Haga clic en el algoritmo de inteligencia artificial anterior y los grandes datos de Python para obtener más productos secos
En la parte superior derecha ... Establece como una estrella ★, obtén recursos a la primera
Solo para intercambio académico, si hay alguna infracción, comuníquese para eliminar
Reimpreso en: El corazón de la máquina
Esta vez, NVIDIA lanzó la herramienta de desarrollo "Metaverse".
La interpretación final del metaverso depende de NVIDIA.
Hace unos meses, el debate entre el verdadero y el falso Huang Renxun encendió el concepto del "metaverso". El 9 de noviembre, la conferencia GTC abrió nuevamente y el fundador y director ejecutivo de Nvidia, Huang Renxun, salió de su cocina virtual.
¿Es "real" esta vez?

En la entrevista con los medios recién concluida, Huang Renxun se enfrentó a la curiosidad de la gente: "Todo en el discurso de apertura fue renderizado, nada era real, todo era virtual".
Los comentarios animaron a los reporteros que se conectaron al teléfono. Entonces, un reportero preguntó: "¿Acabas de decir que todo es virtual, incluyéndote a ti mismo?" "Jajaja, todo es virtual, pero excepto yo, soy real", agregó Huang Renxun. Parece que Huang Renxun solo usó este gran grito ahogado para hacer una broma a todos.
Mirando hacia atrás en este GTC Keynote, podemos encontrar varios puntos muy importantes, como el metaverso y la computación acelerada.
La versión Q de Huang Renxun que abraza el Metaverso
"Les contaré los planes importantes en los que estamos trabajando que remodelarán nuestra industria", dijo Jen-Hsun Huang.
Nvidia ha demostrado cómo se puede usar Omniverse para simular almacenes, fábricas, sistemas físicos y biológicos, comunicaciones 5G, robótica, autos sin conductor, y ahora la última tecnología puede generar directamente avatares completamente funcionales.
Esta versión Q de Huang Renxun se llama Toy-Me, que puede comunicarse con personas en lenguaje natural.

Utiliza Megatron 530B, el modelo de procesamiento de lenguaje natural preentrenado más grande de la industria, "toma prestada" la voz, la imagen y el gesto del habla de Huang Renxun, y toda la persona también tiene efectos especiales de trazado de rayos: lo más importante es que todo es en tiempo real. Generado. Hace unos meses esto no era posible.
Para probar si toda la persona virtual es realmente útil, la gente le hizo algunas preguntas no tan simples y obtuvo respuestas satisfactorias:

Conoce la astronomía por encima y por debajo de la geografía, y también entiende los temas de protección ambiental.
Decir que "Internet ha cambiado todo" parece un eufemismo ahora, todos estamos conectados entre nosotros hoy. Internet es esencialmente una representación digital del mundo, principalmente información de texto, voz, imagen y video en 2D. "Esto está a punto de cambiar, y ahora tenemos la tecnología para crear un mundo 3D completamente nuevo o modelar el mundo físico. En el mundo virtual, existen leyes reales de la física y, por supuesto, se pueden violar", dijo Huang Renxun. . "Allí podemos estar con amigos, o podemos estar con AI".
