Los modelos de transformadores son la base de los sistemas de IA. Ya hay innumerables diagramas de la estructura central de "cómo funciona Transformer".
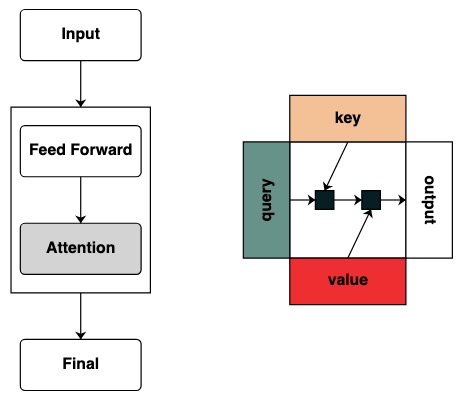
Pero estos diagramas no proporcionan ninguna representación intuitiva del marco para calcular este modelo. Cuando un investigador está interesado en cómo funciona un Transformador, se vuelve muy útil tener una intuición sobre cómo funciona.
En el artículo Thinking Like Transformers , se propone un marco informático de la clase transformer, que calcula e imita directamente los cálculos de Transformer. Utilizando el lenguaje de programación RASP , cada programa se compila en un Transformador especial.
En esta publicación de blog, reproduje una variante de RASP (RASPy) en Python. El lenguaje es más o menos el mismo que el original, pero con algunos cambios más que creo que son interesantes. Con estos lenguajes, el trabajo de la autora Gail Weiss ofrece un conjunto desafiante de formas interesantes y correctas para ayudar a comprender cómo funcionan.
!pip install git+https://github.com/srush/RASPy
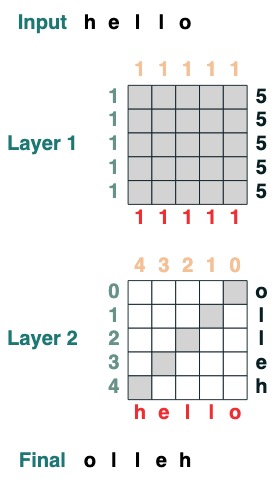
Antes de hablar sobre el lenguaje en sí, veamos un ejemplo de cómo se ve la codificación con Transformers. Aquí hay un código que calcula un giro, es decir, invierte la secuencia de entrada. El código en sí usa dos capas de Transformador para aplicar atención y cálculos matemáticos para llegar a este resultado.
def flip():
length = (key(1) == query(1)).value(1)
flip = (key(length - indices - 1) == query(indices)).value(tokens)
return flip
flip()
Directorio de artículos
- Parte 1: Transformadores como código
- Parte II: Escribiendo Programas con Transformadores
Transformadores como código
Nuestro objetivo es definir un conjunto de formas computacionales que minimicen la representación de los Transformadores. Describiremos cada construcción del lenguaje y su contraparte en Transformers por analogía. (Para conocer la especificación del idioma oficial, consulte el enlace al texto completo del documento al final de este artículo).
La unidad central del lenguaje es la operación de secuencia que transforma una secuencia en otra secuencia de la misma longitud. Los llamaré transformaciones más adelante.
ingresar
En un Transformador, la capa base es una entrada de alimentación hacia adelante para un modelo. Esta entrada generalmente contiene token sin procesar e información de ubicación.
En el código, las características de los tokens representan la transformación más simple, que devuelve los tokens después del modelo, y la secuencia de entrada predeterminada es "hola":
tokens

Si queremos cambiar la entrada en la transformación, usamos el método de entrada para pasar el valor.
tokens.input([5, 2, 4, 5, 2, 2])

Como Transformers, no podemos aceptar directamente las posiciones de estas secuencias. Pero para simular incrustaciones de ubicación, podemos obtener el índice de la ubicación:
indices

sop = indices
sop.input("goodbye")

