El fondo de la cuenta oficial registra varios indicadores de lectura de los artículos publicados, que incluyen: título del contenido, número total de lectores, número total de lecturas, número total de quienes comparten, número total de acciones, número de seguidores después de la lectura, tasa de lectura entregada, número de lecturas generadas al compartir, la tasa de intercambio por primera vez, la cantidad de lecturas generadas por cada intercambio y la tasa de finalización de lectura.
Intentamos utilizar el algoritmo de bosque aleatorio en el aprendizaje automático para predecir si existen ciertos indicadores o combinaciones de indicadores que pueden predecir la cantidad de seguidores después de la lectura.
Formatear datos y leer datos.
El conjunto de datos incluye 9 indicadores estadísticos para 1588 artículos.
Leer matriz de estadísticas: WeChatOfficialAccount.txt
Número de seguidores después de leer:
WeChatCuentaOficialSeguidores.txt
feature_file <- "data/WeChatOfficialAccount.txt"
metadata_file <- "data/WeChatOfficialAccountFollowers.txt"
feature_mat <- read.table(feature_file, row.names = 1, header = T, sep="\t", stringsAsFactors =T)
# 处理异常的特征名字
# rownames(feature_mat) <- make.names(rownames(feature_mat))
metadata <- read.table(metadata_file, row.names=1, header=T, sep="\t", stringsAsFactors =T)
dim(feature_mat)## [1] 1588 9La representación de las estadísticas de lectura es la siguiente:
feature_mat[1:4,1:5]## TotalReadingPeople TotalReadingCounts TotalSharingPeople TotalSharingCounts ReadingRate
## 1 8278 11732 937 1069 0.0847
## 2 8951 12043 828 929 0.0979
## 3 18682 22085 781 917 0.0608
## 4 4978 6166 525 628 0.0072La representación de los metadatos es la siguiente.
head(metadata)## FollowersAfterReading
## 1 227
## 2 188
## 3 119
## 4 116
## 5 105
## 6 100Detección y secuenciación de muestras
También es una operación que debe garantizar que el orden de las muestras en la tabla de muestras y la tabla de expresiones estén alineados .
feature_mat_sampleL <- rownames(feature_mat)
metadata_sampleL <- rownames(metadata)
common_sampleL <- intersect(feature_mat_sampleL, metadata_sampleL)
# 保证表达表样品与METAdata样品顺序和数目完全一致
feature_mat <- feature_mat[common_sampleL,,drop=F]
metadata <- metadata[common_sampleL,,drop=F]Ya sea para juzgar la clasificación o la regresión
Los parámetros se proporcionaron al leer los datos anteriormente stringsAsFactors =T, por lo que este paso se puede ignorar.
Si la columna correspondiente al grupo es un número, conviértala a un tipo numérico: realice una regresión
Si la columna correspondiente al grupo está agrupada, conviértala a tipo de factor - haga clasificación
# R4.0之后默认读入的不是factor,需要做一个转换
# devtools::install_github("Tong-Chen/ImageGP")
library(ImageGP)
# 此处的FollowersAfterReading根据需要修改
group = "FollowersAfterReading"
# 如果group对应的列为数字,转换为数值型 - 做回归
# 如果group对应的列为分组,转换为因子型 - 做分类
if(numCheck(metadata[[group]])){
if (!is.numeric(metadata[[group]])) {
metadata[[group]] <- mixedToFloat(metadata[[group]])
}
} else{
metadata[[group]] <- as.factor(metadata[[group]])
}Análisis preliminar del bosque aleatorio
library(randomForest)
# 查看参数是个好习惯
# 有了前面的基础概述,再看每个参数的含义就明确了很多
# 也知道该怎么调了
# 每个人要解决的问题不同,通常不是别人用什么参数,自己就跟着用什么参数
# 尤其是到下游分析时
# ?randomForest
# 查看源码
# randomForest:::randomForest.defaultDespués de cargar el paquete, analícelo directamente y ajuste los parámetros después de ver el resultado.
