluciones continuas que combinan funciones de cámara densa y lidar a vista de pájaro. La capa de fusión continua fusiona características de imágenes de múltiples escalas con mapas de características LIDAR de diferentes escalas en la red.
Se propone un algoritmo de detección de objetos y segmentación semántica basado en LaserNet++ [20]. El algoritmo primero procesa la imagen de la cámara a través de una red residual. Al aplicar el mapeo de proyección, las características de la cámara se transforman en una vista a distancia. Los mapas de características cosidos luego se introducen en LaserNet [22]. Fusion3DSeg [21] emplea una estrategia de fusión iterativa para funciones de cámara y lidar. En Fusion3DSeg, las funciones de cámara y vista a distancia adoptan una estrategia iterativa de agregación profunda para la fusión iterativa de funciones a múltiples escalas. Las últimas funciones se combinan aún más con funciones basadas en puntos de la rama 3D en lugar del posprocesamiento habitual basado en knn [1].
En comparación con [18], el [19] propuesto es modular y cada columna de sensor es independiente entre sí, ya que no se retroalimentan características de imagen a la columna de LiDAR. Además, se propone una nueva estrategia de fusión piramidal bidireccional. LaserNet++ [22] en el otro lado solo se fusiona una vez y no aplica fusión multiescala. Fusion3DSeg [21] es el trabajo más relacionado, que emplea una estrategia de fusión iterativa que es bastante diferente de nuestra estrategia de pirámide paralela de abajo hacia arriba y de arriba hacia abajo.
3. Segmentación semántica 3D basada en Pyramid Fusion Network
El enfoque de fusión profunda de sensores propuesto en este documento consta de cuatro componentes principales , que se presentan en la siguiente sección. Primero, una columna vertebral de cámara y lidar que calcula características a partir de datos de sensores individuales, y luego una columna vertebral de fusión piramidal novedosa que fusiona características de codificador de dos modalidades en diferentes escalas de una manera de arriba hacia abajo y de abajo hacia arriba. El cabezal de fusión piramidal combina estas características y las fusiona con la salida final de los dos decodificadores de la columna vertebral del sensor en el puesto de fusión. La arquitectura general se muestra en la Figura 2a. La modularidad del método y la elección de la estrategia de entrenamiento permiten que el método maneje la indisponibilidad de la cámara, cambie las redes troncales o los sensores y prediga conjuntamente la segmentación semántica de las cámaras y LiDAR sin afectar otros objetivos. Por lo tanto, ambas redes troncales se entrenan previamente en los datos de sus sensores y se congelan mientras se entrena toda la arquitectura de fusión. Por lo tanto, la red troncal aún puede predecir la semántica de un solo sensor como una alternativa para la indisponibilidad de la cámara o la segmentación adicional de la cámara.
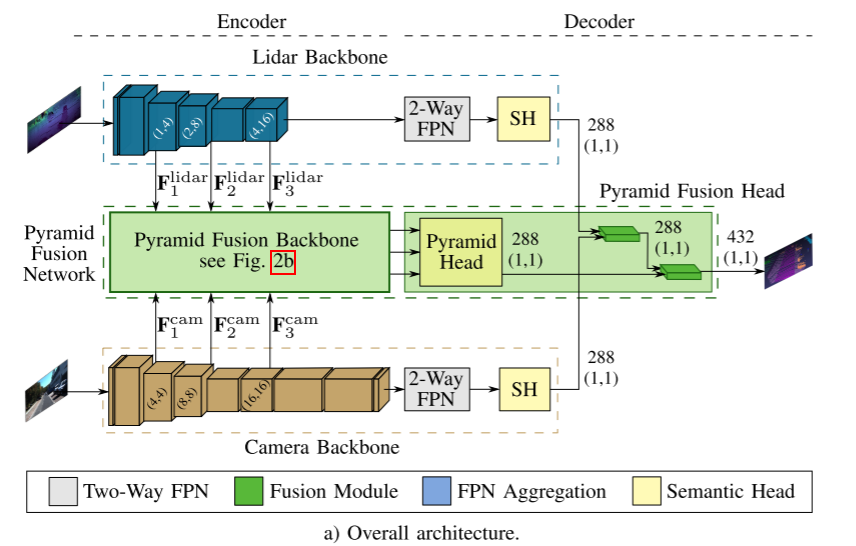
A. Red troncal Lidar
La red troncal lidar calcula las características de la nube de puntos de entrada en función de la proyección esférica de [21], [23], que se representan en una vista a distancia. Su arquitectura está impulsada por EfficientPS [8] y adaptada a vistas de rango. Dado que la resolución de la imagen de rango es menor que la de la imagen de la cámara, especialmente en dirección vertical, los pasos de reducción de resolución de las dos primeras etapas solo se realizan en dirección horizontal . Además, usamos EfficientNet-B1 [24] como codificador y eliminamos las últimas tres etapas. Por lo tanto, FPN bidireccional tiene solo tres etapas en lugar de cuatro, y los canales de salida se reducen a 128, porque EfficientNet-B1 usa menos canales de funciones que EfficientNet-B5. Como se muestra en la Figura 2a, los mapas de características calculados de las etapas tercera, cuarta y sexta se envían a la columna vertebral de fusión piramidal para la fusión con las características de la cámara. Debido a la eliminación de la etapa FPN, el módulo DPC correspondiente [8] también se elimina del encabezado semántico. Cabezal Cabezal de fusión piramidal que proporciona fusión tardía de sus características de salida.