red de realimentación
Después de pasar por la capa de entrada, llegamos a la capa de red feedforward. En Transformer, este paso aplica operaciones matemáticas de forma independiente a cada elemento de la secuencia.
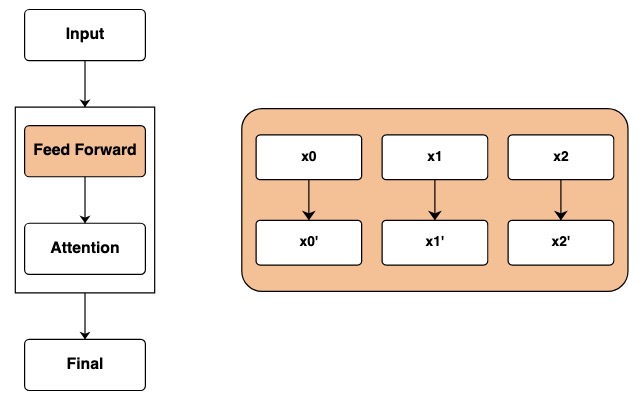
En el código, representamos este paso calculando sobre transformaciones. Se realizan operaciones matemáticas independientes en cada elemento de la secuencia.
tokens == "l"

El resultado es una nueva transformación que se calcula como refactorizada una vez que se reconstruye la nueva entrada:
model = tokens * 2 - 1
model.input([1, 2, 3, 5, 2])

Esta operación puede combinar múltiples Transforms. Por ejemplo, tome el token y los índices mencionados anteriormente como ejemplo, aquí puede clasificar Transformer para rastrear múltiples piezas de información:
model = tokens - 5 + indices
model.input([1, 2, 3, 5, 2])

(tokens == "l") | (indices == 1)

Proporcionamos algunas funciones auxiliares para facilitar la escritura de transformaciones, por ejemplo, wherepara proporcionar una estructura con ifuna funcionalidad .
where((tokens == "h") | (tokens == "l"), tokens, "q")

mapNos permite definir nuestras propias operaciones, como intconvertir . (Los usuarios deben tener cuidado con las operaciones calculadas por redes neuronales simples que se pueden usar)
atoi = tokens.map(lambda x: ord(x) - ord('0'))
atoi.input("31234")

Las funciones (funciones) pueden describir fácilmente la cascada de estas transformaciones. Por ejemplo, la siguiente es la operación donde se aplica y atoi y se suma 2
def atoi(seq=tokens):
return seq.map(lambda x: ord(x) - ord('0'))
op = (atoi(where(tokens == "-", "0", tokens)) + 2)
op.input("02-13")

filtro de atención
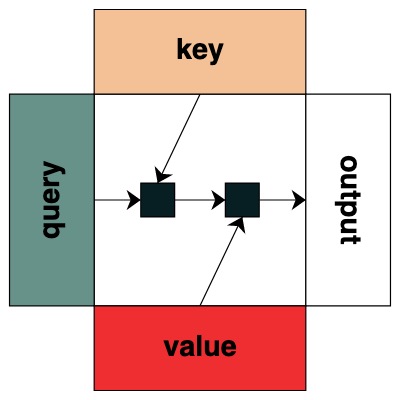
Las cosas empiezan a ponerse interesantes cuando empiezas a aplicar el mecanismo de atención. Esto permitirá el intercambio de información entre los diferentes elementos de la secuencia.
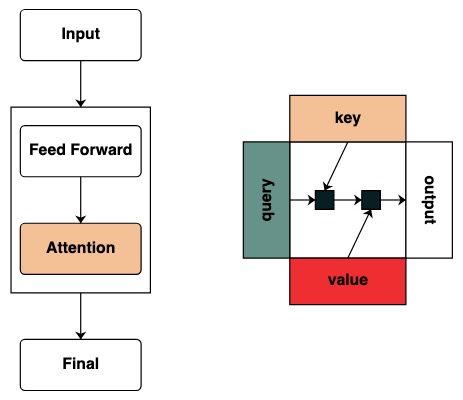
Comenzamos a definir el concepto de clave y consulta. Las claves y las consultas se pueden crear directamente a partir de las transformaciones anteriores. Por ejemplo, si queremos definir una clave, la llamamos key.
key(tokens)

querylo mismo para
query(tokens)

Los escalares keyse queryusar como o , y se transmiten a la longitud de la secuencia subyacente.
query(1)