# 设置随机数种子,具体含义见 https://mp.weixin.qq.com/s/6plxo-E8qCdlzCgN8E90zg
set.seed(304)
# 直接使用默认参数
rf <- randomForest(feature_mat, metadata[[group]])Al observar los resultados preliminares, el tipo de bosque aleatorio se juzga a medida que 分类se construye un árbol, y la decisión óptima se toma 500a partir de indicadores seleccionados al azar 3cada vez que se toma una decisión ( mtry), el residuo cuadrado promedio Mean of squared residuals: 39,82736 y se explica el grado de variación. % Var explained: 74,91. El resultado parece normal.
rf##
## Call:
## randomForest(x = feature_mat, y = metadata[[group]])
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 3
##
## Mean of squared residuals: 39.82736
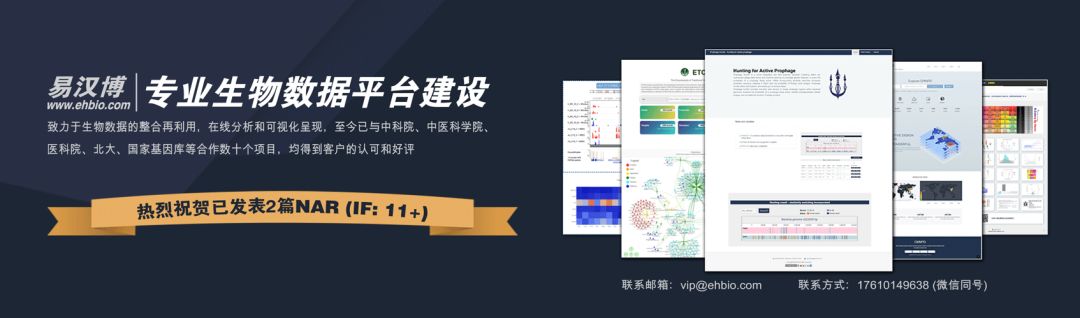
## % Var explained: 74.91Al observar el efecto de predicción del modelo en el conjunto de entrenamiento, parece que la consistencia no es mala.
library(ggplot2)
followerDF <- data.frame(Real_Follower=metadata[[group]], Predicted_Follower=predict(rf, newdata=feature_mat))
sp_scatterplot(followerDF, xvariable = "Real_Follower", yvariable = "Predicted_Follower",
smooth_method = "auto") + coord_fixed(1)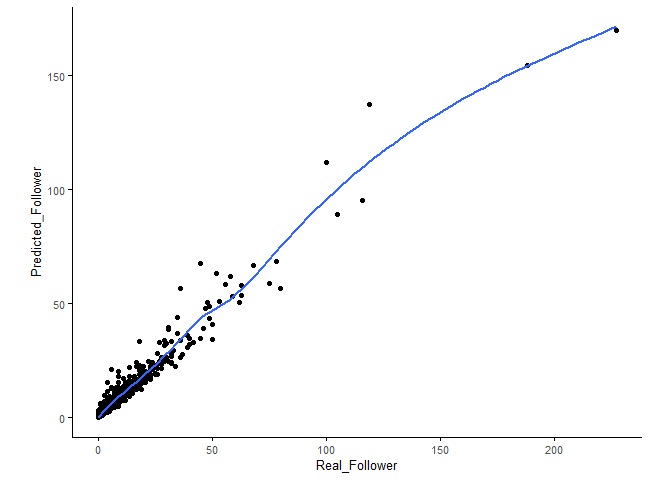
Procedimiento operativo estándar de bosque aleatorio
Dividir conjuntos de entrenamiento y prueba
library(caret)
seed <- 1
set.seed(seed)
train_index <- createDataPartition(metadata[[group]], p=0.75, list=F)
train_data <- feature_mat[train_index,]
train_data_group <- metadata[[group]][train_index]
test_data <- feature_mat[-train_index,]
test_data_group <- metadata[[group]][-train_index]dim(train_data)## [1] 1192 9dim(test_data)## [1] 396 9Selección de características de Boruta para identificar variables categóricas clave
# install.packages("Boruta")
library(Boruta)
set.seed(1)
boruta <- Boruta(x=train_data, y=train_data_group, pValue=0.01, mcAdj=T,
maxRuns=300)
boruta## Boruta performed 14 iterations in 5.917085 secs.
