要約: この論文は主に4種類のKafkaネットワーク中断とネットワークパーティションシナリオ分析をもたらします。
この記事は、HUAWEICLOUDコミュニティ「Kafkaネットワークの中断とネットワークパーティションシナリオ分析」、著者:ミドルウェアの兄弟から共有されています。
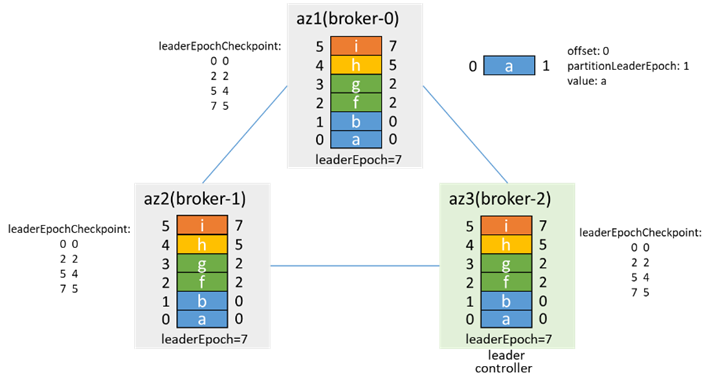
例としてKafkaバージョン2.7.1を取り上げ、zkデプロイメントに依存します
3つのブローカーが3つのaz、3つのzk(ブローカーとのジョイント)、1つのパーティションに3つのレプリカで分散されます
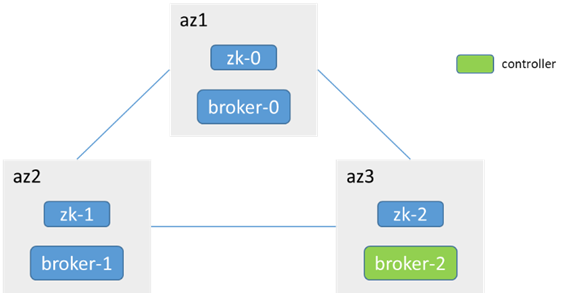
1.単一のブローカーノードとリーダーノードのネットワークが中断されます
ネットワーク停止前:
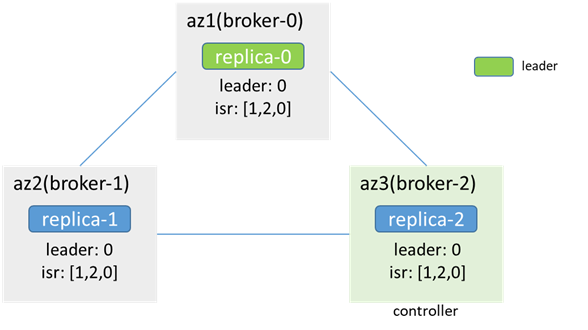
ブローカー1とブローカー0(リーダー)間のネットワークが中断された後、一方的な中断、zkが使用可能になります(zk-1がリーダー、zk-0とzk-2がフォロワー、zk-0は使用不可になりますが、 zkクラスターが使用可能である場合、このプロセスにより、最初にzk-0に接続されていたブローカーノードが最初にzkから切断され、次に他のzkノードに再接続され、コントローラーの切り替えやリーダーの選出などが発生する可能性があります。この分析)、リーダー、isr、コントローラーは変更されていません
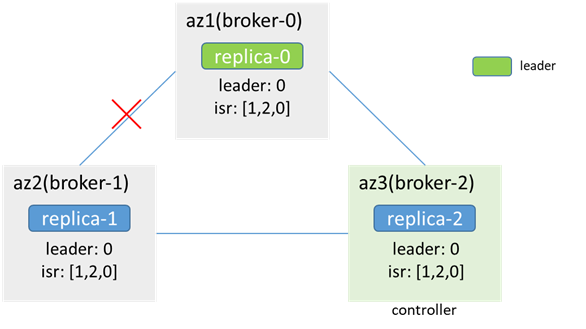
az2のクライアントは生成および消費できません(メタデータはリーダーがブローカー0であることを示しますが、az2はブローカー0に接続できません)、az1 / 3のクライアントは、acks = -1、retries = 1の場合、生成および消費できます。メッセージは失敗し、error_code = 7(REQUEST_TIMED_OUT)(broker-1はisrにありますが、データを同期できないため)、2回送信され(retries = 1のため)、broker-0とbroker-0のそれぞれに2つあります。ブローカー2メッセージが重複していますが、ブローカー1にはありません。ブローカー0には同期データがないため、isrから削除され、コントローラー同期メタデータとleaderAndIsr、isrが[2,0]に更新されます。