B. Columna vertebral de la cámara
El primer backbone que estudiamos seguía siendo EfficientPS, pero usaba el Efficient-B5 original como codificador. En comparación con la red troncal lidar, EfficientPS prácticamente no ha cambiado para su uso como red troncal de cámara. Asimismo, las salidas de la tercera, cuarta y sexta etapa son alimentadas al backbone de fusión piramidal. Para el paso posterior a la fusión del cabezal de fusión piramidal, se utiliza la salida del cabezal semántico.
Además, PSPNet que utiliza el ResNet101 subyacente [25] se elige como otra red troncal. Se proporcionan tres mapas de características de las capas conv3_4, conv4_23 y conv5_3 de ResNet101 como entrada a la columna vertebral de Pyramid Fusion. La salida de PPM se alimenta al paso de fusión posterior.
C. Red de Fusión Pirámide
La parte clave de la arquitectura de fusión es la red de fusión piramidal, que fusiona las funciones de lidar y cámara. El módulo de fusión transforma las características en un espacio común, seguido del paso de fusión, que combina las dos modalidades. La columna vertebral de la fusión piramidal aplica estos módulos a diferentes escalas y agregados y combina las características fusionadas resultantes de forma descendente y ascendente, como se muestra en la Figura 2b. Estas características multimodales y de escala múltiple se combinan y refinan aún más con el cabezal de fusión piramidal en la etapa de fusión posterior.

Transformación de funciones
Para lograr la fusión de lidar y cámara, se necesita un espacio común. Por lo tanto, se requiere una proyección de características desde la imagen de la cámara al espacio de vista a distancia. Además, las proyecciones deben ser adecuadas para diferentes escalas de mapas de características. Para resolver este problema, utilizamos la proyección escalable [21], [26] de Fusion3DSeg. La idea general es crear un mapeo desde la imagen de la cámara hasta las coordenadas de la vista de rango en función de los puntos 3D de la nube de puntos. Cada punto se puede proyectar en la vista de distancia, así como en la imagen de la cámara, creando el vínculo deseado entre la imagen de la cámara y las coordenadas de la vista de distancia.
Módulo de fusión

La transformación y fusión de características se realizan a través del módulo de fusión, como se muestra en la Figura 3. En primer lugar, los mapas de características de los dos sensores se recortan en el campo de visión superpuesto, ya que la fusión solo es posible en esta región. El espacio de funciones de la cámara se transforma en el espacio de vista de rango mediante la transformación de funciones anterior, y luego el lidar se alinea con el espacio de funciones de la cámara mediante la proyección de funciones aprendidas, implementada por un bloque residual invertido (IRB) [8]. Los lidars se caracterizan por un muestreo ascendente bilineal porque la resolución de su mapa de características es más pequeña que la de las cámaras, lo que permite la fusión de diferentes características de los dos sensores. Las funciones de cámara y LiDAR alineadas en el espacio de vista de rango se concatenan, seguidas de uno o más bloques residuales para la fusión de aprendizaje. Este módulo tiene como objetivo aplicar diferentes estrategias de fusión con diferentes tipos y números de bloques. Estudiamos una estrategia de fusión de cuello de botella basada en el bloqueo residual de cuello de botella (BRB) [27] y una estrategia de fusión residual invertida basada en irb.
