
1. Visión general de Durid
Apache Druid es una plataforma de datos analíticos que integra las características de una base de datos de series temporales, un almacén de datos y un sistema de recuperación de texto completo. Este artículo lo llevará a una breve comprensión de las características, los escenarios de uso, las características técnicas y la arquitectura de Druid. Esto lo ayudará a elegir soluciones de almacenamiento de datos, obtener información sobre el almacenamiento de Druid, obtener información sobre el almacenamiento de series temporales y más.
Apache Druid es una base de datos analítica en tiempo real de alto rendimiento.
1.1 Por qué usar
1.1.1 Base de datos nativa en la nube
Una moderna base de datos analítica, nativa de la nube y nativa de la transmisión
Druid está diseñado para flujos de trabajo rápidos de consulta e ingesta de datos. Druid destaca por tener una interfaz de usuario potente, consultas operativas en tiempo de ejecución y procesamiento simultáneo de alto rendimiento. Druid puede verse como una alternativa de código abierto a los almacenes de datos que satisface diversos escenarios de usuarios.
1.1.2 Fácil integración
Integre fácilmente con canalizaciones de datos existentes
Druid puede transmitir datos desde un bus de mensajes (como Kafka, Amazon Kinesis) o cargar archivos por lotes desde un lago de datos (como HDFS, Amazon S3 y otras fuentes de datos similares).
1.1.3 Ultra alto rendimiento
Rendimiento 100 veces más rápido que las soluciones tradicionales
-
Las pruebas comparativas de rendimiento de Druid para la ingestión de datos y la consulta de datos superan con creces a las soluciones tradicionales.
-
La arquitectura de Druid incorpora las mejores funciones de almacenes de datos, bases de datos de series temporales y sistemas de recuperación.
1.1.4 Flujo de trabajo
Desbloquee nuevos flujos de trabajo
Druid desbloquea nuevos métodos de consulta y flujos de trabajo para Clickstream, APM (sistema de gestión de rendimiento de aplicaciones), cadena de suministro (cadena de suministro), telemetría de red, marketing digital y otras formas de escenarios basados en eventos. Druid está diseñado para consultas ad hoc rápidas de datos históricos y en tiempo real.
1.1.5 Múltiples métodos de implementación
Se puede implementar en AWS/GCP/Azure, nube híbrida, k8s y servidores alquilados
Druid se puede implementar en cualquier entorno Linux, ya sea en las instalaciones o en la nube. Implementar Druid es muy fácil: aumente o disminuya agregando o eliminando servicios.
1.2 Escenarios de uso
Apache Druid es adecuado para escenarios con altos requisitos de extracción de datos en tiempo real, consultas de alto rendimiento y alta disponibilidad. Por lo tanto, Druid se usa a menudo como un sistema analítico con una GUI enriquecida, o como back-end para una API altamente concurrente que requiere una agregación rápida. Druid es más adecuado para datos orientados a eventos.
1.2.1 Escenarios de uso común
Escenarios de uso más comunes
1.2.1.1 Actividades y comportamiento del usuario
Druid se usa a menudo en datos de flujo de clics, flujo de acceso y flujo de actividad. Los escenarios específicos incluyen: medir la participación del usuario, rastrear datos de prueba A/B para lanzamientos de productos y comprender cómo los usan los usuarios. Druid puede realizar cálculos precisos y aproximados de las métricas de los usuarios, como las métricas de conteo único. Esto significa que las métricas, como los usuarios activos diarios, pueden aproximarse en un segundo (con una precisión promedio del 98 %) para ver tendencias generales o calcularse con precisión para presentarlas a las partes interesadas. Druid se puede usar para hacer "análisis de embudo" para medir cuántos usuarios toman una acción y no otra. Esto es útil para el seguimiento de registros de usuarios de productos.
1.2.1.2 Flujo de red
Druid se usa a menudo para recopilar y analizar datos de flujo de red. Druid se utiliza para administrar la división de datos de transmisión y combinarlos con atributos arbitrarios. Druid es capaz de extraer una gran cantidad de registros de flujo de red y puede combinar y ordenar rápidamente docenas de atributos en el momento de la consulta, lo que facilita el análisis de flujo de red. Estos atributos incluyen algunos atributos básicos, como IP y número de puerto, pero también algunos atributos mejorados adicionales, como ubicación geográfica, servicio, aplicación, dispositivo y ASN. Druid puede manejar esquemas no fijos, lo que significa que puede agregar las propiedades que desee.
1.2.1.3 Mercadotecnia Digital
Druid se usa a menudo para almacenar y consultar datos de publicidad en línea. Estos datos, generalmente de proveedores de servicios publicitarios, son fundamentales para medir y comprender el rendimiento de la campaña publicitaria, la tasa de clics, la tasa de conversión (tasa de consumo) y otras métricas.
Druid se diseñó originalmente como una potente aplicación de análisis orientada al usuario para datos publicitarios. En términos de almacenamiento de datos publicitarios, Druid ya tiene una gran cantidad de prácticas de producción y una gran cantidad de usuarios en todo el mundo han almacenado datos a nivel de PB en miles de servidores.
1.2.1.4 Gestión del rendimiento de la aplicación
Druid se utiliza a menudo para realizar un seguimiento de los datos operativos generados por las aplicaciones. De manera similar a los escenarios de uso de la actividad del usuario, estos datos pueden ser sobre cómo el usuario interactúa con la aplicación y pueden ser los datos del indicador informados por la propia aplicación. Druid se puede utilizar para profundizar y ver el rendimiento de los diferentes componentes de una aplicación, localizar cuellos de botella y encontrar problemas.
A diferencia de muchas soluciones tradicionales, Druid tiene las características de menor capacidad de almacenamiento, menor complejidad y mayor rendimiento de datos. Puede analizar rápidamente eventos de aplicaciones con miles de atributos y calcular métricas complejas de carga, rendimiento y utilización. Por ejemplo, puntos finales de API basados en una latencia de consulta del 95 %. Podemos organizar y segmentar datos por cualquier atributo temporal, como datos por día, como estadísticas por retrato de usuario, como estadísticas por ubicación del centro de datos.