Creamos filtros para aplicar operaciones entre clave y consulta. Esto corresponde a una matriz binaria que indica a qué clave se refiere cada consulta. A diferencia de Transformers, no se agregan pesos a esta matriz de atención.
eq = (key(tokens) == query(tokens))
eq
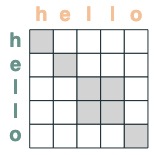
Algunos ejemplos:
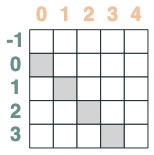
- La posición de coincidencia del selector se compensa en 1:
offset = (key(indices) == query(indices - 1))
offset
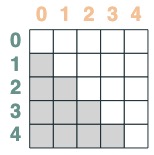
- Un selector cuya clave es anterior a la consulta:
before = key(indices) < query(indices)
before
- Un selector cuya clave es posterior a la consulta:
after = key(indices) > query(indices)
after
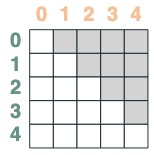
Los selectores se pueden combinar mediante operaciones booleanas. Por ejemplo, este selector combina before y eq, y lo mostramos al incluir un par de clave y valor en la matriz.
before & eq
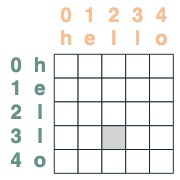
utilizar el mecanismo de atención
Dado un selector de atención, podemos proporcionar una secuencia de valores para la agregación. Agregamos acumulando los valores de verdad seleccionados por esos selectores.
(Nota: en el documento original, usan una operación de agregación promedio y muestran una estructura inteligente en la que la agregación promedio puede representar el cálculo de la suma. RASPy usa la acumulación de forma predeterminada para mantenerlo simple y evitar la fragmentación. De hecho, esto significa que raspy puede subestimar el número de capas necesarias. Los modelos basados en promedio pueden necesitar el doble de este número de capas)
Tenga en cuenta que las operaciones de agregación nos permiten calcular características como histogramas.
(key(tokens) == query(tokens)).value(1)
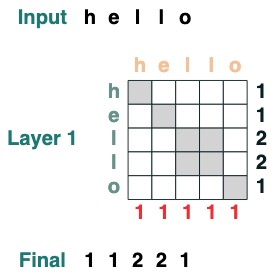
Visualmente seguimos la estructura del gráfico con Consulta a la izquierda, Clave arriba, Valor abajo y salida a la derecha.