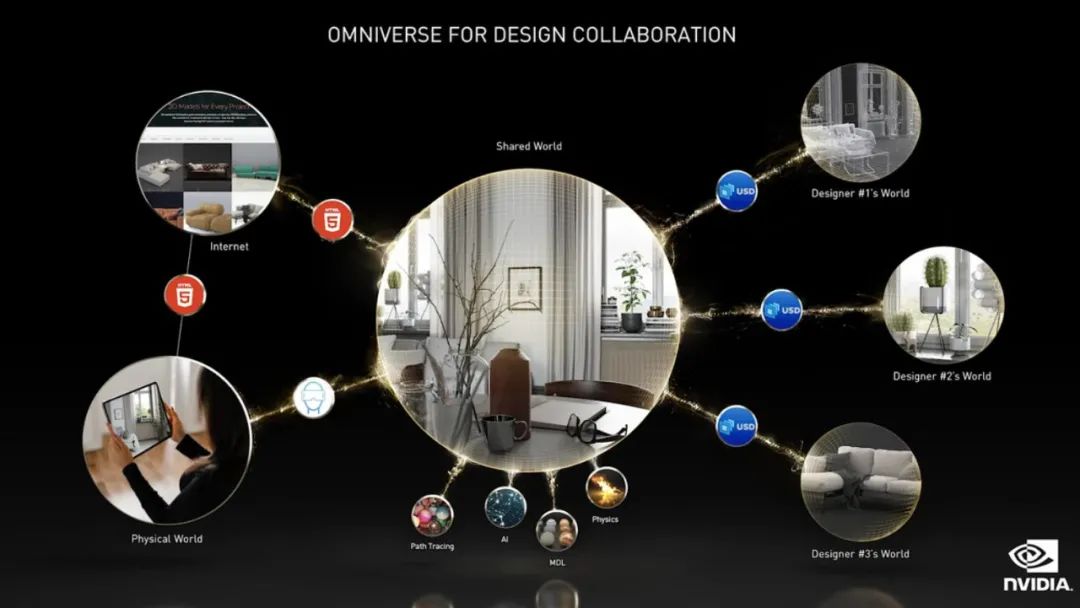
Cambiaremos de un mundo a otro como un salto en la red, y este nuevo mundo será mucho más grande que el mundo real. Vamos a comprar cosas en 3D, al igual que estamos comprando una canción en 2D o un libro ahora. En este mundo también podemos comprar, mantener o vender bienes raíces, muebles, automóviles, artículos de lujo y arte. En el mundo virtual, la gente creará algo más rico y diverso que el mundo físico.
A diferencia de los juegos, Omniverse está diseñado para centros de datos y algún día podrá escalar globalmente. El portal del Omniverso es un "agujero de gusano digital" que conecta a las personas y las computadoras con el Omniverso, que a su vez conecta todos los mundos virtuales. En estos mundos virtuales, puedes diseñar aviones y ejecutar fábricas virtuales. "El funcionamiento de la fábrica del mundo real es una réplica del mundo virtual, que es el concepto de gemelo digital".
En Keynote, Nvidia también mostró una serie de nuevas funciones para Omniverse, incluida Showroom, que muestra gráficos, física, materiales e IA. Granja, una capa de sistema para coordinar trabajos por lotes en múltiples sistemas, estaciones de trabajo, servidores, bare metal o virtualizados. Omniverse AR puede transmitir gráficos a teléfonos y anteojos AR. Omniverse VR es la primera realidad virtual con trazado de rayos interactivo de velocidad de cuadro completa.
11 días de entrenamiento GPT-3, tiempo de inferencia de Megatron 530B reducido a medio segundo, Lao Huang sacrificó un artefacto modelo grande
Construir IA en mundos virtuales requiere construir modelos poderosos y darles capacidades de razonamiento en tiempo real, lo que requiere técnicas completamente diferentes a las anteriores.
Los modelos de lenguaje basados en transformadores en el procesamiento del lenguaje natural han crecido rápidamente en los últimos años, impulsados por cálculos a gran escala, grandes conjuntos de datos y algoritmos y software avanzados para entrenar estos modelos. Un modelo de lenguaje con una mayor cantidad de parámetros, más datos y más tiempo de entrenamiento puede conducir a una comprensión del lenguaje más rica y granular. Por lo tanto, se generalizan bien para estudiantes eficientes de tiro cero o pocos tiros con alta precisión en muchas tareas y conjuntos de datos de PNL.