1.2.1.5 IoT y métricas de dispositivos
Driud se puede utilizar como una solución de base de datos de series temporales para almacenar datos de métricas para servidores y dispositivos de procesamiento. Recopile datos generados por máquinas en tiempo real para realizar análisis ad hoc rápidos para medir el rendimiento, optimizar los recursos de hardware y localizar problemas.
A diferencia de muchas bases de datos de series temporales tradicionales, Druid es esencialmente un motor de análisis. Druid combina los conceptos de bases de datos de series temporales, bases de datos de análisis en columnas y sistemas de recuperación. Admite la partición basada en el tiempo, el almacenamiento en columnas y los índices de búsqueda en un solo sistema. Esto significa que las consultas basadas en el tiempo, las agregaciones numéricas y las consultas de filtros de recuperación son extremadamente rápidas.
Puede incluir millones de valores de dimensión únicos en sus métricas y combinar grupos y filtrar por cualquier dimensión a voluntad (la dimensión de dimensión en Druid es similar a la etiqueta en la base de datos de series temporales). Puede calcular una gran cantidad de métricas complejas basadas en grupos de etiquetas y clasificaciones. Y puede buscar y filtrar etiquetas más rápido que las bases de datos de series temporales tradicionales.
1.2.1.6 OLAP e inteligencia empresarial
Druid se usa a menudo en escenarios de inteligencia comercial. Las empresas implementan Druid para acelerar las consultas y mejorar las aplicaciones. A diferencia de los motores SQL basados en Hadoop (como Presto o Hive), Druid está diseñado para consultas de alta simultaneidad y en segundos, lo que mejora las consultas de datos interactivas a través de la interfaz de usuario. Esto hace que Druid sea más adecuado para el análisis de interacción visual real.
1.2.2 Escenarios adecuados
Druid es una muy buena opción si tu escenario de uso cumple con las siguientes características:
- Los datos se insertan con más frecuencia, pero los datos se actualizan con menos frecuencia
- La mayoría de los escenarios de consulta son consultas de agregación y consultas de agrupación (GroupBy), y también hay ciertas consultas de recuperación y exploración.
- Latencia de consulta de datos objetivo entre 100 ms y unos pocos segundos
- Los datos tienen atributos de tiempo (Druid está optimizado y diseñado para el tiempo)
- En un escenario de varias tablas, cada consulta solo llega a una tabla distribuida grande y la consulta puede llegar a varias tablas de búsqueda más pequeñas.
- Los escenarios contienen columnas de datos dimensionales de alta cardinalidad (por ejemplo, URL, ID de usuario, etc.) que deben contarse y clasificarse rápidamente
- Necesita cargar datos de Kafka, HDFS, almacenamiento de objetos como Amazon S3
1.2.3 Escenarios inadecuados
Usar Druid puede ser una mala elección si su caso de uso cumple con las siguientes características:
- Operaciones de actualización de baja latencia en datos existentes basadas en claves principales. Druid admite la transmisión de inserciones, pero no la transmisión de actualizaciones (las operaciones de actualización se realizan a través de trabajos por lotes en segundo plano)
- Sistemas de datos fuera de línea donde la latencia no es crítica
- Los escenarios incluyen uniones grandes (unir una tabla de hechos grande a otra tabla de hechos grande) y es aceptable tomar mucho tiempo para completar estas consultas.
2. ¿Qué es Durid?
Apache Druid es un motor de almacenamiento de datos distribuidos de código abierto.
El diseño central de Druid incorpora los conceptos de OLAP/bases de datos analíticas, bases de datos de series temporales y sistemas de búsqueda para crear un sistema unificado aplicable a una amplia gama de casos de uso. Druid integra las funciones principales de estos tres sistemas en la capa de ingestión de Druid (capa de ingestión de datos), el formato de almacenamiento (capa de formato de almacenamiento), la capa de consulta (capa de consulta) y la arquitectura central (arquitectura central).
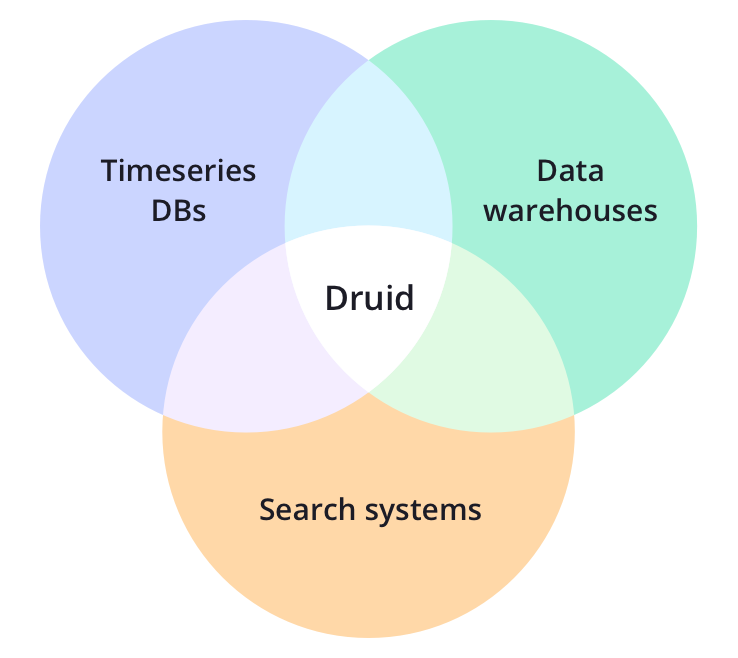
2.1 Características principales
2.1.1 Almacenamiento en columnas
Druid almacena y comprime cada columna de datos por separado. Y solo los datos específicos que deben consultarse se consultan al consultar, y se admiten escaneo rápido, clasificación y agrupación.
2.2.2 Índice de búsqueda nativo
Druid crea un índice invertido para valores de cadena para lograr una búsqueda y filtrado de datos rápidos.
2.2.3 Transmisión de datos por lotes e ingesta
Apache kafka, HDFS, conectores AWS S3, procesadores de flujo listos para usar.
