Este artículo se reprodujo por primera vez en la cuenta pública de Nebula Graph Community

Introducción: En los últimos años, los datos gráficos han sido ampliamente utilizados en el campo de la informática. La cantidad de datos de Internet ha crecido exponencialmente, y la aplicación de tecnología de big data y datos gráficos ha crecido rápidamente.Todas las principales empresas de Internet han invertido una gran cantidad de mano de obra y recursos materiales en el análisis y la aplicación de datos gráficos. Para que nuestra búsqueda sea más inteligente, Tencent Music también utiliza el gráfico de conocimiento. Hoy, compartiré con ustedes la exploración de Tencent Music sobre la recuperación de gráficos y la práctica comercial, que incluye principalmente las siguientes partes:
- Gráfico de conocimiento de introducción a la música
- Selección de base de datos de gráficos
- Introducción a la arquitectura del proyecto
- Ejemplo de aplicación de la función de búsqueda de gráfico de conocimiento
- Resumen y Outlook
Gráfico de conocimiento de introducción a la música
En primer lugar, permítanme presentarles el conocimiento relevante del mapa de conocimiento musical.
1. Clasificación de datos musicales
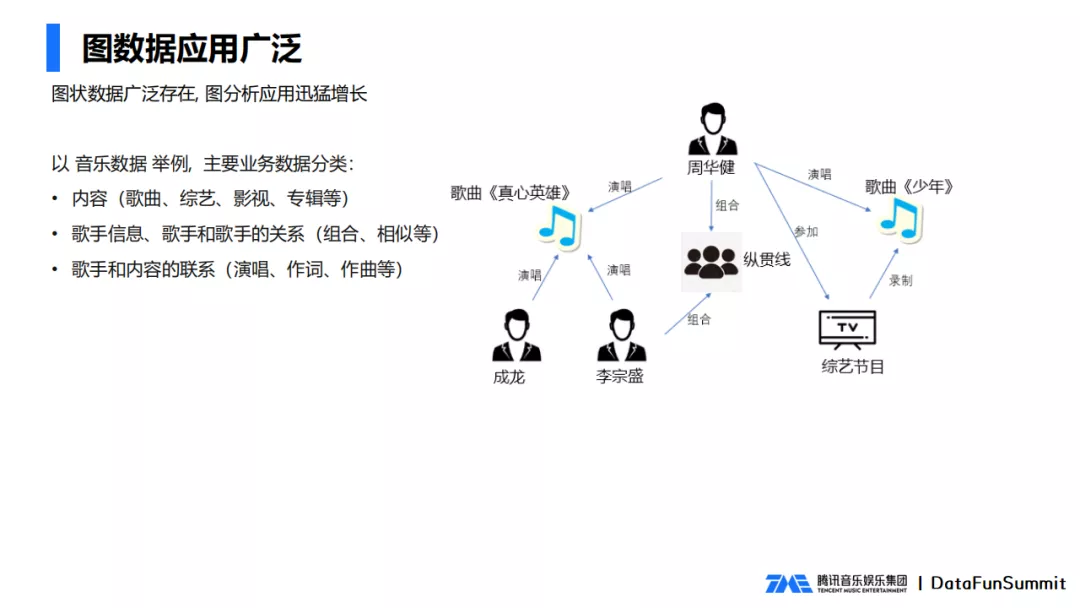
Los datos gráficos existen ampliamente, entre los cuales los datos comerciales relacionados con la música se clasifican principalmente en las siguientes tres categorías:
- En cuanto al contenido, hay canciones, programas de variedades, películas, discos, etc.;
- Para los cantantes, hay información del cantante y la relación entre los cantantes, incluida la combinación, la similitud, etc.;
- La relación entre cantante y contenido de cantante incluye cantar, escribir letras, componer, etc.
