Autor: Vivo Internet Operations Team - Hu Tao
Dieser Artikel stellt die praktischen Ideen der Benutzerzugriffsoptimierung für kurze Videos von vivo vor und erläutert kurz einige Prinzipien hinter der Praxis.
1. Hintergrund
Wenn wir normalerweise Videos von Douyin Kuaishou ansehen, wenn wir zu einem bestimmten Videobildschirm wischen und uns einige Sekunden lang nicht bewegen, besteht eine hohe Wahrscheinlichkeit, dass es weggewischt wird. Daher kommt es bei kurzen Videoprojekten zum Einfrieren des Bildschirms wirkt sich stark auf die Benutzererfahrung aus. Je höher die Startgeschwindigkeit, desto mehr Benutzer können gehalten werden.
Die Startgeschwindigkeit ist vereinfacht ausgedrückt die Zeit vom Beginn des Anrufs bis zum ersten Frame auf dem Bildschirm, die sich grob in zwei Teile unterteilen lässt:
-
Zeitaufwändiger Download von Videodateien
-
Zeitaufwändige Videodekodierung
Dieser Artikel beginnt hauptsächlich mit der Perspektive der Betriebs- und Wartungsfehlersuche, beginnt mit jedem Link des Netzwerks und kombiniert den speziellen Fall des kurzen Vivo-Videos, um den Optimierungsprozess mit Ihnen zu teilen.
2. Benutzerzugriffslink
Lassen Sie uns zuerst den nächsten vollständigen Netzwerkanforderungsprozess sortieren, indem wir die Client-Perspektive als Beispiel nehmen, wie in der folgenden Abbildung gezeigt:

Der Zugriff auf CDN kann in mehrere Stufen unterteilt werden:
Auflösung des DNS-Domänennamens : Rufen Sie die IP-Adresse des Servers ab.
TCP-Verbindungsaufbau : Stellen Sie eine Verbindung mit der Server-IP her, d. h. TCP-Dreiwege-Handshake.
TLS-Handshake : Der Client erfragt und verifiziert den öffentlichen Schlüssel des Servers vom Server, und die beiden Parteien verhandeln, um einen „Sitzungsschlüssel“ zu erstellen und eine verschlüsselte Kommunikation durchzuführen.
CDN-Antwort : Verteilen Sie Inhaltsressourcen an Server, die sich an mehreren geografischen Standorten befinden, und geben Sie sie an den Client zurück.
Lassen Sie uns für die oben genannten Phasen darüber sprechen, wie das Vivo-Kurzvideo optimiert wird.
3. Auflösung des DNS-Domänennamens
Wenn wir im Internet surfen, verwenden wir normalerweise Domänennamen anstelle von IP-Adressen, da Domänennamen für das menschliche Gedächtnis praktisch sind. Was diese Technologie dann realisiert, ist die DNS-Domänennamenauflösung, DNS kann die Domänennamen-URL automatisch in eine bestimmte IP-Adresse umwandeln.
3.1 Hierarchische Beziehung von Domänennamen
Domänennamen in DNS werden durch Punkte getrennt , wie z. B. www.server.com , wobei Punkte die Grenzen zwischen verschiedenen Ebenen darstellen . Je weiter rechts in einem Domainnamen, desto höher die Stufe . Die Stammdomäne befindet sich auf der obersten Ebene, und die nächste Ebene ist die com-Domäne der obersten Ebene, und darunter befindet sich server.com .
Daher ähnelt die hierarchische Beziehung des Domänennamens einer Baumstruktur:
-
Root-DNS-Server
-
DNS-Server der obersten Ebene (com)
-
Autorisierender DNS-Server ( server.com )
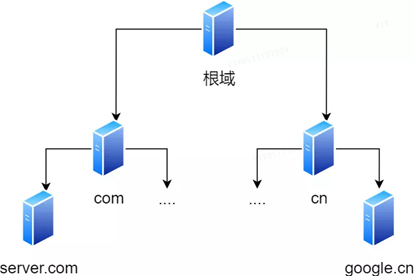
Die DNS-Serverinformationen der Stammdomäne werden auf allen DNS-Servern im Internet gespeichert. Auf diese Weise kann jeder DNS-Server den DNS-Server der Stammdomäne finden und darauf zugreifen.
Solange der Client einen DNS-Server finden kann, kann er daher den DNS-Server der Stammdomäne finden und dann einen Ziel-DNS-Server finden, der sich vollständig in der unteren Schicht befindet.
3.2 Workflow der Domänennamenauflösung
Der Browser prüft zunächst, ob im eigenen Cache welche vorhanden sind, falls nicht, fragt er den Cache des Betriebssystems, falls nicht, prüft er die lokalen Dateihosts zur Auflösung von Domänennamen, falls noch nicht vorhanden, fragt er den DNS-Server ab Der Abfrageprozess ist wie folgt:
Der Client sendet zuerst eine DNS-Anfrage, fragt nach der IP von www.server.com und sendet sie an den lokalen DNS-Server (d. h. die DNS-Serveradresse, die in den TCP/IP-Einstellungen des Clients eingetragen ist).
Nachdem der lokale Domänennamenserver die Anfrage des Clients erhalten hat und die Tabelle im Cache www.server.com finden kann , gibt er die IP-Adresse direkt zurück. Wenn nicht, fragt das lokale DNS seinen Root-Domain-Name-Server: „Boss, können Sie mir die IP-Adresse von www.server.com nennen ?“ Der Root-Domain-Name-Server ist die höchste Ebene, er wird nicht direkt für den Domain-Namen verwendet Auflösung, aber es kann eine Straße angeben.
