Prefacio
Hace algún tiempo, vi en una plataforma de terceros que la cantidad de palabras en mi escritura en realidad excedía los 10 W. Es difícil imaginar que tuve que usar saltos de línea para completar la composición de 800 palabras en la escuela secundaria (las personas que lo saben deben haberlo hecho).
Después de hacer esto, desarrollé un hábito: verifique todo lo que pueda verificar usted mismo.
Así que escribí una herramienta en el tiempo libre de trabajar horas extras el viernes pasado:
https://github.com/crossoverJie/NOWS
Use SpringBoot para contar cuántas palabras ha escrito con una sola línea de comandos.
java -jar nows-0.0.1-SNAPSHOT.jar /xx/Hexo/source/_postsIngrese el directorio del artículo que se escaneará para generar los resultados (actualmente solo admite archivos Markdown que terminan en .md)

Por supuesto, el resultado es simplemente feliz (40 decenas de miles de palabras), porque en los primeros blogs, me gustaban los códigos postales grandes y algunas palabras en inglés no se filtraban, por lo que los resultados eran bastante diferentes.
Si solo se cuentan los caracteres chinos, debe ser preciso, la herramienta tiene un método de expansión flexible incorporado y los usuarios pueden personalizar la estrategia de estadísticas. Consulte el texto siguiente para obtener más detalles.
De hecho, esta herramienta es bastante simple, la cantidad de código es pequeña y no hay mucho de lo que valga la pena hablar. Pero después de recordar, ya sea una entrevista o una comunicación con los internautas, encontré un fenómeno común:
La mayoría de los desarrolladores novatos considerarán el subproceso múltiple, pero casi no existe una práctica relevante. Algunos incluso no saben qué multiproceso es útil en el desarrollo real.
Por este motivo, quiero traer un caso multiproceso práctico y fácil de entender para este tipo de amigos basado en esta sencilla herramienta.
Al menos déjate saber:
- ¿Por qué necesitamos multihilo?
- ¿Cómo implementar un programa multiproceso?
- ¿Problemas y soluciones causados por subprocesos múltiples?
Estadísticas de un solo hilo
Antes de hablar sobre el subproceso múltiple, hablemos sobre cómo implementar un solo subproceso.
Los requisitos esta vez también son muy simples, simplemente escanee un directorio para leer todos los archivos a continuación.
Entonces nuestra implementación tiene los siguientes pasos:
- Leer todos los archivos de un directorio.
- Mantenga todas las rutas de archivo a la memoria.
- Recorra todos los archivos uno por uno para leer el recuento de palabras del registro de texto.
Primero veamos cómo se implementan los dos primeros, y cuando escanee al directorio, debe continuar leyendo los archivos en el directorio actual.
Tal escenario es muy adecuado para la recursividad:
public List<String> getAllFile(String path){
File f = new File(path) ;
File[] files = f.listFiles();
for (File file : files) {
if (file.isDirectory()){
String directoryPath = file.getPath();
getAllFile(directoryPath);
}else {
String filePath = file.getPath();
if (!filePath.endsWith(".md")){
continue;
}
allFile.add(filePath) ;
}
}
return allFile ;
}
}Mantenga la ruta del archivo en una colección después de leerlo.
Cabe señalar que este número de recursividad debe controlarse para evitar el desbordamiento de la pila (StackOverflow).