2. Escenarios de aplicación de Music Knowledge Graph
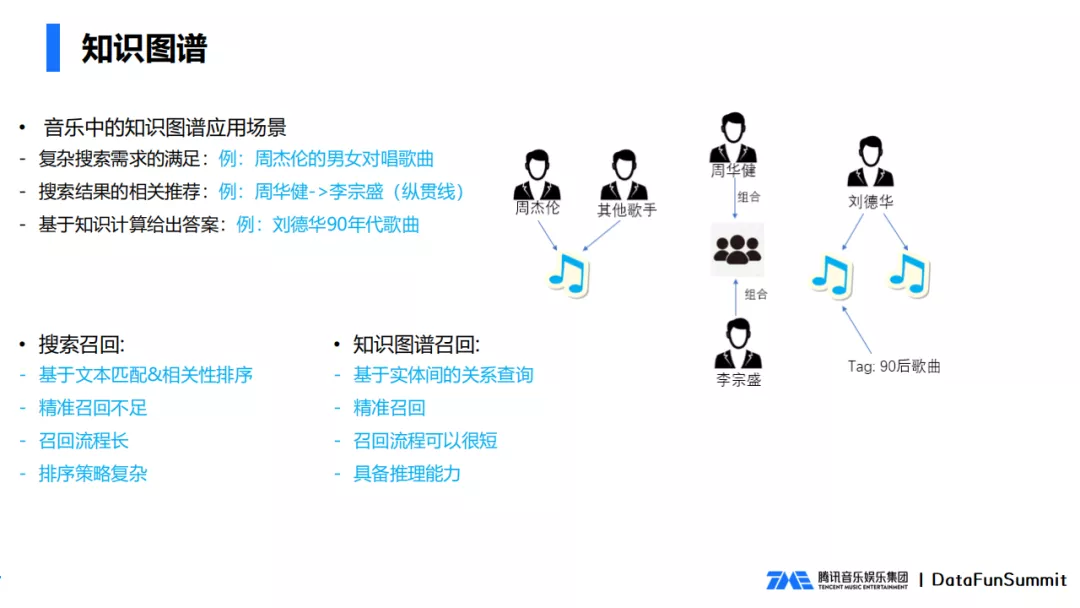
(1) Realización de requisitos de búsqueda complejos
El gráfico de conocimiento musical no solo puede realizar búsquedas simples, sino también cumplir requisitos de búsqueda complejos. Por ejemplo, si desea consultar las canciones de Jay Chou debido a hombres y mujeres, si desea implementar esta consulta, debe filtrar las canciones de Jay Chou, el número de cantantes debe ser igual a 2 y el género del otro cantante es mujer. , cantante de pesos, etc. Es muy complicado realizar esta función en los datos relacionales tradicionales. Es relativamente simple usar el mapa de conocimiento. Primero, encuentre al cantante Jay Chou, encuentre todas las canciones de Jay Chou que satisfagan el coro de 2 personas, y el género del otro cantante es femenino, y las consultas de búsqueda complejas se pueden realizar con solo dos saltos
(2) Recomendaciones relacionadas con los resultados de búsqueda
Los nodos de entidad en el gráfico se pueden consultar de acuerdo con las palabras clave buscadas, los nodos asociados se pueden consultar de acuerdo con los nodos de entidad y los resultados recomendados se pueden obtener mediante los nodos asociados. Por ejemplo, si un usuario busca Zhou Huajian, puede recomendar a Li Zongsheng a través de información relacionada. Si usa un motor de búsqueda, es difícil recomendar a Li Zongsheng, pero usando el mapa de conocimiento, solo toma dos saltos, el cantante de Zhou Huajian al grupo correspondiente (línea vertical), del grupo a otro cantante Li Zongsheng, solo dos salta
(3) Respuesta basada en el cálculo del conocimiento
Se pueden dar algunas respuestas de acuerdo con los resultados del cálculo del gráfico de conocimiento, y las respuestas correspondientes se pueden consultar a través de la información asociada del gráfico, la información superior e inferior de la entidad y la información del atributo de la entidad. Por ejemplo, si un usuario busca las canciones de Andy Lau en la década de 1990, utilizando el gráfico de conocimiento, siempre que el cantante Andy Lau; las canciones de la década de 1990, las dos se pueden combinar para obtener el resultado.