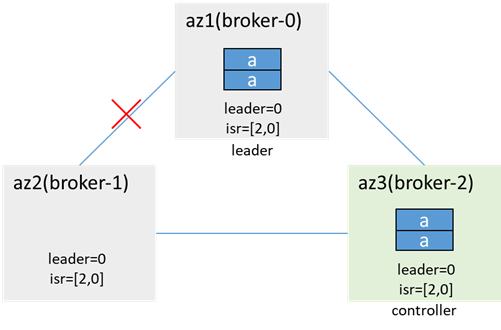
ネットワークが復元された後、データが同期され、isrが更新されます
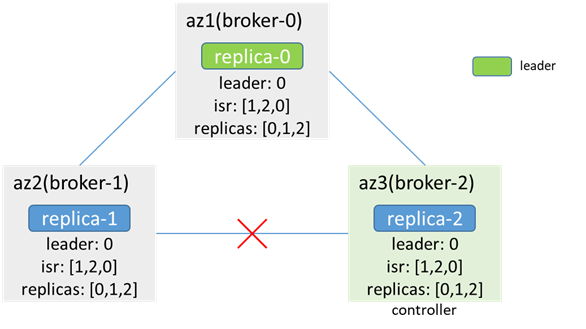
2.単一のブローカーノードとコントローラーノードのネットワークが中断されます
ブローカーとコントローラーの間の切断は、生産と消費に影響を与えず、データの不整合はありません。
リーダーとisrが変更されると、コントローラーはリーダーとisrの変更をブローカーに更新できないため、メタデータに一貫性がなくなります。
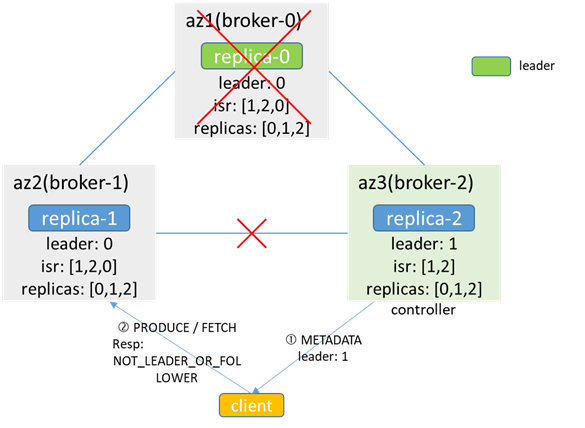
ブローカー0に障害が発生すると、コントローラー(ブローカー2)がそれを検知し、レプリカに従って新しいリーダーをブローカー1として選択しますが、ブローカー1とのネットワークの中断により、ブローカー1と同期できず、リーダーがキャッシュされます。ブローカーによって-1はまだブローカー0であり、isrは[1,2,0]です。クライアントが生成および消費しているときに、メタデータがブローカー2から取得された場合、リーダーは1であると見なされ、ブローカー1はNOT_LEADER_OR_FOLLOWERを返します。ブローカー1から取得した場合、メタデータに関しては、リーダーは0と見なされ、ブローカー0へのアクセスに失敗すると生産と消費の失敗につながります。
3.非コントローラーノードが配置されているazは分離(パーティション化)されています

zk-0はzk-1およびzk-2では機能しません。半分未満です。az1のzkは使用できません。ブローカー0はzkにアクセスできません。コントローラーの選出は行われず、コントローラーはブローカー1にあります。
ネットワークが復元された後、broker-0はクラスターに参加し、データを同期します
3.1 3つのレプリカパーティション(replicas:[1,0,2])、元のリーダーはブローカー-1(またはブローカー-2)にあります