Nachdem das Root-DNS die Anfrage vom lokalen DNS erhalten hat, stellt es fest, dass das Suffix .com ist, und sagt: „Der Domainname www.server.com wird vom .com-Bereich verwaltet“, ich gebe Ihnen die Adresse des Top-Level-Domain-Nameservers von .com, und Sie können danach fragen. "
Nachdem das lokale DNS die Adresse des Domänennamenservers der obersten Ebene erhalten hat, initiiert es eine Anfrage und fragt: "Zweites Kind, können Sie mir die IP-Adresse von www.server.com mitteilen ?"
Der Top-Level-Domain-Nameserver sagte: „Ich werde Ihnen die Adresse des autoritativen DNS-Servers geben, der für die Zone www.server.com verantwortlich ist , und Sie sollten in der Lage sein, ihn zu erfragen, wenn Sie danach fragen.“
Das lokale DNS wendet sich an den autoritativen DNS-Server: „Mein drittes Kind, welche IP entspricht www.server.com ?“ Der autoritative DNS-Server von server.com ist die ursprüngliche Quelle der Ergebnisse der Domänennamenauflösung. Warum heißt es Autorität? Es ist mein Domainname und ich habe das Sagen.
Der autoritative DNS-Server teilt dem lokalen DNS nach der Abfrage die zugehörige IP-Adresse XXXX mit.
Das lokale DNS gibt dann die IP-Adresse an den Client zurück, und der Client stellt eine Verbindung mit dem Ziel her.Gleichzeitig speichert das lokale DNS die IP-Adresse im Cache, sodass die nächste Auflösung desselben Domainnamens nicht ausreichen muss Iterative DNS-Abfrage.
Bisher haben wir den DNS-Auflösungsprozess abgeschlossen. Zusammenfassend wird der gesamte Prozess in ein Bild gezeichnet.
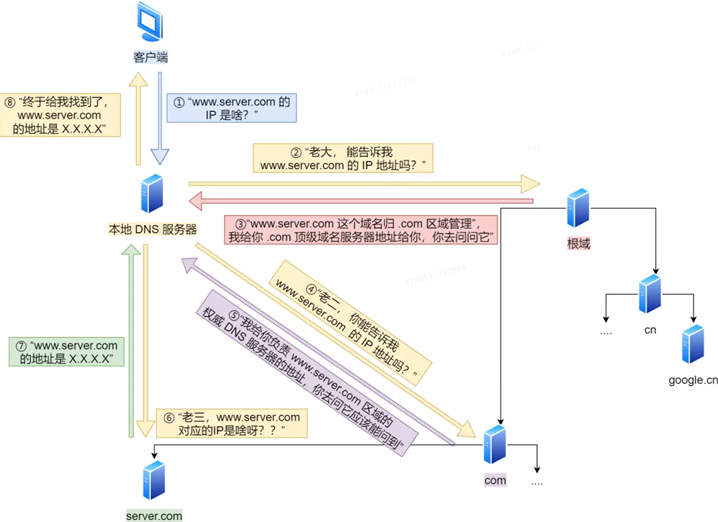
Der Prozess der Auflösung von DNS-Domainnamen ist recht interessant, der ganze Prozess ähnelt dem Prozess, jemanden zu finden, der in unserem täglichen Leben nach dem Weg fragt, nur den Weg zeigt, aber nicht den Weg weist .
3.3 Optimierung von vivo-Kurzvideos
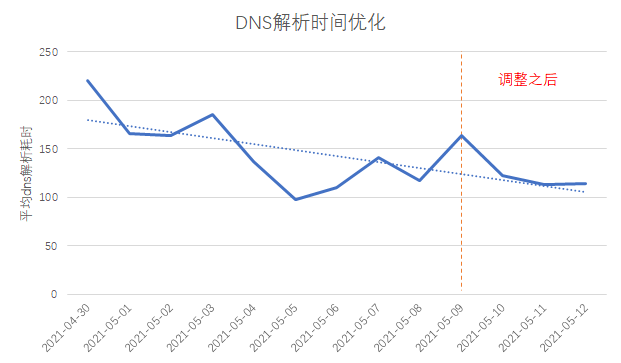
Klärte den Workflow der Domainnamenauflösung, verglich und analysierte den vivo-Domainnamen und den Domainnamen des Top-Herstellers und stellte fest, dass die zeitaufwändige und instabile Domainnamenauflösung von vivo-Kurzvideos eine große Schwankungsbreite aufweist Die Anzahl der Benutzer in einigen Bereichen ist gering, und die Cache-Trefferrate des lokalen DNS-Servers ist niedrig. Daher besteht unsere Optimierungsidee darin, die lokale DNS-Cache-Trefferrate zu verbessern .

Wie in der obigen Abbildung gezeigt, besteht eine einfache Möglichkeit zur Verbesserung der DNS-Cache-Trefferrate darin, eine landesweite DFÜ-Testaufgabe hinzuzufügen, um DNS-Heizung durchzuführen .
Durch den Vergleich der DNS-Auflösungszeit vor und nach der Anpassung ist ersichtlich, dass der Zeitverbrauch um ca. 30ms reduziert wurde.
4. HTTP-Leistung
Hier ist ein kurzer Vergleich der Leistung von HTTP/1, HTTP/2 und HTTP/3.
Das HTTP-Protokoll basiert auf TCP/IP und verwendet den „ Request-Response “-Kommunikationsmodus, daher liegt der Schlüssel zur Leistung in diesen beiden Punkten .