2.2.4 Esquema de datos flexible
Druid se adapta con gracia a esquemas de datos cambiantes y tipos de datos anidados.
2.2.5 Particionamiento optimizado basado en el tiempo
Druid divide los datos de forma inteligente en función del tiempo. Como resultado, las consultas basadas en el tiempo de Druid serán significativamente más rápidas que las bases de datos tradicionales.
2.2.6 Declaración de soporte SQL
Además de las consultas nativas basadas en JSON, Druid también es compatible con HTTP y SQL basado en JDBC.
2.2.7 Escalabilidad horizontal
Tasa de ingesta de datos de millones/segundo, almacenamiento masivo de datos, consulta de subsegundos.
2.2.8 Facilidad de operación y mantenimiento
Puede expandirse y reducirse agregando o eliminando servidores. Druid admite el reequilibrio automático y la conmutación por error.
2.3 Selección técnica
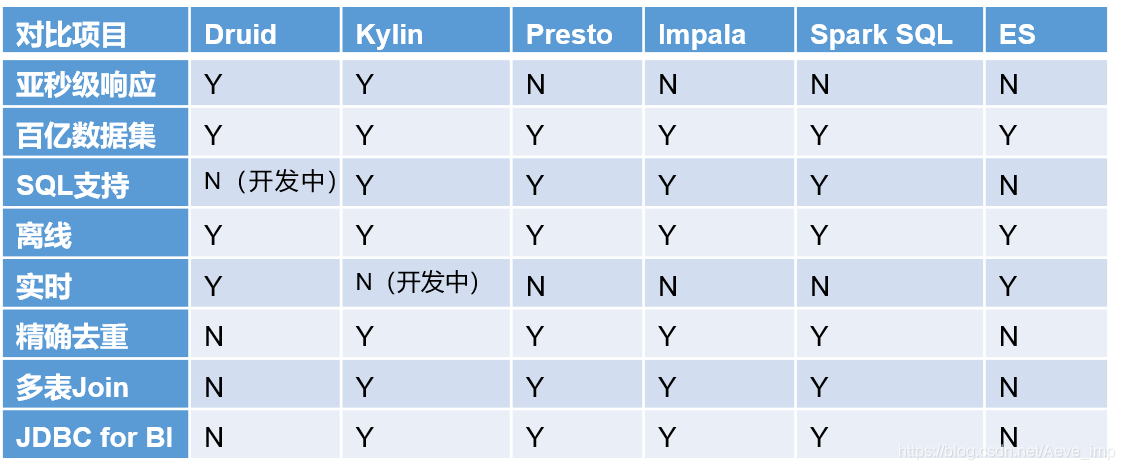
Comparación de tecnología
druida
es una base de datos OLAP que procesa datos de series temporales en tiempo real, su índice primero se segmenta según el tiempo, y la consulta también se enruta según la línea de tiempo.
Kylin
El núcleo es Cube. Cube es una tecnología de precomputación que realiza una indexación multidimensional de los datos por adelantado. Al consultar, solo se escanea el índice sin acceder a los datos originales para acelerar.
Pronto
No utiliza MapReduce y es un orden de magnitud más rápido que Hive en la mayoría de los escenarios. La clave es que todo el procesamiento se realiza en la memoria.
Impala
Basado en operaciones en memoria, es rápido y no admite tantas fuentes de datos como Presto.
Chispa SQL
Basado en un marco OLAP en la plataforma Spark, la idea básica es agregar máquinas para realizar cómputo paralelo, mejorando así la velocidad de consulta.
ES
La característica más importante es que el índice invertido se utiliza para resolver el problema del índice. Según la investigación, ES utiliza más recursos para la adquisición y agregación de datos que Druid.
Selección de cuadro
- De la eficiencia de consultas de grandes datos: Druid > Kylin > Presto > Spark SQL
- En términos de fuentes de datos compatibles: Presto > Spark SQL > Kylin > Druid
2.4 Ingestión de datos
Druid admite la transferencia de datos por secuencias y por lotes. Druid generalmente se conecta a fuentes de datos sin procesar a través de un bus de mensajes como Kafka (para cargar datos de transmisión) o a través de un sistema de archivos distribuido como HDFS (para cargar datos masivos).
Druid almacena datos sin procesar en nodos de datos en forma de segmentos a través del procesamiento de indexación. El segmento es una estructura de datos optimizada para consultas.
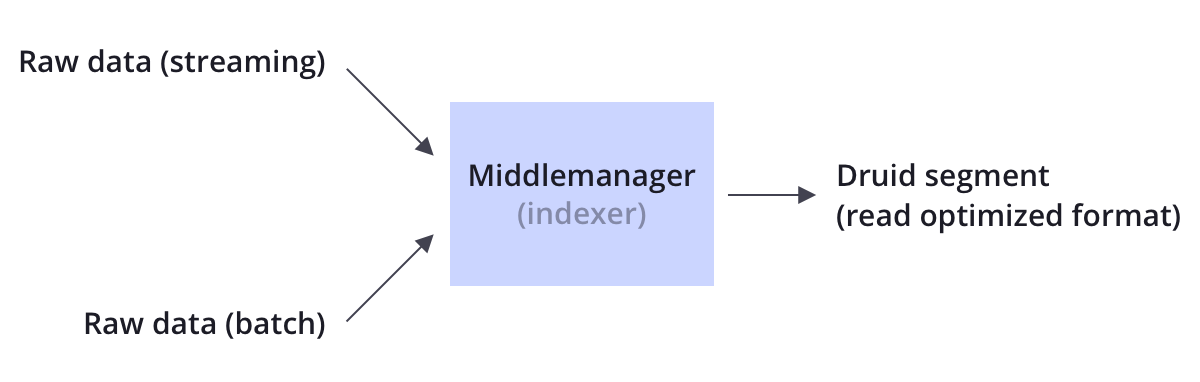
2.5 Almacenamiento de datos
Como la mayoría de las bases de datos analíticas, Druid utiliza almacenamiento en columnas. Según el tipo de datos (cadena, número, etc.) de las diferentes columnas, Druid utiliza diferentes métodos de compresión y codificación para ellas. Druid también crea diferentes tipos de índices para diferentes tipos de columnas.
