contenido
2 Algoritmo de bosque aleatorio de aislamiento
2.1 Descripción general del algoritmo
4 Implementación de código Python
1. Introducción
Isolation Forest es un algoritmo eficiente de detección de anomalías, similar al random forest, pero cada vez que se seleccionan aleatoriamente los atributos de división y los puntos (valores) de división, en lugar de seleccionar según la ganancia de información o el índice de Gini.
[Recomendación] La belleza de los sistemas de potencia y los algoritmos
2 Algoritmo de bosque aleatorio de aislamiento
2.1 Descripción general del algoritmo
Aislamiento, que significa aislamiento/aislamiento, es un sustantivo. Su verbo es aislar, y bosque es bosque. Juntos, es "bosque aislado", y también se llama "bosque único". Parece que no hay un nombre chino unificado. Tal vez todos estén acostumbrados a usar su nombre en inglés de bosque de aislamiento, conocido como iForest.
El algoritmo iForest es eliminado conjuntamente por Zhou Zhihua de la Universidad de Nanjing y Fei Tony Liu, Kai Ming Ting de la Universidad de Monash, Australia, etc., y se usa para extraer datos. Es adecuado para la detección de anomalías de datos numéricos continuos. La anomalía está definida ya que es "más probable que esté separado" - puede entenderse como un punto que está escasamente distribuido y lejos de una población de alta densidad. El uso de estadísticas para explicar, en el espacio de datos, las áreas con distribución dispersa indican que la probabilidad de que ocurran datos en esta área es muy baja, por lo que se puede considerar que los datos que caen en estas áreas son anormales. Suele utilizarse para la detección de ataques y el análisis de anomalías de tráfico en la seguridad de la red, y las instituciones financieras lo utilizan para descubrir comportamientos fraudulentos. Para los datos anómalos encontrados, elimine directamente los datos anómalos, como eliminar el ruido de los datos en la limpieza de datos, o analice profundamente los datos anómalos, como el análisis de las características de comportamiento de los ataques y el fraude.
2.2 Introducción al principio
iForest es un enfoque no paramétrico y no supervisado, es decir, no define modelos matemáticos ni etiqueta entrenamiento. iForest utiliza una estrategia muy eficiente para encontrar qué puntos se aíslan fácilmente. Supongamos que usamos un hiperplano aleatorio para dividir el espacio de datos, y una división puede generar dos subespacios (se detalla con un cuchillo y el pastel se divide en dos). Luego, continuamos cortando cada subespacio con un hiperplano aleatorio y hacemos un bucle hasta que solo haya un punto de datos en cada subespacio. Intuitivamente, podemos encontrar que los cúmulos con alta densidad se cortan muchas veces antes de dejar de cortar, pero los puntos con baja densidad son fáciles de detener en un subespacio muy temprano.
El algoritmo de iForest se beneficia de la idea del bosque aleatorio. Así como el bosque aleatorio se compone de una gran cantidad de árboles de decisión, el bosque de iForest también se compone de una gran cantidad de árboles binarios. El árbol en iForest es llamado árbol de aislamiento, o iTree para abreviar. El árbol iTree no es lo mismo que el árbol de decisión. El proceso de construcción también es más simple que un árbol de decisión y es un proceso completamente aleatorio.
Suponiendo que hay N piezas de datos en el conjunto de datos, al construir un ITree, N muestras se muestrean uniformemente a partir de las N piezas de datos (generalmente muestreo sin reemplazo), como las muestras de entrenamiento del árbol. En la muestra, se selecciona aleatoriamente una característica y se selecciona aleatoriamente un valor dentro del rango de todos los valores de esta característica (entre los valores mínimo y máximo), la muestra se divide en binario y el menor que este valor en la muestra se divide en nodos El lado izquierdo del nodo, mayor o igual a este valor se divide al lado derecho del nodo. A partir de esto, se obtienen una condición de división y conjuntos de datos en los lados izquierdo y derecho, y luego el proceso anterior se repite en los conjuntos de datos izquierdo y derecho respectivamente, hasta que el conjunto de datos tenga un solo registro o la altura límite del árbol sea alcanzado.
Porque los datos anormales son pequeños y los valores propios son muy diferentes de los datos normales. Por lo tanto, al construir un iTree, los datos anormales están más cerca de la raíz, mientras que los datos normales están más lejos de la raíz. El resultado de un ITree a menudo no es confiable.El algoritmo iForest construye múltiples árboles binarios a través de múltiples muestreos. Finalmente, los resultados de todos los árboles se integran y la profundidad promedio se toma como la profundidad de salida final, calculando así la rama atípica del punto de datos.