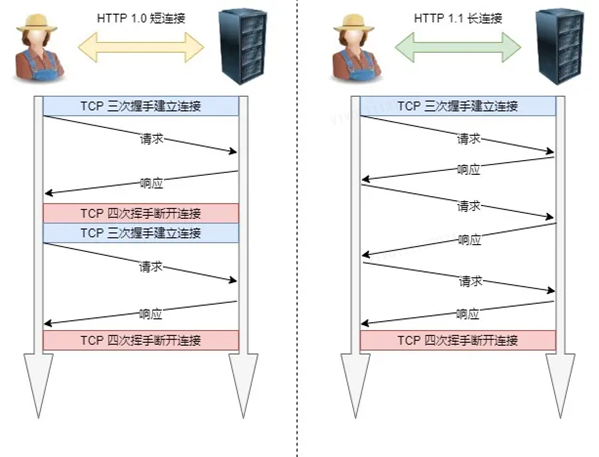
1. Lange Verbindung
Ein großes Problem bei der Leistung von frühem HTTP/1.0 besteht darin, dass jedes Mal, wenn eine Anfrage initiiert wird, eine neue TCP-Verbindung (Drei-Wege-Handshake) erstellt werden muss, und es sich um eine serielle Anfrage handelt, die den Aufbau und die Trennung von TCP-Verbindungen unnötig macht. was den Kommunikationsaufwand erhöht.
Um das obige TCP-Verbindungsproblem zu lösen, schlägt HTTP/1.1 eine Kommunikationsmethode mit langer Verbindung vor, die auch als dauerhafte Verbindung bezeichnet wird. Der Vorteil dieses Verfahrens liegt darin, dass es den zusätzlichen Overhead durch das wiederholte Auf- und Abbauen von TCP-Verbindungen reduziert und die Serverseite entlastet.
Das Merkmal einer dauerhaften Verbindung besteht darin, dass sie den TCP-Verbindungsstatus aufrechterhält, solange eines der beiden Enden nicht explizit die Trennung anfordert.
2. Pipeline-Netzwerkübertragung
HTTP/1.1 übernimmt die lange Verbindungsmethode, die die Übertragung über das Pipeline-Netzwerk ermöglicht.
Das heißt, der Client kann in derselben TCP-Verbindung mehrere Anfragen initiieren. Solange die erste Anfrage gesendet wird, kann die zweite Anfrage gesendet werden, ohne auf ihre Rückkehr zu warten, was die Gesamtantwortzeit verkürzen kann .
Beispielsweise muss ein Client zwei Ressourcen anfordern. Die vorherige Praxis bestand darin, zuerst eine A-Anfrage in derselben TCP-Verbindung zu senden, dann auf die Antwort des Servers zu warten und dann nach Erhalt eine B-Anfrage zu senden. Der Pipeline-Mechanismus ermöglicht es dem Browser, gleichzeitig eine A-Anforderung und eine B-Anforderung auszugeben.
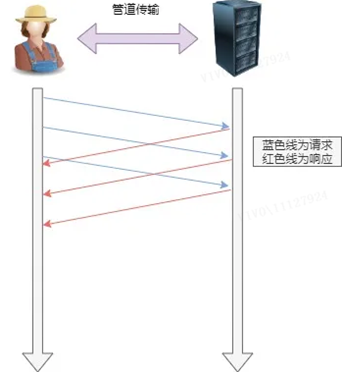
Der Server antwortet jedoch weiterhin der Reihe nach auf die A-Anforderung und antwortet dann nach Abschluss auf die B-Anforderung. Wenn die vorherige Antwort besonders langsam ist, stehen später viele Anfragen in der Schlange. Dies wird als "Leitungskopfblockierung" bezeichnet.
3. Head-of-Line-Blockierung
Das "Request-Response"-Modell verschlimmert HTTP-Performance-Probleme.
Denn wenn eine Anforderung in der sequenziell gesendeten Anforderungssequenz aus irgendeinem Grund blockiert wird, werden alle später in die Warteschlange gestellten Anforderungen ebenfalls zusammen blockiert, was dazu führt, dass der Client niemals Daten anfordert, was eine "Head-of-Line-Blockierung" ist . Es ist wie ein Stau auf dem Weg zur Arbeit.
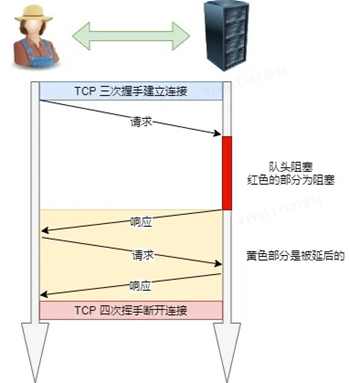
4.1 HTTP/1.1 Leistungsverbesserung im Vergleich zu HTTP/1.0:
Die Verwendung von langen TCP-Verbindungen verbessert den Leistungsaufwand, der durch kurze HTTP/1.0-Verbindungen verursacht wird.
Es unterstützt die Pipeline-Netzwerkübertragung.Solange die erste Anfrage gesendet wird, kann die zweite Anfrage gesendet werden,ohne auf ihre Rückkehr zu warten, was die Gesamtantwortzeit verkürzenkann.
Aber HTTP/1.1 hat immer noch Leistungsengpässe:
Der Anforderungs-/Antwort-Header (Header) wird ohne Komprimierung gesendet, und je mehr Header-Informationen, desto größer die Verzögerung. Nur der Body-Teil kann komprimiert werden;
Senden Sie lange Header. Jedes Mal denselben Header zu senden, verursacht mehr Abfall;
Der Server antwortet in der Reihenfolge der Anfragen.Wenn der Server langsam antwortet, kann der Client keine Daten anfordern, das heißt, derKopf der Warteschlange wird blockiert;
Keine Anforderungsprioritätssteuerung;
Anfragen können nur vom Client ausgehen, und der Server kann nur passiv antworten.
Für den Leistungsengpass von HTTP/1.1 oben hat HTTP/2 einige Optimierungen vorgenommen. Und da das HTTP/2-Protokoll auf HTTPS basiert, ist auch die Sicherheit von HTTP/2 gewährleistet.
4.2 HTTP/2-Leistungsverbesserung im Vergleich zu HTTP/1.1:
1. Kopfkompression
HTTP/2 komprimiert den Header (Header).Wenn Sie mehrere Anfragen gleichzeitig senden und ihre Header gleich oder ähnlich sind, hilft Ihnen das Protokoll, die doppelten Teile zu eliminieren .
