Directorio artículo
- configuración de la máquina virtual de Windows Hadoop Colmena (b)
- Xftp utilizar un paquete cargado en el Linux
- Dos de preparación sin densa Login
- paquete a / opt / módulo de extracción automática de tres
- Cuatro ediciones variables de entorno:
- Cinco para recargar las variables de entorno de archivos para tener efecto
- Seis Hadoop modificar el fichero de configuración:
configuración de la máquina virtual de Windows Hadoop Colmena (b)
Totalmente distribuida: demonios Hadoop se ejecutan en un clúster de
pseudo-distribuir: Ejecución de Hadoop en un solo grupo de nodos en la que todos los demonios que se ejecuta en el mismo consumo de máquina de la máquina un poco más pequeño.
Xftp utilizar un paquete cargado en el Linux
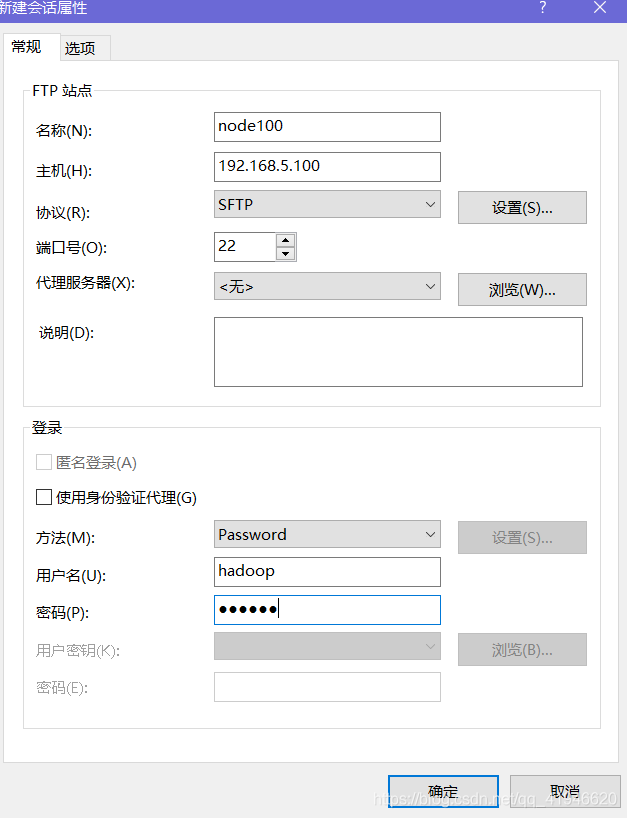
No utilice el nombre de usuario root, el usuario inicia sesión en el uso de Hadoop, el software Hadoop se transfiere al siguiente directorio:
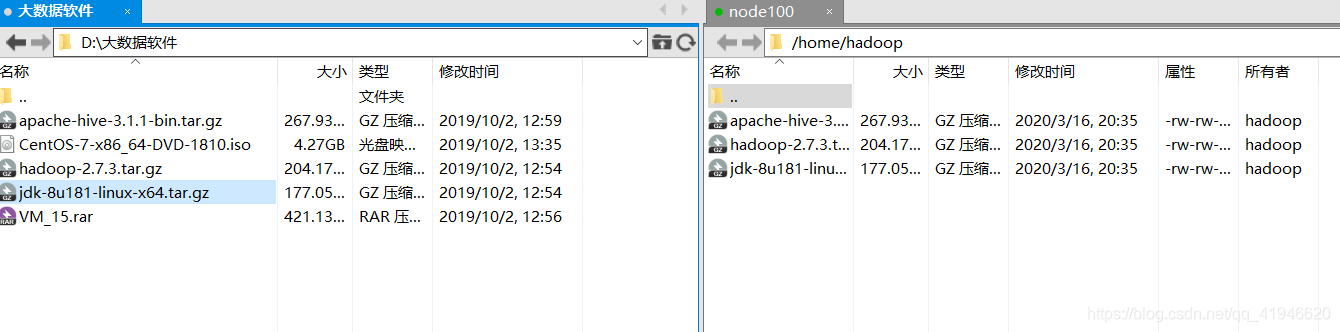
cheque en Xshell si existen estos programas:
Dos de preparación sin densa Login
La razón del inicio de sesión sin contraseña: Si el clúster no es un pseudo-distribuido, y guarde el archivo cuando múltiples copias, por ejemplo, guardan tres, entonces él va a ser descargado desde diferentes bloques en el tiempo de descarga, que desea descargar el node101 archivo , es necesario introducir para descarga. Si no lo hace de configuración de inicio de sesión evitar densa, si es necesario introducir una contraseña cada tres nodos perdieron la contraseña que puedo aceptar, pero si los tres archivos 10000 bloques, bloques en diferentes máquinas, hay que introduce el código tanto, mi corazón no está muy bloquee.