Algunas operaciones del mecanismo de atención ni siquiera requieren un token de entrada. Por ejemplo, para calcular la longitud de la secuencia, creamos un filtro de atención "seleccionar todo" y le asignamos un valor.
length = (key(1) == query(1)).value(1)
length = length.name("length")
length
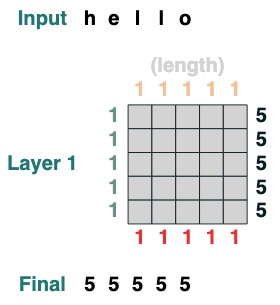
Aquí hay ejemplos más complejos, que se muestran paso a paso a continuación. (Es como hacer una entrevista)
Queremos calcular la suma de los valores adyacentes de una secuencia, primero truncamos hacia adelante:
WINDOW=3
s1 = (key(indices) >= query(indices - WINDOW + 1))
s1
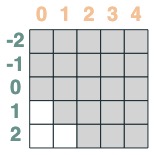
Luego truncamos hacia atrás:
s2 = (key(indices) <= query(indices))
s2
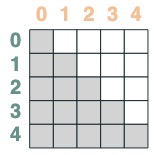
Ambos se cruzan:
sel = s1 & s2
sel
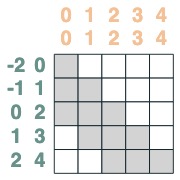
Agregación final:
sum2 = sel.value(tokens)
sum2.input([1,3,2,2,2])
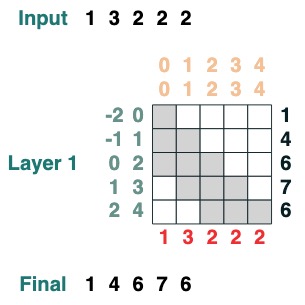
Aquí hay un ejemplo que puede calcular la suma acumulada Aquí presentamos la capacidad de nombrar la transformación para ayudarlo a depurar.
def cumsum(seq=tokens):
x = (before | (key(indices) == query(indices))).value(seq)
return x.name("cumsum")
cumsum().input([3, 1, -2, 3, 1])
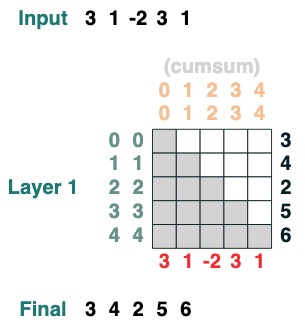
capa
El lenguaje admite la compilación de transformaciones más complejas. También calcula capas haciendo un seguimiento de cada operación.
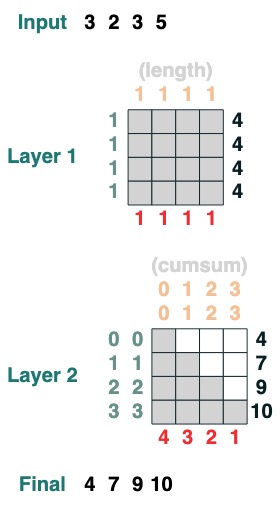
Aquí hay un ejemplo de una transformación de 2 capas, la primera correspondiente al cálculo de la longitud y la segunda correspondiente a la suma acumulativa.
x = cumsum(length - indices)
x.input([3, 2, 3, 5])
Programación con transformadores
Con esta biblioteca, podemos escribir una tarea compleja. Gail Weiss me hizo una pregunta extremadamente desafiante para desglosar este paso: ¿Podemos cargar un transformador que sume números de cualquier longitud?
Por ejemplo: Dada una cadena "19492+23919", ¿podemos cargar la salida correcta?