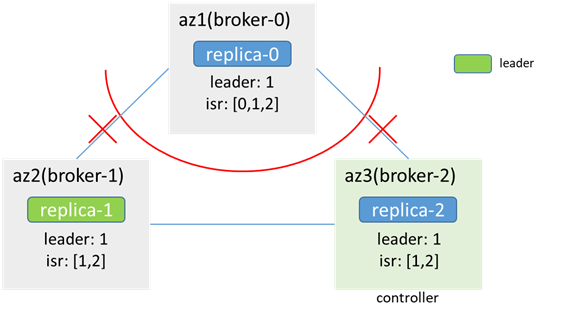
az1の内部:
ブローカー0はzkにアクセスできず、ノードの変更を認識できず、メタデータは更新されません(リーダー:1、isr:[1、0、2])、それでもフォロワーであると見なし、リーダーは1、az1のクライアント生産および消費することはできません
az2 / 3の場合:
zkが使用可能であり、broker-0がオフラインであり、メタデータが更新され、リーダーの切り替えが発生しないことを検出します(isr:[1,0,2]-> [1,2]、leader:1);az2およびaz3のクライアント通常の生産と消費である可能性があります
3.2 3つのレプリカパーティション(replicas:[0,1,2])、元のリーダーはブローカー0にあります
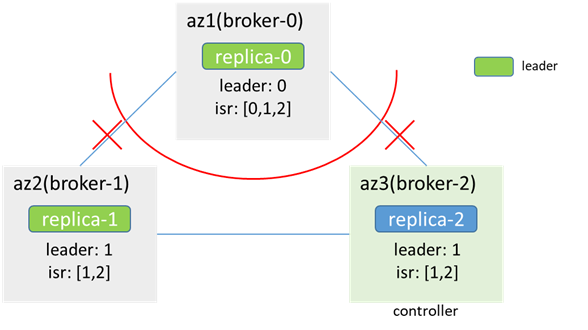
az1の内部:
zk-0とzk-1およびzk-2の間の接続が中断され、半分未満、az1のzkクラスターが使用不可、ブローカー0がzkに接続できず、ノードの変更を検知できず、isrを更新できず、メタデータが残っている変更なし、リーダーとisrはすべて変更されません。az1のクライアントは、ブローカー0への生成と消費を継続できます。
az2 / 3の場合:
zk-1とzk-2が接続され、zkが使用可能であり、クラスターがブローカー0がオフラインであることを検知し、リーダーの切り替えをトリガーし、ブローカー1が新しいリーダーになります(時間はzookeeper.session.timeout.msによって異なります)。 isrを更新します。/3のaz2クライアントは、broker-1を生成および消費できます。
この時点で、パーティションにはデュアルマスター現象があります。レプリカ0とレプリカ1の両方がリーダーであり、どちらも本番環境と消費環境に使用できます。
2つの分離ドメインの両方のクライアントがメッセージを生成すると、データの不整合が発生します
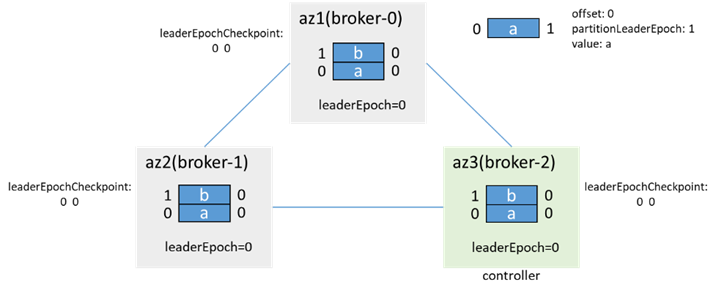
例:(ネットワーク分離の前に2つのメッセージがあると仮定します。leaderEpoch=0)
