[Proyecto de ciencia de datos 1]: cree su primer proyecto de ciencia de datos

Introducción
Todos hemos escuchado una palabra de moda: "ciencia de datos" . La mayoría de nosotros no sabemos mucho sobre "¿qué es? ¿Puedo ser analista de datos o científico de datos? ¿Qué habilidades necesito?" Por ejemplo: quiero comenzar un proyecto de ciencia de datos, pero no sé cómo hacerlo. La mayoría de
nosotros aprendimos sobre el campo a través de algunos cursos en línea. Nos sentimos cómodos con las tareas y proyectos dados en el curso. Sin embargo, cuando comenzamos a analizar conjuntos de datos completamente nuevos o desconocidos, nos perdemos. analizar nuestro Con cualquier conjunto de datos y problemas con los que nos encontremos, debemos practicar constantemente. Creo que una de las mejores maneras es aprender en proyectos . Entonces, todos deben comenzar su primer proyecto. Así que voy a escribir una columna para llevar a todos a completar proyectos de ciencia de datos . Los amigos interesados pueden comunicarse y completar juntos. Se espera que haya no menos de 50 artículos. Esta columna es una columna práctica.
Entonces, ¿cómo hacemos para construir un proyecto de ciencia de datos?
Para tener éxito en un proyecto de ciencia de datos, debemos comprender su proceso y optimizarlo para garantizar que los resultados sean confiables y que el proyecto sea fácil de rastrear, mantener y modificar cuando sea necesario. Por lo tanto, la forma mejor y más rápida es usar una plantilla canónica para construir el proyecto. Aquí resumo un proceso relativamente estandarizado, como se muestra a continuación.
- Paso 1: recopilar datos
- Paso 2: elija un IDE adecuado
- Paso 3: Enumere las actividades que se realizarán en el conjunto de datos
- Paso 4: Resumen del proyecto
- Paso 5: Comparte tu proyecto en una plataforma de código abierto
1. Adquisición de datos
El proceso de entrenar un algoritmo de aprendizaje automático es un poco como enseñar a los niños pequeños el nombre de un objeto por primera vez y luego hacer que lo identifiquen individualmente la próxima vez que lo vean. Los humanos solo necesitan algunos ejemplos para reconocer un nuevo objeto. Pero ese no es el caso de una máquina, que necesita cientos o miles de ejemplos similares para familiarizarse con un objeto. Y estos ejemplos son los conjuntos de datos que queremos.
Para entrenar un algoritmo de aprendizaje automático, necesita obtener suficientes datos. Ahora, la pregunta es, ¿dónde recopilas datos para cualquier proyecto en el que quieras trabajar?
Puede recopilar conjuntos de datos preexistentes de fuentes oficiales, puede importar datos de bases de datos, puede extraer datos directamente de páginas web, puede recopilar datos a través de algunos canales de redes sociales y también puede utilizar formularios en línea para la recopilación de datos. Hay muchas otras fuentes, y su método de recopilación de datos depende de su proyecto de ciencia de datos. Si está trabajando en un proyecto de ciencia de datos por primera vez, elija el conjunto de datos que le interese. Puede ser sobre deportes, películas o música, cualquier cosa que le interese. Aquí te recomiendo unas cuantas webs de las que suelo sacar datos:
- Conjunto de datos Kaggle
- conjunto de datos UCI
- datos mundiales
- sitio web del gobierno
- Raspe los datos usted mismo
Aquí, he elegido un conjunto de datos para practicar el análisis predictivo. Saqué el conjunto de datos del sitio web de Kaggle.
El conjunto de datos de este proyecto también se carga en mi github: conjunto de datos
# 首先安装kaggle
! pip install -q kaggle
# 将kaggle的json文件导入
!mkdir -p ~/.kaggle
!cp /content/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle config set -n path -v /content
# 下载数据集并解压。
! kaggle datasets download -d mirichoi0218/insurance
! unzip insurance.zip -d health-insurance
2. Elija un IDE
Si un trabajador quiere hacer un buen trabajo, primero debe afilar sus herramientas
Una vez que tenemos los datos, consideramos qué herramientas usar para procesar y modelar los datos. Elija un IDE con el que esté más familiarizado. Si usa el lenguaje Python, aquí hay algunos IDE comunes
-
Pycharm: es un IDE diseñado para escribir código Python. Proporciona varias funciones de producción, como la finalización de código inteligente, la verificación de errores y la corrección de códigos . Es compatible con el desarrollo web y la ciencia de datos al proporcionar integración con capacidades de control de versiones para facilitar el mantenimiento del proyecto.
-
Jupyter Notebook: es una aplicación web de código abierto que le permite crear y compartir documentos que contienen código en vivo, visualizaciones . Ayuda a simplificar el trabajo y facilitar la colaboración.