Dies ist der sogenannte HPACK-Algorithmus: Pflegen Sie gleichzeitig eine Header-Informationstabelle auf Client und Server, alle Felder werden in dieser Tabelle gespeichert, eine Indexnummer wird generiert und das gleiche Feld wird nicht gesendet In Zukunft wird nur noch die Indexnummer gesendet, was die Geschwindigkeit erhöht .
2. Binäres Format
HTTP/2 ist keine reine Textnachricht mehr wie HTTP/1.1, sondern ein Binärformat wird vollständig übernommen .
Sowohl die Header-Informationen als auch der Datenkörper sind binär und werden gemeinsam als Frames bezeichnet: Header-Informationsframe und Datenframe .
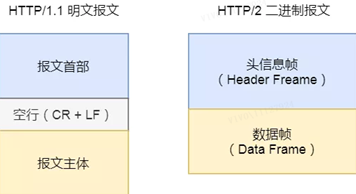
Dies ist zwar nicht menschenfreundlich, aber sehr computerfreundlich, da Computer nur binär verstehen, sodass nach dem Empfang der Nachricht die Klartextnachricht nicht in eine binäre konvertiert werden muss, sondern die binäre Nachricht direkt geparst wird, was die Datenübertragung erhöht Effizienz .
3. Datenfluss
HTTP/2-Datenpakete werden nicht der Reihe nach gesendet, und aufeinanderfolgende Datenpakete in derselben Verbindung können zu unterschiedlichen Antworten gehören. Daher muss das Paket markiert werden, um anzuzeigen, zu welcher Antwort es gehört.
Alle Datenpakete jeder Anfrage oder Antwort werden als Datenstrom (Stream) bezeichnet.
Jeder Datenstrom ist mit einer eindeutigen Nummer gekennzeichnet, die festlegt, dass die Anzahl der vom Client gesendeten Datenströme ungerade und die Anzahl der vom Server gesendeten Datenströme gerade ist.
Clients können auch die Priorität von Datenströmen festlegen . Bei Anfragen mit hoher Priorität antwortet der Server zuerst auf die Anfrage.
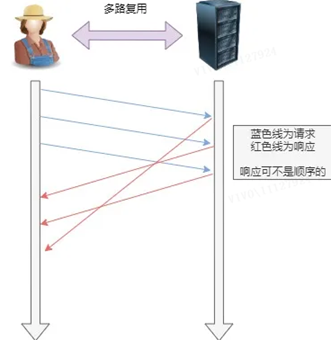
4. Multiplexing
HTTP/2 ermöglicht das gleichzeitige Senden mehrerer Anforderungen oder Antworten in einer Verbindung, anstatt einer Eins-zu-Eins-Korrespondenz nacheinander .
Die serielle Anfrage in HTTP/1.1 wird entfernt, das Warten in der Warteschlange entfällt, und das Problem des "Head of Line Blocking" tritt nicht mehr auf, was die Verzögerung verringert und die Auslastung der Verbindung erheblich verbessert .
Bei einer TCP-Verbindung erhält der Server beispielsweise zwei Anfragen von Client A und B. Wenn er feststellt, dass der Verarbeitungsprozess von A sehr zeitaufwändig ist, antwortet er auf den verarbeiteten Teil der Anfrage von A und antwortet dann auf die Anfrage von B .Nach Abschluss , und antworte dann auf den Rest von A's Anfrage.
5. Server-Push
HTTP/2 verbessert auch gewissermaßen die traditionelle „Request-Response“-Arbeitsweise: Der Dienst antwortet nicht mehr passiv, sondern kann auch aktiv Nachrichten an den Client senden.
Wenn der Browser beispielsweise nur HTML anfordert, sendet er aktiv statische Ressourcen wie JS- und CSS-Dateien, die im Voraus an den Client verwendet werden können, um Wartezeiten zu reduzieren , d. h. Server-Push (Server-Push, auch Cache-Push genannt).
4.3 Was sind also die Schwachstellen von HTTP/2? Welche Optimierungen hat HTTP/3 vorgenommen?
HTTP/2 verbessert die Leistung von HTTP/1.1 durch neue Funktionen wie Header-Komprimierung, Binärcodierung, Multiplexing und Server-Push erheblich, aber der Wermutstropfen ist, dass das HTTP/2-Protokoll basierend auf TCP implementiert wird, also gibt es das drei Mängel: individuell.
-
Verzögerung beim Handshake zwischen TCP und TLS;
-
Head-of-Line-Blockierung;
-
Die Netzwerkmigration erfordert eine erneute Verbindung.
1. Verzögerung beim Handshake zwischen TCP und TLS
Für die HTTP/1- und HTTP/2-Protokolle sind TCP und TLS geschichtet, die zur vom Kernel implementierten Transportschicht bzw. zur von der openssl-Bibliothek implementierten Präsentationsschicht gehören, sodass sie nur schwer zusammengeführt werden können und per Handshake ausgeführt werden müssen in Stapeln zuerst TCP-Handshake und dann TLS-Handshake.
Beim Initiieren einer HTTP-Anfrage muss sie den Prozess des TCP-Dreiwege-Handshakes und des TLS-Vierwege-Handshakes (TLS 1.2) durchlaufen, sodass insgesamt 3 RTT-Verzögerungen erforderlich sind, um die Anfragedaten zu senden.