Si desea probarlo usted mismo, ofrecemos una versión puede probar usted mismo.
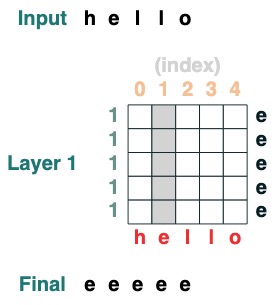
Desafío 1: Elija un índice dado
carga una secuencia con todos los elementos ien el
def index(i, seq=tokens):
x = (key(indices) == query(i)).value(seq)
return x.name("index")
index(1)
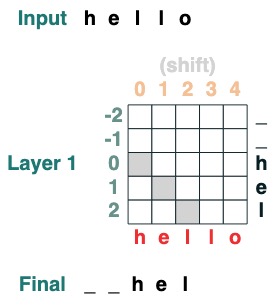
Desafío dos: conversión
Mueva todas las fichas a la derecha por iposición .
def shift(i=1, default="_", seq=tokens):
x = (key(indices) == query(indices-i)).value(seq, default)
return x.name("shift")
shift(2)
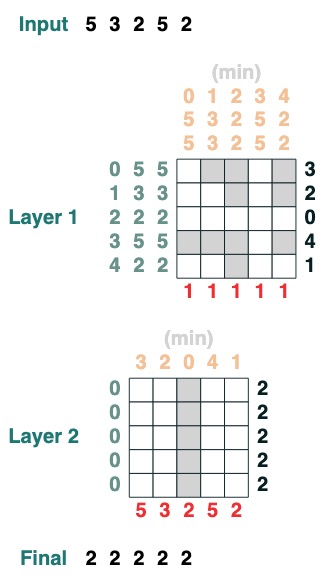
Desafío tres: Minimizar
Calcula el valor mínimo de una secuencia. (Este paso se vuelve difícil, nuestra versión usa un mecanismo de atención de 2 capas)
def minimum(seq=tokens):
sel1 = before & (key(seq) == query(seq))
sel2 = key(seq) < query(seq)
less = (sel1 | sel2).value(1)
x = (key(less) == query(0)).value(seq)
return x.name("min")
minimum()([5,3,2,5,2])
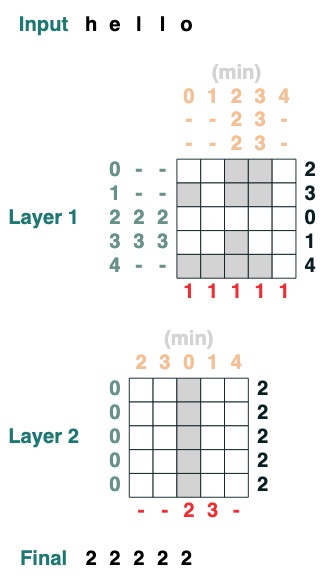
Desafío cuatro: primer índice
Calcular el primer índice con token q (2 capas)
def first(q, seq=tokens):
return minimum(where(seq == q, indices, 99))
first("l")
Desafío cinco: alineación correcta
Alinea a la derecha una secuencia de relleno. Ejemplo: " ralign().inputs('xyz___') ='—xyz'" (2 capas)
def ralign(default="-", sop=tokens):
c = (key(sop) == query("_")).value(1)
x = (key(indices + c) == query(indices)).value(sop, default)
return x.name("ralign")
ralign()("xyz__")
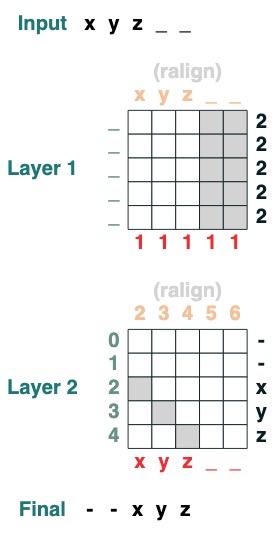
Desafío Seis: Separación
Divida una secuencia en dos partes en el token "v" y alinee a la derecha (2 capas):
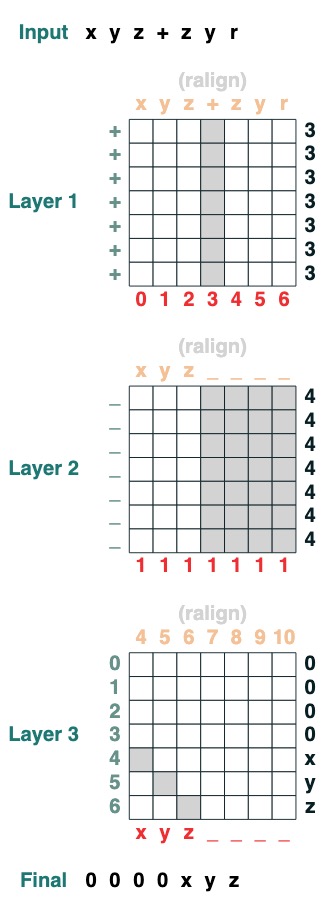
def split(v, i, sop=tokens):
mid = (key(sop) == query(v)).value(indices)
if i == 0:
x = ralign("0", where(indices < mid, sop, "_"))
return x
else:
x = where(indices > mid, sop, "0")
return x
split("+", 1)("xyz+zyr")
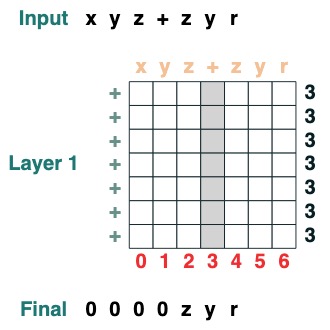