Similar al sistema de recuperación, Druid crea un índice invertido para la columna de cadena para lograr una búsqueda y filtrado más rápidos. De forma similar a las bases de datos de series temporales, Druid divide de forma inteligente los datos en función del tiempo para consultas basadas en el tiempo más rápidas.
A diferencia de la mayoría de los sistemas tradicionales, Druid puede preagregar datos antes de ingerirlos. Esta operación de agregación previa se denomina resumen y puede ahorrar costos de almacenamiento significativos.
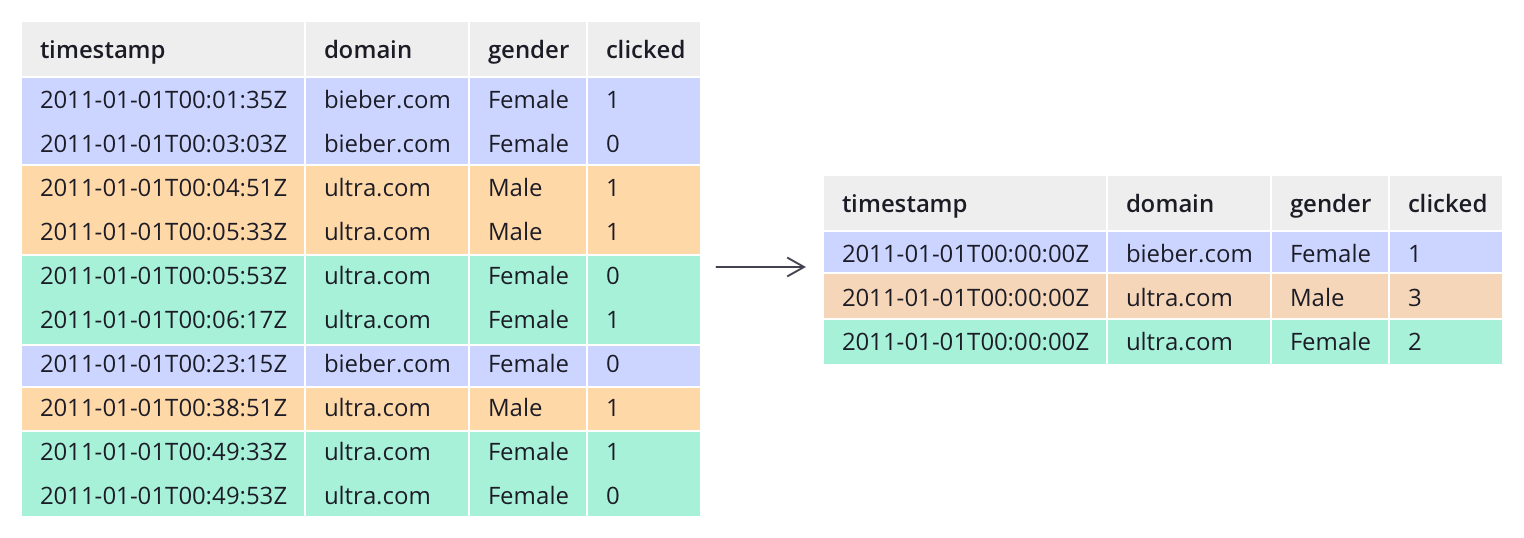
2.6 Consulta
Druid admite métodos de consulta JSON sobre HTTP y SQL. Además de las operaciones estándar de SQL, Druid también admite una gran cantidad de operaciones únicas, y el conjunto de algoritmos proporcionado por Druid puede realizar rápidamente cálculos de conteo, clasificación y cuantiles.
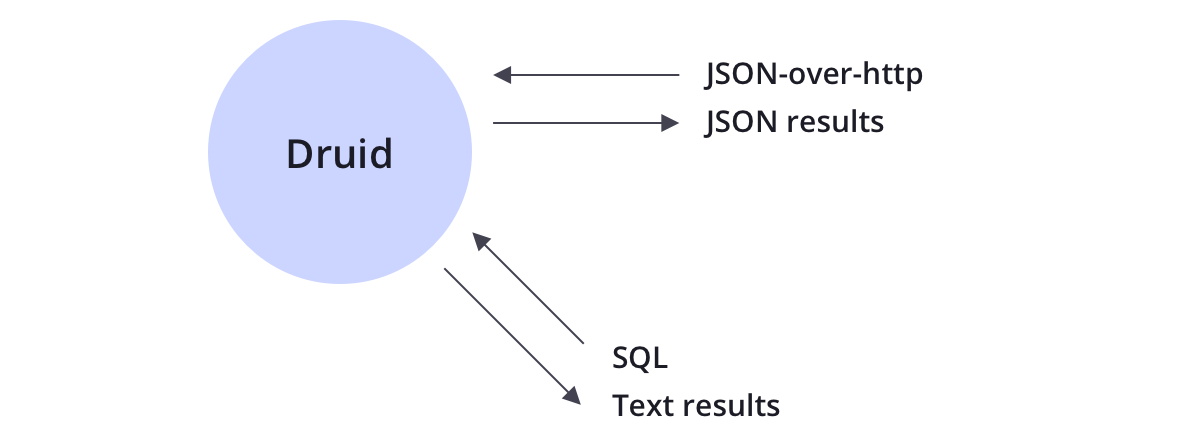
Drui está diseñado para ser un sistema robusto y debe funcionar las 24 horas del día, los 7 días de la semana.
Druid tiene las siguientes funciones para garantizar un funcionamiento a largo plazo y garantizar que no se pierdan datos.
2.6.1 Copia de datos
Druid crea múltiples copias de datos de acuerdo con la cantidad de copias configuradas, por lo que la falla de una sola máquina no afectará la consulta de Druid.
2.6.2 Servicios Independientes
Druid nombra claramente cada servicio principal, y cada servicio se puede ajustar en consecuencia según el uso. Los servicios pueden fallar de forma independiente sin afectar el funcionamiento normal de otros servicios. Por ejemplo, si falla el servicio de ingesta de datos, no se cargarán nuevos datos en el sistema, pero aún se pueden consultar los datos existentes.