3. Ventajas y desventajas de la recuperación de búsqueda y la recuperación de gráfico de conocimiento
La búsqueda y el recuerdo se basan en la coincidencia de texto. Después del recuerdo, implicará la clasificación por correlación, que es relativamente compleja, carece de precisión y puede recordar demasiado. El proceso de búsqueda y recuperación es más complicado, y la estrategia de clasificación también es relativamente complicada.
La recuperación de gráficos de conocimiento es una consulta basada en la relación entre entidades, que puede lograr una recuperación precisa, y el proceso de recuperación puede ser muy corto, es decir, varias oraciones de consulta de gráficos. Además, el gráfico de conocimiento también tiene cierta capacidad de razonamiento.
Selección de base de datos de gráficos
Para implementar la consulta de gráficos, primero debe seleccionar la base de datos de gráficos.
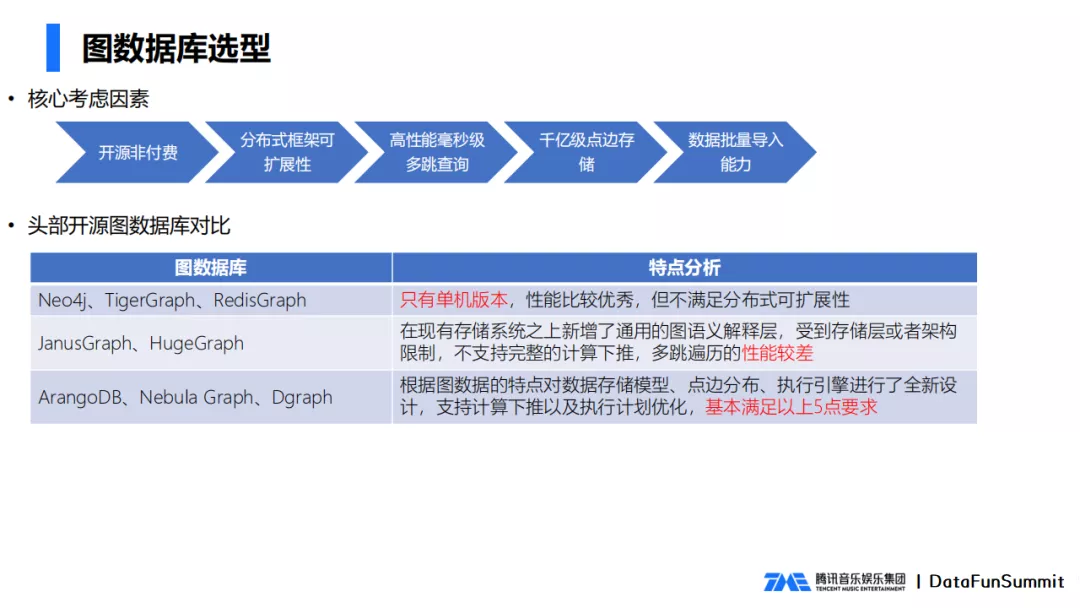
Al seleccionar una base de datos de gráficos, se deben considerar los siguientes factores:
- El código abierto no se paga, teniendo en cuenta el costo y la capacidad de control del código fuente, opte por adoptar el código abierto;
- El marco distribuido es escalable y el backend debe ser escalable a medida que los datos aumentan y disminuyen;
- Consulta de saltos múltiples de nivel de milisegundos de alto rendimiento, para lograr una respuesta en línea de nivel de milisegundos;
- Admite cientos de miles de millones de volúmenes de datos;
- Admite la importación y exportación de datos por lotes.
Comparamos 8 bases de datos, analizamos las ventajas y desventajas y clasificamos estas bases de datos:
- La primera categoría, representada por Neo4j, tiene solo una versión independiente con excelente rendimiento, pero no cumple con los requisitos de escalabilidad distribuida. La versión comercial de Neo4j admite la distribución, pero hay una tarifa.
- La segunda categoría, bases de datos como JanusGraph y HugeGraph, admiten escalabilidad distribuida. Su característica común es que se agrega una capa de interpretación semántica general del gráfico al gráfico existente, que está limitada por la arquitectura de la capa de almacenamiento (la capa de almacenamiento está implementada por una base de datos externa).), no es compatible con la función de pushdown informático, lo que resulta en un rendimiento deficiente.