2.3 Pasos del algoritmo
Cómo cortar este espacio de datos es la idea central del diseño de iForest. Este artículo solo aprende los métodos más básicos. Dado que el corte es aleatorio, es necesario usar el método de conjunto para obtener un valor de convergencia (método Monte Carlo), es decir, cortar desde el principio repetidamente y luego promediar los resultados de cada corte. IForest consta de t iTree (Árbol de aislamiento) árboles aislados, cada iTree es una estructura de árbol binario, así que hablemos primero sobre la construcción del árbol iTree y luego veamos la construcción del árbol iForest.
explicación de 3 parámetros
(1) n_estimators: cuántos árboles construir, int, opcional (predeterminado=100) especifica el número de árboles aleatorios generados en el bosque
(2) max_samples: el número de muestras, automáticamente 256, int, opcional (predeterminado='auto)
El número de muestras utilizadas para entrenar números aleatorios, es decir, el tamaño del submuestreo:
1) Si se establece una constante int, las muestras max_samples se extraerán de la muestra total X para generar un árbol iTree
2) Si se establece un valor flotante, max_samples*X.shape[0] muestras se extraerán de la muestra total X, y X.shape[0] representa el número total de muestras
3) Si se configura "auto", entonces max_samples=min(256, n_samples), n_samples es el número total de muestras
Si el valor de max_samples es mayor que el número total de muestras proporcionadas, todas las muestras se utilizarán para construir el número, lo que significa que no hay muestreo, y las muestras utilizadas por los n_estimators construidos son las mismas, es decir, todas las muestras .
(3) contaminación: c(n) es 0,1 de forma predeterminada, flotante en (0, 0,5), opcional (predeterminado = 0,1), el rango de valores es (0, 0,5), lo que indica la proporción de datos anómalos en un conjunto de datos dado , es la cantidad de contaminación en el conjunto de datos, el papel de definir el valor de este parámetro es definir el umbral en la función de decisión. Si se establece en "auto", el umbral para la función de decisión es el mismo que en el documento, con un cambio en la versión 0.20: el valor predeterminado cambió de 0.1 a automático con 0.22.
(4) max_features: el número máximo de características, el valor predeterminado es 1, int o float, opcional, especifica el número de atributos extraídos de la muestra total X para entrenar cada árbol iTree, solo se usa un atributo por defecto
Si se establece en int, extrae los atributos max_features
Si es un flotador, extraiga los atributos max_features *X.shape[1]
(5) bootstrap: booleano, opcional (predeterminado = Falso), al construir un árbol, si se reemplaza el muestreo la próxima vez, si True es un reemplazo, entonces cada árbol se puede volver a colocar para muestrear los datos de entrenamiento; si False no es un reemplazo , es decir, ejecutar muestras sin reemplazo
(6) n_jobs: int o Ninguno, opcional (predeterminado = Ninguno), el número de trabajos a ejecutar en paralelo cuando se ejecutan las funciones fit() y predict(). Excepto en el caso del contexto joblib.parallel_backend, Ninguno significa 1 y configurarlo en -1 significa usar todos los procesadores disponibles.