- Un cambio a la raíz:
su - root - 2 Cerrar selinux:
vim /etc/selinux/configPulse i modo de inserción,SELINUX=disabled
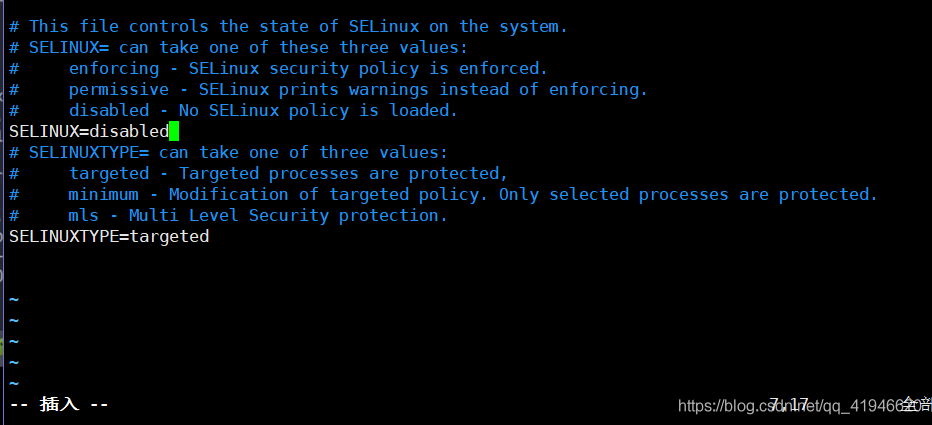
ESC :wqpara guardar y salir de la pantalla se borra .clear
- 3 Hadoop usuario para cambiar a:
su - hadoop - 4 en el directorio principal de Hadoop:
cd
Después de entrar en el directorio principal de Hadoop, entre el mandato siguiente:
Nota: media logarítmica ssh a otras máquinas significan, ahora estoy node100, para iniciar sesión en el 101, en un clúster puede iniciar sesión, registro puede entrar en el equivalente en otro equipo.
ssh-keygen -t rsa[de entrada, incluso después de cuatro pulse Intro]
ssh node100[Sí, hadoop introducción de la contraseña del usuario]
ssh-copy-id node100[enter hadoop la contraseña del usuario]
Los cheques para el éxito: ssh node100no necesitan una contraseña para iniciar sesión en
paquete a / opt / módulo de extracción automática de tres
Para cambiar a la raíz, crear una carpeta dentro del módulo en opt:
Cambiar a la carpeta opt en el usuario root: cd /opt/
Crear una carpeta del módulo:mkdir module
Cambiar el propietario y todos los grupos de Hadoop:
chgrp hadoop module/
chown hadoop module/
Inicio guía posterior empezar a extraer:
cd
tar -zxvf ./jdk-8u181-linux-x64.tar.gz -C /opt/module/
tar -zxvf ./hadoop-2.7.3.tar.gz -C /opt/module/
tar -zxvf ./apache-hive-3.1.1-bin.tar.gz -C /opt/module/