- La tercera categoría, representada por Nebula Graph, ha implementado su propia capa de almacenamiento, admite la reducción del cálculo, la eficiencia optimizada y el rendimiento mejorado mucho.
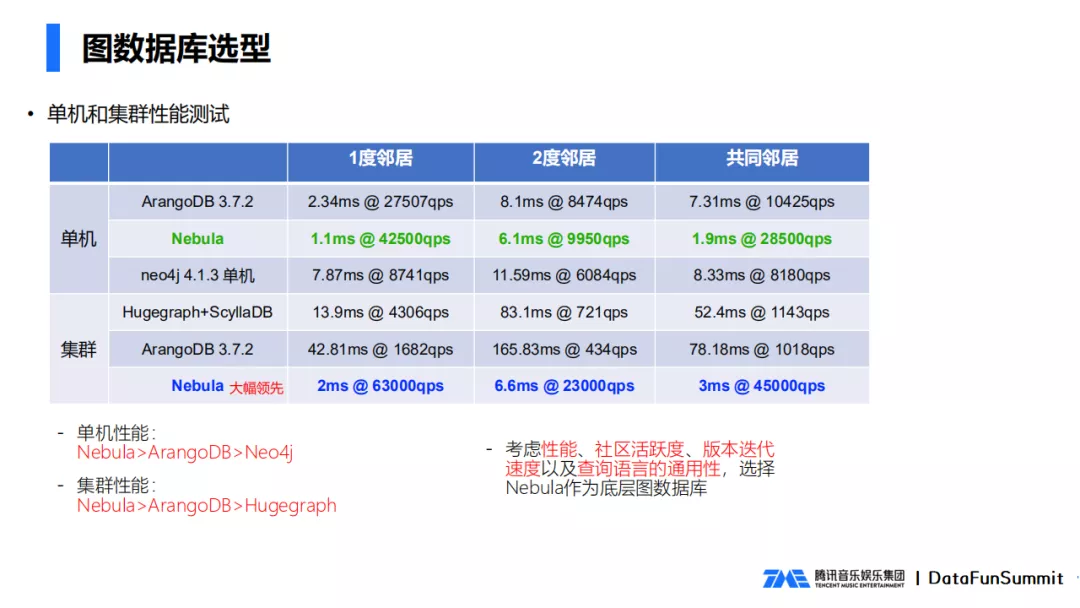
Consulte los datos completos de la prueba de rendimiento de la figura anterior. Probamos el rendimiento de la base de datos a través de vecinos de 1 grado (puntos conectados directamente a un punto), vecinos de 2 grados y vecinos comunes. Podemos ver que Nebula Graph es muy superior tanto al rendimiento independiente como al rendimiento del clúster. productos Teniendo en cuenta el rendimiento, la actividad de la comunidad, la velocidad de iteración de la versión y la versatilidad del lenguaje, finalmente elegimos Nebula Graph como la base de datos de gráficos para nuestro proyecto.
