Toda la clasificación en este artículo está en orden ascendente como ejemplo

contenido
1. Clasificación por inserción directa
Tres, clasificación por selección
3. Método de puntero delantero y trasero (recomendado de esta forma de escritura)
Optimización de clasificación rápida
1. Método chino de tres números
2. Recursión a pequeños subintervalos
El resumen de estabilidad de los ocho tipos:
1. Clasificación por inserción directa
Idea básica: Cuando solemos jugar al póquer, la idea de clasificación por inserción se utiliza en la clasificación de la etapa de sorteo de cartas.
1. Al insertar el elemento n, los números n-1 anteriores ya están en orden
2. Use este número n para compararlo con el número n-1 anterior, busque la posición que se va a insertar e insértelo (el número en la posición original no se sobrescribirá porque se guarda de antemano)
3. Los datos en la posición original se mueven hacia atrás a su vez
Implementación:
①Implementación unidireccional (inserte x en el intervalo ordenado de [0,fin])
Es decir, para la inserción en general, enumeramos aleatoriamente algunos números, y los números a insertar se dividen en dos casos
(1) El número a insertar es el número medio en el número ordenado anterior, y la comparación directa asigna x a la posición final+1
(2) x es el número más pequeño, end alcanzará la posición de -1 y finalmente asignará x directamente a la posición end+1

② Implementación de ordenar toda la matriz
No sabíamos si la matriz estaba ordenada al principio, por lo que controlamos el subíndice, el final comienza desde 0 y siempre guarda el valor en la posición final + 1 en x, y el ciclo se puede ordenar en un solo paso. Al final, end= El número en la posición n-2, n-1 se almacena en x