ネットワーク分離前:
az1が分離され、パーティションがデュアルマスターになった後、az1のクライアントはc、d、eの3つのメッセージを書き込み、az2 / 3のクライアントはf、gの2つのメッセージを書き込みます。
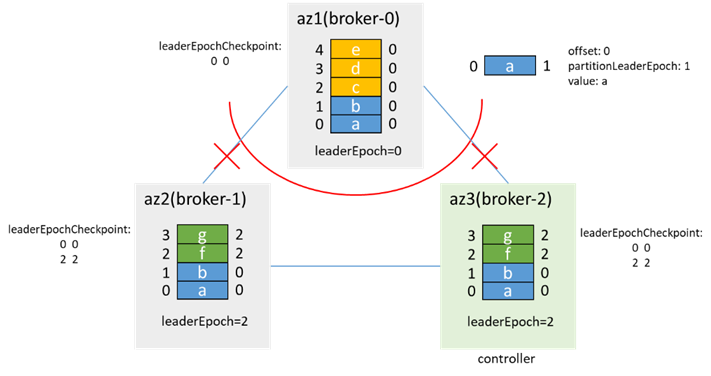
ここでは、leaderEpochを増やすための2つの操作があるため、leaderEpochが2増加します。1つはPartitionStateMachineのhandleStateChangesがOnlinePartitionに行くときのリーダー選出であり、もう1つはReplicationStateMachineのhandleStateChangesがOfflineReplicaに行くときのremoveReplicasFromIsrです。
ネットワークが復元された後:
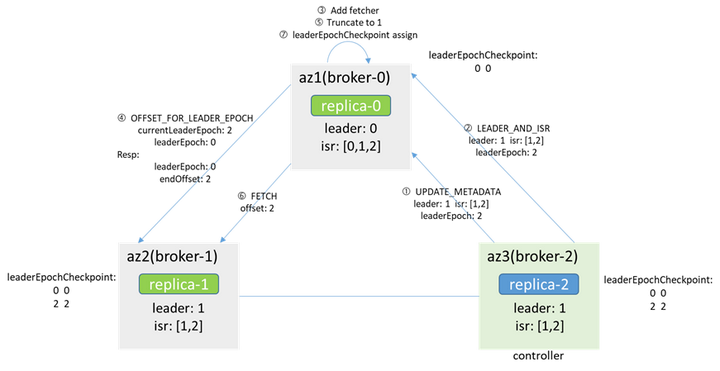
コントローラはbroker-2にあり、キャッシュのリーダーであり、zkはbroker-1であるため、コントローラはbroker-0 makerFollowerに通知し、broker-0はすぐにフェッチャーを追加し、最初にleaderEpochに対応するendOffsetをから取得します。リーダー(ブローカー-1)(OFFSET_FOR_LEADER_EPOCH経由)、返された結果に従って切り捨て、次にFETCHメッセージを開始し、メッセージ内のleaderEpochに従って割り当てて、リーダーと一致するようにします。
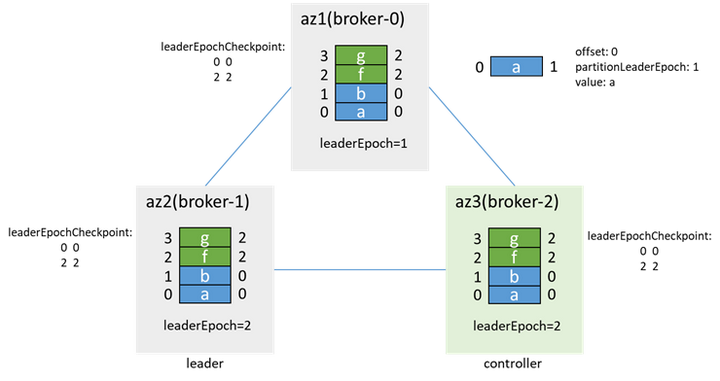
データが同期されたら、isrを追加し、isrを[1,2,0]に更新します。その後、preferredLeaderElectionがトリガーされると、broker-0が再びリーダーになり、leaderEpochが3に増加します。
ネットワーク分離中に、az1のクライアントにacks=-1およびretries=3がある場合、本番メッセージは失敗しますが、データディレクトリには本番メッセージの数の4倍のメッセージがあります(各メッセージは4回繰り返し)
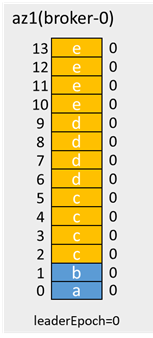