Introducción a la arquitectura del proyecto
1. Capa en línea
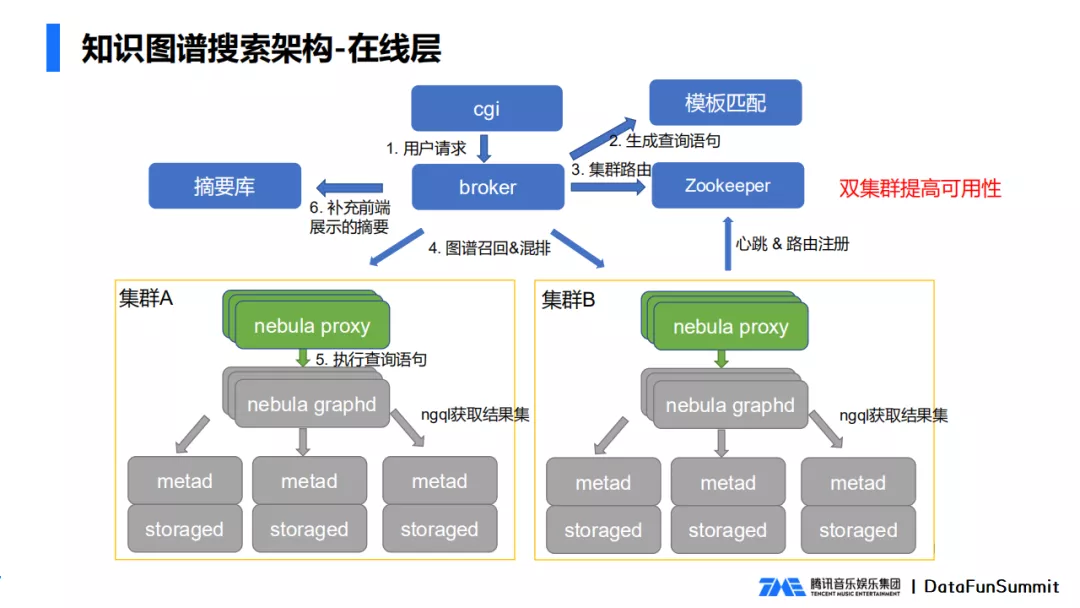
Contiene los siguientes módulos:
- storaged es responsable del almacenamiento de datos específicos, incluidos datos de puntos, datos de borde e índices relacionados;
- metad es responsable de almacenar la metainformación de los datos gráficos, como el esquema de la base de datos, la adición, etc.;
- Nebula graphd es responsable de la capa lógica de cálculo de datos. No tiene estado y se puede expandir en paralelo. El motor de cálculo de ejecución interno se utiliza para completar todo el proceso de consulta.
- Nebula proxy es nuestro módulo recién agregado. Como la capa de proxy de todo el módulo de nebula, puede aceptar comandos externos y operar en datos gráficos, incluida la consulta, actualización y eliminación de gráficos. Además, nebula proxy también es responsable de la conversión de protocolos, el latido del clúster y el registro de rutas.
Dado que un solo clúster necesita reconstruir los datos y evitar fallas en la sala de computadoras, elegimos clústeres duales para respaldar la disponibilidad de todo el servicio.
El proceso de procesamiento de solicitud de capa en línea es que después de que cgi recibe la solicitud del usuario, pasa la solicitud del usuario al módulo del intermediario y la plantilla de solicitud del intermediario coincide para generar la declaración de consulta gráfica correspondiente, extrae los clústeres disponibles de Zookeeper y envía el declaración de consulta al proxy de nebula. Para la recuperación de gráficos, el proxy de nebula pasa la declaración de consulta específica a nebula graphd, nebula graphd es responsable de ejecutar la declaración final y luego devuelve el resultado a la capa de intermediario. Después de que la capa de intermediario agrega algunos front- resúmenes de visualización final, devuelve los datos al front-end para su visualización.