## 8 attributes confirmed important: AverageReadingCountsForEachSharing, FirstSharingRate,
## ReadingRate, TotalReadingCounts, TotalReadingCountsOfSharing and 3 more;
## 1 attributes confirmed unimportant: ReadingFinishRate;Mire los resultados de la identificación de importancia de la variable (de hecho, también se ha reflejado en el resultado anterior), 8una variable importante, 0una variable posiblemente importante ( tentative variable, la puntuación de importancia no tiene diferencia estadística con la mejor puntuación de la variable sombra), 1una es Variables no importantes.
table(boruta$finalDecision)##
## Tentative Confirmed Rejected
## 0 8 1Grafique la importancia de las variables identificadas. Si hay pocas variables, puede utilizar el dibujo predeterminado. Cuando hay muchas variables, la imagen dibujada no se puede ver con claridad y debe organizar los datos y dibujar usted mismo.
Defina una función para extraer el valor de importancia correspondiente a cada variable.
library(dplyr)
boruta.imp <- function(x){
imp <- reshape2::melt(x$ImpHistory, na.rm=T)[,-1]
colnames(imp) <- c("Variable","Importance")
imp <- imp[is.finite(imp$Importance),]
variableGrp <- data.frame(Variable=names(x$finalDecision),
finalDecision=x$finalDecision)
showGrp <- data.frame(Variable=c("shadowMax", "shadowMean", "shadowMin"),
finalDecision=c("shadowMax", "shadowMean", "shadowMin"))
variableGrp <- rbind(variableGrp, showGrp)
boruta.variable.imp <- merge(imp, variableGrp, all.x=T)
sortedVariable <- boruta.variable.imp %>% group_by(Variable) %>%
summarise(median=median(Importance)) %>% arrange(median)
sortedVariable <- as.vector(sortedVariable$Variable)
boruta.variable.imp$Variable <- factor(boruta.variable.imp$Variable, levels=sortedVariable)
invisible(boruta.variable.imp)
}boruta.variable.imp <- boruta.imp(boruta)
head(boruta.variable.imp)## Variable Importance finalDecision
## 1 AverageReadingCountsForEachSharing 4.861474 Confirmed
## 2 AverageReadingCountsForEachSharing 4.648540 Confirmed
## 3 AverageReadingCountsForEachSharing 6.098471 Confirmed
## 4 AverageReadingCountsForEachSharing 4.701201 Confirmed
## 5 AverageReadingCountsForEachSharing 3.852440 Confirmed
## 6 AverageReadingCountsForEachSharing 3.992969 ConfirmedSólo Confirmedse trazan las variables. Se puede ver en la figura que las principales 4variables en el ranking de importancia están todas relacionadas con "compartir" (el número de lecturas generadas al compartir, el número total de participantes, el número total de acciones, la primera tasa de acciones), y compartir artículos es muy importante para aumentar la atención.