Código general:
void InsertSort(int* a, int n)
{
assert(a);
for (int i = 0; i < n - 1; ++i)
{
int end = i;
int x=a[end+1];//将end后面的值保存到x里面了
//将x插入到[0,end]的有序区间
while (end >= 0)
{
if (a[end] > x)
{
a[end + 1] = a[end]; //往后挪动一位
--end;
}
else
{
break;
}
}
a[end + 1] = x; //x放的位置都是end的后一个位置
}
}Resumen de clasificación por inserción directa:
① Cuanto más cerca estén los elementos del pedido, mayor será la eficiencia de la clasificación por inserción directa
②Complejidad de tiempo: O(N^2)
En el peor de los casos, cada vez que se inserta un número, se debe mover el número anterior, un total de 1+2+3+...+n=n(n+1)/2
③ Complejidad del espacio: O(1)
Sin espacio adicional, solo un número constante de variables
2. Clasificación de colinas
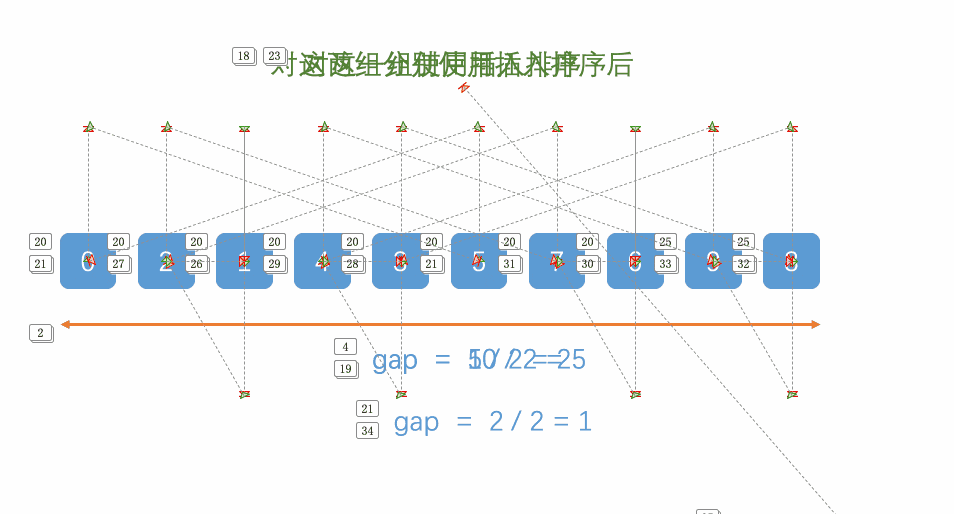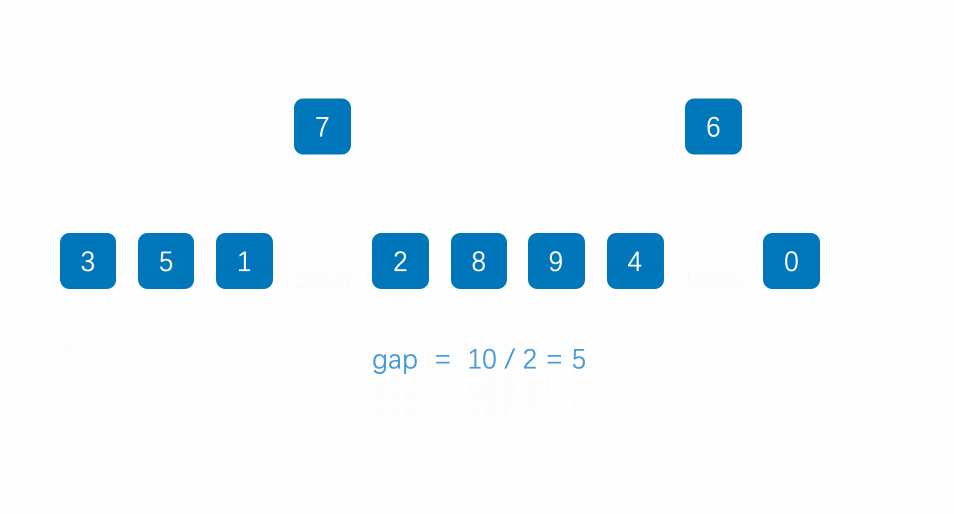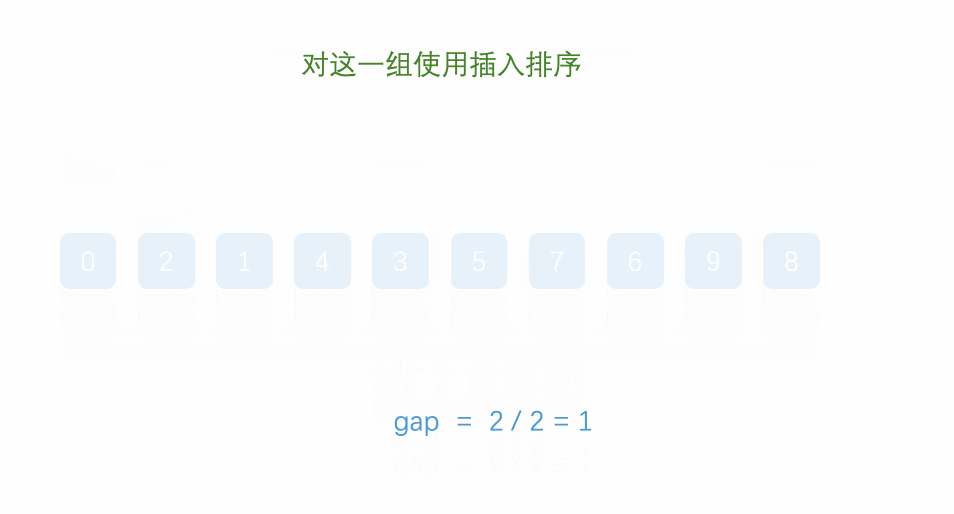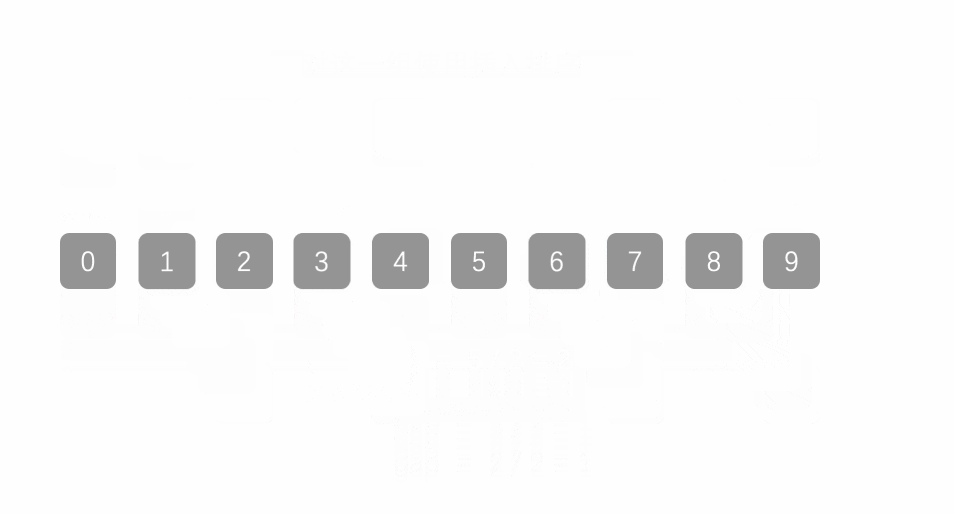
Idea básica:
1. Primero seleccione un número menor que n como el espacio, y todos los números con una distancia del espacio se agrupan en un grupo para la clasificación previa (clasificación por inserción directa)
2. Seleccione otro número menor que el espacio y repita la operación de ①
3. Cuando gap = 1, es equivalente a que toda la matriz es un grupo, y el orden general se puede ordenar insertando una vez más.
P.ej:

Implementación:
① Clasificación de un solo grupo
Es lo mismo que la inserción directa anterior, es decir, el intervalo original es 1, y ahora se convierte en un espacio, y cada grupo se preordena por separado.

②Se ordenan varios grupos

③ Ordenar toda la matriz (brecha de control)
Múltiples clasificaciones previas (brecha> 1) + una clasificación de inserción (brecha == 1)
(1) Cuanto mayor sea la brecha, más rápido será el arreglo previo y menos cerca de la orden.
(2) Cuanto menor sea la brecha, más lento será el arreglo previo y más cerca de la orden.
El resultado es:

Código general:
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap /= 2;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int x = a[end + gap];
while (end >= 0)
{
if (a[end] > x)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = x;
}
}
}Resumen de clasificación de colinas:
①Hill sort es una optimización de la ordenación por inserción directa
②Complejidad de tiempo: O(N^1.3)
③ Complejidad del espacio: O(1)
3. Clasificación de selección 
Idea básica:
Seleccione el más grande o el más pequeño de la matriz cada vez y guárdelo en el extremo derecho o izquierdo de la matriz hasta que todos estén ordenados
Implementación:
Hemos optimizado aquí En una clasificación, el número más grande (a [maxi]) y el número más pequeño (a [mini]) se seleccionan directamente y se colocan en el extremo derecho y el extremo izquierdo, de modo que la eficiencia de clasificación es el doble del original.
①Orden única
Encuentra el número más pequeño (a[mini]) y el número más grande (a[maxi]) y colócalos en el extremo izquierdo y derecho
pd: Begin y end guardan los subíndices izquierdo y derecho de los registros, y los registros mini y maxi guardan los subíndices mínimo y máximo