2. Capa sin conexión
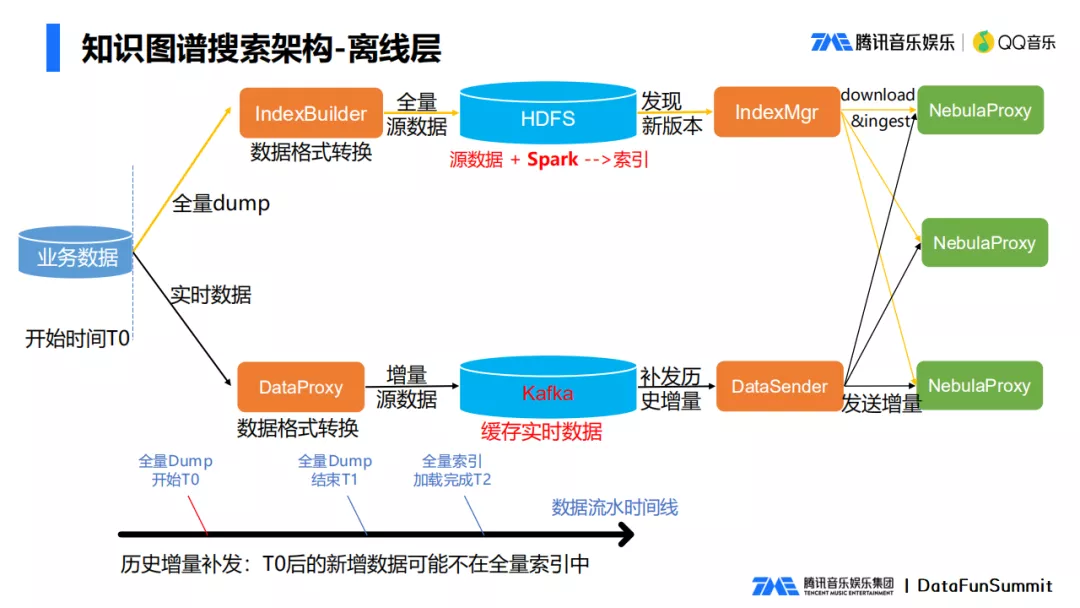
Los datos de música tienen datos nuevos en tiempo real, como álbumes recién lanzados y actualizaciones completas de datos, por lo que elegimos la solución de capa de datos completa e incremental.
(1) esquema completo de generación de datos
Una gran cantidad de datos de música se almacenan en la base de datos. Después de descargar los datos de la base de datos, el módulo IndexBuilder convierte el formato de datos al formato requerido para formar una fuente de datos completa. Después de cargar la fuente de datos completa en HDFS, ejecute Spark La tarea es convertir los datos en el archivo de datos requerido por la capa inferior de Nebula Graph. Después de que IndexMgr encuentra que se generan nuevos datos constantes, descarga el archivo de datos y carga la cantidad total de datos en NebulaProxy, de modo que la cantidad total de datos es generado.
(2) Generación de datos en tiempo real
De vez en cuando, generalmente unos minutos, después de que se vuelcan los datos de modificación comercial dentro de unos minutos, se convierte a un formato específico para formar una fuente de datos incremental, y la fuente de datos incremental se almacena en Kafka, que se puede utilizado Para la retransmisión y recuperación de datos, DataSender extrae los datos más recientes de la cola de Kafka y los envía al clúster a través de NebulaProxy, para que los datos incrementales surtan efecto.
Esto implica un problema de reemisión incremental, porque el proceso de volcar los datos de existencias lleva mucho tiempo, puede llevar varias horas, y también hay nuevos datos incrementales en el proceso de volcar la cantidad total de datos y los datos incrementales durante este período puede no estar incluido en la cantidad total de datos. Por lo tanto, aquí se requiere una nueva emisión incremental histórica. Los datos recién agregados después de T0 (la hora de inicio de la sincronización completa) no se incluyen en la cantidad total de datos, y todos los datos después de T0 deben volver a emitirse.
Ejemplo de aplicación de la función de búsqueda de gráfico de conocimiento
1. Recuperación configurada
El método de recuperación convencional es: generar una declaración de consulta de acuerdo con Query, obtener el resultado de la recuperación, barajar según la estrategia y mostrar el resultado de la recuperación.
El problema de hacer esto es que los cuatro pasos anteriores deben repetirse cada vez que se agrega una nueva estrategia de recuperación, por lo que la recuperación no es lo suficientemente flexible y el negocio cambia mucho.