La lectura final del contenido del archivo es usar la secuencia en Java8 para leer, de modo que el código pueda ser más conciso:
Stream<String> stringStream = Files.lines(Paths.get(path), StandardCharsets.UTF_8);
List<String> collect = stringStream.collect(Collectors.toList());El siguiente paso es leer el recuento de palabras y filtrar algún texto especial (por ejemplo, quiero filtrar todos los espacios, saltos de línea, hipervínculos, etc.).
Capacidad de expansión
Para un procesamiento simple, puede atravesar recopilar en el código anterior y reemplazar el contenido que debe filtrarse con vacío.
Pero las ideas de todos pueden ser diferentes. Por ejemplo, solo quiero filtrar los espacios, los saltos de línea y los hipervínculos, pero algunas personas necesitan eliminar todas las palabras en inglés que contienen, o incluso mantener los saltos de línea (como escribir un texto).
Entonces esto requiere un enfoque más flexible.
Habiendo leído lo anterior "Uso del modelo de cadena de responsabilidad para diseñar un interceptor", debería ser fácil pensar que tal escenario, el modelo de cadena de responsabilidad es más adecuado.
No se detallará el contenido específico del modelo de cadena de responsabilidad, y los interesados pueden consultar lo anterior.
Mira la implementación directamente aquí:
Defina la interfaz abstracta y el método de procesamiento de la cadena de responsabilidad:
public interface FilterProcess {
/**
* 处理文本
* @param msg
* @return
*/
String process(String msg) ;
}Implementación de espacios de manipulación y saltos de línea:
public class WrapFilterProcess implements FilterProcess{
@Override
public String process(String msg) {
msg = msg.replaceAll("\\s*", "");
return msg ;
}
}Implementación de manejo de hipervínculos:
public class HttpFilterProcess implements FilterProcess{
@Override
public String process(String msg) {
msg = msg.replaceAll("^((https|http|ftp|rtsp|mms)?:\\/\\/)[^\\s]+","");
return msg ;
}
}De esta manera, debe agregar estos identificadores de procesamiento a la cadena de responsabilidad durante la inicialización y proporcionar una API para que la ejecute el cliente.
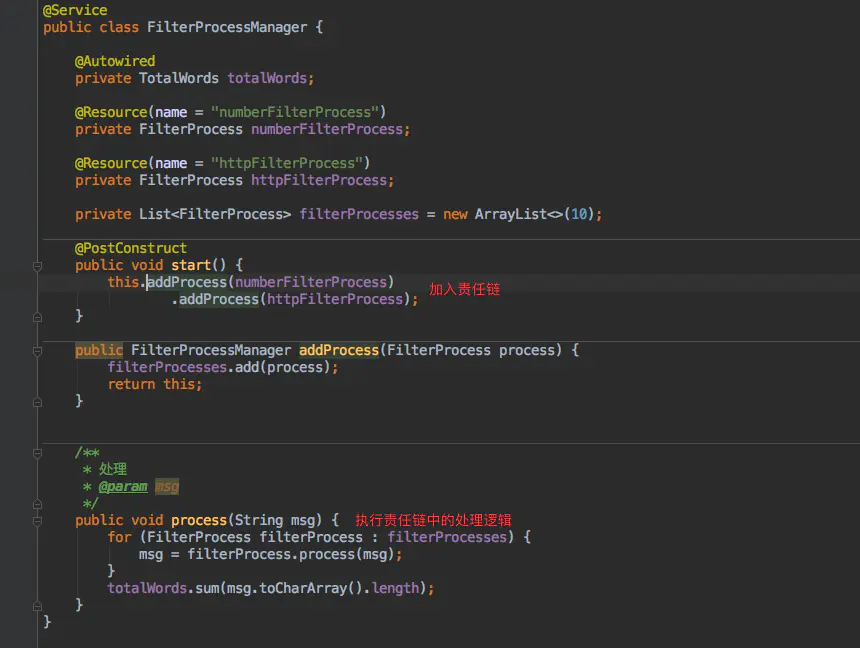
Una herramienta tan simple para contar palabras está completa.
Modo multiproceso
Es rápido de ejecutar una vez con la condición de que haya docenas de blogs en mi área local, pero si nuestros archivos son decenas de miles, cientos de miles o incluso millones.
Aunque la función puede realizarse, es concebible que tal tiempo se incremente definitivamente exponencialmente.
En este momento, los subprocesos múltiples se aprovechan y varios subprocesos pueden leer el archivo y resumir los resultados por separado.
El proceso de realización se convierte en:
- Leer todos los archivos de un directorio.
- La ruta del archivo es manejada por diferentes hilos.
- Resultados resumidos finales.
Problemas causados por subprocesos múltiples
No se trata de utilizar subprocesos múltiples. Echemos un vistazo al primer problema: compartir recursos.
En pocas palabras, es cómo asegurarse de que el recuento total de palabras de las estadísticas de subprocesos múltiples y de un solo subproceso sea coherente.
Según mi entorno local, echemos un vistazo a los resultados de la operación de un solo subproceso:

El total es: 414,142 palabras.
A continuación, cambie a un método de subprocesos múltiples:
List<String> allFile = scannerFile.getAllFile(strings[0]);
logger.info("allFile size=[{}]",allFile.size());
for (String msg : allFile) {
executorService.execute(new ScanNumTask(msg,filterProcessManager));
}
public class ScanNumTask implements Runnable {
private static Logger logger = LoggerFactory.getLogger(ScanNumTask.class);
private String path;
private FilterProcessManager filterProcessManager;
public ScanNumTask(String path, FilterProcessManager filterProcessManager) {
this.path = path;
this.filterProcessManager = filterProcessManager;
}
@Override
public void run() {
Stream<String> stringStream = null;
try {
stringStream = Files.lines(Paths.get(path), StandardCharsets.UTF_8);
} catch (Exception e) {
logger.error("IOException", e);
}
List<String> collect = stringStream.collect(Collectors.toList());
for (String msg : collect) {
filterProcessManager.process(msg);
}
}
}Utilice el grupo de subprocesos para administrar los subprocesos. Para obtener más contenido relacionado con el grupo de subprocesos, consulte aquí: "Cómo usar y comprender el grupo de subprocesos con elegancia"
Resultados del:

Encontraremos que no importa cuántas veces se ejecute, este valor será menor que nuestro valor esperado.
Veamos cómo se implementan las estadísticas.
@Component
public class TotalWords {
private long sum = 0 ;
public void sum(int count){
sum += count;
}
public long total(){
return sum;
}
}Se puede ver que solo está acumulando un tipo básico. ¿Qué provocó que este valor fuera menor de lo esperado?
Creo que la mayoría de la gente dirá: la operación de subprocesos múltiples hará que algunos subprocesos sobrescriban los valores calculados por otros subprocesos.
Pero, de hecho, esto es solo la apariencia del problema y la causa raíz aún no está clara.
Visibilidad de la memoria
La razón principal en realidad es causada por las regulaciones del Modelo de memoria de Java (JMM).
A continuación, se incluye una explicación de la "palabra clave volátil que debe conocer" escrita anteriormente:
Debido a las regulaciones del Modelo de memoria de Java (JMM), todas las variables se almacenan en la memoria principal y cada hilo tiene su propia memoria de trabajo (caché).
Cuando un hilo está funcionando, necesita copiar los datos de la memoria principal a la memoria de trabajo. De esta manera, cualquier operación en los datos se basa en la memoria de trabajo (eficiencia mejorada) y no puede manipular directamente los datos en la memoria principal y la memoria de trabajo de otros subprocesos, y luego vaciar los datos actualizados a la memoria principal.
La memoria principal mencionada aquí se puede considerar simplemente como memoria de pila , y la memoria de trabajo se puede considerar como memoria de pila .
Como se muestra abajo:
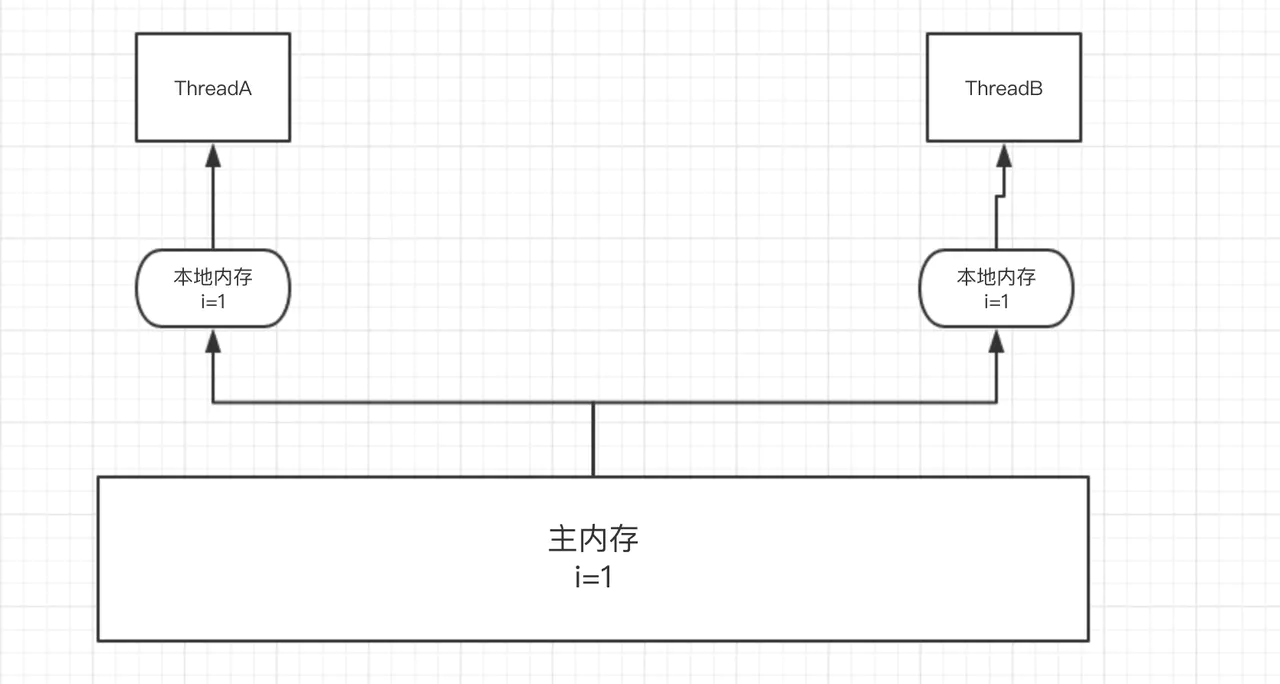
Por lo tanto, durante la operación simultánea, puede parecer que los datos leídos por el hilo B son los datos antes de que se actualice el hilo A.
No se ampliará más contenido relacionado, y los amigos interesados pueden consultar las publicaciones de blogs anteriores.
Hablemos de cómo resolver este problema, JDK nos ha ayudado a pensar en estos problemas.
Hay muchas herramientas de concurrencia que puede utilizar en el paquete de concurrencia java.util.concurrent.
Esto es muy adecuado para AtomicLong, que puede modificar datos de forma atómica.
Echemos un vistazo a la implementación modificada:
@Component
public class TotalWords {
private AtomicLong sum = new AtomicLong() ;
public void sum(int count){
sum.addAndGet(count) ;
}
public long total(){
return sum.get() ;
}
}Solo usa sus dos API. Ejecute el programa nuevamente y verá que el resultado sigue siendo incorrecto .