② Ordenar toda la matriz
begin++ y end-- para que los n-2 números restantes se puedan organizar la próxima vez, y se realice una sola pasada nuevamente, para que se pueda formar un ciclo hasta que begin sea menor que end
Código general:
void SelectSort(int* a, int n)
{
int begin = 0,end = n - 1;
while (begin<end)
{
int mini = begin, maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[mini], &a[begin]);
//当begin==maxi时,最大值会被换走,修正一下
if (begin==maxi)
{
maxi=mini;
}
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}Resumen de clasificación de selección directa:
① La clasificación de selección directa se entiende bien, pero la eficiencia real no es alta y rara vez se usa
②Complejidad de tiempo: O(N^2)
③ Complejidad del espacio: O(1)
Cuarto, ordenar en montón
Idea básica:
1. Construya la secuencia para ordenarla en un montón grande. De acuerdo con la naturaleza del montón grande, el nodo raíz (parte superior del montón) del montón actual es el elemento más grande de la secuencia;
2. Intercambie el elemento superior del montón con el último elemento y luego reconstruya los nodos restantes en un montón grande;
3. Repita el paso 2, y así sucesivamente, comenzando desde la primera construcción del montón grande, cada vez que construimos, podemos obtener el valor máximo de una secuencia y luego colocarlo en la cola del montón grande. Finalmente, se obtiene una secuencia ordenada.
Pequeña conclusión:
Ordenar en orden ascendente, construir un montón
Ordenar en orden descendente, construir un montón pequeño
Implementación:,
① Ajuste hacia abajo del algoritmo
Construimos una secuencia de matriz dada en un montón grande. Construir un montón desde el nodo raíz requiere múltiples algoritmos de ajuste hacia abajo.
Algoritmo de ajuste hacia abajo del montón (use la premisa):
(1) Si desea ajustarlo a un montón pequeño, entonces los subárboles izquierdo y derecho del nodo raíz deben ser montones pequeños.
(2) Si desea ajustarlo a un montón grande, los subárboles izquierdo y derecho del nodo raíz deben ser montones grandes.
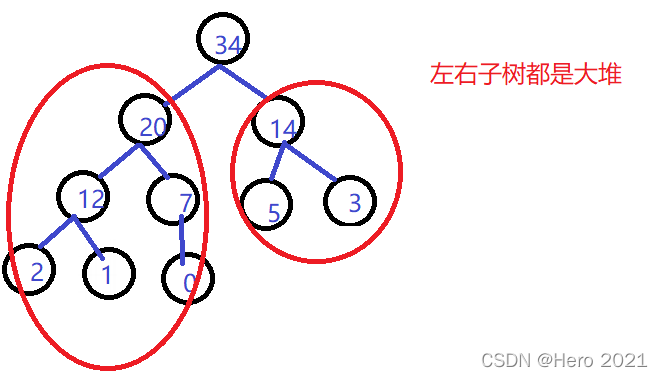
La idea básica del algoritmo de ajuste a la baja:
1. Comenzando desde el nodo raíz, seleccione el que tenga los valores secundarios izquierdo y derecho más grandes
2. Si el valor del niño seleccionado es mayor que el valor del padre, entonces intercambie los valores de los dos
3. Trate al niño mayor como el nuevo padre y continúe ajustándose hacia abajo hasta que alcance el nodo hoja

//向下调整算法
//以建大堆为例
void AdJustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
//默认左孩子较大
while (child < n)
{
if (child + 1 < n && a[child+1] > a[child ])//如果这里右孩子存在,
//且更大,那么默认较大的孩子就改为右孩子
{
child++;
}
if(a[child]>a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}②Construir un montón (construir una matriz arbitraria dada en un montón grande)
La idea de construir un montón:
Comenzando desde el penúltimo nodo que no es una hoja, de atrás hacia adelante, se usa como padre a su vez y se ajusta hacia abajo a su vez, hasta que se ajusta a la posición raíz.
Diagrama de montón:

//最后一个叶子结点的父亲为i,从后往前,依次向下调整,直到调到根的位置
for (int i = (n - 1 - 1) / 2;i>=0;--i)
{
AdJustDown(a,n,i);
}③ Clasificación de montones (usando la idea de eliminación de montones)
La idea de clasificación de montón:
1. Después de construir el montón, intercambie el número en la parte superior del montón con el último número
2. No mire el último número, y ajuste los números n-1 restantes en un montón y luego vaya al paso 1 .3. Parar hasta que solo quede un número al final, para que quede ordenado