Columna vertebral de fusión piramidal
Este módulo de fusión está integrado en un FPN bidireccional para fusionar dos modalidades a diferentes escalas y luego calcular características multimodales y multiescala a través de la agregación de abajo hacia arriba y de arriba hacia abajo. Desde la red troncal LIDAR, los mapas de características de tres escalas diferentes, como se muestra en la Fig. 2b, se pasan a sus respectivos módulos de fusión. Luego, los mapas de características se muestrean a la resolución de salida de destino y se fusionan con los mapas de características de la columna vertebral de la cámara de tres escalas diferentes. Los tres mapas de características resultantes se agregan luego en forma de pirámides de características de abajo hacia arriba y de arriba hacia abajo para calcular características de múltiples escalas. De esta manera, la agregación de características multimodales a diferentes escalas comienza, por un lado, con detalles e incorporando más y más contexto, y por otro lado, con contexto y agregando más y más detalles. Finalmente, las dos salidas de cono se combinan y las características de cono multimodal y de escala múltiple resultantes se pasan al cabezal de fusión piramidal.
Cabeza de fusión piramidal
El primer paso de la cabeza de fusión es similar a la cabeza semántica de la columna vertebral LIDAR, que combina los tres mapas de características de la FPN bidireccional y, en este caso, de la columna vertebral de fusión piramidal. Este último fusiona características de ambos codificadores, con un paso adicional de posfusión que fusiona las características finales de los decodificadores de cámara y lidar para refinar aún más las características de la red de fusión piramidal. Por lo tanto, los últimos mapas de características de la columna vertebral de la cámara y LIDAR se fusionan con las características agregadas de la columna vertebral de fusión piramidal a través de dos módulos de fusión adicionales, como se muestra en la Figura 2a.
El mapa de características final se introduce en una convolución 1x1 seguida de una función de activación softmax para la clasificación a nivel de píxel de la entrada de vista de distancia. Aplique el posprocesamiento basado en knn [1] a la segmentación semántica 3D.
4. Evaluación
Las siguientes evaluaciones se realizan en dos desafiantes conjuntos de datos al aire libre a gran escala, SemanticKITTI [28] y PandaSet [29], en ambos casos, la intersección media (mIoU) de los campos de visión superpuestos de dos sensores se informa como Estudie nuestro método y compárelo con otros métodos de última generación.
SemanticKITTI es un conjunto de datos de anotación puntual basado en Velodyne-HDL64E de escaneos lidar de 360◦ de la tarea de odometría KITTI Vision Benchmark [30]. Contiene aproximadamente 43.000 escaneos para 22 secuencias anotadas y 19 clases. De estas secuencias, solo las primeras 11 tienen verdad de terreno público. Reportamos nuestros resultados en la Secuencia de Validación Formal08. Dado que no existen imágenes etiquetadas semánticamente para la tarea de odometría, la columna vertebral de la cámara se entrena previamente utilizando datos del Desafío de segmentación semántica [31]. Contiene 200 imágenes anotadas, usamos 0 - 149 para entrenamiento y el resto para validación.
PandaSet proporciona escaneos LIDAR anotados de 6080 puntos de Pandar64 e imágenes de cámara correspondientes de la cámara frontal central. Para la comparabilidad con otros métodos [23], agrupamos las clases etiquetadas en subconjuntos de 14 clases y seguimos la división de datos propuesta en [23].
A. Detalles de implementación
El método se entrena en modo de precisión mixto, utilizando entrenamiento paralelo de datos distribuidos en hasta 4 GPU Tesla V100. Durante el entrenamiento, la red se optimiza utilizando una pérdida de entropía cruzada ponderada con pesos wc = log(nc/n), donde n define el número total de puntos o píxeles y el valor de nc para cada clase c. Además, la tasa de aprendizaje se reduce en 1−(i/imax)0.9 utilizando un programador de tasa de aprendizaje poli, donde i denota una iteración. Si no se indica lo contrario, se utilizó un optimizador SGD con una caída de peso de 0,0001.