Cuatro ediciones variables de entorno:
cd En el directorio principal, esto es un archivo oculto .bash_profile
vim ~/.bash_profile

Se añade al final del archivo (la última línea del cursor, de acuerdo con una minúscula O)
la JAVA_HOME = / opt / Module1 / jdk1.8.0_181
HADOOP_HOME es = / opt / Module1 / Hadoop-2.7.3
HIVE_HOME = / opt / Module1 / Apache-Hive bin - 3.1.1
el PATH =
HOME / bin:
HADOOP_HOME / bin:
HIVE_HOME / bin
export JAVA_HOME
exportación HADOOP_HOME
exportación HIVE_HOME
export PATH

ESC: wq
Cinco para recargar las variables de entorno de archivos para tener efecto
En el directorio principal de Hadoop
source ~/.bash_profile
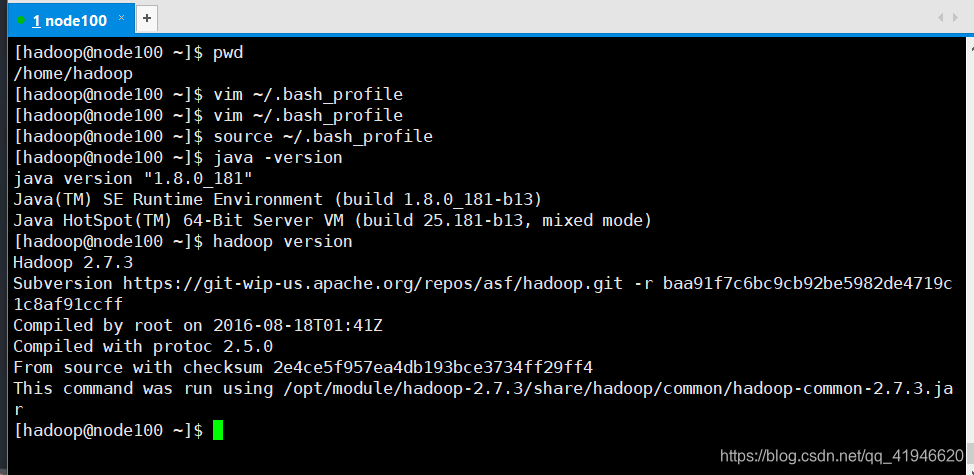
para verificar la correcta:
java -version
hadoop version
Seis Hadoop modificar el fichero de configuración:
En el usuario Hadoop:
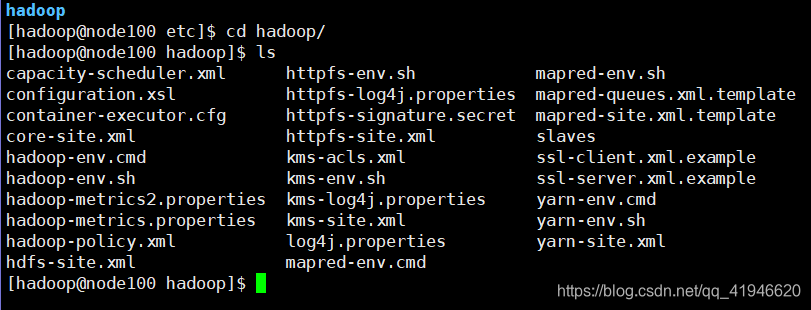
cd /opt/module/hadoop-2.7.3/etc/hadoop

. Etc. es almacenar el archivo de configuración en el etc echamos un vistazo a:

un archivo de Hadoop, vamos:
tenemos que modificar algunos de ellos: copiar y pegar el siguiente comando
1.vim ./hadoop-env.sh
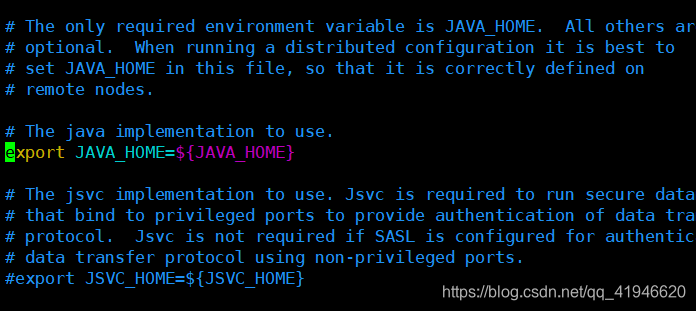
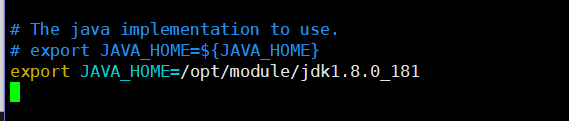
va a colocar el cursor los cambios en el código (o notas) como sigue: Nota jdk1.8.0_181 para que se corresponda con su versión del nombre del archivo después de extraer!