for (int end = n - 1; end > 0; --end)
{
Swap(&a[end],&a[0]);
AdJustDown(a,end,0);
}El código general es el siguiente:
void AdJustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child+1] > a[child ])
{
child++;
}
if(a[child]>a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int*a,int n)
{
for (int i = (n - 1 - 1) / 2;i>=0;--i)
{
AdJustDown(a,n,i);
}
for (int end = n - 1; end > 0; --end)
{
Swap(&a[end],&a[0]);
AdJustDown(a,end,0);
}
}5. Clasificación de burbujas
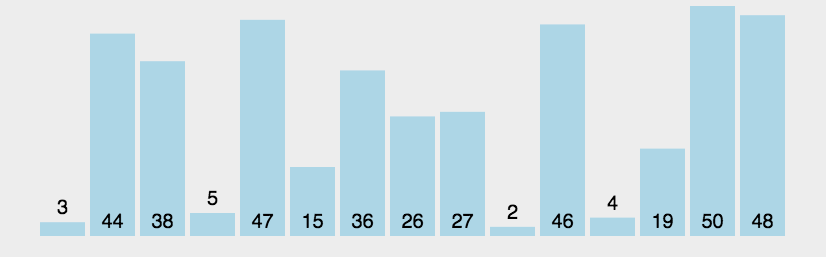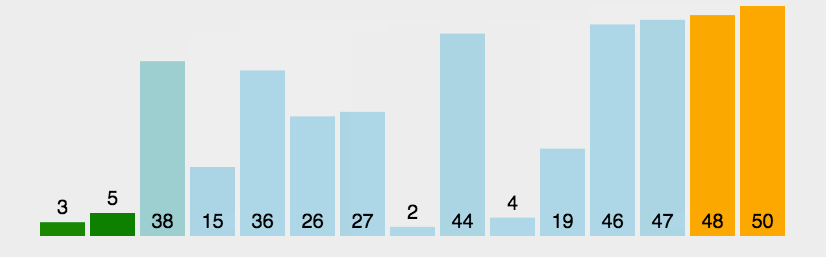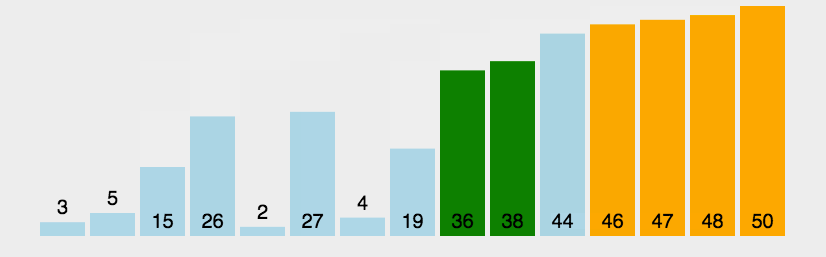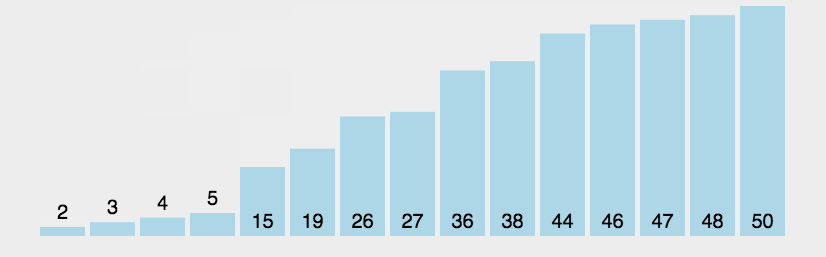
La idea básica del tipo de burbuja:
En el proceso de un viaje, los dos números anteriores y posteriores se comparan a la vez, y el número mayor se empuja hacia atrás. La próxima vez, solo se deben comparar los números n-1 restantes, y así sucesivamente.
//优化版本的冒泡排序
void BubbleSort(int* a, int n)
{
int end = n-1;
while (end>0)
{
int exchange = 0;
for (int i = 0; i < end; i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
exchange = 1;
}
}
if (exchange == 0)//单趟过程中,若没有交换过,证明已经有序,没有必要再排序
{
break;
}
end--;
}
}Resumen de clasificación de burbujas:
① Clasificación muy fácil de entender
②Complejidad de tiempo: O(N^2)
③ Complejidad del espacio: O(1)
6. Clasificación rápida
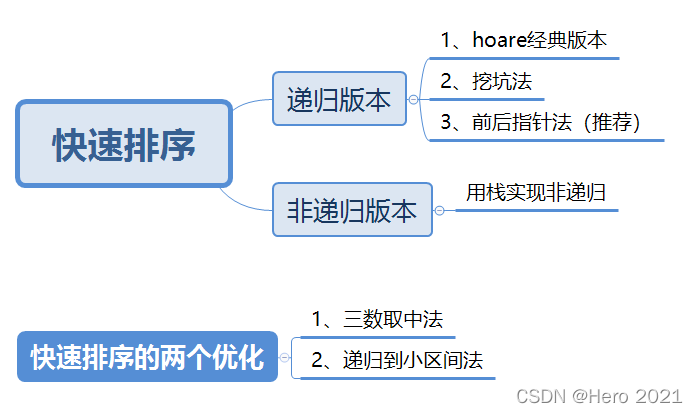
versión recursiva
1. Versión Hoare
El pensamiento unidireccional de Hoare:
1. Haga la clave a la izquierda, vaya primero a la derecha para encontrar un valor más pequeño que la clave
2. Regrese a la izquierda y encuentre un valor mayor que la clave
3. Luego intercambie los valores de izquierda y derecha
4. Repita los pasos anteriores 1 2 3 todo el tiempo
5. La posición de los dos cuando se encuentran se intercambia con el valor clave seleccionado en el extremo izquierdo
Esto pone la llave en la posición correcta.
Demostración animada: 
//hoare版本
//单趟排序 让key到正确的位置上 keyi表示key的下标,并不是该位置的值
int partion1(int* a, int left, int right)
{
int keyi = left;//左边作keyi
while (left < right)
{ //右边先走,找小于keyi的值
while (left < right && a[right] >= a[keyi])
{
right--;
}
//左边后走,找大于keyi的值
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
return left;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int keyi = partion1(a, left, right);
//[left,keyi-1] keyi [keyi+1,right]
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}2. Método de excavación
De hecho, es esencialmente una deformación de hoare
Método de excavación unidireccional:
1. Primero almacene los primeros datos en el extremo izquierdo en la clave variable temporal para formar un hoyo
2. Comience a la derecha para encontrar un valor más pequeño que la clave, y luego arroje el valor al hoyo, formando un nuevo hoyo en este momento
3. Comience desde la izquierda y encuentre un valor mayor que la clave, arroje el valor al hoyo y forme un nuevo hoyo en este momento
4. Repita los pasos 1 2 3 todo el tiempo
5. Hasta que los dos lados se encuentran, se forma un nuevo pozo y finalmente se arroja el valor clave en él.
De esta forma la llave ha llegado a la posición correcta
Demostración animada:

//挖坑法
int partion2(int* a, int left, int right)
{
int key = a[left];
int pit = left;
while (left < right)
{
while (left < right && a[right] >= key)
{
right--;
}
a[pit] = a[right];//填坑
pit=right;
while (left < right && a[left] <= key)
{
left++;
}
a[pit] = a[left];//填坑
pit=left;
}
a[pit] = key;
return pit;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int keyi = partion2(a, left, right);
//[left,keyi-1] keyi [keyi+1,right]
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}3. Método de puntero delantero y trasero (recomendado de esta forma de escritura)
La idea de los punteros delantero y trasero:
1. Inicialmente, seleccione anterior como el inicio de la secuencia, el puntero actual apunta a la siguiente posición de anterior, y también seleccione el primer número a la izquierda como clave
2. Cur va primero, encuentra un valor menor que la clave y se detiene cuando lo encuentra
3、++anterior
4. Intercambiar prev y cur como valores de subíndice
5. Repita los pasos 2 3 4 en un bucle. Después de detenerse, finalmente intercambie key y prev como valor de subíndice
De esta forma la llave también llega a la posición correcta
Demostración animada:

int partion3(int* a, int left, int right)
{
int prev = left;
int cur = left + 1;
int keyi = left;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)//prev != cur 防止cur和prev相等时,相当于自己和自己交换,可以省略
{ //前置 ++ 的优先级大于 != 不等于的优先级
Swap(&a[prev], &a[cur]);
}
++cur;
}
Swap(&a[keyi], &a[prev]);
return prev;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int keyi = partion3(a, left, right);
//[left,keyi-1] keyi [keyi+1,right]
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}Gráfico de expansión recursivo
Optimización de clasificación rápida
1. Método chino de tres números
La ordenación rápida es sensible a los datos. Si la secuencia es muy desordenada y caótica, entonces la eficiencia de la ordenación rápida es muy alta, pero si la secuencia está en orden, la complejidad del tiempo cambiará de O(N*logN) a O(N ^2), equivalente a la ordenación de burbuja
Si la clave seleccionada para cada clasificación es exactamente el valor medio de la secuencia, es decir, la clave se encuentra en el medio de la secuencia después de una única clasificación, entonces la complejidad temporal de la clasificación rápida es O(NlogN)
Pero esta es una situación ideal, cuando nos enfrentamos a un conjunto de secuencias en casos extremos, que son matrices ordenadas, si elegimos el lado izquierdo como valor clave, entonces degenerará en una complejidad O(N^2), por lo que En este momento, seleccionamos la primera posición, la posición de la cola y el número en la posición media como tres números, seleccionamos el número en la posición media y lo colocamos en el extremo izquierdo. De esta manera, la selección de teclas comienza desde el lado izquierdo Después de la optimización, todo se convierte en una situación ideal.