Incluso es 0.
Comunicación entre hilos
En este momento, hay un nuevo problema, veamos cómo obtener los datos totales.
List<String> allFile = scannerFile.getAllFile(strings[0]);
logger.info("allFile size=[{}]",allFile.size());
for (String msg : allFile) {
executorService.execute(new ScanNumTask(msg,filterProcessManager));
}
executorService.shutdown();
long total = totalWords.total();
long end = System.currentTimeMillis();
logger.info("total sum=[{}],[{}] ms",total,end-start);No sé si puede ver el problema. De hecho, cuando finalmente imprime el número total, no sabe si otros hilos han completado la ejecución.
Debido a que executeorService.execute () regresará directamente, ningún hilo ha terminado de ejecutarse al imprimir para obtener los datos, lo que conduce a este resultado.
Sobre la comunicación entre hilos También escribí contenido relacionado antes: "Comprensión profunda de la comunicación entre hilos"
Existen aproximadamente las siguientes formas:

Aquí usamos el método del grupo de subprocesos:
Agregue una condición de juicio después de desactivar el grupo de subprocesos:
executorService.shutdown();
while (!executorService.awaitTermination(100, TimeUnit.MILLISECONDS)) {
logger.info("worker running");
}
long total = totalWords.total();
long end = System.currentTimeMillis();
logger.info("total sum=[{}],[{}] ms",total,end-start);Así que lo intentamos de nuevo y descubrimos que no importa cuántas veces el resultado sea correcto:

Mejora de la eficiencia
Algunos amigos pueden preguntar, este método no ha mejorado mucho la eficiencia.
En realidad, esto se debe al hecho de que tengo menos archivos locales y el procesamiento de un archivo, que requiere mucho tiempo, es relativamente corto.
Incluso si el número de subprocesos se abre lo suficiente como para provocar cambios de contexto frecuentes, la eficiencia de ejecución se reduce.
Para simular la mejora de la eficiencia, dejé que el hilo actual duerma durante 100 milisegundos para simular el tiempo de ejecución de cada archivo procesado.
Veamos cuánto tiempo lleva ejecutarse en un solo hilo.

Tiempo total: [8404] ms
Entonces toma tiempo cuando el tamaño del grupo de subprocesos es 4:
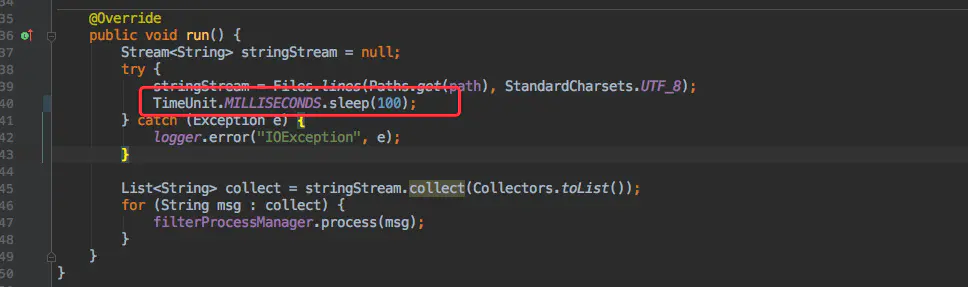

Tiempo total: [2350] ms
Puede verse que la mejora de la eficiencia sigue siendo muy obvia.
Piensa más
Este es solo uno de los usos del multihilo. Creo que los amigos que vean aquí deberían comprenderlo mejor.
Dejemos un ejercicio posterior a la lectura para todos, la escena es similar:
Hay decenas de millones de datos de números de teléfonos móviles almacenados en Redis u otros medios de almacenamiento.Cada número es único y es necesario recorrer todos estos números en el menor tiempo posible.
Los amigos que estén interesados en ideas pueden dejar un mensaje al final del artículo para participar en la discusión.
para resumir
Espero que los amigos que hayan terminado de leer puedan tener sus propias respuestas a las preguntas al principio del artículo:
- ¿Por qué necesitamos multihilo?
- ¿Cómo implementar un programa multiproceso?
- ¿Problemas y soluciones causados por subprocesos múltiples?
El código del artículo está aquí.
https://github.com/crossoverJie/NOWS