export JAVA_HOME = / opt / Módulo / jdk1.8.0_181
: WQ
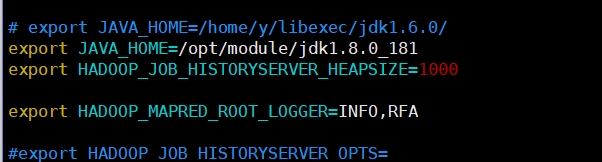
2.vim ./mapred-env.sh
export JAVA_HOME = / opt / módulo / jdk1.8.0_181
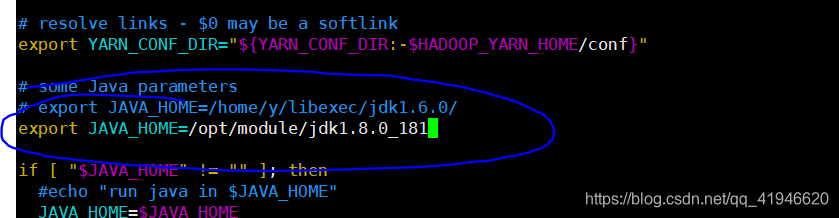
3.vim ./yarn-env.sh
export JAVA_HOME = / opt / módulo / jdk1.8.0_181
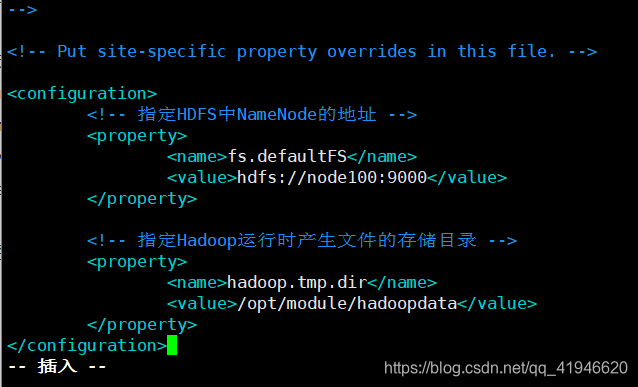
4.vim ./core-site.xml
en el centro de la primera fila y el número inverso de la penúltima línea, pulse una tecla o

<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node100:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoopdata</value>
</property>
Copiar y pegar, sino también la copia en blanco, en medio de Node100 al cambio de acuerdo con su propio nombre de la máquina:
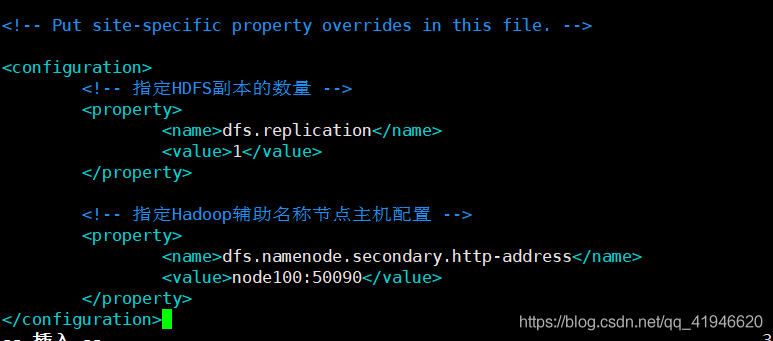
5.vim ./hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node100:50090</value>
</property>
6.cp ./mapred-site.xml.template ./mapred-site.xml
primera copia en el pasado, y luego editar el archivo después de copiar

vim ./mapred-site.xml (z tengo que presionar una cierta nota al lugar designado edición)
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
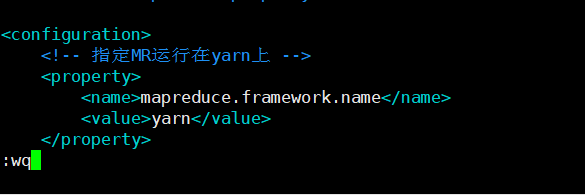
7.vim ./yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node100</value>
</property>
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
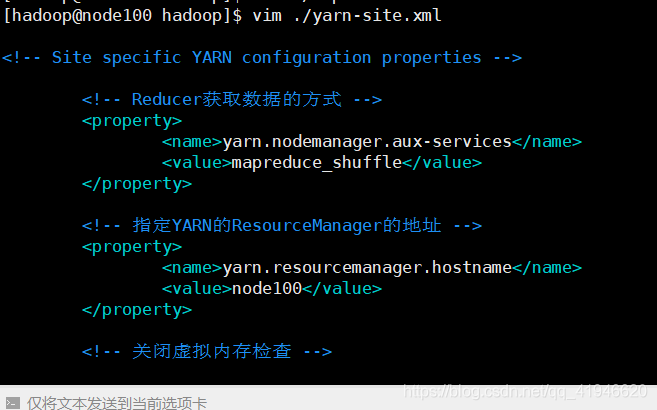
8.vim ./slaves
Delete (minúscula dd modo normal) localhost, a NODE100
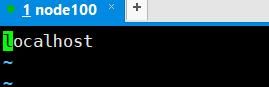
NODE100
Nueve, el formato de clúster Hadoop
Nota: Este comando sólo se puede formatear de nuevo formato será un problema!