En la conferencia GTC de ayer, NVIDIA presentó el marco NVIDIA NeMo Megatron optimizado para entrenar modelos de lenguaje con billones de parámetros, el Modelo de lenguaje grande (LLM) personalizable Megatron 530B para entrenar nuevos dominios e idiomas, y el Multi-GPU Megatron 530B, NVIDIA Triton inference servidor con capacidades de inferencia distribuida de múltiples nodos . Estas herramientas, combinadas con el sistema NVIDIA DGX, brindan una solución de nivel empresarial que se puede implementar en entornos de producción del mundo real para simplificar el desarrollo y la implementación de modelos de lenguaje grandes.
"Entrenar un modelo de lenguaje grande requiere mucho coraje: un sistema que cuesta cientos de millones de dólares y entrenar modelos de billones de parámetros en petabytes de datos durante meses requiere una gran creencia, una gran experiencia y una pila optimizada", dijo Huang Renxun en el habla. Entonces crearon NeMo Megatron, un marco para entrenar modelos de habla y lenguaje con billones de parámetros. NeMo Megatron es un proyecto de código abierto desarrollado sobre la base de Megatron, dirigido por investigadores de NVIDIA, para estudiar el entrenamiento eficiente de grandes modelos de lenguaje Transformer. El marco se ha optimizado para escalar horizontalmente a sistemas a gran escala manteniendo una alta eficiencia computacional.

Huang Renxun dijo que sus investigadores habían probado el Selene DGX SuperPOD de 500 nodos de NVIDIA, y los resultados mostraron que NeMo Megatron completó el entrenamiento de GPT-3 en solo 11 días . Además, junto con Microsoft, completaron el entrenamiento del modelo Megatron MT-NLG 530 mil millones de parámetros en 6 semanas. “Con Nemo Megatron, cualquier empresa puede entrenar modelos de lenguaje de última generación a gran escala”, dijo Jen-Hsun Huang.
Después del entrenamiento, ¿cómo se ejecuta un modelo de lenguaje grande? Esto requiere un servidor de inferencia dedicado. En un entorno de producción, la inferencia en modelos grandes requiere una latencia extremadamente baja para poder utilizarse. "En un servidor de CPU dual Xeon Platinum de gama alta, el tiempo de inferencia del Megatron 530B lleva más de un minuto. Para muchas aplicaciones, esto es básicamente inutilizable". Huang Renxun dio un ejemplo: "Los modelos acelerados por GPU también son muy desafiantes. , porque los requisitos de tamaño del modelo son mucho más altos que la memoria de la GPU". GPT-3 tiene 175 mil millones de parámetros y requiere al menos 350 GB de memoria, y Megatron tiene más parámetros y requisitos de memoria de hasta 1 TB.
Para resolver problemas de inferencia de modelos grandes, NVIDIA creó el servidor de inferencia Triton. Huang Renxun dijo que Triton es el primer servidor de inferencia distribuida del mundo, que puede realizar inferencia distribuida entre múltiples GPU y múltiples nodos. Con Triton, GPT-3 puede ejecutarse fácilmente en un servidor de 8 GPU; Megatron 530B puede implementarse en dos sistemas DGX, lo que reduce el tiempo de inferencia de 1 minuto a medio segundo.
Los modelos de lenguaje a hiperescala son importantes para el futuro, ya que responden preguntas complejas, comprenden y resumen documentos extensos, permiten la traducción, organizan el lenguaje, escriben historias, escriben códigos, comprenden las intenciones de las personas y automáticamente sin supervisión humana. La capacitación también se puede realizar sin muestras, lo que significa pueden soportar una amplia variedad de tareas en diferentes dominios.
La construcción de sistemas para modelos de lenguaje a gran escala puede ser la mayor aplicación de supercomputación en el futuro. Dado que las demandas de potencia informática superan con creces el desarrollo de las capacidades de GPU, Nvidia ha encontrado varios caminos nuevos.
"En la ciencia, se está produciendo una revolución de software basada en el aprendizaje profundo, y este proceso finalmente tendrá un gran impacto. Tres sistemas dinámicos interrelacionados en la ciencia computacional nos permitirán hacer millones de veces el salto de potencia informática", dijo Huang.