//快排的优化
//三数取中法
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[right])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[mid] > a[right])
{
return right;
}
else
{
return left;
}
}
else
{
if (a[mid] > a[left])
{
return left;
}
else if (a[mid] < a[right])
{
return right;
}
else
{
return mid;
}
}
}
int partion5(int* a, int left, int right)
{
//三数取中,面对有序时是最坏的情况O(N^2),现在每次选的key都是中间值,变成最好的情况了
int midi = GetMidIndex(a, left, right);
Swap(&a[midi], &a[left]);//这样还是最左边作为key
int prev = left;
int cur = left + 1;
int keyi = left;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)//prev != cur 防止cur和prev相等时,相当于自己和自己交换,可以省略
{ //前置 ++ 的优先级大于 != 不等于的优先级
//++prev;
Swap(&a[prev], &a[cur]);
}
++cur;
}
Swap(&a[keyi], &a[prev]);
return prev;
}2. Recursión a pequeños subintervalos
A medida que aumenta la profundidad de recurrencia, el número de recurrencias aumenta a una tasa de 2 veces por capa, lo que tiene un gran impacto en la eficiencia.Cuando la longitud de la secuencia que se va a clasificar se divide en un cierto tamaño, la eficiencia de continuar dividir es peor que el de la clasificación por inserción. Puede usar insertar fila en lugar de fila rápida
Podemos usar la ordenación por inserción para ordenar los números restantes cuando la longitud del intervalo dividido es inferior a 10
//小区间优化法,可以采用直接插入排序
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
if (right - left + 1 < 10)
{
InsertSort(a + left, right - left + 1);
}
else
{
int keyi = partion5(a, left, right);
//[left,keyi-1] keyi [keyi+1,right]
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
}versión no recursiva
El algoritmo recursivo divide principalmente subintervalos. Si desea implementar una clasificación rápida de forma no recursiva, solo necesita usar una pila para guardar el intervalo. Generalmente, lo primero que viene a la mente al cambiar un programa recursivo a uno no recursivo es usar una pila, porque la recursividad en sí misma es un proceso de empujar una pila.
La idea básica de la no recursividad:
1. Solicite una pila para almacenar las posiciones inicial y final de la matriz ordenada.
2. Empuje las posiciones inicial y final de toda la matriz en la pila.
3. Dado que las características de la pila son: el último en entrar, el primero en salir, la derecha vuelve a la pila, por lo que la derecha sale primero de la pila.
Defina un final para recibir el elemento superior de la pila y saque la pila, y defina un comienzo para recibir el elemento superior de la pila y saque la pila.
4. Ordene la matriz en un solo paso y devuelva el subíndice del valor clave.
5. En este momento, es necesario organizar la secuencia a la izquierda de la tecla de valor de referencia.
Si solo la posición inicial y la posición final de la secuencia en el lado izquierdo de la clave de valor de referencia se almacenan en la pila, el siguiente intervalo no se encontrará cuando se ordene el lado izquierdo. Así que primero almacene la posición inicial y la posición final de la secuencia de la derecha en la pila, y luego almacene la posición inicial y la posición final de la secuencia izquierda en la pila.
6. Determine si la pila está vacía, de lo contrario, repita los pasos 4 y 5. Si está vacía, la clasificación está completa.
void QuickSortNonR(int* a, int left, int right)
{
Stack st;
StackInit(&st);
StackPush(&st,left);
StackPush(&st, right);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
int keyi = partion5(a,begin,end);
//区间被成两部分了 [begin,keyi-1] keyi [keyi+1,end]
if (keyi + 1 < end)
{
StackPush(&st,keyi+1);
StackPush(&st,end);
}
if (keyi-1>begin)
{
StackPush(&st, begin);
StackPush(&st, keyi -1);
}
}
StackDestroy(&st);
}Resumen de clasificación rápida:
① Los escenarios generales de rendimiento y uso integrales de quicksort son relativamente buenos, por lo que nos atrevemos a llamarlo quicksort
②El único callejón sin salida de la clasificación rápida es clasificar algunas secuencias ordenadas o casi ordenadas, como 2,3,2,3,2,3,2,3, que se convertirán en una complejidad de tiempo O(N^2)
③Complejidad de tiempo O(N*logN)
④ Complejidad espacial O(logN)
Siete, ordenar por fusión
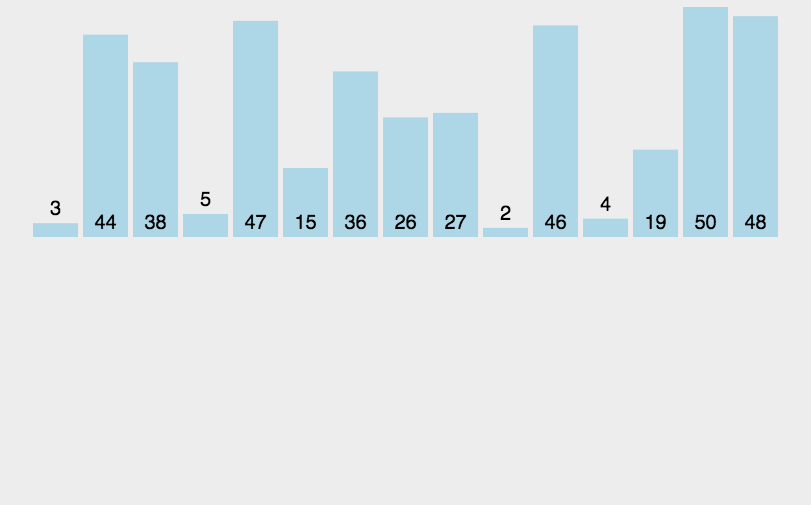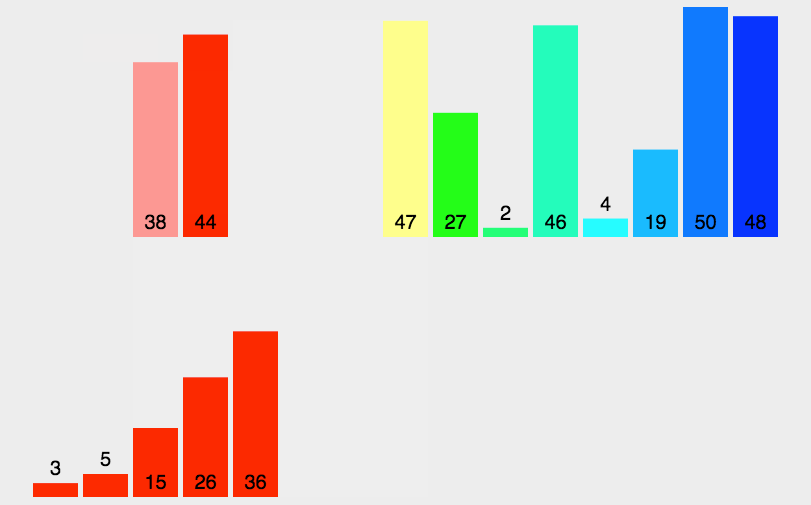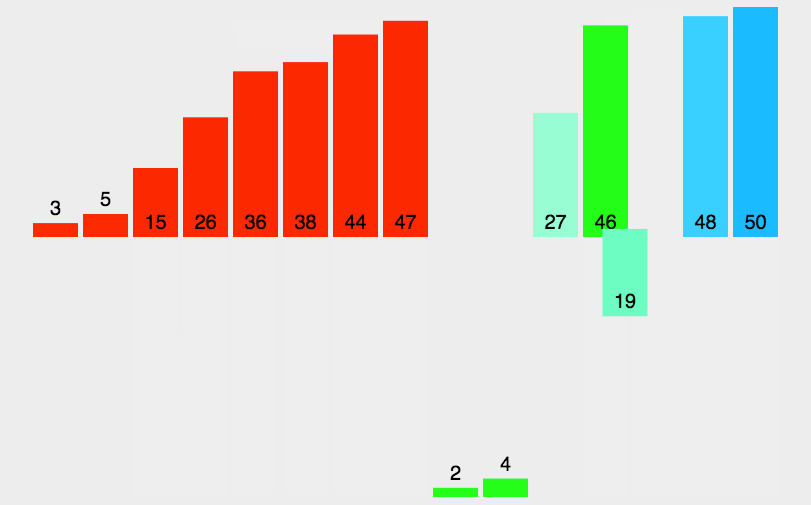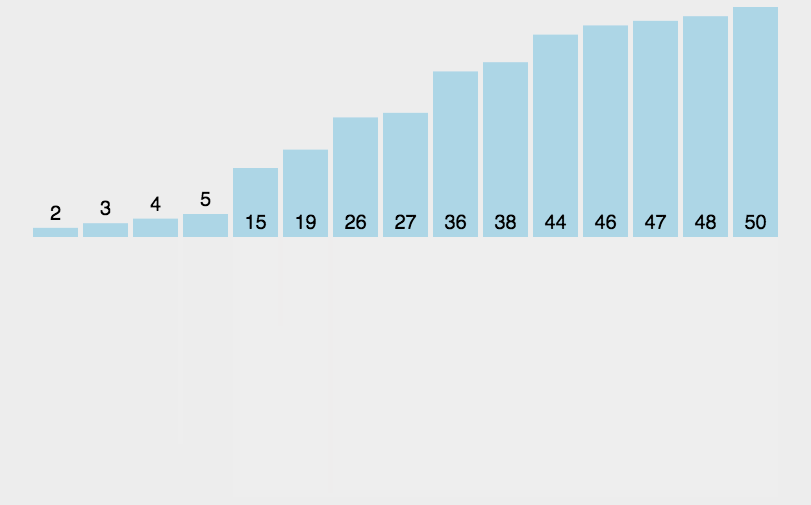
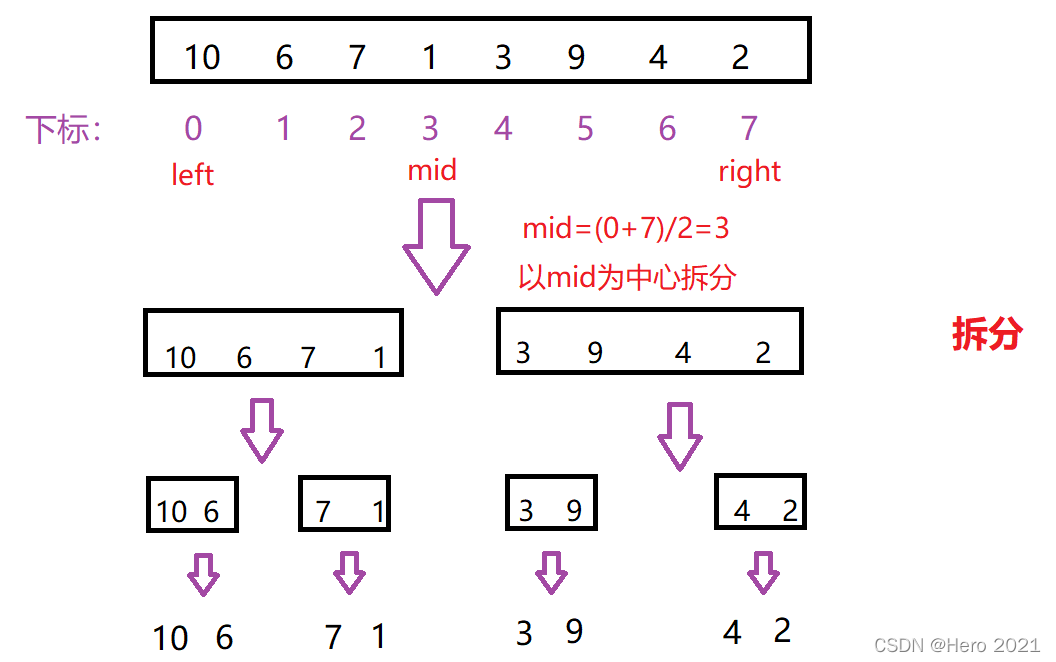
La idea básica de merge sort (idea de divide y vencerás):
1. ( Dividir ) Divida una matriz en una secuencia izquierda y una secuencia derecha, permita que ambas se ordenen por separado y luego subdivida la secuencia izquierda en una secuencia izquierda y una secuencia derecha, y repita este paso hasta que la subdivisión no exista en el intervalo o hasta que solo quede un número
2. ( Combinar ) Combinar los números obtenidos en el primer paso en un intervalo ordenado
Implementación:
① Dividir
②Fusionar