前述のように、ネットワークが復元された後、オフセット2〜13のメッセージは上書きされますが、これらのメッセージは本番環境にあるため、acks = -1であり、本番環境の障害がクライアントに返されるため、メッセージとしてカウントされません。損失。
したがって、この状況を考慮すると、client acks=-1をお勧めします。
4.コントローラーノードが配置されているazは分離(パーティション化)されています
4.1リーダーノードが分離されていない
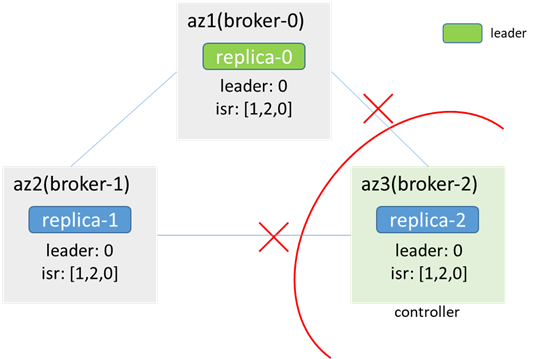
ネットワークが中断された後、az3のzkは使用できなくなり、ブローカー2(元のコントローラー)はzkクラスターから切断され、ブローカー0とブローカー1がコントローラーを再選出します。
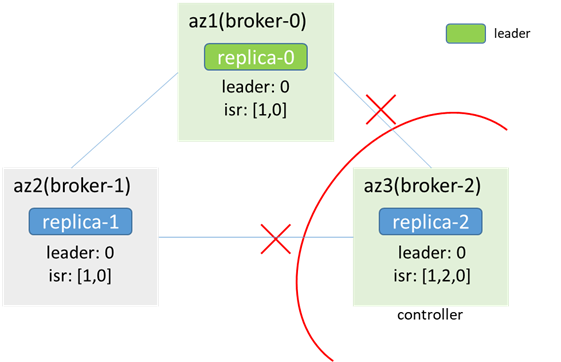
最終的に、ブローカー0がコントローラーとして選出され、ブローカー2もそれ自体をコントローラーと見なし、コントローラーにはデュアルマスターがあります。同時に、zkを接続できないため、メタデータを更新できません。 az3のクライアントは生成および消費できず、az1/2の通常の生成および消費のクライアント
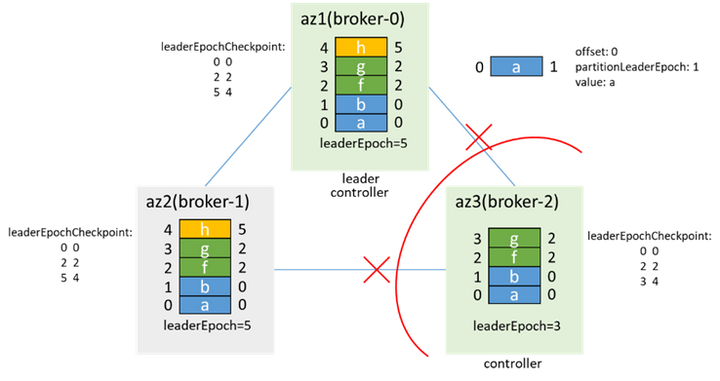
障害が回復した後、ブローカー2はzk接続ステータスが変更されたことを認識し、最初に辞任してからコントローラーの実行を試みます。ブローカー0はすでにコントローラーであることがわかり、コントローラーの実行を断念します。同時に、broker-0はbroker-2がオンラインであることを検知します。LeaderAndIsrとメタデータをbroker-2に同期し、broker-2がデータを同期した後にisrを追加します。
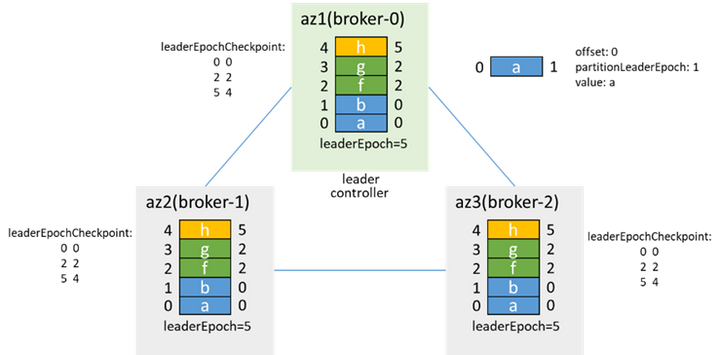
4.2リーダーノードとコントローラーは同じノードであり、一緒に分離されています
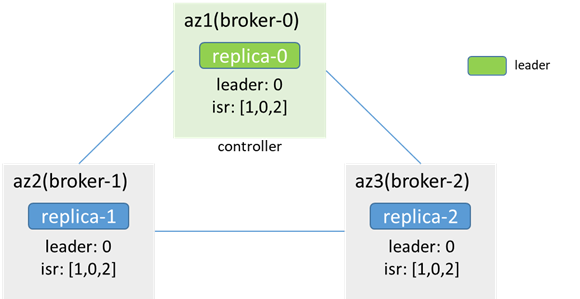
分離する前は、コントローラーとリーダーの両方がブローカー0にあります。