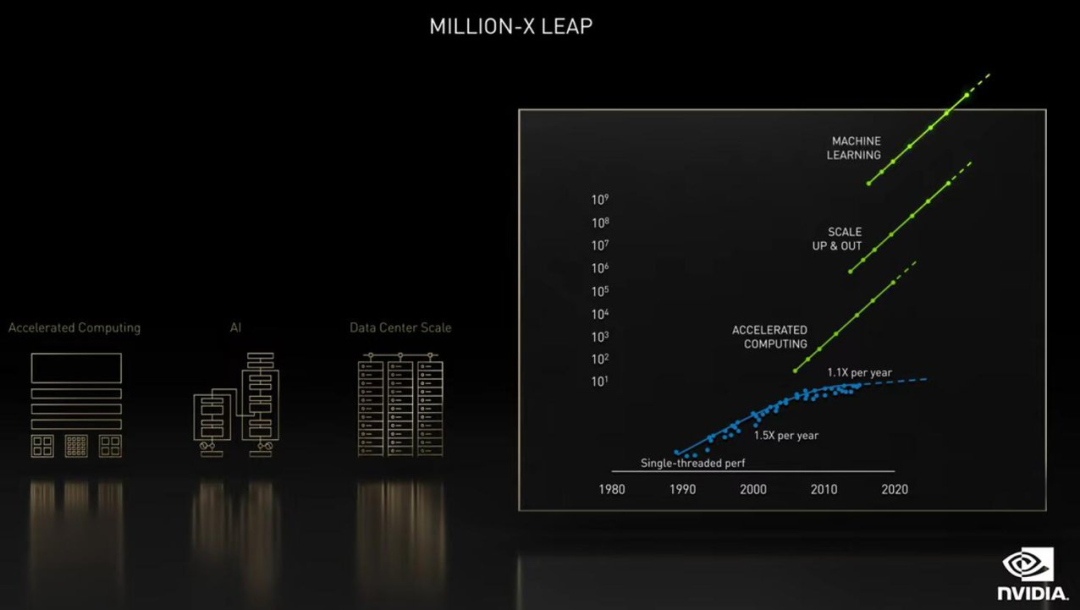
Esta triple aceleración, la primera es la aceleración informática, el chip, el sistema y la biblioteca de aceleración, y luego la computación completa de la aplicación nos traerá un aumento de velocidad de 50 veces.
En segundo lugar, está la fuerza impulsora, el auge del aprendizaje profundo que ha provocado la revolución moderna de la IA, cambiando fundamentalmente el software. El software escrito en aprendizaje profundo está altamente paralelizado, lo que lo hace útil para la aceleración con GPU y puede escalar a múltiples GPU y múltiples uniones. Ampliar a un sistema grande como el DGX SuperPOD puede aumentar la velocidad en otras 5000x.
Finalmente, el software de IA escrito a través del aprendizaje profundo puede predecir resultados de 1000 a 10 000 veces más rápido que el software escrito por humanos, reescribiendo por completo la forma en que resolvemos problemas, e incluso los problemas que podemos resolver.
"Puede ser hasta 250 millones de veces. Por supuesto, los resultados que obtenga serán diferentes, dependiendo de la escala de su inversión. Pero si el problema se puede resolver, la inversión llegará", dijo Huang Renxun.
---------♥---------
Declaración: este contenido proviene de Internet y los derechos de autor pertenecen al autor original
Las imágenes provienen de Internet y no representan la posición de esta cuenta oficial. Si hay alguna infracción, póngase en contacto para eliminar
WeChat privado del Dr. AI, todavía hay algunas vacantes


¿Cómo dibujar un hermoso diagrama de modelo de aprendizaje profundo?
¿Cómo dibujar un hermoso diagrama de red neuronal?
Un artículo para comprender varias circunvoluciones en el aprendizaje profundo
Click para ver soporte