library(ImageGP)
sp_boxplot(boruta.variable.imp, melted=T, xvariable = "Variable", yvariable = "Importance",
legend_variable = "finalDecision", legend_variable_order = c("shadowMax", "shadowMean", "shadowMin", "Confirmed"),
xtics_angle = 90, coordinate_flip =T)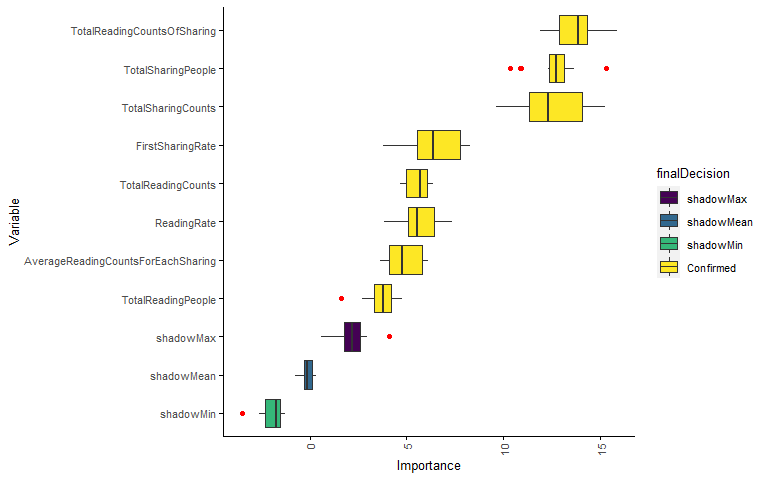
Extraer variables importantes y variables potencialmente importantes.
boruta.finalVarsWithTentative <- data.frame(Item=getSelectedAttributes(boruta, withTentative = T), Type="Boruta_with_tentative")data <- cbind(feature_mat, metadata)
variableFactor <- rev(levels(boruta.variable.imp$Variable))
sp_scatterplot(data, xvariable = group, yvariable = variableFactor[1], smooth_method = "auto")
Debido a que no hay muchas variables, también puede usarlo ggpairspara ver cómo se relacionan todas las variables entre sí y cómo se relacionan con la variable de respuesta.
library(GGally)
ggpairs(data, progress = F)
Validación cruzada para elegir parámetros y ajustar el modelo.
Defina una función para generar algunas columnas para prueba mtry(una serie de valores no mayores que el número total de variables).
generateTestVariableSet <- function(num_toal_variable){
max_power <- ceiling(log10(num_toal_variable))
tmp_subset <- c(unlist(sapply(1:max_power, function(x) (1:10)^x, simplify = F)), ceiling(max_power/3))
#return(tmp_subset)
base::unique(sort(tmp_subset[tmp_subset<num_toal_variable]))
}
# generateTestVariableSet(78)Seleccionar datos relacionados con variables características clave
# 提取训练集的特征变量子集
boruta_train_data <- train_data[, boruta.finalVarsWithTentative$Item]
boruta_mtry <- generateTestVariableSet(ncol(boruta_train_data))Tuning y modelado con Caret
library(caret)
if(file.exists('rda/wechatRegression.rda')){
borutaConfirmed_rf_default <- readRDS("rda/wechatRegression.rda")
} else {
# Create model with default parameters
trControl <- trainControl(method="repeatedcv", number=10, repeats=5)
seed <- 1
set.seed(seed)
# 根据经验或感觉设置一些待查询的参数和参数值
tuneGrid <- expand.grid(mtry=boruta_mtry)
borutaConfirmed_rf_default <- train(x=boruta_train_data, y=train_data_group, method="rf",
tuneGrid = tuneGrid, #
metric="RMSE", #metric='Kappa'
trControl=trControl)
saveRDS(borutaConfirmed_rf_default, "rda/wechatRegression.rda")
}
borutaConfirmed_rf_default## Random Forest
##
## 1192 samples
## 8 predictor
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 5 times)