Ejecutado en node100 esta máquina: hdfs NameNode -format
Después de un formato bueno puede activar o desactivar el cluster Hadoop
Diez, el arranque / parada del clúster Hadoop
ejecución node100 comenzó en esta máquina: start-all.sh
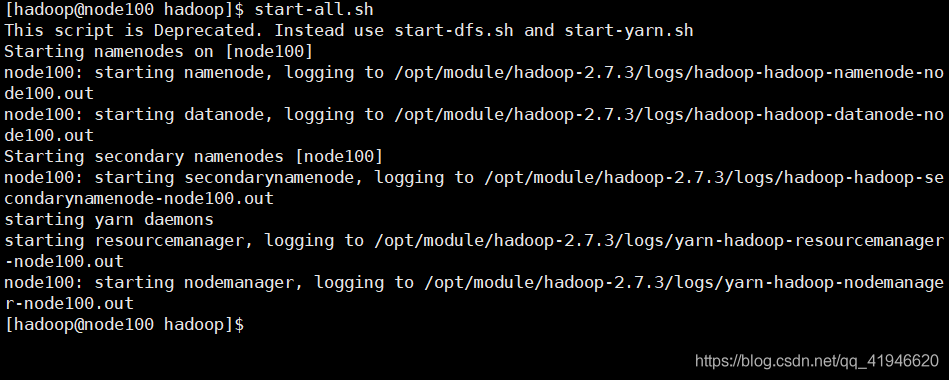
ver si la operación exitosa: JPS
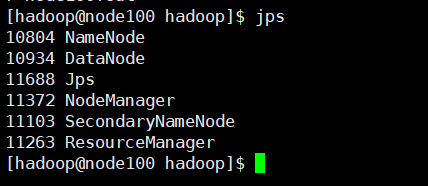
un total de seis procesos, uno más uno menos no funcionará
En node100 esta máquina para realizar cerrado: stop-all.sh
XI, verificar racimo
- Verificar si la página lo normal : Introduzca la siguiente dirección en el navegador del ordenador: Dirección IP se puede encontrar en la terminal de ifconfig
192.168.5.100:50070
192.168.5.100:8088
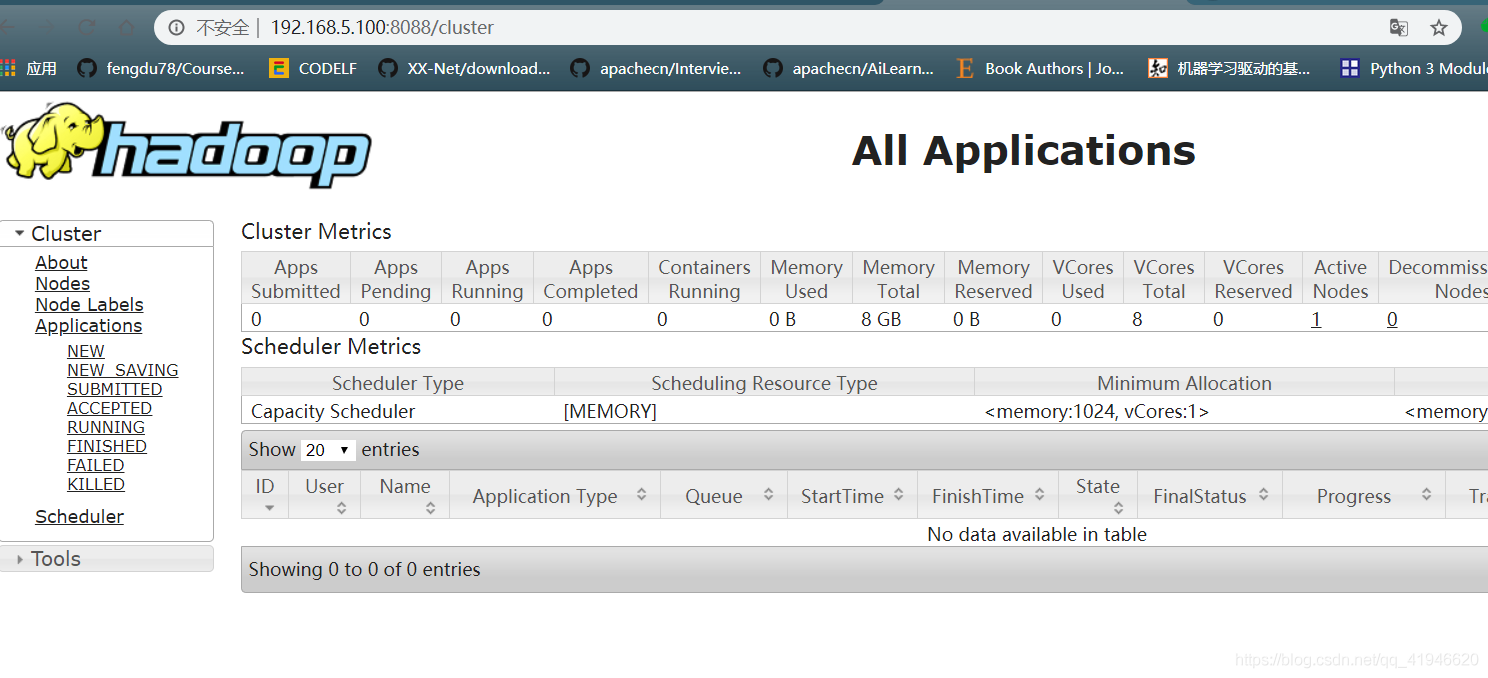
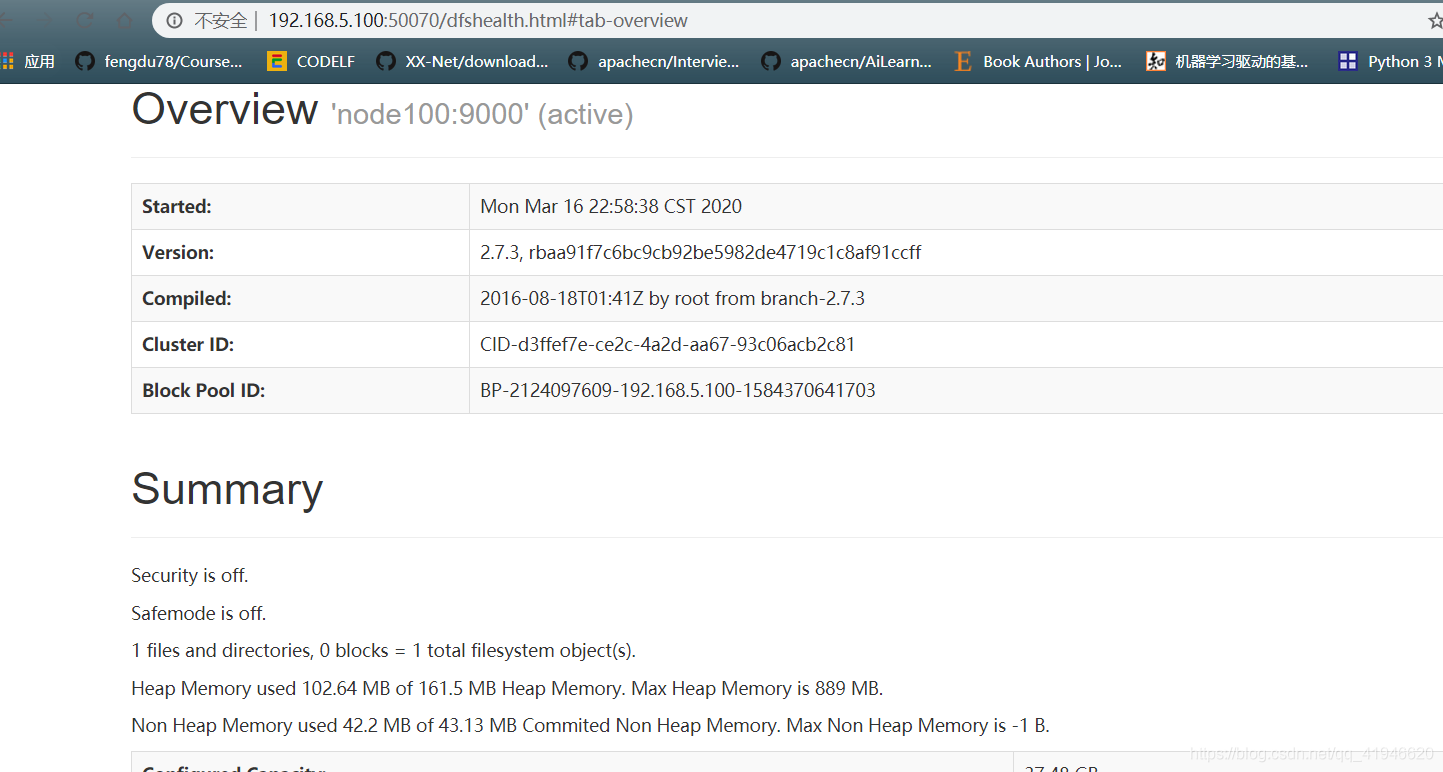
Si la página no aparece podría ser un servidor de seguridad no está desactivado:
desactive el firewall: cambiar al usuario root,