-
Google Colab: permite a los usuarios escribir y ejecutar código Python. Es ideal para proyectos de aprendizaje automático y ciencia de datos porque proporciona recursos informáticos de forma gratuita. Aquí puede ejecutar fácilmente algoritmos pesados de aprendizaje automático sin preocuparse por la infraestructura o el costo.
-
Un archivo de texto simple con una extensión .py, aunque las opciones anteriores están disponibles y son fáciles de usar, si prefiere codificar con el Bloc de notas, puede usarlo y guardar el archivo con una extensión .py. Luego puede ejecutar el mismo comando usando la línea de comando con la sintaxis "python .py". Esto ejecutará su programa, pero para el trabajo de ciencia de datos, esta puede no ser la mejor opción, ya que no podrá ver el código o visualizar la salida sobre la marcha.
Aquí, he elegido Google Colab como entorno de trabajo.
Una vez que tenga los datos con los que trabajar, el siguiente paso es obtener una primera impresión de los datos examinando su calidad . El objetivo principal de esta fase es realizar controles de cordura en los datos, y la mejor manera de hacerlo es buscar lo imposible o lo extremadamente improbable. Verifique valores atípicos y faltantes, verifique los tipos de datos correctos y verifique los casos más extremos. ¿Tienen sentido? Una buena práctica es ejecutar algunas pruebas estadísticas simples en los datos y visualizarlos para comprender rápidamente las propiedades estadísticas de los datos y detectar posibles valores atípicos.
3. Listar las actividades a realizar en el conjunto de datos
Enumere las operaciones que se realizarán en el conjunto de datos para que tenga una ruta clara antes de comenzar. Las acciones comunes que realizamos en proyectos de ciencia de datos son
Lectura de datos, limpieza de datos, transformación de datos, análisis exploratorio de datos, creación de modelos, evaluación de modelos e implementación de modelos . Estos pasos se describen brevemente a continuación.
La lectura de datos lee datos en una estructura de marco de datos , usando pandas
# 导入基本库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.cbook import boxplot_stats
import statsmodels.api as sm
from sklearn.model_selection import train_test_split,GridSearchCV, cross_val_score, cross_val_predict
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.tree import DecisionTreeRegressor
from sklearn import ensemble
import numpy as np
import pickle
# 读取数据,并总览一下数据情况。
health_ins_df = pd.read_csv("health-insurance/insurance.csv")
health_ins_df.head()
| índice | años | sexo | IMC | niños | fumador | región | cargos |
|---|---|---|---|---|---|---|---|
| 0 | 19 | femenino | 27,9 | 0 | sí | Sur oeste | 16884.924 |
| 1 | 18 | masculino | 33.77 | 1 | no | Sureste | 1725.5523 |
| 2 | 28 | masculino | 33.0 | 3 | no | Sureste | 4449.462 |
| 3 | 33 | masculino | 22.705 | 0 | no | noroeste | 21984.47061 |
| 4 | 32 | masculino | 28.88 | 0 | no | noroeste | 3866.8552 |
Limpieza de datos: identificación y eliminación de valores atípicos y faltantes en conjuntos de datos
# 查看缺失值
health_ins_df.isnull().sum()
# 可以看出数据集中没有缺失值
age 0
sex 0
bmi 0
children 0
smoker 0
region 0
charges 0
dtype: int64
Transformación de datos: implica cambiar el tipo de datos de una columna, crear una columna derivada o deduplicar datos, etc.
Análisis exploratorio de datos : realizar análisis univariados y multivariados en un conjunto de datos para descubrir algunas de las relaciones ocultas en él.
Realicemos la limpieza de datos y el análisis exploratorio de datos en variables numéricas y categóricas.
Análisis exploratorio de datos
Análisis de Variables Numéricas
#数值型变量的可视化
# 直方图绘制
fig,axes = plt.subplots(1,2,figsize=(12,6))
plt.style.use('ggplot')#使用ggplot主题,R语言的一个绘图包
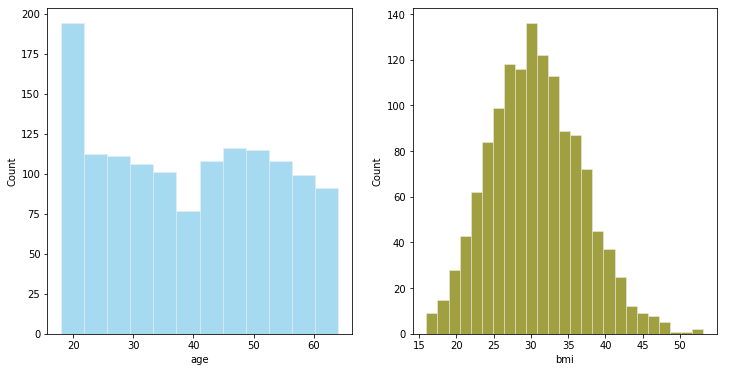
sns.histplot( health_ins_df['age'] , color="skyblue",ax=axes[0])
sns.histplot( health_ins_df['bmi'] , color="olive",ax=axes[1])
plt.show()
-
Podemos agrupar la edad en grupos de edad .