## Summary of sample sizes: 1073, 1073, 1073, 1072, 1073, 1073, ...
## Resampling results across tuning parameters:
##
## mtry RMSE Rsquared MAE
## 1 6.441881 0.7020911 2.704873
## 2 6.422848 0.7050505 2.720557
## 3 6.418449 0.7052825 2.736505
## 4 6.431665 0.7039496 2.742612
## 5 6.453067 0.7013595 2.754239
## 6 6.470716 0.6998307 2.758901
## 7 6.445304 0.7020575 2.756523
##
## RMSE was used to select the optimal model using the smallest value.
## The final value used for the model was mtry = 3.Precisión de trazado frente a hiperparámetros
plot(borutaConfirmed_rf_default)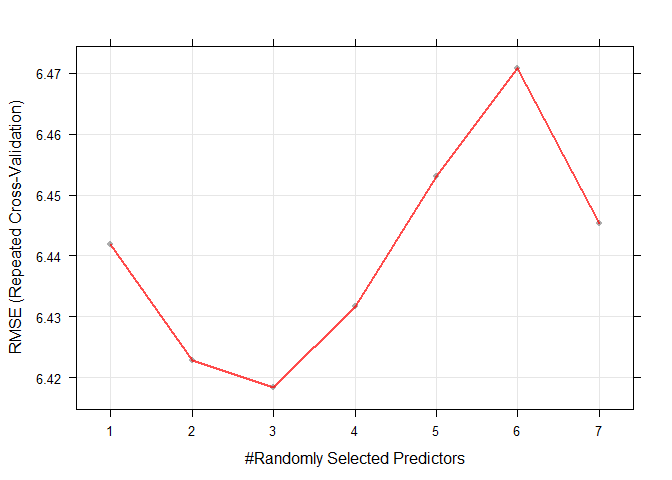
Trace las 20 variables con la mayor contribución (la importancia de las variables evaluadas por Boruta es ligeramente diferente de la importancia evaluada por el modelo mismo)
dotPlot(varImp(borutaConfirmed_rf_default))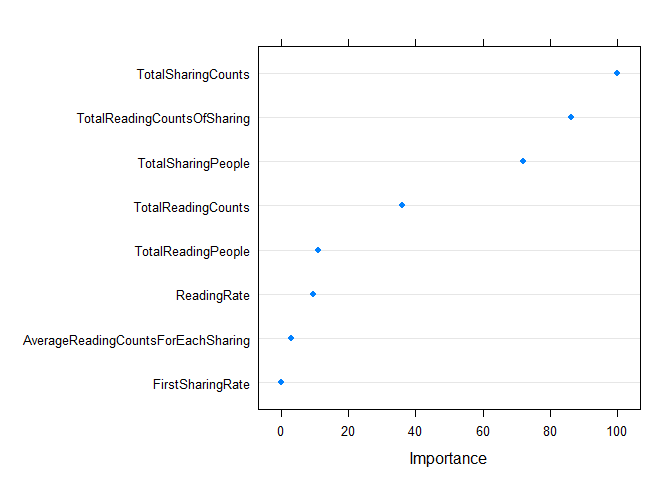
Extraer el modelo final seleccionado y evaluar su desempeño.
borutaConfirmed_rf_default_finalmodel <- borutaConfirmed_rf_default$finalModelPrimero, utilice el conjunto de datos de entrenamiento para evaluar el efecto de entrenamiento del modelo construido, RMSE=3.1lo Rsquared=0.944cual es bastante bueno.
# 获得模型结果评估参数
predictions_train <- predict(borutaConfirmed_rf_default_finalmodel, newdata=train_data)
postResample(pred = predictions_train, obs = train_data_group)## RMSE Rsquared MAE
## 3.1028533 0.9440182 1.1891391Utilice los datos de prueba para evaluar el efecto predictivo del modelo, RMSE=6.2, Rsquared=0.825ok. Continúe con otros métodos para ver si se puede mejorar.