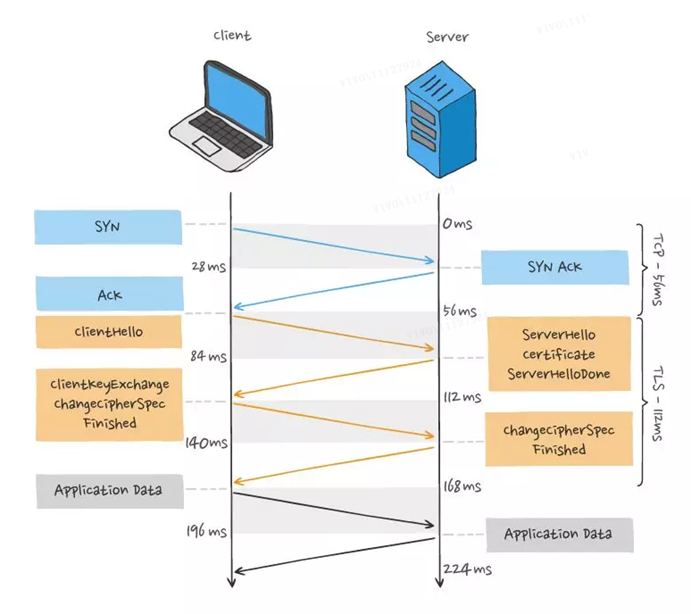
Da TCP außerdem die Eigenschaften der "Überlastungssteuerung" hat, wird das TCP, das gerade eine Verbindung aufgebaut hat, einen "langsamen Start"-Prozess haben, der eine "Verlangsamungs"-Wirkung auf die TCP-Verbindung haben wird.
2. Head-of-Line-Blockierung
HTTP/2 realisiert Stream-Parallelität, mehrere Streams müssen nur eine TCP-Verbindung multiplexen, sparen TCP- und TLS-Handshake-Zeit und reduzieren die Auswirkungen der langsamen TCP-Startphase auf den Datenverkehr. Es können nur unterschiedliche Stream-IDs gleichzeitig sein, selbst wenn Frames außerhalb der Reihenfolge gesendet werden, gibt es kein Problem, aber die Frames im selben Stream müssen in strikter Reihenfolge sein. Darüber hinaus kann die Priorität von Stream gemäß der Renderreihenfolge der Ressourcen festgelegt werden, wodurch die Benutzererfahrung verbessert wird.
HTTP/2 löst das Problem der Head-of-Line-Blockierung in HTTP/1 durch die Parallelitätsfähigkeit von Stream, die perfekt zu sein scheint, aber HTTP/2 hat immer noch das Problem der "Head-of-Line-Blockierung", aber die Das Problem liegt nicht auf HTTP-Ebene, sondern auf TCP-Ebene.
Mehrere HTTP/2-Anforderungen werden in einer TCP-Verbindung ausgeführt. Wenn also TCP-Pakete verloren gehen, muss das gesamte TCP auf die erneute Übertragung warten, und alle Anforderungen in der TCP-Verbindung werden blockiert.
Da TCP ein Byte-Stream-Protokoll ist, muss die TCP-Schicht sicherstellen, dass die empfangenen Byte-Daten vollständig und in Ordnung sind. Wenn das TCP-Segment mit einer niedrigeren Sequenznummer während der Netzwerkübertragung verloren geht, auch wenn das TCP-Segment mit einer höheren Sequenznummer dies hat Nach Erhalt kann die Anwendungsschicht diesen Teil der Daten nicht aus dem Kernel lesen, aus Sicht von HTTP wird die Anfrage blockiert.
Zum Beispiel wie unten gezeigt:
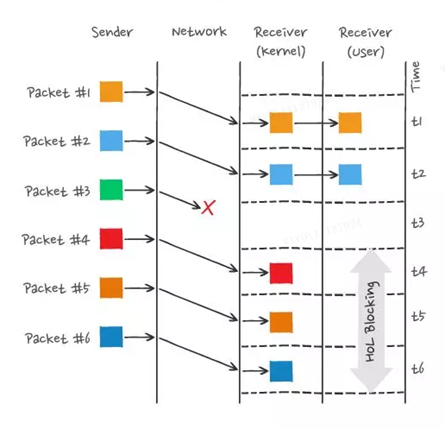
In der Abbildung hat der Absender viele Pakete gesendet, und jedes Paket hat seine eigene Sequenznummer, die als Sequenznummer von TCP betrachtet werden kann.Davon ging Paket 3 im Netzwerk verloren, selbst nachdem die Pakete 4-6 empfangen wurden der Empfänger, aufgrund des Kernels Die eingehenden TCP-Daten sind nicht kontinuierlich, daher kann die Anwendungsschicht des Empfängers sie nicht aus dem Kernel lesen.Erst nachdem Paket 3 erneut übertragen wurde, kann die Anwendungsschicht des Empfängers die Daten aus dem Kernel lesen.Dies ist HTTP/ 2 tritt das Head-of-Line-Blocking-Problem auf TCP-Ebene auf.
3. Die Netzwerkmigration erfordert eine erneute Verbindung
Eine TCP-Verbindung wird durch ein Vierer-Tupel bestimmt (Quell-IP-Adresse, Quellport, Ziel-IP-Adresse, Zielport), was bedeutet, dass eine Änderung der IP-Adresse oder des Ports zu einem erneuten Handshake zwischen TCP und TLS führt. Dies ist nicht förderlich für Szenarien, in denen mobile Geräte Netzwerke wechseln, wie z. B. das Wechseln von einer 4G-Netzwerkumgebung zu WIFI.
Diese Probleme sind dem TCP-Protokoll inhärent, und unabhängig davon, wie HTTP/2 auf der Anwendungsschicht konzipiert ist, können sie nicht entkommen.
Um dieses Problem zu lösen, ersetzte HTTP/3 das Transportschichtprotokoll von TCP zu UDP und entwickelte das QUIC-Protokoll auf dem UDP-Protokoll, um eine zuverlässige Datenübertragung zu gewährleisten.