-
IMC cercano a la distribución normal
# 箱线图
fig,axes=plt.subplots(1,2,figsize=(10,5))
sns.boxplot(x = 'age', data = health_ins_df, ax=axes[0])
sns.boxplot(x = 'bmi', data = health_ins_df, ax=axes[1])
plt.show()

Se puede ver que hay algunos valores atípicos en el IMC , ahora echemos un vistazo a estos puntos
outlier_list = boxplot_stats(health_ins_df.bmi).pop(0)['fliers'].tolist()
print(outlier_list)
#查找包含异常值的行数
outlier_bmi_rows = health_ins_df[health_ins_df.bmi.isin(outlier_list)].shape[0]
print("bmi 中包含异常值的行数:", outlier_bmi_rows)
#离群值占比
#Percentage of rows which are outliers
percent_bmi_outlier = (outlier_bmi_rows/health_ins_df.shape[0])*100
print("bmi离群值异常值的百分比 : ", percent_bmi_outlier)
[49.06, 48.07, 47.52, 47.41, 50.38, 47.6, 52.58, 47.74, 53.13]
bmi 中包含异常值的行数: 9
bmi离群值异常值的百分比 : 0.672645739910314
Conversión de datos para variables numéricas
# 将年龄转换为分桶的
print("Minimum value for age : ", health_ins_df['age'].min(),"\nMaximum value for age : ", health_ins_df['age'].max())
'''
18至40岁的年龄将属于青年
41至58岁的年龄将低于中年
58岁以上将落入老年
'''
health_ins_df.loc[(health_ins_df['age'] >=18) & (health_ins_df['age'] <= 40), 'age_group'] = '青年'
health_ins_df.loc[(health_ins_df['age'] >= 41) & (health_ins_df['age'] <= 58), 'age_group'] = '中年'
health_ins_df.loc[health_ins_df['age'] > 58, 'age_group'] = '老年'
Minimum value for age : 18
Maximum value for age : 64
# 去除BMI中的异常值
health_ins_df_clean = health_ins_df[~health_ins_df.bmi.isin(outlier_list)]
sns.boxplot(x = 'bmi', data = health_ins_df_clean)

Análisis de variables categóricas
fig,axes=plt.subplots(1,5,figsize=(20,8))
sns.countplot(x = 'sex', data = health_ins_df_clean, palette = 'magma',ax=axes[0])
sns.countplot(x = 'children', data = health_ins_df_clean, palette = 'magma',ax=axes[1])
sns.countplot(x = 'smoker', data = health_ins_df_clean, palette = 'magma',ax=axes[2])
sns.countplot(x = 'region', data = health_ins_df_clean, palette = 'magma',ax=axes[3])
sns.countplot(x = 'age_group', data = health_ins_df_clean, palette = 'magma',ax=axes[4])

Una vez completada la preparación de datos, la siguiente etapa es el modelado. La elección de un algoritmo apropiado dependerá del tipo de datos. Por ejemplo, si los datos son continuos, aplicaría un modelo de regresión y, si los datos fueran categóricos, aplicaría un modelo de algoritmo de clasificación. Como científico de datos, probará muchos modelos para obtener el mejor ajuste.
Construcción del modelo
Pruebe y pruebe todos los modelos posibles en el conjunto de datos antes de elegir el correcto en función de las restricciones comerciales/técnicas . En esta etapa, también puede probar algunas técnicas de embolsado o refuerzo. Aquí, construí un modelo de regresión lineal, una regresión de árbol de decisión y una regresión de aumento de gradiente.
Modelo de regresión lineal simple
Aquí, primero usamos un modelo de regresión lineal como modelo de referencia.
