Tencent anunció el proyecto de componente de ciencia de datos distribuidos de código abierto Fast-Causal-Inference. Esta es una biblioteca de cálculo de inferencia causal y análisis estadístico desarrollada por Tencent WeChat que utiliza la interacción SQL y se basa en la vectorización distribuida. Se ha aplicado en múltiples negocios internos de WeChat, como las cuentas de video de WeChat y la búsqueda de WeChat.
Según la introducción, el proyecto tiene como objetivo resolver el cuello de botella de rendimiento de la biblioteca de modelos estadísticos existente (R/Python) bajo big data y proporcionar capacidades de inferencia causal que puedan ejecutar decenas de miles de millones de datos en segundos. Al mismo tiempo, el lenguaje SQL se utiliza para reducir el umbral de uso de modelos estadísticos, facilitando su uso en entornos de producción.
Principales ventajas del proyecto.
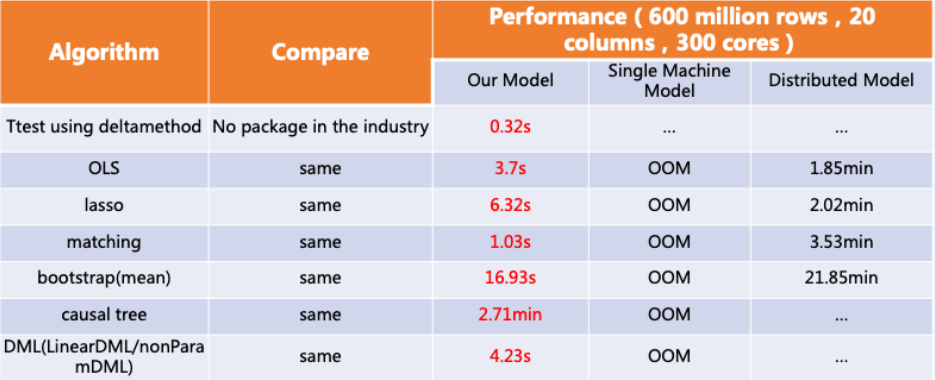
1. Proporcionar capacidad de inferencia causal para la ejecución masiva de datos en segundos.
Basado en el motor de ejecución OLAP vectorizado ClickHouse/StarRocks, la velocidad es más propicia para la mejor experiencia de usuario
2. Forma minimalista de utilizar SQL
SQLGateway WebServer reduce el umbral para usar modelos estadísticos a través del lenguaje SQL y proporciona una forma minimalista de usar SQL en la capa superior, realizando de manera transparente la expansión y optimización de SQL relacionada con el motor.
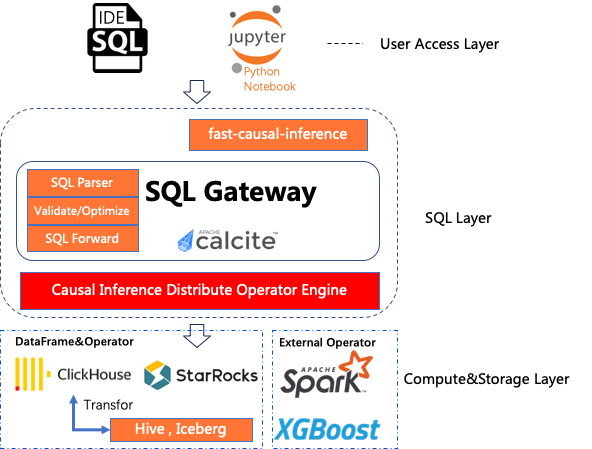
3. Proporcionar capacidades de inferencia causal para operadores básicos, operadores de orden superior y encapsulación de aplicaciones de capa superior.
支持 ttest, OLS, Lasso, modelo basado en árbol, coincidencia, bootstrap, DML

La primera versión ya admite las siguientes características
Herramientas básicas de inferencia causal
- Prueba basada en deltamétodo, compatible con CUPED.
- OLS, mil millones de filas de datos, nivel inferior al segundo
Herramientas avanzadas de inferencia causal
- Se están incubando mediación IV, WLS y otros GLS, DID, control sintético, CUPED y basados en OLS
- elevación: operaciones a nivel de minutos en decenas de millones de datos
- Los marcos de simulación de datos, como bootstrap/permutación, resuelven el problema de la estimación de la varianza sin mostrar soluciones.