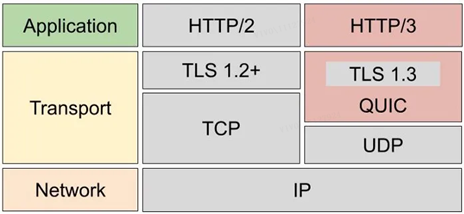
4.4 Merkmale des QUIC-Protokolls
Es gibt keine Head-of-Line-Blockierung , es gibt keine Abhängigkeit zwischen mehreren Streams auf der QUIC-Verbindung, sie sind alle unabhängig und es gibt keine zugrunde liegenden Protokolleinschränkungen. Paketverlust tritt in einem bestimmten Stream auf, nur dieser Stream ist betroffen , und andere Streams sind nicht betroffen ;
Der Verbindungsaufbau ist schnell , da QUIC TLS1.3 enthält, sodass nur 1 RTT benötigt wird, um den Verbindungsaufbau und die TLS-Schlüsselaushandlung "gleichzeitig" abzuschließen, und selbst bei der zweiten Verbindung kann das Anwendungsdatenpaket Informationen per Handshake verarbeiten QUIC (Verbindungsinformationen + TLS-Informationen) werden zusammen gesendet, um den Effekt von 0-RTT zu erzielen.
Verbindungsmigration Das QUIC-Protokoll verwendet kein Quadrupel, um die Verbindung zu „binden", sondern um die beiden Endpunkte der Kommunikation durch die Verbindungs-ID zu markieren. Der Client und der Server können jeweils einen Satz von IDs auswählen, um sich selbst zu markieren, also sogar Wechselt das mobile Endgerät nach dem Netz, ändert sich die IP-Adresse Solange die Kontextinformationen (wie Verbindungs-ID, TLS-Schlüssel etc.) noch erhalten bleiben, kann die ursprüngliche Verbindung "nahtlos" wiederverwendet werden, um die Kosten zu beseitigen Wiederverbindung.
Außerdem synchronisiert QPACK von HTTP/3 die dynamischen Tabellen beider Parteien durch zwei spezielle unidirektionale Streams, wodurch das Head-of-Queue-Blocking-Problem von HPACK von HTTP/2 gelöst wird.
Da QUIC jedoch das UDP-Übertragungsprotokoll verwendet, ist UDP ein „Bürger zweiter Klasse". Die meisten Router verwerfen UDP-Pakete, wenn das Netzwerk ausgelastet ist, und geben TCP-Paketen „Platz". Daher sollte die Förderung von QUIC nicht schwierig sein So einfach. Wir freuen uns auf den Tag, an dem HTTP/3 offiziell eingeführt wird !
4.5 Optimierung von vivo-Kurzvideos
Bei der Entwicklung von vivo Kurzvideo in verschiedenen Zeiträumen haben wir verschiedene Optimierungen vorgenommen:
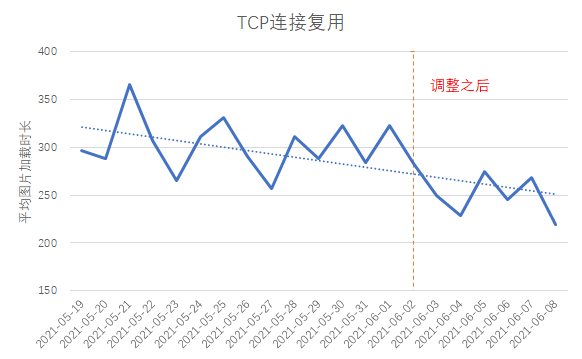
1. Verwenden Sie HTTP/1.1 : Der Client führt den Domänennamen des ersten Frame-Bildes und den Domänennamen des Kommentar-Avatars zusammen, die TCP-Link-Wiederverwendungsrate steigt um 4 % und die durchschnittliche Bildladezeit verringert sich um etwa 40 ms;
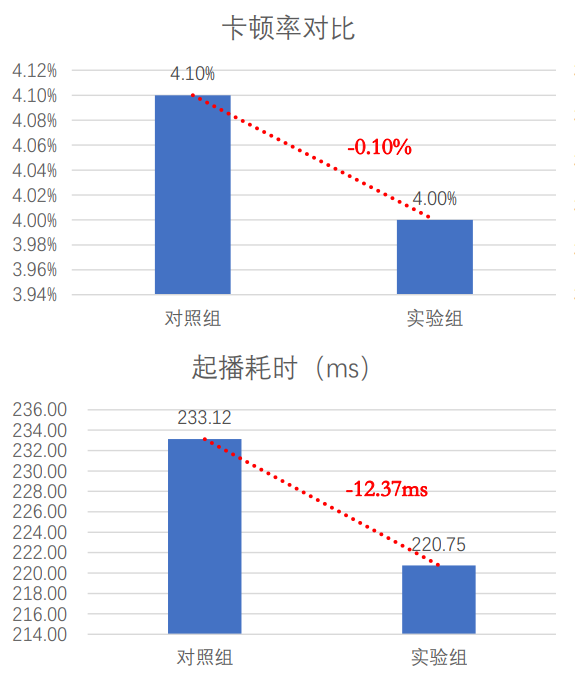
2. Verwenden Sie HTTP/2 : Der Client verwendet H2 in Graustufen für einige Domänennamen, und die Einfrierrate sinkt um 0,5 %
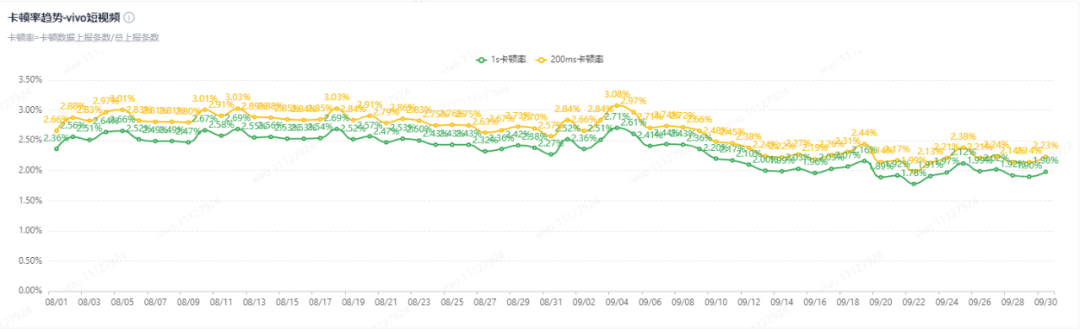
3. QUIC verwenden : Für schwache Netzwerkszenarien verwendet der Client vorrangig das QUIC-Protokoll, gleichzeitig optimiert er die Performance von QUIC gezielt für die Eigenschaften von Kurzvideodiensten.
