Tipo de inserción directa
- Insertar un elemento en una matriz ordenada se puede usar como base de un método de clasificación
- Un conjunto con un solo elemento es un conjunto ordenado. Para un conjunto de n elementos, puede comenzar desde el conjunto de unidades formado por el primer elemento e implementar continuamente la operación de inserción
- Inserte el segundo elemento para obtener una matriz ordenada de 2 elementos. Inserte el tercer elemento para obtener una matriz ordenada de 3 elementos
- Repita de esta manera para obtener una matriz ordenada de n elementos
Ejemplos
Inserte directamente la secuencia: 6, 5, 8, 4, 3, 1
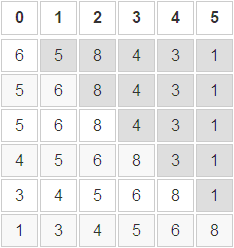
- La parte gris en la figura representa la secuencia a ordenar
- La parte transparente en la figura representa la secuencia ordenada
int main () { int a [ 10 ] = { 6 , 5 , 8 , 4 , 3 , 7 }; int temp, j; para ( int i = 1 ; i < 6 ; ++ i) { temp = a [i]; para (j = i - 1 ; j> = 0 && temp <a [j]; - j) { a [j + 1 ] = a [j]; } a [j + 1] = temp; } j = 0 ; while (j < 6 ) { printf ( " % d " , a [j]); ++ j; } devuelve 0 ; }
Análisis de la complejidad del tiempo.
Seleccione la capa más interna insertando el código de clasificación directamente
a [j + 1 ] = a [j];
Como una declaración de operación básica
- Considere el peor de los casos, donde se invierte toda la secuencia, O (n ^ 2)
- Considere el mejor caso donde se ordena toda la secuencia, O (n)
En resumen, la complejidad de tiempo promedio de este algoritmo es O (n ^ 2)
Análisis de complejidad espacial.
- El espacio de almacenamiento auxiliar requerido por el algoritmo no cambia con el tamaño de la secuencia a clasificar, es una constante, O (1)
Tipo de media inserción
- Similar a la idea de la clasificación por inserción directa, la diferencia es que el método para encontrar la posición de inserción es diferente, y la clasificación por mitad de inserción utiliza el método de media búsqueda para encontrar la posición de inserción
- Busque la posición de inserción del registro R [i] en la secuencia ordenada por media búsqueda
Ejemplos
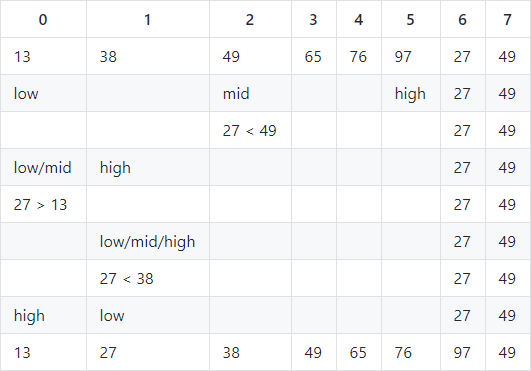
La secuencia: 13,38,49,65,76,97,27,49 es una secuencia de medio inserto.
Los primeros 6 elementos han sido secuenciados, encuentre la posición de inserción de 27
- mid = (0 + 5) / 2 = 2, la posición actual, 27 <49, la posición de inserción de 27 está en la mitad inferior de 49
- h = mid-1, mid = (0 + 1) / 2 = 0, posición actual, 27> 13, la posición de inserción 27 está en la mitad superior de 13
- bajo = medio + 1, medio = (1 + 1) / 2 = 1, 27 <38, la posición de inserción de 27 está en la mitad inferior de 38
- high = m-1 = 0, high <low, la mitad de la búsqueda finaliza, la posición de inserción de 27 es después de high, y el elemento detrás de la posición de inserción se mueve hacia atrás
int main () { // a [0] es la ubicación donde se almacena la variable temporal int a [ 9 ] = { 0 , 13 , 38 , 49 , 65 , 76 , 97 , 27 , 49 }; int low, high, mid; para ( int i = 2 ; i <= 8 ; ++ i) { a [ 0 ] = a [i]; bajo = 1 ; alto = i- 1 ; while (bajo <= alto) { medio = (bajo + alto) / 2 ; if (a [mid]> a [ 0 ]) { high = mid - 1 ; } else { bajo = medio + 1 ; } } para ( int j = i - 1 ; j> = alto + 1 ; - j) { a [j + 1 ] = a [j]; } a [alto + 1] = a [ 0 ]; } int j = 0 ; while (j < 8 ) { printf ( " % d " , a [j]); ++ j; } devuelve 0 ; }
Análisis de la complejidad del tiempo.
- La clasificación por inserción binaria es adecuada para escenas con una gran cantidad de palabras clave. En comparación con la clasificación por inserción directa, el tiempo dedicado a la clasificación por inserción a la mitad para encontrar la posición de inserción se reduce considerablemente
- La ordenación de media inserción es igual a la ordenación de inserción directa en el número de movimientos de palabras clave, por lo que la complejidad temporal es la misma que la ordenación de inserción directa
- Se puede ver que el mejor caso de la complejidad temporal del tipo de media inserción es O (nlog2n), el peor caso es O (n ^ 2), y el caso promedio es O (n ^ 2)
Análisis de complejidad espacial.
Igual que el tipo de inserción directa, O (1)
Clasificación de colinas (clasificación incremental más pequeña)
-
Divida la secuencia a ordenar en varias subsecuencias, e inserte y clasifique estas subsecuencias directamente
-
Si el incremento es 1, inserte ordenar directamente
Este método es esencialmente un método de inserción de paquetes
- Comparar números que están muy separados (llamados deltas), de modo que cuando el número se mueve a través de múltiples elementos, una sola comparación puede eliminar intercambios de múltiples elementos
Idea de algoritmo
-
Primero divida el grupo de números que se ordenarán en varios grupos de acuerdo con un incremento d, y los subíndices registrados en cada grupo difieren en d
-
Ordene todos los elementos en cada grupo, y luego use un pequeño incremento para ordenarlo, y luego ordene en cada grupo
-
Cuando el incremento se reduce a 1, el número entero a ordenar se divide en un grupo, la clasificación se completa
Ejemplos
- Secuencia original: 49 38 65 97 76 13 27 45 55 04

- Los elementos señalados por la línea divisoria se insertan y ordenan directamente
anular ShellSort ( int r [], int n) { int i, j, d; int x; d = n / 2 ; // d = n >> 1 while (d> = 1 ) { para (i = d; i <n; i ++ ) { x = r [i]; para (j = id; j> = 0 ; j- = d) { if (r [j]> x) { r [j + d] = r [j]; } else { descanso ; } } r [j + d] = x; } // para i d >> = 1 ; } // while } // ShellSort
La clasificación de las colinas es inestable.
-
El último valor de la secuencia de incremento debe ser 1
-
Los valores en la secuencia incremental no deben tener un factor común que no sea 1
Complejidad de tiempo
- El tiempo está relacionado con la selección del tamaño del paso, pero actualmente no hay una expresión analítica correspondiente