El tamaño del lote de los dos conjuntos de datos de la red troncal Lidar es 16, la tasa de aprendizaje inicial de SemanticKITTI es 0,07 y la tasa de aprendizaje inicial de PandaSet es 0,001. Este último está optimizado por Adam. Para reducir el sobreajuste, se aplicaron cambios horizontales aleatorios con probabilidad de 0,5 y recortes aleatorios (tamaño de recorte 64 × 1024) en los dos conjuntos de datos, respectivamente.
Camera Backbone Ambas redes usan pesos preentrenados del paisaje urbano [32] y se entrenan más en lotes de 4. Para EfficientPS se aplica una tasa de aprendizaje inicial de 0,0007, mientras que para PSPNet se utiliza 0,0001. Cambios horizontales aleatorios y desenfoque gaussiano con probabilidad de 0,5, y cultivos aleatorios de tamaño 300 × 600 y rotaciones aleatorias dibujadas uniformemente desde [−5◦, 5◦]. Si no se indica, EfficientPS se utiliza como columna vertebral de la cámara.
Deep Fusion entrena el método de fusión en SemanticKITTI con un tamaño de lote de 16 y una tasa de aprendizaje de 0,07 después de entrenar previamente y congelar las dos redes troncales. En PandaSet, el tamaño del lote se establece en 8, la tasa de aprendizaje inicial es 0,001 y se utiliza el optimizador Adam. Para el aumento de datos, la probabilidad de un giro horizontal aleatorio es 0,5. Las resoluciones de los campos de visión superpuestos en la vista a distancia son 45×485 y 61×266, respectivamente. Debido al pequeño tamaño del sensor, no se utiliza el recorte aleatorio para las partes superpuestas. Dado que las imágenes de cámara etiquetadas semánticamente no existen en PandaSet, la columna vertebral de la cámara no se congela para los experimentos correspondientes. Para tener en cuenta la formación previa, fijamos la tasa de aprendizaje de EfficientPS en 0,0001 y la de PSPNet en 0,001.
B. Redes de fusión piramidal
Los primeros experimentos que evaluamos investigan el impacto del método propuesto y sus componentes en SemanticKITTI. Los resultados se muestran en la Tabla 1. Dos líneas base importantes son la red troncal LiDAR como línea base de sensor único y la estrategia posterior a la fusión como línea base de fusión, donde los mapas de características finales de las dos redes troncales se fusionan con el módulo de fusión propuesto. Agregar nuestra columna vertebral de fusión, PFB, mejora significativamente los resultados, lo que enfatiza el valor de las características multimodales y, además, destaca los beneficios de nuestra estrategia de fusión multiescala, que supera la fusión tardía. Hasta ahora, la cabeza semántica de la columna vertebral de LIDAR se utiliza como cabeza de pirámide para agregar características piramidales. La implementación de nuestro cabezal de fusión PFH, incluido un paso adicional de fusión tardía, mejora aún más los resultados. En general, PyFu supera a las dos líneas de base en un 3,9 % y un 2,7 %, respectivamente, con un tiempo de inferencia de 48 ms. El siguiente paso es estudiar diferentes estrategias de fusión dentro del módulo de fusión, y los resultados se muestran en la Tabla II. En primer lugar, se evalúa el impacto de diferentes estrategias en el PFB de la columna vertebral piramidal. La estrategia de fusión de cuello de botella que usa BRB+BB [27] supera a la estrategia de fusión inversa que se basa en irb. Esto también se aplica a toda la red de fusión piramidal.
Se lleva a cabo otro experimento en PandaSet para investigar diferentes redes troncales de cámaras. Como se mencionó anteriormente, dado que no existen datos de imagen etiquetados semánticamente, la columna vertebral de la cámara se entrena con la arquitectura general en PandaSet. Aunque en este caso no es posible una segmentación conjunta de lidar y cámara, muestra que nuestro método también se puede entrenar en imágenes sin etiquetado semántico. La Tabla III muestra que EfficientPS como columna vertebral de la cámara supera significativamente a PSPNet, logrando una mejora significativa de +8,8 % con respecto a la línea de base. No obstante, la línea de base LiDAR la supera significativamente en ambos casos, lo que confirma que la arquitectura propuesta funciona bien con diferentes redes troncales de cámaras. EfficientPS también ofrece otra ventaja, ya que requiere menos memoria, lo que le permite procesar las imágenes de la cámara en su resolución nativa. De lo contrario, se realizará la reducción de muestreo inicial por un factor de 2, lo que reducirá el rendimiento. En SemanticKITTI, PSPNet funciona mejor como red troncal con un valor de mIoU del 61,9 %. Para este último y SemanticKITTI, el paso LF no proporciona ninguna mejora. Finalmente, la Figura 4 muestra los resultados cualitativos de estos dos conjuntos de datos bajo tres escenarios diferentes.