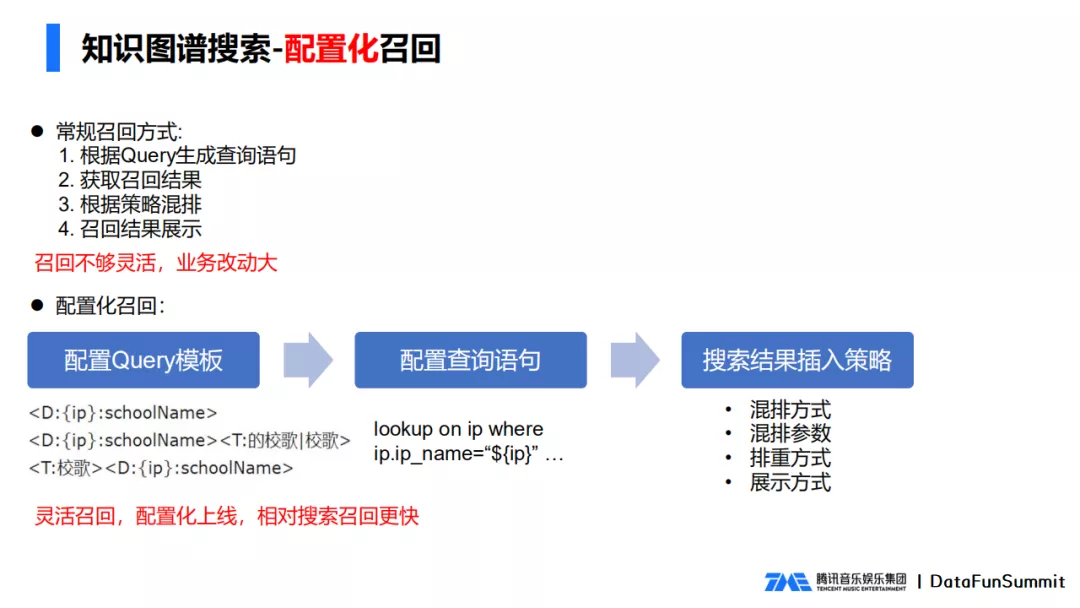
Hemos agregado un nuevo método de recuperación basado en la plantilla de consulta, que es generar declaraciones de consulta correspondientes de acuerdo con la plantilla y preestablecer algunas estrategias comunes de barajado. Por ejemplo, configuramos una plantilla para agregar una canción escolar. Al consultar la canción escolar, extraemos el nombre de la escuela y lo completamos en la declaración de consulta para formar una declaración de consulta gráfica completa. Al mismo tiempo, algunas estrategias de inserción de barajado están preestablecidas y los parámetros de barajado correspondientes se pueden completar para conectarse en línea. La ventaja de esto es que la recuperación es más flexible y el costo de la recuperación en línea es relativamente pequeño en comparación con la búsqueda.
2. Aplicaciones comerciales
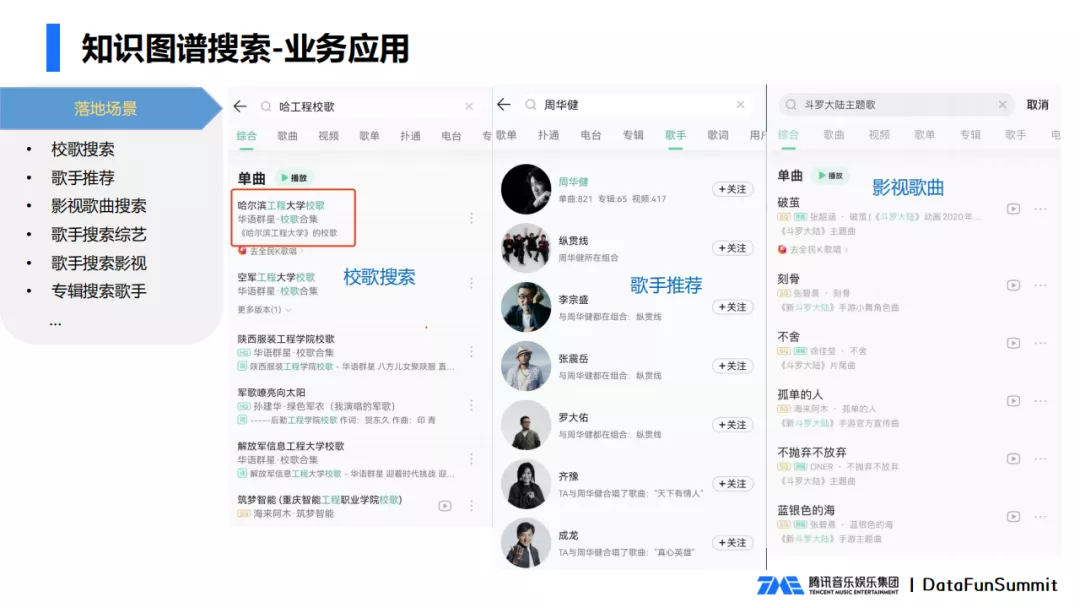
Finalmente, lanzamos los servicios que se muestran arriba, que admiten varios escenarios de búsqueda.