2.6.3 Copia de seguridad automática de datos
Druid realiza una copia de seguridad automática de todos los datos indexados en un sistema de archivos, que puede ser un sistema de archivos distribuido como HDFS. Puede perder todos los datos del clúster de Druid y volver a cargar rápidamente desde los datos de copia de seguridad.
2.6.4 Actualización continua
Con actualizaciones continuas, puede actualizar su clúster de Druid sin tiempo de inactividad, que es independiente del usuario. Todas las versiones de Druid son compatibles con versiones anteriores.
3. Instalación y despliegue
3.1 Introducción al entorno
3.1.1 Lista de puertos de Durid
La siguiente es la lista de puertos predeterminados de Durid para evitar que el servidor no se inicie debido a la ocupación del puerto
| Role | Puerto | introducir |
|---|---|---|
| Coordinador | 8081 | Administrar la disponibilidad de datos en el clúster |
| Histórico | 8083 | Almacenar datos consultados históricamente |
| Corredor | 8082 | Manejo de solicitudes de consulta de clientes externos |
| Tiempo real | 8084 | |
| Señor | 8090 | Controle la distribución de las cargas de trabajo de ingesta de datos |
| Gerente de nivel medio | 8091 | Responsable de la ingesta de datos. |
| enrutador | 8888 | Puede enrutar solicitudes a corredores, coordinadores y jefes supremos |
3.2 Método de instalación
Hay varias formas de obtener el paquete de instalación de Druid
3.2.1 Compilación del código fuente
druid /release se usa principalmente para requisitos personalizados, como combinar las dependencias circundantes en el entorno real o agregar optimizaciones que admitan consultas específicas.
3.2.2 Descargar desde el sitio web oficial
Descarga del paquete de instalación del sitio web oficial: descarga , incluidos los componentes más básicos para la implementación y el funcionamiento de Druid
3.2.3 Kit combinado implícito
Implica , esta suite incluye una versión estable de los componentes Druid, servicios de soporte de escritura de datos en tiempo real, componentes de soporte de consulta SQL y interfaz de usuario web de visualización gráfica, etc. El propósito es crear productos de aplicación de análisis de datos basados en Druid rápido despliegue.
3.3 Referencia de configuración independiente
3.3.1 Inicio rápido nano
1 CPU, 4 GB de RAM
- Comando de inicio:
bin/start-nano-quickstart - Directorio de configuración:
conf/druid/single-server/nano-quickstart
3.3.2 Inicio rápido micro
4 CPU, 16 GB de RAM
- Comando de inicio:
bin/start-micro-quickstart - Directorio de configuración:
conf/druid/single-server/micro-quickstart
3.3.3 Pequeño
8 CPU, 64 GB de RAM (~i3.2xgrande)
- Comando de inicio:
bin/start-small - Directorio de configuración:
conf/druid/single-server/small
3.3.4 Medio
16 CPU, 128 GB de RAM (~i3.4xgrande)
- Comando de inicio:
bin/start-medium - Directorio de configuración:
conf/druid/single-server/medium
3.3.5 Grande
32 CPU, 256 GB de RAM (~i3.8xgrande)
- Comando de inicio:
bin/start-large - Directorio de configuración:
conf/druid/single-server/large
3.3.6 Muy grande
64 CPU, 512 GB de RAM (~i3.16xgrande)
- Comando de inicio:
bin/start-xlarge - Directorio de configuración:
conf/druid/single-server/xlarge
3.4 Instalación de la versión independiente
3.4.1 Requisitos de software
- Java 8 (8u92+)
- Linux, Mac OS X u otro sistema operativo similar a Unix (Windows no es compatible)
- Instalar el entorno Docker
- Instalar el entorno de Docker-compose
3.4.2 Requisitos de hardware
Druid incluye varios ejemplos de configuraciones de un solo servicio, así como scripts para iniciar procesos de Druid con esas configuraciones.
Si está ejecutando en una máquina pequeña como una computadora portátil para una evaluación rápida, la configuración de micro-inicio rápido es una buena opción para un entorno de 4 CPU/16 GB de RAM. Si planea usar una implementación de una sola máquina para una evaluación adicional fuera del tutorial, le recomendamos que use una configuración más grande que micro-inicio rápido.
Si bien se proporcionan configuraciones de ejemplo para máquinas individuales grandes, a escalas más altas recomendamos ejecutar Druid en una implementación en clúster para tolerancia a fallas y reducción de la contención de recursos.
3.5 implica instalación
Se recomienda instalar el método Imply El método Imply proporciona componentes de druida, así como funciones como gráficos e informes.