5. CDN-Beschleunigung
Der vollständige Name von CDN lautet Content Delivery Network, der chinesische Name lautet „Content Distribution Network“ und löst das Problem des langsamen Netzwerkzugriffs aufgrund großer Entfernungen.
Einfach ausgedrückt verteilt CDN Inhaltsressourcen auf Server, die sich in Computerräumen an mehreren geografischen Standorten befinden, sodass wir beim Zugriff auf Inhaltsressourcen nicht den Quellserver besuchen müssen. Stattdessen greifen wir direkt auf den uns am nächsten gelegenen CDN-Knoten zu, was Zeitkosten für lange Anfahrtswege spart und so eine Netzwerkbeschleunigung erreicht.
Was CDN beschleunigt, ist, dass Inhaltsressourcen statische Ressourcen sind.
Die sogenannte „statische Ressource“ bedeutet, dass die Dateninhalte statisch und unverändert sind und der Zugriff jederzeit gleich ist, wie Bilder und Audio. Im Gegensatz dazu bedeutet "dynamische Ressourcen", dass sich die Dateninhalte dynamisch ändern und bei jedem Besuch anders sind, wie beispielsweise Benutzerinformationen. Sollen jedoch auch dynamische Ressourcen zwischengespeichert und beschleunigt werden, muss auf dynamisches CDN zurückgegriffen werden: Eine Möglichkeit besteht darin, die logische Berechnung der Daten auf den CDN-Knoten zu legen, was als Edge Computing bezeichnet wird.
Es gibt zwei Möglichkeiten der CDN-Beschleunigungsstrategie, nämlich „ Push-Modus “ und „ Pull-Modus “.
Die meisten CDN-Beschleunigungsstrategien verwenden den „Pull-Modus". Wenn die angeforderten Daten nicht im nächsten CDN-Knoten zwischengespeichert werden, auf den der Benutzer zugreift, lädt das CDN die Daten aktiv vom Quellserver herunter und aktualisiert sie im Cache des CDN-Knotens. Es ist ersichtlich, dass der Pull-Modus ein passives Caching-Verfahren ist und der entgegengesetzte "Push-Modus" ein aktives Caching-Verfahren ist. Wenn Sie Ressourcen auf CDN-Knoten zwischenspeichern möchten, bevor Benutzer darauf zugreifen, können Sie den „Push-Modus“ verwenden, der auch als CDN-Vorwärmung bezeichnet wird. Senden Sie über die vom CDN-Dienst bereitgestellte API-Schnittstelle Informationen wie die Adresse der Ressource, die vorgeheizt werden muss, und den Bereich, der vorgeheizt werden muss. Nachdem das CDN sie erhalten hat, werden die CDN-Knoten in diesen Bereichen ausgelöst zurück zur Quelle, um eine Ressourcenvorwärmung zu erreichen.
5.1 Wie finde ich den CDN-Knoten, der dem Benutzer am nächsten ist?
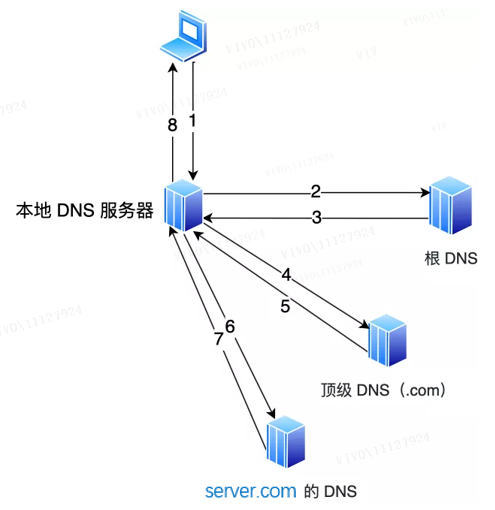
Die Suche nach dem nächstgelegenen CDN-Knoten zum Benutzer liegt in der Verantwortung des Global Load Balancer des CDN (Global Sever Load Balance, GSLB). Wann wirkt GSLB? Bevor wir diese Frage beantworten, werfen wir einen Blick darauf, was passiert, wenn auf einen Domainnamen ohne CDN zugegriffen wird. Wenn kein CDN vorhanden ist, gibt der DNS-Server beim Besuch eines Domainnamens schließlich die Adresse des Ursprungsservers zurück. Wenn wir beispielsweise den Domänennamen www.server.com in den Browser eingeben und den Domänennamen nicht in der lokalen Hostdatei finden, greift der Client auf den lokalen DNS-Server zu.
In diesem Moment:
-
Wenn der lokale DNS-Server die Adresse der Website zwischengespeichert hat, gibt er die Adresse der Website direkt zurück;
-
Wenn nicht, fordern Sie zuerst den Root- ; ) durch eine rekursive Abfrage an, und der Root-DNS gibt die Adresse des Top-Level-DNS (.com DNS IP-Adresse ab, die www.server.com entspricht, und geben Sie dann diese IP-Adresse zurück. Gleichzeitig speichert das lokale DNS die IP-Adresse im Cache, sodass die nächste Auflösung desselben Domänennamens keine iterative DNS-Abfrage durchführen muss .