split("+", 0)("xyz+zyr")
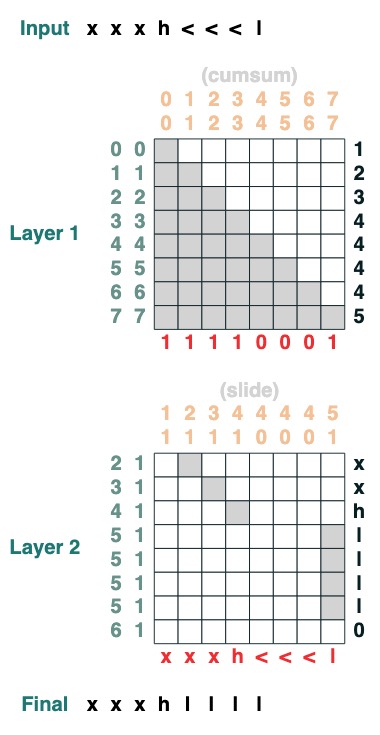
Desafío siete: deslizar
Reemplace el token especial "<" con el valor "<" más cercano (2 niveles):
def slide(match, seq=tokens):
x = cumsum(match)
y = ((key(x) == query(x + 1)) & (key(match) == query(True))).value(seq)
seq = where(match, seq, y)
return seq.name("slide")
slide(tokens != "<").input("xxxh<<<l")
Desafío Ocho: Aumentar
Quiere realizar la suma de dos números. Aquí están los pasos.
add().input("683+345")
- Divida en dos partes. Convertir a plástico. participar
“683+345” => [0, 0, 0, 9, 12, 8]
- Calcular la cláusula de acarreo. Tres posibilidades: 1 lleva, 0 no lleva, < quizás lleva.
[0, 0, 0, 9, 12, 8] => “00<100”
- Coeficiente de acarreo deslizante
“00<100” => 001100"
- adición completa
Estos son 1 línea de código. El sistema completo son 6 mecanismos de atención. (¡Aunque Gail dice que puedes hacerlo en 5 si eres lo suficientemente cuidadoso!).
def add(sop=tokens):
# 0) Parse and add
x = atoi(split("+", 0, sop)) + atoi(split("+", 1, sop))
# 1) Check for carries
carry = shift(-1, "0", where(x > 9, "1", where(x == 9, "<", "0")))
# 2) In parallel, slide carries to their column
carries = atoi(slide(carry != "<", carry))
# 3) Add in carries.
return (x + carries) % 10
add()("683+345")
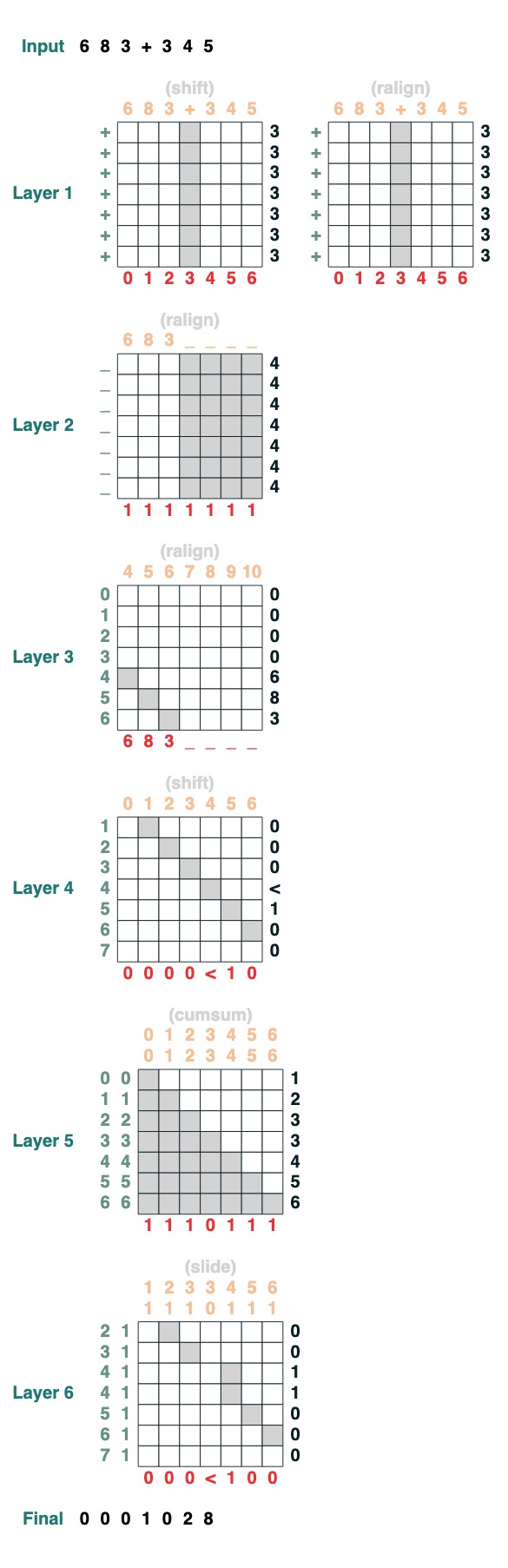
683 + 345
1028
¡Hecho perfectamente!
Referencias y enlaces en el texto:
- Si te interesa este tema y quieres saber más, consulta el paper: Thinking Like Transformers
- y aprenda más sobre el lenguaje RASP
- Si está interesado en "Lenguajes formales y redes neuronales" (FLaNN) o conoce a alguien que esté interesado, ¡bienvenido a invitarlo a unirse a nuestra comunidad en línea !
- Esta publicación de blog contiene el contenido de la biblioteca, el cuaderno y la publicación de blog.
- Esta publicación de blog fue escrita por Sasha Rush y Gail Weiss
<hr>
Texto original en inglés: Thinking Like Transformers
Traductor: innovación64 (Li Yang)