systemctl PARADA firewalld.service
systemctl desactivar firewalld.service
Doce, recuento de palabras de Hadoop
plazo sobre la barra de tareas, crear un archivo en el directorio principal de la Hadoop
1.vim word.txt
de escritura:
el Hola Python
del Hola Java
del Hola Scala
el Hola mundo
está disponible para su compra a Beijing
: WQ Guardar
prueba 2.wordcount
crear una carpeta en un clúster:
hadoop FS -mkdir / prueba
en examinar el sistema de archivos para acceder al sistema de archivos
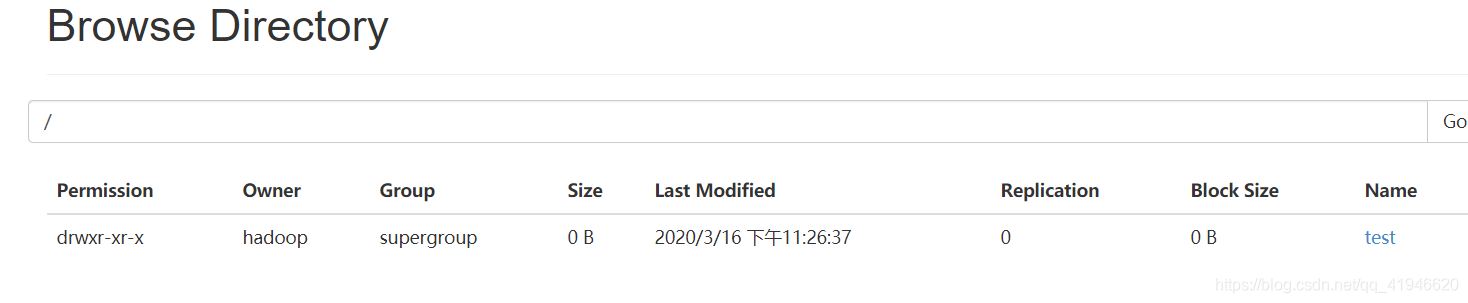
del mundo que ha creado anteriormente, txt copiado a prueba en (ejecución directorio personal)
hadoop FS -poner ./word. txt / prueba de


ejecución (el número de veces que aparece cada palabra en las estadísticas de archivos):
hadoop JAR /opt/module/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar recuento de palabras / / word.txt prueba / salida