- Búsqueda de canciones escolares: cuando un usuario busca una combinación de nombre de universidad y canción escolar, recupera la canción escolar de la escuela correspondiente;
- Escena de cantante: cuando un usuario busca el nombre de un cantante, devuelve el grupo del cantante, así como los co-cantantes que han cantado canciones conocidas, etc.;
- Escena de películas y TV: cuando el usuario busca temas de películas y TV, canciones finales, episodios, etc., se devuelven las canciones de películas y TV correspondientes.
Resumen y Outlook
La discusión de hoy comienza desde la selección de datos de gráficos, hasta la definición de clasificación de esquemas, el diseño de la capa de arquitectura del proyecto y la búsqueda de gráficos de conocimiento. La conclusión es que mediante el uso de datos gráficos, la experiencia de los expertos se puede integrar de forma inteligente en el gráfico. La base de conocimiento realizada por la tecnología de datos de gráficos mejora funciones como la recuperación, la recomendación y la visualización. Tencent Music ha aplicado bien la tecnología de gráficos de conocimiento, lo que mejora en gran medida la experiencia de búsqueda del cliente y aumenta la permanencia del cliente. Abracemos la tecnología de IA y hagámosla mejor para la vida.
Preguntas y respuestas maravillosas
P: ¿Se considera la información de audio en el proceso de búsqueda?
R: Esto es para tenerlo en cuenta. Podemos usar la tecnología de reconocimiento de audio para identificar primero una gran categoría de canciones, como los géneros folk, rock y pop, y luego, cuando busquemos en línea, usaremos esta búsqueda por voz para recordar. Además, también hemos cooperado con QQ Music Tianjin Laboratory, como escuchar la música actual de Jinkeshi, y también usamos nuestra búsqueda limitada en segundo plano, que también es a través de la recuperación de información de audio.
P: ¿Dónde se clasifican los resultados de la búsqueda semántica? ¿Cómo se ordena con la búsqueda por palabra clave?
R: En primer lugar, usaremos un algoritmo para extraer la similitud entre una etiqueta semántica y una canción. Si busca semántica, puede recuperar las etiquetas semánticas y priorizar los resultados con una alta similitud semántica al frente. Por supuesto, habrá algunas situaciones extrañas. Por ejemplo, Zhao Lei tiene una canción llamada Folk Ballad. Folk Ballad es una canción, y también es semántica. Para clasificar, pondremos las canciones populares primero, porque es después de todo, la canción de un cantante relativamente conocido, y la estructura semántica correspondiente se colocará en la parte posterior, y luego tendremos un modelo de clasificación basado en algoritmos en la capa superior para dar a los usuarios Se recomienda sintonizar previamente con un alto número de clics.
P: ¿Se duplicará la memoria de doble búfer cuando se cambie la versión de índice completo?
R: De hecho, no tenemos búferes dobles en el proceso de cambio de índice. Cambiamos cada copia debajo de cada fragmento uno por uno. Al cambiar, se descargará dinámicamente, por lo que no ocupa memoria adicional.
P: Truncamiento cruzado, ¿es mejor truncar en el índice o seleccionar el truncamiento en línea?
R: El truncamiento en línea está seleccionado. Si el truncamiento fuera de línea provocará la pérdida de datos, no hay forma de retroceder. El truncamiento también se fragmenta y la recuperación de vectores también se puede fragmentar para la recuperación en paralelo.
Eso es todo por el compartir de hoy, gracias a todos.
Compartiendo invitados:

¿Tecnología de base de datos de gráficos de intercambio? Para unirse al grupo de intercambio de Nebula, complete primero su tarjeta de presentación de Nebula y el asistente de Nebula lo llevará al grupo ~~