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges']#自闭哪里
y = health_ins_df_processed['charges']#因变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)#划分训练集和测试集
lm.fit(X_train,y_train)
print("R-Squared on train dataset={}".format(lm.score(X_train,y_train)))#训练集R2
lm.fit(X_test,y_test)
print("R-Squaredon test dataset={}".format(lm.score(X_test,y_test)))#测试集R2
R-Squared on train dataset=0.7494776882061486
R-Squaredon test dataset=0.7372938495110573
A partir de los resultados, utilizando una regresión lineal simple R 2 R^2R2 es 0,74, lo que indica que el modelo explica el 74 % de la información de los datos. Veamos a continuación algunos modelos más complejos.
regresión del árbol de decisión
X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'charges']
y = health_ins_df_processed['charges']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
dtr = DecisionTreeRegressor(max_depth=4,min_samples_split=5,max_leaf_nodes=10)#初始化参数
dtr.fit(X_train,y_train)
print("R-Squared on train dataset={}".format(dtr.score(X_train,y_train)))#训练集R2
dtr.fit(X_test,y_test)
print("R-Squaredon test dataset={}".format(dtr.score(X_test,y_test)))#测试集R2
R-Squared on train dataset=0.8594291626976573
R-Squaredon test dataset=0.8571718114547656
Los parámetros anteriores los establezco al azar. También puede ajustar los parámetros para mejorar el efecto. Subí el código de ajuste de parámetros a github https://github.com/JoJoYao996/data-science-projects
Regresión de aumento de gradiente
Los principales parámetros de ajuste del modelo de regresión de aumento de gradiente
- learning_rate : tasa de aprendizaje, por defecto es 0.1
- n_estimadores : el valor predeterminado es 100
- max_ depth : La profundidad máxima de un estimador de regresión único. La profundidad máxima limita el número de nodos en el árbol. Ajuste este parámetro para un rendimiento óptimo; el valor óptimo depende de la interacción de las variables de entrada. El valor debe estar en el rango [1, inf).
- min_samples_split : Número mínimo de muestras requeridas para dividir nodos internos:
- min_samples_leaf : el número mínimo de muestras para los nodos hoja, este parámetro afectará el efecto de suavizado del modelo, especialmente en la regresión.
Usé gridsearch para ajustar estos parámetros por separado, y el siguiente es el resultado después de ajustar los parámetros.
#最终的模型
f_model = ensemble.GradientBoostingRegressor(learning_rate=0.015,n_estimators=250,max_depth=2,min_samples_leaf=5,
min_samples_split=2,subsample=1,loss = 'squared_error')
f_model.fit(X_train, y_train)
print("Accuracy score (training): {0:.3f}".format(f_model.score(X_train, y_train)))
f_model.fit(X_test, y_test)
print("Accuracy score (test): {0:.3f}".format(f_model.score(X_test, y_test)))
Accuracy score (training): 0.866
Accuracy score (test): 0.818
Ver la importancia de las características
#查看变量的重要性
feature_importance = f_model.feature_importances_
sorted_idx = np.argsort(feature_importance)#得到重要性的排序索引
fig = plt.figure(figsize=(12, 6))
pos = np.arange(sorted_idx.shape[0]) + .5
plt.barh(pos, feature_importance[sorted_idx], align='center')
plt.yticks(pos, np.array(health_ins_df_processed.columns)[sorted_idx])
plt.show()

Se puede observar que las tres características más importantes son: smoker_no, children_5, bmi
guardar modelo
# 保存模型
filename = 'health_insurance_data_model.sav'
pickle.dump(f_model, open(filename, 'wb'))
# 加载模型
filename = 'health_insurance_data_model.sav'
loaded_model = pickle.load(open(filename, 'rb'))
result = loaded_model.score(X_test, y_test)
print(result) #测试集精度
0.8180114370687565
4. Prepara el resumen
Resuma un documento que describa brevemente el proyecto y los pasos tomados para completarlo. Trate de resumir la declaración del problema comercial y la solución de ciencia de datos que diseñó. También mencione detalles vívidos sobre el proyecto para futuras referencias.
Puede preparar el resumen utilizando un documento de Word simple o una presentación de PowerPoint. Puede tener 5 partes. En la primera parte, se explican brevemente los antecedentes y problemas. En la segunda parte, mencione cuál es el conjunto de datos que está utilizando para el análisis predictivo y cuál es la fuente de los datos. Como se mencionó en la Parte 3, ¿qué limpieza de datos, transformación de datos y análisis exploratorio de datos realizó? Luego, mencione brevemente la prueba de concepto de los diferentes modelos predictivos que ha probado y comprobado. Finalmente, puede mencionar el resultado final y la solución al problema comercial.
Prepararé un breve resumen cuando este proyecto esté completo.
5. Comparte en plataformas de código abierto
Elija una plataforma de código abierto en la que desee publicar resúmenes o código del proyecto, como github, gitee, etc., para facilitar la comunicación con más científicos de datos y mejorar continuamente su proyecto.
El espacio es limitado. El código completo se puede ver en mi github. Bienvenido a star and fork.
dirección de github : código completo
Si no puede acceder a github, puede enviarme un mensaje privado para obtener el código fuente.