de verificación (aparece resultado):
Hadoop FS -cat / salida / 00000-R & lt Part-
Trece, instalación colmena
colmena --version
comenzar la instalación:
Crear un directorio de almacenamiento de datos en la colmena HDFS
hadoop FS -mkdir / tmp # tmp directorio ya está existió, justo a tiempo para ejecutar la tarea ya había visto
hadoop fs -mkdir - P / usuario / colmena / Almacén
permiso # dar
Hadoop FS -chmod G + W / tmp
Hadoop FS -chmod G + W / usuario / colmena / Almacén
Realizar comando de inicialización en el directorio de software colmena
en el directorio de la colmena: cd /opt/module/apache-hive-3.1.1-bin/
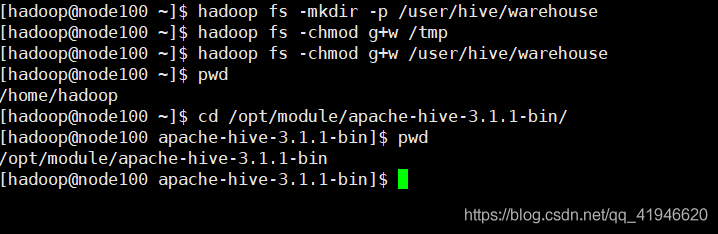
bin / SchemaTool -dbType derby -initSchema
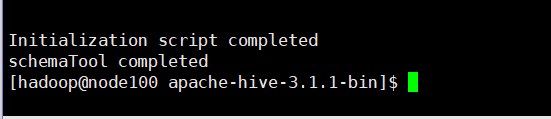
después de la inicialización exitosa generará derby en el directorio de instalación de la colmena archivos de registro .log y metadatos de base de datos metastore_db