Implementación recursiva:
Es muy similar a un árbol binario en idea, por lo que podemos usar un método recursivo para implementar la ordenación por fusión
el código se muestra a continuación:
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
{
return;
}
int mid = (left + right) / 2;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid+1, right, tmp);
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
for (int j = left; j <= right; j++)
{
a[j] = tmp[j];
}
}
//归并排序
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int)*n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
_MergeSort(a,0,n-1,tmp);
free(tmp);
tmp = NULL;
}Implementación no recursiva:
Sabemos que la desventaja de la implementación recursiva es que siempre se llamará a la pila y la memoria de la pila suele ser muy pequeña. Entonces, tratamos de usar el método de bucle para lograr
Dado que estamos manipulando el subíndice del arreglo, necesitamos usar el arreglo para ayudarnos a almacenar el subíndice del arreglo obtenido recursivamente arriba. La diferencia con la recursividad es que la recursividad tiene que subdividir el intervalo todo el tiempo, y el intervalo de la izquierda tiene que ser dividido recursivamente. , y luego divide recursivamente el intervalo correcto, y la no recursividad de la matriz es procesar los datos a la vez, y copiar el subíndice nuevamente a la matriz original cada vez
La idea básica de la ordenación por fusión es considerar la secuencia a ordenar a[0...n-1] como n secuencias ordenadas de longitud 1, y fusionar listas ordenadas adyacentes en pares para obtener n/2 longitud 2 La lista ordenada de ; fusiona estas secuencias ordenadas nuevamente para obtener n/4 secuencias ordenadas de longitud 4; y así sucesivamente, y finalmente obtiene una secuencia ordenada de longitud n.