分離後、az1ネットワークが分離され、zkが使用できなくなり、ブローカー2がコントローラーとして選出され、コントローラーにはデュアルマスターがあります。同時に、レプリカ2がリーダーになり、パーティションにもデュアルマスターがあります。
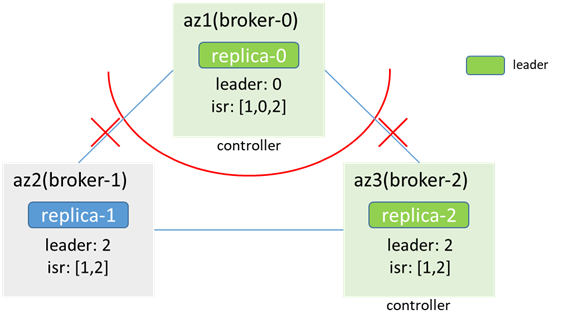
このときのシーンは3.2に似ています。このとき、プロダクションメッセージにデータの不整合がある可能性があります
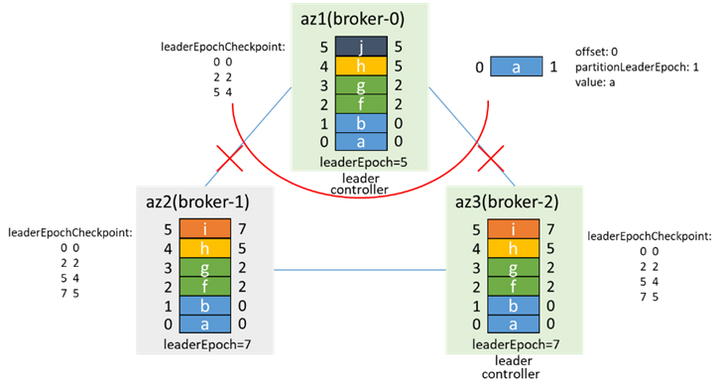
ネットワークリカバリ後の状況は3.2に似ており、ブローカー2はコントローラーとリーダーであり、ブローカー0はleaderEpochに従って切り捨てられ、ブローカー2からのデータを同期します。
isrに参加し、preferredLeaderElectionを介して再びリーダーになり、leaderEpochを1増やします。
5.補足:障害シナリオによって引き起こされるデータの不整合
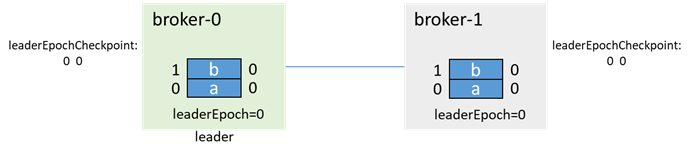
5.1データ同期の瞬間的な失敗
最初は、broker-0がリーダーで、broker-1がフォロワーであり、それぞれに2つのメッセージaとbがあります。
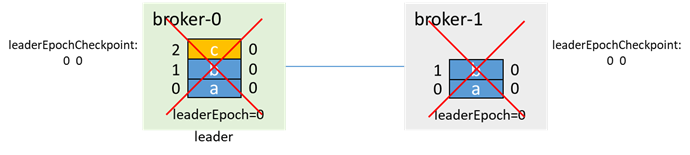
リーダーはメッセージcを書き込み、フォロワーと同期する時間がなくなる前に、両方のブローカーが失敗します(次のように)。
その後、broker-1が最初に起動してリーダーになり(unclean.leader.election.enableがtrueであるかどうかに関係なく、0と1の両方がisrにあり、マスターに昇格できます)、leaderEpochをインクリメントします。 :
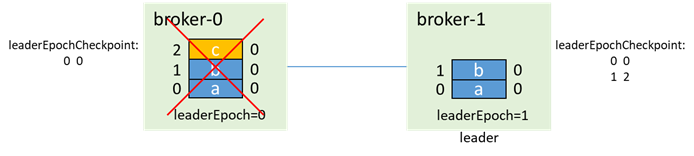
次に、現時点ではフォロワーであるブローカー0が開始し、ブローカー1からOFFSET_FOR_LEADER_EPOCHを介してleaderEpoch=0のendOffsetを取得します。
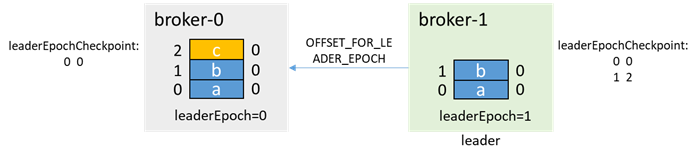