predictions_train <- predict(borutaConfirmed_rf_default_finalmodel, newdata=test_data)
postResample(pred = predictions_train, obs = test_data_group)## RMSE Rsquared MAE
## 6.2219834 0.8251457 2.7212806library(ggplot2)
testfollowerDF <- data.frame(Real_Follower=test_data_group, Predicted_Follower=predictions_train)
sp_scatterplot(testfollowerDF, xvariable = "Real_Follower", yvariable = "Predicted_Follower",
smooth_method = "auto") + coord_fixed(1)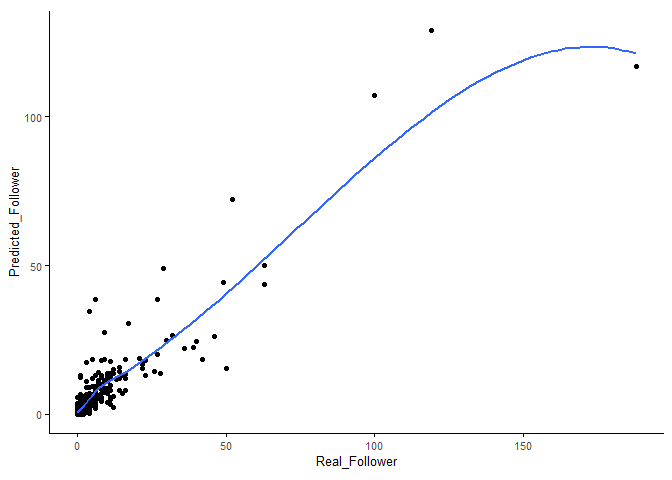
Inconvenientes de la regresión forestal aleatoria
Los valores predichos por el modelo de regresión de bosque aleatorio no excederán el rango de valores de la variable de respuesta en el conjunto de entrenamiento y no se pueden utilizar para extrapolación.
Los bosques aleatorios mejorados por regresión (RERF) se pueden utilizar como solución.
Referencias
https://medium.com/swlh/random-forest-and-its-implementation-71824ced454f
https://neptune.ai/blog/random-forest-regression-when-does-it-fail-and-why
https://levelup.gitconnected.com/random-forest-regression-209c0f354c84
https://rpubs.com/Isaac/caret_reg
Serie de tutoriales de aprendizaje automático
A partir de bosques aleatorios, comprenda paso a paso los conceptos y prácticas de árboles de decisión, bosques aleatorios, ROC/AUC, conjuntos de datos y validación cruzada.
Utilice texto para palabras que se puedan explicar claramente, utilice imágenes para mostrar, fórmulas para descripciones poco claras y escriba un código simple para fórmulas poco claras para aclarar cada vínculo y concepto paso a paso.
Luego, madure la aplicación del código, ajuste de modelos, comparación de modelos, evaluación de modelos y aprenda los conocimientos y habilidades necesarios para todo el aprendizaje automático.
Una imagen para sentir varios algoritmos de aprendizaje automático.
Algoritmo de aprendizaje automático: descripción teórica del bosque aleatorio
Algoritmo de aprendizaje automático: un estudio preliminar de bosque aleatorio (1)
Aprendizaje automático: validación cruzada manual de bosque aleatorio 10 veces
Indicadores de evaluación del modelo de aprendizaje automático: curva ROC y valor AUC
Aprendizaje automático: conjunto de entrenamiento, conjunto de validación, conjunto de prueba
Una función unifica 238 paquetes R de aprendizaje automático, lo cual es sorprendente
4 formas de ajustar aleatoriamente los parámetros de Random Forest según Caret
Aprendizaje automático, parte 17: detección de variables de funciones (1)
Aprendizaje automático, parte 18: Detección de variables de características de Boruta (2)
Enviarle un sitio web de aprendizaje automático en línea, ¡qué fragante!
Múltiples conjuntos de datos de expresión de cáncer para el aprendizaje automático
Productos anteriores (haga clic en la imagen para ir directamente al texto del tutorial correspondiente)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























Responda en segundo plano con "La primera ola de beneficios en la Colección Life Letter" o haga clic para leer el texto original y obtener una colección de tutoriales.