(7) comportamiento: str, default='antiguo', el comportamiento de la función de decisión decision_function, que puede ser "antiguo" y "nuevo". Si estableces behavior='new', decision_function se adaptará a la API de otros algoritmos de detección de anomalías, que se configurarán como predeterminados en el futuro. Como se explica en detalle en la documentación del atributo offset_, decision_function se vuelve dependiente del parámetro de contaminación, con 0 como su umbral natural para detectar valores atípicos.
Nuevo en la versión 0.20: el parámetro de comportamiento se agregó en la versión 0.20 para compatibilidad con versiones anteriores
comportamiento='viejo' quedó en desuso en la versión 0.20 y no funcionará en la versión 0.22
El parámetro de comportamiento quedará obsoleto en la versión 0.22 y se eliminará en la versión 0.24
(8)random_state:int,RandomState instancia o Ninguno,opcional(predeterminado=Ninguno)
Si se establece en una constante int, el valor del parámetro random_state es la semilla utilizada para el generador de números aleatorios
Si se establece en una instancia de RandomState, random_state es un generador de números aleatorios
Si se establece en Ninguno, el generador de números aleatorios es la instancia de RandomState utilizada en np.random
(9) verbose: int, opcional (predeterminado=0) controla la verbosidad del proceso de construcción del árbol
(10) warm_start: bool, opcional (predeterminado = Falso), cuando se establece en TRUE, reutiliza el resultado de la llamada anterior para ajustar y agrega más árboles al conjunto de bosque 1 anterior; de lo contrario, ajusta un bosque completamente nuevo
4 Implementación de código Python
# _*_coding:utf-8_*_
#~~~~欢迎关注公众号:电力系统与算法之美~~~~~~~·
#~~~~~~~~导入相关库~~~~~~~~~~~·
import numpy as np
import matplotlib.pyplot as plt
from pylab import *
import matplotlib; matplotlib.use('TkAgg')
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
from sklearn.ensemble import IsolationForest #孤立随机森林
rng = np.random.RandomState(42) #该方法为np中的伪随机数生成方法,其中的42表示种子,只要种子一致 产生的伪随机数序列即为一致。
#~~~~~~~产生训练数据~~~~~~~~~~
X = 0.3 * rng.randn(100, 2) #randn:标准正态分布;rand的随机样本位于[0, 1)中
X_train = np.r_[X + 2, X - 2]
X = 0.3 * rng.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))
#~~~~~~~~~训练模型~~~~~~~~~~~~·
clf = IsolationForest( max_samples=100,random_state=rng, contamination='auto')
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_outliers)
xx, yy = np.meshgrid(np.linspace(-5, 5, 50), np.linspace(-5, 5, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
#~~~~~~~~~~~~~~~~可视化~~~~~~~~~~~~~~~~~~·
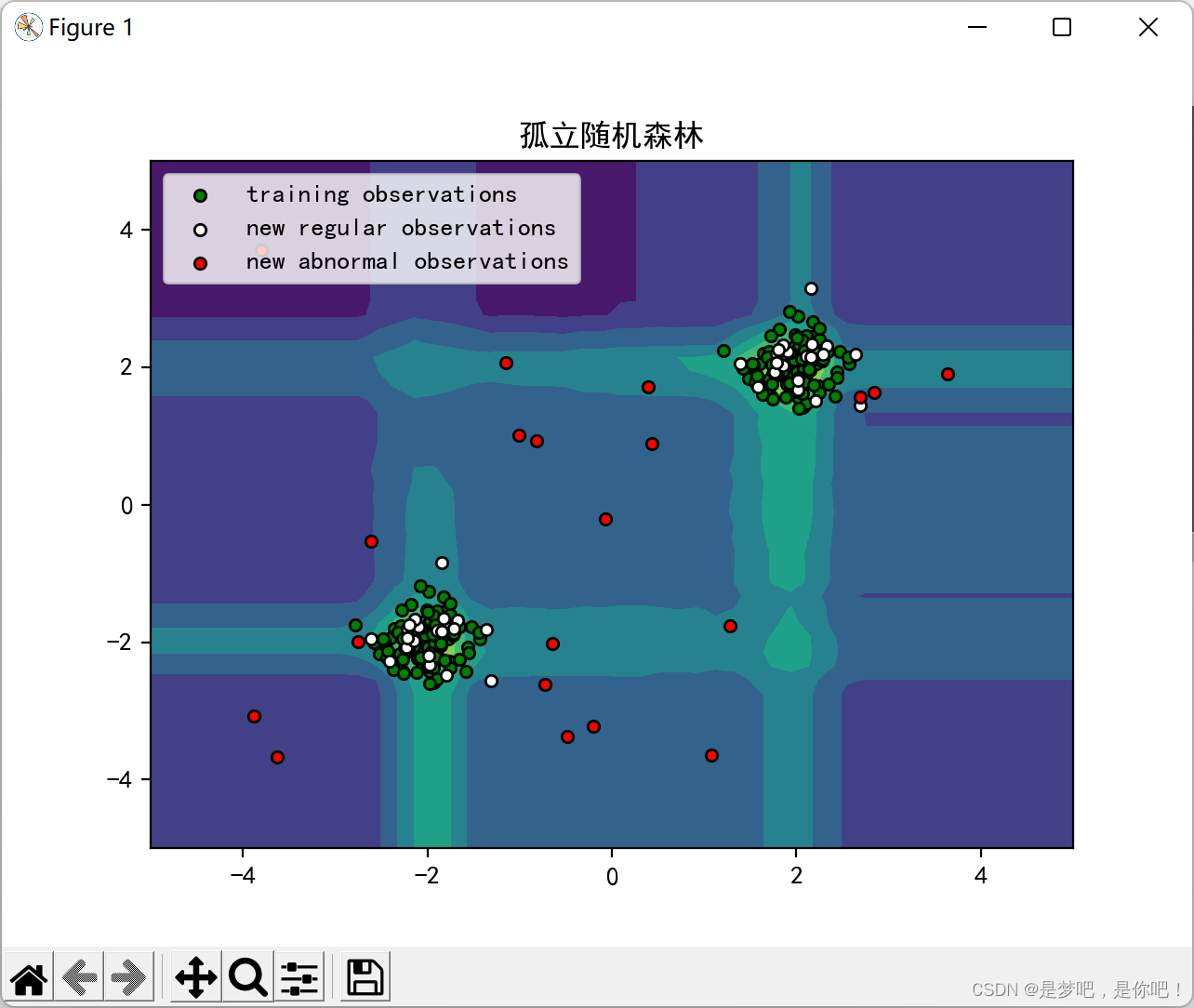
plt.title("孤立随机森林")
plt.contourf(xx, yy, Z, camp=plt.cm.Blues_r)
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='green',
s=20, edgecolor='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='white',
s=20, edgecolor='k')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='red',
s=20, edgecolor='k')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([b1, b2, c],
["training observations",
"new regular observations", "new abnormal observations"],
loc="upper left")
plt.show()5 resultados