Hola a todos, este artículo les mostrará cómo embellecer los números en un DataFrame de Pandas y usar algunas de las opciones de visualización más avanzadas al estilo de Pandas para mejorar su capacidad de analizar datos con Pandas.
Los ejemplos comunes son:
-
Utilice símbolos de moneda cuando trate con valores monetarios. Por ejemplo, si sus datos contienen el valor 25,00, no sabrá inmediatamente si el valor es Yuan chino, USD, GBP o alguna otra moneda.
-
El porcentaje es otra indicación útil, ¿0,05 o 5%? Usar el símbolo de porcentaje da una imagen muy clara de cómo interpretar los datos.
-
Los estilos de Pandas también incluyen herramientas más avanzadas para agregar color u otros elementos visuales a la salida.
[Nota] Únase a nuestro grupo de discusión técnica al final del artículo
analisis de CASO
Este artículo utilizará datos virtuales para explicárselo. Los datos son datos de ventas de 2018 para una organización ficticia.
El enlace del conjunto de datos es el siguiente:
https://www.aliyundrive.com/s/Tu9zBN2x81c
1. Importe la biblioteca relevante y lea los datos
import numpy as np
import pandas as pd
df = pd.read_excel('2018_Sales_Total.xlsx')
El efecto es el siguiente:  después de leer estos datos, podemos hacer un resumen rápido para ver cuánto nos compran los clientes y cuál es su monto promedio de compra. Para simplificar, he interceptado los primeros 5 elementos de datos aquí.
después de leer estos datos, podemos hacer un resumen rápido para ver cuánto nos compran los clientes y cuál es su monto promedio de compra. Para simplificar, he interceptado los primeros 5 elementos de datos aquí.
df.groupby('name')['ext price'].agg(['mean', 'sum'])
El resultado es el siguiente:
2. Agregar símbolo de moneda
Cuando miras estos datos, es un poco difícil entender la escala de los números porque tienes 6 puntos decimales y algunos números más grandes. Además, no está claro si se trata del dólar estadounidense o de otra moneda. Podemos resolver este problema usando DataFrame style.format.
(df.groupby('name')['ext price']
.agg(['mean', 'sum'])
.style.format('${0:,.2f}'))
Aquí está el resultado:  al usar la función de formato, puede usar todas las capacidades de las herramientas de formato de cadenas de Python en los datos. En este caso, usamos ${0:,.2f} para colocar el signo de dólar inicial, agregar una coma y redondear el resultado a dos lugares decimales.
al usar la función de formato, puede usar todas las capacidades de las herramientas de formato de cadenas de Python en los datos. En este caso, usamos ${0:,.2f} para colocar el signo de dólar inicial, agregar una coma y redondear el resultado a dos lugares decimales.
Por ejemplo, si quisiéramos redondear a 0 decimales, podríamos cambiar el formato a ${0:,0f}.
(df.groupby('name')['ext price']
.agg(['mean', 'sum'])
.style.format('${0:,.0f}'))
El resultado es el siguiente:
3. Añadir porcentaje
Si queremos ver las ventas totales por mes, podemos usar grouper para agregar por mes y calcular el porcentaje de cada mes de las ventas anuales totales.
monthly_sales = df.groupby([pd.Grouper(key='date', freq='M')])['ext price'].agg(['sum']).reset_index()
monthly_sales['pct_of_total'] = monthly_sales['sum'] / df['ext price'].sum()
Aquí está el resultado:  Para mostrar este porcentaje más claramente, mejor lo convertimos a un porcentaje.
Para mostrar este porcentaje más claramente, mejor lo convertimos a un porcentaje.
format_dict = {
'sum':'${0:,.0f}', 'date': '{:%m-%Y}', 'pct_of_total': '{:.2%}'}
monthly_sales.style.format(format_dict).hide_index()
El resultado es el siguiente: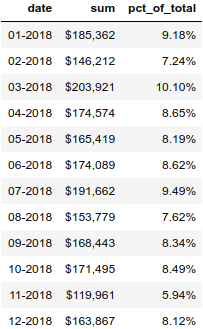
4. Resalta números
Además de diseñar números, también podemos diseñar celdas en un DataFrame. Resaltemos los números más altos en verde y los números más altos y más bajos en color.
(monthly_sales
.style
.format(format_dict)
.hide_index()
.highlight_max(color='lightgreen')
.highlight_min(color='#cd4f39'))
El resultado es el siguiente:
5. Establecer el color del degradado
Otra función útil es background_gradient, que resalta el rango de valores en una columna.
(monthly_sales.style
.format(format_dict)
.background_gradient(subset=['sum'], cmap='BuGn'))
El resultado es el siguiente:
6. Establecer la barra de datos
La función de estilo pandas también admite dibujar gráficos de barras dentro de las columnas.
(monthly_sales
.style
.format(format_dict)
.hide_index()
.bar(color='#FFA07A', vmin=100_000, subset=['sum'], align='zero')
.bar(color='lightgreen', vmin=0, subset=['pct_of_total'], align='zero')
.set_caption('2018 Sales Performance'))
El resultado es el siguiente:
7. Dibujar minigráficos
Creo que esta es una característica genial.
import sparklines
def sparkline_str(x):
bins=np.histogram(x)[0]
sl = ''.join(sparklines(bins))
return sl
sparkline_str.__name__ = "sparkline"
df.groupby('name')['quantity', 'ext price'].agg(['mean', sparkline_str])
El resultado es el siguiente:
artículo recomendado
-
El curso de mandarín "Aprendizaje automático" de Li Hongyi (2022) ya está aquí
-
Alguien hizo una versión china del aprendizaje automático y el aprendizaje profundo del Sr. Wu Enda
-
Soy adicto, y recientemente le di a la compañía una gran pantalla visual (con código fuente)
-
Tan elegantes, los artefactos de análisis de datos automáticos de 4 Python son realmente fragantes
Intercambio de Tecnología
¡Bienvenido a reimprimir, coleccionar, dar me gusta y apoyar!

En la actualidad, se ha abierto un grupo de intercambio técnico, con más de 2000 miembros . La mejor manera de comentar al agregar es: fuente + dirección de interés, que es conveniente para encontrar amigos de ideas afines.
- Método 1. Envíe la siguiente imagen a WeChat, mantenga presionada para identificarla y responda en segundo plano: agregar grupo;
- Método ②, agregar microseñal: dkl88191 , nota: de CSDN
- Método ③, cuenta pública de búsqueda de WeChat: aprendizaje de Python y extracción de datos , respuesta en segundo plano: agregar grupo