C. Resultados cuantitativos
En el siguiente paso, nuestro método se comparará más con los métodos de última generación basados en la vista a distancia para evaluar los beneficios de la fusión de cámara y lidar. Los resultados de SemanticKITTI se muestran en la Tabla 4. Supera a todos los métodos LIDAR en general y también supera a todos los métodos LIDAR en la mayoría de las clases individuales. Vale la pena mencionar que la principal mejora proviene en parte de la fusión, no de líneas de base ya mejores. Esto nuevamente enfatiza el valor de las características de la cámara para mejorar la segmentación semántica 3D. A continuación, nuestra arquitectura y estrategia de fusión se estudian en comparación con otros métodos de fusión profunda, consulte la Tabla 4. La estrategia de fusión piramidal supera a todos los demás métodos de fusión, y el rendimiento superior de PyFu y Fusion3DSeg [21] destaca los beneficios de la fusión de sensores multiescala. Comparado con este último, se logran resultados significativamente mejores, especialmente para motocicletas, otros vehículos y cercas. En [21], se evalúan otros métodos para campos de visión superpuestos con posprocesamiento basado en kNN. [15] de Razani et al., no se pudo calcular porque no había ningún código disponible.
Finalmente, PyFu se compara con otros métodos de fusión en PandaSet. Una vez más, nuestro método funciona mejor, mucho mejor que todos los demás. En categorías individuales, especialmente camiones (+22,4%), otros vehículos (+10,9%) y obstáculos en la carretera (+9,1%), PyFu se desempeña significativamente mejor. Nuestra red troncal lidar también supera a la red troncal lidar de Fusion3DSeg en estos casos. Sin embargo, muestra que la estrategia de fusión propuesta es capaz de mejorar aún más las clases ya fuertes. Para las clases de automóvil, persona, edificio y fondo, nuestro método logra los mejores resultados, aunque con un mejor rendimiento, la columna vertebral lidar de Fusion3DSeg. Si nuestro enfoque no logra los mejores resultados para la clase, otra columna vertebral funcionará mejor que la nuestra. Sin embargo, la estrategia de fusión piramidal reduce significativamente la varianza. En general, esto muestra el gran potencial de nuestra estrategia y arquitectura de fusión.


5. Conclusión
En este trabajo, proponemos una nueva arquitectura de fusión basada en pirámide, PyFu, que fusiona características de LiDAR y cámaras en múltiples escalas para mejorar la segmentación semántica 3D. La red troncal de fusión piramidal fusiona características de múltiples escalas a través de estrategias de arriba hacia abajo y de abajo hacia arriba para mejorar la utilización de información multimodal. Utiliza módulos de fusión flexibles y estrategias intercambiables. Un cabezal de fusión piramidal agrega características piramidales y las refina en un paso de fusión posterior. En dos conjuntos de datos al aire libre desafiantes, PyFu supera a otros métodos de fusión y vista de rango lidar. Los resultados destacan la importancia de la fusión de sensores en general y las ventajas de la arquitectura de fusión propuesta en particular. También enfatiza que la estructura piramidal propuesta hace el mejor uso de la fusión de sensores. En conjunto, este método tiene un gran potencial para mejorar la segmentación semántica de nubes de puntos 3D usando imágenes de cámara.
Resume tú mismo:
1. Siento que la idea es muy simple, la fusión de características de múltiples capas y la pirámide de tres capas son ideas muy maduras, pero ¿cómo arreglas la red original y luego la entrenas?
2. El módulo de fusión, agregando hacia adelante y hacia atrás, ¿es esta la fuente de mejora? ¿Por qué funciona tan bien?
3. La parte de alineación de datos es un poco confusa, las dimensiones de los datos son diferentes y las imágenes no se entienden