3.5.1 Instalar perl
Debido a que el entorno perl debe usarse para iniciar druid, debe instalarse
yum install perl gcc kernel-devel
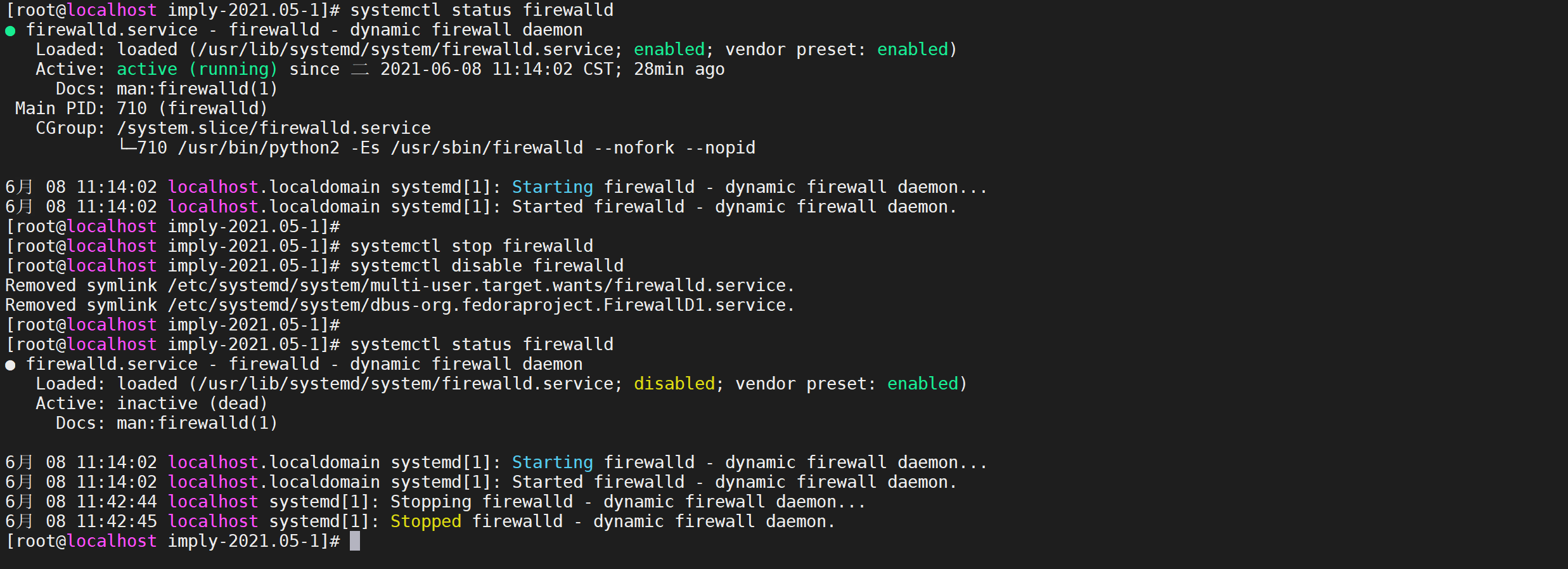
3.5.2 Desactivar el cortafuegos
#查看防火状态
systemctl status firewalld
#暂时关闭防火墙
systemctl stop firewalld
#永久关闭防火墙
systemctl disable firewalld
3.5.3 Instalar JDK
Elige la versión que se adapte a tu sistema, la mía es Centos7 de 64 bits, así que si fuera yo elegiría esta versión, recuerda que si la descargas termina en tar.gz.
3.5.3.1 Descargar JDK
Vaya al sitio web oficial de Oracle para descargar jdk1.8 , seleccione
jdk-8u301-linux-x64.tar.gz
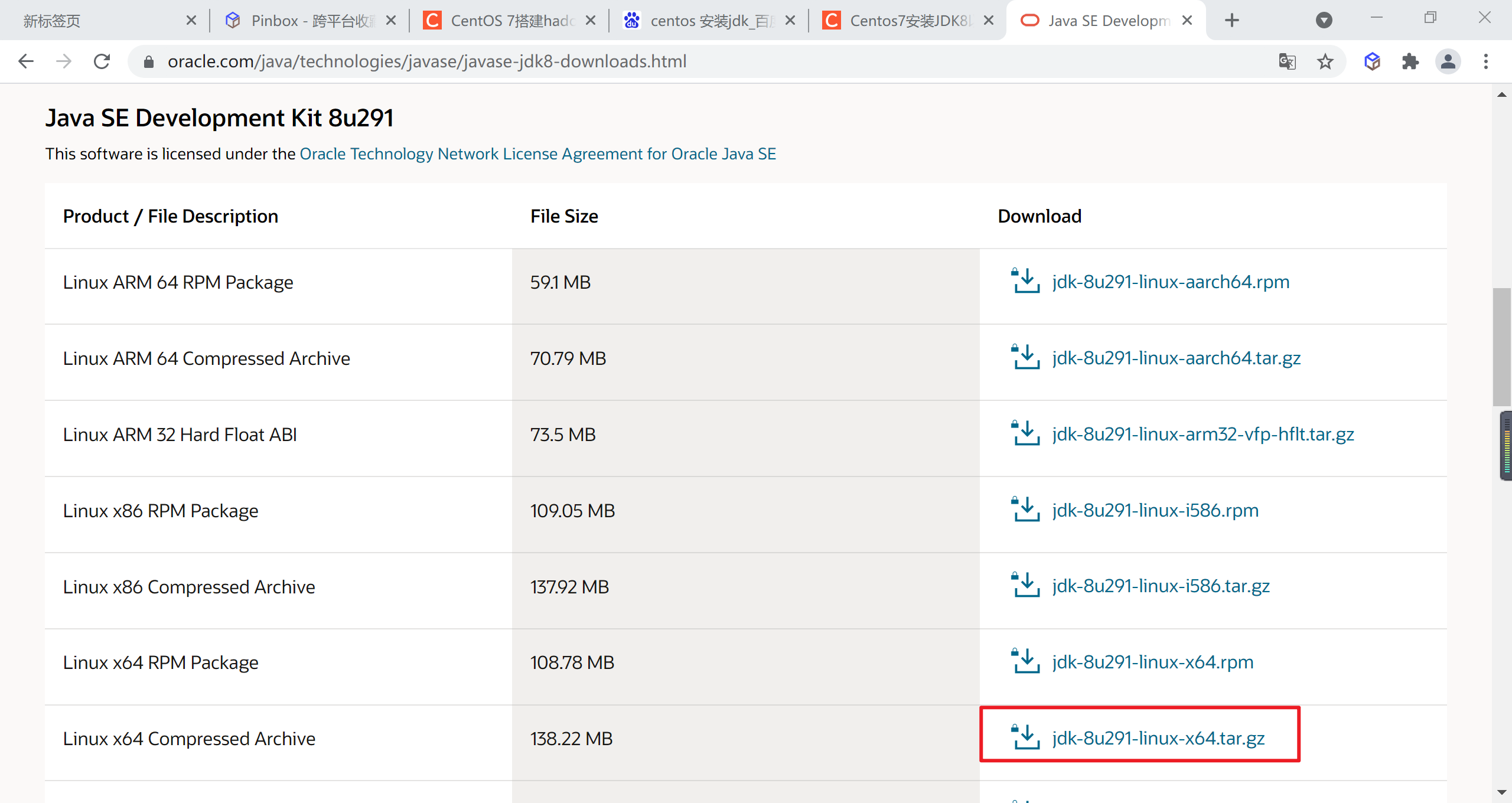
Descargue el archivo localmente y cárguelo en el directorio de Linux
3.5.3.2 Subir y descomprimir
subir archivos
mkdir /usr/local/java
descomprimir directorio
tar -zxvf jdk-8u301-linux-x64.tar.gz
3.5.3.3 Configuración de variables de entorno
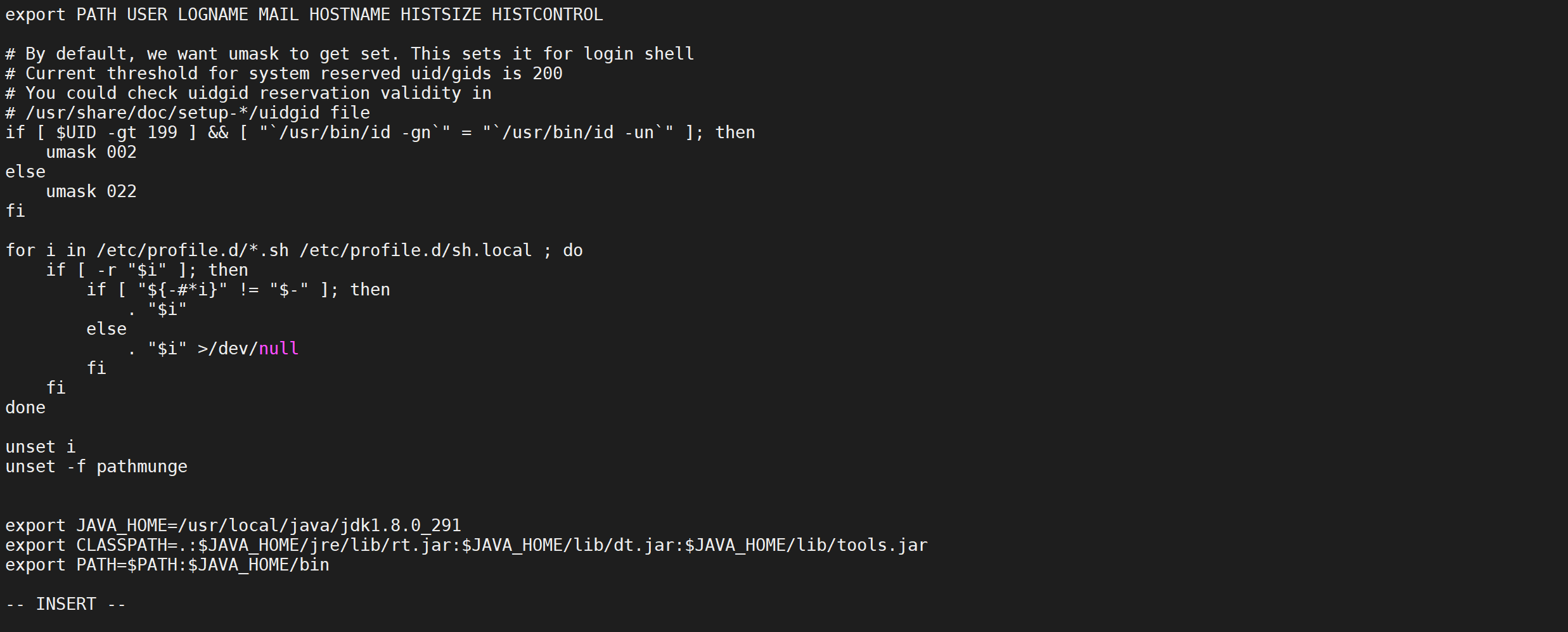
Configure las variables de entorno, modifique el archivo de perfil y agregue el siguiente contenido