comienzan colmena: entrar en el directorio apach bin/hive(debe ser iniciado en este catálogo)
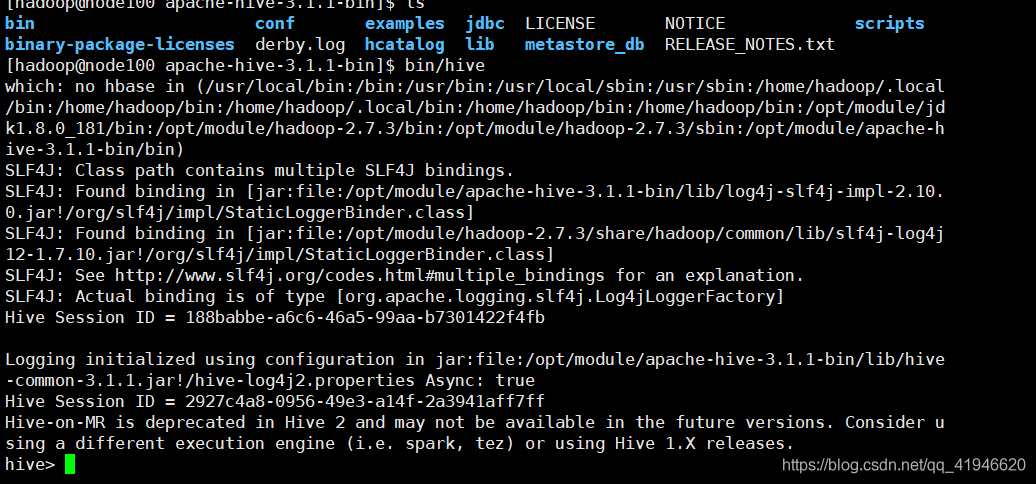
para ver la base de datos: bases de datos de demostración;
la validación es correcta, no ejecutar otros comandos: exit para salir;
Nota: salir del modo seguro licencia Hadoop Hadoop dfsadmin -safemode (porque a veces se le pedirá al clúster está en modo seguro, si se ejecuta esta sentencia en modo seguro)
MapReduce es un marco de procesamiento de la tarea orientada a lotes convencional. Tez como nuevo motor de procesamiento más inclinado a un acceso casi consulta en tiempo real. Con la llegada de Hilados, HDFS está convirtiendo en un entorno multi-arrendatario que permite una gran cantidad de patrones de acceso a datos, como el acceso a granel, el acceso y el acceso interactivo en tiempo real.