Pero estamos en una situación ideal (número par), y hay controles de límite especiales.Cuando el número de datos no es un número par, los grupos de brecha que dividimos están obligados a tener lugares fuera de los límites.
El primer caso:

Segundo caso:

el código se muestra a continuación:
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int)*n);
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
// [i,i+gap-1] [i+gap,i+2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// 核心思想:end1、begin2、end2都有可能越界
// end1越界 或者 begin2 越界都不需要归并
if (end1 >= n || begin2 >= n)
{
break;
}
// end2 越界,需要归并,修正end2
if (end2 >= n)
{
end2 = n- 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
// 把归并小区间拷贝回原数组
for (int j = i; j <= end2; ++j)
{
a[j] = tmp[j];
}
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}
Resumen de la ordenación por combinación:
①La desventaja es que requiere una complejidad de espacio O(N), y la ordenación por fusión es más para resolver el problema de la ordenación fuera del disco
②Complejidad de tiempo: O(N*logN)
③ Complejidad del espacio: O(N)
Ocho, contando y clasificando
También conocido como clasificación no comparativa, también conocido como principio de casillero, es una aplicación variante del método de direccionamiento directo hash
Idea básica:
1. Contar el número de ocurrencias del mismo elemento
2. De acuerdo con los resultados estadísticos, copie los datos nuevamente a la matriz original
Implementación:
① Cuente el número de ocurrencias del mismo elemento
Para un arreglo arbitrario dado a, necesitamos abrir un arreglo de conteo conteo, a[i] es unos pocos, y el subíndice del arreglo de conteo es unos pocos ++

Aquí usamos el mapeo absoluto, es decir, el elemento de la matriz en a[i] es unos pocos, y estamos en la posición donde el subíndice de la matriz de conteo es unos pocos ++, pero para la agregación de datos, no comienza desde un número más pequeño, como 1001. Para datos como 1002, 1003 y 1004, podemos usar el método de mapeo relativo para evitar el desperdicio de abrir espacio de matriz. El tamaño del espacio de la matriz de conteo se puede determinar restando el mínimo value + 1 del valor máximo en la matriz a (es decir, range=max-min+1), podemos obtener el subíndice de la matriz de conteo j =a[i]-min

② De acuerdo con el resultado de la matriz de conteo, copie los datos nuevamente en una matriz
El número de datos en cuenta[j] indica cuántas veces ha aparecido el número, si es 0 no es necesario copiarlo

el código se muestra a continuación:
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];//如果不赋值,min和max就是默认随机值,最好给赋值一个a[0]
for (int i=1;i<n;i++)//修正 找出A数组中的最大值和最小值
{
if (a[i] < min)
{
min=a[i];
}
if (a[i]>max)
{
max=a[i];
}
}
int range = max - min + 1;//控制新开数组的大小,以免空间浪费
int* count = (int*)malloc(sizeof(int) * range);
memset(count,0, sizeof(int) * range);//初始化为全0
if (count==NULL)
{
printf("malloc fail\n");
exit(-1);
}
//1、统计数据个数
for (int i=0;i<n;i++)
{
count[a[i]-min]++;
}
//2、拷贝回A数组
int j = 0;
for (int i=0;i<range;i++)
{
while (count[i]--)
{
a[j++] = i + min;
}
}
free(count);
count = NULL;
}Resumen de clasificación de conteo:
①Cuando el rango de datos está relativamente concentrado, la eficiencia es muy alta, pero los escenarios de uso son muy limitados, se pueden organizar números negativos, pero no se puede hacer nada con los números de punto flotante
②Complejidad de tiempo: O(MAX(N,rango))
③ Complejidad del espacio: O (rango)
El resumen de estabilidad de los ocho tipos:
Las clasificaciones estables son: clasificación por inserción directa, clasificación por burbuja, clasificación por fusión
La clasificación inestable incluye: clasificación por colinas, clasificación por selección, clasificación por montones, clasificación rápida, clasificación por conteo