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_301
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3.5.3.4 Configuración efectiva
source /etc/profile
3.5.3.5 Comprobar el entorno
java -version

3.5.4 Instalar implica
3.5.4.1 Iniciar sesión en el sitio web oficial de Imply
Visite https://imply.io/get-started , ingrese al sitio web oficial de Imply, busque el paquete de instalación de la versión adecuada de imply y complete la breve información para descargar
3.5.4.2 Descomprimir implica
Después de descargarlo, súbelo al servidor y descomprímelo
# 创建imply安装目录
mkdir /usr/local/imply
# 解压imply
tar -zxvf imply-2021.05-1.tar.gz
3.5.4.3 Preparación Ambiental
Después de entrar en el
imply-2021.05-1directorio
# 进入imply目录
cd imply-2021.05-1
3.5.4.4 Inicio rápido
Use almacenamiento local, derby de almacenamiento de metadatos predeterminado y comience con zookeeper para experimentar
druid
# 创建日志目录
mkdir logs
# 使用命令启动
nohup bin/supervise -c conf/supervise/quickstart.conf > logs/quickstart.log 2>&1 &
3.5.4.5 Ver registro
quickstart.logVer el registro de inicio impl por
tail -f logs/quickstart.log
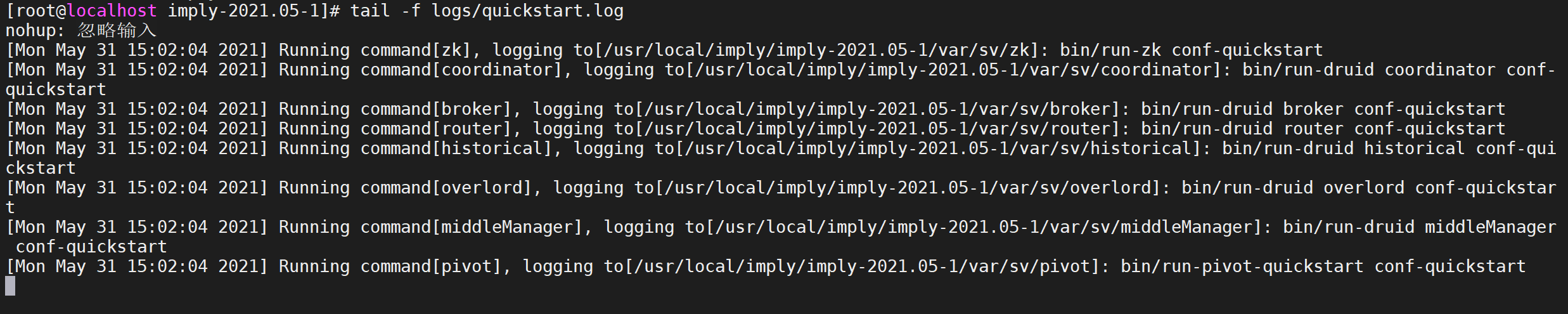
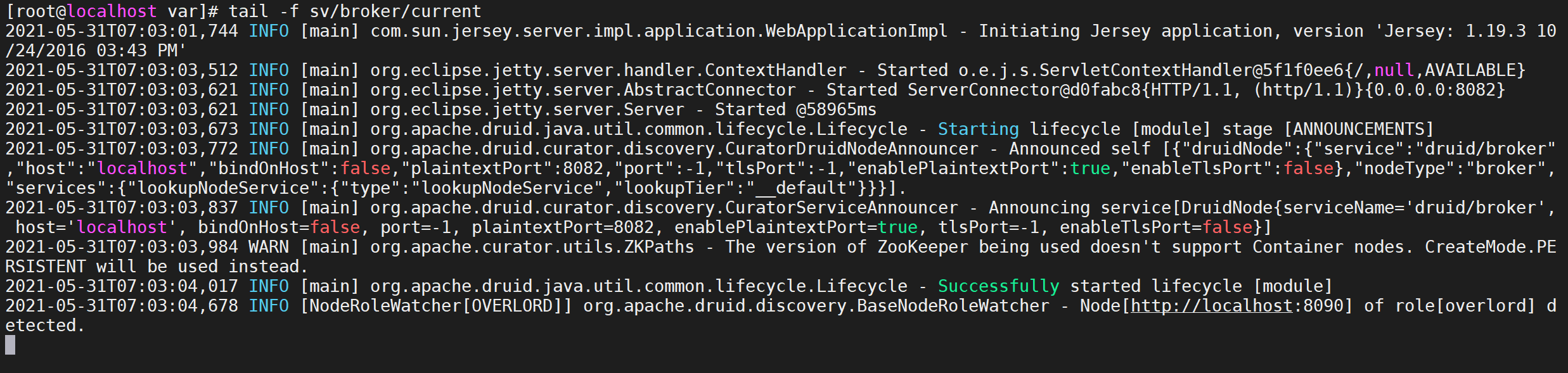
Cada vez que se inicia un servicio, se imprime un registro. Puede ver la información de registro cuando se inicia el servicio a través de var/sv/xxx/current
tail -f var/sv/broker/current
3.5.4.6 Acceso a Imply
Página de administración a la que se puede acceder visitando el
9095puertoimply
http://192.168.64.173:9095/

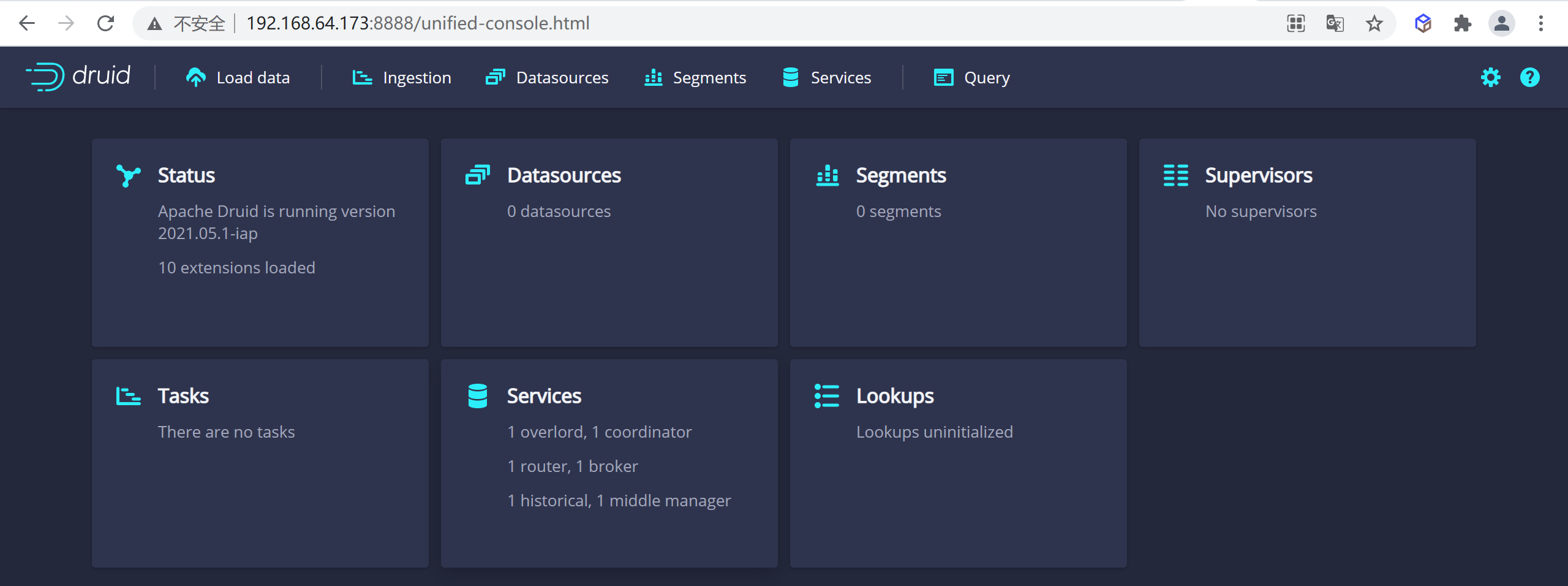
3.5.4.7 Acceso al druida
Accede
8888al puerto para acceder adruidnuestro
http://192.168.64.173:8888/
Este artículo fue publicado por el arquitecto salvaje de Yubo Xuegu. Si este artículo te es útil, síguelo y dale me gusta. Si tienes alguna sugerencia, también puedes dejar un comentario o una carta privada. Tu apoyo es la fuerza motriz para mí. para persistir en la creación. ¡Por favor indique la fuente!