Aber nach dem Beitritt zum CDN ist es anders.
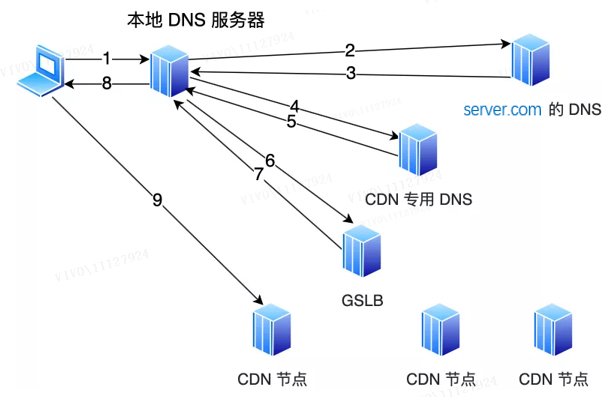
Auf dem DNS-Server server.com wird ein CNAME-Alias festgelegt , der auf einen anderen Domänennamen www.server.cdn.com verweist , und an den lokalen DNS-Server zurückgegeben. Fahren Sie dann mit der Auflösung des Domainnamens fort. Zu diesem Zeitpunkt ist server.cdn.com der DNS-Server, der dem CDN zugeordnet ist. Auf diesem Server wird ein CNAME so eingestellt, dass er auf einen anderen Domainnamen verweist. Diesmal verweist er auf die GSLB des CDN. Als nächstes fordert der lokale DNS-Server den Domainnamen des GSLB des CDN an und das GSLB wählt einen geeigneten CDN-Knoten aus, um Dienste für den Benutzer bereitzustellen.Die Auswahlgrundlage umfasst im Wesentlichen die folgenden Punkte:
-
Sehen Sie sich die IP-Adresse des Benutzers an, schlagen Sie in der Tabelle nach, um den geografischen Standort zu erfahren, und finden Sie den relativ nächstgelegenen CDN-Knoten.
-
Sehen Sie sich das Betreibernetzwerk an, in dem sich der Benutzer befindet, und finden Sie den CDN-Knoten desselben Netzwerks.
-
Sehen Sie sich die vom Benutzer angeforderte URL an, um festzustellen, auf welchem Server sich die vom Benutzer angeforderte Ressource befindet.
-
Fragen Sie den Laststatus von CDN-Knoten ab und finden Sie Knoten mit geringerer Last.
GSLB führt eine umfassende Analyse basierend auf den oben genannten Bedingungen durch, findet den am besten geeigneten CDN-Knoten heraus und gibt die IP-Adresse des CDN-Knotens an den lokalen DNS-Server zurück, und dann speichert der lokale DNS-Server die IP-Adresse und gibt die IP zurück an den Client , der Client greift auf diesen CDN-Knoten zu und lädt Ressourcen herunter.
5.2 Optimierung von vivo-Kurzvideos
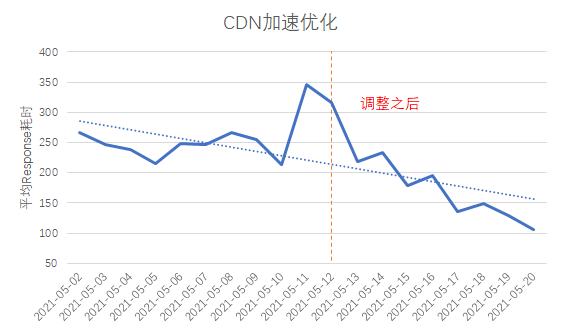
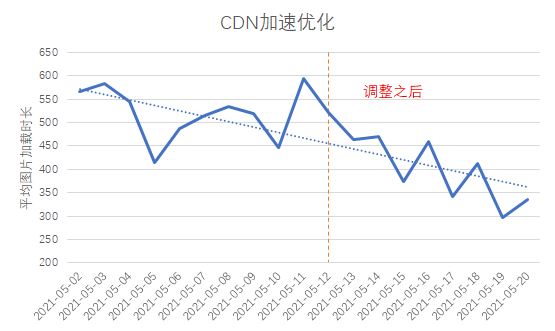
Nach unserer Analyse haben wir festgestellt, dass auf einige mit dem CDN verbundene Domainnamen in einigen Provinzen im ganzen Land nicht in der Nähe zugegriffen wird, und das Problem der überregionalen Abdeckung von CDN-Edge-Knoten ist relativ ernst. Daher haben wir den CDN-Hersteller gebeten, gezielte Anpassungen vorzunehmen: Nach der Anpassung wurde der durchschnittliche Request-Time-Verbrauch auf etwa 300 ms und der First-Packet-Time-Verbrauch ebenfalls auf über 100 ms reduziert.
6. Zusammenfassung und Ausblick
Mit der Entwicklung des Geschäfts wird die Verbesserung der Benutzererfahrung immer wichtiger. Die Optimierung der Benutzerzugriffserfahrung wird ein nie endender Prozess sein. Zusätzlich zu den oben genannten Methoden gibt es auch einige Optimierungen, die wir ausprobiert haben. Zum Beispiel:
-
Verbindungsoptimierung : Wenn Sie während der Videowiedergabe nach oben und unten gleiten, wird die Verbindung häufig getrennt, und die Verbindung kann nicht wiederverwendet werden.
-
Pre-Cache-Dateien : Verkürzen Sie die Startzeit.
-
Inhaltsoptimierung : Reduzieren Sie die Dateiübertragungsgröße.
Ich hoffe, dieser Artikel kann Ihnen helfen, die Benutzerzugriffserfahrung in Ihrer täglichen Arbeit zu optimieren.