ブローカー0は、リーダーエポックendOffsetに従って切り捨てます。
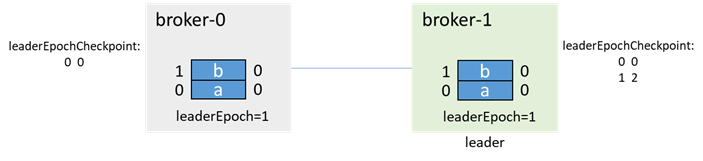
次に、通常の本番メッセージとレプリカが同期されます。

このプロセスでは、acks = -1の場合、メッセージcが生成されると、生成の失敗がクライアントに返され、メッセージは失われません。acks= 0または1の場合、メッセージcは失われます。
5.2 unclean.leader.election.enable=trueによって引き起こされるデータ損失
この例では、broker-0がリーダー、broker-1がフォロワーであり、それぞれに2つのメッセージaとbがあります。この時点で、broker-1はダウンしています。isr= [0]
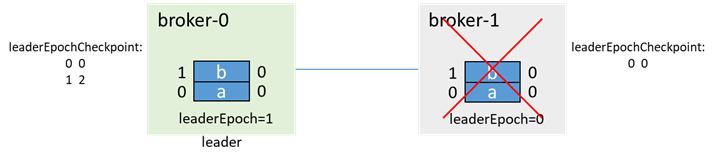
ブローカー1の障害時に、ブローカー1がisrに存在しないため、メッセージcが生成されます。したがって、acks = -1であっても、正常に生成できます。
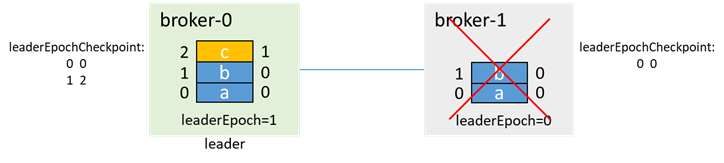
次に、broker-0もダウンし、leader = -1、isr = [0]

このとき、broker-1が最初にプルアップされます。unclean.leader.election.enable= trueの場合、broker-1がisrにない場合でも、broker-1が唯一の生きているノードであるため、broker-1はリーダーに選出され、リーダーを更新しますEpochは2です
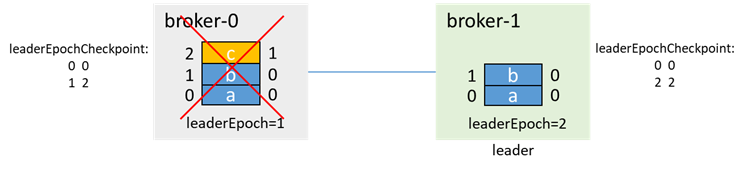
このとき、broker-0が再度プルアップされると、最初にOFFSET_FOR_LEADER_EPOCHを渡して、broker-1からエポック情報を取得し、データを切り捨てます。
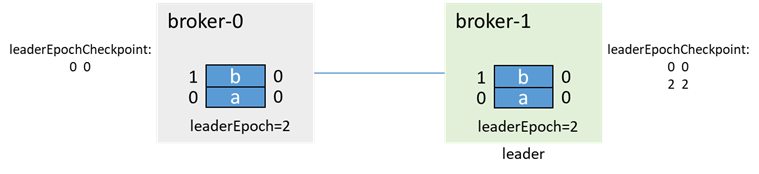
本番メッセージとレプリカを再同期します
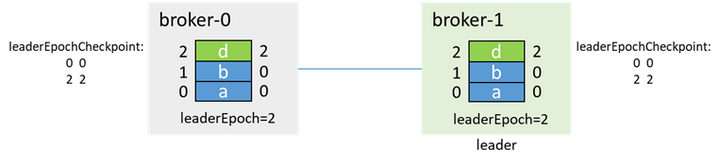
メッセージcが失われました
[フォロー]をクリックして、HUAWEI CLOUDの新技術について初めて学びましょう〜